目录
五种IO模型
Linux高级I/O提供了一套超越标准I/O的机制,核心目标是提升I/O操作的效率,特别适合处理大量并发连接或需要高性能I/O的场景。
阻塞IO
阻塞IO:在内核将数据准备好之前,系统调用会一直等待。所有的套接字,默认都是阻塞方式。
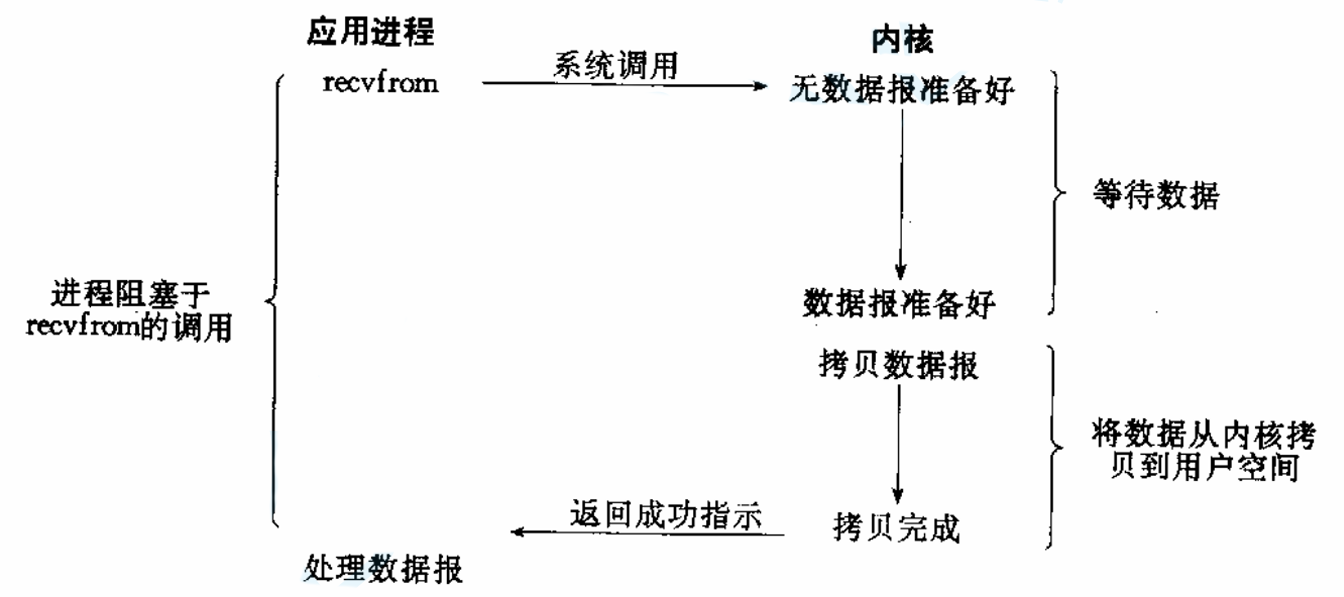
阻塞IO实现简单,但是效率低,资源利用率差。
非阻塞IO
非阻塞IO:如果内核还未将数据准备好,系统调用仍然会直接返回,并且返回EWOULDBLOCK错误码。
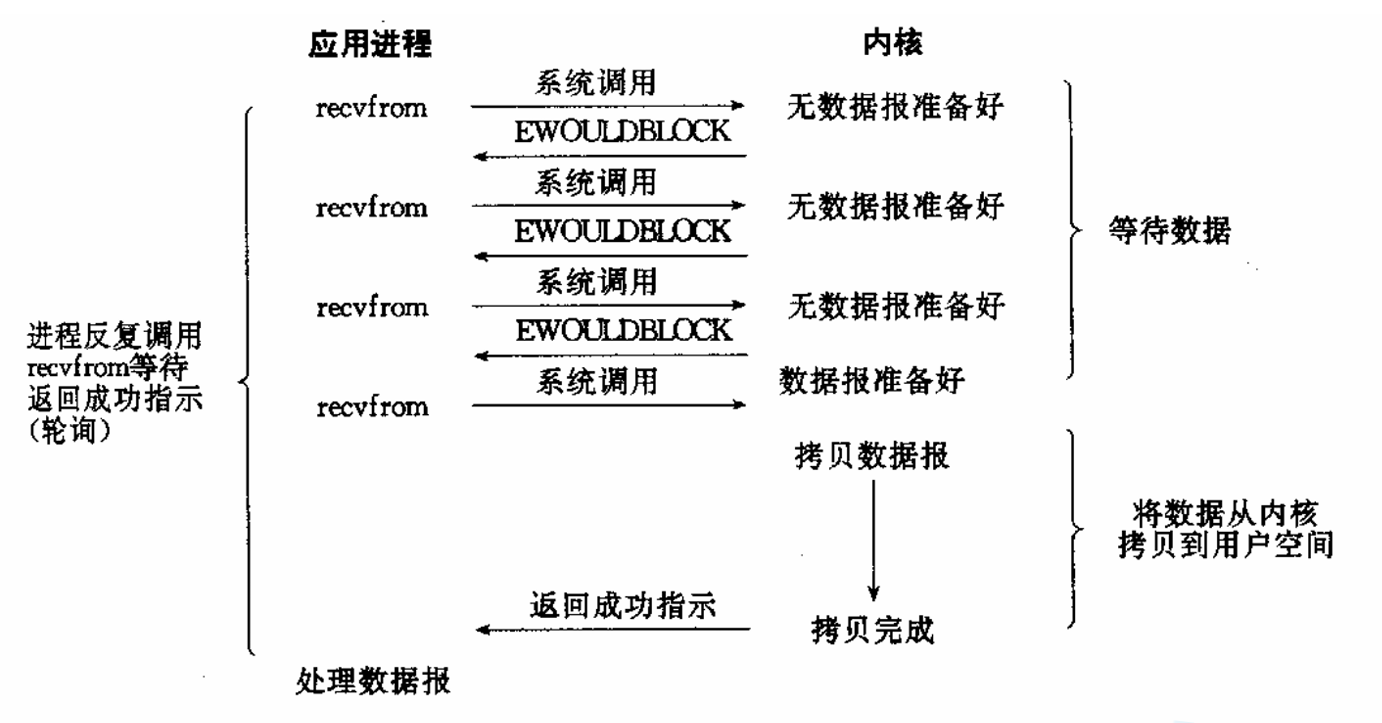
非阻塞IO往往需要程序员循环的方式反复尝试读写文件描述符,这个过程称为轮询。这对CPU来说是较大的浪费,一般只有特定场景下才使用。
信号驱动IO
信号驱动IO:内核将数据准备好的时候,使用SIGIO信号通知应用程序进行IO操作。
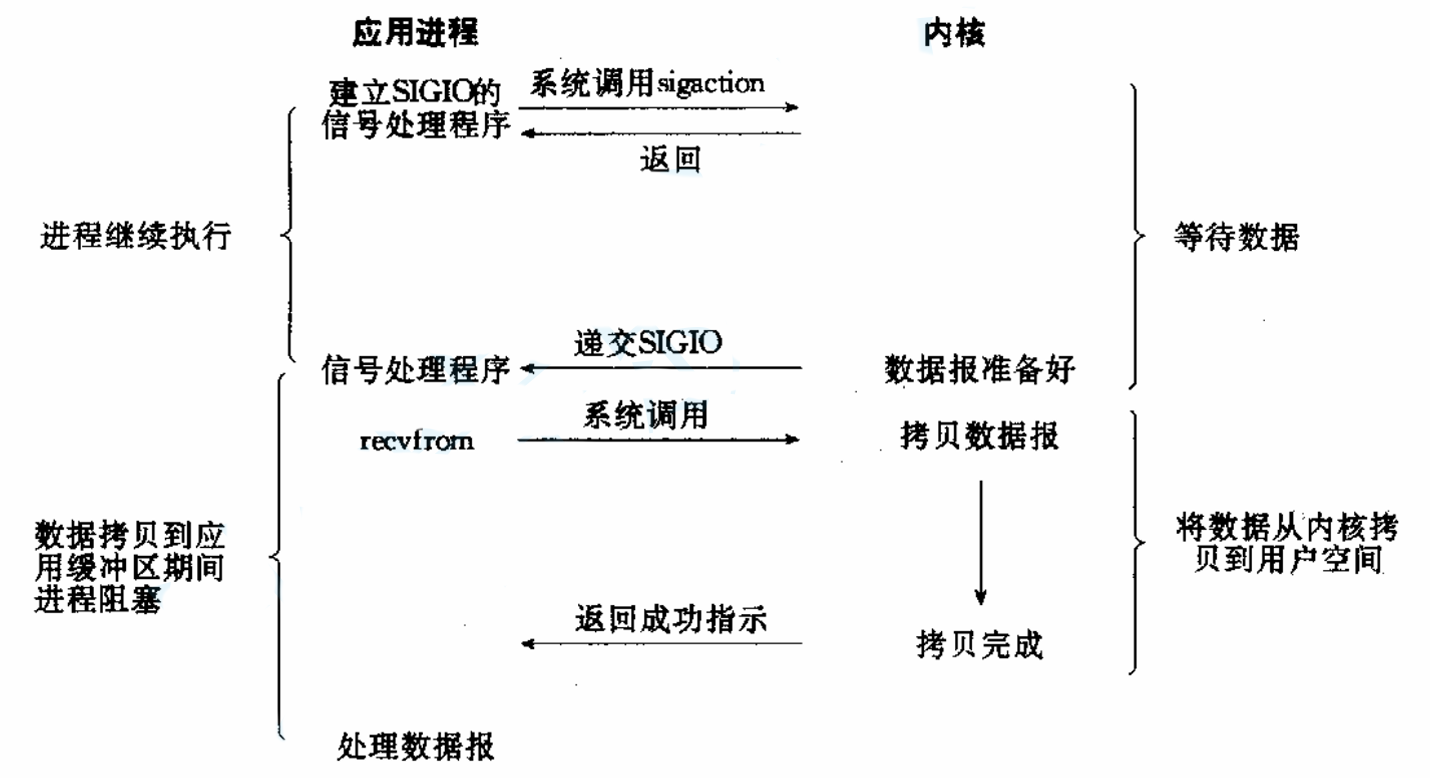
异步通知,但信号处理复杂,不适合高频I/O操作,对TCP套接字实用性较低。
IO多路转接(多路复用)
IO多路转接:虽然从流程图上看起来和阻塞IO类似。实际上最核心在于IO多路转接能够同时等待多个文件描述符的就绪状态。
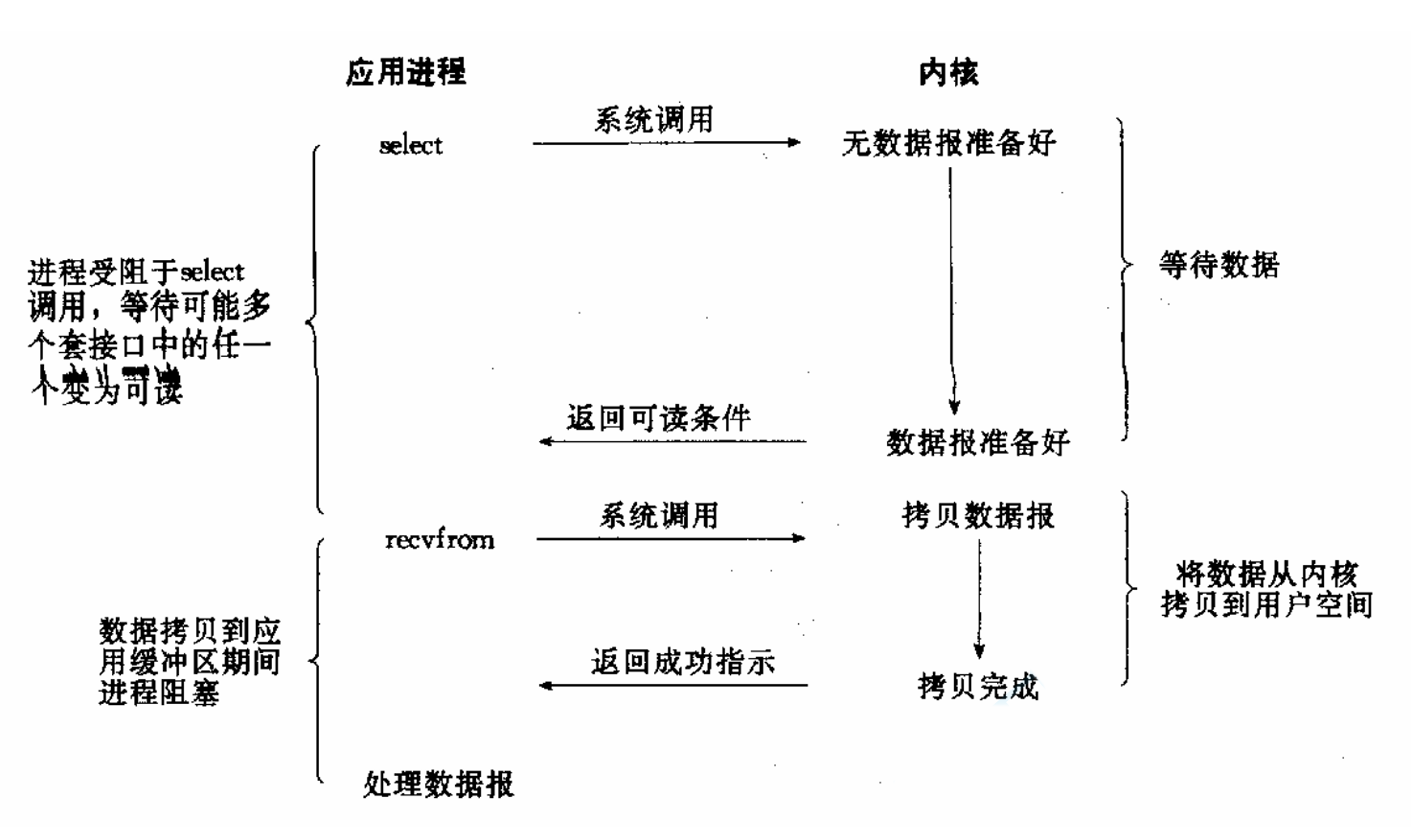
使用 select/poll/epoll 同时监控多个I/O描述符,当某个描述符就绪时,再调用I/O函数进行数据读写。这种方式可以高效处理高并发连接,一个线程可管理大量连接,适用于高并发网络服务,但编程复杂度较高。
异步IO
异步IO:由内核在数据拷贝完成时,通知应用程序(而信号驱动是告诉应用程序何时可以开始拷贝数据)。
