本文主要讲解 Hadoop 的 HDFS 和 MapReduce 组件,具体情况如下所示。
安装 Hadoop 请参考网址:https://editor.csdn.net/md/?articleId=153209992
第1章 HDFS 的使用
HDFS 是一个为大规模数据集设计的分布式文件系统 。它的核心思想是 "分而储之"。
它将大文件切分成固定大小的数据块 ,并将这些数据块冗余存储 在由普通计算机组成的集群中的多个节点上。HDFS 采用主从架构:
-
主节点(NameNode) :负责管理文件系统的元数据,如文件名、目录结构以及数据块的位置,相当于文件的"索引目录"。
-
text
**从节点(DataNode)**:负责在本地磁盘上**存储实际的数据块**,并定期向 NameNode 报告其存储情况。
HDFS 的主要特点是:
- 高容错性:通过多副本冗余机制,即使某个硬件故障,数据也不会丢失。
- 高吞吐量 :它被优化用于一次写入、多次读取的流式数据访问模式,适合进行大规模数据分析,而非低延迟的数据交互。
- 处理超大文件:适合存储 GB、TB 甚至 PB 级别的大文件。
简单来说,HDFS 就像一个巨大的、可靠的联合仓库:NameNode 是中央管理员,知道所有货物(数据块)存放在哪个货架(DataNode);而 DataNode 就是一个个货架,负责安全地存放货物。即使少数货架损坏,也因为货物有备份,整个仓库的运营完全不受影响。它通常与 MapReduce 配合,成为大数据生态系统的存储基石。
HDFS(Hadoop Distributed File System)是 Hadoop 的分布式文件系统,用于处理解决于分布式相关的问题,关于HDFS 的使用如下所示。
1.启动和停止 HDFS
bash
cd $HADOOP_HOME①启动HDFS
bash
sbin/start-dfs.sh
jps # 检查Java进程,可以看到: NameNode, DataNode, SecondaryNameNode②# 停止HDFS
bash
sbin/stop-dfs.sh
jps # 检查Java进程
2.熟悉 Hadoop 的 HDFS 上的基本文件操作:
①文件操作示例:
bash
bin/hdfs dfs -mkdir dir # 创建单个文件夹
bin/hdfs dfs -mkdir -p /dir1/dir2 # 创建多层文件夹
bin/hdfs dfs -put etc/hadoop/*.xml dir #将本地文件夹内的xml文件,上传到HDFS中
