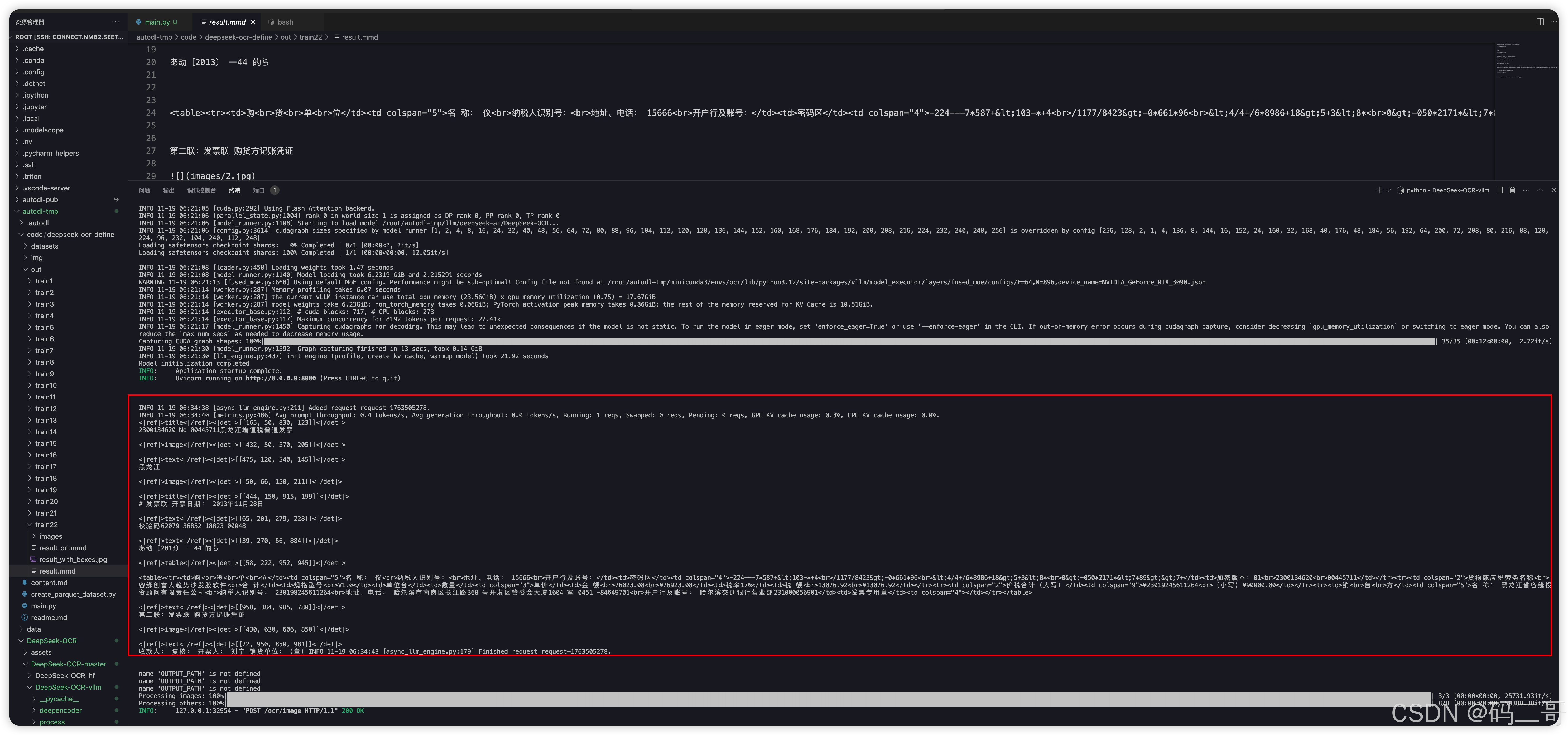
试验环境说明
本次的试验环境:
- autodl提供的GPU算力
- 本地环境是Mac
查看远程服务器上cuda版本号
(base) root@autodl-container-4d7d449e0f-962d5f9d:~# nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Wed_Sep_21_10:33:58_PDT_2022
Cuda compilation tools, release 11.8, V11.8.89
Build cuda_11.8.r11.8/compiler.31833905_0试验前提条件
已经安装了deepseek-ocr, vllm
本次需求
本次的需求是,希望将通过vllm推理deepseek-ocr的方式,改成web方式。
提高效率。
免的每次请求,都得重新加载deepseek-ocr模型。
实现方案
借助豆包
已经有大模型了,自己写代码是不可能的。
问豆包的问题,如下所示:
run_dpsk_ocr_image.python, config.py
是deepseek-ai/DeepSeek-OCR目录下的。
豆包给的答复,如下:
python
# main.py
import asyncio
import re
import os
import torch
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from typing import Optional
import uvicorn
# 配置环境变量
if torch.version.cuda == '11.8':
os.environ["TRITON_PTXAS_PATH"] = "/usr/local/cuda-11.8/bin/ptxas"
os.environ['VLLM_USE_V1'] = '0'
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
# 导入所需模块
from vllm import AsyncLLMEngine, SamplingParams
from vllm.engine.arg_utils import AsyncEngineArgs
from vllm.model_executor.models.registry import ModelRegistry
import time
from deepseek_ocr import DeepseekOCRForCausalLM
from PIL import Image, ImageDraw, ImageFont, ImageOps
import numpy as np
from tqdm import tqdm
from process.ngram_norepeat import NoRepeatNGramLogitsProcessor
from process.image_process import DeepseekOCRProcessor
from config import MODEL_PATH, BASE_SIZE, IMAGE_SIZE, CROP_MODE, TOKENIZER
# 注册模型
ModelRegistry.register_model("DeepseekOCRForCausalLM", DeepseekOCRForCausalLM)
# 初始化FastAPI应用
app = FastAPI(title="Deepseek OCR Web Service")
# 全局变量存储模型引擎(启动时加载)
engine = None
# 请求参数模型
class OCRRequest(BaseModel):
input_path: str
output_path: str
prompt: str
crop_mode: Optional[bool] = CROP_MODE
# 工具函数(从原有代码迁移)
def load_image(image_path):
try:
image = Image.open(image_path)
corrected_image = ImageOps.exif_transpose(image)
return corrected_image
except Exception as e:
print(f"error: {e}")
try:
return Image.open(image_path)
except:
return None
def re_match(text):
pattern = r'(<\|ref\|>(.*?)<\|/ref\|><\|det\|>(.*?)<\|/det\|>)'
matches = re.findall(pattern, text, re.DOTALL)
mathes_image = []
mathes_other = []
for a_match in matches:
if '<|ref|>image<|/ref|>' in a_match[0]:
mathes_image.append(a_match[0])
else:
mathes_other.append(a_match[0])
return matches, mathes_image, mathes_other
def extract_coordinates_and_label(ref_text, image_width, image_height):
try:
label_type = ref_text[1]
cor_list = eval(ref_text[2])
except Exception as e:
print(e)
return None
return (label_type, cor_list)
def draw_bounding_boxes(image, refs):
image_width, image_height = image.size
img_draw = image.copy()
draw = ImageDraw.Draw(img_draw)
overlay = Image.new('RGBA', img_draw.size, (0, 0, 0, 0))
draw2 = ImageDraw.Draw(overlay)
font = ImageFont.load_default()
img_idx = 0
for i, ref in enumerate(refs):
try:
result = extract_coordinates_and_label(ref, image_width, image_height)
if result:
label_type, points_list = result
color = (np.random.randint(0, 200), np.random.randint(0, 200), np.random.randint(0, 255))
color_a = color + (20, )
for points in points_list:
x1, y1, x2, y2 = points
x1 = int(x1 / 999 * image_width)
y1 = int(y1 / 999 * image_height)
x2 = int(x2 / 999 * image_width)
y2 = int(y2 / 999 * image_height)
if label_type == 'image':
try:
cropped = image.crop((x1, y1, x2, y2))
cropped.save(f"{OUTPUT_PATH}/images/{img_idx}.jpg")
except Exception as e:
print(e)
pass
img_idx += 1
try:
if label_type == 'title':
draw.rectangle([x1, y1, x2, y2], outline=color, width=4)
draw2.rectangle([x1, y1, x2, y2], fill=color_a, outline=(0, 0, 0, 0), width=1)
else:
draw.rectangle([x1, y1, x2, y2], outline=color, width=2)
draw2.rectangle([x1, y1, x2, y2], fill=color_a, outline=(0, 0, 0, 0), width=1)
text_x = x1
text_y = max(0, y1 - 15)
text_bbox = draw.textbbox((0, 0), label_type, font=font)
text_width = text_bbox[2] - text_bbox[0]
text_height = text_bbox[3] - text_bbox[1]
draw.rectangle([text_x, text_y, text_x + text_width, text_y + text_height],
fill=(255, 255, 255, 30))
draw.text((text_x, text_y), label_type, font=font, fill=color)
except:
pass
except:
continue
img_draw.paste(overlay, (0, 0), overlay)
return img_draw
def process_image_with_refs(image, ref_texts):
result_image = draw_bounding_boxes(image, ref_texts)
return result_image
# 初始化模型引擎(启动时执行)
def init_engine():
global engine
if engine is None:
engine_args = AsyncEngineArgs(
model=MODEL_PATH,
hf_overrides={"architectures": ["DeepseekOCRForCausalLM"]},
block_size=256,
max_model_len=8192,
enforce_eager=False,
trust_remote_code=True,
tensor_parallel_size=1,
gpu_memory_utilization=0.75,
)
engine = AsyncLLMEngine.from_engine_args(engine_args)
return engine
# 异步生成函数
async def stream_generate(engine, image=None, prompt=''):
logits_processors = [NoRepeatNGramLogitsProcessor(
ngram_size=30,
window_size=90,
whitelist_token_ids={128821, 128822}
)]
sampling_params = SamplingParams(
temperature=0.0,
max_tokens=8192,
logits_processors=logits_processors,
skip_special_tokens=False,