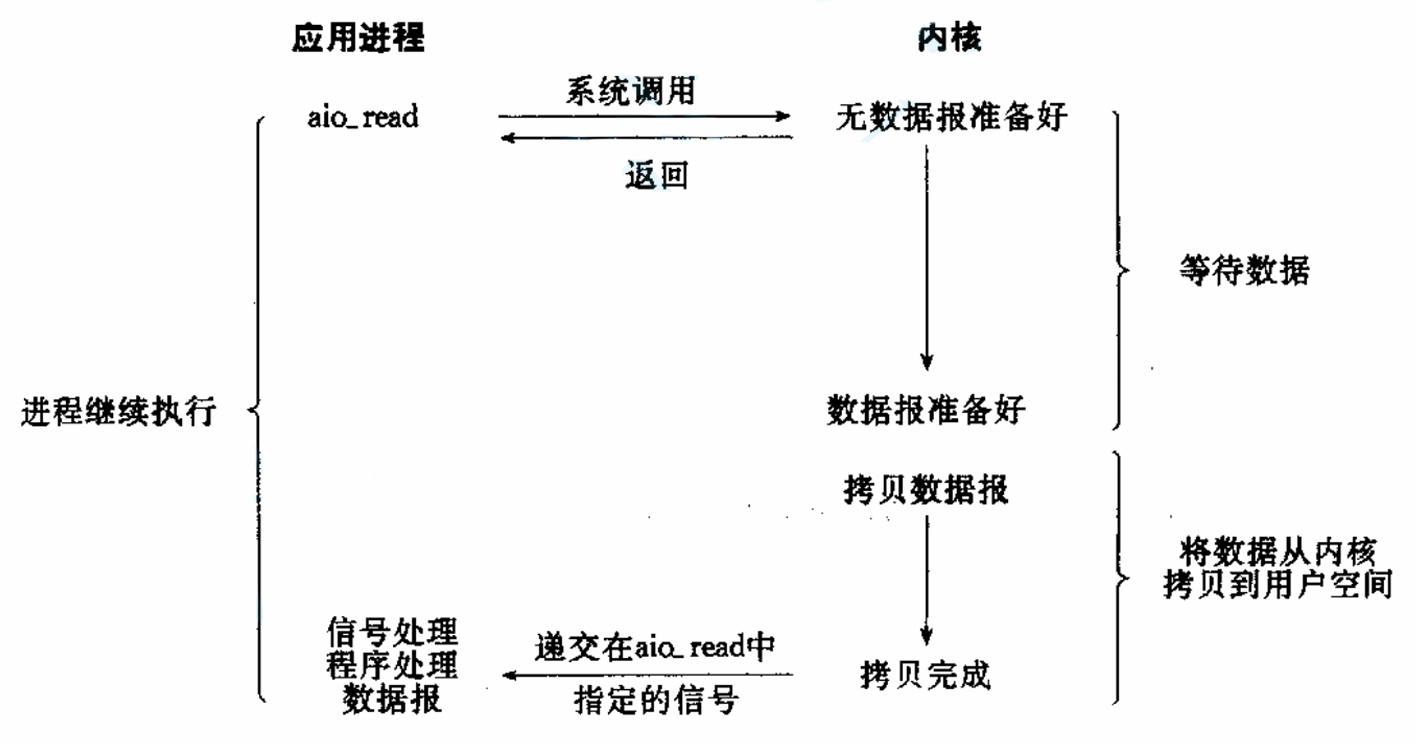
异步IO是真正的异步,进程发起I/O请求后立即返回,内核完成所有工作(包括数据拷贝)后,通过回调或信号通知进程,进程完全不参与等待和拷贝。
IO的本质是等 + 拷贝。IO的过程一定要调用系统调用read && write,read && write函数本质就是在用户层和内核之间进行拷贝。在拷贝之前,必须判断条件成不成立,比如调用read就得判断缓冲区有没有数据,调用write就得判断缓冲区有没有满,条件不成立就得等,所以IO的本质是等 + 拷贝。这个判断条件则被称为读写事件。
我们想要进行高效的IO,就得降低等的比重,因为拷贝的过程无法避免,这也是学习高级IO的目的。
同步 VS 异步
同步:所谓同步,就是在发出一个调用时,在没有得到结果之前,该调用就不返回。但是一旦调用返回,就得到返回值了。换句话说,就是由调用者主动等待这个调用的结果。
异步:异步则是相反,调用在发出之后,这个调用就直接返回了,所以没有返回结果。换句话说,当一个异步过程调用发出后,调用者不会立刻得到结果。而是在调用发出后,被调用者通过状态、通知来通知调用者,或通过回调函数处理这个调用。
阻塞IO、非阻塞IO、信号驱动IO、IO多路转接都属于同步IO。
为什么非阻塞IO是同步的呢?
非阻塞IO确实不会傻等事件就绪,但是它还是在等,只不过等的时候可以做一些其他事情罢了。
为什么信号驱动IO是同步的呢?
信号驱动可以不用轮询事件是否就绪,而是在资源就绪后通知自己,但是归根结底得到事件就绪的通知后还要执行拷贝操作,拷贝操作还是同步的。
为什么多路转接是同步的呢?
