前言
前面我们讲过,为了提高项目的构建速度,社区将大部分的精力放到构建工具上,例如rspack、esbuild、swc等,利用语言优势提升构建速度。而像 webpack 这种老牌构建工具则将优化方向放在缓存上,但是他缓存的是构建流程中的中间结果,例如每个文件经过 loader 转换后的产物。
而本章节要介绍的任务缓存是指缓存任务执行之后的产物,例如构建或者测试任务,对于一个 package 来说,如果他的代码没发生改变,下一次执行 build 命令时可以直接读取上一次的构建产物,而无需再次进行构建,因为每次重复构建或者测试同一段代码的成本是非常昂贵的。
下面我们将专注于 Nx 的任务缓存机制,一起学习它的功能使用和原理实现。
定义缓存任务
使用 nx 创建项目时默认启用了任务缓存,开发者也可以在根目录的 nx.json 中全局配置任务缓存,也可以在每个 package 的 package.json 中单独配置。
jsx
// nx.json
{
"targetDefaults": {
"build": {
"cache": true
}
"test": {
"cache": true
}
}
}
// package.json
{
"name": "myreactapp",
...
"targets": {
"build": {
"cache": true
}
"test": {
"cache": true
}
}
}以下面这个项目为例:
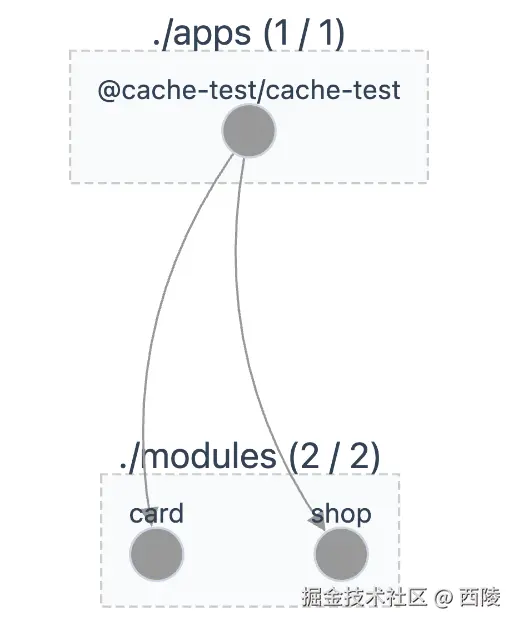
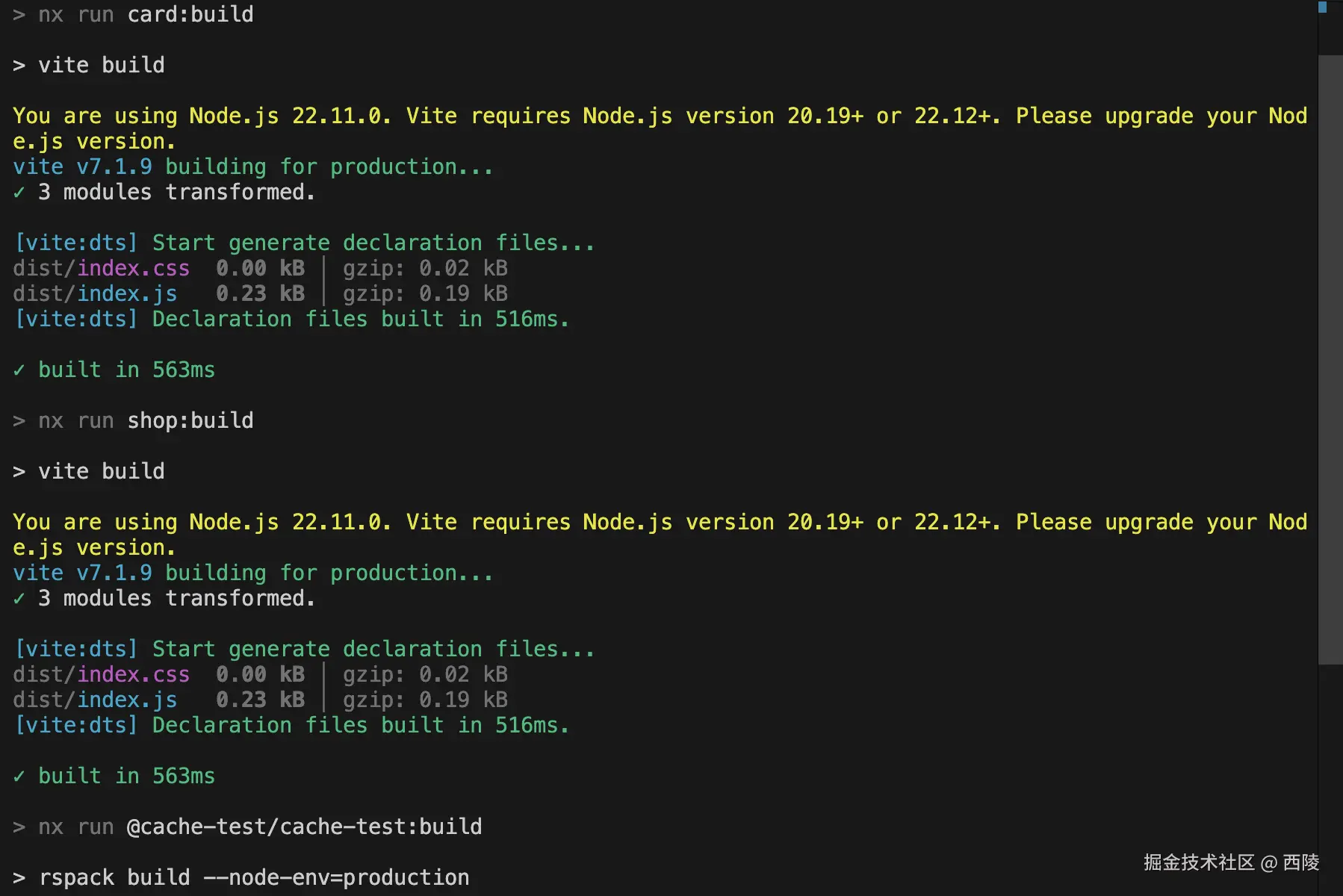
我们有一个 cache-test 项目,其依赖了 card 和 shop 这两个 package,当首次执行 cache-test 的 build 命令时,输出如下:
当修改 shop 中的代码再次执行cache-test 的 build 命令时,输出如下:
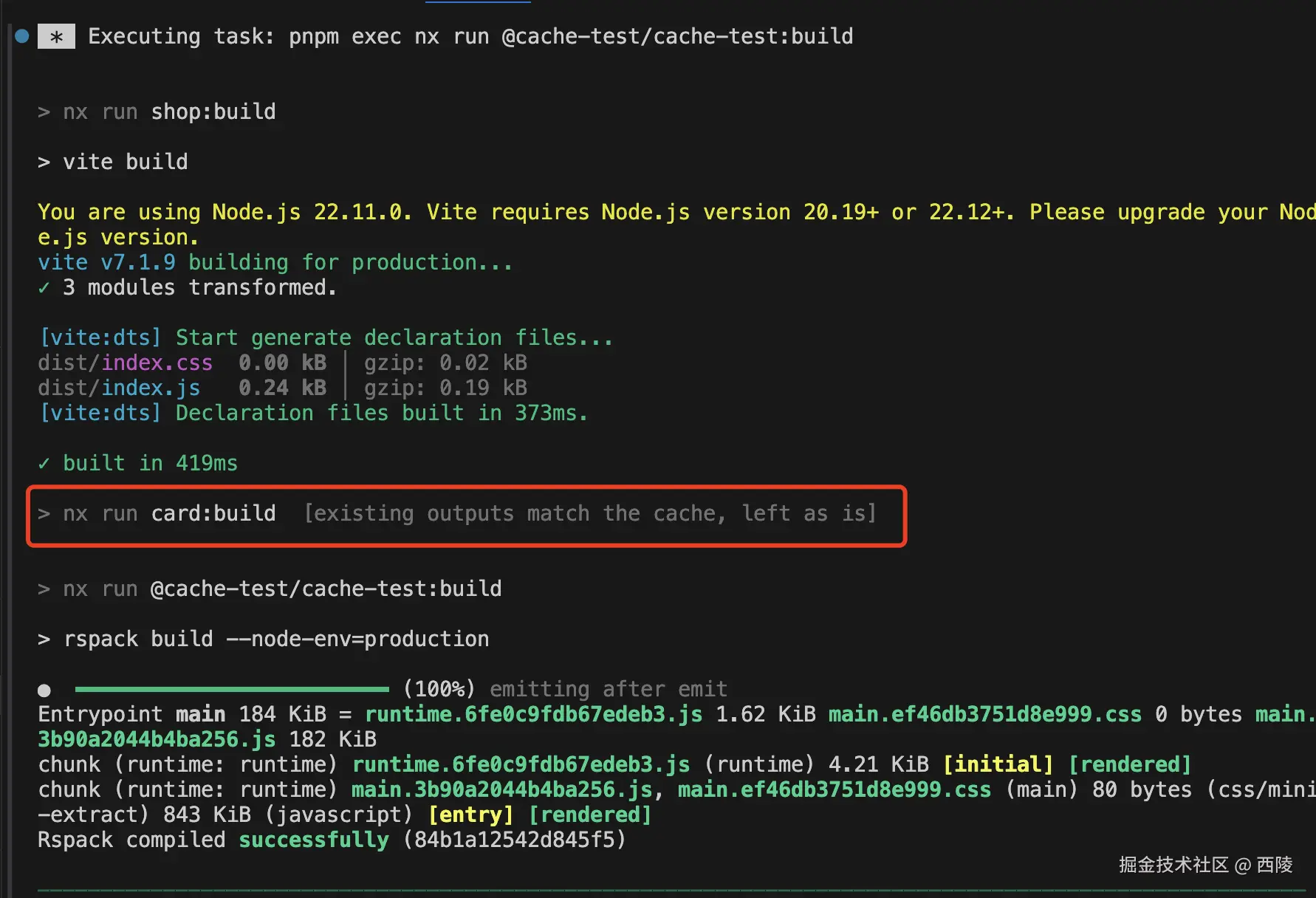
可以发现 card 并没有重新构建,而是读取的上一次构建的产物。除此之外我们分别在 shop 和 card 中添加了单测逻辑,并使用的 vitest,我们可以看下 test 任务的缓存逻辑是否生效(nx run-many --target=test),首次运行如下:
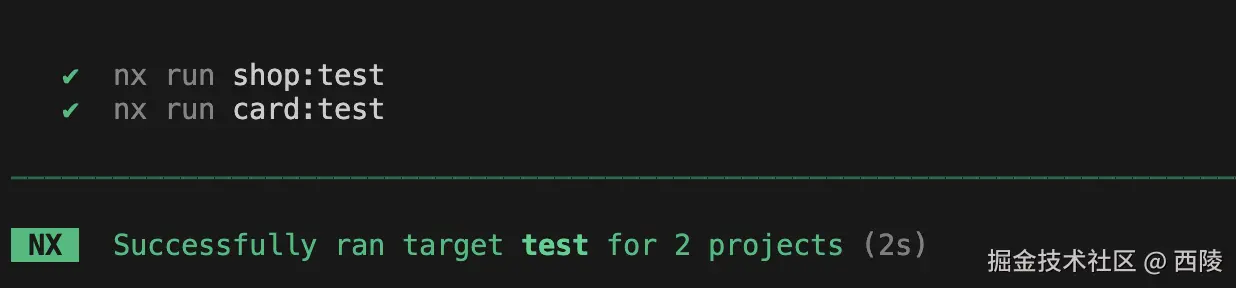
修改 card 的代码之后再次运行:
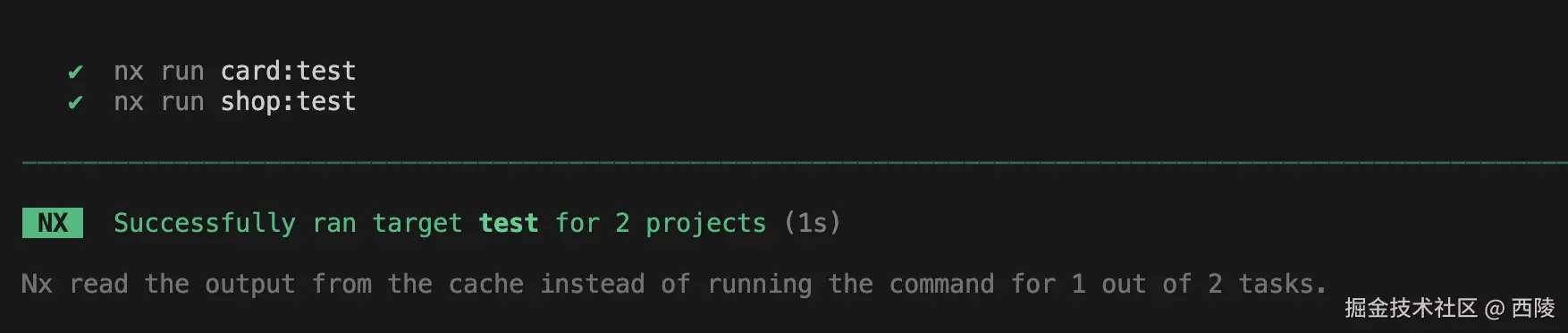
