文章目录
- [AI(学习笔记第十二课) 使用langsmith的agents](#AI(学习笔记第十二课) 使用langsmith的agents)
-
- [1. `AI agents`](#1.
AI agents) -
- [1.1 什么是`AI agent`](#1.1 什么是
AI agent)
- [1.1 什么是`AI agent`](#1.1 什么是
- [2. `AI agents`的关键概念以及传统的`langchain`调用方式](#2.
AI agents的关键概念以及传统的langchain调用方式) -
- [2.1 使用`defined tool`](#2.1 使用
defined tool) - [2.2 使用`retrieve tool`](#2.2 使用
retrieve tool)
- [2.1 使用`defined tool`](#2.1 使用
- [3. 使用`AI agent`并运行`AI agent`(`AgentExecutor (Legacy)`)](#3. 使用
AI agent并运行AI agent(AgentExecutor (Legacy))) -
- [3.1 `langsmith`导入](#3.1
langsmith导入) - [3.2 `langsmith`导入的`langchain`示例代码](#3.2
langsmith导入的langchain示例代码) - [3.3 执行`langsmith`的`agent`](#3.3 执行
langsmith的agent) - [3.4 `roadmap`继续](#3.4
roadmap继续)
- [3.1 `langsmith`导入](#3.1
- [1. `AI agents`](#1.
AI(学习笔记第十二课) 使用langsmith的agents
- 什么是
AI agents -
AI agents的关键概念以及传统的langchain调用方式 - 使用
AI agent并运行AI agent(AgentExecutor (Legacy)) - 在
memory中保存AI agent
1. AI agents
1.1 什么是AI agent
前面的llm都是用户给出提示词,llm将回答的文本(output text)简单的会给用户,langchain的另外一个使用是create agents。
AI agent使用大模型llm作为reasoning engine。- 利用
llm决定采用哪个action,以及这个action的input arguments应该是什么。 - 接着将这些
action的执行结果,进一步判断,接下来进行那些action。 - 最后给出用户最终的结果。
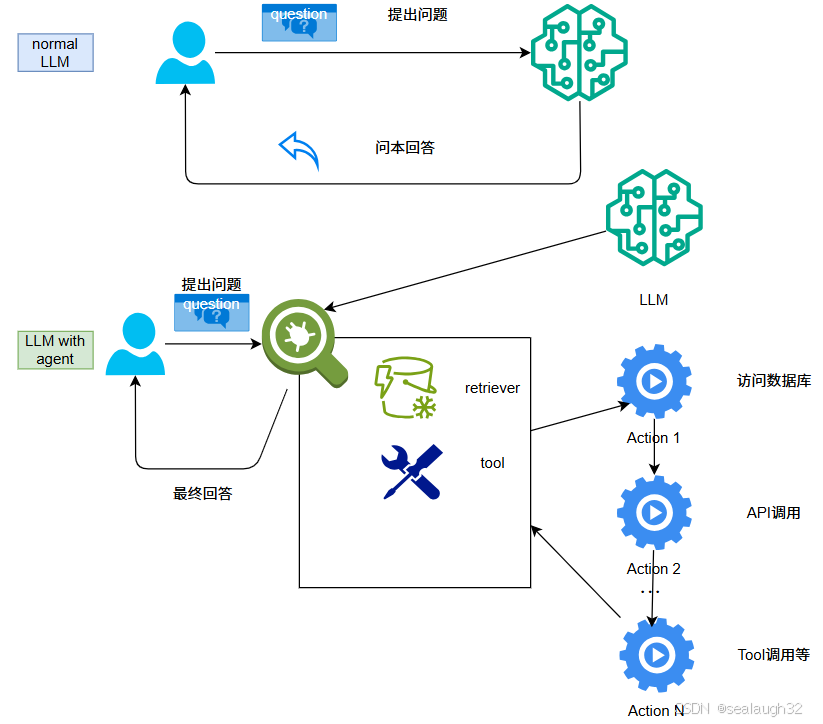
- 下面给出了通常的大模型
normal LLM和LLM with agent的比较
可以看出,normal LLM对于用户来说只能回答静态的文本回答plain text reply,但是LLM with agent却能够动起来,可以为用户执行动作API Call,Tool Call,Retrieve from internet等动作action。
2. AI agents的关键概念以及传统的langchain调用方式
2.1 使用defined tool
