React
设计理念
- 构建快速响应的大型 Web 应用程,解决CPU、IO的瓶颈
- CPU瓶颈,在浏览器每一帧的时间中,预留5ms(实际> 5ms && < 6ms)给JS线程,
React利用这部分时间更新组件,当预留的时间不够用时,React将线程控制权交还给浏览器使其有时间渲染UI,React则等待下一帧时间到来继续被中断的工作,称为时间切片(time slice)。而时间切片的关键是:将同步的更新 变为可中断的异步更新。 - IO瓶颈,
网络延迟是前端开发者无法解决的,点击切换页面后,先在当前页面停留了一小段时间,这一小段时间被用来请求数据,当"这一小段时间"足够短时,用户是无感知的。如果请求时间超过一个范围,再显示loading的效果。为此,React实现了Suspense (opens new window)功能及配套的hook------useDeferredValue (opens new window)。(需要可中断的异步更新)
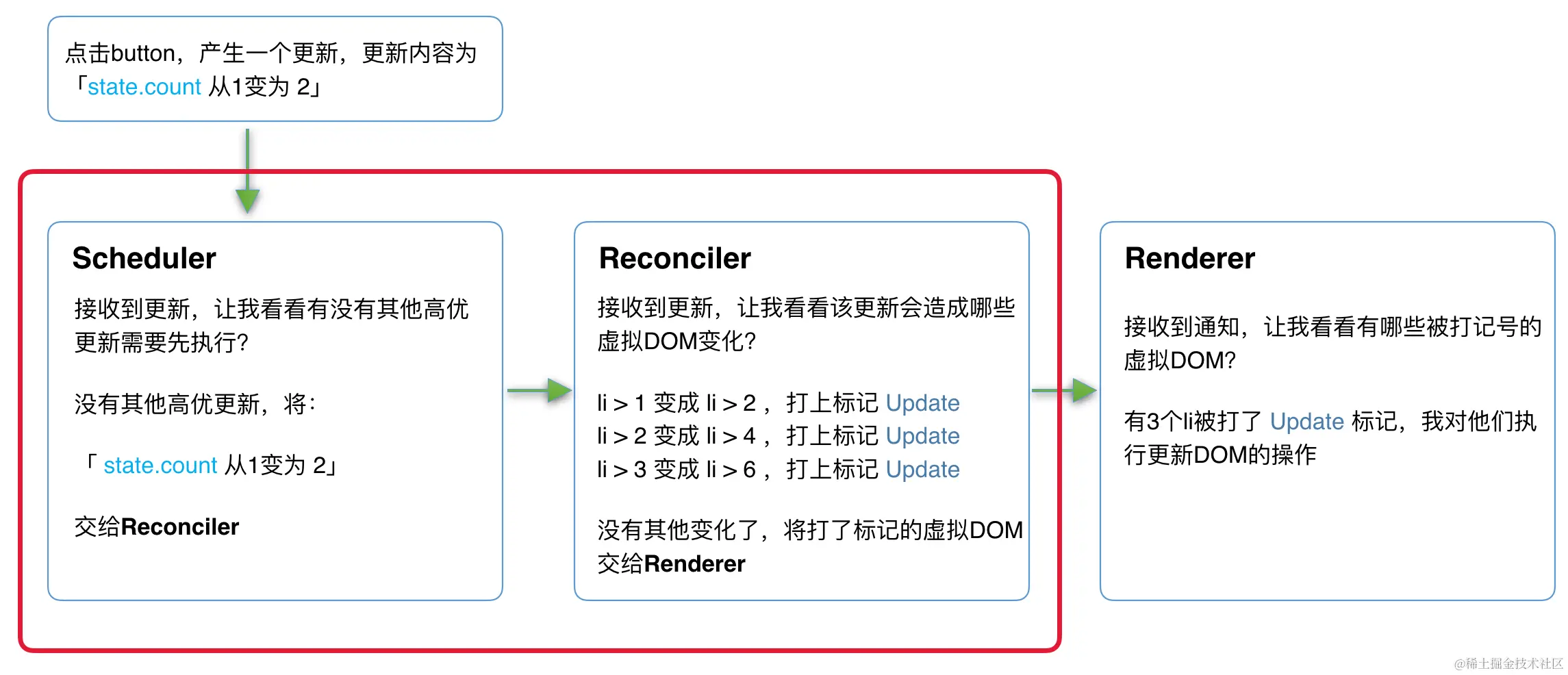
架构(Scheduler、Reconciler、Renderer)
-
Scheduler(调度器)------ 调度任务的优先级,高优任务优先进入Reconciler
- 当浏览器有剩余时间时通知我们,触发回调
- 提供了多种调度优先级供任务设置
- requestIdleCallback浏览器兼容性,触发频率不稳定,受很多因素影响。比如当我们的浏览器切换tab后,之前tab注册的
requestIdleCallback触发的频率会变得很低。使用postMessage宏任务实现
-
Reconciler(协调器)------ 负责找出变化的组件
- Fiber架构(链表)把更新工作从递归
同步更新变成了异步可中断更新(浏览器时间分片用尽或有更高优任务插队)。每次循环都会调用shouldYield判断当前是否有剩余时间,当可以继续执行时恢复之前执行的中间状态。
scssfunction workLoopConcurrent() { // Perform work until Scheduler asks us to yield while (workInProgress !== null && !shouldYield()) { workInProgress = performUnitOfWork(workInProgress); } }- Reconciler 与Renderer 不再是交替工作;整个Scheduler 与Reconciler 的工作都在内存中进行。当Scheduler 将任务交给Reconciler 后,Reconciler 会为变化的虚拟DOM打上代表增/删/更新的标记,只有当所有组件都完成Reconciler 的工作,才会统一交给Renderer。
- Fiber架构(链表)把更新工作从递归
-
Renderer(渲染器)------ 负责将变化的组件渲染到页面上
- Renderer 根据Reconciler为虚拟DOM打的标记,同步执行对应的DOM操作。
- Scheduler 和Reconciler 的工作都在内存中进行,即使反复中断,用户也不会看见更新不完全的DOM,中断原因(有其他更高优任务需要先更新,当前帧没有剩余时间)
Reconciler与Renderer
-
Reconciler
render阶段开始于performSyncWorkOnRoot或performConcurrentWorkOnRoot方法的调用。
scss// performSyncWorkOnRoot会调用该方法 function workLoopSync() { while (workInProgress !== null) { performUnitOfWork(workInProgress); } } // performConcurrentWorkOnRoot会调用该方法 function workLoopConcurrent() { // 如果当前浏览器帧没有剩余时间,`shouldYield`会中止循环,直到浏览器有空闲时间后再继续遍历。 while (workInProgress !== null && !shouldYield()) { // `performUnitOfWork`方法会创建下一个`Fiber节点`并赋值给`workInProgress`, // 并将`workInProgress`与已创建的`Fiber节点`连接起来构成`Fiber树` performUnitOfWork(workInProgress); } }-
performUnitOfWork的工作可以分为两部分:"递"和"归",通过current === null ?来区分组件是处于mount还是update。 -
"递"阶段,首先从
rootFiber开始向下深度优先遍历。为遍历到的每个Fiber节点调用beginWork方法,该方法会根据传入的Fiber节点创建子Fiber节点,并将这两个Fiber节点连接起来,当遍历到叶子节点(即没有子组件的组件)时就会进入"归"阶段。- mount时,会根据
fiber.tag不同,创建不同类型的子Fiber节点。如(FunctionComponent/ClassComponent/HostComponent),最终会进入reconcileChildren方法创建新的子Fiber节点。 update时:如果current存在,(oldProps === newProps && workInProgress.type === current.type,或者!includesSomeLane(renderLanes, updateLanes),即当前Fiber节点优先级不够) ,复用current节点,进入reconcileChildren比较Diff算法,将比较workInProgress.child和current.child的结果生成新Fiber节点。- 在reconcileChildren,
mountChildFibers(mount)与reconcileChildFibers(update)的逻辑基本一致,会生成新的子Fiber节点并赋值给workInProgress.child,作为本次beginWork返回值 (opens new window),并作为下次performUnitOfWork执行时workInProgress - reconcileChildFibers(update)会为生成的
Fiber节点带上effectTag属性,要执行DOM操作的具体类型就保存在fiber.effectTag中。当一个FunctionComponent含有useEffect或useLayoutEffect,他对应的Fiber节点也会被赋值effectTag。对于HostComponent、ClassComponent如果包含ref操作,那么也会赋值相应的effectTag。 (在mount时只有rootFiber会赋值Placement effectTag,防止整棵Fiber树都会执行一次插入操作)
- mount时,会根据
-
"归"阶段,会调用completeWork (opens new window)处理
Fiber节点;当某个Fiber节点执行完completeWork,如果其存在兄弟Fiber节点(即fiber.sibling !== null),会进入其兄弟Fiber的"递"阶段。如果不存在兄弟Fiber,会进入父级Fiber的"归"阶段。completeWork也是针对不同fiber.tag调用不同的处理逻辑,如下处理HostComponentmount时,为Fiber节点生成对应的DOM节点,由于completeWork属于"归"阶段调用的函数,每次调用appendAllChildren时都会将已生成的子孙DOM节点插入当前生成的DOM节点下。那么当"归"到rootFiber时,我们已经有一个构建好的离屏DOM树;与update逻辑中的updateHostComponent类似的处理props的过程- update时,
onClick、onChange等回调函数的注册;主要是处理props,被处理完的(变化了的 )props会以数组形式key, value被赋值给workInProgress.updateQueue,并最终会在commit阶段被渲染在页面上 - 在"归"阶段,所有有
effectTag的Fiber节点都会被追加在effectList中,最终形成一条以rootFiber.firstEffect为起点的单向链表,在commit阶段只需要遍历effectList就能执行所有effect了。
-
render阶段全部工作完成。在performSyncWorkOnRoot函数中fiberRootNode被传递给commitRoot方法,开启commit阶段工作流程。
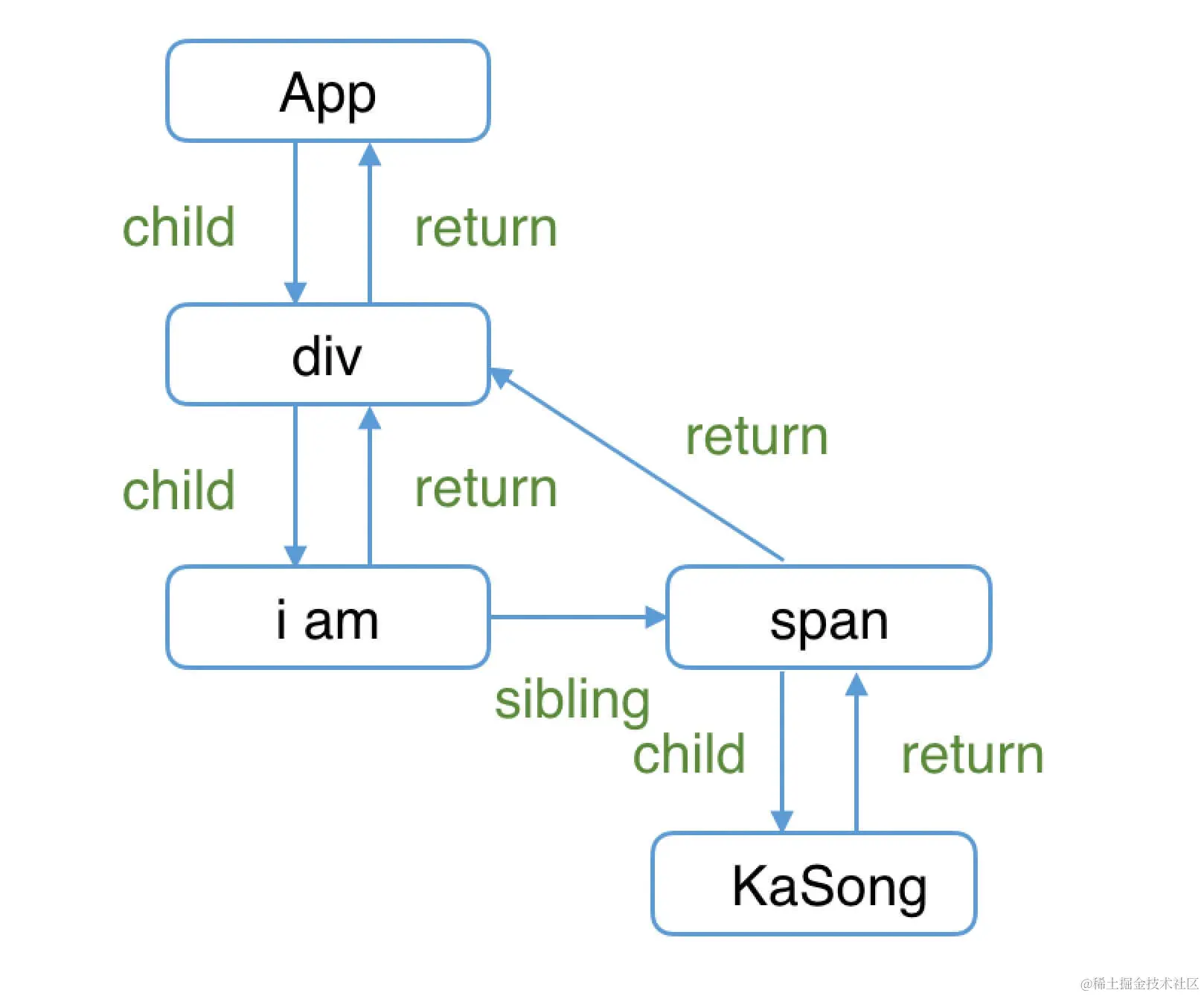
php
```
// `render阶段`会依次执行:
1. rootFiber beginWork
2. App Fiber beginWork
3. div Fiber beginWork
4. "i am" Fiber beginWork
5. "i am" Fiber completeWork
6. span Fiber beginWork
7. span Fiber completeWork
8. div Fiber completeWork
9. App Fiber completeWork
10. rootFiber completeWork
// 之所以没有 "KaSong" Fiber 的 beginWork/completeWork,
// 是因为作为一种性能优化手段,针对只有单一文本子节点的`Fiber`,`React`会特殊处理。
```- Renderer
- 在
rootFiber.firstEffect上保存了一条需要执行副作用的Fiber节点的单向链表effectList,这些Fiber节点的updateQueue中保存了变化的props。 - before mutation阶段(执行
DOM操作前)- 遍历
effectList处理DOM节点渲染/删除后的autoFocus、blur逻辑。 - 调用
getSnapshotBeforeUpdate生命周期钩子,在commit阶段同步执行一次,代替componentWillXXX在render阶段任务可能中断/重新开始多次执行。 before mutation阶段在scheduleCallback中以某个优先级异步调度flushPassiveEffects(防止同步执行时阻塞浏览器渲染)layout阶段之后将effectList赋值全局变量给rootWithPendingPassiveEffectsscheduleCallback触发flushPassiveEffects,flushPassiveEffects内部遍历rootWithPendingPassiveEffects(即effectList)执行useEffect回调函数。
- 遍历
- mutation阶段(执行
DOM操作)- 遍历
effectList根据effectTag分别处理,其中effectTag包括(Placement|Update|Deletion|Hydrating) - Placement effect,获取父级
DOM节点根据DOM兄弟节点是否存在决定调用parentNode.insertBefore或parentNode.appendChild执行DOM插入stateNode - Update effect,
Fiber节点需要更新,会遍历effectList,执行所有useLayoutEffect hook的销毁函数。 - Deletion effect,解绑
ref,调度useEffect的销毁函数;1. 递归调用Fiber节点及其子孙Fiber节点中fiber.tag为ClassComponent的componentWillUnmount(opens new window)生命周期钩子,从页面移除Fiber节点对应DOM节点
- 遍历
- layout阶段(执行
DOM操作渲染完成后)- commitLayoutEffectOnFiber(调用
生命周期钩子和hook相关操作) - 对于
ClassComponent,会通过current === null?区分是mount还是update,调用componentDidMount或componentDidUpdate;触发状态更新的this.setState如果赋值了第二个参数回调函数,也会在此时调用。 - 对于
FunctionComponent及相关类型,他会调用useLayoutEffect hook的回调函数(销毁到回调同步执行),调度useEffect所有的销毁与回调函数useLayoutEffect hook从上一次更新的销毁函数调用到本次更新的回调函数调用是同步执行的。(layout渲染绘制屏幕之前触发,不会闪烁);而useEffect则需要先调度,在(Layout阶段完成后)再异步执行。useLayoutEffect内部的代码和所有计划的状态更新阻塞了浏览器重新绘制屏幕。如果过度使用,这会使你的应用程序变慢。如果可能的话,尽量选择useEffect
- commitAttachRef(赋值 ref)获取
DOM实例stateNode,更新ref的current。
- commitLayoutEffectOnFiber(调用
- 在
mutation阶段结束后,layout阶段开始前,current指向新的workInProgress Fiber树
- 在
Fiber架构
Fiber是React内部实现的一套状态更新机制。支持任务不同优先级,可中断与恢复,并且恢复后可以复用之前的中间状态。
每个Fiber节点对应一个React element,保存了该组件的类型(函数组件/类组件/原生组件...)、对应的DOM节点等信息,本次更新中该组件改变的状态、要执行的工作(需要被删除/被插入页面中/被更新...)
ini
function FiberNode(
tag: WorkTag,
pendingProps: mixed,
key: null | string,
mode: TypeOfMode,
) {
// 作为静态数据结构的属性
// Fiber对应组件的类型 Function/Class/Host...
