在数字化浪潮席卷全球的今天,金融行业对数据的依赖已达到前所未有的高度。无论是高频交易、实时风控,还是监管报送、客户画像,背后都离不开海量数据的精准流转与同步。然而,当数据规模迈入"千万级"门槛,传统ETL工具在稳定性、一致性与容错能力上的短板日益凸显。如何在高并发、高可用、强合规的金融场景下,实现"零丢失、零重复、低延迟"的数据同步?这正是ETLCloud所要回答的核心命题。
一、什么是"金融级稳定性"?
金融行业对数据基础设施的要求远超一般行业。所谓"金融级稳定性",不仅意味着系统全年可用性需达到99.99%甚至更高,更要求:
-
数据绝对准确:任何一条交易记录的丢失或重复都可能引发合规风险或财务损失;
-
强一致性保障:源端与目标端数据必须严格一致,支持事务级回溯;
-
毫秒级故障恢复:系统需具备自动容错与自愈能力,避免人工干预导致的业务中断;
-
全链路可审计:满足《巴塞尔协议》《GDPR》及国内金融监管对数据血缘、操作日志的强制要求。
这些严苛标准,构成了金融级数据同步的"黄金准则"。
二、千万级数据同步的三大挑战
当数据规模达到"千万级"(日均处理数千万至数十千万条记录),同步过程将面临前所未有的复杂性。金融场景下的典型挑战包括:
1. 性能瓶颈:高吞吐与低延迟难以兼得
千万级数据意味着巨大的 I/O 压力与计算负载。传统工具在全量同步时往往耗时数小时,增量同步也易因单线程处理而积压延迟。而金融业务要求在保障高吞吐的同时,将端到端延迟控制在秒级以内,这对传输架构提出极高要求。
2. 异构系统集成复杂度高
金融企业普遍存在"多源异构"现状:核心系统用 Oracle,互联网渠道用 MySQL,风控平台依赖 Kafka,数仓采用 Hive 或 Doris,客户画像存储于 MongoDB。不同系统在数据类型、事务机制、变更捕获方式(CDC)上差异巨大,统一集成难度极高。
3. 数据质量与容错机制缺失
在海量数据流中,脏数据(如空值、格式错误、主键冲突)不可避免。若缺乏实时拦截与隔离机制,脏数据会污染下游数仓或应用,导致报表失真、模型失效。更严重的是,传统工具往往在任务失败后需人工介入重跑,无法自动断点续传,极大影响业务连续性。
这些挑战共同构成了金融界千万级数据同步的"不可能三角":快、准、稳三者难以同时满足。而 ETLCloud 的产品设计,正是围绕破解这一三角展开。
三、ETLCloud的金融级保障体系
ETLCloud并非依赖传统批处理或复杂编码,而是通过其实时+离线双模集成能力、高性能传输架构与内建数据质量机制,为金融行业提供稳定、高效、可审计的数据同步基础。具体体现在以下四个方面:
1. 毫秒级实时数据同步,满足金融高频场景需求
ETLCloud 能够自动识别不同数据库类型(如 Oracle、MySQL、MongoDB 等)的变更日志,实现数据表的毫秒级实时同步。同步过程中,支持将同一份实时数据并行分发至多个目标系统(如 Hive、Doris、Kafka、MongoDB 或 SQL 数据库),满足风控、反欺诈、实时报表等对时效性要求极高的金融业务场景。
2. ETL 与 ELT 双引擎,灵活应对复杂集成架构