为什么说是defined tool呢,因为好多商用平台提供了好多提前做好的tool,所以这里称为defined tool。这里给出了tavily公司提供的tool。
这里,可以使用github的账号作为sso来登录注册tavily,之后获得API key进行工具tool的调用。
python
import os
from langchain_tavily import TavilySearch
os.environ["TAVILY_API_KEY"] = "XXXXX"
tool = TavilySearch(
max_results=5
)
result = tool.invoke({"query": "What happened at the last \
japanese election,answer with japanese"})
print(result)执行tavily工具的结果:
json
{'query': 'What happened at the last japanese election,answer with japanese', 'follow_up_questions': None, 'answer': None, 'images': [], 'results': [
{'url': 'https: //www.bbc.com/news/articles/c9xvn90yr8go', 'title': "Japan's PM vows to stay on despite bruising election loss - BBC", 'content': 'Japan\'s ruling coalition has lost its majority in the country\'s upper house, but Prime Minister Shigeru Ishiba has said he has no plans to quit. Voters went to the polls on Sunday for the tightly-contested election, being held at a time of frustration at the coalition of the Liberal Democratic Party (LDP) and its junior partner Komeito over rising prices and the threat of US tariffs. Mr Hall said some of the party\'s support had gone towards the Sanseito party - who would now be saying things which "haven\'t been said in public before by members of the upper house," - noting the party\'s pull towards "conspiracy theories, anti-foreign statements, [and] very strong revisionist views about history".', 'score': 0.43929082, 'raw_content': None}, .....(省略)可以看出,tavily的tool给出了它的搜索结果,帮助搜索到internet的很多相关资料。