运行自带的例子bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.4.0.jar grep dir output 'dfsa-z.+'
bash
bin/hdfs dfs -cat output/* #查看HDFS文本文件内容
bin/hdfs dfs -get output op #将HDFS文件夹内的文件,下载到本地文件夹中
bash
cat op/* #查看本地文件夹文本文件内容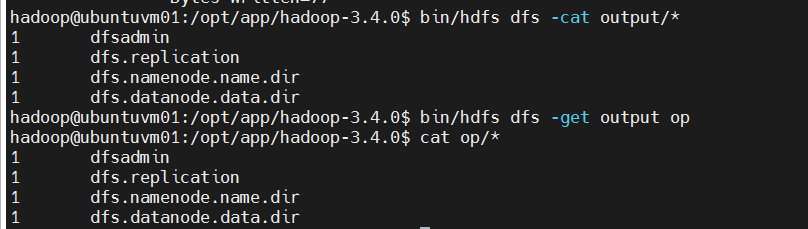
bash
rm -rf op
bash
bin/hdfs dfs -rm -r dir #删除HDFS文件
bin/hdfs dfs -rm -r output #删除HDFS文件夹
bash
bin/hdfs dfs -rm -r /dir1/dir2
bash
bin/hdfs dfs -rm -r /dir1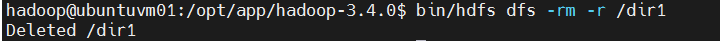
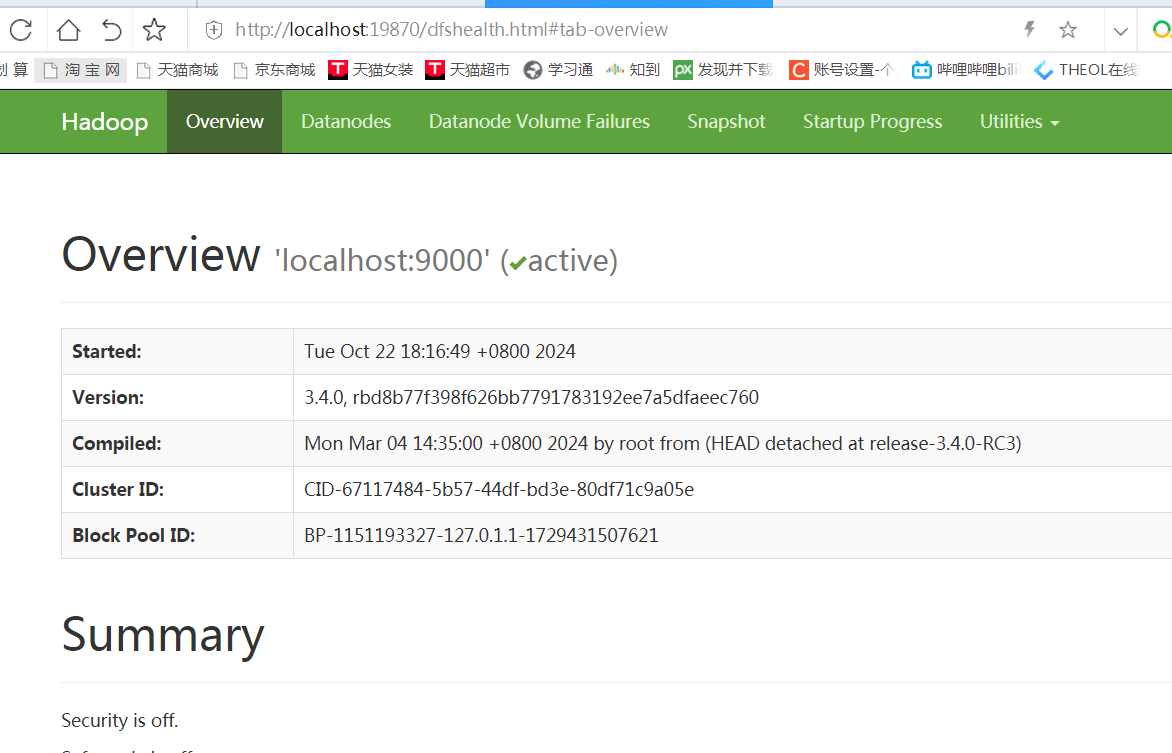
3.通过 Web 界面,打开文件浏览器,进行文件的管理操作。
通过浏览器,访问名称节点的 Web 界面。 名称节点(NameNode)在虚拟机上开启了 Web 服务: http://localhost:19870
4.运行 Hadoop 的基本样例程序。
①# 创建用户文件夹,下面的 username 就是 hadoop。只需要执行一次。
命令格式: bin/hdfs dfs -mkdir -p /user/
bash
bin/hdfs dfs -mkdir -p /user/hadoop继续在 HDFS 的用户文件夹 /user/hadoop 里面,创建 input 文件夹。
bash
bin/hdfs dfs -mkdir input将本地的一些 xml 文件,上传到 HDFS 的 /user/hadoop/input 文件夹里。
bash
bin/hdfs dfs -put etc/hadoop/*.xml input运行自带的例子。
bash
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.4.0.jar
grep input output 'dfs[a-z.]+'查看 HDFS 文件夹 /user/hadoop/output 内的运行结果:
bash
bin/hdfs dfs -cat output/*. 
