我的WINDOWS机器参数:内存64GB可用40GB,CPU逻辑处理器12。
安装docker。
本地安装JDK17+MAVEN3.9+SBT1.10.7
docker搭建spark集群
脚本
version: "3.9"
services:
# ------------------- Hadoop NameNode -------------------
hadoop-namenode:
image: bde2020/hadoop-namenode:2.0.0-hadoop3.1.2-java8
container_name: hadoop-namenode
hostname: hadoop-namenode
environment:
- CLUSTER_NAME=test
- CORE_CONF_fs_defaultFS=hdfs://hadoop-namenode:8020
- HDFS_CONF_dfs_replication=1
ports:
- "9870:9870" # NameNode Web UI
- "8020:8020" # NameNode RPC
volumes:
- ./hadoop-data/namenode:/hadoop/dfs/name
networks:
- spark-net
# ------------------- Hadoop DataNode -------------------
hadoop-datanode:
image: bde2020/hadoop-datanode:2.0.0-hadoop3.1.2-java8
container_name: hadoop-datanode
hostname: hadoop-datanode
environment:
- CORE_CONF_fs_defaultFS=hdfs://hadoop-namenode:8020
- HDFS_CONF_dfs_datanode_data_dir=file:///hadoop/dfs/data
- SERVICE_PRECONDITION=hadoop-namenode:8020
depends_on:
- hadoop-namenode
volumes:
- ./hadoop-data/datanode:/hadoop/dfs/data
- ./data:/data
networks:
- spark-net
# ------------------- Spark Master -------------------
spark-master:
image: apache/spark:3.5.1
container_name: spark-master
hostname: spark-master
command: /opt/spark/sbin/start-master.sh
environment:
- SPARK_NO_DAEMONIZE=true
- SPARK_MASTER_WEBUI_PORT=8080
- SPARK_MASTER_PORT=7077
- SPARK_EVENTLOG_ENABLED=true
- SPARK_EVENTLOG_DIR=file:/opt/spark-events
- HADOOP_CONF_DIR=/opt/hadoop-conf
ports:
- "8080:8080" # Spark Master UI
- "7077:7077" # Cluster connect port
- "4040:4040" # ✅ Spark Driver UI (App Detail)
volumes:
- ./spark-events:/opt/spark-events
- ./hadoop-conf:/opt/hadoop-conf
depends_on:
- hadoop-namenode
- hadoop-datanode
networks:
- spark-net
# ------------------- Spark Worker 1 -------------------
spark-worker-1:
image: apache/spark:3.5.1
container_name: spark-worker-1
hostname: spark-worker-1
command: /opt/spark/sbin/start-worker.sh spark://spark-master:7077
environment:
- SPARK_NO_DAEMONIZE=true
- SPARK_WORKER_CORES=6
- SPARK_WORKER_MEMORY=20G
- SPARK_EVENTLOG_ENABLED=true
- SPARK_EVENTLOG_DIR=file:/opt/spark-events
- HADOOP_CONF_DIR=/opt/hadoop-conf
depends_on:
- spark-master
volumes:
- ./spark-events:/opt/spark-events
- ./hadoop-conf:/opt/hadoop-conf
networks:
- spark-net
# ------------------- Spark Worker 2 -------------------
spark-worker-2:
image: apache/spark:3.5.1
container_name: spark-worker-2
hostname: spark-worker-2
command: /opt/spark/sbin/start-worker.sh spark://spark-master:7077
environment:
- SPARK_NO_DAEMONIZE=true
- SPARK_WORKER_CORES=6
- SPARK_WORKER_MEMORY=20G
- SPARK_EVENTLOG_ENABLED=true
- SPARK_EVENTLOG_DIR=file:/opt/spark-events
- HADOOP_CONF_DIR=/opt/hadoop-conf
depends_on:
- spark-master
volumes:
- ./spark-events:/opt/spark-events
