1、问题现象
分布式下,并发更新(UPDATE/DELETE/MERGE)同一个表的时候,有时候会触发以下报错:
ERROR: concurrent update under Stream mode is not yet supported
2、原因分析
内核设计中,考虑到性能因素,对于stream算子设计为单向流算子,故不支持并行更新。
-
数据更新(update/delete)时,发现满足更新条件的记录已经被别的事物T1更新,但是事物T1尚未提交
-
执行数据更新(update/delete)的语句走了stream计划,且数据更新算子下层含有stream算子
|-----|----------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 预置条件 |||
| CREATE TABLE t1(a int, b int) DISTRIBUTE BY HASH(a); CREATE TABLE t2(a int, b int) DISTRIBUTE BY HASH(a); INSERT INTO t1 VALUES(1, 1); INSERT INTO t2 VALUES(1, 1); |||
| UPDATE/DELETE/MERGE INTO 场 景 触 发 条 件 |||
| 时间线 | SESSION 1.0 | SESSION 2.0 |
| 1 | START TRANSACTION; | START TRANSACTION; |
| 2 | UPDATE t1 SET b = 2; | |
| 3 | | -- 例1 并发undate报错 UPDATE t1 SET b = 2 FROM (SELECT * FROM t2 WHERE b = 1)t WHERE t.b = t1.a; -- 例2 并发delete报错 DELETE FROM t1 USING (SELECT * FROM t2 WHERE b = 1)t WHERE t.b = t1.a; -- 例3 并发merge报错 MERGE INTO t1 USING (SELECT * FROM t2) t ON (t.b = t1.a) WHEN MATCHED THEN UPDATE SET t1.b = t.a WHEN NOT MATCHED THEN INSERT VALUES (t.b, t.a); |
| 4 | COMMIT; | |
| 5 | | 执行报错 ERROR: concurrent update under Stream mode is not yet supported |
3)以MERGE INTO触发场景为例
示例中的MERGE INTO计划,可以看到MERGE的下层存在算子Streaming(type: REDISTRIBUTE)
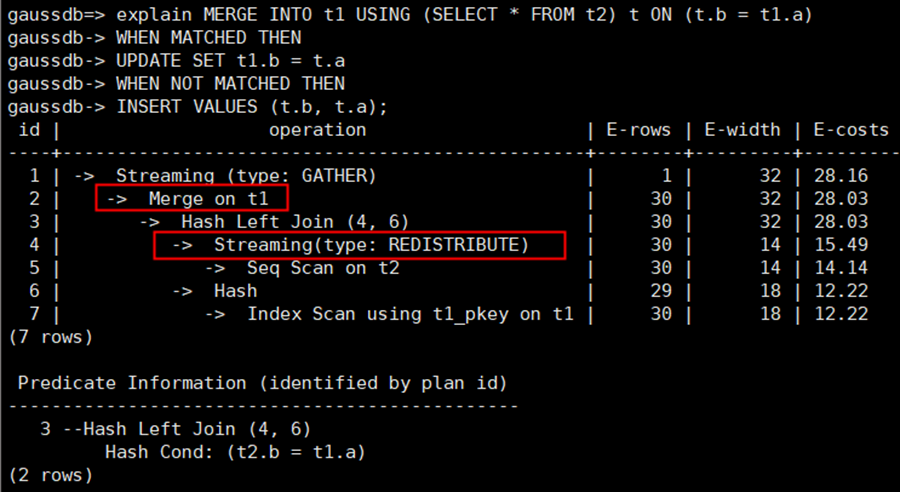
执行计划走了stream,而stream算子有并行更新的约束,导致报错。
3、解决方法
一、消除数据更新(update/delete)算子下面的stream算子,可以通过以下两个步骤解决
- 把要关联的结果集写到临时表中
实际业务场景中更新的关联结果集可能比较复杂,为了可以完美的消除stream算子,可以将关联结果集转储到一个临时表中,比如本文示例中的"SELECT * FROM t2 WHERE b = 1"这个查询就是要更新的关联结果集
1.1) 如果更新(update/delete)的目标表的分布列出现在更新关联列上,临时表的分布列设置为关联条件列,且分布列的数据类型跟对端一致
1.2) 如果更新(update/delete)的目标表的分布列没有出现在更新关联列上,临时表定义为复制表
比如当前示例中的两个SQL,数据更新(update/delete)的关联条件是 t.b = t1.a, 因此可以把关联结果集转储的中间表的分布列定义为b;
CREATE TEMP TABLE t DISTRIBUTE BY HASH(b) AS SELECT * FROM t2 WHERE b = 1;
临时表t尽量使用hash表,因为复制表实际写数据量比较大,可能会引入性能问题
- 使用临时表跟更新(update/delete)的目标表做联动更新
如本文示例,关联结果集转储之后,更新语句可以改写为如下SQL
UPDATE t1 SET b = 2 FROM t WHERE t.b = t1.a;
DELETE FROM t1 USING t WHERE t.b = t1.a;
二、通过改造MERGE INTO语句为UPSERT语法来规避并行更新报错约束
在语义上,merge into 本身不支持多并发,如果merge into目标表有唯一约束,且merge into通过此唯一约束来判断数据是否存在的话,可以考虑将merge into语法改写为upsert语法,如将示例中的merge into语句改下为如下upsert语法
insert into t1(a,b) select t2.b,t2.a from t1,t2 where t1.a = t2.b ON DUPLICATE KEY UPDATE t1.b=values(b);
|-----|----------------------|-----------------------------------------------------------------------------------------------------------|
| 预置条件 |||
| CREATE TABLE t1(a int PRIMARY KEY, b int) DISTRIBUTE BY HASH(a); CREATE TABLE t2(a int, b int) DISTRIBUTE BY HASH(a); INSERT INTO t1 VALUES(1, 1); INSERT INTO t2 VALUES(1, 1); |||
| UPSERT 改 造 后 场 景 |||
| 时间线 | SESSION 1.0 | SESSION 2.0 |
| 1 | START TRANSACTION; | START TRANSACTION; |
| 2 | UPDATE t1 SET b = 2; | |
| 3 | | insert into t1(a,b) select t2.b,t2.a from t1,t2 where t1.a = t2.b ON DUPLICATE KEY UPDATE t1.b=values(b); |
| 4 | COMMIT; | 未报错 |
| 5 | | COMMIT; |