)
request_id = f"request-{int(time.time())}"
printed_length = 0
if image and '<image>' in prompt:
request = {
"prompt": prompt,
"multi_modal_data": {"image": image}
}
elif prompt:
request = {
"prompt": prompt
}
else:
raise ValueError("Prompt cannot be empty")
final_output = ""
async for request_output in engine.generate(request, sampling_params, request_id):
if request_output.outputs:
full_text = request_output.outputs[0].text
new_text = full_text[printed_length:]
print(new_text, end='', flush=True)
printed_length = len(full_text)
final_output = full_text
print('\n')
return final_output
# API接口
@app.post("/ocr/image")
async def ocr_image(request: OCRRequest):
try:
# 验证输入路径
if not os.path.exists(request.input_path):
raise HTTPException(status_code=400, detail=f"Input file not found: {request.input_path}")
# 创建输出目录
os.makedirs(request.output_path, exist_ok=True)
os.makedirs(f'{request.output_path}/images', exist_ok=True)
# 加载图像
image = load_image(request.input_path)
if image is None:
raise HTTPException(status_code=400, detail="Failed to load image")
image = image.convert('RGB')
# 处理图像特征
if '<image>' in request.prompt:
image_features = DeepseekOCRProcessor().tokenize_with_images(
images=[image],
bos=True,
eos=True,
cropping=request.crop_mode
)
else:
image_features = ''
# 获取预加载的引擎
global engine
if engine is None:
engine = init_engine()
# 执行OCR识别
result_out = await stream_generate(engine, image_features, request.prompt)
# 保存结果
with open(f'{request.output_path}/result_ori.mmd', 'w', encoding='utf-8') as f:
f.write(result_out)
# 处理边界框和图像
matches_ref, matches_images, mathes_other = re_match(result_out)
result_image = process_image_with_refs(image.copy(), matches_ref)
result_image.save(f'{request.output_path}/result_with_boxes.jpg')
# 处理输出文本
outputs = result_out
for idx, a_match_image in enumerate(tqdm(matches_images, desc="Processing images")):
outputs = outputs.replace(a_match_image, f'\n')
for idx, a_match_other in enumerate(tqdm(mathes_other, desc="Processing others")):
outputs = outputs.replace(a_match_other, '').replace('\\coloneqq', ':=').replace('\\eqqcolon', '=:')
with open(f'{request.output_path}/result.mmd', 'w', encoding='utf-8') as f:
f.write(outputs)
return {
"status": "success",
"output_path": request.output_path,
"message": "OCR processing completed"
}
except Exception as e:
return {
"status": "error",
"message": str(e)
}
# 启动时初始化模型
@app.on_event("startup")
async def startup_event():
print("Initializing Deepseek OCR model...")