2.2 使用retrieve tool
可以使用vector store的retrieve tool作为tool。
示例代码
python
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import FAISS
from langchain_core.messages import HumanMessage
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_ollama import OllamaEmbeddings
from langchain.tools.retriever import create_retriever_tool
import os
from langchain_openai import ChatOpenAI
from langchain_tavily import TavilySearch
# prepare the embedding model
embeddings_model = OllamaEmbeddings(
base_url='http://192.168.2.208:11434',
model="nomic-embed-text")
loader = WebBaseLoader("https://docs.smith.langchain.com/overview")
docs = loader.load()
documents = RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=200
).split_documents(docs)
vector = FAISS.from_documents(documents, embeddings_model)
retriever = vector.as_retriever()
retriever_tool = create_retriever_tool(
retriever,
"langsmith_search",
"Search for information about LangSmith. For any questions about LangSmith, you must use this tool!",
)
os.environ["TAVILY_API_KEY"] = "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"
tavily_tool = TavilySearch(
max_results=5
)
tools = [tavily_tool, retriever_tool]
# DeepSeek API
llm = ChatOpenAI(
api_key = 'sk-424423cbc9ef49b9b7d7d628d1568bee',
base_url = 'https://api.deepseek.com/v1',
model='deepseek-chat'# 或其他 DeepSeek 模型
)
model_with_tools = llm.bind_tools(tools)
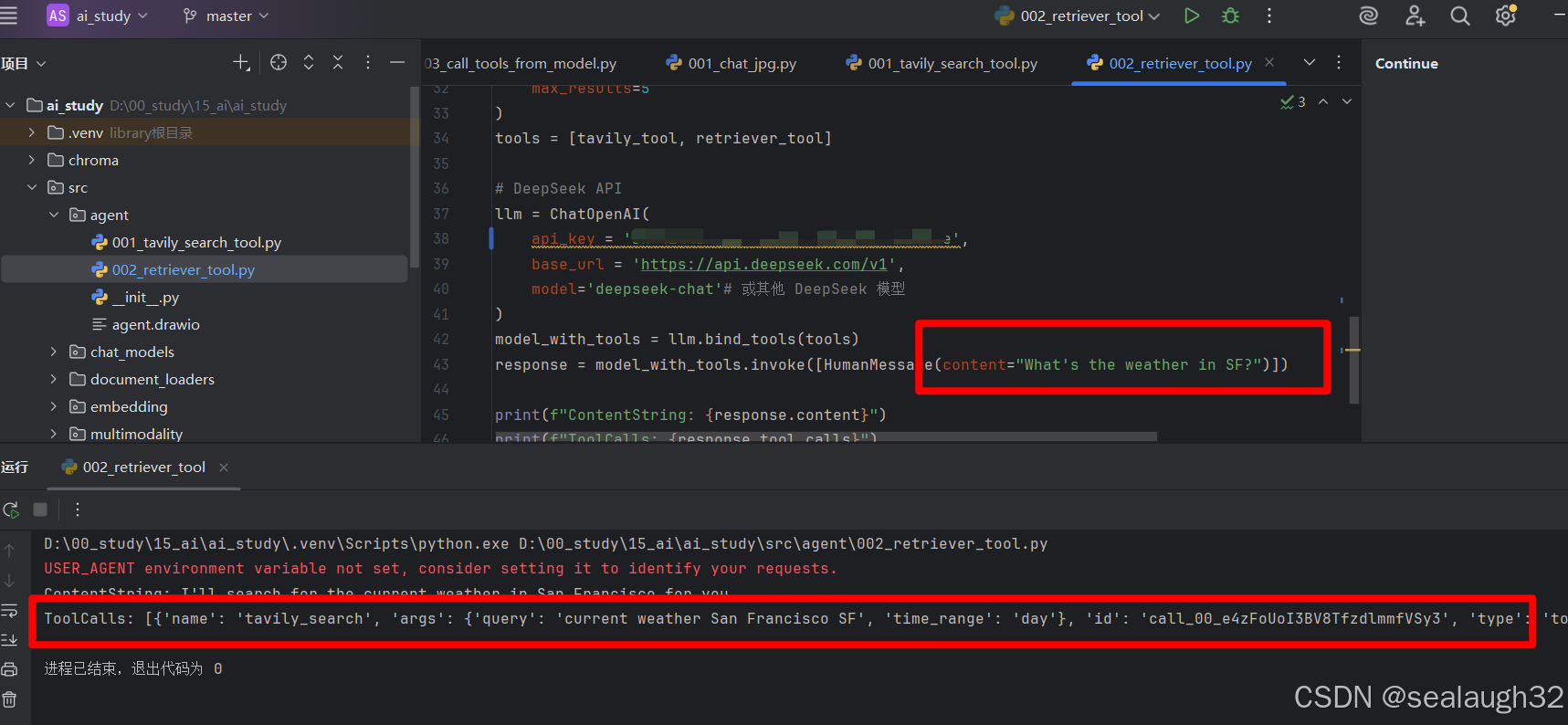
response = model_with_tools.invoke([HumanMessage(content="What's the weather in SF?")])