多路转接可以等待多个文件描述符,拷贝的过程还是自己完成,所以也是同步的。
阻塞 VS 非阻塞
阻塞:阻塞调用是指调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会返回。
非阻塞:非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程。
阻塞IO是最纯粹的阻塞,非阻塞IO、信号驱动IO、IO多路转接通过优化等待方式(轮询或事件通知)提高了单线程处理多个I/O的效率,但它们在数据拷贝的关键步骤上仍然是同步的,并可能在此刻阻塞线程,因此不属于真正的异步操作。
非阻塞IO
首先我们来认识一个函数:
c
int fcntl(int fd, int cmd, ... /* arg */ );fcntl函数(file control)是 Unix/Linux 系统编程中一个非常重要的系统调用,用于对已打开的文件描述符进行各种控制操作。它功能强大,是管理文件描述符属性的主要工具之一。
如果要实现非阻塞的方式有很多,open函数中可以使用对应标志位来进行控制,套接字中recv,send函数也有对应的标志位,但是使用fcntl函数无疑是最为通用的做法。
fcntl函数有5种功能:
复制一个现有的描述符(cmd=F_DUPFD)。
获得/设置文件描述符标记(cmd=F_GETFD或F_SETFD)。
获得/设置文件状态标记(cmd=F_GETFL或F_SETFL)。
获得/设置异步I/O所有权(cmd=F_GETOWN或F_SETOWN)。
获得/设置记录锁(cmd=F_GETLK,F_SETLK或F_SETLKW)。
我们只用第三个功能改变文件状态将其改成非阻塞就行。
cpp
#include<iostream>
#include<unistd.h>
#include <fcntl.h>
#include<errno.h>
#include<string.h>
using namespace std;
void SetNoBlock(int fd)
{
int fl = fcntl(fd, F_GETFL);
if(fl < 0)
{
perror("fcntl");
return;
}
fcntl(fd, F_SETFL, fl | O_NONBLOCK);
}
int main()
{
char buffer[1024] = {0};
SetNoBlock(0);
while(1)
{
printf("please enter# ");
fflush(stdout);
int n = read(0, (void*)buffer, sizeof(buffer));
if(n > 0)
{
buffer[n] = 0;
printf("%s", buffer);
}
else if(n < 0)
{
if(errno == 11)
cout << "errno: " << errno << ", error reason: " << strerror(errno) << endl;
else
{
printf("serious error, exit");
break;
}
}
else
{
printf("end of stdin, close fd and exit\n");
close(0);
break;
}
sleep(1);
}
return 0;
}首先我们要使用fcntl改变文件描述符标记,我们就得先获取它,因为这是一种位图结构,我们要在原有的基础上在对应的标志位上设置非阻塞标记,所以我们先这么调用fcntl函数:
cpp
int fl = fcntl(fd, F_GETFL);fcntl函数可以根据第二个参数来改变后续的可变参数,使用F_GETFL命令后面就不用传参数。
fcntl函数失败返回-1,可以进行错误判断。
之后使用F_SETFL命令可以设置指定文件描述符标记,我们使用按位或,在原有的文件描述符标记基础上进行添加O_NONBLOCK标记位,他表示设置文件描述符为非阻塞轮询。
当设置成非阻塞文件描述符时,我们读取或写入这个文件描述符时如果读写时间不就绪那么就会直接返回负数表示出错,

可以看到,错误码是11,对应的描述是Resource temporarily unavailable(资源暂时不可用),所以当出现这个错误时我们不能直接关闭,这是正常会出现的,要单独处理。
多路转接
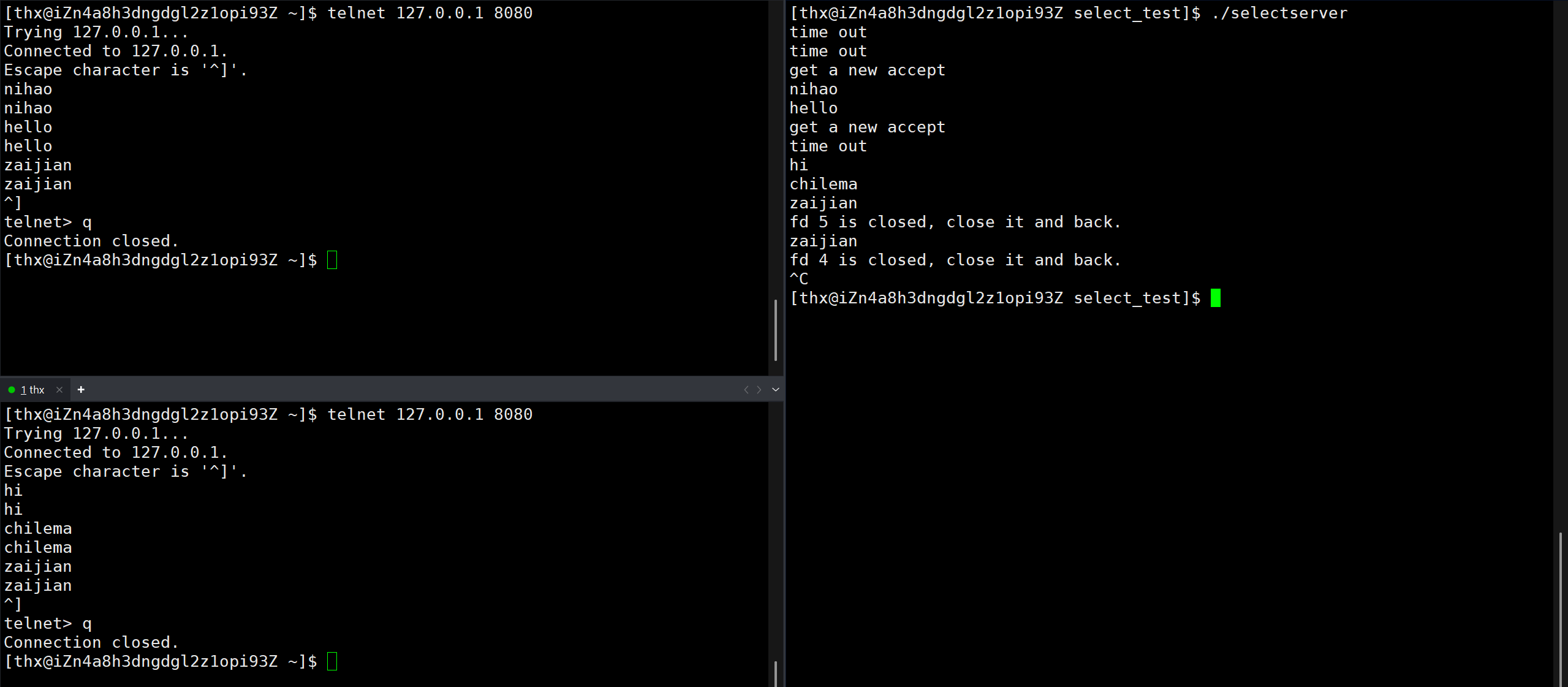
select
select是Linux/Unix系统早期用来解决多路转接给出的方案,现在来看已经过时,但是它的概念和接口都相对容易,适合入门讲解。
select函数可以用来序监视多个文件描述符的状态变化,程序会停在select这里等待,直到被监视的文件描述符有一个或多个发生了状态改变。
c
int select(int nfds, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, struct timeval *timeout);参数nfds是需要监视的最大的文件描述符值+1;参数rdset,wrset,exset分别对应于需要检测的可读文件描述符的集合,可写文件描述符的集合及异常文件描述符的集合;timeout用来设置等待时间。
fd_set是什么呢?这是一个内核定义的数据结构,可以理解为一个位图,因为文件描述符是从0开始的递增的数字,含义就是内核维护的数组的下标,fd_set的大小为128字节,也就是1024bit位,所以使用fd_set就注定了select函数所能监视的文件描述符是有上限的。
如果我们想要在一个select监视readfds那就传,不想监视就传NULL,其余同理,我们也能同时监视多个fd_set,同一个文件描述符也能在多个文件描述符中。
参数rdset,wrset,exset不仅是用来输入的,还是用来输出,它们是输入输出型参数,我们创建好fd_set变量传进去,意思就是让select好好监视我指定的文件描述符的状态变化,当函数发现有文件描述符就绪时,就会检查当前监视的文件描述符有哪些就绪了,根据这个修改传进来的参数,因为是指针,可以达到输出型参数的效果,将就绪的文件描述符对应的位置置为1,未就绪的置为0,然后返回,这样我们就能根据输出型参数知道那些文件描述符就绪了。如果超时返回,也就是指定等待时间内没有文件描述符就绪,那么对用的fd_set就会置为全0。
timeout是内核定义的数据结构,源代码如下
c
struct timeval {
time_t tv_sec; /* seconds */
suseconds_t tv_usec; /* microseconds */
};一个是秒,一个是微秒,两者相加就是实际select函数等待的时间。当给这个参数传NULL时,则表示select()没有timeout,select将一直被阻塞,直到某个文件描述符上发生了事件;当传0时,则仅检测描述符集合的状态,然后立即返回,并不等待外部事件的发生,搭配循环可以达到类似非阻塞轮询的效果,不过一般不会这样用,对cpu资源消耗太大;当设置的是确定的值时,指定值的时间内没有事件发生就会超时返回。
timeout同样是一个输入输出型参数,我们传这个参数表示要求它等待的时间,当函数返回时,它会被修改成剩余的时间,也就是提前2秒返回那就是2秒,超时返回就是0秒。
select的返回值也很有讲究,返回-1表示函数执行失败,返回0表示指定的等待时间内没有一个被监视的文件描述符就绪,大于0表示有n个文件描述符就绪,这时我们只能遍历对应的fd_set参数找到哪些文件描述符就绪了。
由于select函数中大量涉及fd_set变量的设置,fd_set本身可以理解为位图,但是不同环境下的实现方式可能还是有些不同,所以系统贴心地为我们提供了相关的宏函数:
c
void FD_CLR(int fd, fd_set *set); // 清除描述词组set中相关fd 的位
int FD_ISSET(int fd, fd_set *set); // 测试描述词组set中相关fd 的位是否为真
void FD_SET(int fd, fd_set *set); // 设置描述词组set中相关fd的位
void FD_ZERO(fd_set *set); // 清除描述词组set的全部位接下来我们可以用select写一个简易的单线程tcp服务程序。
socket.hpp
cpp
#include<iostream>
#include<string>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include<unistd.h>
#include<string.h>
// std::string defaultip = "127.0.0.1";
// int16_t defaultport = 8080;
enum
{
SOCKETERR = 1,
LISTENERR,
BINDERR,
ACCEPTERR,
CONNECTERR
};
class sock
{
public:
sock()
{
}
void my_socket()
{
_sockfd = socket(AF_INET, SOCK_STREAM, 0);
if(_sockfd < 0)
{
perror("socket");
exit(SOCKETERR);
}
int opt = 1;
setsockopt(_sockfd, SOL_SOCKET, SO_REUSEADDR|SO_REUSEPORT, &opt, sizeof(opt)); // 防止偶发性的服务器无法进行立即重启(tcp协议的时候再说)
}
void my_bind(const std::string& ip, int16_t port)
{
sockaddr_in cli_in;
memset((void*)&cli_in, 0, sizeof(cli_in));
cli_in.sin_addr.s_addr = inet_addr(ip.c_str());
cli_in.sin_family = AF_INET;
cli_in.sin_port = htons(port);
int ret = bind(_sockfd, (const sockaddr*)&cli_in, sizeof(cli_in));
if(ret < 0)
{
perror("bind");
exit(BINDERR);
}
}
void my_listen()
{
int ret = listen(_sockfd, 5);
if(ret < 0)
{
perror("listen");
exit(LISTENERR);
}
}
int my_accept(std::string& clientip, int16_t& clientport)
{
sockaddr_in get;
memset((void*)&get, 0, sizeof(get));
socklen_t glen = sizeof(get);
int ret = accept(_sockfd, (sockaddr*)&get, &glen);
if(ret < 0)
{
perror("accept");
return -1;
}
char ipstr[64] = {0};
clientip = inet_ntop(AF_INET, (const sockaddr*)&get.sin_addr, ipstr, sizeof(ipstr));
clientip = ipstr;
clientport = get.sin_port;
return ret;
}
bool my_connect(const std::string& ip, const int16_t& port)
{
sockaddr_in ser_in;
memset((void*)&ser_in, 0, sizeof(ser_in));
ser_in.sin_addr.s_addr = inet_addr(ip.c_str());
ser_in.sin_family = AF_INET;
ser_in.sin_port = htons(port);
int ret = connect(_sockfd, (const sockaddr*)&ser_in, sizeof(ser_in));
if(ret < 0)
{
perror("accept");
return false;
}
return true;
}
~sock()
{
}
void my_close()
{
close(_sockfd);
}
int get_sockfd()
{
return _sockfd;
}
private:
int _sockfd;
};
cpp
#include"socket.hpp"
#include<fcntl.h>
#include<sys/select.h>
class selectserver
{
public:
selectserver()
{
FD_ZERO(&_fs);
}
void init()
{
_sk.my_socket();
_sk.my_bind("0.0.0.0", 8080);
_sk.my_listen();
FD_SET(_sk.get_sockfd(), &_fs);
_max_fd = _sk.get_sockfd();
}
void event_hander(const fd_set& fs)
{
char buffer[1024] = {0};
for(int i = 0; i <= _max_fd; ++i)
{
if(FD_ISSET(i, &fs))
{
if(i == _sk.get_sockfd())
{
std::cout << "get a new accept" << std::endl;
std::string clientip;
int16_t port = 0;
int acc_fd = _sk.my_accept(clientip, port); // accept时,时间已经就绪,不用等待啦
if(acc_fd >= sizeof(fd_set) * 8)
{
std::cout << "out of the range of select, can not accept" << std::endl;
close(acc_fd);
}
else
{
FD_SET(acc_fd, &_fs);
_max_fd = std::max(_max_fd, acc_fd);
}
}
else
{
ssize_t n = read(i, buffer, sizeof(buffer)); // 读的时候,时间已经就绪,不用等待啦
if(n < 0)
{
perror("read");
return;
}
else if(n == 0)
{
