概述
日常使用ChatGPT,也接触各种OpenAI系列模型,但对于他们的发布日期和功能定位,一直缺乏一个系统性地脉络梳理,本文记录一下。
时间线
以时间线方式从前往后梳理GPT系列模型,也是OpenAI最核心模型,专注于自然语言理解和生成。
- GPT-1:发布于2018年6月,参数量约1.17亿,开创性地将Transformer架构应用于大规模无监督预训练+下游任务微调的范式;
- GPT-2:发布于2019年2月,最大版本约15亿,展示LLM在零样本(zero-shot)学习上的惊人能力;
- GPT-3:发布于2020年6月,参数量约1750亿,真正引爆大模型时代的巨作,展示前所未有的上下文学习(in-context learning)能力;
- GPT-3.5:GPT-3系列重要迭代和优化,是ChatGPT(2022年11月发布)背后的初始模型。成本更低、推理速度更快,专为对话和指令遵循进行微调;包括GPT-3.5 Turbo
- GPT-4:发布于2023年3月,第一个真正意义上的多模态大模型;
- GPT-5:发布于2025年8月,系列最强模型。
多模态
ASR
OpenAI最经典的语音识别ASR模型,莫过于开源的Whisper,发布于2022年9月,能够将多种语言的语音转录为文本,并支持语音翻译,在噪声、口音等复杂环境下表现出色。
此外还有Transcribe(转录)两个模型
- GPT-4o Transcribe:使用GPT-4o转录音频,与原始Whisper模型相比,降低单词错误率,并提高语言识别率和准确率,可获得更准确的转录;
- GPT-4o mini Transcribe:使用GPT-4o mini转录音频。
TTS
OpenAI API可使用的TTS模型包括3个:
- TTS-1:1M Tokens要15刀;
- TTS-1 HD:TTS-1的高质量版本,1M Tokens要30刀;
- GPT-4o mini TTS:1M Tokens仅0.6刀;
Audio
同时具备ASR(语音转文本)和TTS(文本转语音)能力的模型,输入和输出都支持文本和音频,都支持函数调用(Function Calling,简称FC,调用外部API来执行操作)
系列包括:
- GPT-4o Audio:官网能看到该模型是预览版(preview),支持流式(Streaming)输出;
- GPT-4o Mini Audio:预览版+经济版,支持流式(Streaming)输出;
- GPT-Audio:是GPT-4o Audio的正式版;
- GPT-Audio-Mini:正式版+经济版。
Realtime
同时具备ASR和TTS能力的模型,输入和输出都支持文本和音频,正式版模型输入还支持图片,都支持FC。
系列包括:
- GPT-4o Realtime:预览版,也就是模型名称是
gpt-4o-realtime-preview; - GPT-4o mini Realtime:预览版+经济版本,模型名称为
gpt-4o-mini-realtime-preview; - GPT-Realtime:正式版,第一个通用实时模型,能够通过WebRTC、WebSocket或SIP连接实时响应音频和文本输入;
- GPT-Realtime-Mini:GPT-Realtime的经济高效版。
模型对比
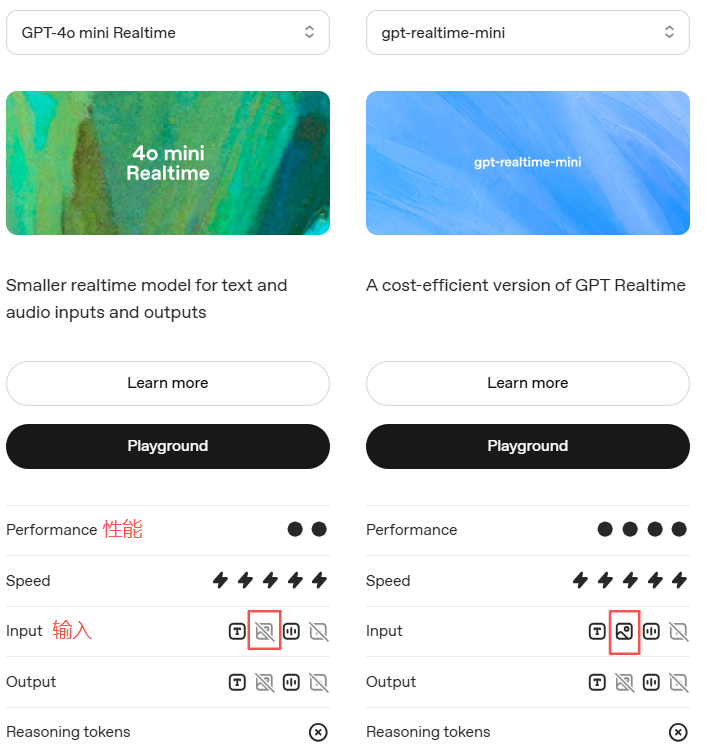
以及
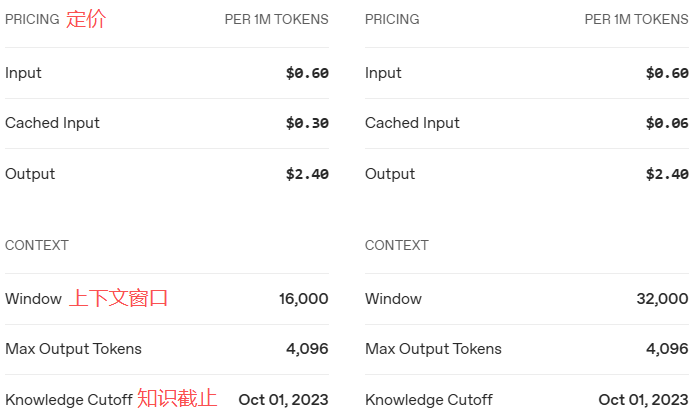
