原文标题 :InstanceCap: Improving Text-to-Video Generation via Instance-aware Captioning
论文链接:https://arxiv.org/abs/2412.09283v1代码链接 :https://github.com/NJU-PCALab/InstanceCap
发表时间 :2024年12月
作者单位 :南京大学等(论文版本为v1)
精读时间:2025年10月14日
一、引言:文本到视频生成的挑战与新方向
近年来,文本到视频生成(Text-to-Video Generation, T2V)技术取得了显著进展。然而,现有方法在实例级细节建模 方面仍存在明显不足:生成的视频常出现实例混淆、属性错配、动作不连贯甚至幻觉等问题。
为解决这一挑战,本文提出了一种全新的实例感知图像-视频描述框架------InstanceCap 。其核心思想是:通过结构化的、细粒度的实例描述来增强视频生成过程中的语义控制能力,从而显著提升生成视频在实例细节、时空一致性和语义准确性方面的表现。
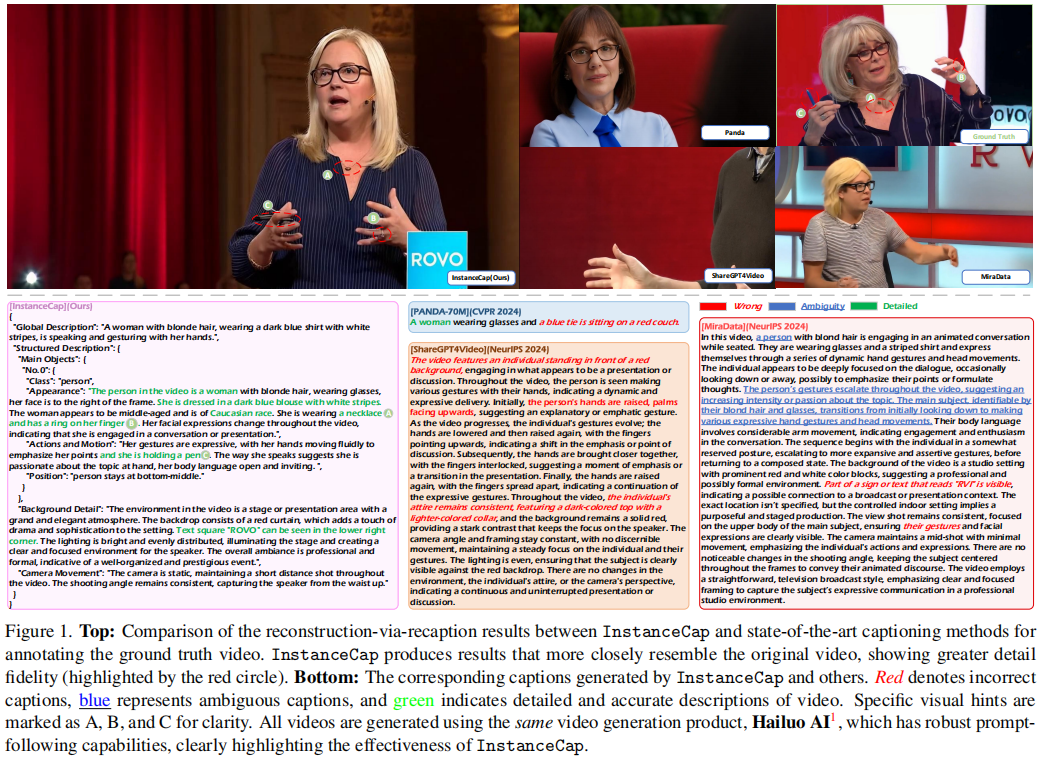
本文将深入解读InstanceCap的技术架构、数据构建、模型设计以及实验验证,并结合论文中的关键图表进行详细分析。
二、核心思想:从"粗描述"到"细结构"的范式转变
传统T2V模型依赖的数据集(如WebVid、Panda-70M)通常使用自动生成或人工标注的简短描述,这些描述往往只包含场景级别的语义信息,缺乏对视频中每个视觉实例的精确刻画。
InstanceCap提出了一种实例感知的结构化描述生成方法,其目标是:
- 识别视频中的主要实例(Main Instance Identification)
- 提取每个实例的细粒度属性(如外观、姿态、动作)
- 建模实例间的交互与空间关系
- 生成结构化、信息丰富的文本描述
这种结构化描述不仅提升了描述的信息密度,也为后续的视频生成模型提供了更强的语义控制信号。
三、方法详解:InstanceCap 框架设计
3.1 整体架构:两阶段增强流程(Figure 2)
清晰地展示了从全局视频信息 到局部实例信息的转换过程,强调了多模型协同与信息融合的重要性。
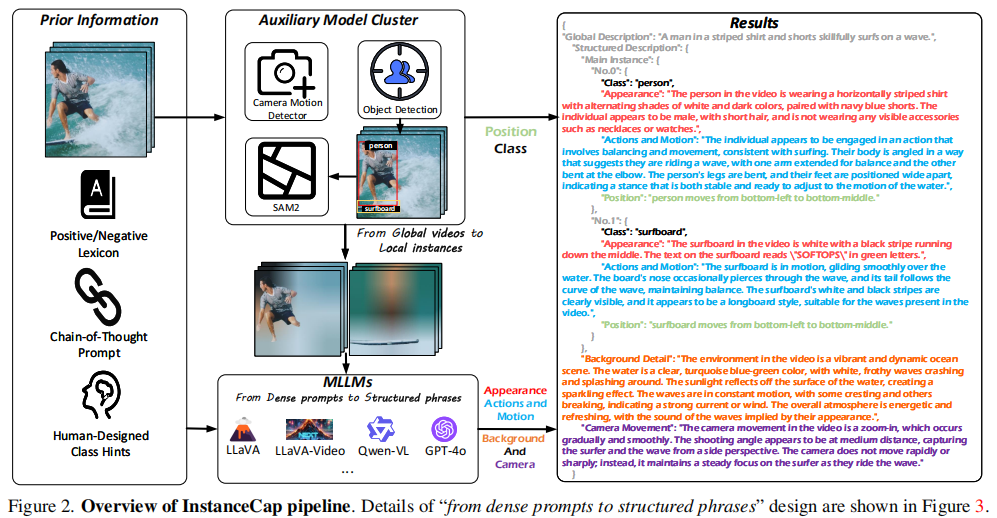