std::cout << "fd " << i << " is closed, close it and back." << std::endl;
close(i);
FD_CLR(i, &_fs);
return;
}
else
{
buffer[n] = 0;
std::cout << buffer;
write(i, buffer, n);
}
}
}
}
}
void start()
{
while(1)
{
// fd_set cy_fs = _fs; // 可以但不推荐,可能有些平台出错
fd_set cy_fs; // 因为是输入输出型参数,所以不能反复使用,每一个循环创建一个
FD_ZERO(&cy_fs);
for(int i = 0; i < sizeof(fd_set) * 8; ++i)
if(FD_ISSET(i, &_fs))
FD_SET(i, &cy_fs);
timeval otime; // 因为是输入输出型参数,所以不能反复使用,每一个循环创建一个
otime.tv_sec = 0;
otime.tv_usec = 5;
int n = select(_max_fd + 1, &cy_fs, nullptr, nullptr, nullptr);
if(n < 0)
{
perror("select");
return;
}
else if(n == 0)
{
std::cout << "time out" << std::endl;
}
else
{
event_hander(cy_fs);
}
}
}
private:
sock _sk;
fd_set _fs;
int _max_fd;
};
select的缺点如下:
1.等待的fd是有上限的,接口依赖fd_set变量,fd_set变量大小普遍为,这决定了select最多能监视1024个文件描述符。
2.输入输出型参数比较多,在用户态和内核态之间切换需要频繁的拷贝fd_set。
3.每次调用都要重新设置fd_set,因为之前传进去的已经被修改了。
4.用户层设置fd_set、处理就绪的fd时都需要频繁的遍历,内核也需要不断遍历监视,从要传最大fd就能看出,这是在传边界值方便遍历。两边都在遍历,要监视的fd一多,效率也会随之下降,当然多路转接监视的fd变多IO效率也会提升,所以这两者最终会有一个转折点。
现在select只用于一些嵌入式设备、轻量级IO的场景。
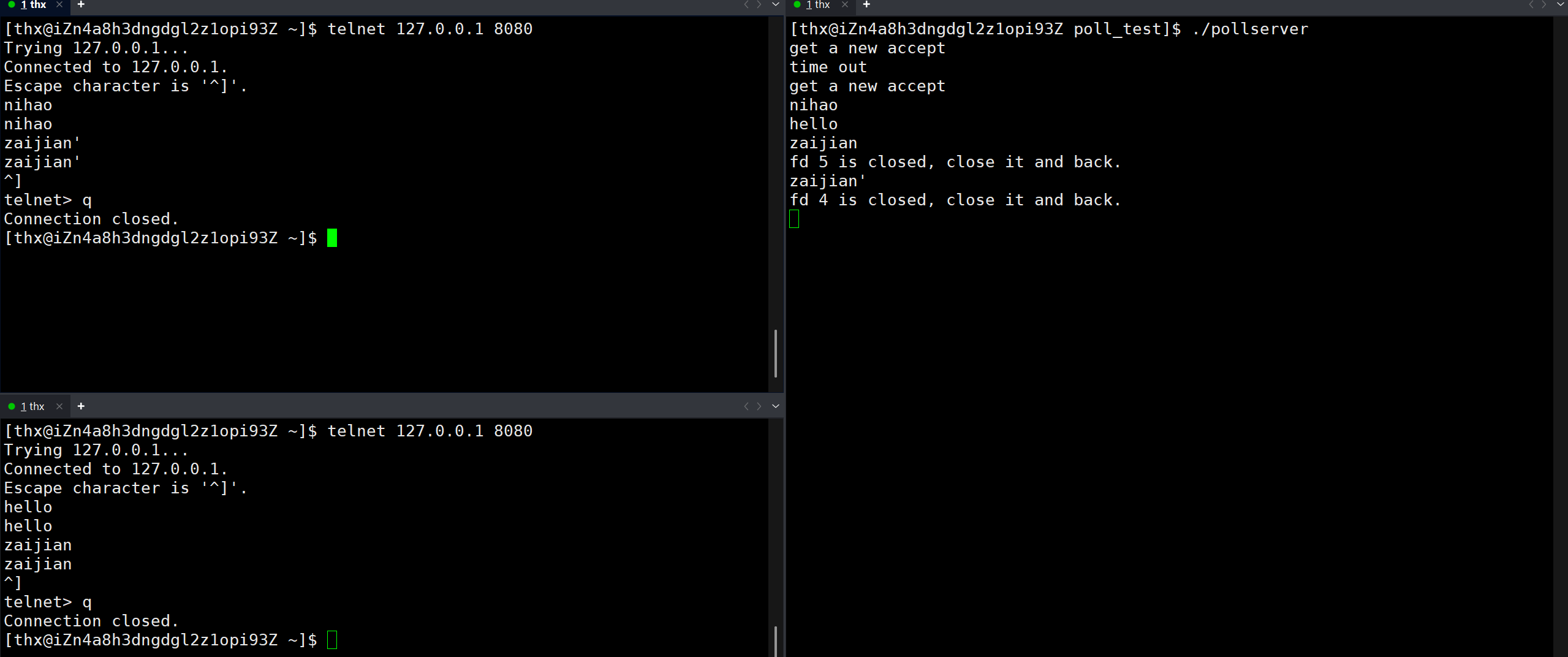
poll
poll是在select之后推出的函数,因为select存在诸多问题,poll针对其缺点做了改进。
和select一样,poll可以监视多个文件描述符,程序会停在select这里等待,直到被监视的文件描述符有一个或多个发生了状态改变。
c
int poll(struct pollfd *fds, nfds_t nfds, int timeout);参数fds是一个指向 struct pollfd结构体数组的首指针。每个结构体对应一个你想要监视的文件描述符,是 poll操作的核心。nfds指定 fds数组中的元素个数,即要监视的文件描述符的总数。timout指定等待的毫秒数,这里和select不一样了,这里不再是输入输出型参数,-1 表示阻塞直到有事件;0 表示立即返回;正数表示最大等待时长。。
poll函数的核心无疑是struct pollfd结构体,这是一个内核定义的结构体,我们来看一下源码,
c
struct pollfd
{
int fd; /* file descriptor */
short events; /* requested events */
short revents; /* returned events */
};fd就是我们想让poll监视的文件描述符。events是我们想让poll监视的事件,其本身是一个short类型,short类型有16bit,这里同样是一个bit对应一个事件,是位图的形式,下面是poll函数可以监视的事件,这些事件对应的英文就是一个个宏,我们可以直接使用这些宏来设置我们想要poll监视的事件。
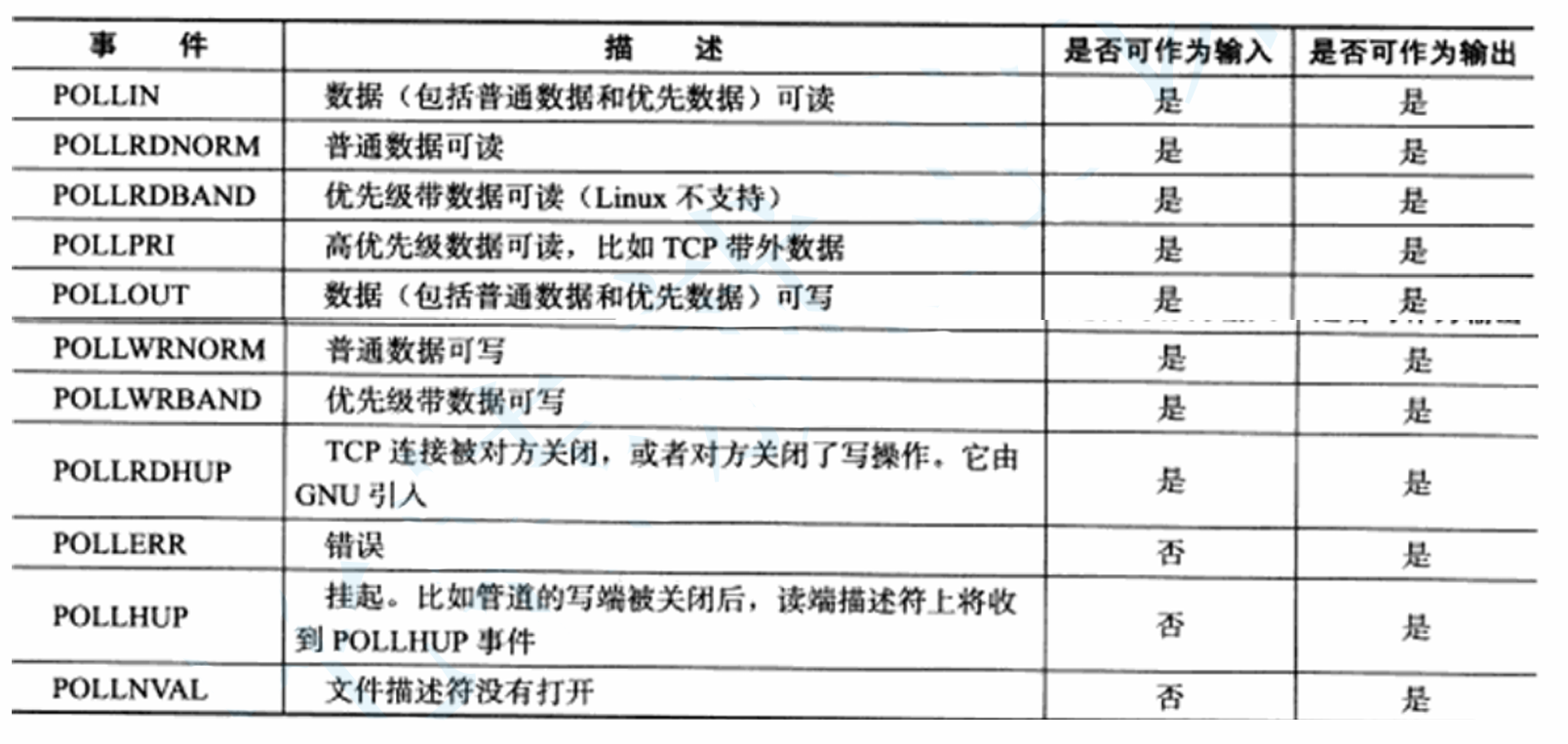
revents则是poll函数返回时在对应fd上设置的,他表示该fd的指定事件已就绪,是一个输出型的变量。将传入用来指定函数监视的事件和返回表明已经就绪的时间分开,这样就不会像select一样覆盖原有的参数导致不能重复使用的问题,我们定义的数组可以一直用。
由于poll函数不再依赖fd_set,所以它没有长度限制了,也没有范围限制了,我们可以定义一个静态数组,也可以定义一个动态的,往数组中添加想监视的fd,传入,就行了。可以看到相比于select,poll人性化了许多,接口的发展就是如此,都是往简单高效的方向发展。
poll的返回值和select类似。小于0表示函数调用失败,用errno查看错误原因。等于0表示超时。大于0有n个fd有对应的事件发生。
这样我们就能在原来select的基础上将其改成poll,两者用法有差异,但是整体代码逻辑框架不变
cpp
#include"socket.hpp"
#include<fcntl.h>
#include<poll.h>
#include<sys/select.h>
int defaultfd = -1;
short defaultevent = 0;
class pollserver
{
public:
pollserver()
{
for(int i = 0; i < POLL_SIZE; ++i)
{
_pf_arr[i].fd = defaultfd;
_pf_arr[i].events = defaultevent;
_pf_arr[i].revents = defaultevent;
}
_pa_size = 0;
}
void init()
{
_sk.my_socket();
_sk.my_bind("0.0.0.0", 8080);
_sk.my_listen();
_pf_arr[_pa_size].fd = _sk.get_sockfd();
_pf_arr[_pa_size].events = POLLIN;
++_pa_size;
}
void event_hander()
{
char buffer[1024] = {0};
for(int i = 0; i <= _pa_size; ++i)
{
if(_pf_arr[i].revents == POLLIN)
{
if(_pf_arr[i].fd == _sk.get_sockfd())
{
std::cout << "get a new accept" << std::endl;
std::string clientip;
int16_t port = 0;
int acc_fd = _sk.my_accept(clientip, port); // accept时,事件已经就绪,不用等待啦
if(_pa_size >= POLL_SIZE) // 这里设置的静态数组,所以有容量,可以设置成动态的这样就不会有容量了,可以一直添加
{
std::cout << "out of the range of poll, can not accept" << std::endl;
close(acc_fd);
}
else // 可以遍历找失效的pollfd结构体,这里图省事就没有搞
{
_pf_arr[_pa_size].fd = acc_fd;
_pf_arr[1=_pa_size].events = POLLIN;
++_pa_size;
}
}
else
{
ssize_t n = read(_pf_arr[i].fd, buffer, sizeof(buffer)); // 读的时候,事件已经就绪,不用等待啦
if(n < 0)
{
perror("read");
return;
}
else if(n == 0)
{
std::cout << "fd " << _pf_arr[i].fd << " is closed, close it and back." << std::endl;
close(_pf_arr[i].fd);
_pf_arr[i].fd = defaultfd; // fd为负数poll会直接忽略,相当于移除了,因为直接挪动成本太高
return;
}
else
{
buffer[n] = 0;
std::cout << buffer;
write(_pf_arr[i].fd, buffer, n);
}
}
}
}
}
void start()
{
while(1)
{
int n = poll(_pf_arr, POLL_SIZE, 5000);
if(n < 0)
{
perror("poll");
return;
}
else if(n == 0)
{
std::cout << "time out" << std::endl;
}
else
{
event_hander();
}
}
}
private:
sock _sk;
static const int POLL_SIZE = 4096;
struct pollfd _pf_arr[POLL_SIZE];
int _pa_size = 0;
};
poll解决了select的诸多问题,poll没有文件描述符数目范围限制了,poll输入输出变量分离,调用前不再需要重置。这些都让poll相较于select使用起来更加便捷,但是对于用户态内核态的拷贝仍没有解决,用户层和内核层的循环遍历也没有解决,性能瓶颈问题没有得到解决,所以还需要更强大的多路转接方案。
poll的使用场景和select类似,相较于select,它更现代,所以很多使用select的场景其实使用poll更推荐。
epoll
epoll是poll的升级版,但是两者之间可以说是天壤之别。epoll 是现在Linux系统中实现高性能网络服务的核心机制之一,特别擅长处理海量并发连接。
在 epoll 出现之前,网络服务器主要使用 select或 poll来处理多个连接。但它们在高并发场景下存在明显瓶颈:当需要监控成千上万个连接时,每次调用都需要将整个要监控的文件描述符集合传递给内核,内核需要遍历所有描述符以检查其状态,用户进程在收到返回后还需再次遍历整个集合来找出真正活跃的连接。这种线性扫描的方式在连接数很大时,CPU时间会大量消耗在无效的遍历上。
epoll 的设计正是为了高效解决这些问题,其核心思想是 "事件驱动" :当某个被监控的连接有事件发生(如数据到达)时,内核才通知应用程序,从而避免了盲目的轮询。
我们先来认识接口:
c
int epoll_create(int size);这个函数用来创建一个 epoll 实例,参数在现代Linux中已被废弃,它原本用于告知内核调用者预期会向这个 epoll 实例添加的文件描述符的大致数量,内核利用这个信息来预先分配内部数据结构的空间,以期在后续操作中减少动态内存分配的开销,从而优化性能。如果实际添加的文件描述符数量超过了这个初始提示,内核仍然会动态分配更多空间,但可能效率会稍低一些。随着 Linux 内核的持续发展(大约从 Linux 2.6.8 版本开始),内核已经能够非常智能地动态调整和管理这些内部数据结构所需的空间,不再需要开发者预先给出提示。因此,size参数就失去了其最初的设计意义。在现在我们只要给一个大于0的数就行了。
函数执行成功后返回一个代表新创建的 epoll 实例的文件描述符。这个描述符本身也是一个文件描述符,在使用完毕后必须通过close()关闭,以避免资源泄露。失败的话返回-1,可以通过errno查看错误原因。
c
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);这个函数负责动态配置你需要监控的文件描述符和事件。参数epfd就是epoll_create返回的文件描述符,参数op表示我们要进行的操作,取值有三种:
EPOLL_CTL_ADD :注册新的fd到epfd中;
EPOLL_CTL_MOD :修改已经注册的fd的监听事件;
EPOLL_CTL_DEL :从epfd中删除一个fd;
参数fd表示要想要进行操作的文件藐视符。参数event是 详细的事件配置,告诉 epoll 你关心这个 fd 上的什么事件(如可读、可写)。struct epoll_event同样是内核定义的一个数据结构,源码如下:
c
typedef union epoll_data {
void *ptr;
int fd;
uint32_t u32;
uint64_t u64;
} epoll_data_t;
struct epoll_event {
uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};events可以是以下几个宏的集合:
EPOLLIN : 表示对应的文件描述符可以读 (包括对端SOCKET正常关闭);
EPOLLOUT : 表示对应的文件描述符可以写;
EPOLLPRI : 表示对应的文件描述符有紧急的数据可读 (这里应该表示有带外数据到来);
EPOLLERR : 表示对应的文件描述符发生错误;
EPOLLHUP : 表示对应的文件描述符被挂断;
EPOLLET : 将EPOLL设为边缘触发(Edge Triggered)模式,这是相对于水平触发(Level Triggered)来说的.
EPOLLONESHOT:只监听一次事件, 当监听完这次事件之后, 如果还需要继续监听这个socket的话, 需要
再次把这个socket加入到EPOLL队列里.
对于data,他是一个联合体,可以存多种类型的数据,它的主要作用是让你在注册事件监听时,能够关联一些自定义的上下文信息。当这个事件随后被 epoll_wait触发时,内核会原封不动地将这个数据返还给你。这样你就能立刻知道这个事件是关于谁的、该如何处理,而无需再进行耗时的查找操作。
c
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);这个函数用于高效地等待多个文件描述符上的 I/O 事件。参数epfd传epoll_create函数返回的文件描述符。参数epoll_event是一个struct epoll_event数组的数组指针,这个数组由我们创建传入,函数返回时会将就绪的事件写进这个数组中。maxevents,期望获取的最大事件数,必须大于 0,且不能超过 events数组的大小。timeout,超时时间,毫秒为单位,-1 表示阻塞直到有事件,0 表示立即返回,正数表示最大等待时长。函数返回正数表示已经被写入events数组中的就绪时间的数量,等于0表示超时,小于0表示错误。当有时间就绪时,函数会立刻返回,数组中会被写入就绪的事件,写入的时间数量不会超过maxevents,timeout耗尽都没有一个事件就绪就会超时返回。