可知正式版更便宜,性能更强,上下文窗口更大,还支持图片输入。
DALL·E
文生图模型,先后发布过3个版本:
- DALL·E:发布于2021年1月,首个能根据文本描述生成高质量、多样化图像的模型,与CLIP同时发布;
- DALL·E 2:发布于2022年4月,在DALL·E基础上,利用CLIP的文本编码器,实现了更高分辨率、更逼真、更可控的图像生成;
- DALL·E 3:发布于2023年9月,深度集成到ChatGPT中,能更好地理解复杂、详细的提示词,并根据用户的反馈进行迭代修改。
除DALL·E系列外,还有GPT Image 1也是文生图模型,包括2个模型:
- GPT-Image-1:价格和DALL·E有所不同
- GPT-Image-1-Mini:经济版
Sora
发布于2024年2月15日的文生视频模型Sora,不再对外以API方式提供服务。
Sora 2发布于2025年9月30日,输入支持文本、图片,输出为音频和视频,包括
- Sora 2:输出肖像分辨率为
720x1280,风景为1280x720,每秒0.1刀; - Sora 2 Pro:输出肖像为
720x1280,风景为1280x720,每秒0.3刀;输出肖像为1024x1792,风景为1792x1024,每秒0.5刀。
注:
- Portrait:竖屏,画面比例为9:16,手机竖屏视频的标准格式,非常适合在
Instagram Reels、YouTube Shorts等短视频平台上播放。手机正常自拍或拍摄人像时,就是这种模式; - Landscape:横屏,画面比例为16:9,传统电视、电脑显示器和YouTube长视频的标准高清(HD)格式。手机横过来拍视频,或用相机、摄像机拍摄时,通常就是这种模式。
Search
用于实现深度搜索和深度研究(DeepResearch(上)),输入和输出都只支持文本,支持流式输出和结构化输出。
系列包括:
- GPT-4o Search:预览版,支持流式输出和结构化输出;
- GPT-4o mini Search:预览版+轻量级版,支持流式输出和结构化输出;
- o3-deep-research:非预览版,输入支持图片,支持流式输出;
- o4-mini-deep-research:非预览版,输入支持图片,支持流式输出;
o系列
包括:
- o1-preview:推理模型,经过强化学习训练,可执行复杂的推理。在回答之前会先思考,在回应用户之前会产生一个很长的内部思维链。预览版,支持流式输出、结构化输出、FC,不再以API方式提供服务;
- o1:正式版,支持图片输入、流式输出、结构化输出、FC;
- o1-mini:正式版+经济版,支持流式输出,不再以API方式提供服务;
- o3:功能全面且强大的跨领域模型。提供卓越的STEM(Science、Technology、Engineering、Mathematics)功能,尤其擅长科学、数学和编码;为数学、科学、编程和视觉推理任务树立新的标准,在技术写作和指令执行方面也表现出色。可用于文本、代码和图像分析的多步骤问题。支持图片输入、流式输出、结构化输出、FC;继任者为GPT-5;
- o3-mini:支持函数调用、结构化输出、流式输出;三种推理努力选项(低、中、高);
- o3-Pro:支持图片输入、结构化输出、FC;使用更多计算资源进行更深入的思考,并持续提供更优质的答案。旨在解决棘手问题,部分请求可能需要几分钟才能完成。为避免超时,请尝试使用后台模式;
- o4-mini:推理模型,支持图片输入、流式输出、结构化输出、FC、微调;继任者为GPT-5 Mini;
