1. 论文摘要介绍表格
| 维度 | 内容 |
|---|---|
| 论文标题 | NaVid: Video-based VLM Plans the Next Step for Vision-and-Language Navigation (NaVid:基于视频的VLM规划视觉语言导航的下一步) |
| 核心问题 | 视觉语言导航(VLN)在连续环境中的泛化难题,特别是从仿真到现实(Sim-to-Real)的迁移,以及对地图、里程计和深度数据的依赖。 |
| 主要创新点 | 1. 纯视频输入 :首个仅依赖单目 RGB 视频流和语言指令实现 SOTA 性能的 VLN 方法,无需地图、里程计或深度信息。 2. 端到端 VLM :直接输出带有具体参数(距离、角度)的低级可执行动作,而非抽象的路点。 3. 视频历史编码 :利用指令查询 Token 和指令无关 Token 机制,有效将历史轨迹编码为视频上下文。 4. 混合训练策略:结合 Oracle 数据、Dagger 采样数据和指令推理辅助任务进行联合训练。 |
| 关键成果 | 1. 仿真性能 :在 VLN-CE R2R 数据集上达到 SOTA 水平;在 R2R-RxR 跨数据集评估中表现优异。 2. 现实迁移 :在真实世界 Turtlebot4 机器人实验中,实现了约 66% 的成功率,远超传统基线模型。 3. 鲁棒性:消除了里程计噪声和深度传感器域差异带来的影响。 |
| 应用场景 | 家庭服务机器人、室内导航助手、无地图环境下的自主移动机器人。 |
2. 论文具体实现流程
输入 (Input)
- 视觉输入 :机器人单目 RGB 相机捕获的视频流。
- 历史帧序列: { x 0 , ... , x t − 1 } \{x_0, \dots, x_{t-1}\} {x0,...,xt−1}
- 当前帧: x t x_t xt
- 文本输入 :自然语言导航指令 I I I(例如:"向前走到墙边,然后左转...")。
核心处理流程 (Process Logic)
- 视觉编码 (Vision Encoding) :
- 使用 EVA-CLIP 视觉编码器提取每一帧的特征。
- Token 生成 (Tokenization) :
- 指令查询 Token (Instruction-queried Tokens) :使用 Q-Former,结合指令文本 I I I,从图像特征中提取与指令相关的特征。
- 指令无关 Token (Instruction-agnostic Tokens) :使用网格池化 (Grid Pooling) 保留图像的空间几何信息(这对导航至关重要)。
- 策略:为了效率,当前帧保留较多 Token (64个),历史帧保留较少 Token (4个)。
- 序列构建 :
- 使用特殊标记符将信息拼接:
<HIS>历史Token</HIS>+<OBS>当前Token</OBS>+<NAV>指令文本Token。
- 使用特殊标记符将信息拼接:
- 大模型推理 (LLM Reasoning) :
- 输入给 Vicuna-7B (基于 LLaMA 的大语言模型)。
- 模型结合视觉历史、当前视野和文本指令,进行逻辑推理。
- 输出解码 :
- LLM 输出自然语言形式的动作描述(例如 "Move forward 75 cm")。
- 使用正则表达式解析出动作类型(前进/左转/右转/停止)和参数(距离/角度)。
数据流程 (Data Flow & Training)
- 数据来源 :
- Web 数据:76.3万视频-文本对(用于 LLaMA-VID 预训练)。
- VLN 数据:R2R 数据集(32万 Oracle 样本)。
- 增强数据 (Dagger) :
- 将模型放入环境运行,收集非完美(非 Oracle)的轨迹数据(18万样本),让模型学习如何从错误中恢复(修正)。
- 辅助任务 :
- 指令推理:输入视频轨迹,让模型反向预测对应的指令(增强环境理解能力)。
- 流转逻辑 :
- 观测 → \rightarrow → 编码 → \rightarrow → LLM → \rightarrow → 动作 → \rightarrow → 执行 → \rightarrow → 新观测 → \rightarrow → 循环。
3. 有趣的白话版详细解说
嘿,朋友!来听听这个叫 "NaVid" 的机器人大脑是怎么回事。
想象一下,把你蒙上眼睛带到一个陌生的大楼里,摘下眼罩,给你一张纸条写着:"往前走,看到白色垃圾桶左转,进那个门。"
以前的机器人是怎么做的?
以前的机器人(咱们叫它"老古董")特别死板。它们手里必须得拿着精确的地图,脚底下得装着精准的计步器(里程计),还得用激光雷达不断扫描墙壁距离。如果它的计步器稍微有点误差,或者地图跟现实稍微对不上,它就彻底懵圈了,像个无头苍蝇一样乱撞。而且,如果你在电脑模拟器里训练好"老古董",把它放到真实世界里,它往往会因为真实世界的光线、地毯摩擦力跟模拟器不一样,直接"罢工"。
NaVid 是怎么做的?