epoll的原理
epoll的实现原理非常值得研究,首先我们应该要知道,epoll解决了select和poll的效率问题。之前我们也说过,select和poll的效率问题有如下几条:
1.输入输出型参数比较多,在用户态和内核态之间切换需要频繁的拷贝fd_set。
2.用户层设置fd_set、处理就绪的fd时都需要频繁的遍历,内核也需要不断遍历监视,从要传最大fd就能看出,这是在传边界值方便遍历。两边都在遍历,要监视的fd一多,效率也会随之下降,当然多路转接监视的fd变多IO效率也会提升,所以这两者最终会有一个转折点。
操作系统是一款管理软件,系统运行时,会有各种进程需要各种硬件资源,如果硬件资源没有就绪就会被挂起到等待队列等待硬件资源就绪,那么硬件资源就绪时操作系统要怎么知道呢?最先想到的肯定是轮询,但是这样很浪费资源,实际硬件资源就绪时会通过硬件中断来通知cpu,这样cpu通过硬件中断请求和中断向量表就能找到对应的方法执行,从而正确处理硬件资源。这个场景看着很眼熟,因为我们在等待IO事件时也是一直轮询的,select和poll就是这么做的,也因为这么做导致了效率问题,所以该怎么办呢?当然是仿照硬件中断的思路啦,也就是IO事件的就绪与否不应该一直由我轮询,而是自己好了就调用对应的方法自己进行处理。
具体来说,我们的系统会为每一个epoll维护一个红黑树和一个就序链表,红黑树中的一个个节点就是该epoll实例要监视的文件描述符,一个个结点对应一个个结构体,结构体中有要监视的文件描述符,对应的事件等等。当底层硬件准备就绪比如网卡收到数据了,就会触发硬件中断,将数据向上交付,当交付到socket的接收缓冲区后,会调用socket中注册的一个回调函数,该回调函数会执行的操作是在红黑树中进行查找,找到对应的节点后检查当前的状态和该节点中设置的要该epoll关心的状态是否匹配,如果匹配,就会将该节点链入到就绪链表中(无需拷贝哦,一个节点可以在多个数据结构中存在),这时就绪链表上就有就绪的时间了,如果这时有先前调用epoll_wait因为那时就绪队列没有就绪事件而挂起阻塞的进程的话,就会将其唤醒,这时用户的epoll_wait函数因为链表有事件,就会将链表中的事件一个个拷贝到传进函数的数组中,按照给定的最大尺寸,如果没达到就是把链表拷完了,这时链表也会清空,如果烤满了还有余,那么就只会清除拷走的部分,这样用户就拿到了装满就绪事件的数组了。
看完整个过程,可以说,epoll的设计极为优秀。首先,用户不再需要自己维护数组装填要监视的事件往返于内核和用户之间不断拷贝了,内核维护的红黑树替代了它,而且这块内存是基于mmap的共享内存,双方都能访问,整个过程只有epoll_wait中的输出型数组返回时需要将就绪的事件拷贝一下,频繁拷贝的问题解决了。对于用户和内核遍历的问题,首先是内核,通过提前注册回调函数解决了轮询问题,用户层因为epoll_wait返回的就是纯纯的装满就绪事件的数组,所以也不需要遍历了,遍历的问题解决了。
当我们调用epoll_create时,会进行红黑树和就绪链表的初始化,它们两又会被一个结构体包含,最终被包含进struct file,获得一个文件描述符,这就是为什么后续我们在调用epoll的其他函数必须得有它。
当我们调用epoll_ctl时,就是对红黑树进行增删查改,同时还会在socket在内核的数据结构中注册对应的回调函数。
当我们调用epoll_wait时,就是在就绪链表拿数据,这就是为什么要传数组进去。而且返回值在这时也有了作用,之前的select和poll因为数组不全是就绪时间,所以确实返回了就绪时间的个数,也没什么用,该遍历还是得遍历,这里就不一样了,我数组里全是就绪事件,n就大有用处了。
epoll虽说是poll的升级版,但两者之间可谓天壤之别,对于select和poll操作系统并没有为这两个函数做什么大刀阔斧的改动,而epoll则真的为他设计了一系列机制,内核数据结构,epoll的使用明显更现代,效率更高,是我们高性能网络服务的核心机制之一。接口的进步总是如此,一开始只是简单实现一下满足当下的需求,随着时代进步,需求不断提高,接口就需要大刀阔斧的改变,就像进程通信,一开始只是基于文件的管道,后面才有了共享内存,消息队列等。
说了那么多,我们来简单用epoll写一段代码,
socket.hpp
cpp
#include<iostream>
#include<string>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include<unistd.h>
#include<string.h>
// std::string defaultip = "127.0.0.1";
// int16_t defaultport = 8080;
enum
{
SOCKETERR = 1,
LISTENERR,
BINDERR,
ACCEPTERR,
CONNECTERR
};
class sock
{
public:
sock()
{
}
void my_socket()
{
_sockfd = socket(AF_INET, SOCK_STREAM, 0);
if(_sockfd < 0)
{
perror("socket");
exit(SOCKETERR);
}
int opt = 1;
setsockopt(_sockfd, SOL_SOCKET, SO_REUSEADDR|SO_REUSEPORT, &opt, sizeof(opt)); // 防止偶发性的服务器无法进行立即重启(tcp协议的时候再说)
}
void my_bind(const std::string& ip, int16_t port)
{
sockaddr_in cli_in;
memset((void*)&cli_in, 0, sizeof(cli_in));
cli_in.sin_addr.s_addr = inet_addr(ip.c_str());
cli_in.sin_family = AF_INET;
cli_in.sin_port = htons(port);
int ret = bind(_sockfd, (const sockaddr*)&cli_in, sizeof(cli_in));
if(ret < 0)
{
perror("bind");
exit(BINDERR);
}
}
void my_listen()
{
int ret = listen(_sockfd, 5);
if(ret < 0)
{
perror("listen");
exit(LISTENERR);
}
}
int my_accept(std::string& clientip, int16_t& clientport)
{
sockaddr_in get;
memset((void*)&get, 0, sizeof(get));
socklen_t glen = sizeof(get);
int ret = accept(_sockfd, (sockaddr*)&get, &glen);
if(ret < 0)
{
perror("accept");
return -1;
}
char ipstr[64] = {0};
clientip = inet_ntop(AF_INET, (const sockaddr*)&get.sin_addr, ipstr, sizeof(ipstr));
clientip = ipstr;
clientport = get.sin_port;
return ret;
}
bool my_connect(const std::string& ip, const int16_t& port)
{
sockaddr_in ser_in;
memset((void*)&ser_in, 0, sizeof(ser_in));
ser_in.sin_addr.s_addr = inet_addr(ip.c_str());
ser_in.sin_family = AF_INET;
ser_in.sin_port = htons(port);
int ret = connect(_sockfd, (const sockaddr*)&ser_in, sizeof(ser_in));
if(ret < 0)
{
perror("accept");
return false;
}
return true;
}
~sock()
{
}
void my_close()
{
close(_sockfd);
}
int get_sockfd()
{
return _sockfd;
}
private:
int _sockfd;
};Epoller.hpp
cpp
#include<sys/epoll.h>
#include<iostream>
struct nocopy
{
nocopy(){}
nocopy(nocopy& n) = delete;
const nocopy& operator=(const nocopy& n) = delete;
};
class Epoller : public nocopy
{
public:
Epoller()
{
_ep_fd = epoll_create(128);
if(_ep_fd < 0)
{
perror("epoll_create");
}
}
int Epoller_wait(epoll_event* e_arr, int max_e_arr)
{
return epoll_wait(_ep_fd, e_arr, max_e_arr, 3000);
}
int Epoller_Update(int fd, int op, uint32_t event)
{
int n;
if(op == EPOLL_CTL_DEL)
{
n = epoll_ctl(_ep_fd, op, fd, nullptr);
if(n < 0)
{
perror("epoll_ctl");
}
}
else
{
epoll_event ee;
ee.events = event;
ee.data.fd = fd;
n = epoll_ctl(_ep_fd, op, fd, &ee);
if(n < 0)
{
perror("epoll_ctl");
}
}
return n;
}
~Epoller()
{
if(_ep_fd >= 0) close(_ep_fd);
}
private:
int _ep_fd;
};epoller_server.hpp
cpp
#include"socket.hpp"
#include"Epoller.hpp"
#include<sys/epoll.h>
class epollserver
{
public:
epollserver()
{
}
void init()
{
_sk.my_socket();
_sk.my_bind("0.0.0.0", 8080);
_sk.my_listen();
_ep.Epoller_Update(_sk.get_sockfd(), EPOLL_CTL_ADD, EPOLLIN);
}
void event_handler(struct epoll_event* ee_arr_ptr, int r_num)
{
for(int i = 0; i < r_num; ++i)
{
if(ee_arr_ptr[i].events & EPOLLIN)
{
if(ee_arr_ptr[i].data.fd == _sk.get_sockfd())
{
std::cout << "get a new accept" << std::endl;
std::string clientip;
int16_t clientport = 0;
int ret_ap_fd = _sk.my_accept(clientip, clientport);
if(ret_ap_fd < 0)
{
perror("my_accept");
}
else
{
_ep.Epoller_Update(ret_ap_fd, EPOLL_CTL_ADD, EPOLLIN);
}
}
else
{
char buffer[1024] = {0};
ssize_t n = read(ee_arr_ptr[i].data.fd, buffer, sizeof(buffer));
if(n < 0)
{
perror("read");
}
else if(n == 0)
{
std::cout << "fd " << ee_arr_ptr[i].data.fd << " is closed, close it and back." << std::endl;
_ep.Epoller_Update(ee_arr_ptr[i].data.fd, EPOLL_CTL_DEL, 0);
close(ee_arr_ptr[i].data.fd); // 先删除再close,防止报错
}
else
{
write(ee_arr_ptr[i].data.fd, buffer, n);
}
}
}
}
}
void start()
{
struct epoll_event ee_arr[1024] = {0};
while(1)
{
int n = _ep.Epoller_wait(ee_arr, sizeof(ee_arr));
if(n < 0)
{
perror("Epoller_wait");
}
else if(n == 0)
{
std::cout << "time out" << std::endl;
}
else
{
event_handler(ee_arr, n);
}
sleep(1);
}
}
private:
sock _sk;
Epoller _ep;
};main.cpp
cpp
#include"epoll_server.hpp"
int main()
{
epollserver es;
es.init();
es.start();
return 0;
}上述的代码是一个最简单的tcp服务器,没有上层业务,所以只是最简单的收到数据直接返回,而且这里的数据量并没有很大,所以序列化反序列化以及tcp粘包我呢提都没有解决,说到底是不太好的,之前的select和poll也是如此,但是这里只是简单演示,还是往简单的写比较好。
epoll的工作方式
epoll的工作方式分为两种:水平触发(LT)和边缘触发(ET)。
水平触发是只要文件描述符(fd)处于就绪状态(如读缓冲区有数据),就会持续通知。边缘触发是仅在 fd 的状态发生变化时(如读缓冲区从空变为非空,或者从有到多等等)通知一次。
打个比方就是:
水平触发 (LT):像一个耐心的提醒者。只要事情没做完(比如读缓冲区还有数据),它就会一直提醒你:"你没读完,我继续提醒你。"