InstanceCap的完整处理流程是一个典型的"感知-推理-生成"架构,该流程包含以下核心组件:
- 输入视频:原始视频帧序列。
- 辅助模型集群 (Auxiliary Model Cluster):
- 目标检测器(Object Detection):识别视频中的主要实例(如人、车、动物)。
- 相机运动检测器(Camera Motion Detector):分析镜头运动(如平移、缩放、旋转)。
- SAM2:用于精确的实例分割,获取实例的像素级掩码。
- MLLMs (多模态大语言模型):
- 接收来自辅助模型的密集提示(Dense Prompts),包括实例的外观、动作、背景和相机运动信息。
- 通过改进的思维链提示(Chain-of-Thought Prompting)策略,将这些信息整合为结构化描述。
- 输出 :结构化短语,包含
Appearance(外观)、Actions and Motion(动作与运动)、Background(背景)和Camera Movement(相机运动)四个维度。
3.2 结构化描述生成:改进的思维链设计(Figure 3)
深入展示了"从密集提示到结构化短语"的内部设计,其核心是改进的思维链(CoT)提示策略。
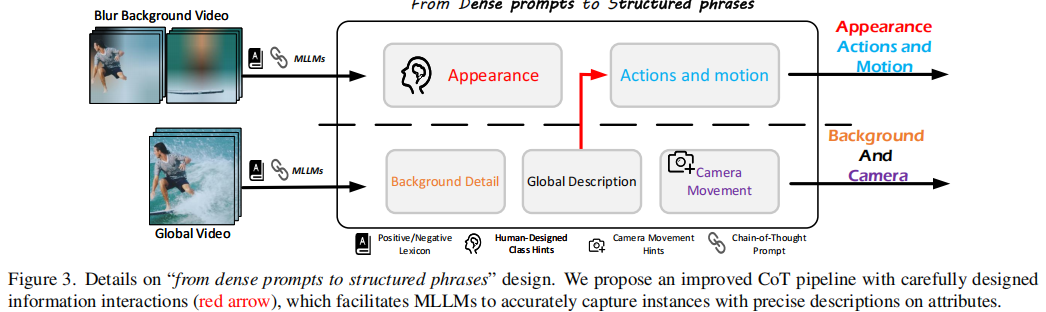
传统CoT提示(如"让我们一步步思考")在捕捉实例细节方面表现不佳。InstanceCap通过以下改进提升性能:
- 细粒度提示设计:例如,"请观察角色是否有配饰"、"请描述人物的服装材质和颜色"。
- 信息交互机制(红色箭头):在不同属性维度(外观、动作、背景、相机)之间建立信息流动,确保描述的一致性。
- 正负词典引导(Positive/Negative Lexicon):使用预构建的词典引导LLM生成更具美感的描述,避免使用负面词汇。
- 人工设计类别提示(Human-Designed Class Hints):针对不同类别(如"人"、"车"、"动物")提供定制化的提示模板。
例如,对于"人"类,提示为:
"Please focus primarily on the person's facial expressions, attire, age, gender, and race in the video and give description in detail. Please mention if there are any necklaces, watches, hat or other decoration; otherwise, there's no need to bring them up."