GPT-4
系列包括:
- GPT-4 Turbo:预览版,支持微调;
- GPT-4:支持流式输出、微调;
- ChatGPT-4o:在ChatGPT聊天Web端使用的模型,支持图片输入、流式输出、预测输出;
- GPT-4o:o代表
omni,是大多数任务的最佳模型,也是除o系列模型之外功能最强大的模型。支持图片输入、流式输出、预测输出、结构化输出、FC、微调、蒸馏; - GPT-4o mini:适用于专注型任务,非常适合进行微调,支持图片输入、流式输出、预测输出、结构化输出、FC、微调;
- GPT-4.1:擅长指令跟踪和工具调用,拥有跨领域的广泛知识。拥有1M Token上下文窗口,无需推理步骤,延迟低。支持图片输入、流式输出、结构化输出、FC、微调、蒸馏。支持的工具:联网搜索、文件搜索、图片生成、代码解释、MCP;继任者是GPT-5;
- GPT-4.1 Mini:GPT-4.1的更小、更快版本;支持图片输入、流式输出、结构化输出、FC、微调、预测输出;继任者是GPT-5 Mini;
- GPT-4.1 Nano:相比于GPT-4.1和GPT-4.1 Mini,速度最快(推理能力最弱)、成本最省;擅长指令跟踪和工具调用,具有1M Token上下文窗口,无需推理步骤即可实现低延迟。支持图片输入、流式输出、结构化输出、FC、微调、预测输出。推荐使用GPT-5 Nano。
GPT-OSS
- GPT-OSS-20B:总参数为210亿,但启动参数仅为36亿。
- GPT-OSS-120B:1170亿总参数,但每个Token仅启动51亿参数;
稀疏启动设计使得模型可保持强大效能,大幅降低运行成本。在注意力机制方面,两个模型都采用交替的密集和局部带状稀疏注意力模式,结合分组多查询注意力(分组大小为8),有效提升推论和存储器效率。原生支援128k上下文长度,并使用旋转位置嵌入(RoPE)进行位置编码,展现在长文本处理方面的优势。
在训练过程中未对模型的CoT进行任何直接监督,为监测模型的不当行为、欺骗和滥用提供可能。
在安全性方面,采用「最坏情况微调」评估方法,通过在专门的生物学和网络安全资料上对模型进行恶意微调,模拟攻击者可能采用的手段,研究团队发现即使经过广泛的恶意微调,这些模型仍无法达到其「防范准备框架」所定义的高能力水平。这一发现为开源模型的安全性提供重要的实证支撑。
特点:
- 上下文长度皆为128k;
- 可调节的推理强度:根据具体场景和延迟要求,灵活设置推理模式(低、中、高),实现性能与响应速度的平衡;
- 完整的思维链输出:可访问模型完整的推理过程,有助于调试和提升对结果的信任(但并非面向终端用户展示);
- 支持微调:可通过参数微调将模型深度定制为适配自身任务的专用版本;
- 原生智能体能力:模型原生支持函数调用、网页浏览、Python代码执行以及结构化输出,具备智能体能力;
- 原生MXFP4量化训练:MoE层采用MXFP4精度训练,GPT-OSS-120B可在单张H100上运行,GPT-OSS-20B可在16GB显存内运行,硬件友好,推理高效。
评测
GPT-OSS-120B在多个任务上超越o3-mini,并在竞赛编程(Codeforces)、通用问题解决(MMLU与HLE)、工具调用(TauBench)方面表现出色,与o4-mini持平甚至略有超越。在健康问答(HealthBench)和竞赛数学(AIME 2024与2025)任务中,GPT-OSS-120B的表现甚至优于o4-mini。