边缘触发 (ET):像一个高效的信号兵。他只在你关注的情况发生变化的那一刻(比如读缓冲区从空变为非空)发一次信号:"情况变了,我只说一次,剩下的你自己处理。" 后续如何处理是你的事。
select和poll只有LT的工作模式,没有也无法实现ET的工作模式。因为select和poll的API设计和内核实现是"无状态"的,函数只会监视用户传进来的要求它去关注的fd,然后去轮询,它只能在轮询到这个fd时查看它的事件是否就绪,并不能知道是不是刚变为就绪的。而epoll时自己维护的红黑树,自己注册的回调函数,当底层事件就绪时,就会出发回调,内核就能得知这个fd对应的资源就绪了,也就是发生了变化,所以它能只返回发生状态变化的fd。
LT和ET模式谁更好呢?诚然,LT模式用着更舒心,因为你没读完下次它还接着通知你,但是,我们无法否认,ET的通知模式更高效。当我们使用ET模式时,如果我们不一次性将数据处理完,epoll就得在下一次资源状态发生变化时再通知我们了,我们写一个可靠的程序不能等待一个未知的事件,所以这倒逼程序员必须一次性把数据全部处理完,一次性处理完就意味着可以腾出更大的缓冲区,这在tcp中意味着更大的窗口,更大的窗口意味着更大的数据吞吐量,更大的数据吞吐量意味着更高效,所以这就是ET的优势。当然如果我们使用LT也能在每一次通知时间就绪时就将数据处理完,达到的效果是和ET一样的,当时这要求我们有更高的自觉。
当我们使用ET模式时,我们就得一次性将数据读完,但是我们不知道缓冲区数据的大小,所以我们不能只靠一次read就将数据全部读取完,一是因为不知道数据大下,所以用户层缓冲区不知道设多大,不好一次读完,再者就是read函数可能会被信号打断,所以可能出现read函数调用失败的情况,调用失败了ET模式又不会通知第二次,这些数据在下次fd状态发生变化前就一直留在缓冲区了。所以该怎么办呢?很简单,将ET模式下监视的fd设置成非阻塞就行了。
使用epoll_ctl函数可以设置event参数中的events事件为EPOLLET(还要按位与上其他事件),fcntl可以设置fd非阻塞,之前讲过。
Reactor
Reactor 模式,又称"反应器模式",是一种事件驱动的设计模式,用于处理多个并发输入的服务请求。它的核心思想是:
"当某个事件发生时,通知你,然后你来处理它。"
而不是:
"你不断地去询问每个对象,看它有没有事需要你处理。"
第一种是 Reactor(事件驱动),第二种是 主动轮询。Reactor 模式的效率远高于后者。我们使用epoll的ET模式来简单实现一下Reactor。
commen.hpp
cpp
#include <unistd.h>
#include <fcntl.h>
#include<iostream>
void SetNoBlock(int fd)
{
int fl = fcntl(fd, F_GETFD);
if(fl < 0)
{
perror("fcntl");
return;
}
fcntl(fd, F_SETFL, fl | O_NONBLOCK);
}nocopy.hpp
cpp
struct nocopy
{
nocopy(){}
nocopy(nocopy& n) = delete;
const nocopy& operator=(const nocopy& n) = delete;
};Epoller.hpp
cpp
#include<sys/epoll.h>
#include<iostream>
#include<unistd.h>
#include"nocopy.hpp"
class Epoller : public nocopy
{
public:
Epoller()
{
_ep_fd = epoll_create(128);
if(_ep_fd < 0)
{
perror("epoll_create");
}
}
int Epoller_wait(epoll_event* e_arr, int max_e_arr)
{
return epoll_wait(_ep_fd, e_arr, max_e_arr, 3000);
}
int Epoller_Update(int fd, int op, uint32_t event)
{
int n;
if(op == EPOLL_CTL_DEL)
{
n = epoll_ctl(_ep_fd, op, fd, nullptr);
if(n < 0)
{
perror("epoll_ctl");
}
}
else
{
epoll_event ee;
ee.events = event;
ee.data.fd = fd;
n = epoll_ctl(_ep_fd, op, fd, &ee);
if(n < 0)
{
perror("epoll_ctl");
}
}
return n;
}
~Epoller()
{
if(_ep_fd >= 0) close(_ep_fd);
}
private:
int _ep_fd;
};socket.hpp
cpp
#include<iostream>
#include<string>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include<unistd.h>
#include<string.h>
// std::string defaultip = "127.0.0.1";
// int16_t defaultport = 8080;
enum
{
SOCKETERR = 1,
LISTENERR,
BINDERR,
ACCEPTERR,
CONNECTERR
};
class sock
{
public:
sock()
{
}
void my_socket()
{
_sockfd = socket(AF_INET, SOCK_STREAM, 0);
if(_sockfd < 0)
{
perror("socket");
exit(SOCKETERR);
}
int opt = 1;
setsockopt(_sockfd, SOL_SOCKET, SO_REUSEADDR|SO_REUSEPORT, &opt, sizeof(opt)); // 防止偶发性的服务器无法进行立即重启(tcp协议的时候再说)
}
void my_bind(const std::string& ip, int16_t port)
{
sockaddr_in cli_in;
memset((void*)&cli_in, 0, sizeof(cli_in));
cli_in.sin_addr.s_addr = inet_addr(ip.c_str());
cli_in.sin_family = AF_INET;
cli_in.sin_port = htons(port);
int ret = bind(_sockfd, (const sockaddr*)&cli_in, sizeof(cli_in));
if(ret < 0)
{
perror("bind");
exit(BINDERR);
}
}
void my_listen()
{
int ret = listen(_sockfd, 5);
if(ret < 0)
{
perror("listen");
exit(LISTENERR);
}
}
int my_accept(std::string& clientip, int16_t& clientport)
{
sockaddr_in get;
memset((void*)&get, 0, sizeof(get));
socklen_t glen = sizeof(get);
int ret = accept(_sockfd, (sockaddr*)&get, &glen);
if(ret < 0)
{
perror("accept");
return -1;
}
char ipstr[64] = {0};
clientip = inet_ntop(AF_INET, (const sockaddr*)&get.sin_addr, ipstr, sizeof(ipstr));
clientip = ipstr;
clientport = get.sin_port;
return ret;
}
bool my_connect(const std::string& ip, const int16_t& port)
{
sockaddr_in ser_in;
memset((void*)&ser_in, 0, sizeof(ser_in));
ser_in.sin_addr.s_addr = inet_addr(ip.c_str());
ser_in.sin_family = AF_INET;
ser_in.sin_port = htons(port);
int ret = connect(_sockfd, (const sockaddr*)&ser_in, sizeof(ser_in));
if(ret < 0)
{
perror("accept");
return false;
}
return true;
}
~sock()
{
}
void my_close()
{
close(_sockfd);
}
int get_sockfd()
{
return _sockfd;
}
private:
int _sockfd;
};protocol.hpp
cpp
#include<iostream>
#include<jsoncpp/json/json.h>
#define Separator_Spa ' '
#define Separator_Pro '\n'
std::string encode(std::string msg)
{
std::string ret = std::to_string(msg.size());
ret += Separator_Pro;
ret += msg;
ret += Separator_Pro;
return ret;
}
bool decode(std::string& msg, std::string& content)
{
size_t pos = msg.find(Separator_Pro);
if(pos == std::string::npos) return false;
std::string szstr = msg.substr(0, pos);
size_t sz = std::stoi(szstr);
size_t totalsz = sz + szstr.size() + 2;
if(totalsz < msg.size()) return false;
content = msg.substr(pos + 1, sz);
msg.erase(0, totalsz);
return true;
}
class Request
{
public:
bool Serialization(std::string& message)
{
// message += std::to_string(_a);
// message += Separator_Spa;
// message += _op;
// message += Separator_Spa;
// message += std::to_string(_b);
// return true;
return Json_Serialization(message);
}
bool Json_Serialization(std::string& message)
{
Json::Value v;
v["a"] = _a;
v["op"] = _op;
v["b"] = _b;
Json::StyledWriter w;
message = w.write(v);
return true;
}
bool Deserialization(std::string& msg)
{
// size_t left = msg.find(Separator_Spa);
// if(left == std::string::npos) return false;
// _a = std::stoi(msg.substr(0, left));
// size_t right = msg.find(Separator_Spa, left + 1);
// if(right == std::string::npos) return false;
// _op = msg[left + 1];
// _b = std::stoi(msg.substr(right + 1));
// return true;
return Json_Deserialization(msg);
}
bool Json_Deserialization(std::string& msg)
{
Json::Value v;
Json::Reader r;
r.parse(msg, v);
_a = v["a"].asInt();
_b = v["b"].asInt();
_op = v["op"].asInt();
return true;
}
int _a;
int _b;
char _op;
};
class Response
{
public:
bool Serialization(std::string& message)
{
// message += std::to_string(_result);
// message += Separator_Spa;
// message += std::to_string(_status_code);
// return true;
return Json_Serialization(message);
}
bool Json_Serialization(std::string& message)
{
Json::Value v;
v["result"] = _result;
v["status_code"] = _status_code;
Json::StyledWriter w;
message = w.write(v);
return true;
}
bool Deserialization(std::string& msg)
{
// size_t mid = msg.find(Separator_Spa);
// if(mid == std::string::npos) return false;
// _result = std::stoi(msg.substr(0, mid));
// _status_code = std::stoi(msg.substr(mid + 1));
// return true;
return Json_Deserialization(msg);
}
bool Json_Deserialization(std::string& msg)
{
Json::Value v;
Json::Reader r;