this.tag = tag;
this.key = key;
this.elementType = null;
// 对于 FunctionComponent,指函数本身,对于ClassComponent,指class,对于HostComponent,指DOM节点tagName
this.type = null;
// Fiber对应的真实DOM节点
this.stateNode = null;
// 用于连接其他Fiber节点形成Fiber树
this.return = null;
this.child = null;
this.sibling = null;
this.index = 0;
this.ref = null;
// 作为动态的工作单元的属性,保存本次更新造成的状态改变相关信息
this.pendingProps = pendingProps;
this.memoizedProps = null;
this.updateQueue = null;
this.memoizedState = null;
this.dependencies = null;
this.mode = mode;
// 保存本次更新会造成的DOM操作
this.effectTag = NoEffect;
this.nextEffect = null;
this.firstEffect = null;
this.lastEffect = null;
// 调度优先级相关
this.lanes = NoLanes;
this.childLanes = NoLanes;
// 指向该fiber在另一次更新时对应的fiber
this.alternate = null;
}-
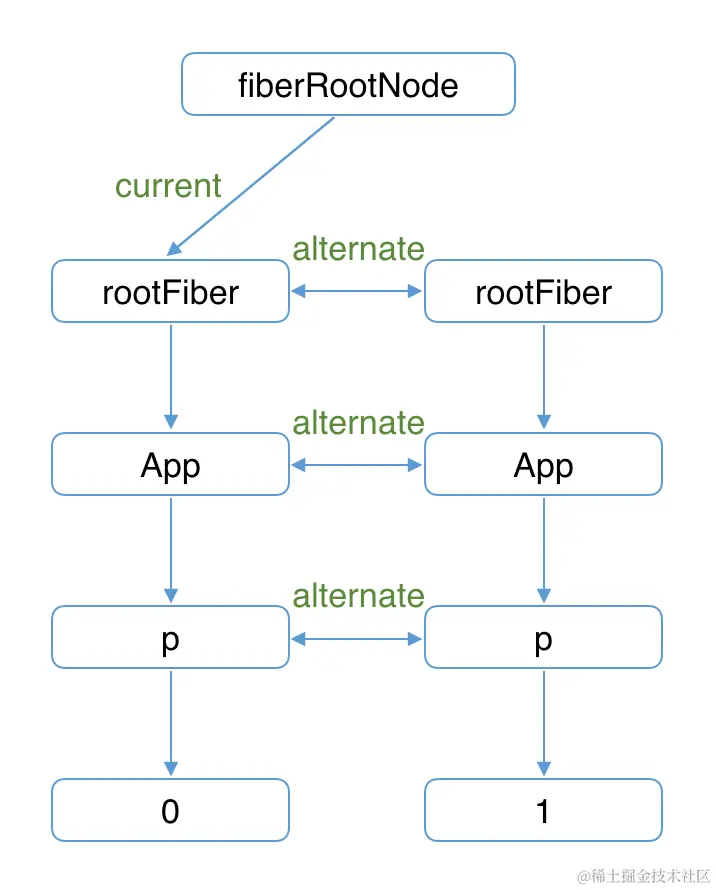
React使用"双缓存"(在内存中构建并直接替 )来完成Fiber树的构建与替换------对应着DOM树的创建与更新。- 在
React中最多会同时存在两棵Fiber树。当前屏幕上显示内容对应的Fiber树称为current Fiber树,正在内存中构建的Fiber树称为workInProgress Fiber树。current fiber节点与workInProgress fiber节点,他们通过alternate属性连接。
inicurrentFiber.alternate === workInProgressFiber; workInProgressFiber.alternate === currentFiber;- 1.mount时, 首次执行
ReactDOM.render会创建fiberRootNode(源码中叫fiberRoot)和rootFiber。其中fiberRootNode是整个应用的根节点,rootFiber是<App/>所在组件树的根节点。 - 2.接下来进入
render阶段,根据组件返回的JSX在内存中依次创建Fiber节点并连接在一起构建Fiber树,被称为workInProgress Fiber树。在构建workInProgress Fiber树时会尝试复用current Fiber树中已有的Fiber节点内的属性,在首屏渲染时只有rootFiber存在对应的current fiber(即rootFiber.alternate)。 - 3.已构建完的
workInProgress Fiber树在commit阶段渲染到页面,fiberRootNode的current指针指向workInProgress Fiber树使其变为current Fiber 树。 - 4.update时, 触发状态改变,这会开启一次新的
render阶段并构建一棵新的workInProgress Fiber 树
- 在
JSX简介
JSX在编译时会被Babel编译为React.createElement方法。 React.createElement最终会调用ReactElement方法返回一个包含组件数据的对象,该对象有个参数$$typeof: REACT_ELEMENT_TYPE标记了该对象是个React Element,还有type、key、props、ref等属性。
FunctionComponent对应的Element的type字段为AppFunc自身,ClassComponent对应的Element的type字段为AppClass自身;React通过ClassComponent实例原型上的isReactComponent变量判断是否是ClassComponent。
JSX与Fiber节点区别,JSX是一种描述当前组件内容的数据结构,不包含组件在更新中的优先级,state,用于Renderer 的标记等信息。
Diff算法
Diff算法的本质是对比current Fiber和JSX对象,生成workInProgress Fiber。- reconcileChildFibers只对同级元素进行
Diff;两个不同类型的元素会产生出不同的树,会销毁其及其子孙节;开发者可以通过key prop来暗示哪些子元素在不同的渲染下能保持稳定 - 单节点
Diff(newChild为object)- 当
key相同且type不同时,所以都需要标记删除。 - 当
key不同时只代表遍历到的该fiber不能被p复用,后面还有兄弟fiber还没有遍历到。所以仅仅标记该fiber删除。
- 当
- 多节点
Diff(newChild为array)- 第一轮遍历:处理
更新的节点。- 遍历
newChildren,将newChildren[i]与oldFiber比较,判断DOM节点是否可复用。 - 如果可复用,
i++,继续比较newChildren[i]与oldFiber.sibling,可以复用则继续遍历。 key相同type不同导致不可复用,会将oldFiber标记为DELETION,并继续遍历;key不同导致不可复用,立即跳出整个遍历,第一轮遍历结束。- 如果
newChildren或者oldFiber遍历完,第一轮遍历结束。 newChildren与oldFiber同时遍历完,此时Diff结束。newChildren没遍历完,oldFiber遍历完,本次更新有新节点插入,我们只需要遍历剩下的newChildren为生成的workInProgress fiber依次标记Placement。newChildren遍历完,oldFiber没遍历完,有节点被删除了。所以需要遍历剩下的oldFiber,依次标记Deletion。newChildren与oldFiber都没遍历完,有节点在这次更新中改变了位置。
- 遍历
- 第二轮遍历:处理剩下的不属于
更新的节点。- 将所有还未处理的
oldFiber存入以key为key,oldFiber为value的Map中。遍历剩余的newChildren,通过newChildren[i].key就能在existingChildrenmap中找到key相同的oldFiber。 - 第一轮遍历中最后一个可复用的节点在
oldFiber中的索引lastPlacedIndex - 遍历
newChildren的一项从map中匹配到节点在oldFiber的中的索引oldIndex - oldIndex >= lastPlacedIndex 该可复用节点不需要移动,重置lastPlacedIndex的值为oldIndex,继续遍历newChildren
- oldIndex < lastPlacedIndex 该节点需要向右移动。
- 考虑性能,我们要尽量减少将节点从后面移动到前面的操作
- 将所有还未处理的
- 第一轮遍历:处理
class组件状态更新update原理
-
ClassComponent与HostRoot(即rootFiber.tag对应类型)共用同一种Update结构。perlconst update: Update<*> = { eventTime, lane, // 优先级相关字段,同`Update`优先级可能是不同的。 suspenseConfig, tag: UpdateState, // 更新挂载的数据,对于`ClassComponent`,`payload`为`this.setState`的第一个传参; // 对于`HostRoot`,`payload`为`ReactDOM.render`的第一个传参 payload: null, // 更新的回调函数。`this.setState`的第二个传参;layout阶执行 callback: null, next: null, // 与其他`Update`连接形成单向环状链表。 };- 方法内部调用了两次
this.setState。这会在该fiber中产生两个Update,个Update会组成链表并被包含在fiber.updateQueue中。(React Hooks有batchedUpdates批量更新) Fiber节点最多同时存在两个updateQueue,current updateQueue和workInProgress updateQueue,中断重新开始时,会基于current updateQueue克隆出workInProgress updateQueue。由于current updateQueue.lastBaseUpdate已经保存了上一次的Update,所以不会丢失。updateQueue有三种类型,其中针对HostComponent类型我们在completeWork中数组形式key, value存变化的props;ClassComponent与HostRoot使用的UpdateQueue结构如下:
perlconst queue: UpdateQueue<State> = { // 本次更新前该`Fiber节点`的`state`,`Update`基于该`state`计算更新后的`state` baseState: fiber.memoizedState, // `firstBaseUpdate`与`lastBaseUpdate`:本次更新前该`Fiber节点`已保存的`Update`。 // 以链表形式存在,链表头为`firstBaseUpdate`,链表尾为`lastBaseUpdate`。 // 之所以在更新产生前该`Fiber节点`内就存在`Update`, // 是由于某些`Update`优先级较低所以在上次`render阶段`由`Update`计算`state`时被跳过。 firstBaseUpdate: null, lastBaseUpdate: null, // 触发更新时,产生的`Update`会保存在`shared.pending`中形成单向环状链表。 // `shared.pending` 会保证始终指向最后一个插入的`update` // 当由`Update`计算`state`时这个环会被剪开并连接在`lastBaseUpdate`后面 // 单向环状链表使shared.pending.next指向第一个加入update shared: { pending: null, }, // 数组。保存`update.callback !== null`的`Update` effects: null, };- render阶段beginWork时 ,