这种精细化的提示设计显著提升了MLLM对实例属性的捕捉能力。
3.3 实例增强器(InstanceEnhancer)实现(Figure 5)
展示了InstanceEnhancer的具体实现流程,包含两个阶段。
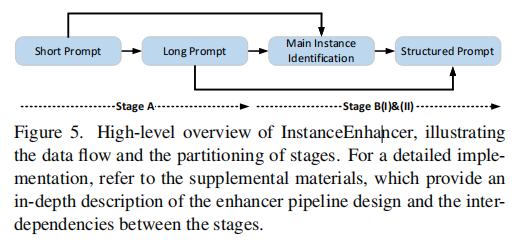
Stage A:短文本扩展
- 输入:原始的粗粒度描述(如"一个人在跑步")。
- 处理:使用LLM(如GPT-4o)扩展为更详细的描述,引入可能的实例属性和场景细节。
- 输出:扩展后的密集提示。
Stage B:实例感知重描述
- Stage B(I):基于辅助模型的输出,构建结构化描述模板。
- Stage B(II):将模板输入MLLM,生成最终的自然语言描述。
- 关键:在整个过程中,实例锚点确保每个描述片段都对应到具体的视觉实例,避免指代模糊。
介绍了如何将一个简单的输入逐步转化为一个丰富、准确、结构化的输出。
四、数据与系统设计
4.1 正负词典构建(Figure S1)
论文构建了正向词典 (Positive Lexicon)和负向词典(Negative Lexicon):
- 正向词典:从开源模型画廊中提取描述性、美学性强的形容词(如"vibrant"、"elegant"、"dynamic")。
- 负向词典:手动构建并用GPT-4o扩展,包含低质量或负面描述词汇(如"blurry"、"distorted"、"ugly")。
- 这些词典用于引导LLM生成更具美感的描述,避免生成低质量内容。
4.2 系统提示设计(Figure S5)
展示了InstanceCap的系统提示(System Prompt),规定了描述生成的严格规范(图比较大,这里就不放了哦,建议到原文中看):
关键要求包括:
- 排除声音相关描述(因无音频信号)。
- 描述需流畅、精确,避免分析和抒情。
- 仅描述可确定的信息,禁止推测。
- 不提及帧号或时间戳。
- 主对象需详细描述,其他对象简要提及。
- 严格遵循结构化输出格式。
这一提示确保了生成描述的客观性、一致性和实用性。
五、实验与评估:量化与用户研究双验证