r.parse(msg, v);
_result = v["result"].asInt();
_status_code = v["status_code"].asInt();
return true;
}
int _result = 0;
int _status_code = 0;
};servercal.hpp
cpp
#include <iostream>
#include "protocol.hpp"
enum
{
DIVERR = 1,
MODERR,
OPERR
};
class Calculator
{
public:
static Response Calculation(const Request& rq)
{
Response rp;
switch (rq._op)
{
case '+':
rp._result = rq._a + rq._b;
break;
case '-':
rp._result = rq._a - rq._b;
break;
case '*':
rp._result = rq._a * rq._b;
break;
case '/':
if (rq._a != 0) rp._result = rq._a / rq._b;
else rp._status_code = DIVERR;
break;
case '%':
if (rq._a != 0) rp._result = rq._a % rq._b;
else rp._status_code = MODERR;
break;
default:
rp._status_code = OPERR;
}
return rp;
}
static std::string server_cal(std::string& message)
{
std::string content;
bool back = decode(message, content);
if(!back) return "";
Request rq;
back = rq.Deserialization(content);
if(!back) return "";
Response rp = Calculation(rq);
std::string ret;
back = rp.Serialization(ret);
if(!back) return "";
ret = encode(ret);
return ret;
}
};tcpserver.hpp
cpp
#include"socket.hpp"
#include"Epoller.hpp"
#include"commen.hpp"
#include<unordered_map>
#include <functional>
#define EVENT_IN EPOLLIN|EPOLLET
#define EVENT_OUT EPOLLIN|EPOLLET
struct Connection;
class tcpserver;
typedef void(*func_t)(Connection*);
struct Connection
{
Connection(int fd, func_t recv, func_t send, func_t except, tcpserver* ts, const std::string& ip, uint16_t port):
_fd(fd),
_recv_cb(recv),
_send_cb(send),
_except_cb(except),
_ts(ts)
{
}
int _fd;
std::string _inbuffer; // string 二进制流,vector
std::string _outbuffer;
func_t _recv_cb;
func_t _send_cb;
func_t _except_cb;
tcpserver* _ts;
std::string _ip;
uint16_t _port;
};
class tcpserver
{
static const int num = 64;
public:
tcpserver(int port, func_t OnMessage):
_port(port),
_quit(true),
_OnMessage(OnMessage)
{
}
void init()
{
_sk.my_socket();
_sk.my_bind("0.0.0.0", _port);
_sk.my_listen();
AddConnection(_sk.get_sockfd(), EVENT_IN, Accepter, nullptr, nullptr, "0.0.0.0", 0);
SetNoBlock(_sk.get_sockfd());
// std::cout << _sk.get_sockfd() << std::endl;
}
void AddConnection(int fd, uint32_t event, func_t recv, func_t send, func_t except, const std::string ip, int16_t port)
{
Connection* newConnection = new Connection(fd, recv, send, except, this, ip, port);
_connections[fd] = newConnection;
_ep.Epoller_Update(fd, EPOLL_CTL_ADD, event);
}
void DelConnection(int fd)
{
delete _connections[fd];
_connections.erase(fd);
_ep.Epoller_Update(fd, EPOLL_CTL_DEL, 0);
}
void EventDispatcher(int timeout)
{
int n = _ep.Epoller_wait(revs, sizeof(revs));
if(n < 0)
{
perror("Epoller_wait");
exit(1);
}
for(int i = 0; i < n; ++i)
{
int fd = revs[i].data.fd;
uint32_t events = revs[i].events;
if(_connections.count(fd) != 0)
{
if (events & EPOLLERR) // 交给读写处理函数处理
events |= (EPOLLIN | EPOLLOUT);
if (events & EPOLLHUP)
events |= (EPOLLIN | EPOLLOUT);
if(events & EPOLLIN)
{
if(_connections[fd]->_recv_cb) _connections[fd]->_recv_cb(_connections[fd]);
}
else if(events & EPOLLOUT)
{
if(_connections[fd]->_send_cb) _connections[fd]->_send_cb(_connections[fd]);
}
}
}
}
static void Accepter(Connection* ct)
{
while(1)
{
sockaddr_in get;
memset((void*)&get, 0, sizeof(get));
socklen_t glen = sizeof(get);
// std::cout << 1 << std::endl;
int ac_fd = accept(ct->_fd, (sockaddr*)&get, &glen);
// std::cout << 2 << std::endl;
if(ac_fd > 0)
{
std::cout << "get a new accept" << std::endl;
char ipstr[64] = {0};
std::string ip = inet_ntop(AF_INET, (const sockaddr*)&get.sin_addr, ipstr, sizeof(ipstr));
int16_t port = get.sin_port;
ct->_ts->AddConnection(ac_fd, EVENT_IN, Recver, Sender, Excepter, ip, port);
SetNoBlock(ac_fd);
}
else
{
if (errno == EWOULDBLOCK)
{
// std::cout << "resource depletion" << std::endl;
break;
}
else if (errno == EINTR)
continue;
else
break;
}
}
}
static void Recver(Connection* ct)
{
// std::cout << "Recver fd : " << ct->_fd << std::endl;
while(1)
{
char buffer[1024] = {0};
ssize_t n = read(ct->_fd, buffer, sizeof(buffer) - 1);
// std::cout << "read ret:" << n << std::endl;
if(n > 0)
{
buffer[n] = 0;
ct->_inbuffer += buffer;
}
else if(n == 0)
{
std::cout << "client is close, server close" << std::endl;
ct->_ts->Excepter(ct);
return;
}
else
{
if (errno == EWOULDBLOCK)
{
// std::cout << "resource depletion" << std::endl;
break;
}
else if (errno == EINTR)
continue;
else
{
ct->_ts->Excepter(ct);
return;
}
}
}
ct->_ts->_OnMessage(ct);
}
static void Sender(Connection* ct)
{
// std::cout << 1 << std::endl;
while(1)
{
ssize_t n = write(ct->_fd, ct->_outbuffer.c_str(), ct->_outbuffer.size());
if(n > 0)
{
ct->_outbuffer.erase(0, n);
if(ct->_outbuffer.empty()) break;
}
else if(n == 0)
{
break;
}
else
{
if (errno == EWOULDBLOCK)
{
// std::cout << "resource depletion" << std::endl;
break;
}
else if (errno == EINTR)
continue;
else
{
ct->_ts->Excepter(ct);
break;
}
}
}
if(ct->_outbuffer.empty())
{
ct->_ts->EnableEvent(ct->_fd, true, false);
}
else
{
ct->_ts->EnableEvent(ct->_fd, true, true);
}
}
static void Excepter(Connection* ct)
{
int fd = ct->_fd;
ct->_ts->DelConnection(fd);
close(fd);
}
void EnableEvent(int fd, bool readable, bool writeable)
{
uint32_t events = 0;
events |= ((readable ? EPOLLIN : 0) | (writeable ? EPOLLOUT : 0) | EPOLLET);
_ep.Epoller_Update(fd, EPOLL_CTL_MOD, events);
}
void PRINT_CONNECTIONS() // debug
{
for(auto& e : _connections)
{
std::cout << e.first << std::endl;
}
}
void loop()
{
_quit = false;
while(!_quit)
{
EventDispatcher(1000);
PRINT_CONNECTIONS();
sleep(1);
}
}
~tcpserver()
{
for(auto &e : _connections)
{
close(e.first);
delete e.second;
}
}
private:
sock _sk;
Epoller _ep;
std::unordered_map<int, Connection*> _connections;
struct epoll_event revs[num];
uint16_t _port;
bool _quit;
func_t _OnMessage;
};main.cpp
cpp
#include"tcpserver.hpp"
#include"servercal.hpp"
Calculator ccl;
void OnMessage(Connection* ct)
{
// std::cout << "get message: " << ct->_inbuffer << std::endl;
std::cout << "get message: " << ct->_inbuffer << std::endl;
std::string ret = ccl.server_cal(ct->_inbuffer);
if(ret.empty()) return;
ct->_outbuffer += ret;
ct->_ts->Sender(ct);
}
int main()
{
tcpserver ts(8080, OnMessage);
ts.init();
ts.loop();
return 0;
}clientcal.cpp
cpp
#include<iostream>
#include"protocol.hpp"
#include"socket.hpp"
#define SIZE 1024
#include<time.h>
void String_Parsing(Request& rq, const std::string& str)
{
ssize_t left = str.find(' ');
rq._a = std::stoi(str.substr(0, left));