或者,将 HDFS 里 /user/hadoop/output 文件夹内容下载到本地 output 文件夹再查看结果:
bash
# 将 HDFS 里 `/user/hadoop/output` 文件夹内容下载到本地 output 文件夹。
bin/hdfs dfs -get output output查看本地 output 文件夹内的结果。
bash
cat output/*
【可选】清理干净。
bash
bin/hdfs dfs -rm -r input
bin/hdfs dfs -rm -r output
rm -rf output
第2章 使用 MapReduce
MapReduce 是一种用于大规模数据集的并行分布式编程模型,核心思想是 "分而治之"。
它把处理过程抽象为两个阶段:
- Map(映射)阶段 :
- 将大规模数据集拆分成大量的小数据块。
- 将这些小数据块分发给集群中的多个节点进行并行处理。
- 每个节点处理自己分到的数据,并输出一组中间键值对。
- Reduce(归约)阶段 :
- 将 Map 阶段输出的所有中间结果,按照相同的键 进行排序、分组和聚合。
- 再将分组后的数据分发给 Reduce 节点进行汇总计算,并生成最终结果。
简单来说,MapReduce 的工作流程就像统计一屋子人手里各种水果的总数:
- Map :让每个人(工作节点)分别报出自己手里有哪几种水果,每种有几个(输出中间键值对,如
(苹果, 1), (香蕉, 2))。 - Shuffle & Sort:把大家报出的结果收集起来,把所有"苹果"的放一堆,所有"香蕉"的放一堆(按键分组)。
- Reduce:然后分别对"苹果"堆和"香蕉"堆进行求和,得到苹果的总数和香蕉的总数(归约计算,输出最终结果)。
它的主要优点是:将复杂的分布式并行编程(如数据分发、容错、负载均衡)封装了起来,开发者只需关注实现 Map 和 Reduce 两个核心逻辑,就能轻松让程序在成百上千台机器上运行,高效处理海量数据。Hadoop 是 MapReduce 模型最著名的实现。
- 启动 HDFS
bash
cd $HADOOP_HOME
sbin/start-dfs.sh
jps # 进程中可以看到有:NameNode,DataNode,以及SecondaryNameNode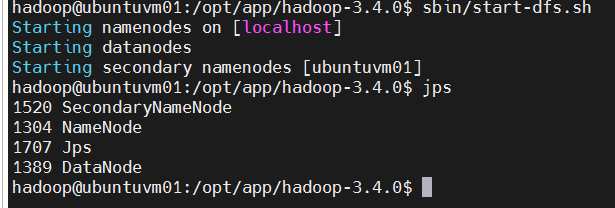
- 将 exercise1 源码压缩包解压缩:
① # change directory to hadoop's user home.
bash
cd② # 创建文件夹(这里mr代表MapReduce的意思)
bash
mkdir mrproject
cd mrproject
③ # 解压缩
bash
tar zxf /media/sf_vmshare/exercise1_src.tar.gz
④ 检查一下,可以看到如下3个文件夹:
bash
ll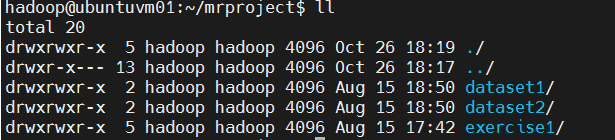
其中, dataset1 里面是第1题(Merge.java)的输入文件,含2个输入数据文件;dataset2 里面是第2题(MergeSort.java)的输入文件,含3个输入数据文件;exercise1 是 Java 项目源码,它里面有 Merge.java 和 MergeSort.java,是这2题的 MapReduce 源程序。
- 将本地文件夹 dataset1 和 dataset2 中的输入文件,上传到 HDFS 中:
bash
cd $HADOOP_HOME① # 第1题(Merge.java)的输入文件,在HDFS中创建文件夹,并上传数据文件。
bash
bin/hdfs dfs -mkdir -p input/exercise1
bin/hdfs dfs -put ~/mrproject/dataset1/A.txt input/exercise1
bin/hdfs dfs -put ~/mrproject/dataset1/B.txt input/exercise1检查一下,刚才上传的输入数据文件应该已经存在了。
bash
bin/hdfs dfs -ls input/exercise1清理掉之前遗留的输出文件夹(如果存在的话)
bash
bin/hdfs dfs -rm -r output/exercise1
第2题(MergeSort.java)的输入文件,在HDFS中创建文件夹,并上传数据文件。
bash
bin/hdfs dfs -mkdir -p input/exercise2
bin/hdfs dfs -put ~/mrproject/dataset2/1.txt input/exercise2
bin/hdfs dfs -put ~/mrproject/dataset2/2.txt input/exercise2
bin/hdfs dfs -put ~/mrproject/dataset2/3.txt input/exercise2检查一下,刚才上传的输入数据文件应该已经存在了。
bash
bin/hdfs dfs -ls input/exercise2清理掉之前遗留的输出文件夹(如果存在的话)
bash
bin/hdfs dfs -rm -r output/exercise2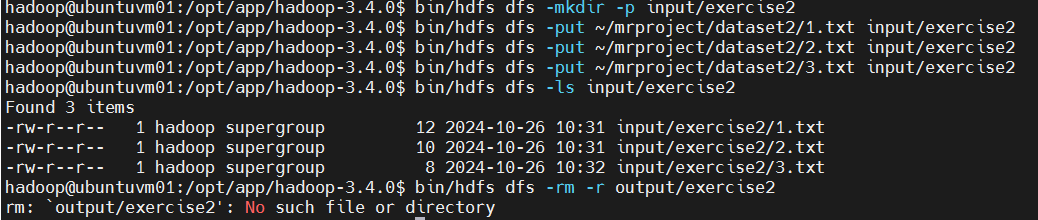
- 启动 IntelliJ IDEA 集成开发工具软件:
bash
# 以后台方式启动 IntelliJ IDEA
idea &
- 在 IntelliJ IDEA 集成开发环境中,打开此 Java 项目: ~/mrproject/exercise1