shared.pending的环被剪开并连接在updateQueue.lastBaseUpdate后面,以fiber.updateQueue.baseState为初始state,依次与遍历到的每个Update计算并产生新的state(该操作类比Array.prototype.reduce) - 遍历时如果有优先级低的
Update会被跳过。在其之前的B2由于优先级不够被跳过。update之间可能有依赖关系,所以被跳过的update及其后面所有update会成为下次更新的baseUpdate。 (即B2 --> C1 --> D2)。在commit阶段结尾会再调度一次更新,该次更新中的baseState基于被跳过的前一个update计算出的值;C1执行了两次,componentWillXXX也会触发两次。 state的变化在render阶段产生与上次更新不同的JSX对象,通过Diff算法产生effectTag
rustshared.pending: A1 --> B2 --> C1 --> D2 第一次render阶段使用的Update: [A1, C1], commit完后 baseState: 'A',baseUpdate: B2 --> C1 --> D2,memoizedState: 'AC' 第二次render阶段使用的Update: [B2, C1, D2],baseState: 'A'计算 commit完后memoizedState: 'ABCD' - 方法内部调用了两次
react18相对react16.8新增的api和功能
- 并发渲染引擎。ReactDOM.createRoot(container) 取代 ReactDOM.render,开启并发能力。让更新可中断可恢复、可优先级调度,提升大页面的流畅度。
- 自动批处理(Automatic Batching)。跨事件、setTimeout、Promise 等的多个 setState 会自动合并一次渲染。 若需立即同步更新,可用 flushSync(fn) 强制同步刷新。
- useTransition & startTransition: 区分紧急更新(如用户输入)和过渡更新(如搜索结果渲染),标记非紧急更新为可中断任务,提升交互流畅性。
- useDeferredValue: 延迟渲染非关键值(如大型列表),类似防抖但更智能,避免阻塞用户操作。
并发渲染(Concurrent Rendering)Scheduler 原理
- Fiber 链表结构,渲染过程中可中断,中断后通过指针定位恢复位置(如 workInProgress 指针),天然支持可中断遍历。
- 双缓存机制 维护两棵 Fiber 树: Current Tree:当前渲染完成的 UI。 Work-in-Progress Tree:正在构建的更新树。 通过指针切换实现原子性更新,避免直接修改当前树。
- 时间分片,每次执行后shouldYield检查5ms是否有剩余时间。超时5ms或有优先级任务则中断当前任务。Render 阶段:可中断,处理 Fiber 链表的构建和差异计算(调用 shouldYield 判断是否中断)。 Commit 阶段:同步,应用 DOM 更新(无中断)
- 启动调度 调用 requestHostCallback 触发异步循环: 浏览器环境:基于 MessageChannel(0~1ms 延迟)。 降级方案:setTimeout(0)。
react触发更新机制api
-
class组件ReactDOM.render,props,this.setState,this.forceUpdate
- 备注,this.forceUpdate创建的update对象
tag为ForceUpdate,那么当前ClassComponent不会受其他性能优化手段(shouldComponentUpdate|PureComponent)影响,一定会更新。
- 备注,this.forceUpdate创建的update对象
-
函数式组件调用useState、useReducer的dispatch方法更改状态,useContext订阅时,该context.provide的value值改变,useSelector(state => state.reducerA.val)返回redux的新值。
- React Context 的更新机制会绕过 shouldComponentUpdate(类组件)和 React.memo(函数组件)的性能优化逻辑,导致被优化的组件强制重渲染。Context 更新属于全局状态变更,通过 Fiber 树的特殊标记(updateQueue)强制触发渲染2。
-
批量更新失效;
- 异步回调中更新状态 场景:在 setTimeout、Promise.then、fetch 回调或 useEffect 的异步操作中调用 setState。
- 原生事件处理函数 场景:直接绑定浏览器原生事件(如 document.addEventListener)而非 React 合成事件。
- React 18 之前的遗留模式 场景:使用 ReactDOM.render(非 createRoot)挂载应用。
解决:React 18 默认在 createRoot 模式下,所有环境(包括异步回调)的更新均自动批处理;若需强制同步更新,可使用 flushSync API。使用 unstable_batchedUpdates: 在异步回调中包裹状态更新,强制批处理;
react context
- 使用
- React.createContext(defaultValue):创建 Context 对象,defaultValue 仅在无 Provider 包裹时生效。
<Provider value={}>:包裹组件树,提供数据,当 Provider 的 value 变化时,所有消费组件会强制重渲染。内层Provider值会覆盖外层值。- 消费数据的组件: 类组件:static contextType = MyContext 或
<Consumer>{value => (<><>)}</Consumer>; 函数组件:useContext(MyContext);
- 机制
- 当 Provider 的 value 变化时,React 会主动遍历子树,直接触发所有使用 useContext 或 Consumer 的订阅的组件强制更新。此过程不受 shouldComponentUpdate 或 React.memo 阻断,即使组件的 props 未变化。
- shouldComponentUpdate 和 React.memo 仅拦截 props/state 变化,但 Context 更新属于全局状态变更,通过 Fiber 树的特殊标记(updateQueue)强制触发渲染。若 Context value 包含 { theme: 'dark', user: 'Alice' },即使组件仅使用 user 字段,theme 的变更仍会触发重渲染。
- 优化
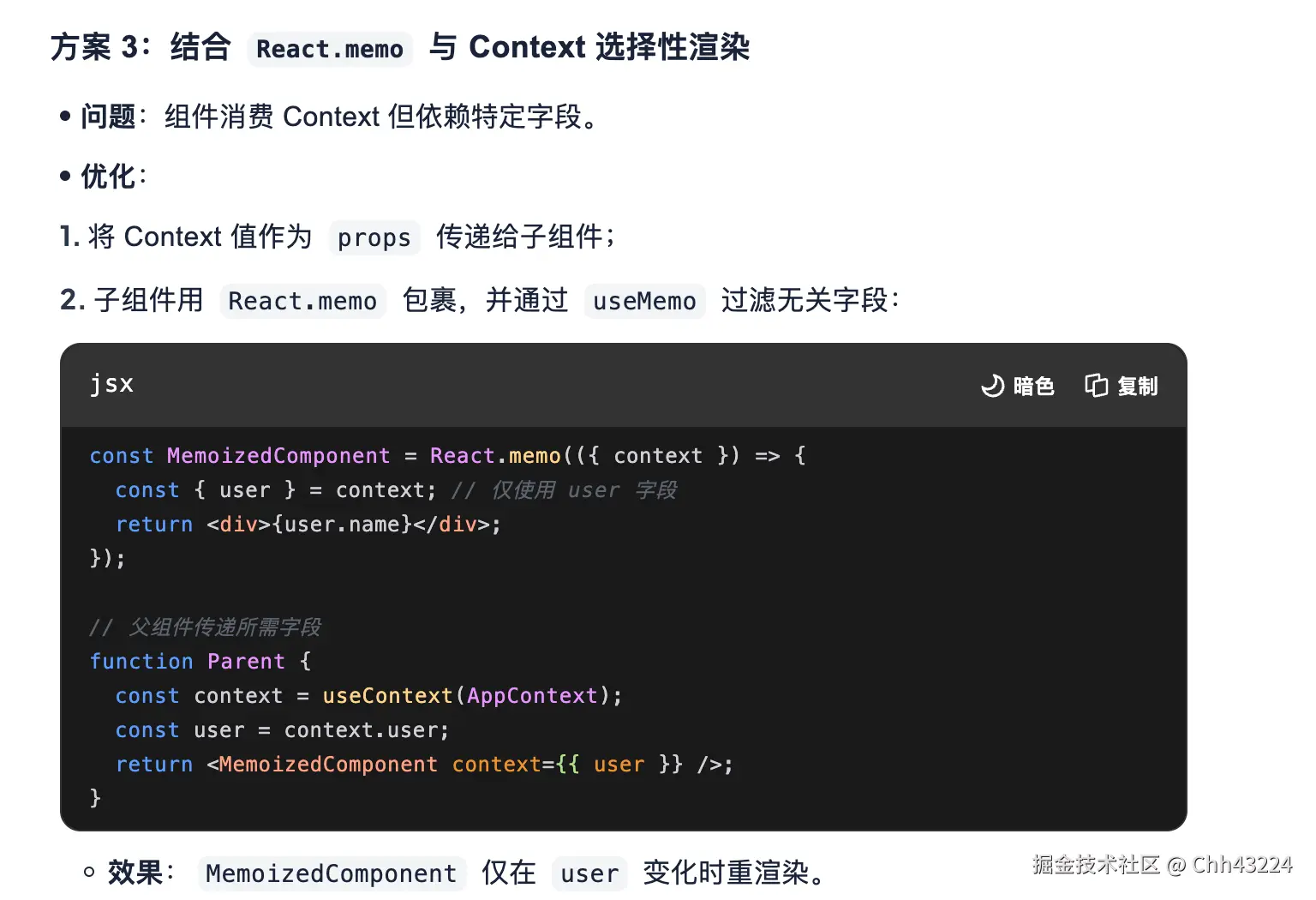
- 按业务拆分为多个细粒度 Context,组件仅订阅所需 Context,减少无关渲染。
- 通过 useMemo,useCallback 冻结对象类型value引用,稳定 Context 的value引用。
- 再包一层或者往下拆一层,将 Context 值作为 props 传递给子组件,子组件用 React.memo 包裹,并通过 useMemo 过滤无关字段:
ErrorBoundary
React 的错误边界(Error Boundary)是一种类组件,用于捕获其子组件树在渲染过程中抛出的错误,并展示降级 UI。仅处理渲染阶段同步错误(如 render、生命周期方法、构造函数)。

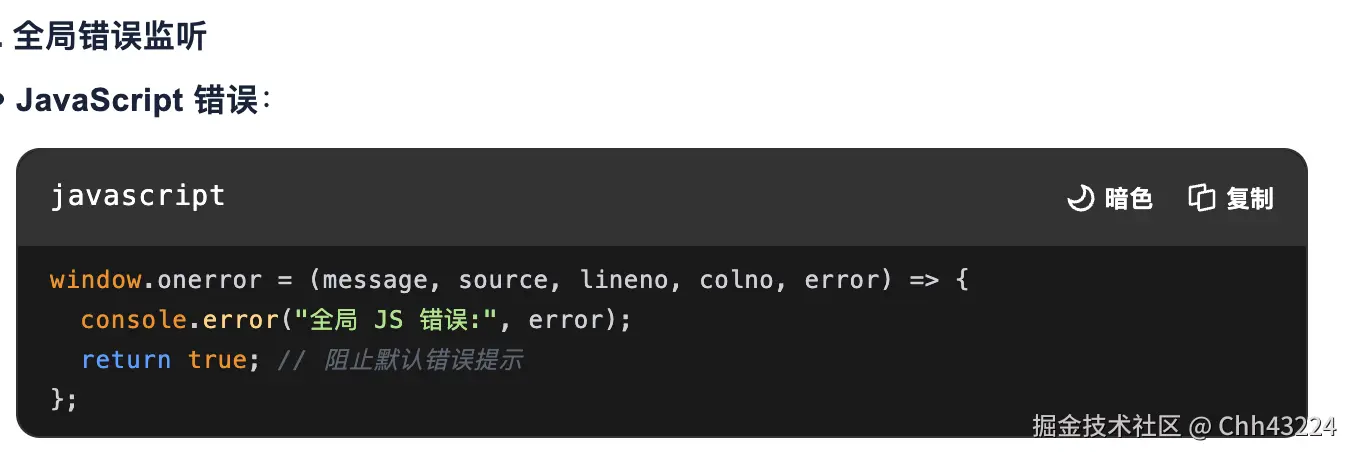
- 事件处理函数,异步代码错误,try/catch + async/await;
- Promise使用.catch 回调;全局监听 unhandledrejection 事件捕获未处理的 Promise 错误;
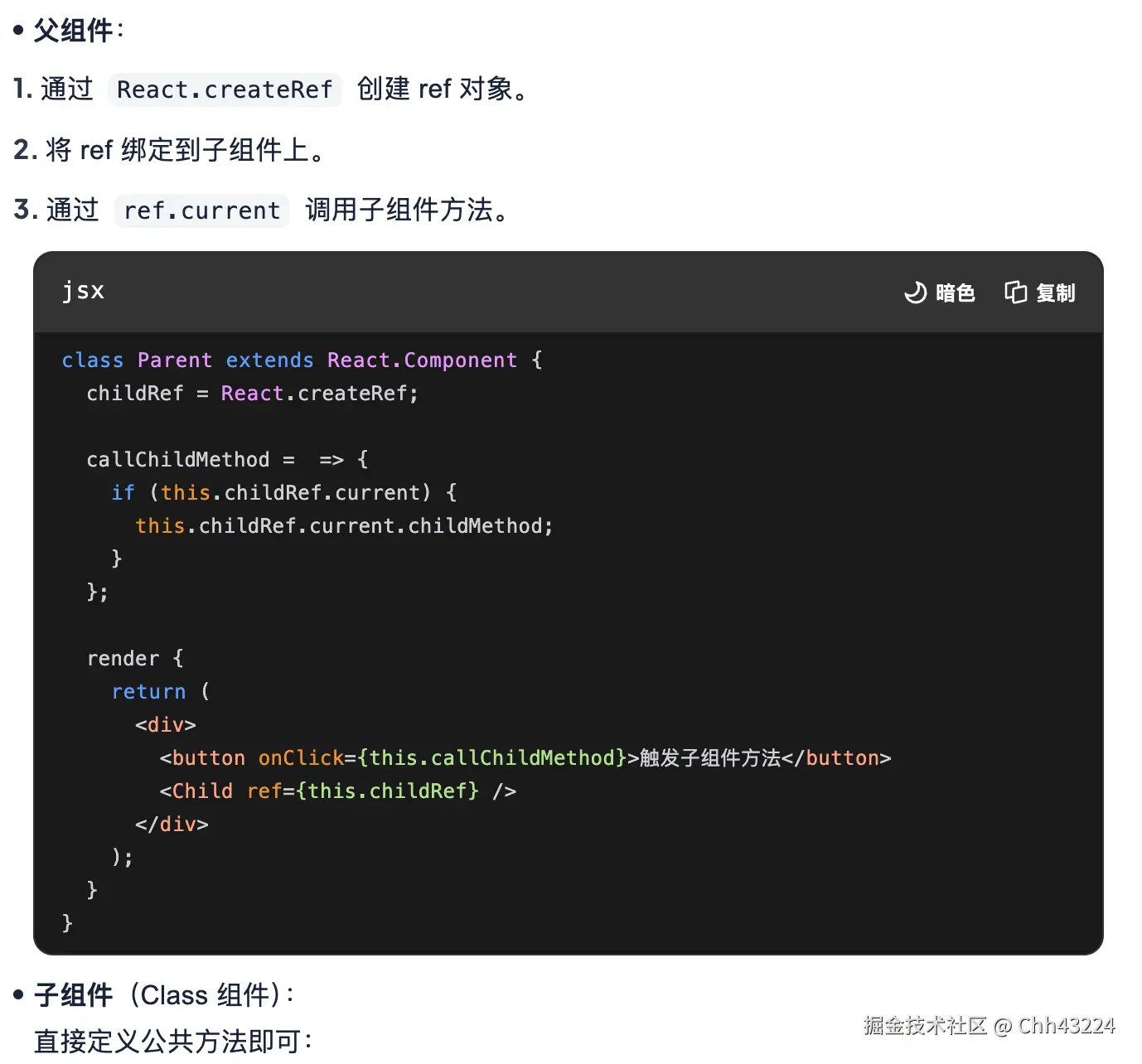
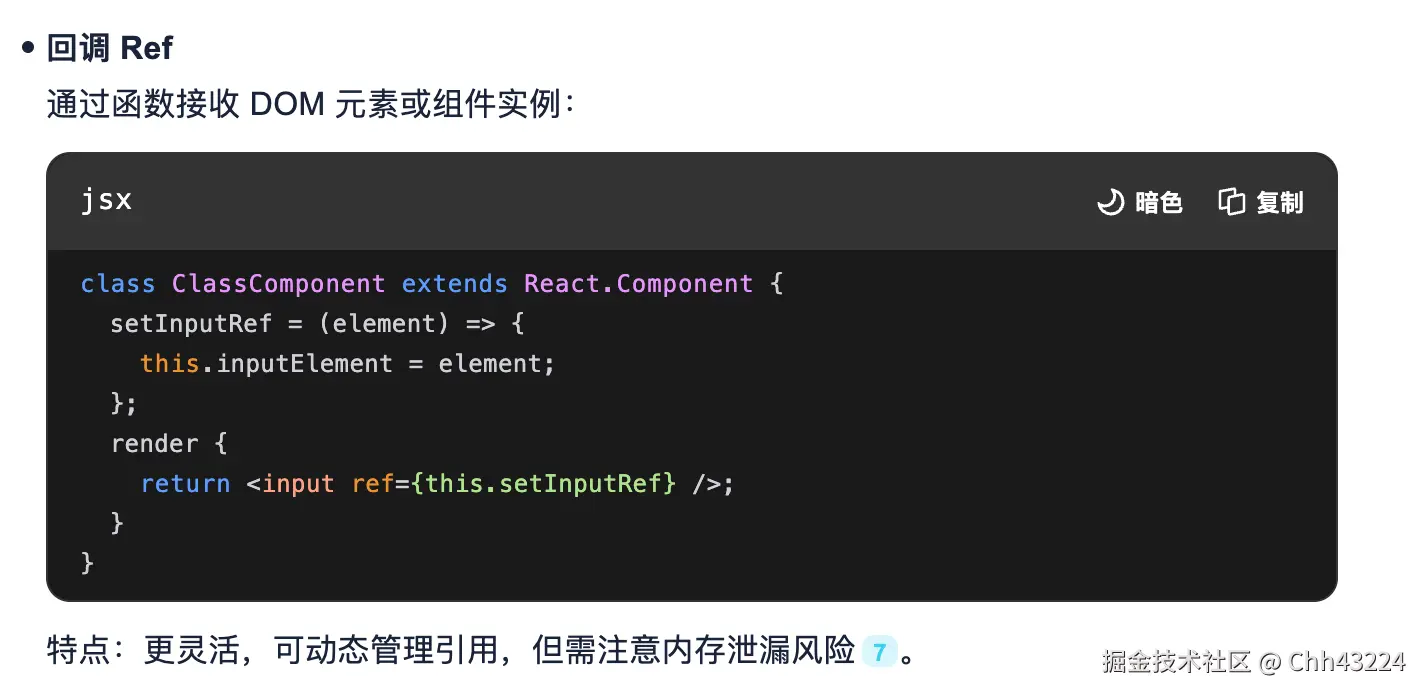
react ref



react 性能优化
- 拆分组件优化渲染范围,仅受影响的子组件重渲染。按业务拆分状态数据,最少状态数据更新。
- 类组件用 PureComponent(自动浅比较),shouldComponentUpdate(手动比较),函数组件用 React.memo。
- immer.js会当修改深层次对象时,从改变的子节点到根节点的整一条路径对象地址都会改变。其他分支的对象地址不会改变。juejin.cn/post/692609...
- useCallback/useMemo 缓存函数和对象。
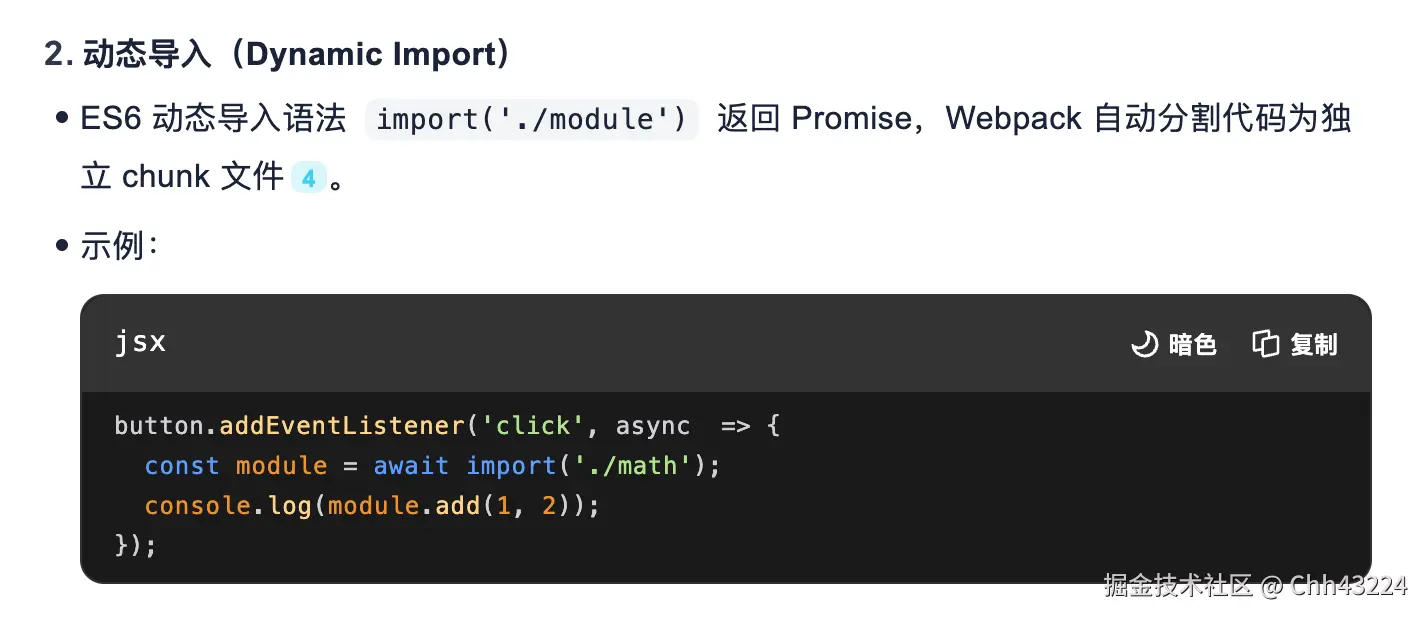
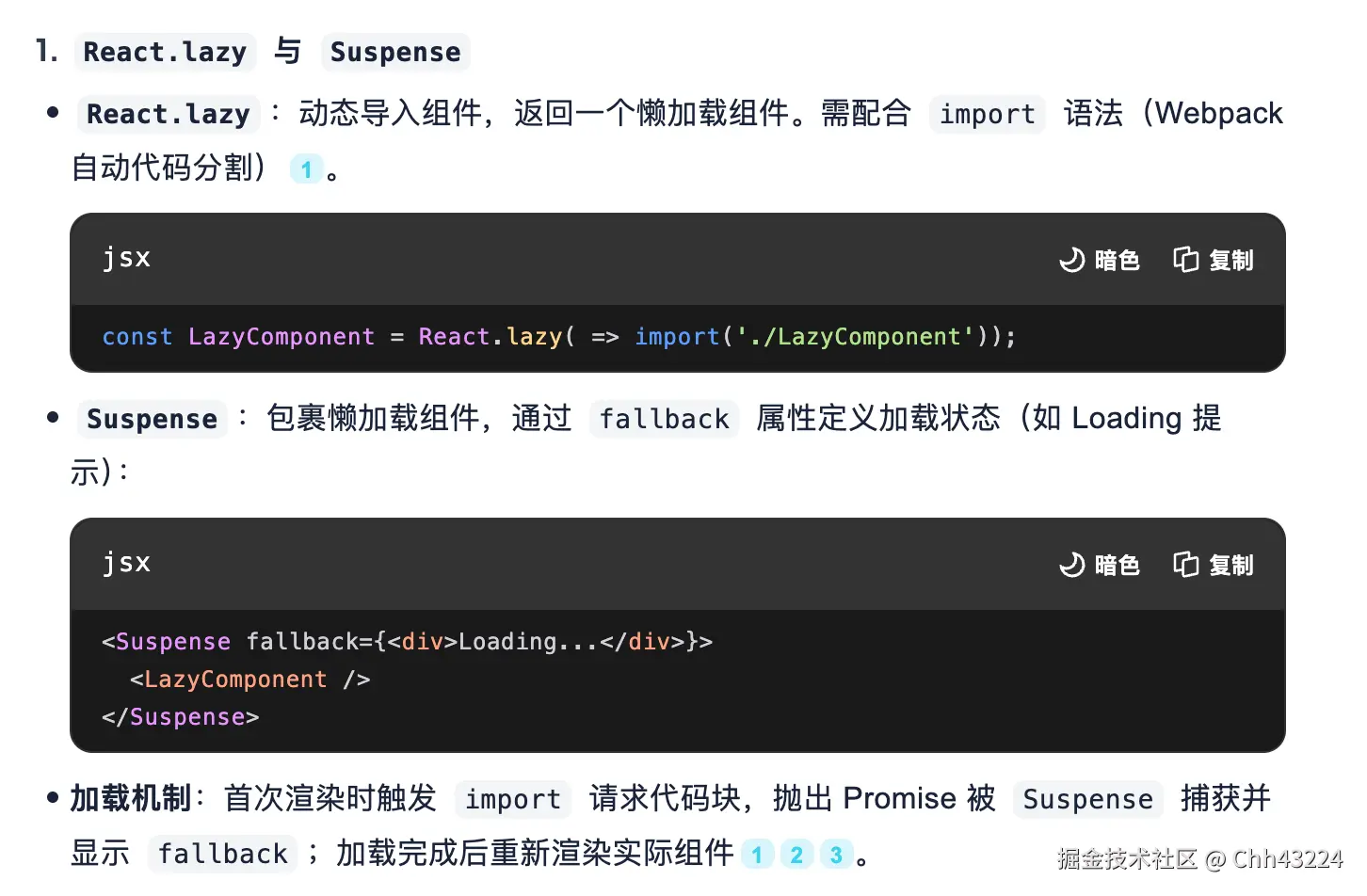
- 懒加载(React.lazy)和代码分割(webpack的import的/webpackChunkName /注释语法)。
import执行会返回一个Promise值为module.default作为异步加载的手段- 路由懒加载,结合react-router-dom里的lazy实现路由组件按需加载,首屏 JS 体积减少 30%~70%,加载时间缩短。
- 组件级别懒加载,对非首屏组件(如弹窗、富文本编辑器)按需加载。
-
循环正确使用key,避免用随机数或index和用index拼接其他的字段做key;绑定事件尽量不要使用箭头函数,使用useCallback。
-
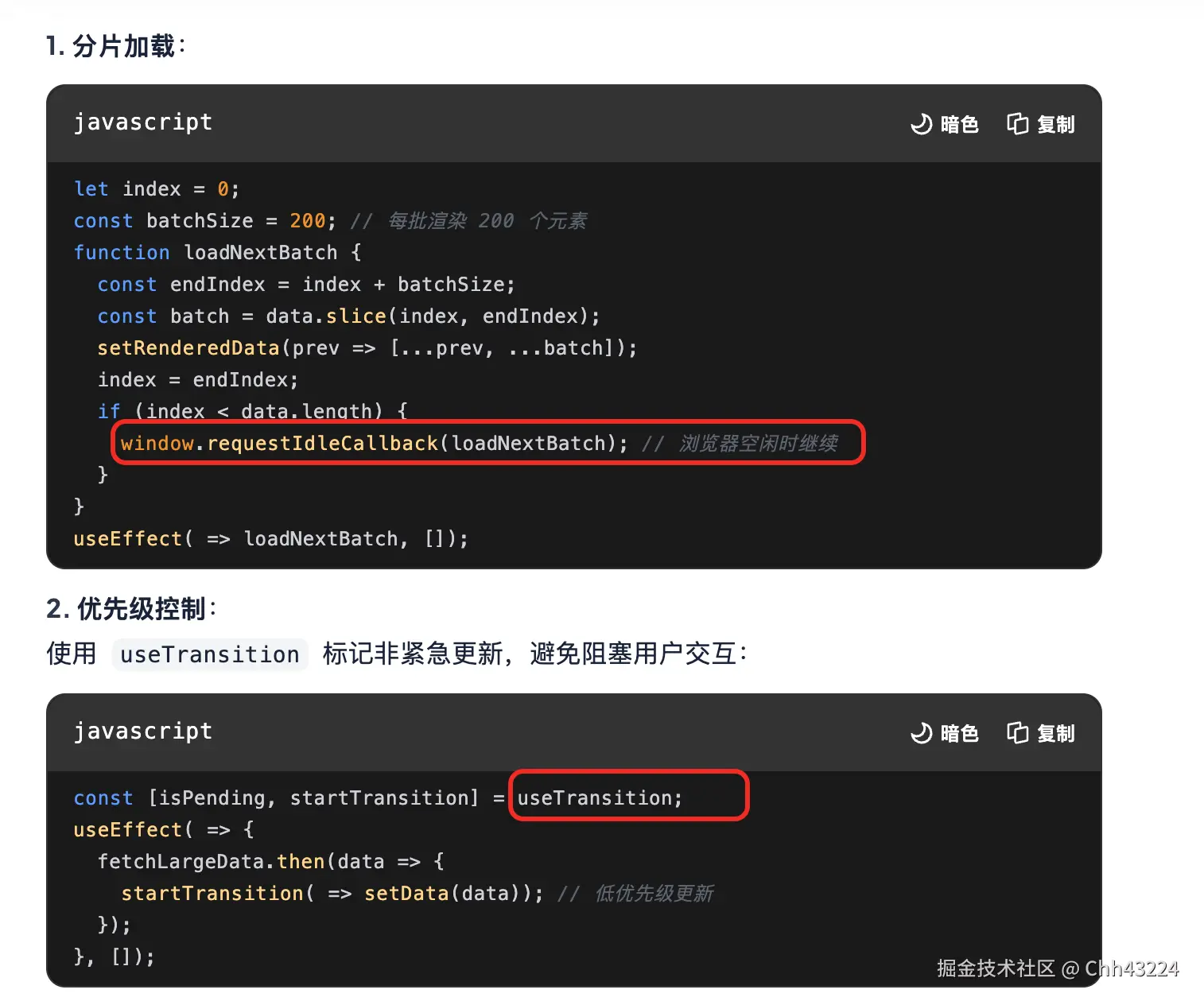
时间分片,初始化加载大量数据到内存中。优先级控制,useTransition()标记为非紧急更新;
-
虚拟列表;分为渲染区,缓冲区,冲区的作用就是防止快速下滑或者上滑过程中,会有空白的现象。
- 计算出容器高度scorllBoxHeight和item的高度itemHeight,Math.ceil(scorllBoxHeight / itemHeight) + bufferCount一屏个数加上缓冲区个数endNum渲染出撑出滚动条
- 监听滚动容器的
onScroll事件,根据scrollTop来计算渲染区域向上偏移量,使用translate3d开启cpu加速移动容器,并计算出新的startNum和endNum
