文章目录
- 火山引擎大模型语音识别技术实践:从提交到获取完整识别结果
-
- 概述
- 核心架构设计
-
- [1. 任务处理流程](#1. 任务处理流程)
- 代码结构详解
-
- [2.1 任务提交模块](#2.1 任务提交模块)
-
- [2.1.1 请求](#2.1.1 请求)
- [2.1.2 接口地址](#2.1.2 接口地址)
- [2.1.3 响应](#2.1.3 响应)
- [2.2 状态查询模块](#2.2 状态查询模块)
- [2.3 结果获取模块](#2.3 结果获取模块)
- 关键技术特性
-
- [3.1 高级功能支持](#3.1 高级功能支持)
- [3.2 结果数据结构](#3.2 结果数据结构)
- [3.3 错误码](#3.3 错误码)
- 错误处理机制
-
- [4.1 多层级错误处理](#4.1 多层级错误处理)
- 最佳实践建议
-
- [5.1 性能优化](#5.1 性能优化)
- [5.2 数据安全](#5.2 数据安全)
- 总结
火山引擎大模型语音识别技术实践:从提交到获取完整识别结果
概述
火山引擎的大模型语音识别服务提供了高精度的音频转文字功能,特别适用于会议录音、访谈记录等场景。本文将详细解析其API调用流程和技术实现细节。
核心架构设计
1. 任务处理流程
整个识别过程采用异步任务机制,分为三个主要阶段:
提交任务 → 轮询状态 → 获取结果大模型录音文件识别服务的处理流程分为提交任务和查询结果两个阶段
任务提交:提交音频链接,并获取服务端分配的任务 ID
结果查询:通过任务 ID 查询转写结果
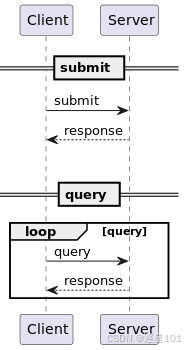
这种设计有效处理了长音频文件识别耗时较长的问题,保证了服务的稳定性和可扩展性。
代码结构详解
2.1 任务提交模块
2.1.1 请求

2.1.2 接口地址
火山地址:
bash
https://openspeech.bytedance.com/api/v3/auc/bigmodel/submit
python
def submit_task():
submit_url = "https://openspeech.bytedance.com/api/v3/auc/bigmodel/submit"
task_id = str(uuid.uuid4())
headers = {
"X-Api-App-Key": appid,
"X-Api-Access-Key": token,
"X-Api-Resource-Id": "volc.bigasr.auc",
"X-Api-Request-Id": task_id,
"X-Api-Sequence": "-1"
}
request = {
"user": {
"uid": "fake_uid"
},
"audio": {
"url": file_url,
"format": "mp3",
"codec": "raw",
},
"request": {
"model_name": "bigmodel",
"model_version": "400",
"enable_itn": True,
"enable_punc": True,
"enable_ddc": True,
"show_utterances": True,
"enable_channel_split": True,
"enable_speaker_info": True,
"corpus": {
"boosting_table_name": "test",
"correct_table_name": "",
"context": ""
}
}
}
print(f'Submit task id: {task_id}')
response = requests.post(submit_url, data=json.dumps(request), headers=headers)
if 'X-Api-Status-Code' in response.headers and response.headers["X-Api-Status-Code"] == "20000000":
print(f'Submit task response header X-Api-Status-Code: {response.headers["X-Api-Status-Code"]}')
print(f'Submit task response header X-Api-Message: {response.headers["X-Api-Message"]}')
x_tt_logid = response.headers.get("X-Tt-Logid", "")
print(f'Submit task response header X-Tt-Logid: {response.headers["X-Tt-Logid"]}\n')