print(f"ContentString: {response.content}")
print(f"ToolCalls: {response.tool_calls}")这里看出,还是传统的langchain对llm绑定tool,之后对model_with_tools的大模型llm进行提问。
看看执行效果。
[HumanMessage(content="What's the weather in SF?")
这里结果是调用tavily_tool,并且大模型llm给出了必要的参数。
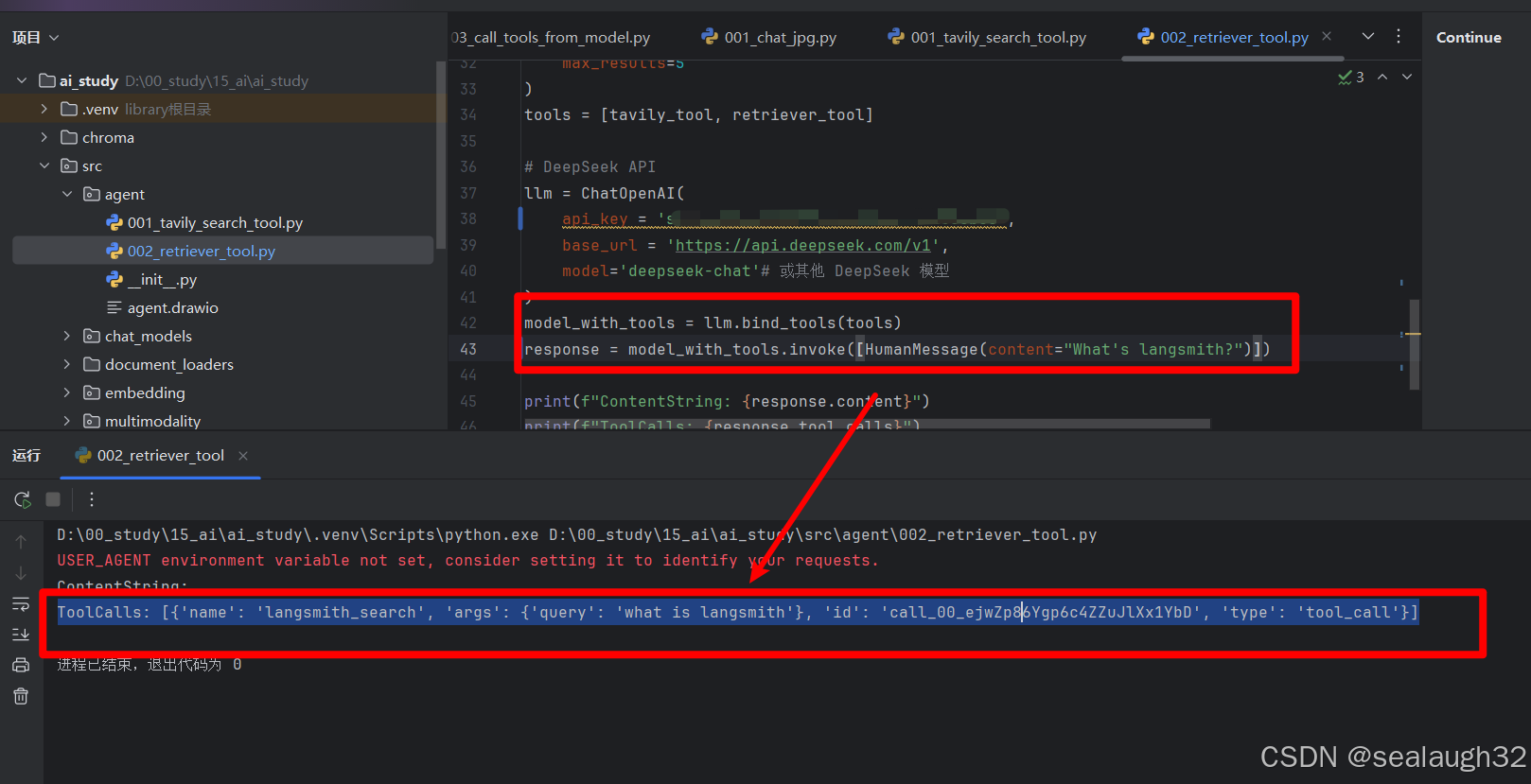
[HumanMessage(content="What's langsmith?")
ToolCalls: [{'name': 'langsmith_search', 'args': {'query': 'what is langsmith'}, 'id': 'call_00_ejwZp86Ygp6c4ZZuJlXx1YbD', 'type': 'tool_call'}]
除了传统的方法,看看AI agent能如何实现。
3. 使用AI agent并运行AI agent(AgentExecutor (Legacy))
3.1 langsmith导入
这里,langchain的agent实际上已经是开始使用langsmith了。
langsmith
LangSmith is framework agnostic --- you can use it with or without LangChain's open source frameworks langchain and langgraph.
这里可以看出,使用langsmith可以使用langchain框架,也可以使用langgraph。
3.2 langsmith导入的langchain示例代码
这里注意,langsmith需要提前登录账号langsmith home page才能使用。但是这里可以使用github的账号进行SSO登录。
python
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import FAISS
from langchain_core.messages import HumanMessage
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_ollama import OllamaEmbeddings
from langchain.tools.retriever import create_retriever_tool
import os
from langchain_openai import ChatOpenAI
from langchain_tavily import TavilySearch
from langchain.agents import create_tool_calling_agent
from langchain import hub
from langchain.agents import AgentExecutor
# prepare the embedding model
embeddings_model = OllamaEmbeddings(