NaVid 就像是一个模仿人类的高手。它不需要地图,不需要计步器,也不用激光雷达。它就靠一只眼睛(普通的 RGB 摄像头)和一个超级大脑(大语言模型)。
- 看视频:它把你给它的指令记在心里,然后像看电影一样,一边走一边看摄像头拍到的画面。
- 记性好:它不仅看现在的画面,还记得刚才走过了什么(历史视频)。比如它记得"哦,我刚路过那个沙发了"。
- 人话指挥:它的思考方式不是冷冰冰的代码,而是像人一样自言自语:"嗯,我现在看到墙了,根据指令我该左转了,大概转个90度吧,然后再往前走两步。"
它是怎么练成的?
科学家们不仅喂给它标准的"正确答案"(专家走的路线),还故意让它在模拟器里乱跑,然后教它怎么走回正道(这招叫 Dagger)。还让它做"反向推理"题:给它看一段走路的视频,让它猜这原本是想去哪。这样练下来,它就成了个老司机。
为什么它很牛?
因为它解决了机器人领域一个超级头疼的问题:"模拟器里猛如虎,现实世界二百五"。NaVid 在现实世界里表现特别好,因为它不依赖那些容易出错的传感器数据,就靠眼睛看,跟人一样,适应性极强。
个人观点与理解:
这就好比自动驾驶从"高精地图派"转向了"纯视觉派"(像特斯拉 FSD)。NaVid 的出现证明了,只要大模型(LLM)足够聪明,视觉理解能力足够强,机器人完全可以抛弃昂贵且脆弱的依赖(如激光雷达、预建地图),仅凭便宜的摄像头就能干复杂的活。
不过 ,这玩意儿也有个缺点:脑子转得有点慢。因为它每走一步都要用大模型思考一下,处理视频和文本,大概需要 1.5 秒才能憋出一个动作。要在现实里跑得飞快,还得把这个"大脑"再优化优化。但无论如何,这绝对是未来家用机器人(比如能听懂人话去拿可乐的机器人)该有的样子!
4. 论文完整中文翻译
摘要
视觉语言导航(VLN)是具身智能(Embodied AI)的一个关键研究问题,旨在使智能体能够根据语言指令在未见过的环境中导航。在该领域,泛化能力是一个长期的挑战,无论是对分布外场景的泛化,还是从仿真到现实(Sim-to-Real)的泛化。在本文中,我们提出了 NaVid,一种基于视频的大型视觉语言模型(VLM),以缩小这种泛化差距。NaVid 首次尝试展示了 VLM 在不依赖任何地图、里程计或深度输入的情况下,达到最先进(SOTA)导航性能的能力。遵循人类指令,NaVid 仅需要机器人上配备的单目 RGB 相机的实时视频流来输出下一步动作。我们的公式模仿了人类的导航方式,自然地摆脱了由里程计噪声引起的问题,以及由地图或深度输入带来的 Sim2Real 差距。此外,我们基于视频的方法可以有效地将机器人的历史观测编码为时空上下文,用于决策和指令跟随。我们使用从连续环境中收集的 51 万个导航样本(包括动作规划和指令推理样本)以及 76.3 万个大规模网络数据来训练 NaVid。大量实验表明,NaVid 在仿真环境和现实世界中均达到了最先进的性能,展示了卓越的跨数据集和 Sim2Real 迁移能力。因此,我们相信我们提出的 VLM 方法不仅为导航智能体,也为这一研究领域规划了下一步。
I. 引言
作为具身智能的一项基本任务,视觉语言导航(VLN)32, 70 要求智能体根据自由形式的语言指令,在多样化且尤其是未见过的环境中导航。VLN 要求机器人理解复杂多样的视觉观测,同时解释细粒度的指令 13, 99,例如"上楼梯并在门口停下",因此这仍是一项具有挑战性的任务。为了解决这一挑战,该领域的大量研究 85, 18, 104, 98, 69, 48, 4 都在简化设置下启动,即在离散环境中的决策(例如 MP3D 模拟器 12 中的 R2R 46)。具体来说,真实环境被抽象为连接图(connectivity graphs),导航被转化为在这些图上的路点集合上的瞬间移动(teleportation)。尽管这些方法发展迅速并取得了令人印象深刻的结果 85, 121, 63, 104,但离散化的环境设置引入了额外的挑战,例如需要地标图 45, 47 和用于在地标之间导航的局部模型 84, 87, 83。