- ./hadoop-conf:/opt/hadoop-conf
networks:
- spark-net
# ------------------- ✅ Spark History Server -------------------
spark-history:
image: apache/spark:3.5.1
container_name: spark-history
hostname: spark-history
command: /opt/spark/sbin/start-history-server.sh
environment:
- SPARK_NO_DAEMONIZE=true
- SPARK_HISTORY_OPTS=-Dspark.history.fs.logDirectory=file:/opt/spark-events -Dspark.history.ui.port=18080
- SPARK_HISTORY_UI_PORT=18080
- HADOOP_CONF_DIR=/opt/hadoop-conf
ports:
- "18080:18080" # History Server Web UI
volumes:
- ./spark-events:/opt/spark-events
- ./hadoop-conf:/opt/hadoop-conf
depends_on:
- spark-master
networks:
- spark-net
networks:
spark-net:
driver: bridge文件结构
PY生成测试数据
python
import csv
import random
# ----------------------------
# 配置参数
# ----------------------------
total_records = 50_000_000 *3 # 总记录数
hot_ratio = 0.8 # 热点比例
hot_customer_id = "CUST_HOT_001"
hot_records = int(total_records * hot_ratio) # 80% 热点
normal_records = total_records - hot_records # 20% 普通客户
output_file = "claims_skewed_large.csv"
# ----------------------------
# 生成 CSV 数据
# ----------------------------
with open(output_file, "w", newline="") as f:
writer = csv.writer(f)
writer.writerow(["claim_id", "customer_id", "policy_id", "claim_amount", "claim_type", "region"])
# 生成热点客户记录
for i in range(hot_records):
claim_id = f"CLM_HOT_{i:08d}"
policy_id = f"POL_HOT_{i:08d}"
claim_amount = round(random.uniform(100, 1000), 2)
claim_type = random.choice(["car", "health", "life", "property"])
region = random.choice(["North", "South", "East", "West"])
writer.writerow([claim_id, hot_customer_id, policy_id, claim_amount, claim_type, region])
# 生成普通客户记录
for i in range(normal_records):
claim_id = f"CLM_{i:08d}"
customer_id = f"CUST_{random.randint(2, 1_000_000)}"
policy_id = f"POL_{i:08d}"
claim_amount = round(random.uniform(100, 1000), 2)
claim_type = random.choice(["car", "health", "life", "property"])
region = random.choice(["North", "South", "East", "West"])
writer.writerow([claim_id, customer_id, policy_id, claim_amount, claim_type, region])
print(f"✅ 数据生成完成: {output_file}")
print(f"总记录数: {total_records:,} 条(热点 {hot_records:,} 条,普通客户 {normal_records:,} 条)")上传数据到hdfs
docker cp D:\prj_py\test_data_gen\claims_skewed.csv hadoop-namenode:/tmp/claims_skewed.csv
docker exec -it hadoop-namenode bash
hdfs dfs -mkdir -p /data
hdfs dfs -put -f /tmp/claims_skewed.csv /data/claims_skewed.csv
编写scala rdd测试代码
spark-max-age/
├── build.sbt
├── project/
│ └── assembly.sbt
└── src/
└── main/
└── scala/
└── MaxAgeRDD.scala
build.sbt
Scala
name := "spark-max-age"
version := "1.0"
scalaVersion := "2.12.15"
// ✅ Spark 依赖
libraryDependencies ++= Seq(
"org.apache.spark" %% "spark-core" % "3.5.1" % "provided"
)
// ✅ 添加这一行(重要!)