ssize_t pos = left;
while(1)
{
if(str[pos] == ' ') pos++;
else break;
}
rq._op = str[pos];
ssize_t right = str.find(' ', pos);
rq._b = std::stoi(str.substr(right));
}
int main()
{
srand(time(NULL));
sock sk;
sk.my_socket();
sk.my_connect("127.0.0.1", 8080);
std::string opstr = "+-*/%=&";
char buffer[SIZE] = {0};
int cnt = 5;
while(cnt--)
{
// char buffer[SIZE] = {0};
sleep(1);
Request rq;
std::string message;
rq._a = rand()%100;
rq._b = rand()%100;
rq._op = opstr[rand()%7];
std::cout << rq._a << " " << rq._op << " " << rq._b << std::endl;
// std::getline(std::cin, message);
// String_Parsing(rq, message);
message = "";
rq.Serialization(message);
std::string content = encode(message);
std::cout << content.c_str() << std::endl;
write(sk.get_sockfd(), content.c_str(), content.size());
ssize_t ret = read(sk.get_sockfd(), buffer, SIZE);
if(ret > 0)
{
buffer[ret] = 0;
std::string buf = buffer;
Response rp;
std::string tmp;
decode(buf, tmp);
rp.Deserialization(tmp);
std::cout << rp._result << " " << rp._status_code << std::endl;
}
}
return 0;
}代码很多,整体也很复杂,这很正常,Reactor本身就是一个相对复杂的模式,下面让我来梳理一下。
首先,Reactor的核心实现其实是tcpserver.hpp,和他配套的是socket.hpp(对套接字的简单封装)、Epoller.hpp(对epoll的简单封装)和commen.hpp(实现了一个将fd设置成非阻塞的函数),这些之前都提到过,其实都不是很难。其余的都是应用层的东西了,因为tcpserver传上来的数据需要被应用层层真正消费,所以引入了之前文章中的代码,详情可以查看我的文章:
【Linux网络】简易应用层协议定制
这些就是用户层定制协议序列化反序列化和定界相关的代码,我将他们copy过来了,因为缺少协议消费。
下面我就对tcpserver.hpp这个最核心的代码进行讲解:
首先是Connection
cpp
struct Connection
{
Connection(int fd, func_t recv, func_t send, func_t except, tcpserver* ts, const std::string& ip, uint16_t port):
_fd(fd),
_recv_cb(recv),
_send_cb(send),
_except_cb(except),
_ts(ts)
{
}
int _fd;
std::string _inbuffer; // string 二进制流,vector
std::string _outbuffer;
func_t _recv_cb;
func_t _send_cb;
func_t _except_cb;
tcpserver* _ts;
std::string _ip;
uint16_t _port;
};这是我们管理fd的类,我们将这个类的读、写、异常处理函数都包含在里面,fd对应的应用层读写缓冲区各一个,这样fd之间就都有自己的用户层读写缓冲区了。
在tcpserver类中,有Connection的unordered_map(哈希)存储fd和Connection的映射,这样当fd状态发生变化,epoll_wait返回时,就能通过event中的epoll_data中存的fd通过哈希找到Connection,进而通过Connection中提前注册好的对应的事件的回调函数进行相关事件的处理。Reactor就是通过建立连接后为其注册回调,在事件就绪后通过回调进行事件分发。
这样我们就需要这两个函数
cpp
void AddConnection(int fd, uint32_t event, func_t recv, func_t send, func_t except, const std::string ip, int16_t port)
{
Connection* newConnection = new Connection(fd, recv, send, except, this, ip, port);
_connections[fd] = newConnection;
_ep.Epoller_Update(fd, EPOLL_CTL_ADD, event);
}
void DelConnection(int fd)
{
delete _connections[fd];
_connections.erase(fd);
_ep.Epoller_Update(fd, EPOLL_CTL_DEL, 0);
}一个是fd创建时为fd创建Connection,再将其加入哈希,之后添加进epoll监视。一个是对端关闭时自己也要关闭,多以删除哈希中的fd,删除epoll实例中的fd,再将它close。
这样初始化函数就能写了
cpp
void init()
{
_sk.my_socket();
_sk.my_bind("0.0.0.0", _port);
_sk.my_listen();
AddConnection(_sk.get_sockfd(), EVENT_IN, Accepter, nullptr, nullptr, "0.0.0.0", 0);
SetNoBlock(_sk.get_sockfd());
// std::cout << _sk.get_sockfd() << std::endl;
}简单的套接字初始化,再将监听套接字AddConnection,之后不要忘记设置监听fd为非阻塞。设置回调时因为监听套接字只会读也就是accept,所以只给设置了读回调
cpp
static void Accepter(Connection* ct)
{
while(1)
{
sockaddr_in get;
memset((void*)&get, 0, sizeof(get));
socklen_t glen = sizeof(get);
// std::cout << 1 << std::endl;
int ac_fd = accept(ct->_fd, (sockaddr*)&get, &glen);
// std::cout << 2 << std::endl;
if(ac_fd > 0)
{
std::cout << "get a new accept" << std::endl;
char ipstr[64] = {0};
std::string ip = inet_ntop(AF_INET, (const sockaddr*)&get.sin_addr, ipstr, sizeof(ipstr));
int16_t port = get.sin_port;
ct->_ts->AddConnection(ac_fd, EVENT_IN, Recver, Sender, Excepter, ip, port);
SetNoBlock(ac_fd);
}
else
{
if (errno == EWOULDBLOCK)
{
// std::cout << "resource depletion" << std::endl;
break;
}
else if (errno == EINTR)
continue;
else
break;
}
}
}accept成功时将新的连接套接字AddConnection,读回调为Recver,写回调为Sender,异常回调为Excepter。
cpp
static void Recver(Connection* ct)
{
// std::cout << "Recver fd : " << ct->_fd << std::endl;
while(1)
{
char buffer[1024] = {0};
ssize_t n = read(ct->_fd, buffer, sizeof(buffer) - 1);
// std::cout << "read ret:" << n << std::endl;
if(n > 0)
{
buffer[n] = 0;
ct->_inbuffer += buffer;
}
else if(n == 0)
{
std::cout << "client is close, server close" << std::endl;
ct->_ts->Excepter(ct);
return;
}
else
{
if (errno == EWOULDBLOCK)
{
// std::cout << "resource depletion" << std::endl;
break;
}
else if (errno == EINTR)
continue;
else
{
ct->_ts->Excepter(ct);
return;
}
}
}
ct->_ts->_OnMessage(ct);
}
static void Sender(Connection* ct)
{
// std::cout << 1 << std::endl;
while(1)
{
ssize_t n = write(ct->_fd, ct->_outbuffer.c_str(), ct->_outbuffer.size());
if(n > 0)
{
ct->_outbuffer.erase(0, n);
if(ct->_outbuffer.empty()) break;
}
else if(n == 0)
{
break;
}
else
{
if (errno == EWOULDBLOCK)
{
// std::cout << "resource depletion" << std::endl;
break;
}
else if (errno == EINTR)
continue;
else
{
ct->_ts->Excepter(ct);
break;
}
}
}
if(ct->_outbuffer.empty())
{
ct->_ts->EnableEvent(ct->_fd, true, false);
}
else
{
ct->_ts->EnableEvent(ct->_fd, true, true);
}
}
static void Excepter(Connection* ct)
{
int fd = ct->_fd;
ct->_ts->DelConnection(fd);
close(fd);
}异常的处理就是DelConnection。此外还需要注意写事件,这里并没有一开始就设置对写事件进行监视,因为写事件是发送缓冲区是否有时间,这经常是OK的(因为写都是我们写,我们不写就一直是就绪的),所以如果我们设置关心,那么就会导致其经常返回,有时我们根本不想写数据,消耗资源没有意义,所以我们要写的时候正常写,写完了就返回,如果没有写完了发现数据没写完(outbuffer还有数据)再设置对其的关心,这时就靠epoll监听fd,如果之后数据写完了,我们再去掉关心。
初始化完我们就能进入循环
cpp
void loop()
{
_quit = false;
while(!_quit)
{
EventDispatcher(1000);
PRINT_CONNECTIONS();
sleep(1);
}
}不断循环事件派发器。
cpp
void EventDispatcher(int timeout)
{
int n = _ep.Epoller_wait(revs, sizeof(revs));
if(n < 0)
{
perror("Epoller_wait");
exit(1);
}
for(int i = 0; i < n; ++i)
{
int fd = revs[i].data.fd;
uint32_t events = revs[i].events;
if(_connections.count(fd) != 0)
{
if (events & EPOLLERR) // 交给读写处理函数处理
events |= (EPOLLIN | EPOLLOUT);
if (events & EPOLLHUP)
events |= (EPOLLIN | EPOLLOUT);
if(events & EPOLLIN)
{
if(_connections[fd]->_recv_cb) _connections[fd]->_recv_cb(_connections[fd]);
}
else if(events & EPOLLOUT)
{
if(_connections[fd]->_send_cb) _connections[fd]->_send_cb(_connections[fd]);
}
}
}
}这里将EPOLLERR和EPOLLHUP都按位与上EPOLLIN和EPOLLOUT,原因有2:
EPOLLERR和 EPOLLHUP永远不会单独出现:
根据 Linux 的 man epoll手册,EPOLLERR和 EPOLLHUP事件可能会在 events字段中设置,而无需在 event中请求。这意味着,即使你的 epoll_ctl只监听了 EPOLLIN,当连接出错时,epoll_wait返回的事件也可能是 EPOLLIN | EPOLLERR。
获取错误详情的唯一途径:
epoll 本身只告诉你"有错误发生",但它不告诉你错误的具体原因(是连接被对端重置 ECONNRESET,还是对端正常关闭 EOF,或是其他错误)。要获取具体的错误代码(errno),必须通过后续的 I/O 系统调用(如 read或 write) 或者使用 getsockopt(fd, SOL_SOCKET, SO_ERROR, ...)来获取。