base_url='http://192.168.2.208:11434',
model="nomic-embed-text")
loader = WebBaseLoader("https://docs.smith.langchain.com/overview")
docs = loader.load()
documents = RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=200
).split_documents(docs)
vector = FAISS.from_documents(documents, embeddings_model)
retriever = vector.as_retriever()
retriever_tool = create_retriever_tool(
retriever,
"langsmith_search",
"Search for information about LangSmith. For any questions about LangSmith, you must use this tool!",
)
os.environ["TAVILY_API_KEY"] = "xxxxxx"
os.environ["LANGSMITH_API_KEY"] = "xxxxxx"
tavily_tool = TavilySearch(
max_results=5
)
tools = [tavily_tool, retriever_tool]
# DeepSeek API
llm = ChatOpenAI(
api_key = 'sk-xxxxxx',
base_url = 'https://api.deepseek.com/v1',
model='deepseek-chat'# 或其他 DeepSeek 模型
)
prompt = hub.pull("hwchase17/openai-functions-agent")
print(prompt.messages)
agent = create_tool_calling_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools)
result = agent_executor.invoke({"input": "how can langsmith help with testing?"})
print(result)3.3 执行langsmith的agent
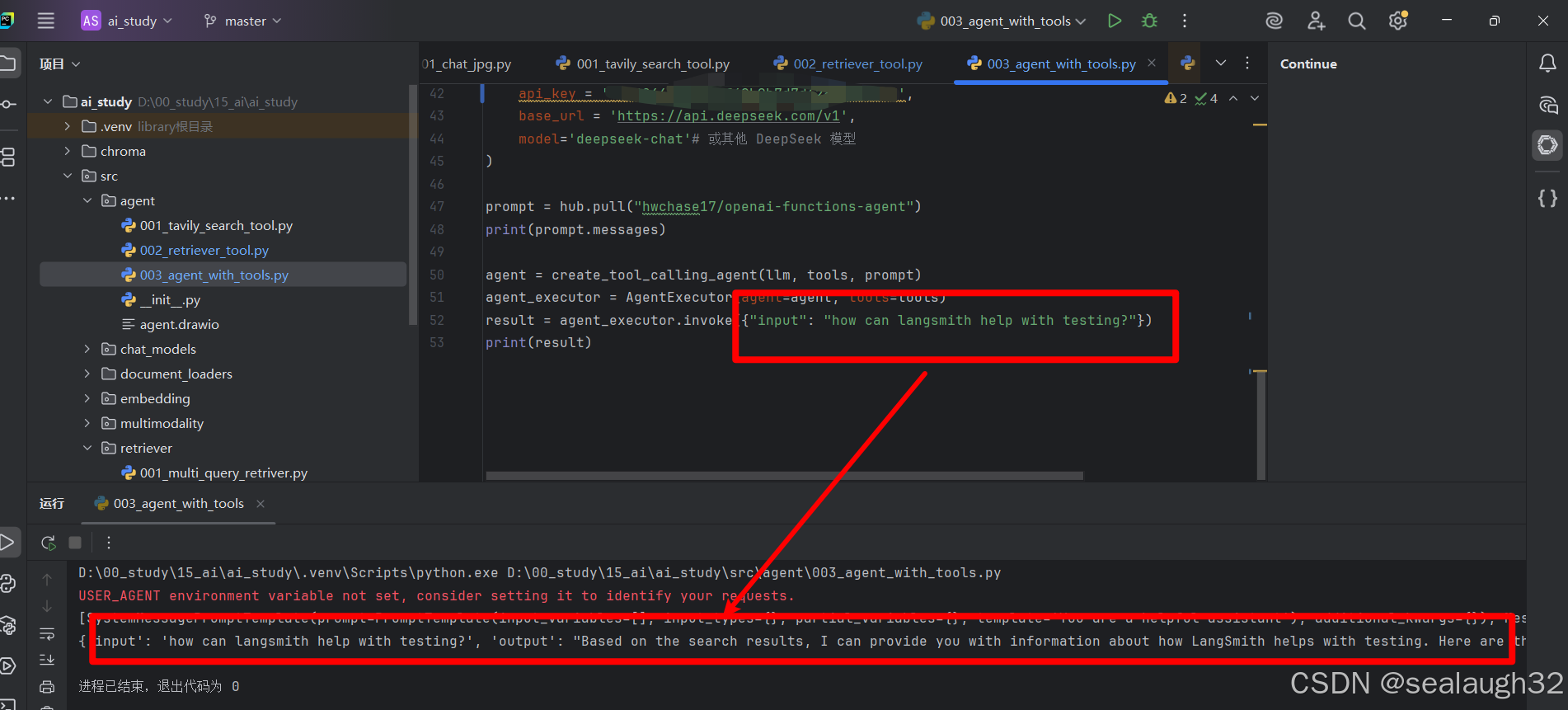
可以看到,langsmith的agent已经超过langchain的传统模式,已经可以自主调用tool,之后使用deepseek的大模型进行结果的分析,最后给出合理的回答。注意,这里llm大模型能够动起来了
Based on the search results, I can provide you with information about how LangSmith helps with testing. Here are the key ways LangSmith supports testing for LLM applications(...其他省略)3.4 roadmap继续
下次继续langchain的callbacks学习。