ThisBuild / resolvers += "Aliyun Maven" at "https://maven.aliyun.com/repository/public"assembly.sbt
Scala
addSbtPlugin("com.eed3si9n" % "sbt-assembly" % "2.2.0")
Scala
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
import scala.util.Random
object GroupBySkewDemoRDD {
def main(args: Array[String]): Unit = {
// ================================
// Spark 初始化配置
// ================================
val conf = new SparkConf()
.setAppName("JoinSkewDemoRDD")
.setMaster("spark://spark-master:7077")
.set("spark.eventLog.enabled", "true")
.set("spark.eventLog.dir", "file:/opt/spark-events")
val sc = new SparkContext(conf)
// ================================
// 读取 CSV 数据
// ================================
val filePath = "hdfs://hadoop-namenode:8020/data/claims_skewed_large.csv"
// 跳过表头
val dataRDD: RDD[String] = sc.textFile(filePath)
val header = dataRDD.first()
val rows = dataRDD.filter(_ != header)
// 格式: claim_id,customer_id,policy_id,claim_amount,claim_type,region
val claims = rows.map(_.split(","))
.map(arr => (arr(1), arr(3).toDouble)) // (customer_id, claim_amount)
println(s"数据总量: ${claims.count()} 条")
// ================================
// Part 1: 普通 groupByKey(容易倾斜)
// ================================
val start1 = System.currentTimeMillis()
val groupedNormal = claims
.groupByKey()
.mapValues(values => values.sum)
groupedNormal.count() // 触发 action
val end1 = System.currentTimeMillis()
println(s"⚠️ 普通 groupByKey 执行耗时: ${(end1 - start1) / 1000.0} 秒")
// ================================
// Part 2: 加盐优化(Salting)
// ================================