-
双缓存,先在内存中处理操作DOM,并在GPU加速opacity:0,will-change:opacity的隐藏的DOM中预渲染大数据量DOM结构,最后再直接替换当前的DOM。
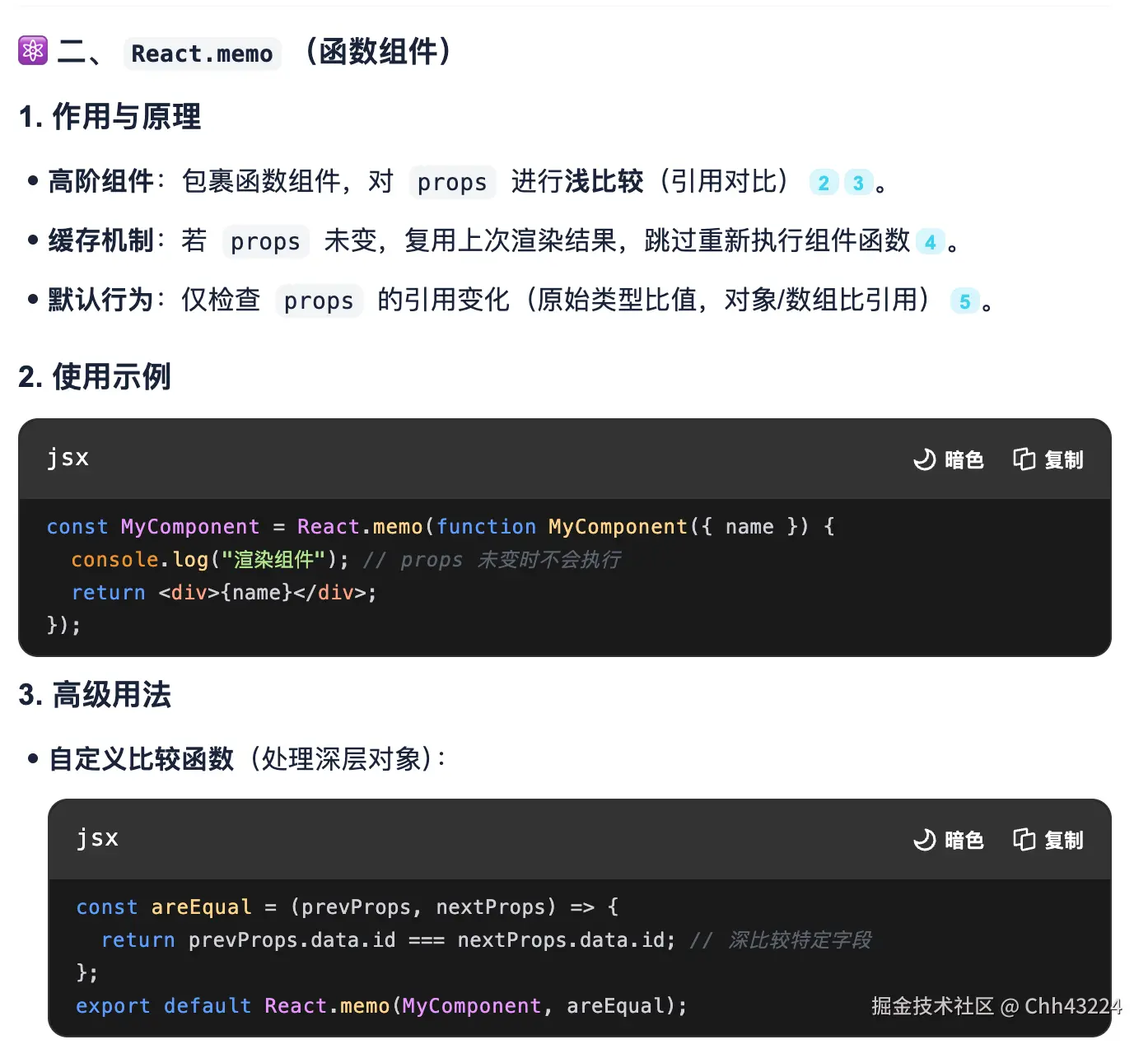
shouldComponentUpdate与React.memo
类组件用 PureComponent(自动浅比较),函数组件用 React.memo。 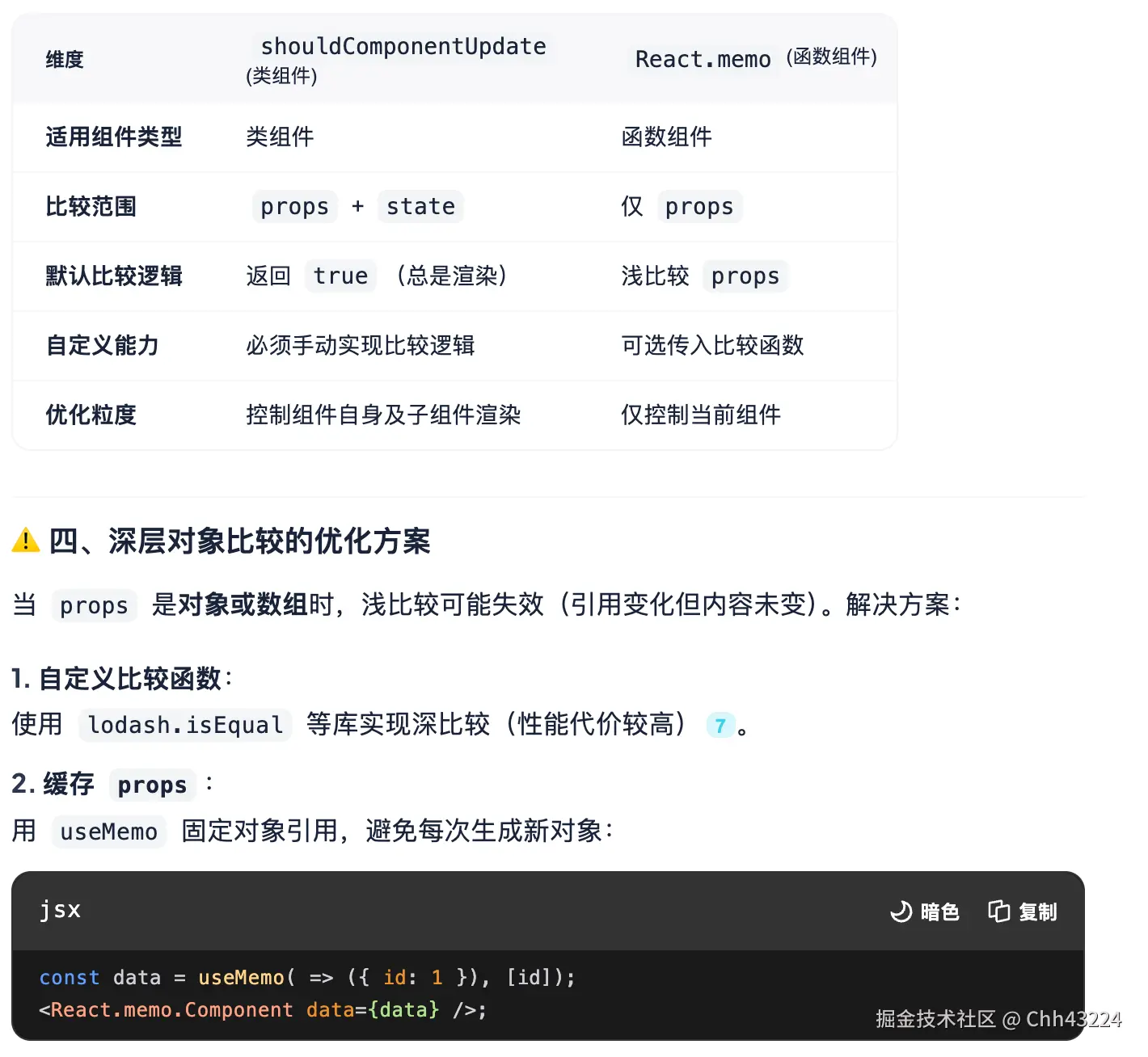
useSelector 与 useDispatch
- useSelector 与 useDispatch联合使用,实现状态读取与更新,替代传统的 connect 高阶组件
- useSelector的选择器函数的第一个参数是 Redux Store 的根状态(state),返回值即为组件中使用的数据。若需获取多个状态,可多次调用 useSelector。
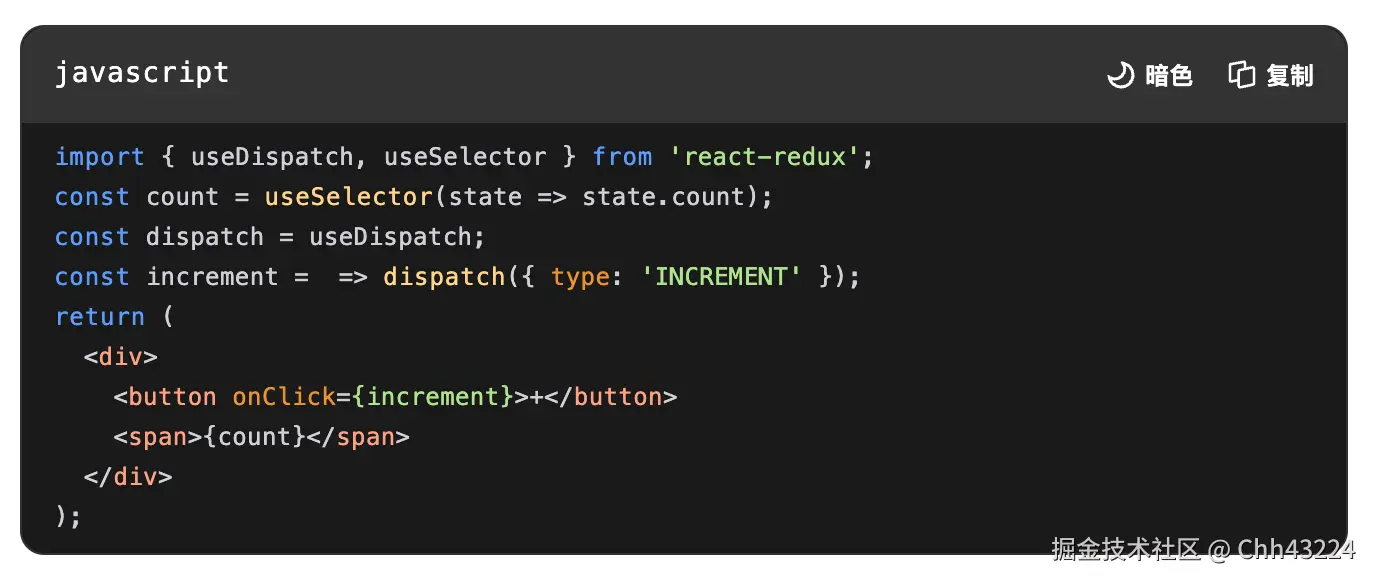
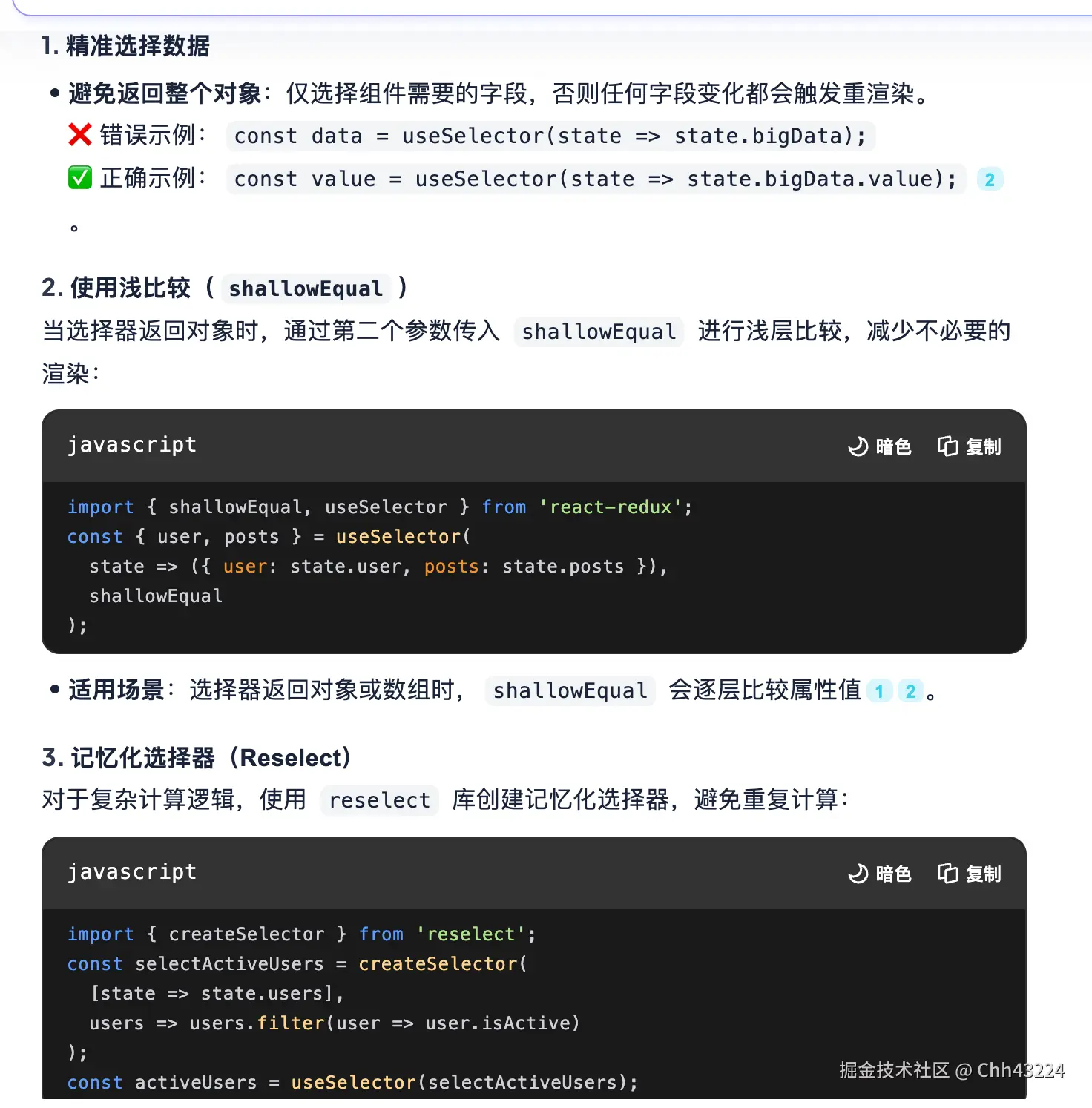
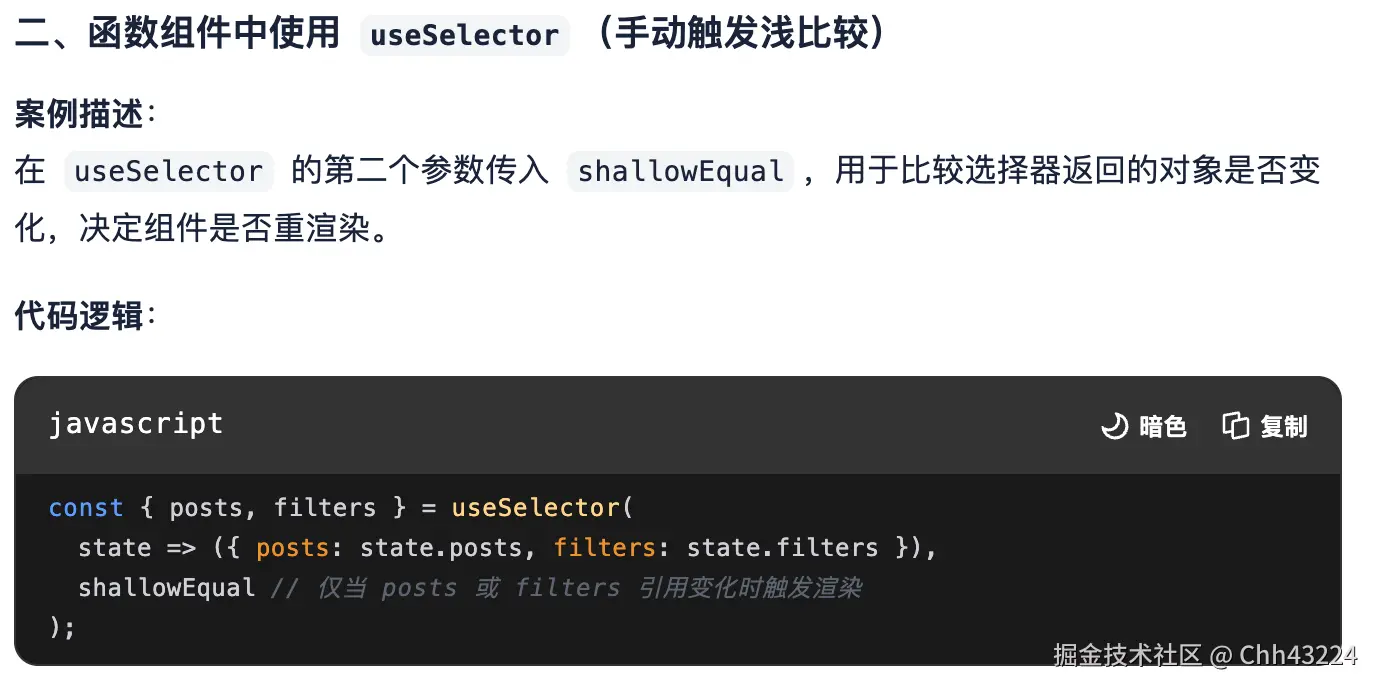
useDispatch执行异步操作,异步操作完成后,useSelector 会自动更新数据。 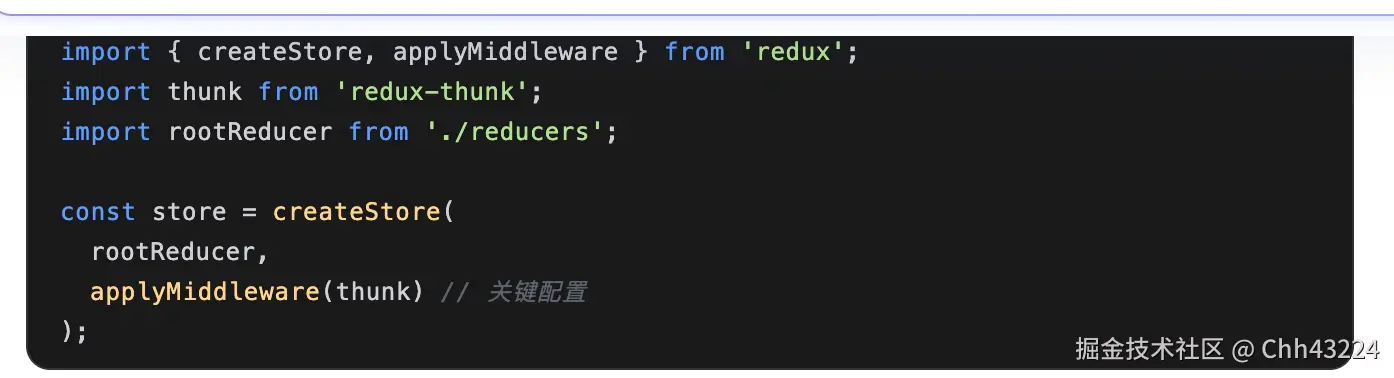
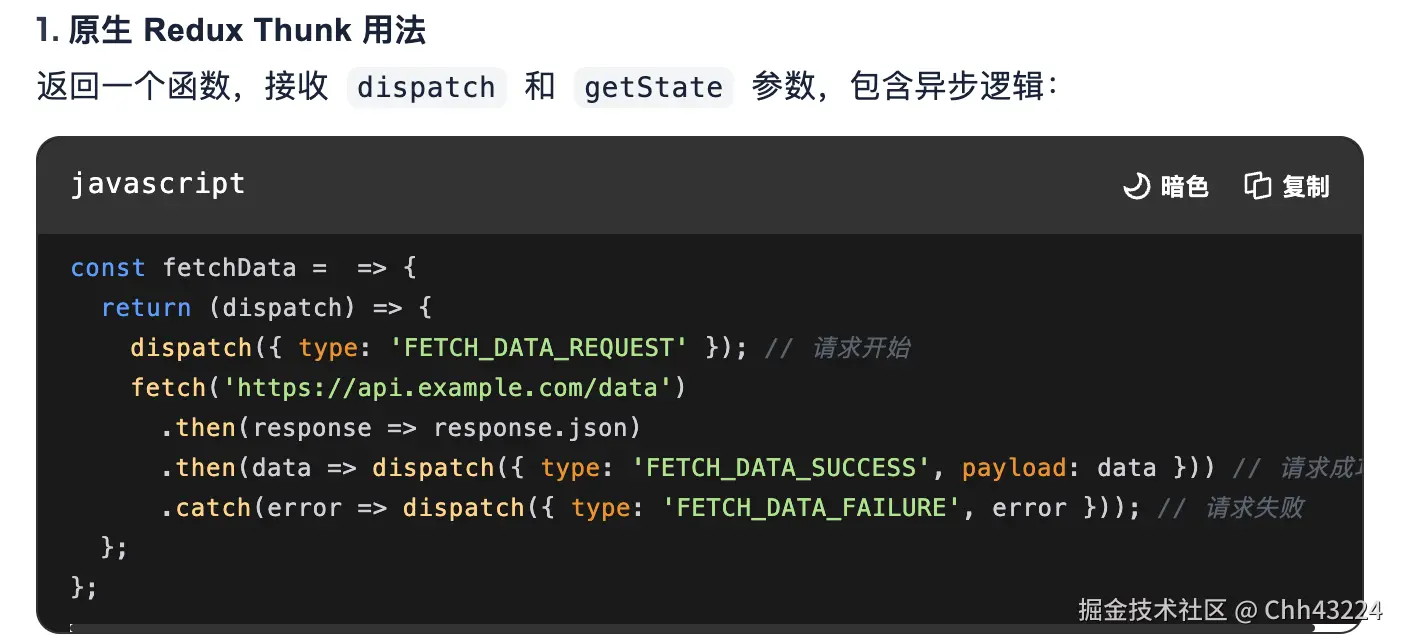
react hook原理
fiber.memoizedState:FunctionComponent对应fiber保存的Hooks链表。- 在
FunctionComponentrender前,根据(current === null || current.memoizedState === null)区分mount与update,可见mount时调用的hook和update时调用的hook其实是两个不同的函数。- 一旦在条件语句中声明
hooks,在下一次函数组件更新,hooks链表结构,将会被破坏,current树的memoizedState缓存hooks信息,和当前workInProgress不一致,如果涉及到读取state等操作,就会发生异常。 hooks通过什么来证明唯一性的,答案 ,通过hooks链表顺序。
- 一旦在条件语句中声明
ini
ReactCurrentDispatcher.current = current === null || current.memoizedState === null
? HooksDispatcherOnMount
: HooksDispatcherOnUpdate; - Hook的数据结构
yaml
const hook: Hook = {
// `fiber.memoizedState`:`FunctionComponent`对应`fiber`保存的`Hooks`链表。
// `hook.memoizedState`:`Hooks`链表中保存的单一`hook`对应的数据。
memoizedState: null,
baseState: null,
baseQueue: null,
queue: null,
next: null,
};-
不同类型
hook的memoizedState保存不同类型数据,具体如下:-
useState:对于
const [state, updateState] = useState(initialState),memoizedState保存state的值 -
useReducer:对于
const [state, dispatch] = useReducer(reducer, {});,memoizedState保存state的值 -
useEffect:
memoizedState保存包含useEffect回调函数、依赖项等的链表数据结构effect,你可以在这里 (opens new window)看到effect的创建过程。effect链表同时会保存在fiber.updateQueue中 -
useRef:对于
useRef(1),memoizedState保存{current: 1} -
useMemo:对于
useMemo(callback, [depA]),memoizedState保存[callback(), depA] -
useCallback:对于
useCallback(callback, [depA]),memoizedState保存[callback, depA]。与useMemo的区别是,useCallback保存的是callback函数本身,而useMemo保存的是callback函数的执行结果 -
有些
hook是没有memoizedState的,比如:useContext
-
-
useState与useReducer- 本质来说,
useState只是预置了reducer的useReducer,useReducer的lastRenderedReducer为传入的reducer参数 - 声明阶段
typescriptfunction mountReducer<S>( initialState: (() => S) | S, ): [S, Dispatch<BasicStateAction<S>>] { // 创建并返回当前的hook,将hook插入fiber.memoizedState链表末尾, // 加入workInProgressHook链表中 const hook = mountWorkInProgressHook(); // ...赋值初始state // 创建queue const queue = (hook.queue = { pending: null, // 保存update对象 dispatch: null, // 保存dispatchAction.bind()的值 // 上一次render时使用的reducer lastRenderedReducer: reducer, // useState为固定的basicStateReducer // 上一次render时的state lastRenderedState: (initialState: any), }); // ...创建dispatch return [hook.memoizedState, dispatch.bind(this)(fiber,hook.queue,]; } function updateReducer<S, I, A>( reducer: (S, A) => S, initialArg: I, init?: I => S, ): [S, Dispatch<A>] { // 移动workInProgressHook指针,获取当前hook const hook = updateWorkInProgressHook(); const queue = hook.queue; queue.lastRenderedReducer = reducer; // ...同update与updateQueue类似的更新逻辑 if (hook.queue.pending) { // ...根据queue.pending中保存的update更新state } const dispatch: Dispatch<A> = (queue.dispatch: any); return [hook.memoizedState, dispatch.bind(this)(fiber,hook.queue,)]; }React用一个标记变量didScheduleRenderPhaseUpdate判断是否是render阶段触发的更新,防止这次更新会开启一次新的render阶段,最终会无限循环更新。- 调用阶段,执行dispatchAction (opens new window),此时该
FunctionComponent对应的fiber以及hook.queue已经通过调用bind方法预先作为参数传入。
javascriptfunction dispatchAction(fiber, queue, action) { // ...创建update var update = { eventTime: eventTime, lane: lane, suspenseConfig: suspenseConfig, action: action, eagerReducer: null, eagerState: null, next: null }; // ...将update加入queue.pending var alternate = fiber.alternate; // 通过`bind`预先保存的`fiber`与`workInProgress`全等,在对应`fiber`的`render阶段` if (fiber === currentlyRenderingFiber$1 || alternate !== null && alternate === currentlyRenderingFiber$1) { // render阶段触发的更新 didScheduleRenderPhaseUpdateDuringThisPass = didScheduleRenderPhaseUpdate = true; } else { if (fiber.lanes === NoLanes && (alternate === null || alternate.lanes === NoLanes)) { // ...fiber的updateQueue为空,优化路径 } // 调度更新 scheduleUpdateOnFiber(fiber, lane, eventTime); } }-
无论是类组件调用
setState,还是函数组件的dispatchAction,都会产生一个update对象,里面记录了此次更新的信息,然后将此update放入待更新的pending队列中,dispatchAction第二步就是判断当前函数组件的fiber对象是否处于渲染阶段,如果处于渲染阶段,那么不需要我们在更新当前函数组件,只需要更新一下当前update的expirationTime即可。 -
如果当前
fiber没有处于更新阶段。那么通过调用lastRenderedReducer获取最新的state,和上一次的currentState,进行浅比较,如果相等,那么就退出,这就证实了为什么useState,两次值相等的时候,组件不渲染的原因了,这个机制和Component模式下的setState有一定的区别。 -
如果两次
state不相等,那么调用scheduleUpdateOnFiber调度渲染当前fiber,scheduleUpdateOnFiber是react渲染更新的主要函数。