return task_id, x_tt_logid
else:
print(f'Submit task failed and the response headers are: {response.headers}')
exit(1)
return task_id, x_tt_logid请求体关键参数说明:
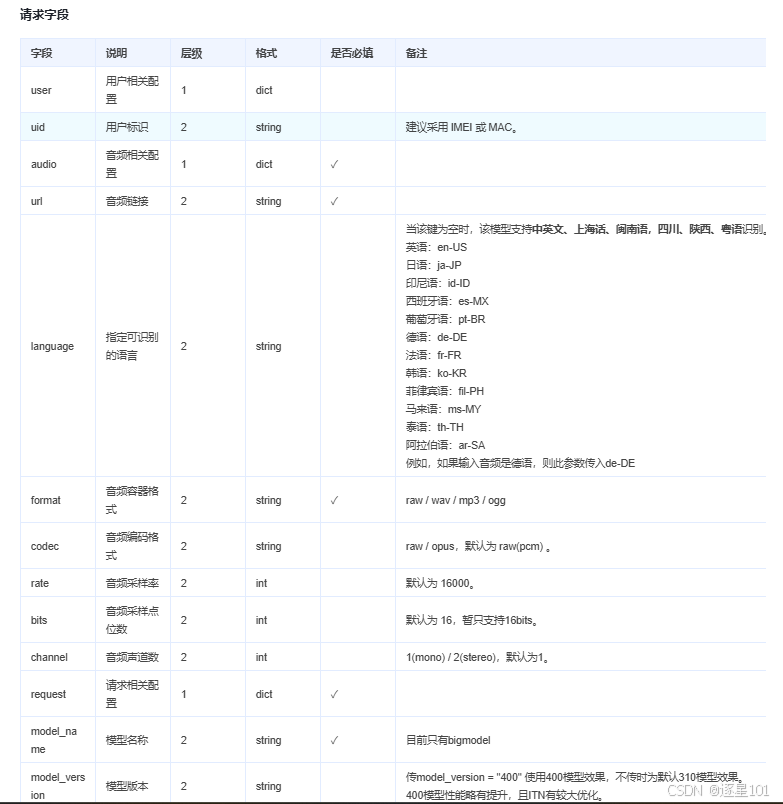
python
request = {
"user": {
"uid": "388808087185088"
},
"audio": {
"url": file_url, # 音频文件URL(支持多种存储方式)
"format": "mp3", # 音频格式
"codec": "raw", # 编码格式
},
"request": {
"model_name": "bigmodel", # 使用大模型引擎
"model_version": "400", # 模型版本
"enable_itn": True, # 启用逆文本归一化
"enable_punc": True, # 启用标点符号
"enable_ddc": True, # 启用数字转换
"show_utterances": True, # 显示分句结果
"enable_channel_split": True, # 支持声道分离
"enable_speaker_info": True, # 启用说话人分离
}
}2.1.3 响应
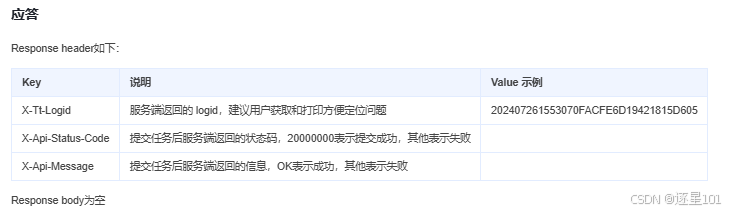
2.2 状态查询模块
接口地址
火山地址:
bash
https://openspeech.bytedance.com/api/v3/auc/bigmodel/query
bash
def query_task(task_id, x_tt_logid):
query_url = "https://openspeech.bytedance.com/api/v3/auc/bigmodel/query"
headers = {
"X-Api-App-Key": appid,
"X-Api-Access-Key": token,
"X-Api-Resource-Id": "volc.bigasr.auc",
"X-Api-Request-Id": task_id,
"X-Tt-Logid": x_tt_logid # 固定传递 x-tt-logid
}
response = requests.post(query_url, json.dumps({}), headers=headers)
if 'X-Api-Status-Code' in response.headers:
print(f'Query task response header X-Api-Status-Code: {response.headers["X-Api-Status-Code"]}')
print(f'Query task response header X-Api-Message: {response.headers["X-Api-Message"]}')
print(f'Query task response header X-Tt-Logid: {response.headers["X-Tt-Logid"]}\n')
else:
print(f'Query task failed and the response headers are: {response.headers}')
exit(1)
return response
python
def query_task(task_id, x_tt_logid):
headers = {
"X-Api-App-Key": appid,
"X-Api-Access-Key": token,
"X-Api-Resource-Id": "volc.bigasr.auc",
"X-Api-Request-Id": task_id,
"X-Tt-Logid": x_tt_logid # 链路追踪ID,用于问题排查
}X-Api-Request-Id 请求自定义的uuid 必传项
用于提交和查询任务的任务ID。查询时需使用提交成功的任务Id
67ee89ba-7050-4c04-a3d7-ac61a63499b3状态码说明:
20000000:任务完成,可获取结果20000001:任务排队中20000002:任务处理中- 其他:任务失败
2.3 结果获取模块
python
def query_result(task_id, x_tt_logid):
while True:
query_response = query_task(task_id, x_tt_logid)