为了实现更现实和直接的建模,连续环境中的导航(例如 R2R-CE, RxR-CE)引起了越来越多的关注。相当多优秀的研究致力于减少 Sim-to-Real 的差距 47, 37, 108, 9。然而,由于数据稀缺以及其模型输入(包括 RGBD、里程计数据或地图)中的领域差距,它们在泛化方面仍面临严峻挑战。泛化问题是大规模现实世界部署中一个关键但尚未被充分探索的挑战,包括从见过场景到新环境的过渡,以及从仿真到现实世界(Sim-to-Real)的过渡。近期大型视觉语言模型(VLMs)的繁荣在许多研究领域展示了前所未有的前景 109, 52, 3。在本文中,我们探索大模型是否能在推动可泛化的 VLN 方面发挥同样的作用。
大模型在广泛的范围内展示了令人印象深刻的泛化能力,涵盖 AIGC 79, 10, 117、通用聊天机器人 2、自动驾驶 28 等。它们也一直在塑造具身智能的未来。RT-2 11 展示了将网络知识从 VLM 转移到可泛化机器人操作的希望。大型语言模型(LLMs)已作为离散环境中 VLN 的规划器发挥了有效作用 63, 69, 121, 14, 74。VLMs 的最新进展正在将 VLN 研究带入一个激动人心的时刻。现在是时候研究 VLMs 是否能提升 VLN 在连续现实世界环境中的泛化能力了。
在本文中,我们首次尝试利用基础 VLMs 的力量将 VLN 泛化到现实世界,并提出了一种基于视频的 VLM 导航智能体,称为 NaVid。它仅依赖机器人单目相机捕获的视频和人类发出的指令作为输入,以端到端的方式规划下一步动作。我们将提出的 NaVid 与三类模型进行了比较:
- 与 AGI 模型 109 或所谓的导航通才 120 相比:这些模型只能执行粗略的导航规划,而 NaVid 是一个实用的视觉-语言-动作(VLA)模型,可以推断出带有定量参数(如移动距离和旋转角度)的可执行动作。这使得 NaVid 能够部署在现实世界中。
- 与使用 LLM 作为规划器的 VLN 模型相比:NaVid 采用了更现实的 VLN 建模。特别是,NaVid 直接推导连续环境中的低级可执行动作,并以视频形式编码视觉观测,这与以前在离散空间建模 VLN 或使用文本描述编码历史观测的基于 LLM 的方法不同 69, 121, 63, 14。
- 与现有的专用 VLN 模型不同:NaVid 消除了动作规划对里程计数据、深度和地图的依赖,从而避免了由里程计噪声或深度感知/导航地图中的领域差异引起的泛化挑战,使 NaVid 易于部署。
据我们所知,提出的 NaVid 是第一个用于连续环境 VLN 的基于视频的 VLM,实现了类似于人类导航行为的仅基于 RGB 的导航。
我们提出的 NaVid 采用预训练的视觉编码器来编码视觉观测,并采用预训练的 LLM 来推理导航动作。通过这种方式,大规模预训练中获得的通用知识被转移到 VLN 任务中,促进了学习并提升了泛化能力。从先进的基于视频的 VLM LLaMA-VID 57 中汲取灵感,我们在机器人视觉观测中用两种类型的 token(令牌)表示每一帧。第一种由指令查询 token 组成,提取与给定指令具体相关的视觉特征。另一种包含指令无关 token,全局编码细粒度的视觉信息,其中 token 数量决定了编码特征的粒度。历史观测的 token 数量允许与当前观测不同。因此,在 NaVid 中,机器人历史轨迹被编码为视频形式的视觉 token,这比以前在离散空间 18, 19 或使用文本描述 69, 121, 63, 14 进行编码的基于 LLM 的 VLN 模型提供了更丰富和适应性更强的上下文。这种基于视频的建模对模型输入施加了严格的约束,因为它不涉及其他信息(例如深度、里程计数据或地图),除了单目视频。如果利用得当,它有助于减轻由里程计噪声以及先前 VLN 工作中深度感知或导航地图中的领域差异引起的泛化挑战。