init_engine()
print("Model initialization completed")
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)启动web服务
执行,如下:
sh
pip install fastapi uvicorn
python main.py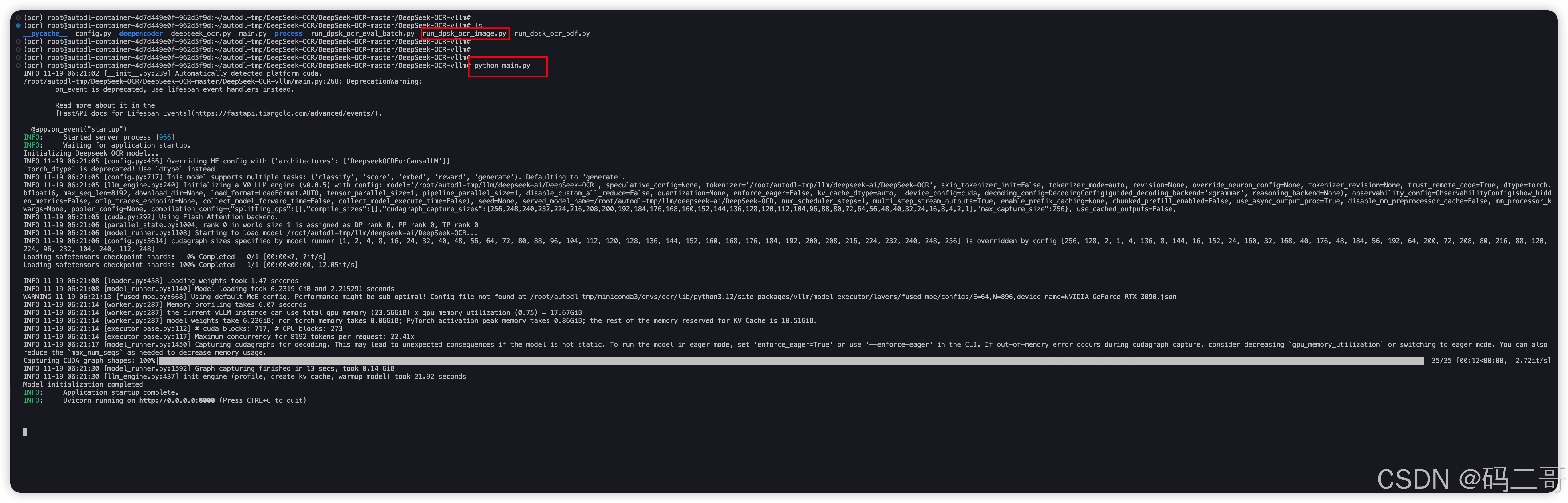
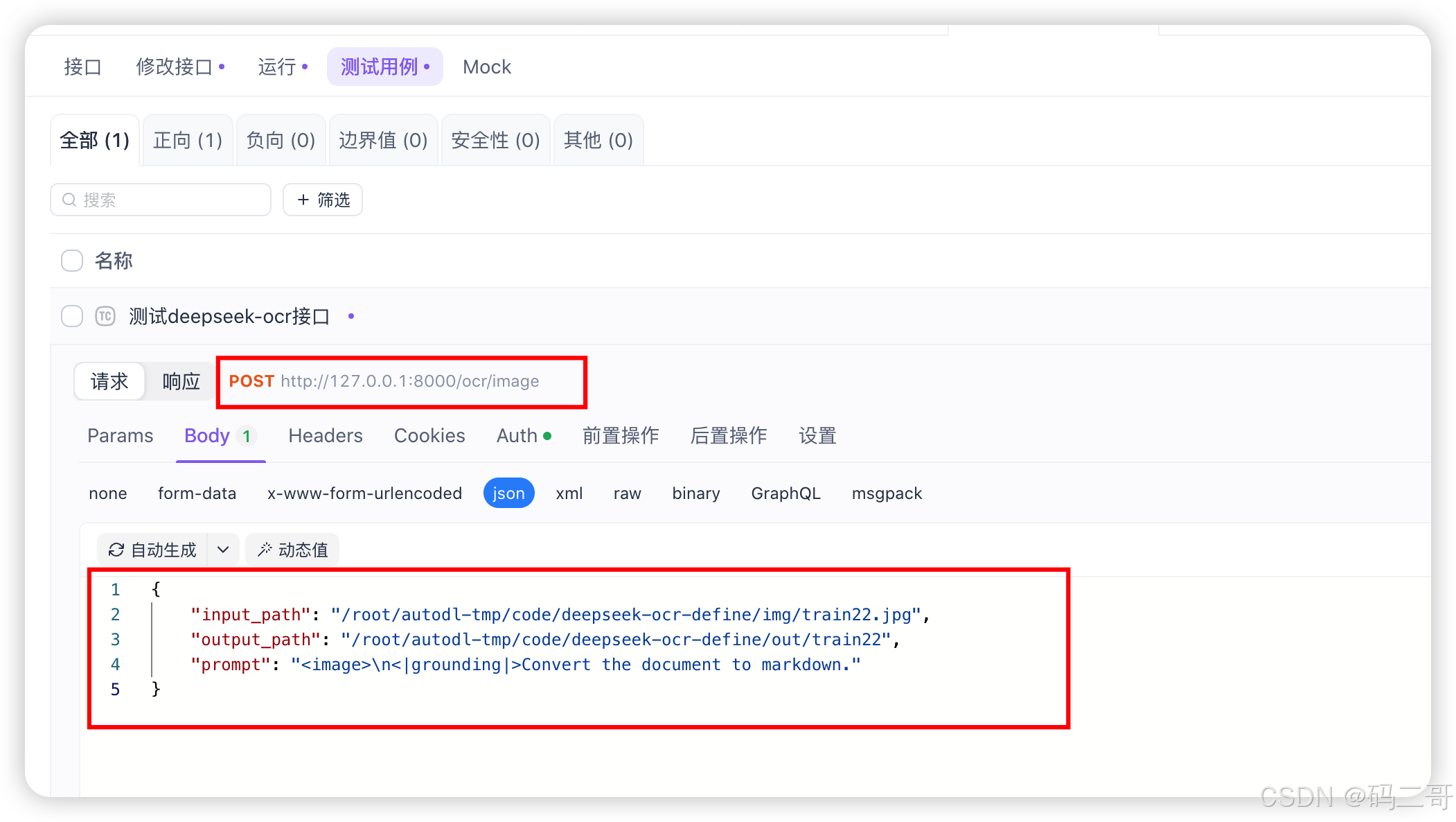
本地测试
上传被识别图片到远程服务器上