针对金融企业既有复杂清洗转换(如监管报送逻辑),又有海量原始数据入湖入仓的需求,ETLCloud 提供 ETL 和 ELT 双引擎模块:
-
ETL 引擎:适用于需在传输前完成复杂逻辑处理的场景,例如将数仓结果反向写回业务系统;
-
ELT 引擎:适用于快速将业务库数据抽取至数仓或数据湖,提升入仓效率。
平台已具备单项目支撑上万条数据管道稳定调度的实施经验,可构建高可靠、高并发的金融级数据架构。
3. 内建数据质量检查与脏数据隔离机制
在数据传输过程中,ETLCloud 支持实时数据质量校验。一旦发现脏数据(如格式错误、空值超标、主键冲突等),系统会自动将其路由至指定隔离表,并触发告警通知,确保主数据流不受污染,同时便于后续人工核查与修复------这一机制对金融行业保障数据准确性与合规性至关重要。
4. 极致性能与可视化开发,提升稳定性与运维效率
ETLCloud 采用Web 可视化设计界面,用户通过拖拽即可完成任务开发,开发效率提升 50% 以上。平台自主研发的自动分片与多通道并行传输技术,显著优于 Kettle、DataX 等开源工具,在千万级数据量下仍能保持高吞吐与低延迟。此外,分钟级数据服务发布能力支持将同步后的数据快速封装为 API,供下游应用调用,形成"集成-治理-服务"闭环。
四、ETLCloud相比传统开源ETL工具的核心优势
相较于 Kettle、DataX 等传统开源数据集成工具,ETLCloud 在金融级千万级数据同步场景中展现出显著优势,主要体现在以下三个方面:
1.极致性能:自主研发的传输引擎大幅领先
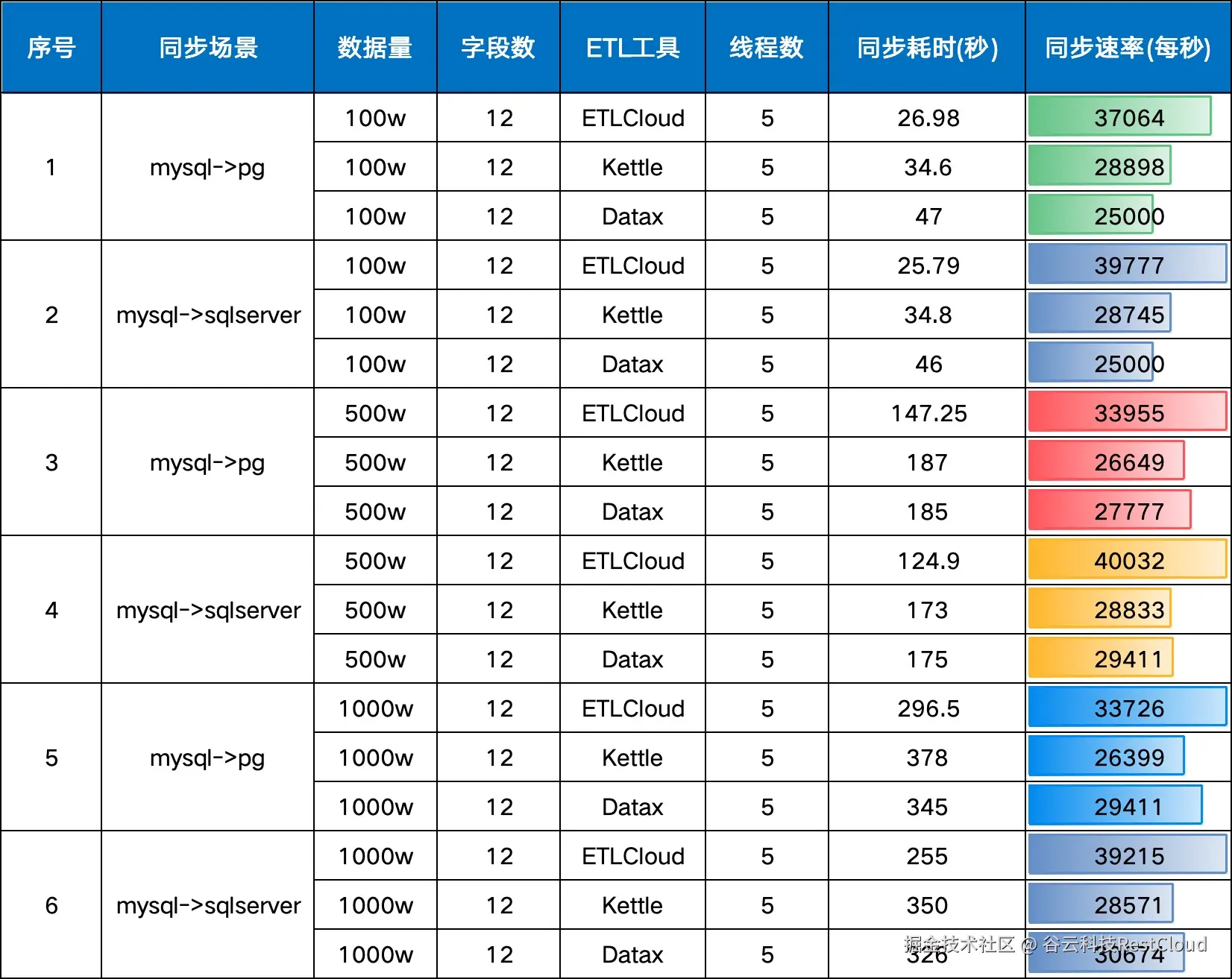
ETLCloud 采用自主研发的自动分片与多通道并行传输技术,在处理千万级数据时展现出远超 Kettle、DataX 的吞吐能力与稳定性。官网明确指出,其传输性能"大幅优于"主流开源工具,能够有效支撑金融业务对高并发、低延迟的数据同步需求。
2.可视化开发:任务构建效率提升50%以上
传统开源工具通常依赖脚本编写或复杂配置,开发门槛高、调试困难。而 ETLCloud 提供全Web可视化设计界面,用户通过简单拖拽和点击即可完成数据任务开发,任务开发效率可提升50%以上。这种低代码方式不仅降低出错率,也加速了数据管道的上线与迭代。
3.一体化能力:从集成到服务的完整闭环
Kettle、DataX 仅聚焦于数据抽取与加载,缺乏数据质量治理与服务能力。而 ETLCloud 不仅支持实时+离线双模集成,还内置脏数据隔离与告警机制,并可分钟级发布数据服务API,实现"集成---治理---服务"一体化。对于金融企业而言,这意味着更短的交付周期、更强的合规保障和更高的业务响应速度。
结语
数据是金融的血液,而准确同步是血液流动的命脉。ETLCloud通过融合云原生架构、金融级容错机制与智能校验体系,不仅解决了千万级数据同步的技术难题,更重新定义了金融数据集成的可靠性标准。未来,随着AI驱动的智能调优、自动数据治理等能力的演进,ETLCloud将持续为金融行业的数字化转型筑牢"稳如磐石"的数据底座。