GPT-OSS-20B也在上述评测中达到或超过o3-mini的水平,在竞赛数学和健康任务上甚至实现反超。
GPT-5
系列模型:
- GPT-5:当前最强模型,支持图片输入、流式输出、结构化输出、FC、蒸馏;支持工具:联网搜索、文件搜索、图片生成、代码解释、MCP;
- GPT-5 Mini:速度略快(推理能力略弱)、成本略节省;
- GPT-5 Nano:速度最快(推理能力最弱)、成本最省;
- GPT-5 Pro:同o3-Pro(对于比o3)类似;
- GPT-5-Codex:针对Codex(OpenAI推出的AI CLI工具)或类似环境中的代理编码任务进行优化,仅在Responses API中可用,底层模型快照将定期更新;
- GPT-5 Chat:ChatGPT聊天应用后台使用的模型。
注:除GPT-5-Codex外,还有个Codex-Mini-Latest,是o4-mini微调版本,也用于Codex CLl,价格不一样。
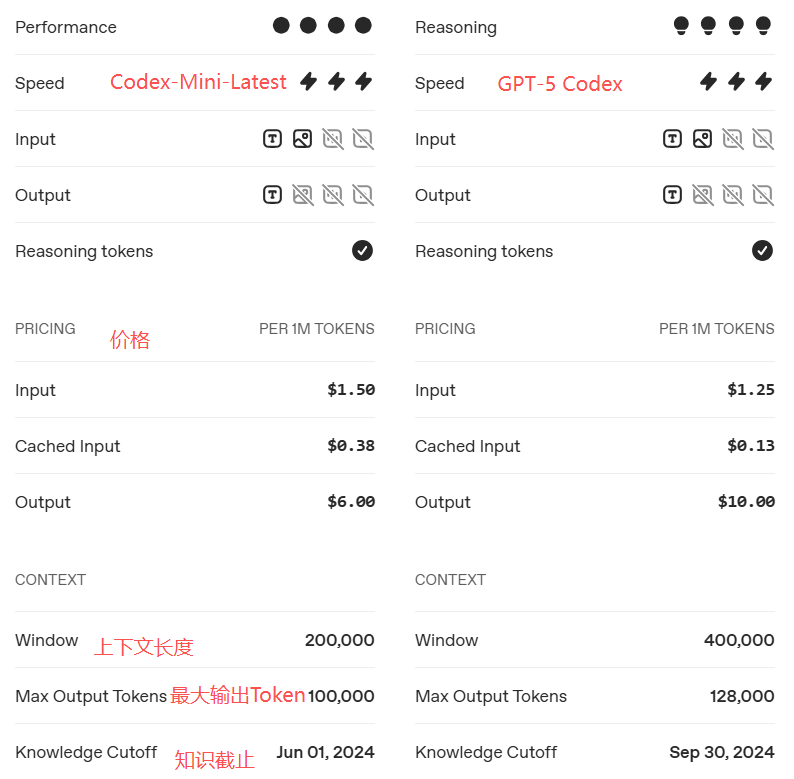
引入Router,可以自动调用,实时判断请求难度、所需工具、延迟预算,自动在GPT-5(快)和GPT-5 thinking(深思)之间切换;额度用完还能降级到mini版。用户不用再手动选模型,像操作系统的线程调度器,把"算力/思考时间"当资源自动分配。
注重强任务分工,Instruction following & agentic tool use模块大幅升级,模型能把复杂请求拆成多步、跨多个外部工具(浏览器、代码沙箱、数据库等)协同完成。
安全机制成为平台内置的能力,而不只是模型被训练出的习惯。比如问一个危险的问题,之前GPT是拒绝回答,现在是部分回答你,解释原因并给出替代方案。
三方榜单
评测
- HealthBench:OpenAI 2025年新建的真实病例基准;
- HealthBench Hard:一个子集
- GPQA Pro:高阶科学
- Humanity's Last Exam (Full Set):跨学科难题的终极闭卷基准
- LongFact & FActScore:开放事实检索基准;GPT-5 thinking 幻觉率约为o3的六分之一。
- Sycophancy Eval:奉承/过度认同率从14.5%→<6%,聊天风格更客观。
- Deception Stress-Test:误导性/虚假完成率4.8%→2.1%,更诚实可靠。
- Economically-Important Tasks(OpenAI内部):覆盖40+职业,约50%任务与专家持平或更好,显著领先o3与ChatGPT Agent。
- SWE-bench Verified:软件工程领域,Bug修复
- MMMU:多模态领域;大学级别的视觉逻辑题,相当于让模型看图说理;
- AIME:美国奥数入门级竞赛题,专门考长链条数学推理能力
- CharXiv:多模态基准
- Aider Polyglot:多语言代码编辑任务。
新增4个官方人格Personas(Cynic毒舌、Robot机器人、Listener倾听者、Nerd)
embedding
OpenAI Embedding模型演进史
- text-embedding-ada-002:发布于2022年12月。一个里程碑式的模型,用单一模型取代此前五个独立专用嵌入模型(如