code = query_response.headers.get('X-Api-Status-Code', "")
if code == '20000000': # 任务完成
result_json = query_response.json()
utterances = result_json.get('result', {}).get('utterances', [])
# 格式化对话内容
conversation_text = format_conversation(utterances)
return {
'status': 'success',
'text': result_json.get('result', {}).get('text', ''),
'utterances': utterances,
'conversation_text': conversation_text
}关键技术特性
3.1 高级功能支持
-
说话人分离 (
enable_speaker_info)- 自动识别不同说话人
- 为每个语音片段标注说话人ID
-
智能文本处理
- 逆文本归一化:将"一百"转为"100"
- 自动标点:添加合适的标点符号
- 数字转换:处理数字相关表达
-
多声道支持 (
enable_channel_split)- 支持立体声音频分离
- 分别处理不同声道内容
3.2 结果数据结构
成功响应的JSON结构包含:
bash
{
"audio_info": {"duration": 709126},
"result": {
"additions": {"duration": "709126"},
"text": "喂,董老板。",
"utterances": [{
"additions": {"channel_id": "1", "speaker": "1"},
"end_time": 1930, "start_time": 770,
"text": "喂,董老板。",
"words": [
{"confidence": 0, "end_time": 1330, "start_time": 770, "text": "喂"},
{"confidence": 0, "end_time": 1570, "start_time": 1530, "text": "董"},
{"confidence": 0, "end_time": 1810, "start_time": 1730, "text": "老"},
{"confidence": 0, "end_time": 1930, "start_time": 1850, "text": "板"}
]
}]
}
}3.3 错误码
| 错误码 | 含义 | 说明 |
|---|---|---|
| 20000000 | 成功 | |
| 20000001 | 正在处理中 | |
| 20000002 | 任务在队列中 | |
| 20000003 | 静音音频 | 返回该错误码无需重新query,直接重新submit |
| 45000001 | 请求参数无效 | 请求参数缺失必需字段 / 字段值无效 / 重复请求。 |
| 45000002 | 空音频 | |
| 45000151 | 音频格式不正确 | |
| 550xxxx | 服务内部处理错误 | |
| 55000031 | 服务器繁忙 | 服务过载,无法处理当前请求。 |
错误处理机制
4.1 多层级错误处理
python
try:
task_id, x_tt_logid = submit_task()
return query_result(task_id, x_tt_logid)
except Exception as e:
return {
'status': 'error',
'message': str(e)
}状态返回类型:
success:完全成功partial_success:结果可用但格式化失败failed:任务处理失败error:系统级错误
最佳实践建议
5.1 性能优化
-
适当的轮询间隔
pythontime.sleep(2) # 2秒间隔,避免过多请求 -
合理的超时设置
- 根据音频长度调整等待时间
- 长音频可能需要更长的处理时间
5.2 数据安全
-
凭证管理
- 妥善保管
appid和token - 避免在代码中硬编码敏感信息
- 妥善保管
-
链路追踪
- 利用
X-Tt-Logid进行问题排查 - 记录完整的请求-响应链路
- 利用
总结
火山引擎大模型语音识别API提供了强大而灵活的语音转文本服务。通过异步任务处理、丰富的功能选项和健全的错误处理机制,能够满足各种复杂场景下的语音识别需求。本文详细解析了其技术实现细节,为开发者提供了完整的集成参考。
该服务的核心优势在于:
- 高精度识别效果
- 丰富的后处理功能
- 稳定的异步处理架构
对于需要处理会议录音、访谈记录、客服电话等场景,提供可靠服务