- 本质来说,
-
useEffect
- 在
flushPassiveEffects方法内部会在commit阶段的layout后从全局变量rootWithPendingPassiveEffects获取effectList。 useEffect和useLayoutEffect中也有同样的问题,所以他们都遵循"全部销毁"再"全部执行"的顺序。- 向
pendingPassiveHookEffectsUnmount数组内push数据的操作发生在layout阶段commitLayoutEffectOnFiber方法内部的schedulePassiveEffects方法中。
- 在
ini
function mountEffect(
create,
deps,
) {
const hook = mountWorkInProgressHook();
const nextDeps = deps === undefined ? null : deps;
hook.memoizedState = pushEffect(
HookHasEffect | hookEffectTag,
create, // useEffect 第一次参数,就是副作用函数
undefined,
nextDeps, // useEffect 第二次参数,deps
);
}-
pushEffect 首先创建一个
effect,判断组件如果第一次渲染,那么创建componentUpdateQueue,就是workInProgress的updateQueue。然后将effect放入updateQueue中。 -
React采用深度优先搜索算法,在render阶段遍历fiber树时,把每一个有副作用的fiber筛选出来,最后构建生成一个只带副作用的effect list链表。 在commit阶段,React拿到effect list数据后,通过遍历effect list,并根据每一个effect节点的effectTag类型,执行每个effect,从而对相应的DOM树执行更改。 -
更新阶段updateEffect ,
useEffect做的事很简单,判断两次deps相等,如果相等说明此次更新不需要执行,则直接调用pushEffect,这里注意effect的标签,hookEffectTag,如果不相等,那么更新effect,并且赋值给hook.memoizedState,这里标签是HookHasEffect | hookEffectTag,然后在commit阶段,react会通过标签来判断,是否执行当前的effect函数。 -
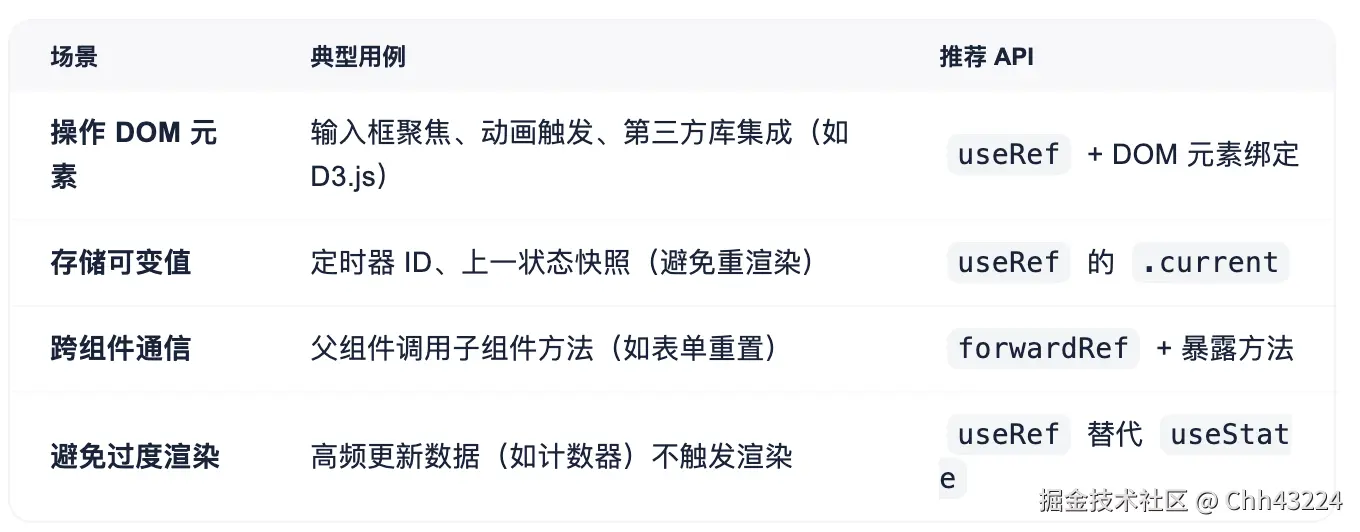
useRef
seRef仅仅是返回一个包含current属性的对象,任何需要被"引用"的数据都可以保存在ref中- 函数组件更新useRef做的事情更简单,就是返回了缓存下来的值,也就是无论函数组件怎么执行,执行多少次,
hook.memoizedState内存中都指向了一个对象,所以解释了useEffect,useMemo中,为什么useRef不需要依赖注入,就能访问到最新的改变值。
csharpfunction mountRef<T>(initialValue: T): {|current: T|} { // 获取当前useRef hook const hook = mountWorkInProgressHook(); // 创建ref const ref = {current: initialValue}; hook.memoizedState = ref; return ref; } function updateRef<T>(initialValue: T): {|current: T|} { // 获取当前useRef hook const hook = updateWorkInProgressHook(); // 返回保存的数据 return hook.memoizedState; }- 在
render阶段的beginWork中,给HostComponent、ClassComponent如果包含ref操作,那么也会赋值相应的Ref effectTag。- 对于
mount,workInProgress.ref !== null,即存在ref属性 - 对于
update,current.ref !== workInProgress.ref,即ref属性改变
- 对于
- 在
commit阶段的mutation阶段中,对于ref属性改变的情况,需要先移除之前的ref,在layout阶段重新赋值。
-
useMemo与useCallback- 执行
useMemo函数,做的事情实际很简单,就是判断两次deps是否相等,如果不想等,证明依赖项发生改变,那么执行useMemo的第一个函数,得到新的值,然后重新赋值给hook.memoizedState,如果相等 证明没有依赖项改变,那么直接获取缓存的值。
- 执行
javascript
//`mountMemo`会将`回调函数callback的执行结果作为`value`保存
//`mountCallback`会将`回调函数`作为`value`保存
function mountCallback<T>(callback: T, deps: Array<mixed> | void | null): T {
// 创建并返回当前hook
const hook = mountWorkInProgressHook();
const nextDeps = deps === undefined ? null : deps;
// 将value与deps保存在hook.memoizedState
hook.memoizedState = [callback, nextDeps];
return callback;
}
//对于`update`,这两个`hook`的唯一区别也是**是回调函数本身还是回调函数的执行结果作为value**。
function updateCallback<T>(callback: T, deps: Array<mixed> | void | null): T {
// 返回当前hook
const hook = updateWorkInProgressHook();
const nextDeps = deps === undefined ? null : deps;
const prevState = hook.memoizedState;
if (prevState !== null) {
if (nextDeps !== null) {
const prevDeps: Array<mixed> | null = prevState[1];
// 判断update前后value是否变化
if (areHookInputsEqual(nextDeps, prevDeps)) {
// 未变化
return prevState[0];
}
}
}
// 变化,将新的callback作为value
hook.memoizedState = [callback, nextDeps];
return callback;
}7.Scheduler
- 时间切片与任务调度
- Message Channel其特点是其两个端口属性支持双向通信和异步订阅发布事件(
port.postMessage(...))。 - Fiber是一个的节点对象,使用链表的形式将所有Fiber节点连接,形成链表树,链表能缓存上次中断遍历的位置
- 在
React的render阶段执行调度工作循环和计算工作循环时,执行每一个工作中Fiber,都会通过Scheduler提供的shouldYield方法(检查5毫秒是否到期的条件)判断是否需要中断遍历。 - 运行一次异步的
MessageChannel的port.postMessage(...)方法,检查是否存在事件响应、更高优先级任务或其他代码需要执行 ,如果有则执行;如果没有则判断执行完一个任务中的回调函数后,检测其是否返回函数(5毫秒时间切片过期后root.callbackNode === originalCallbackNode就会返回其自身)。若返回,则将其作为任务新的回调函数,继续进行工作循环;若未返回,则执行下一个任务的回调函数。在执行调度任务过程中,会执行requestHostCallback(...), 从而调用port.postMessage(...),执行剩下的工作中Fiber。 - 在执行完所有工作中fiber后,React进入提交步骤,更新DOM。2. 任务的回调函数返回空值,调度工作循环因此(运行任务步骤中第二点:若任务的回调函数执行后返回为空,则执行下一个任务)完成此任务,并将此任务从任务队列中删除。
- Message Channel其特点是其两个端口属性支持双向通信和异步订阅发布事件(
- 高优先级插队
-
触发点击事件后,React会运行内部的合成事件相关代码,然后执行一个执行优先级的方法(runWithPriority(UserBlockingPriority, ...)),优先级参数为"用户交互UserBlockingPriority",接着进行
setState操作。 -
在确保root被安排任务的方法(ensureRootIsScheduled),因为现在的优先级更高,调度中心取消对之前低优先级任务的安排,并将之前低优先级任务的回调置空,确保它之后不会被执行。
-
执行高优先级任务,当执行到开始计算工作中类Fiber(
class ConcurrentSchedulingExample),执行更新队列方法时,React将循环遍历工作中类fiber的update环状链表。低优先级的update被跳过,其和其后面update被保存的在baseUpdate中,此处是之后恢复低优先级的关键所在。 -
在完成优先级任务过程的提交渲染DOM步骤中,渲染DOM后,会将root的callbackNode(其名字容易误导其功能,其实就是调度任务,用callbackTask或许更合适)设为空值。
-
执行确保root被安排任务的方法中,因为baseUpdate中不为空且root的callbackNode为空值,所以创建新的任务,即重新创建一个新的低优先级任务。并将任务放入任务列表中。
-
重新执行低优先级任务,所以恢复低优先级任务一定是重新完整执行一遍。
-
redux,react-redux,中间件设计
1.redux
- redux就为我们提供了一种响应式管理公共状态的方案
javascript
import { reducer } from './reducer'
export const createStore = (reducer,applyMiddleware) => {
// 纯函数,函数体内不能修改传入的参数
// heightener(applyMiddleware)是一个高阶函数,用于增强createStore