我们在仿真和现实世界环境中对提出的 NaVid 进行了广泛的实验评估。具体而言,NaVid 在 VLN-CE R2R 数据集上达到了 SOTA 级性能,并在跨数据集评估(R2R-RxR)中展示了显著改进。此外,我们的方法在 Sim-to-Real 部署中表现出令人印象深刻的鲁棒性,在四个不同的室内场景中,仅利用 RGB 视频作为输入,在 200 条指令上实现了约 66% 的成功率。
II. 相关工作
视觉语言导航 (VLN)。 学习跟随人类指令在未访问环境中导航的大量工作建立在离散化的仿真场景之上 7, 49, 72, 97,其中智能体通过对齐语言和视觉观测进行决策 64, 101, 27, 96, 42, 29, 71, 35,在预定义导航图上的节点之间传送。尽管效率很高,但直接将离散空间训练的 VLN 模型转移到现实世界的机器人应用是不切实际的。因此,提出了更现实的连续环境 VLN (VLN-CE) 45, 81,允许智能体通过预测低级控制 78, 40, 15, 31, 16 或从路点预测器 37, 47, 44 估计的可导航子目标中进行选择,自由导航到模拟器中的任何无障碍空间。同时,随着从网络规模的图像-文本对中学习通用视觉-语言表示的成功 20, 56, 91, 53, 95,许多 VLN 模型受益于大型视觉语言模型 55, 36, 18, 19 和 VLN 特定的预训练 34, 67, 33, 107, 73。最近,通过扩大导航训练数据,VLN 智能体在公认的 R2R 基准 46 上的表现正在接近人类 104。这一重大进展表明,在现实世界机器人中实施 VLN 技术是一个越来越可行且及时的考虑因素。
VLN 的 Sim-to-Real 迁移。 尽管取得了巨大进步,现有的 VLN 方法主要是在仿真中构建和评估的,这在很大程度上忽略了现实世界条件错综复杂和不可预测的性质。Sim-to-real VLN 迁移是一个研究不足的话题;直到今天,系统研究这一问题的唯一文献来自 Anderson 等人 8,该文证明了由于动作空间和视觉领域差异导致的性能差距(成功率下降超过 50%)。此外,我们要强调泛化到自由形式语言指令的挑战------即使在数百万个域内视觉数据上训练,智能体也经常无法解释不同风格的指令 104, 41。鉴于此,许多最近的研究利用大型(视觉-)语言模型的卓越泛化能力来促进 VLN 泛化。我们要么研究 LLM 固有的导航推理能力 121, 69, 120, 63, 14, 82, 58,要么通过促进指令解析的模块化设计 17 或注入常识知识 74 将 LLM 整合到导航系统中。我们遵循这一趋势,并进一步探索如何利用统一的大模型进行低级动作预测及其在现实世界场景中的泛化能力。这种方法不仅旨在通过利用 LLM 的全面理解和多功能能力 121, 69, 120, 63, 14, 74 来提升 VLN 的状态,还要弥合仿真环境与现实世界应用呈现的多方面挑战之间的差距。
大模型作为具身智能体。 最近,研究人员一直在探索将大模型整合到不同的具身领域 26, 121, 59, 86, 90, 82, 39。例如,PaLM-E 26 建议将来自各种模态的 token 与文本 token 一起整合到大模型中。然后,模型生成用于移动操作、运动规划和桌面操作等任务的高级机器人指令。更进一步,RT-2 11 生成机器人的低级动作,促进闭环控制。GR-1 106 引入了一种 GPT 风格的模型 75, 121, 63,专门用于多任务语言条件下的视觉机器人操作 111。该模型根据语言指令、观测图像和机器人状态预测机器人动作和未来图像。RoboFlamingo 54 提出了一种视觉语言操作框架,利用预训练的视觉语言模型来制定机器人操作策略。它旨在为机器人操作 22, 94, 111, 89 提供一种经济高效且高性能的解决方案,允许用户使用大模型微调其机器人。EMMA-LWM 112 通过口头交流为驾驶智能体开发了一个世界模型,在数字游戏环境 100 中显示出令人信服的结果。深入研究这些作品,本文聚焦于另一个关键的具身领域:视觉语言导航,这要求机器人在未见过的环境中根据人类指令进行导航。