5.1 字幕生成效果评估
论文采用"通过重描述进行重建"的评估范式。
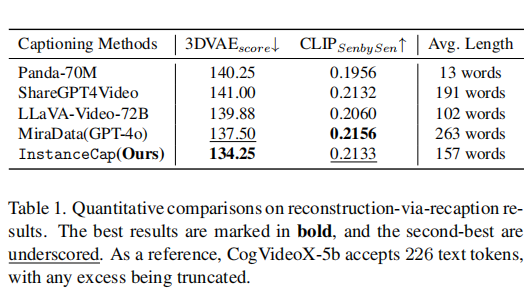
结果分析:
- InstanceCap在指标上优于其他方法或与其他方法相当,表明其提升视频与字幕之间保真度的能力。
- 在200词以下的字幕指标上始终表现优异,这一长度对大多数T2V模型而言是可接受的,充分体现了其泛化能力。
5.2 文本到视频生成效果评估
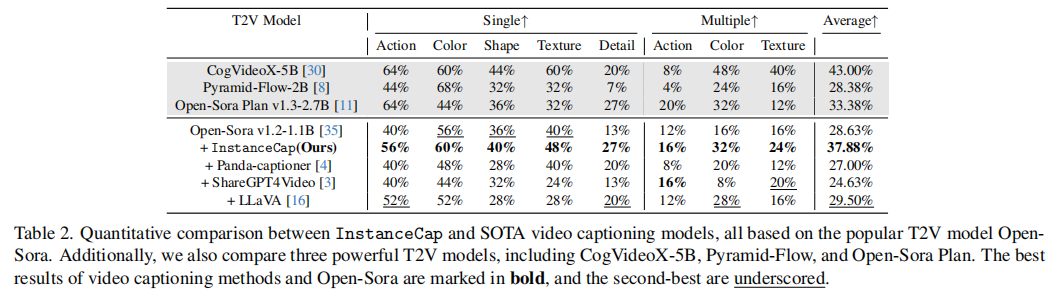
结果分析:
- InstanceCap显著提升了所有指标表现,超越基础模型Open-Sora,充分验证方法有效性。其中细节评分指标拔得头筹,充分证明该模型能精准捕捉视频中的复杂细节特征。
- 基于Open-Sora微调的其他视频描述模型相比,InstanceCap在视频生成任务中展现出明显优势。
- 与CogVideoXor Pyramid-Flow等大型模型相比,文中方法在平均指标上更胜一筹,在"单色/形状/细节"和"多动作"等特定指标上表现与CogVideoX相当,但参数量却大幅减少。
5.3 消融实验


关键发现:
- 移除实例锚点(Instance Anchor)导致幻觉得分显著上升。
- 移除正负词典导致生成描述的美学质量下降。
- 移除人工设计类别提示导致特定类别的描述准确性降低。
- 改进的CoT提示对整体性能提升贡献最大。
六、技术优势与创新点总结
- 实例感知描述生成:首次系统性地将"实例级语义"引入T2V的描述生成环节。
- 增强的语义控制能力:为T2V模型提供了更丰富的控制信号。
- 抑制幻觉的有效机制:实例锚点与结构化描述减少了模型"自由发挥"的空间。
- 高效的信息密度:在较短的描述长度下实现了优于长描述的生成效果。
七、局限性与未来方向
- 计算开销:两阶段处理流程增加了数据预处理成本。
- 实例遮挡与交互建模:在复杂场景中仍具挑战。
- 泛化能力:对罕见物体的泛化能力有待验证。
未来方向:
- 与端到端T2V模型联合训练。
- 探索动态实例关系建模。
- 扩展至3D视频或具身智能场景。
八、结语
InstanceCap代表了文本到视频生成领域的一个重要范式转变:从"场景级描述驱动"迈向"实例级语义控制"。通过引入结构化的实例感知描述,该方法不仅提升了生成视频的质量,也为解决T2V中的幻觉问题提供了新思路。