val start2 = System.currentTimeMillis()
val saltGranularity = 20 // 20 段
val salted = claims.map {
case (customer_id, amount) =>
if (customer_id == "CUST_HOT_001") {
val salt = Random.nextInt(saltGranularity)
((customer_id + "_" + salt), amount)
} else {
(customer_id, amount)
}
}
// 第一次聚合(局部)
val partialAgg = salted.reduceByKey(_ + _)
// 去掉盐再聚合一次(全局)
val finalAgg = partialAgg.map {
case (saltedKey, sumAmount) =>
val baseId = saltedKey.split("_")(0)
(baseId, sumAmount)
}.reduceByKey(_ + _)
finalAgg.count() // 触发 action
val end2 = System.currentTimeMillis()
println(s"✅ 加盐优化后执行耗时: ${(end2 - start2) / 1000.0} 秒")
// ================================
// Part 3: 热点 Key 单独处理(方案 3)
// ================================
val start3 = System.currentTimeMillis()
// 1️⃣ 过滤热点客户
val hot = claims.filter(_._1 == "CUST_HOT_001")
val normal = claims.filter(_._1 != "CUST_HOT_001")
// 2️⃣ 普通客户正常聚合
val normalAgg = normal.reduceByKey(_ + _)
// 3️⃣ 热点客户单独聚合
val hotAgg = hot.reduceByKey(_ + _)
// 4️⃣ 合并结果
val combined = normalAgg.union(hotAgg)
combined.count() // 触发 action
val end3 = System.currentTimeMillis()
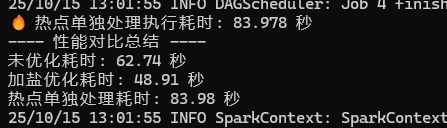
println(s"🔥 热点单独处理执行耗时: ${(end3 - start3) / 1000.0} 秒")
// ================================
// 性能对比总结
// ================================
println("---- 性能对比总结 ----")
println(f"未优化耗时: ${(end1 - start1) / 1000.0}%.2f 秒")
println(f"加盐优化耗时: ${(end2 - start2) / 1000.0}%.2f 秒")
println(f"热点单独处理耗时: ${(end3 - start3) / 1000.0}%.2f 秒")
sc.stop()
}
}打jar包上传
sbt clean assembly
docker cp target/scala-2.12/spark-max-age-assembly-1.0.jar spark-master:/tmp