此 Java 项目需要引入 Hadoop 的 jar 包。打开项目的"Project Structure",在 Libraries 里面添加"hadoop"(指向 Hadoop-3.4.0 的安装路径),并在右边,添加依赖 jar 包。这些依赖 jar 包包括:
share/hadoop/common 里面的全部 jar 包
share/hadoop/common/lib 里面的全部 jar 包
share/hadoop/client 里面的全部 jar 包
share/hadoop/mapreduce 里面的全部 jar 包
将它们都添加进来。项目就能够编译通过。如下图所示:
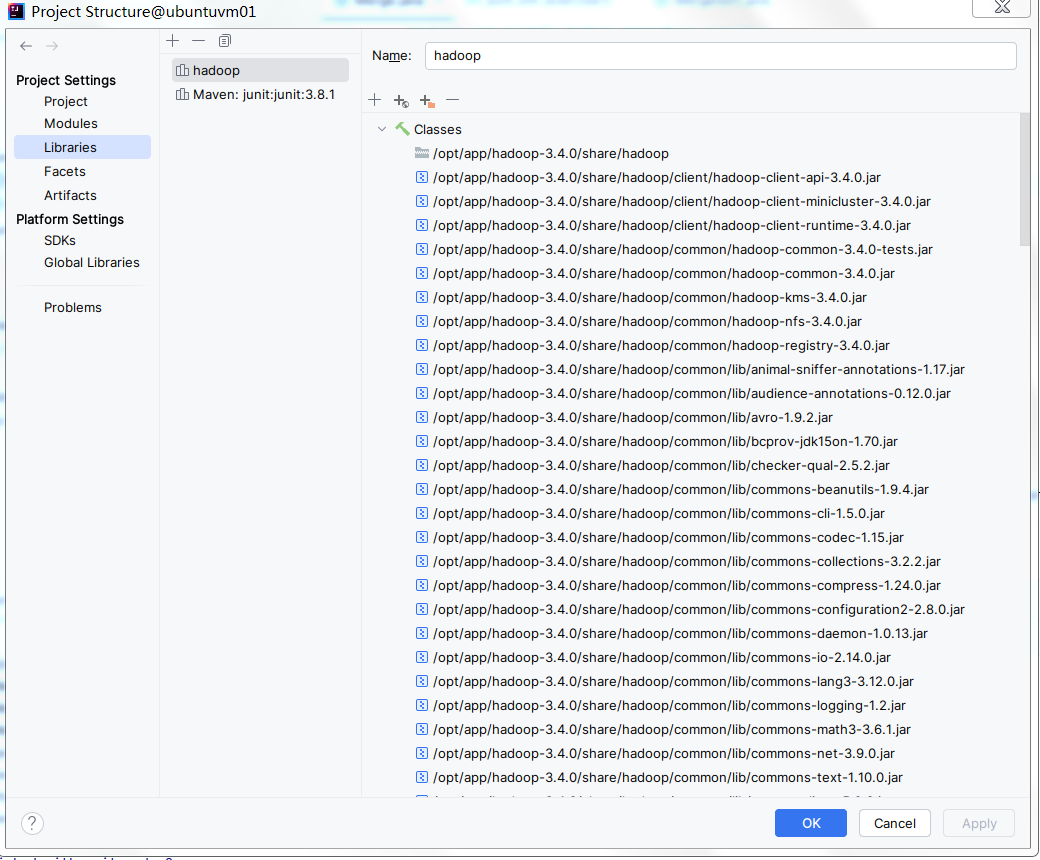
- 在 IntelliJ IDEA 集成开发环境中运行。在 exercise1 项目中, Merge.java 是第一题的
MapReduce 程序; MergeSort.java 是第第二题的 MapReduce 程序。分别运行这两个程序,运行成功结束后,再检查一下输出文件夹。
查看第1题(Merge.java)的输出
bash
bin/hdfs dfs -cat output/exercise1/*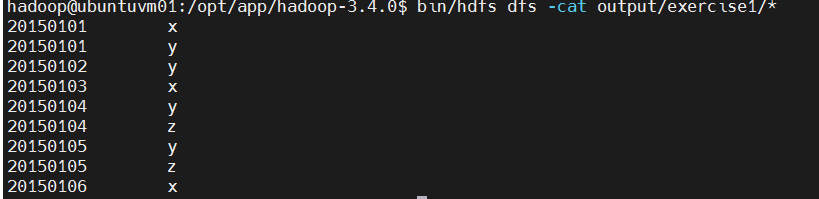
查看第2题(MergeSort.java)的输出
bash
bin/hdfs dfs -cat output/exercise2/*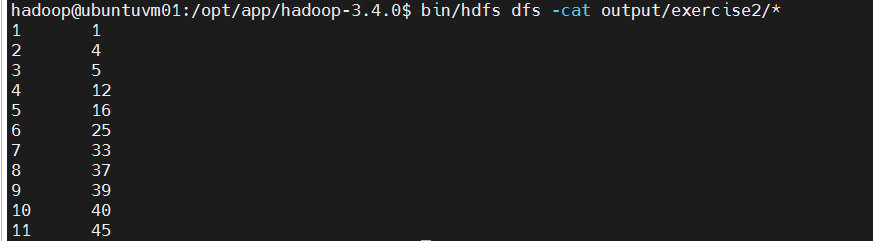
- 【可选】清理掉HDFS上的文件:
bash
cd $HADOOP_HOME清理掉第1题用到的输入和输出文件夹
bash
bin/hdfs dfs -rm -r input/exercise1
bin/hdfs dfs -rm -r output/exercise1
清理掉第2题用到的输入和输出文件夹
bash
bin/hdfs dfs -rm -r input/exercise2
bin/hdfs dfs -rm -r output/exercise2
- 关闭 HDFS:
bash
cd $HADOOP_HOME
# 停止Hadoop
sbin/stop-dfs.sh`bash
bin/hdfs dfs -rm -r input/exercise1
bin/hdfs dfs -rm -r output/exercise1
[外链图片转存中...(img-xq7IrbnU-1760369308140)]
\# 清理掉第2题用到的输入和输出文件夹
```bash
bin/hdfs dfs -rm -r input/exercise2
bin/hdfs dfs -rm -r output/exercise2外链图片转存中...(img-XIELcZxh-1760369308140)
- 关闭 HDFS:
bash
cd $HADOOP_HOME
# 停止Hadoop
sbin/stop-dfs.sh