// 如果存在heightener,则执行增强后的createStore
if (heightener) {
return heightener(createStore)(reducer)
}
let currentState = {}
let observers = [] //观察者队列
function getState() {
return currentState
}
function dispatch(action) {
currentState = reducer(currentState, action)
observers.forEach(fn => fn())
}
function subscribe(fn) {
observers.push(fn)
}
dispatch({ type: '@@REDUX_INIT' }) //初始化store数据
return { getState, subscribe, dispatch }
}
const store = createStore(reducer) //创建store
store.subscribe(() => { console.log('组件1收到store的通知') })
store.subscribe(() => { console.log('组件2收到store的通知') })
store.dispatch({ type: 'plus' }) //执行dispatch,触发store的通知复制代码2.react-redux
- Provider实现,Provider是一个组件,接收store并放进全局的
context对象,我们就能在组件中通过this.context.store这样的形式取到store,不需要再单独import store。
scala
import React from 'react'
import PropTypes from 'prop-types'
export class Provider extends React.Component {
// 需要声明静态属性childContextTypes来指定context对象的属性,是context的固定写法
static childContextTypes = {
store: PropTypes.object
}
// 实现getChildContext方法,返回context对象,也是固定写法
getChildContext() {
return { store: this.store }
}
constructor(props, context) {
super(props, context)
this.store = props.store
}
// 渲染被Provider包裹的组件
render() {
return this.props.children
}
}- connect这种设计,是装饰器模式 的实现,所谓装饰器模式,简单地说就是对类的一个包装,动态地拓展类的功能。connect以及React中的高阶组件(HoC)都是这一模式的实现。除此之外,也有更直接的原因:这种设计能够兼容ES7的
装饰器(Decorator),使得我们可以用@connect这样的方式来简化代码,有关@connect的使用可以看这篇<react-redux中connect的装饰器用法>
scala
export function connect(mapStateToProps, mapDispatchToProps) {
return function(Component) {
class Connect extends React.Component {
componentDidMount() {
//从context获取store并订阅更新
this.context.store.subscribe(this.handleStoreChange.bind(this));
}
handleStoreChange() {
// 触发更新
// 触发的方法有多种,这里为了简洁起见,直接forceUpdate强制更新,
// 也可以通过setState来触发子组件更新
this.forceUpdate()
}
render() {
return (
<Component
// 传入该组件的props,需要由connect这个高阶组件原样传回原组件
{ ...this.props }
// 根据mapStateToProps把state挂到this.props上
{ ...mapStateToProps(this.context.store.getState()) }
// 根据mapDispatchToProps把dispatch(action)挂到this.props上
{ ...mapDispatchToProps(this.context.store.dispatch) }
/>
)
}
}
//接收context的固定写法
Connect.contextTypes = {
store: PropTypes.object
}
return Connect
}
}3.中间件设计
- 中间件进一步柯里化,让next通过参数传入
javascript
const logger = store => next => action => {
console.log('进入log1')
let result = next(action)
console.log('离开log1')
return result
}
const thunk = store => next =>action => {
console.log('thunk')
const { dispatch, getState } = store
return typeof action === 'function' ? action(store.dispatch) : next(action)
}
const logger3 = store => next => action => {
console.log('进入log3')
let result = next(action)
console.log('离开log3')
return result
}
// 洋葱圈模型 进入log1,进入log3,离开log3,离开log1- 洋葱圈模型,进入log1 -> 执行next(mid2) -> 进入log2 -> 执行next(mid3) -> 进入log3 -> 执行next -> next执行完毕(dispatch) -> 离开log3 -> 回到上一层中间件,执行上层中间件next之后的语句 -> 离开log2 -> 回到中间件log1, 执行log1的next之后的语句 -> 离开log1
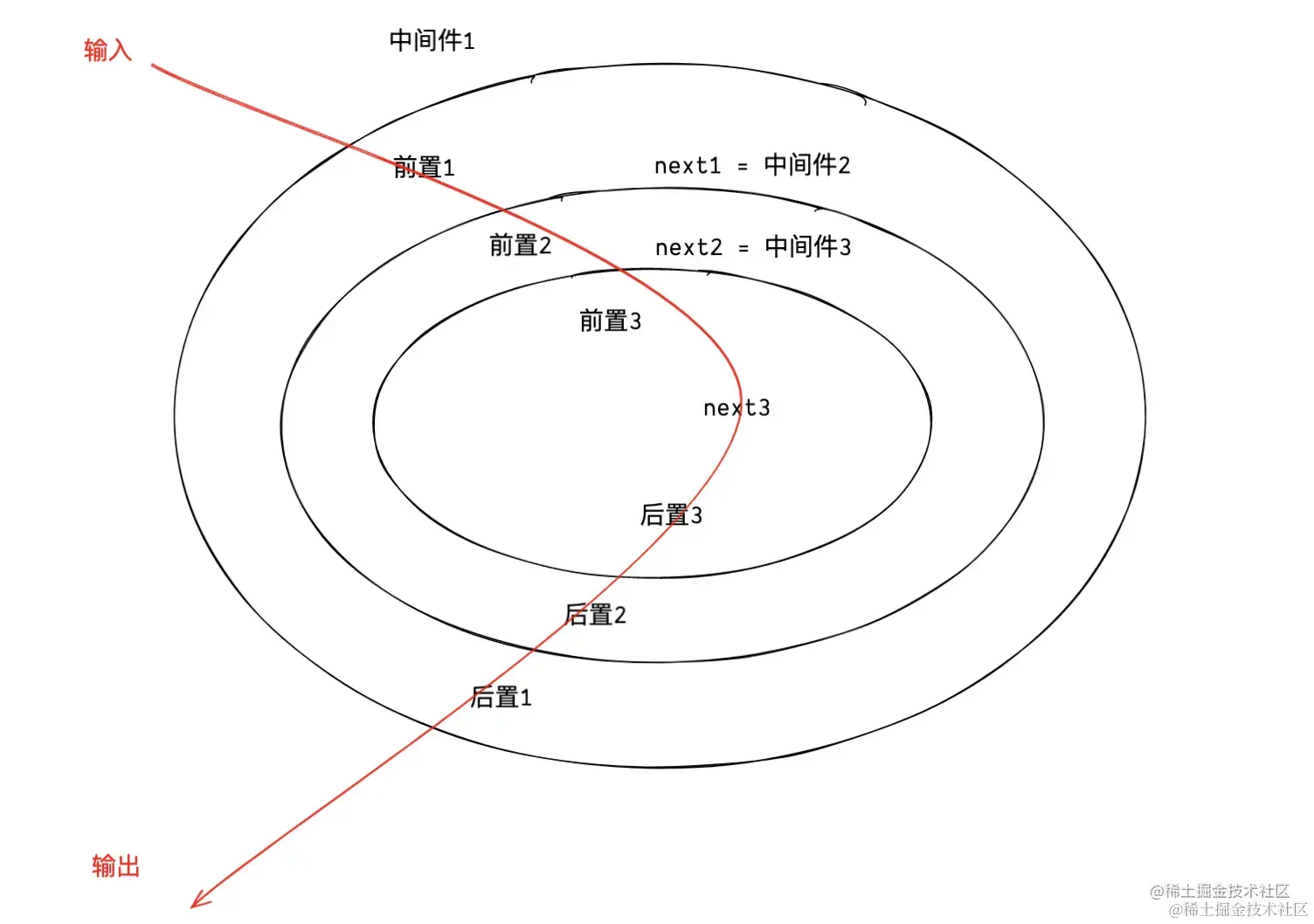
- applyMiddleware实现
javascript
const applyMiddleware = (...middlewares) => createStore => reducer => {
const store = createStore(reducer)
let { getState, dispatch } = store
const params = {
getState,
dispatch: (action) => dispatch(action)
//解释一下这里为什么不直接 dispatch: dispatch
//因为直接使用dispatch会产生闭包,导致所有中间件都共享同一个dispatch,如果有中间件修改了dispatch或者进行异步dispatch就可能出错
}
const middlewareArr = middlewares.map(middleware => middleware(params))
dispatch = compose(...middlewareArr)(dispatch)
return { ...store, dispatch }
}
// compose这一步对应了middlewares.reverse(),是函数式编程一种常见的组合方法
function compose(...fns) {
if (fns.length === 0) return arg => arg
if (fns.length === 1) return fns[0]
return fns.reduce((res, cur) =>(...args) => res(cur(...args)))
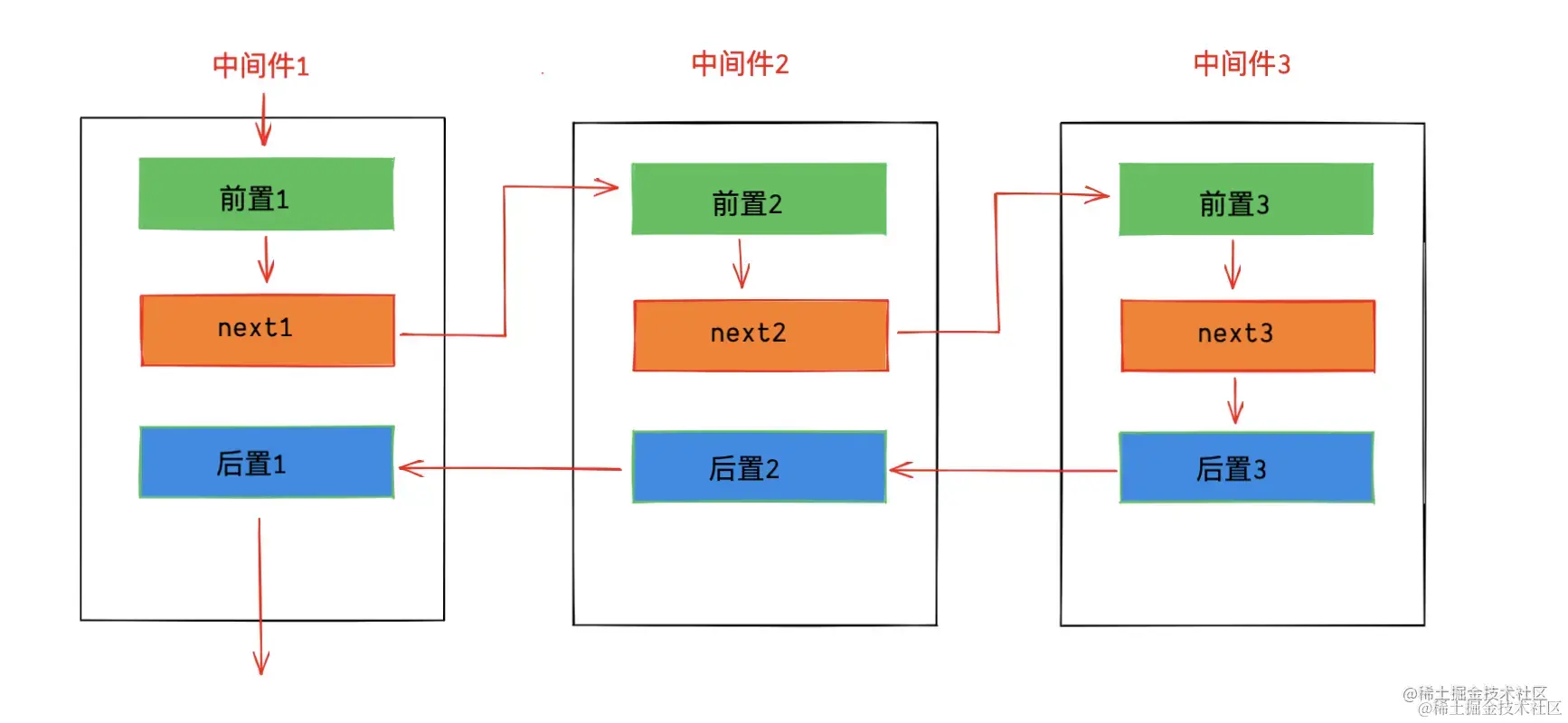
}- compose 内部使用reduce巧妙地组合了中间件函数,使传入的中间件函数变成
(...arg) => mid1(mid2(mid3(...arg)))这种形式,从右往左执行,mid3作为next传给mid2,mid2作为next传给mid1。执行mid1的next相当于执行mid2...
React事件系统工作原理
- 合成事件,在
react中,我们绑定的事件onClick等,并不是原生事件,而是由原生事件合成的React事件,比如click事件合成为onClick事件。比如blur,change,input,keydown,keyup等 , 合成为onChange。react并不是一开始,把所有的事件都绑定在document上,而是采取了一种按需绑定,比如发现了onClick事件,再去绑定document click事件。真实的dom上的click事件被单独处理,已经被react底层替换成空函数。-
React想实现一个全浏览器的框架, 为了实现这种目标就需要提供全浏览器一致性的事件系统,以此抹平不同浏览器的差异。 -
将事件绑定在
document统一管理,防止很多事件直接绑定在原生的dom元素上。从而免去了去操作removeEventListener或者同步eventlistenermap的操作,所以其执行效率将会大大提高,相当于全局给我们做了一次事件委托
-
1.事件合成,插件机制
- 在
React中,处理props中事件的时候,会根据不同的事件名称,找到对应的事件插件,然后统一绑定在document上
css
const SimpleEventPlugin = {
eventTypes:{
'click':{ /* 处理点击事件 */
phasedRegistrationNames:{
bubbled: 'onClick', // 对应的事件冒泡 - onClick
captured:'onClickCapture' //对应事件捕获阶段 - onClickCapture
},
dependencies: ['click'], //事件依赖
...
},
'blur':{ /* 处理失去焦点事件 */ },
...