执行
docker exec -it spark-master /opt/spark/bin/spark-submit --master spark://spark-master:7077 --class GroupBySkewDemoRDD --conf spark.eventLog.enabled=true --conf spark.eventLog.dir=file:/opt/spark-events --conf spark.executor.instances=4 --conf spark.executor.cores=3 --conf spark.executor.memory=10G --conf spark.driver.memory=4G --conf spark.driver.maxResultSize=2g /tmp/spark-max-age-assembly-1.0.jar
结果分析
观察SPARK UI
总览stage
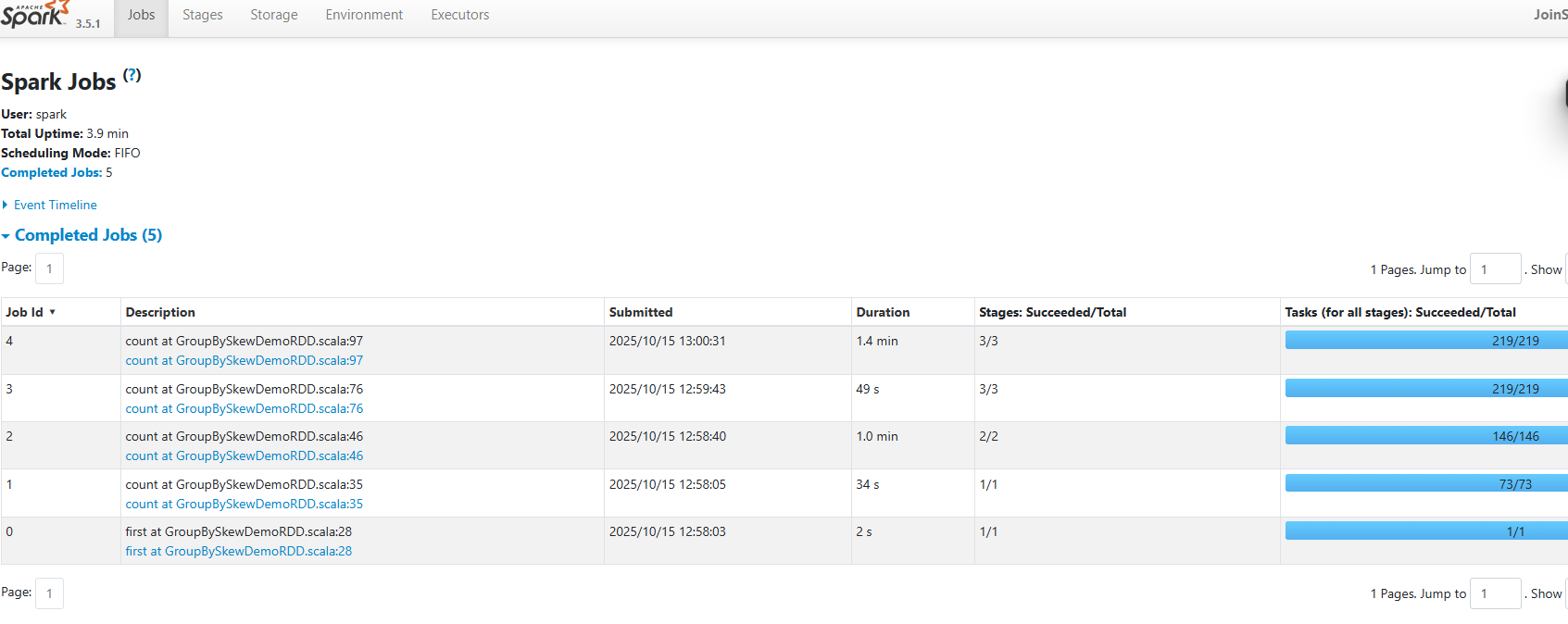
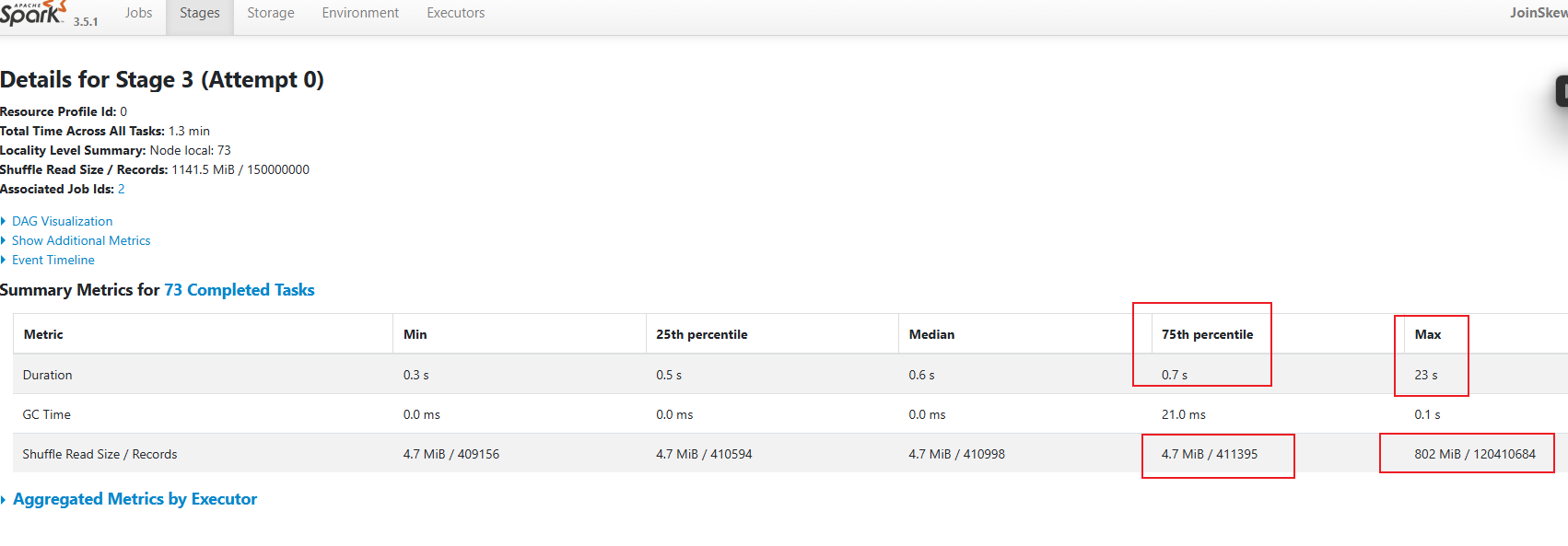
未优化
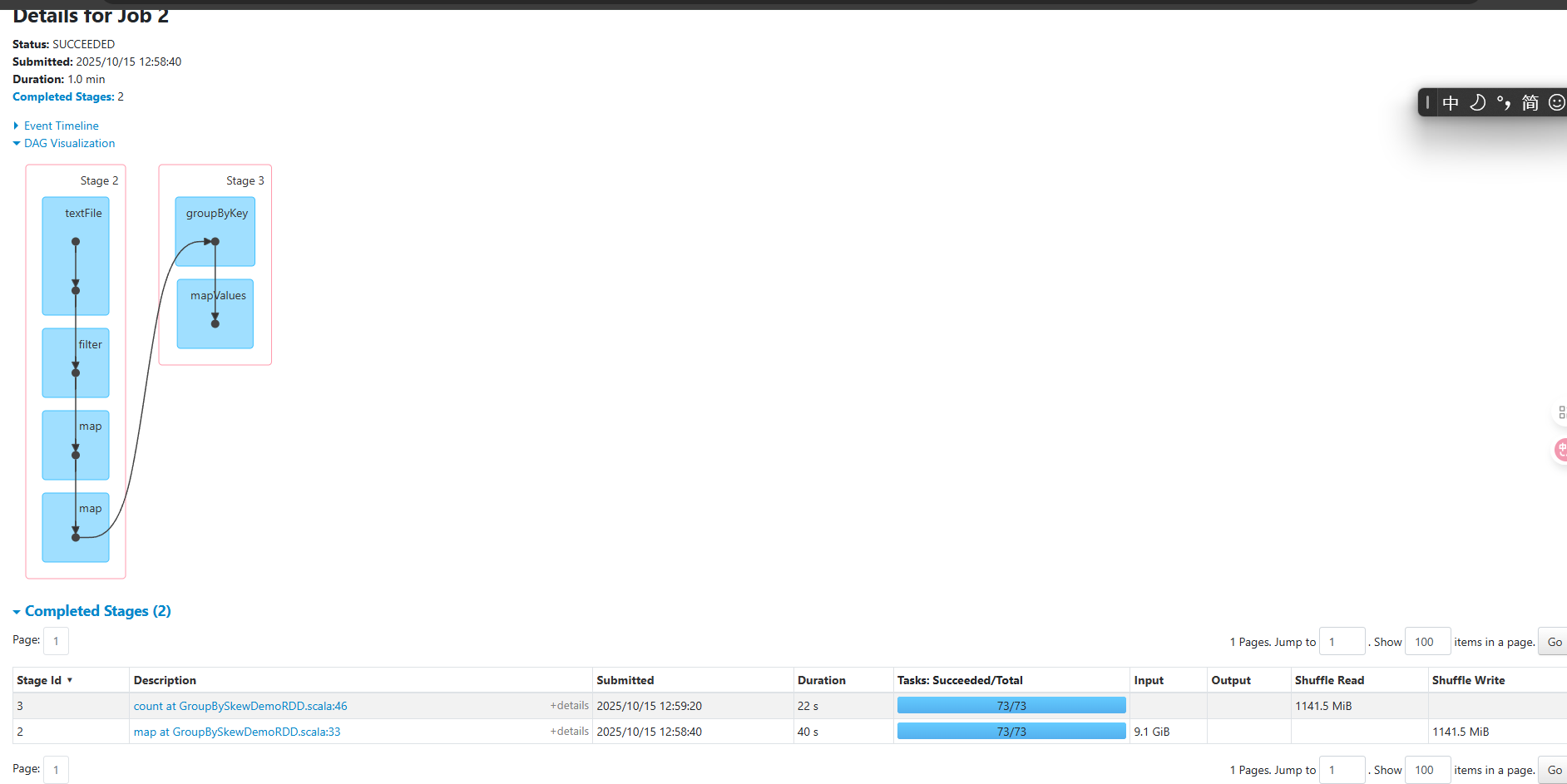
同一个stage内未优化的duration和shuffle size差距太大了
加盐优化后
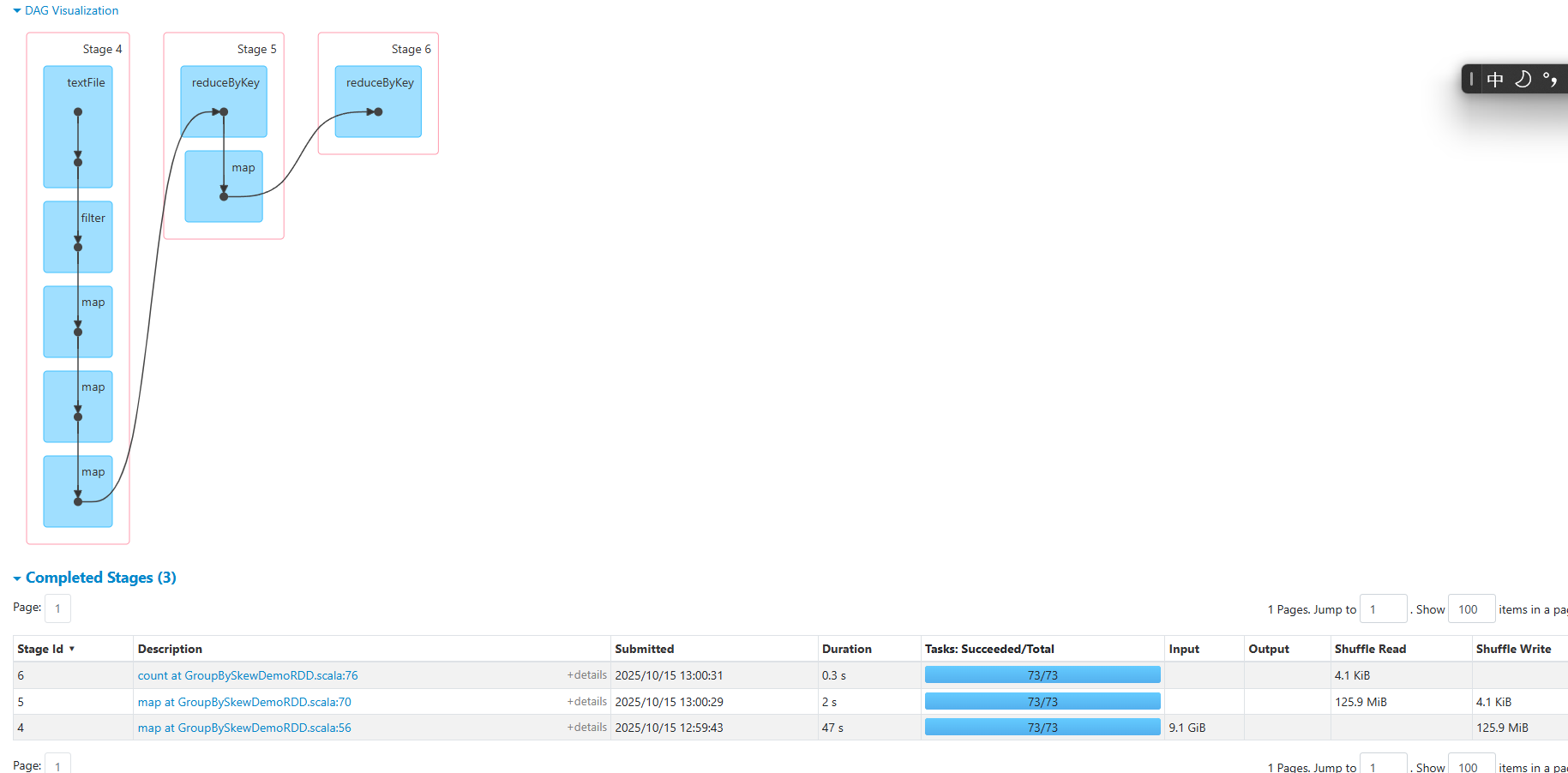
同一个stage内加盐后的duration和shuffle size很均匀
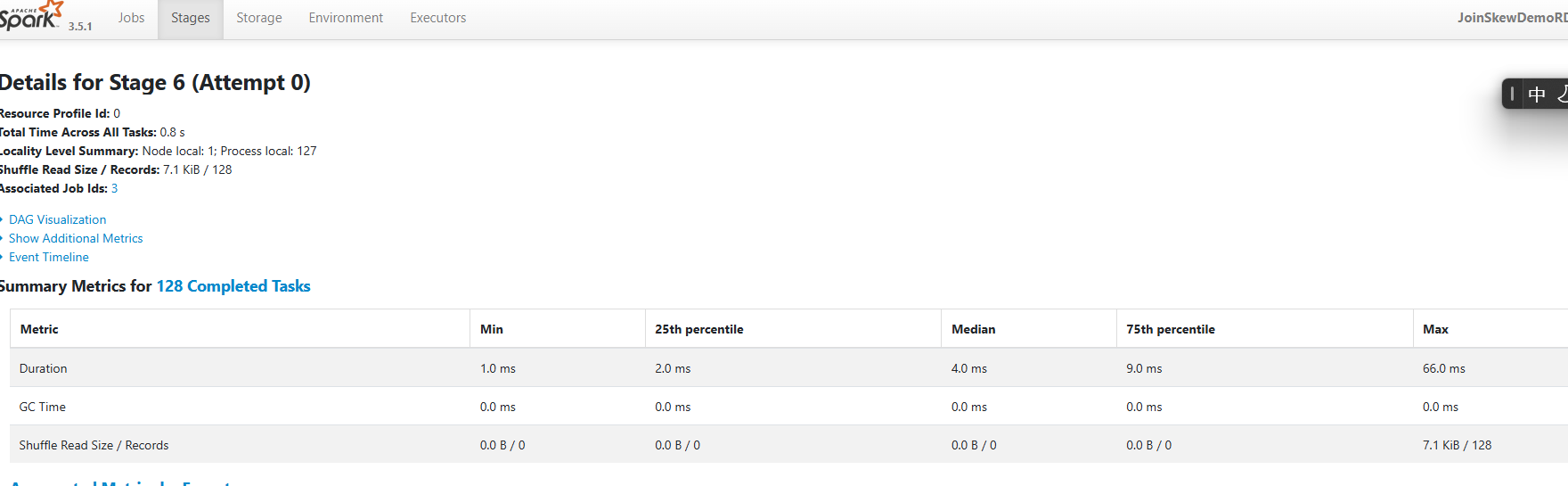
加盐优化的原理
从spark原理的角度来解析,为什么未优化之前会存在单个task的时间和shuffle size很大 ?