从输出结果可以看出,shop 读取的是缓存的结果。
缓存原理
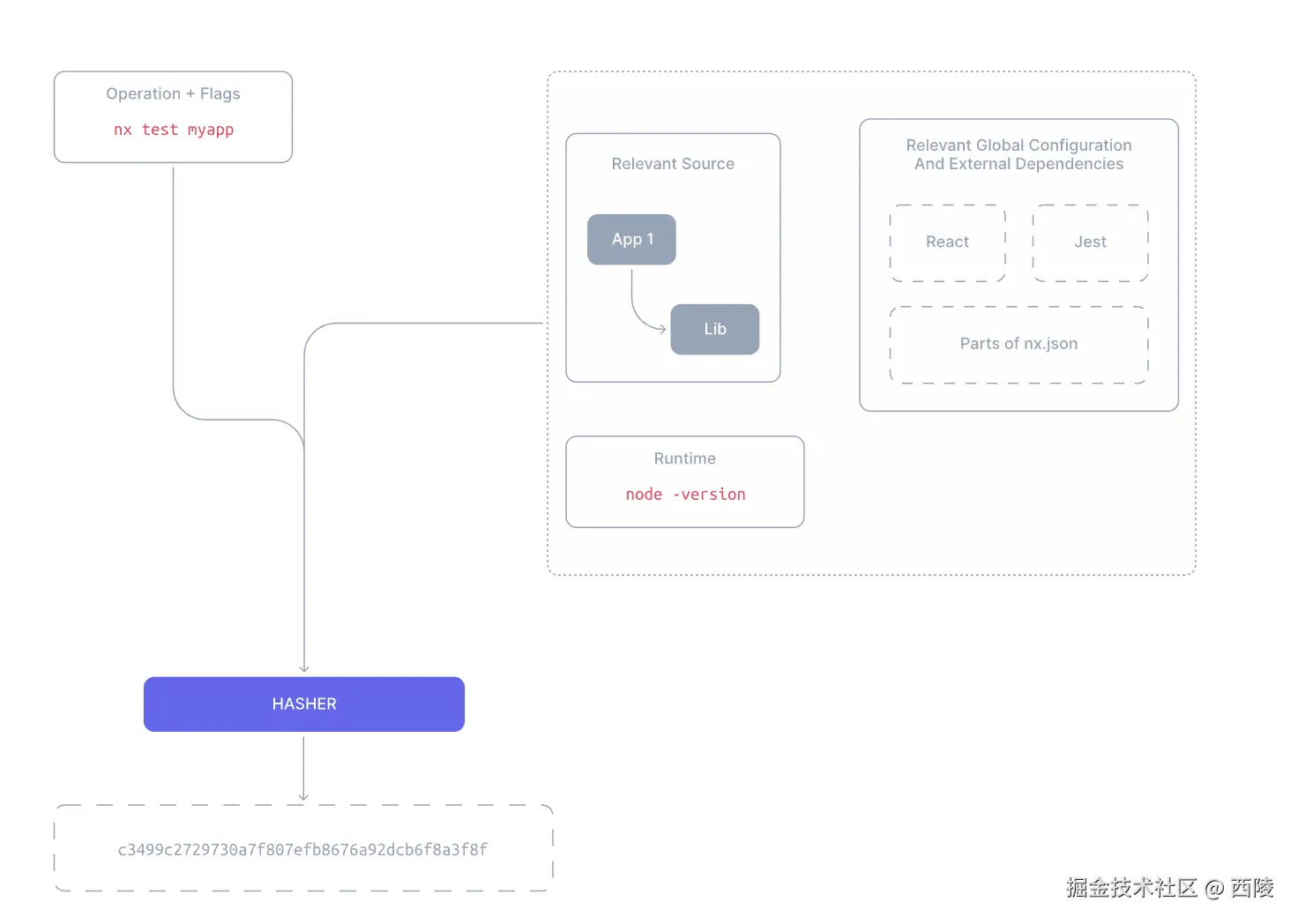
在执行任何可缓存任务之前,比如 nx build myapp 或 nx test myapp,Nx 都会预先计算一段哈希值,这个哈希值表示了:**如果输入完全一样,那么输出也会完全相同。**也就是说,只要任务的所有输入条件都没变,Nx 就可以直接用之前的缓存结果(跳过实际执行),来极大加速构建或测试。
默认情况下,对于 nx test myapp 这种任务其计算哈希的输入会包括:
- myapp 的源码以及其依赖项的源码。
- 全局配置,比如 nx.json、tsconfig.base.json。
- 第三方依赖版本。
- 运行时环境,例如 node 版本。
- 命令行参数
目前大部分 monorepo 项目管理工具都采用类似的策略实现任务缓存,例如rush.js、turborepo等。
配置输入条件
Nx 默认配置的输入条件是非常保守的,默认会把比较多的可能影响输出的内容算进去,避免漏掉导致复用过时结果,下面是 Nx 为 build 任务生成的默认输入条件:
jsx
//nx.json
{
"namedInputs": {
"default": [