III. 问题形式化
本文中连续环境视觉语言导航(VLN-CE)的形式化如下:在时间 t t t,给定一个由 l l l 个单词组成的自然语言指令 I I I 和一个包含帧序列 { x 0 , ... , x t } \{x_0, \dots, x_t\} {x0,...,xt} 的视频观测 O t O_t Ot,智能体需要规划下一步的低级动作 a t + 1 ∈ A a_{t+1} \in A at+1∈A。该动作将把智能体带到下一个状态,智能体将收到新的观测 x t + 1 x_{t+1} xt+1。总体而言,我们可以将决策制定为部分可观测马尔可夫决策过程(POMDP),表示为 { x 0 , a 1 , x 1 , a 2 , ... , x t } \{x_0, a_1, x_1, a_2, \dots, x_t\} {x0,a1,x1,a2,...,xt}。在这项工作中,观测空间 O O O 对应于单目 RGB 相机捕获的视频,不涉及其他额外数据,动作空间包含定性动作类型以及定量动作参数,在该领域也被称为低级动作 45。这种建模使得一种自然的范式成为可能,其中观测纯粹基于视觉且易于获取,而动作直接可执行,类似于人类的导航行为。
IV. 提出的 NaVid 智能体
根据第三节的形式化,我们设计了一种基于视频的 VLM 导航智能体,命名为 NaVid。NaVid 是同类中首个将 VLMs 的通用知识转移到现实 VLN 智能体的模型。我们在 IV-A 节介绍其架构,然后在 IV-B 节详细阐述 VLN 输入和输出的详细建模。训练策略在 IV-C 节详述,实施细节在 IV-D 节描述。
A. 整体架构
我们在通用基于视频的 VLM LLaMA-VID 57 之上构建 NaVid。对于提出的 NaVid,我们继承了 LLaMA-VID 的主要架构,并在其之上整合了特定于任务的设计,以促进通用知识向 VLN-CE 的转移,使其泛化挑战更容易解决。
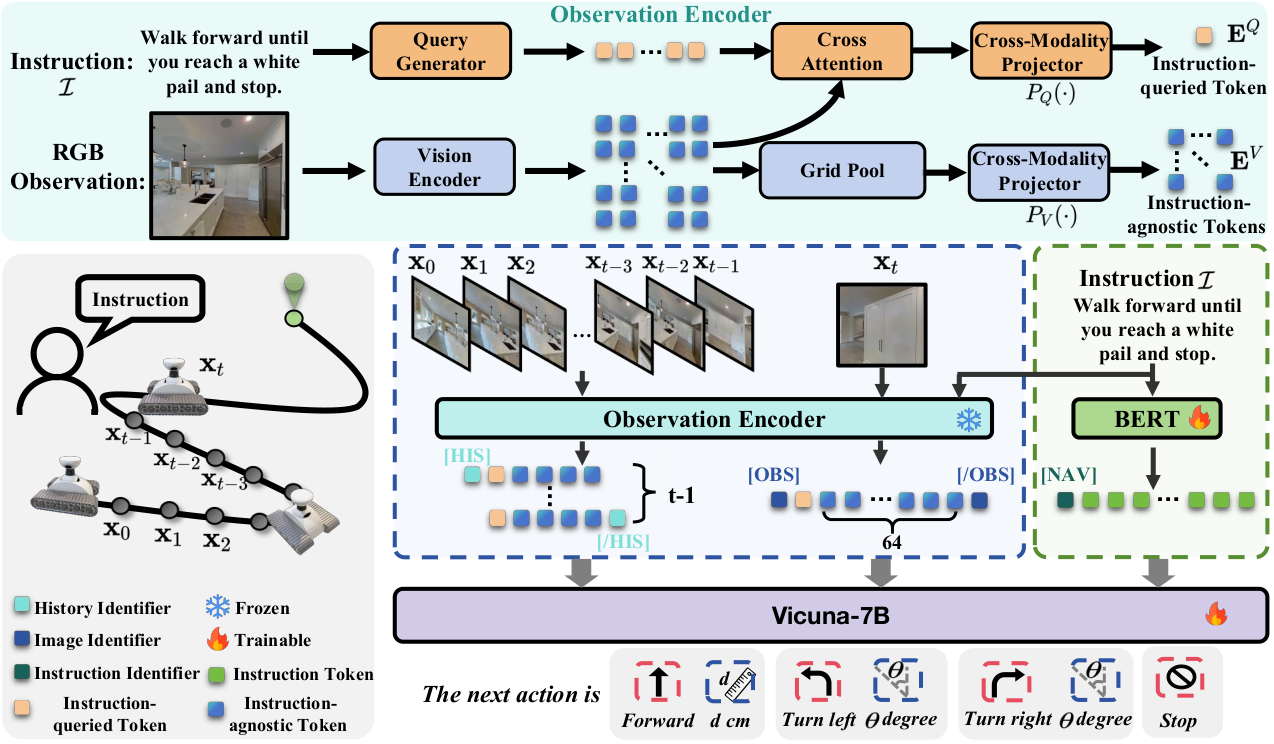
如图 2 所示,NaVid 由一个视觉编码器、一个查询生成器、一个 LLM 和两个跨模态投影器组成。给定直到时间 t t t 的观测,即包含 t t t 帧的视频序列,我们通过视觉编码器(实现中为 EVA-CLIP 92)将其编码为一系列 token,并将它们投影到与语言 token 对齐的空间。为简洁起见,我们将投影的 token 称为观测 token。通常,指令也被标记化为一组 token,称为指令 token。我们将观测 token 和指令 token 串联起来,并将它们发送到 LLM 以推断语言形式的 VLN 动作。请注意,我们的工作侧重于特定于任务的建模,而不是模型架构。
B. NaVid 的 VLN-CE 建模
观测编码。 给定直到时间 t t t 捕获的单目视频,表示为 O t = { x 0 , ... , x t } O_t = \{x_0, \dots, x_t\} Ot={x0,...,xt},我们用一个指令查询视觉 token 和几个指令无关视觉 token 来表示每一帧。指令查询 token 提取与给定指令具体相关的视觉特征,指令无关 token 全局编码细粒度的视觉信息。对于每一帧 x t x_t xt,我们首先使用视觉编码器获取其视觉嵌入 X t ∈ R N x × C X_t \in \mathbb{R}^{N_x \times C} Xt∈RNx×C,其中 N x N_x Nx 是补丁数量( N x N_x Nx 设为 256), C C C 是嵌入维度。