}
extractEvents:function(topLevelType,targetInst,){ /* eventTypes 里面的事件对应的统一事件处理函数,接下来会重点讲到 */ }
}首先事件插件是一个对象,有两个属性,第一个extractEvents作为事件统一处理函数,第二个eventTypes是一个对象,对象保存了原生事件名和对应的配置项dispatchConfig的映射关系。由于v16React的事件是统一绑定在document上的,React用独特的事件名称比如onClick和onClickCapture,来说明我们给绑定的函数到底是在冒泡事件阶段,还是捕获事件阶段执行。
1.事件绑定
- ① 在React,调用diffProperties,diffDOM元素类型的fiber的props对象上的
memoizedProps和pendingProps的时候,如果发现是React合成事件,比如onClick,会就会调用legacyListenToEvent函数。在legacyListenToEvent函数中,先找到React合成事件对应的原生事件集合,比如 onClick -> 'click' , onChange -> `blur` , `change` , `input` , `keydown` , `keyup`,然后遍历依赖项的数组,绑定事件。 - ② 根据React合成事件类型,找到对应的原生事件的类型,然后调用判断原生事件类型,大部分事件都按照冒泡逻辑处理,少数事件会按照捕获逻辑处理(比如
scroll事件)。 - ③ 调用 addTrappedEventListener 进行真正的事件绑定,添加事件监听器
addEventListener绑定在document上,绑定我们的事件统一处理函数dispatchEvent的几个默认参数。
javascript
/*
targetContainer -> document
topLevelType -> click
capture = false
*/
function addTrappedEventListener(targetContainer,topLevelType,eventSystemFlags,capture){
const listener = dispatchEvent.bind(null,topLevelType,eventSystemFlags,targetContainer)
if(capture){
// 事件捕获阶段处理函数。
}else{
/* TODO: 重要, 这里进行真正的事件绑定。*/
targetContainer.addEventListener(topLevelType,listener,false) // document.addEventListener('click',listener,false)
}
}- ④ 有一点值得注意: 只有上述那几个特殊事件比如
scorll,focus,blur等是在事件捕获阶段发生的,其他的都是在事件冒泡阶段发生的,无论是onClick还是onClickCapture都是发生在冒泡阶段,至于 React 本身怎么处理捕获逻辑的。我们接下来会讲到。
2.事件触发
- ①首先通过统一的事件处理函数
dispatchEvent。因为dispatchEvent前三个参数已经被bind了进去,所以真正的事件源对象event,被默认绑定成第四个参数,根据事件源对象,找到e.target真实的dom元素。然后根据dom元素,找到与它对应的fiber对象。然后正式进去legacy模式的事件处理系统,进行批量更新batchedEventUpdates。
javascript
export function batchedEventUpdates(fn,a){
isBatchingEventUpdates = true;
try{
fn(a) // handleTopLevel(bookKeeping)
}finally{
isBatchingEventUpdates = false
}
}handleTopLevel最后的处理逻辑就是执行我们说的事件处理插件(SimpleEventPlugin)中的处理函数extractEvents。- 首先形成
React事件独有的合成事件源对象event,这个对象,保存了整个事件的信息,里面单独封装了比如stopPropagation和preventDefault等方法。将作为参数传递给真正的事件处理函数(handerClick)。 - 然后声明事件执行队列 ,按照
冒泡和捕获逻辑,从事件源开始逐渐向上,查找dom元素类型HostComponent对应的fiber ,收集上面的React合成事件,例如onClick/onClickCapture,对于冒泡阶段的事件(onClick),将push到执行队列后面 , 对于捕获阶段的事件(onClickCapture),将unShift到执行队列的前面。最终形成一个事件执行队列,React就是用这个队列,来模拟事件捕获->事件源->事件冒泡这一过程。 - 将事件执行队列event._dispatchListeners,保存到React事件源对象上。等待执行。
- 首先形成
- ③最后通过
runEventsInBatch执行事件队列,从上往下先执行捕获阶段再往上执行冒泡阶段 。如果发现阻止冒泡,那么break跳出循环,最后重置事件源,放回到事件池中,完成整个流程。dispatchListeners[i](event)就是执行我们的事件处理函数比如handerClick,从这里我们知道,我们在事件处理函数中,返回 false ,并不会阻止浏览器默认行为。
ini
function runEventsInBatch(){
const dispatchListeners = event._dispatchListeners;
const dispatchInstances = event._dispatchInstances;
if (Array.isArray(dispatchListeners)) {
for (let i = 0; i < dispatchListeners.length; i++) {
if (event.isPropagationStopped()) { /* 判断是否已经阻止事件冒泡 */
break;
}
dispatchListeners[i](event)
}
}
/* 执行完函数,置空两字段 */
event._dispatchListeners = null;
event._dispatchInstances = null;
}
javascript
handerClick = () => console.log(1)
handerClick1 = () => console.log(2)
handerClick2 = () => console.log(3)
handerClick3= () => console.log(4)
render(){
return <div onClick={ this.handerClick2 } onClickCapture={this.handerClick3} >
<button onClick={ this.handerClick } onClickCapture={ this.handerClick1 } className="button" >点击</button>
</div>
}打印 // 4 2 1 3
- React会在一个原生事件里触发所有相关节点(只对原生组件)的
onClick事件, 在执行这些onClick之前 React 会打开批量渲染开关,这个开关会将所有的setState变成异步函数(多次setState只会触发一次render)。 - setTimeout(() => {}),document.addEventListener('click',() => {}),Promise.then(() => {})等是是同步的,(多次setState只会触发多次render)。因为此时 batchedEventUpdates中已经执行完
isBatchingEventUpdates = false,所以批量更新被打破。
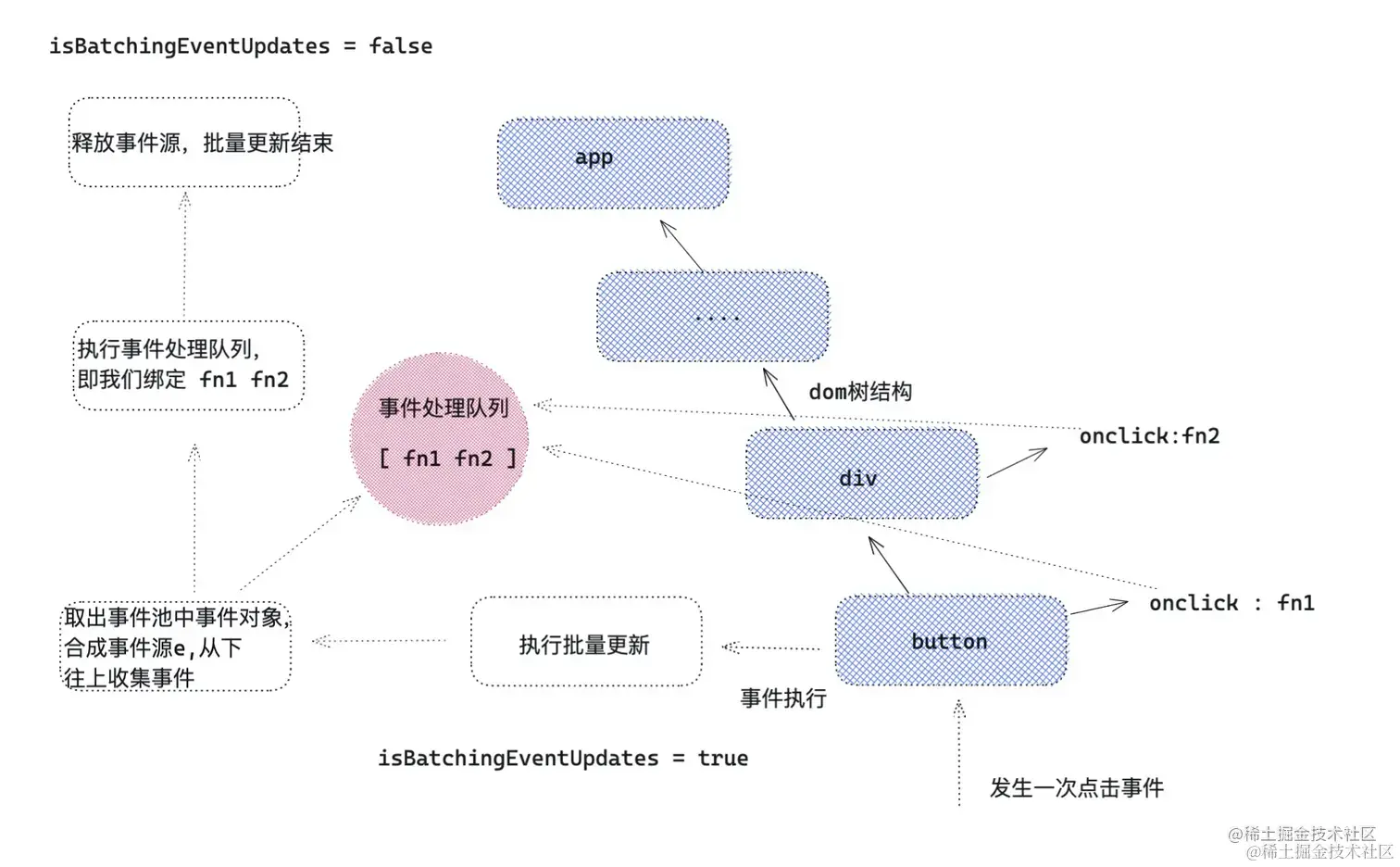
-
React v17事件
- React v17事件统一绑定container上,ReactDOM.render(app, container);而不是document上,这样好处是有利于微前端的,微前端一个前端系统中可能有多个应用,如果继续采取全部绑定在
document上,那么可能多应用下会出现问题。 React 17中终于支持了原生捕获事件的支持, 对齐了浏览器原生标准。同时onScroll事件不再进行事件冒泡。onFocus和onBlur使用原生focusin,focusout合成。- 取消事件池
React 17取消事件池复用,也就解决了上述在setTimeout打印,找不到e.target的问题。
- React v17事件统一绑定container上,ReactDOM.render(app, container);而不是document上,这样好处是有利于微前端的,微前端一个前端系统中可能有多个应用,如果继续采取全部绑定在
-
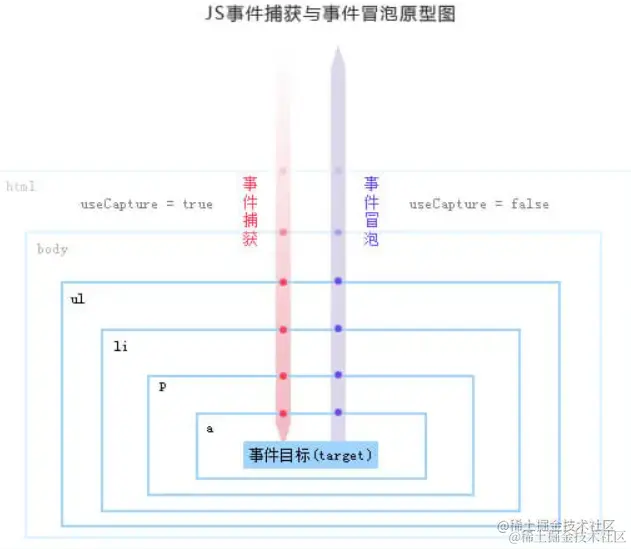
js原生事件
addEventListener(type, listener, useCapture = false);useCapture一个布尔值,表示在 DOM 树中注册了listener的元素,是否要先于它下面的EventTarget调用该listener。当 useCapture(设为 true)时,沿着 DOM 树向上冒泡的事件不会触发 listener。当一个元素嵌套了另一个元素,并且两个元素都对同一事件注册了一个处理函数时,所发生的事件冒泡和事件捕获是两种不同的事件传播方式。事件传播模式决定了元素以哪个顺序接收事件。useCapture默认为false。- 对于事件目标上的事件监听器来说,事件会处于"目标阶段",而不是冒泡阶段或者捕获阶段。捕获阶段的事件监听器会在任何非捕获阶段的事件监听器之前被调用。
DOM事件流(event flow)存在三个阶段:事件捕获阶段、处于目标阶段、事件冒泡阶段。事件捕获(event capturing): 当鼠标点击或者触发dom事件时(被触发dom事件的这个元素被叫作事件源),浏览器会从根节点 =>事件源(由外到内)进行事件传播。注册冒泡阶段的不执行事件冒泡(dubbed bubbling):当一个元素接收到事件的时候,会把他接收到的事件传给自己的父级,一直到window即事件源 =>根节点(由内到外)进行事件传播。注册捕获阶段的不执行。
React-Router原理
前端路由
- hash模式 使用hashchange事件,点击a标签hash改变不会发送到后端。在不刷新页面的前提下修改url,监听和匹配url的变化,并根据路由匹配渲染页面内容
- History模式 使用H5引入的popstate事件(点击浏览器后退、前进、a标签点击或者history.back()、history.forward()、history.go(),才会触发,pushState 和 replaceState不会触发),重写a标签的点击事件,阻止了默认的页面跳转行为,并通过(pushState增加一个 和 replaceState替换当前)无刷新地改变 url,最后渲染对应路由的内容。
- Link在最后渲染的时候其实是创建了a标签,同时添加了一个onClick的监听事件,判定是否应该阻止a标签的默认跳转,如果阻止的话,则根据replace的props值决定执行history.push还是执行history.replace。如果不阻止的话,则其实与直接a标签的写法类似了,当点击操作触发url的hash值改变。
- Link只负责触发url变更,Route只负责根据url渲染组件,history的作用是监听url变更,并同时通知Route重新渲染。
- 前置知识react context 。
- 创建一个 Context 对象。当 React 渲染一个订阅了这个 Context 对象的组件,这个组件会从组件树中离自身最近 的那个匹配的
Provider中读取到当前的 context 值。 - Provider 接收一个
value属性,传递给消费组件。一个 Provider 可以和多个消费组件有对应关系。多个 Provider 也可以嵌套使用,里层的会覆盖外层的数据。 - 当 Provider 的
value值发生变化时(使用Object.is来做比较),它内部的所有消费组件都会重新渲染。从 Provider 到其内部 consumer 组件(包括 .contextType 和 useContext)的传播不受制于shouldComponentUpdate,consumer 组件在其祖先组件跳过更新的情况下也能更新。使用memo来跳过重新渲染并不妨碍子级接收到新的 context 值。 useContext(SomeContext)用组件返回 context 的值。它被确定为传递给树中调用组件上方最近的SomeContext.Provider的value。如果没有这样的 provider,那么返回值将会是为创建该 context 传递给createContext的defaultValue。返回的值始终是最新的。如果 context 发生变化,React 会自动重新渲染读取 context 的组件。useContext 的机制是使用这个 hook 的组件在 context 发生变化时都会重新渲染。
- 创建一个 Context 对象。当 React 渲染一个订阅了这个 Context 对象的组件,这个组件会从组件树中离自身最近 的那个匹配的
ini
const MyContext = React.createContext(defaultValue);
<MyContext.Provider value={/* 某个值 */}>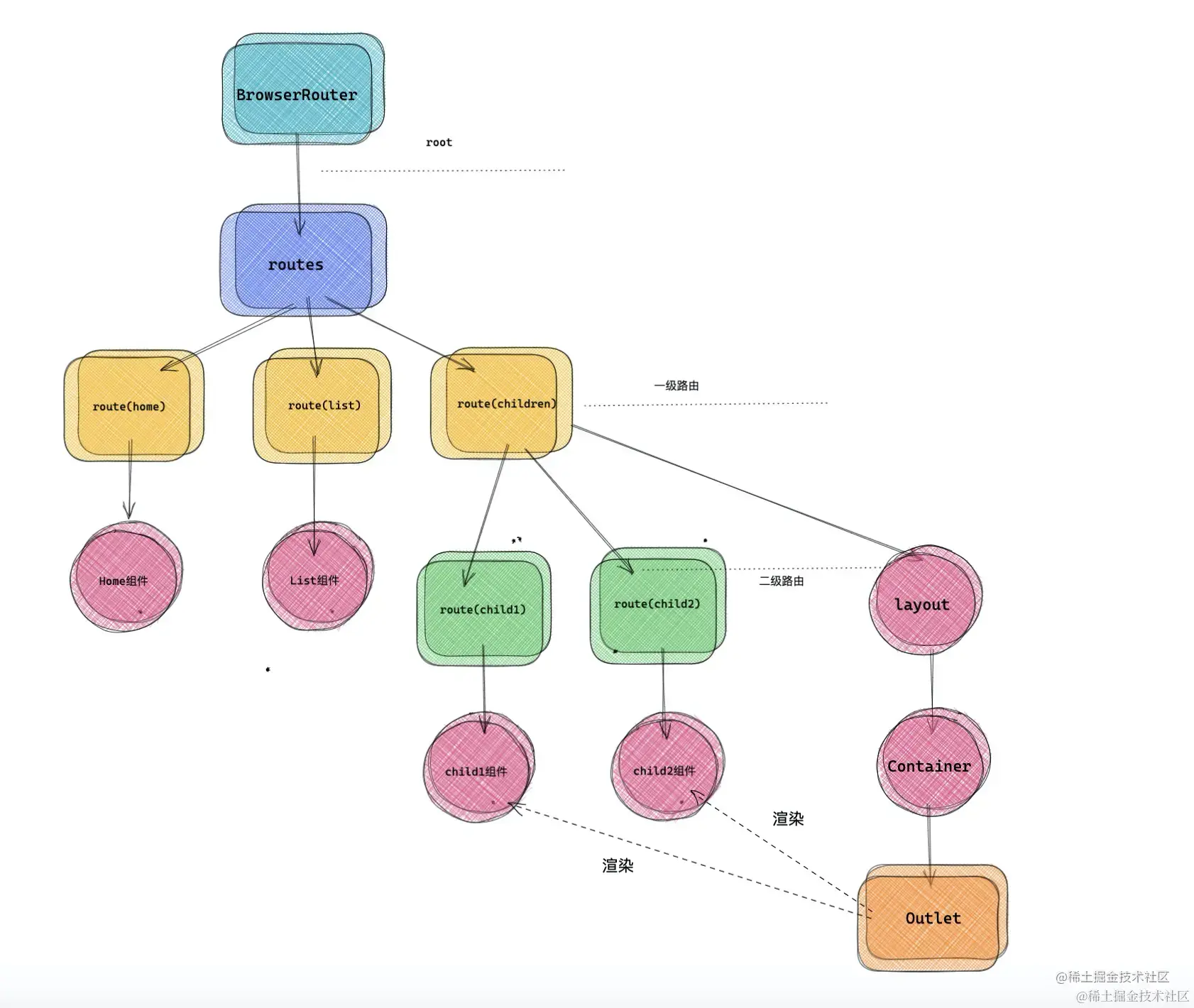
- 新版本的 router 没有
Switch组件,取而代之的是 Routes,route 必须配合 Routes 使用, - 引入 Outlet 占位功能,Outlet是真正的路由组件要挂载的地方,而且不受到组件层级的影响;使嵌套路由结构会更加清晰,不像v5一样配置二级路由,需要在业务组件中配置。
- 状态获取 (useLocation);路由跳转 (useNavigate);获取 url 上的动态路由信息 (useParams);获取,设置url 参数 (useSearchParams);路由的动态配置(useRoutes);
- 传递 history 的
NavigationContext对象,传递 location 的 LocationContext 对象,传递视图的OutletContext对象,
1.BrowserRouter与Router(v6)
- 通过
createBrowserHistory创建history对象,并通过useRef保存 history 对象。 - 当 history 发生变化(浏览器人为输入,获取 a 标签跳转,api 跳转等 )。派发更新,渲染整个 router 树。这是和老版本的区别,老版本里面,监听路由变化更新组件是在 Router 中进行的。
- 在老版本中,有一个
history对象的概念,新版本中把它叫做navigator。
ini
export function BrowserRouter({
basename,
children,
window
}: BrowserRouterProps) {
/* 通过 useRef 保存 history 对象 */
let historyRef = React.useRef<BrowserHistory>();
if (historyRef.current == null) {
historyRef.current = createBrowserHistory({ window });
}
let history = historyRef.current;
let [state, setState] = React.useState({
action: history.action,
location: history.location
});
/* history 监听histosy变化。 */
React.useLayoutEffect(() => history.listen(setState), [history]);
return (
<Router
basename={basename}
children={children}
location={state.location}
navigationType={state.action}
navigator={history}
/>
);
}- 通过 React context 来传递负责跳转路由等功能的 navigator 对象和路由信息的 location 对象。
- 当路由变化时候,在
BrowserRouter中通过 useState 改变 location ,那么当 location 变化的时候,LocationContext发生变化,消费 LocationContext 会更新。
javascript
function Router({basename,children,location:locationProp,navigator}){
/* 形成 navigationContext 对象 保存 basename , navigator 对象等信息。*/
let navigationContext = React.useMemo(
() => ({ basename, navigator, static: staticProp }),
[basename, navigator, staticProp]
);
/* 把 location 里面的状态结构出来 */
const { pathname, search, hash, state, key } = locationProp
/* 形成 locationContext 对象,保存 pathname,state 等信息。 */
let location = React.useMemo(() => {
/* .... */
return { pathname, search, hash, state, key }
},[basename, pathname, search, hash, state, key])
/* 通过 context 分别传递 navigationContext 和 locationContext */
return (
<NavigationContext.Provider value={navigationContext}>
<LocationContext.Provider
children={children}
value={{ location, navigationType }}
/>
</NavigationContext.Provider>
)
}2.useRoutes(Routes)和Outlet(v6)
- Route组件不是常规的组件,可以理解成一个空函数。Routes会过 createRoutesFromChildren 处理把 Route 组件给结构化。
- useRoutes ,可以直接把 route 配置结构变成 element 结构,并且负责展示路由匹配的路由组件,那么 useRoutes 就是整个路由体系核心
- 使用
<Routes />的时候,本质上是通过 useRoutes 返回的 react element 对象。
javascript
export function Routes({children,location }) {
return useRoutes(createRoutesFromChildren(children), location);
