目录

写在前面
Vgent专门用于解决解决长视频理解的难题。简单来说,就是让AI能够更好地看懂和理解几十分钟甚至几小时的视频内容。下面我用通俗易懂的方式给你讲讲它最核心的亮点。
**论文地址:**https://arxiv.org/abs/2510.14032
**github链接:**https://github.com/xiaoqian-shen/Vgent
一、最大的优点:
Vgent最大的优点就是用"关系图"代替"碎片化"处理,真正理解视频内容。
传统方法把长视频切成片段后,每个片段都是孤立的,导致AI无法理解片段之间的关联。Vgent最大的突破是创建了一个视频关系图:把每个视频片段变成图里的节点,通过重复出现的人物、物体或场景把这些节点连接起来。
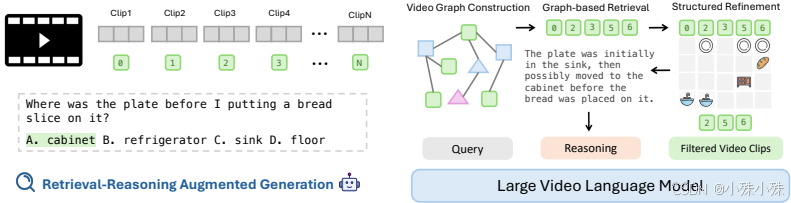
比如一个做饭视频中,"平底锅"可能在不同时间段出现,这个图就会把所有包含平底锅的片段自动关联起来。这样AI就能像人一样,追踪一个物体或人物在视频中的完整轨迹。
二、颠覆性用法
1.先"审问"再回答,过滤无用信息
普通AI是检索到相关信息后直接生成答案,但Vgent增加了一个独特的"审问"环节。它会先对检索到的每个视频片段提出具体问题来验证相关性。
比如问"这个片段里平底锅是干净的吗?""有人在使用平底锅吗?"只有通过验证的片段才会被用来生成最终答案。这个方法消除了无关信息的干扰,在实验中解决了40%的失败情况------就是那种"正确答案就在眼前,但AI就是答错"的问题。
2.一次建图,多次使用,效率倍增
Vgent的图结构是预先构建好的,与具体问题无关。一旦建好图,对同一个视频的不同问题都可以直接使用,不需要重新处理视频。
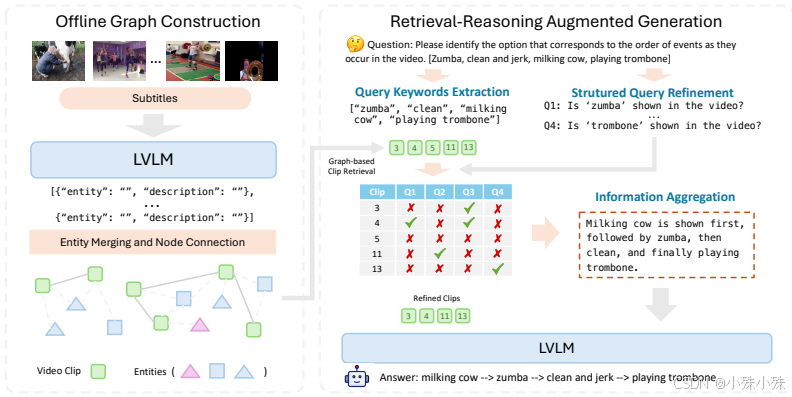
比如一个1小时的教学视频,建好图后,问"老师什么时候写了板书"和"学生什么时候提问"都可以快速找到相关片段,而不需要重新分析整个视频。这使它在处理多问题时比传统方法快1.73倍。
三、实际效果:小模型实现大突破
最厉害的是,Vgent能让小模型达到甚至超过大模型的效果。比如3B参数的模型加持Vgent后,准确率达到70.4%,反而超过了7B的大模型。在需要跨片段推理的任务上(如计数事件数量、排序事件顺序),提升尤其明显,最高达到5.4%的性能提升。
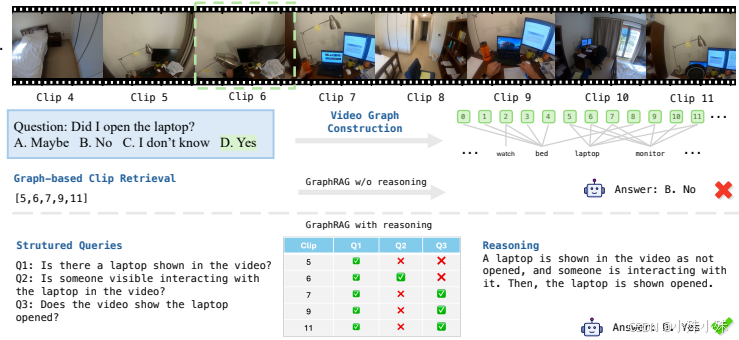
这个例子中,AI原本被多个打开笔记本电脑的片段干扰,错误地回答"没有打开电脑"。但经过结构化审问后,它成功识别出关键的开机动作,给出了正确答案。
Vgent通过创新的图结构+审问机制,让AI真正具备了理解长视频的能力,这在视频内容爆炸的今天具有非常重要的应用价值。
关注不迷路(*^▽^*),暴富入口==》 https://bbs.csdn.net/topics/619691583