为了获得指令查询 token,我们采用基于 Q-Former 的查询生成器 G Q G_Q GQ 来生成指令感知查询 Q t ∈ R M × C Q_t \in \mathbb{R}^{M \times C} Qt∈RM×C,其中 M M M 表示每帧的查询数量, C C C 是每个查询的维度。查询生成公式为:
Q t = G Q ( X t , I ) ( 1 ) Q_t = G_Q(X_t, I) \quad (1) Qt=GQ(Xt,I)(1)
其中 X t X_t Xt 和 I I I 分别是帧 x t x_t xt 的视觉嵌入和指令 I I I 的文本嵌入。 G Q ( ⋅ ) G_Q(\cdot) GQ(⋅) 是一个基于 Q-Former 的变换器,用于通过 X t X_t Xt 和 I I I 之间的跨模态交互学习指令感知查询,如 57 中所述。类似于 Q-Former 52 中的操作,指令查询 token E t Q E_t^Q EtQ 通过 X t X_t Xt 和 Q t Q_t Qt 之间的交叉注意力获得,公式如下:
E t Q = P Q ( P o o l ( S o f t m a x ( Q t X t T ) X t ) ) ( 2 ) E_t^Q = P_Q(Pool(Softmax(Q_t X_t^T)X_t)) \quad (2) EtQ=PQ(Pool(Softmax(QtXtT)Xt))(2)
其中 P Q ( ⋅ ) P_Q(\cdot) PQ(⋅) 表示用于获取指令查询 token 的跨模态投影器, P o o l ( ⋅ ) Pool(\cdot) Pool(⋅) 是沿查询维度的平均操作,使得 E t Q ∈ R 1 × C E_t^Q \in \mathbb{R}^{1 \times C} EtQ∈R1×C。
对于指令无关 token,我们直接执行网格池化操作和跨模态投影来获取它们,公式如下:
E t V = P V ( G r i d P o o l ( X t ) ) ( 3 ) E_t^V = P_V(GridPool(X_t)) \quad (3) EtV=PV(GridPool(Xt))(3)
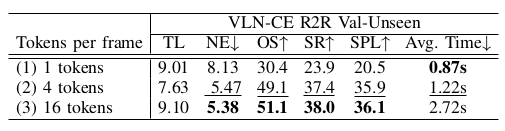
其中 G r i d P o o l ( ⋅ ) GridPool(\cdot) GridPool(⋅) 是网格池化操作 57,将 token 从 N x N_x Nx 压缩到 N v N_v Nv,产生 E t V ∈ R N v × C E_t^V \in \mathbb{R}^{N_v \times C} EtV∈RNv×C。网格池化的详细描述见补充材料。如实验所证,像 LLaMA-VID 57 那样用两个 token 表示每一帧不能满足 VLN-CE 任务的要求。这是因为 LLaMA-VID 主要设计用于高级问答任务,而 NaVid 需要规划机器人的可执行动作。因此,我们在此采用网格池化,使指令无关 token 能够保留足够的几何信息,以便 NaVid 中的 LLM 拥有足够的上下文来推理机器人动作的定量参数。
对于 VLN-CE,当前帧作为导航动作推理的主要基础,而历史帧为追踪导航进度提供重要上下文。考虑到它们对保留几何信息的不同要求,我们在编码历史帧和当前帧时采用不同数量的指令无关 token。在这项工作中,除非另有说明,我们将当前帧的指令无关 token 数量设置为 64,而每个历史帧为 4。这不仅促进了学习,还提高了效率。
为了进一步促进 NaVid 的训练,我们在将不同类型的信息发送到 NaVid 内的 LLM 之前,使用特殊 token 明确区分它们。
具体来说,我们采用特殊 token <HIS>, </HIS> 和 <OBS>, </OBS> 分别界定从历史帧和当前帧编码的 token。此外,我们使用另一个特殊 token <NAV> 提示 LLM 开始处理指令的文本 token 并以语言形式输出机器人动作。因此,NaVid 的输入可以总结如下:
bash
Input: `<HIS> {historical_frames} </HIS> <OBS> {current_frame} </OBS> <NAV> {instruction_content}`
Output: `{answer_content}`在这种格式中,占位符分别代表历史帧、当前帧、指令和推理动作的 token。
动作规划。 NaVid 以语言形式规划 VLN-CE 的下一步动作。其输出的每个动作由两个与 VLN-CE 设置对齐的变量组成。一个是动作类型,选自离散集合 {FORWARD, TURN-LEFT, TURN-RIGHT, STOP}。另一个是对应不同动作类型的定量参数。对于 FORWARD,NaVid 进一步推断具体的移动距离。对于 TURN-LEFT 和 TURN-RIGHT,NaVid 预测具体的旋转度数。使用正则表达式解析器 43 提取动作类型和参数,以便进行模型评估和现实世界部署。
C. NaVid 的训练
可用的导航仿真数据在多样性、真实性和规模方面仍然有限。我们设计了一种混合训练策略,以最大化这些数据在使 NaVid 有效泛化到新场景或现实世界中的利用率。为此,混合训练策略中提出了两种关键方法。一种是收集非 oracle(非专家/非最优)导航轨迹并将其纳入训练循环。另一种是设计辅助任务,以增强 NaVid 在导航场景理解和指令跟随方面的能力。
非 Oracle 导航轨迹收集。 受 Dagger 技术 80 的启发,我们收集非 oracle 导航轨迹并将其纳入 NaVid 的训练中。如果没有这种方法,NaVid 在训练期间只会接触到 oracle(最优)导航轨迹,这与实际应用条件不同,并降低了学习到的导航策略的鲁棒性。为了实现这一点,我们首先从 VLN-CE R2R 数据集收集 oracle 导航轨迹,包括单目视频观测、指令和机器人动作。具体来说,我们从 61 个 MP3D 室内场景 12 收集数据,总共包含 32 万个逐步样本。然后,我们在这些 oracle 轨迹数据上训练 NaVid,并将获得的智能体部署在 VLN-CE 环境中,以进一步收集非 oracle 导航轨迹。结果,我们获得了另外 18 万个逐步样本。来自 oracle 和非 oracle 轨迹的样本被组合用于 NaVid 的最终训练。

VLN-CE 和辅助任务的联合训练。 作为导航智能体,除了规划导航动作外,精确理解环境和遵循给定指令是两项不可或缺的能力。为了促进智能体学习,我们将 VLN-CE 动作规划与两个辅助任务结合在联合训练范式中。为了理解环境,我们设计了一个称为指令推理 的辅助任务。给定基于视频的导航轨迹,要求 NaVid 推断该轨迹对应的指令。这个辅助任务可以很容易地使用 Sec. IV-B 中介绍的共享数据组织格式实现,其中 {instruction_content} 和 {answer_content} 可以实例化为请求机器人导航轨迹描述的提示和数据集中提供的人工标记指令。指令推理辅助任务包含 1 万条轨迹。此外,为了增强指令跟随和防止预训练中获得的通用知识遗忘,我们还将基于视频的问答样本纳入我们的联合训练中。
D. 实施细节
训练配置。 NaVid 在具有 24 个 NVIDIA A100 GPU 的集群服务器上训练大约 28 小时,总共 672 GPU 小时。
评估配置。 在 NaVid 预测语言动作后,我们利用正则表达式匹配 43 来期待有效动作。对于现实世界导航,我们使用远程服务器运行 NaVid 接收观测并命令本地机器人执行预测动作。在导航期间,智能体大约需要 1.2 到 1.5 秒输出每帧的一个动作。
V. 实验
A. 实验设置