1️⃣ Spark Task 的划分逻辑
在 Spark 中,RDD 的 groupByKey() 会触发 Shuffle,其底层执行过程如下:
-
map 阶段:
-
每个分区(Partition)的数据会按 Key 计算 hash,决定落在哪个 Reduce 分区。
-
对应你的场景:普通客户 Key 会散列到多个 Reduce Partition;热点客户 Key
"CUST_HOT_001"因为 Key 唯一,所以 全部数据都会落到同一个 Reduce Partition。
-
-
shuffle 写入:
-
每个 map task 将分区数据写到 shuffle 文件,供对应 reduce task 拉取。
-
对热点 Key,单个 Reduce Partition 会收到绝大多数数据 → Shuffle 文件特别大。
-
-
reduce 阶段:
-
每个 Reduce Task 处理对应 Partition 的所有 Key 数据。
-
对热点 Key,对应 Task 的数据量 = 80% 总数据量 → Task 内存和计算压力巨大。
-
2️⃣ 为什么单个 Task 耗时和 Shuffle Size 大
原因一:数据倾斜(Skew)
-
定义:部分 Key 数据量远大于其他 Key
-
在你的案例:
-
"CUST_HOT_001":占总数据 80% -
其他 20% Key:平均分布到 72 个 Task
-
-
结果:
-
72 个 Task 处理少量数据 → 快(2 秒以内)
-
单个 Task 处理 80% 数据 → 慢(24 秒以上)
-
-
原理:
-
Spark 的 Stage 耗时 = 最慢 Task 耗时
-
单个 Task 成为瓶颈 → Stage 总耗时被拖慢
-
原因二:Shuffle Size 大
-
groupByKey()会把 每个 Key 的所有值都拉到 Reduce Task 内存中 -
对热点 Key:
-
1.5 亿条数据中 80% 属于单个 Key
-
Reduce Task 内存压力大 → shuffle 文件也很大
-
如果 Reduce Task 内存不足,可能触发 spill to disk 或 GC 暂停 → 时间更长
-
原因三:Executor 并行度限制
-
你配置了 executor.instances=4 × cores=3 = 12 核
-
Stage 中 73 个 Task:
-
只有 12 个 Task 同时运行
-
超过部分 Task 排队 → 部分 Task 等待 CPU → Stage 总耗时增加
-
-
对单个超大 Task:
- 数据量集中 → CPU / 内存压力大 → 执行时间远高于其他 Task
3️⃣ 图解理解(逻辑示意)
map 阶段: |----普通Key---|----普通Key---|----普通Key---|----热点Key----| shuffle 阶段: 普通Key散列到多个Reduce Partition,热点Key全部落到同一个Partition reduce 阶段: 普通Task:小数据快完成 热点Task:80%数据集中 → Task耗时长,Shuffle大小大
4️⃣ 核心 Spark 原理总结
-
RDD 分区 + Shuffle
-
groupByKey 会按 Key hash 分区
-
Key 值不均匀 → Reduce Partition 数据量极不均衡 → Task 耗时差异大
-
-
Stage 耗时 = 最慢 Task
- 单个热点 Task 拖慢整个 Stage → "长尾任务"
-
内存压力 + Shuffle 文件
-
大 Task 需要拉取大量 shuffle 数据到 Executor 内存
-
内存不足 → spill → IO 增加 → 时间更长
-
-
解决思路(原理上)
-
加盐 → 把热点 Key 拆分到多个 Reduce Partition
-
分阶段聚合 → 局部 reduce 后再全局 reduce
-
增加并行度 → 多 Task 并行执行,分散热点压力
-
💡 总结一句话:
单个 Task 时间和 shuffle size 很大,本质原因是 数据倾斜导致 Reduce Partition 数据量高度集中,groupByKey 会把所有相同 Key 数据拉到同一个 Task 处理,而 Spark Stage 的耗时由最慢 Task 决定,所以热点 Task 成为性能瓶颈。