直接在本地找一个图片,如下所示

上传到远程服务器的某个目录下,比方说,如下所示:
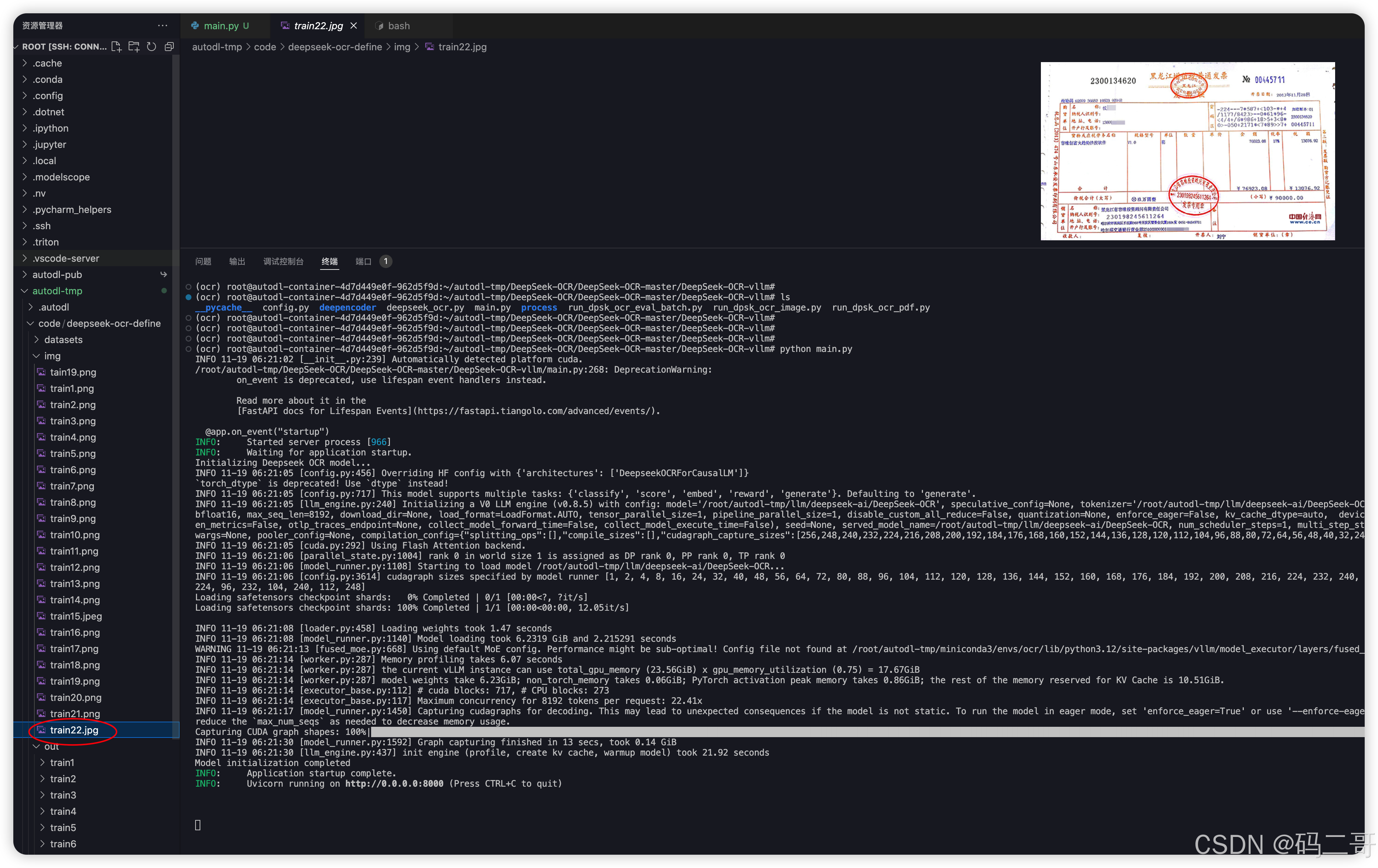
本地通过Apifox测试
input,output是远程服务器上的图片地址,输出地址,非本地的地址

登录到 远程服务器上,查看