}
function createRoutesFromChildren(children) { /* 从把 变成层级嵌套结构 */
let routes = [];
Children.forEach(children, element => {
/* 省略 element 验证,和 flagement 处理逻辑 */
let route = {
caseSensitive: element.props.caseSensitive, // 区分大小写
element: element.props.element, // element 对象
index: element.props.index, // 索引 index
path: element.props.path // 路由路径 path
};
if (element.props.children) {
route.children = createRoutesFromChildren(element.props.children);
}
routes.push(route);
});
return routes;
}useRoutes内部用了useLocation。 当 location 对象变化的时候,useRoutes 会重新执行渲染。- 第一阶段 ,生成对应的 pathname :还是以上面的 demo 为例子,比如切换路由
/children/child1,那么 pathname 就是/children/child1。 - 通过
matchRoutes,找到匹配的路由分支。 如/children/child1,扁平化后匹配的路由结构matches,{pathname: '/children', route: {element:}, pathname: '/children/child1', route: {element:},}
javascript
function useRoutes(routes, locationArg) {
let locationFromContext = useLocation();
/* TODO: 第一阶段:计算 pathname */
// ...代码省略
/* TODO: 第二阶段:找到匹配的路由分支 */
let matches = matchRoutes(routes, {
pathname: remainingPathname
});
console.log('----match-----',matches)
/* TODO: 第三阶段:渲染对应的路由组件 */
return _renderMatches(matches && matches.map(match => Object.assign({}, match, {
params: Object.assign({}, parentParams, match.params),
pathname: joinPaths([parentPathnameBase, match.pathname]),
pathnameBase: match.pathnameBase === "/" ? parentPathnameBase : joinPaths([parentPathnameBase, match.pathnameBase])
})), parentMatches);
}
// 这一段解决了1. 第一层 route 页面是怎么渲染。2. outlet 是如何作为子路由渲染的。
// 3. 路由状态是怎么传递的。
function _renderMatches(matches, parentMatches) {
if (parentMatches === void 0) {
parentMatches = [];
}
if (matches == null) return null;
return matches.reduceRight((outlet, match, index) => {
/* 把前一项的 element ,作为下一项的 outlet */
return createElement(RouteContext.Provider, {
children: match.route.element !== undefined ? match.route.element : /*#__PURE__*/createElement(Outlet, null),
value: {
outlet,
matches: parentMatches.concat(matches.slice(0, index + 1))
}
});
}, null);
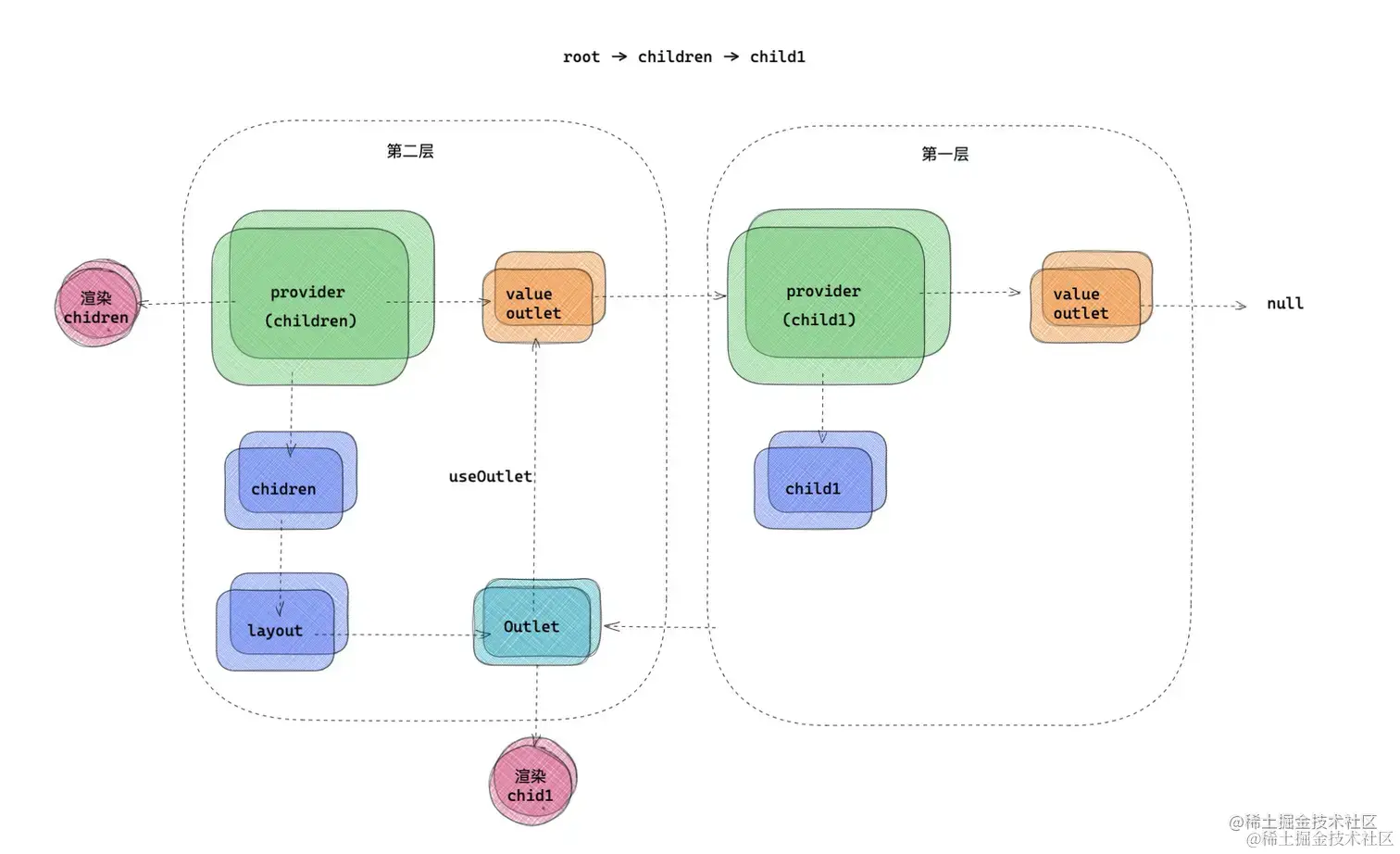
}- reduceRight 是从右向左开始遍历,match 结构是 root -> children -> child1, reduceRight 把前一项返回的内容作为后一项的 outlet(通过 provider 方式逐层传递 Outlet)
- 首先通过 provider 包裹 child1,那么 child1 真正需要渲染的内容 Child1 组件 ,将被当作 provider 的 children,最后把当前 provider 返回,child1 没有子路由,所以第一层 outlet 为 null。
- 接下来第一层返回的 provider,讲作为第二层的 outlet ,通过第二层的 provider 的 value 里面 outlet 属性传递下去。然后把 Layout 组件作为 children 返回。
- 接下来渲染的是第一层的 Provider ,所以 Layout 会被渲染,那么 Child1 并没有直接渲染,而是作为 provider 的属性传递下去。
- child1 是在
container中用Outlet占位组件的形式渲染的,用 useContext 把第一层 provider 的 outlet 获取到然后渲染就可以渲染 child1 的 provider 了,而 child1 为 children 也就会被渲染了 - 就是获取上一级的 Provider 上面的 outlet ,(在上面 demo 里就是包裹 Child1 组件的 Provider ),然后渲染 outlet ,所以二级子路由就可以正常渲染了。
javascript
export function Outlet(props: OutletProps): React.ReactElement | null {
return useOutlet(props.context);
}
export function useOutlet(context?: unknown): React.ReactElement | null {
let outlet = React.useContext(RouteContext).outlet;
if (outlet) {
return (
<OutletContext.Provider value={context}>{outlet}</OutletContext.Provider>
);
}
return outlet;
}
3.BrowserRouter 和 HashRouter(v5)
- 引入history库用不同的createHistory创建了一个 history对象,然后将其和子组件一起透传给了Router。
- history 使您可以在任何运行 JavaScript 的地方轻松管理会话历史记录。一个 history 对象可以抽象出各种环境中的差异,并提供一个最小的API,使您可以管理历史记录堆栈,导航和在会话之间保持状态
scala
const App = () => {
return (
<BrowserRouter>
<Route path="/" component={Home}></Route>
</BrowserRouter>
);
}
// <BrowserRouter> 源码
import React from "react";
import { Router } from "react-router";
import { createBrowserHistory as createHistory } from "history";
class BrowserRouter extends React.Component {
history = createHistory(this.props);
render() {
return <Router history={this.history} children={this.props.children} />;
}
}
export default BrowserRouter;
// <HashRouter> 源码
import React from "react";
import { Router } from "react-router";
import { createHashHistory as createHistory } from "history";
class HashRouter extends React.Component {
history = createHistory(this.props);
render() {
return <Router history={this.history} children={this.props.children} />;
}
}
export default HashRouter;4.Router监听location变化,派发更新(v5)
- 绑定了路由监听事件,使每次路由的改变都触发setState更新location对象(触发子组件重新渲染),给子组件包了一层context,让路由信息( history 和 location 对象)能传递给其下所有子孙组件,子孙组件(switch,route组件)在拿到当前路由信息后,取出对应的组件并传入路由信息渲染出来,通过props能获取路由信息。
- 一个项目应该有一个根
Router, 来产生切换路由组件之前的更新作用。如果存在多个Router会造成,会造成切换路由,页面不更新的情况。
kotlin
// 这个 RouterContext 并不是原生的 React Context, 由于React16和15的Context互不兼容, 所以React Router使用了一个第三方的 context 以同时兼容 React 16 和 15
// 这个 context 基于 mini-create-react-context 实现, 这个库也是React context的Polyfil, 所以可以直接认为二者用法相同
import RouterContext from "./RouterContext";
import React from 'react';
class Router extends React.Component {
// 该方法用于生成根路径的 match 对象
// 第一次看这个 match 对象可能有点懵逼, 其实后面看到 <Route> 实现的时候就能理解 match 对象的用处, 这个对象是提供给<Route>判断当前匹配页面的
static computeRootMatch(pathname) {
return { path: "/", url: "/", params: {}, isExact: pathname === "/" };
}
constructor(props) {
super(props);
// 从传入的 history 实例中取了 location 对象存到了state里, 后面会通过setState更改location来触发重新渲染
// location 对象包含 hash/pathname/search/state 等属性, 其实就是当前的路由信息
this.state = {
location: props.history.location
};
// isMounted 和 pendingLocation 这两个私有变量可能让读者有点迷惑, 源码其实也在这进行了一整段注释说明, 解释为什么在 constructor 而不是 componentDidMount 中去监听路由变化
// 简单来说, 由于子组件会比父组件更早完成挂载, 如果在 componentDidMount 进行监听, 则有可能在监听事件注册之前 history.location 已经发生改变, 因此我们需要在 constructor 中就注册监听事件, 并把改变的 location 记录下来, 等到组件挂载完了以后, 再更新到 state 上去
// 其实如果去掉这部分的hack, 这里只是简单地设置了路由监听, 并在路由改变的时候更新 state 中的路由信息
// 判断组件是否已经挂载, componentDidMount阶段会赋值为true
this._isMounted = false;
// 储存在构造函数执行阶段发生改变的location
this._pendingLocation = null;
// 判断是否处于服务端渲染 (staticContext 是 staticRouter 传入<Router>的属性, 用于服务端渲染)
if (!props.staticContext) {
// 使用 history.listen() 添加路由监听事件
this.unlisten = props.history.listen(location => {
if (this._isMounted) {
// 如果组件已经挂载, 直接更新 state 的 location
this.setState({ location });
} else {
// 如果组件未挂载, 就先把 location 存起来, 等到 didmount 阶段再 setState
this._pendingLocation = location;
}
});
}
}
// 对应构造函数里的处理, 将 _isMounted 置为 true, 并使用 setState 更新 location
componentDidMount() {
this._isMounted = true;
if (this._pendingLocation) {
this.setState({ location: this._pendingLocation });
}
}
// 组件被卸载时, 同步解绑路由的监听
componentWillUnmount() {
if (this.unlisten) this.unlisten();
}
render() {
return (
// react.createContext 创建一个 context上下文
// Provider将value向下传递给组件树上的组件
<RouterContext.Provider
// 透传子组件
children={this.props.children || null}
value={{
history: this.props.history,
// 当前路由信息
location: this.state.location,
// 是否为根路径
match: Router.computeRootMatch(this.state.location.pathname),
// 服务端渲染用到的 staticContext
staticContext: this.props.staticContext
}}
/>
);
}
}
export default Router5.Route组件页面承载容器(v5)
- 引入了
path-to-regexp来拼接路径正则以实现不同模式的匹配(生成match对象),路由组件 作为一个高阶组件包裹业务组件, 通过比较当前路由信息match对象和传入的path,以不同的优先级来渲染对应组件 - 组件的渲染逻辑,子组件> component属性传入的组件 > children是函数 这样的优先级渲染
scala
import React from "react";
import RouterContext from "./RouterContext";
import matchPath from "../utils/matchPath.js";
function isEmptyChildren(children) {
return React.Children.count(children) === 0;
}
class Route extends React.Component {
render() {
return (
{/* Consumer 接收了 <Router> 传下来的 context, 包含了history对象, location(当前路由信息), match(匹配对象)等信息 */}
<RouterContext.Consumer>
{/* 拿到路由信息
拿到 match 对象(来源优先级:Switch → props.path → context)
props.computedMatch 是 <Switch> 传下来的, 是已经计算好的match, 优先级最高
<Route> 组件上的 path 属性, 优先级第二
计算 match 对象, 下一小节会详解这个 matchPath
context 上的 match 对象
把当前的 location 和 match 拼成新的 props,这个 props 会通过 Provider 继续向下传
<Route>组件提供的三种渲染方式, 优先级 children > component > render
这里对children为空的情况做了一个兼容, 统一赋为null, 这是因为 Preact 默认使用空数组来表示没有children的情况 (Preact是一个3kb的React替代库, 挺有趣的, 读者们可以看看)
*/}
{context => {
const location = this.props.location || context.location;
const match = this.props.computedMatch
? this.props.computedMatch
: this.props.path
? matchPath(location.pathname, this.props)
: context.match;
const props = { ...context, location, match };
let { children, component, render } = this.props;
if (Array.isArray(children) && isEmptyChildren(children)) {
children = null;
}
// 把拼好的新的props通过context继续往下传
// 第一层判断: 如果有 match 对象, 就渲染子组件 children 或 Component
// 第二层判断: 如果有子组件 children, 就渲染 children, 没有就渲染 component
// 第三层判断: 如果子组件 children 是函数, 那就先执行函数, 并将路由信息 props 作为回调参数
return (
<RouterContext.Provider value={props}>
{props.match
? children
? typeof children === "function"
? children(props)
: children
: component
? React.createElement(component, props)
: render
? render(props)
: null
: typeof children === "function"
? children(props)
: null}
</RouterContext.Provider>
);
}}
</RouterContext.Consumer>
);
}
}
export default Route;