text-similarity-ada-001等),极大简化开发者选择;性能强大、价格低廉;迅速成为行业事实上的标准。 - text-embedding-3:最新模型,在性能、多语言支持和灵活性上实现巨大飞跃,包括text-embedding-3-small和text-embedding-3-large。引入核心功能:可调节的输出维度。用户可通过API参数
dimensions将向量长度动态缩减(如large模型可缩减至256维,small模型可缩减至512维),在几乎不损失性能的前提下,大幅节省存储和计算开销。
API
网络上随处可见的OpenAI Python库的使用,略过。
参数Verbosity:可控制模型响应输出的长度,分为low、medium、high。
py
response = client.responses.create(
model="gpt-5-mini",
input=question,
text={"verbosity": verbosity}
)Free-Form:函数调用,GPT-4中传递给各种工具是JSON数据,现在可以传递原始文本,如Python代码、SQL查询、Shell命令等。
py
response = client.responses.create(
model="gpt-5-mini",
input="Please use the code_exec tool to calculate the cube of the number of vowels in the word 'pineapple'",
text={"format": {"type": "text"}},
tools=[{
"type": "custom",
"name": "code_exec",
"description": "Executes arbitrary python code",
}]
)输出为可执行的Python代码。
Context-Free Grammar:CFG,通过CFG可确保模型输出符合编程语言、数据格式、其他结构化文本的语法规则,比如确保输出的Python代码没有语法错误等。
py
email_regex = r"^[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}$"
prompt = "Give me a valid email address for John Doe. It can be a dummy email"
response = client.responses.create(
model="gpt-5", # grammar-constrained model
input=prompt,
text={"format": {"type": "text"}},
tools=[{
"type": "custom",
"name": "email_grammar",
"description": "Outputs a valid email address.",
"format": {
"type": "grammar",
"syntax": "regex",
"definition": email_regex
}
}],
parallel_tool_calls=False
)
print("GPT-5 Output:", response.output[1].input)最小化推理:最小化推理模式可减少API调用成本,加快响应速度,比如数据提取、格式化等任务。
py
response = client.responses.create(
reasoning={
"effort": "minimal"
}
)