"{projectRoot}/**/*",
"sharedGlobals"
],
"production": [
"default",
"!{projectRoot}/**/?(*.)+(spec|test).[jt]s?(x)?(.snap)",
"!{projectRoot}/tsconfig.spec.json",
"!{projectRoot}/src/test-setup.[jt]s"
],
"sharedGlobals": []
},
// ...
"targetDefaults": {
"build": {
"inputs": ["production", "^production"],
"cache": true
}
}
}namedInputs 中定义的是一些通用的输入集,nx 默认定义了两个输入集 default 和 production ,每个输入集中会通过特定的语法定义文件的匹配规则。而每个规则中的projectRoot 表示当前 package 的根目录。
在 targetDefaults 中配置了 build 任务的输入条件,第一个条件 production 很好理解,表示符合 production 输入集下的所有文件都作为输入内容。第二个 ^production 则表示其依赖的 package 中所有符合 production 输入集的所有文件都作为输入内容。
举个例子,我们希望将 *.md 文件从输入中排除,像 build 和 test 都不需要依赖 *.md 文件,为了实现这一点可以添加以下配置:
jsx
//nx.json
{
"namedInputs": {
"production": [
"default",
"!{projectRoot}/**/?(*.)+(spec|test).[jt]s?(x)?(.snap)",
"!{projectRoot}/tsconfig.spec.json",
"!{projectRoot}/src/test-setup.[jt]s",
+ "!{projectRoot}/**/*.md"
]
}
}总结
在本章节中我们介绍了 Nx 的一个核心功能------任务缓存,任务缓存是通过直接缓存任务的最终输出结果来提升效率,这与构建工具的缓存机制有所不同,像 webpack 这种构建工具的缓存功能缓存的是构建过程的中间结果。
接着我们介绍了如何在项目中定义任务缓存,当我们使用 Nx 的插件生成代码时,Nx 会默认给任务自动配置缓存,并设置默认的缓存输入条件。除此之外 Nx 还允许用户配置缓存的输入条件,灵活控制缓存的实效性。