仿真环境。 我们在 VLN-CE 基准上评估我们的方法。我们考虑 VLN-CE 中的 R2R 46 和 RxR 49。为了公平比较,所有方法都在 10,819 个 R2R 训练分割上进行训练,并分别在 1,839 个 R2R val-unseen 分割和 1,517 个 RxR val-unseen 分割上进行评估,以评估跨分割和跨数据集的性能。
现实世界环境。 为了评估我们方法在现实世界环境中的性能,我们遵循 8, 108 的实验设置,设计了包括不同室内场景和不同难度指令的综合实验。我们选择了四个不同的室内场景,包括 Meeting_room, Office, Lab 和 Lounge。我们使用配备 Kinect DK 相机的 Turtlebot4 进行实验。
指标。 我们遵循标准 VLN 评估指标 7, 46, 50, 51,包括成功率 (SR)、Oracle 成功率 (OS)、路径长度加权成功率 (SPL)、轨迹长度 (TL) 和离目标导航误差 (NE)。
基线。 我们与直接预测低级动作原语的方法进行比较,包括 Seq2Seq 45, CMA 45, WS-MGMap 16。
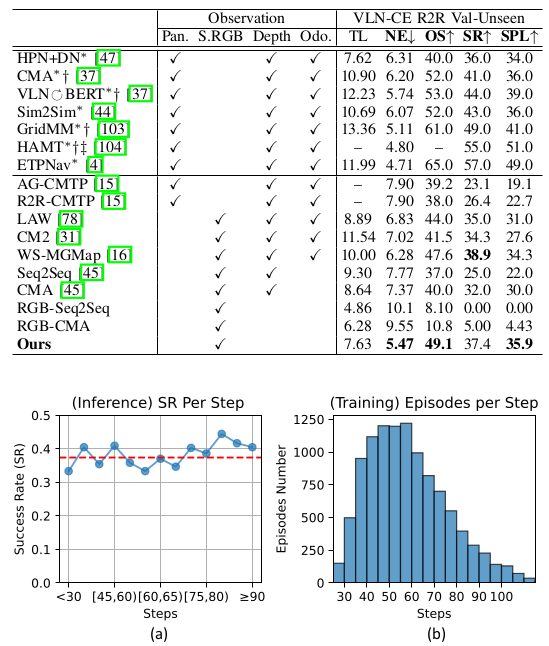
B. 仿真环境比较
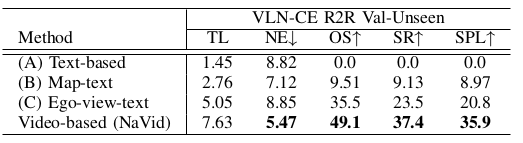
VLN-CE R2R。 结果如表 I 所示。我们的方法仅使用 RGB 观测。与相关的 VLN-CE 设置(低级动作空间)相比,我们的方法在 SPL, NE 方面取得了 SOTA 性能,并且在 SR 上与 WS-MGMap 相当,且不使用深度和里程计信息。这证明了仅依靠 RGB 观测的有效性。
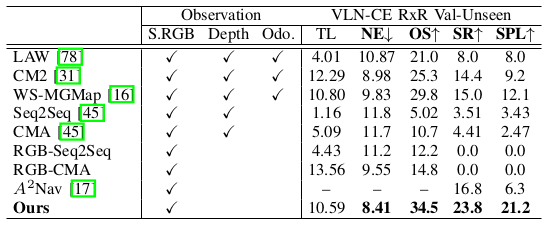
VLN-CE RxR。 为了评估跨数据集性能,我们在 R2R 上训练模型并在 RxR Val-Unseen 数据分割上比较零样本性能。如表 II 所示,我们的方法在 NE, OS, SR 和 SPL 方面大幅优于现有方法。
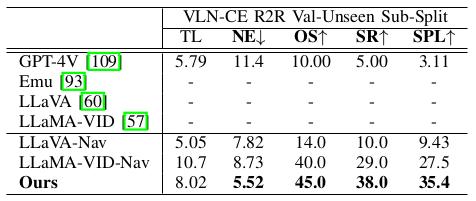
与大基础模型的比较。 我们评估了主流大模型在 VLN 任务上的性能,如 GPT-4V, LLaVA, LLaMA-VID 等(表 III)。结果发现,未在导航数据上微调的方法表现很差。微调后,我们的 NaVid 依然表现出色。
C. 现实世界环境比较
我们在现实世界环境中进行了广泛实验(表 VI)。结果发现我们的方法相较于所有基线方法都有显著提升。Seq2Seq 和 CMA 等端到端方法表现极差,体现了 Sim-to-Real 的巨大差距。WS-MGMap 通过利用语义地图表现较好。然而,我们的方法仅需 RGB 视频,就能完成大多数指令(约 84%)和相当复杂的指令(约 48%)。



D. 消融实验
我们在表 VII 中验证了各组件的有效性。联合训练数据对性能至关重要。移除特殊 token 会导致性能下降。Waypoint prediction(路点预测)变体表现极差,证明直接输出连续位置和方向对 VLM 来说极具挑战性。
VI. 讨论与结论
本文提出了 NaVid,一种用于视觉语言导航的基于视频的 VLM 方法。NaVid 在不依赖里程计、深度传感器或地图的情况下实现了 SOTA 导航性能。我们扩展了基于视频的 VLM 模型,通过整合自定义特殊 token 来编码历史和当前导航数据。为了学习视觉指令跟随能力,我们收集了 51 万个动作规划样本和 1 万个指令推理样本。实验表明 NaVid 仅用单目视频即可实现 SOTA 性能,并具有良好的 Sim-to-Real 泛化能力。
局限性: 计算成本导致延迟问题;长上下文问题可能导致性能下降;缺乏高质量长视频注释数据。
未来工作: 扩展到移动操作等其他具身 AI 任务;研究允许同时控制手臂和底座的动作设计;收集带注释的移动操作视频数据集。