目录
大家在日常开发中应该能发现,单表的CRUD功能代码重复度很高,也没有什么难度。而这部分代码量往往比较大,开发起来比较费时。
因此,目前企业中都会使用一些组件来简化或省略单表的CRUD开发工作。目前在国内使用较多的一个组件就是MybatisPlus。MyBatisPlus官网
当然,MybatisPlus不仅仅可以简化单表操作,而且还对Mybatis的功能有很多的增强。可以让我们的开发更加的简单,高效。
通过今天的学习,我们要达成下面的目标:
-
能利用MybatisPlus实现基本的CRUD
-
会使用条件构造器构建查询和更新语句
-
会使用MybatisPlus中的常用注解
-
会使用MybatisPlus处理枚举、JSON类型字段
-
会使用MybatisPlus实现分页
1、快速入门
为了方便测试,我们先准备一个用于演示测试的项目,并准备一些基础数据。
1.1、环境准备
1.1.1、导入项目
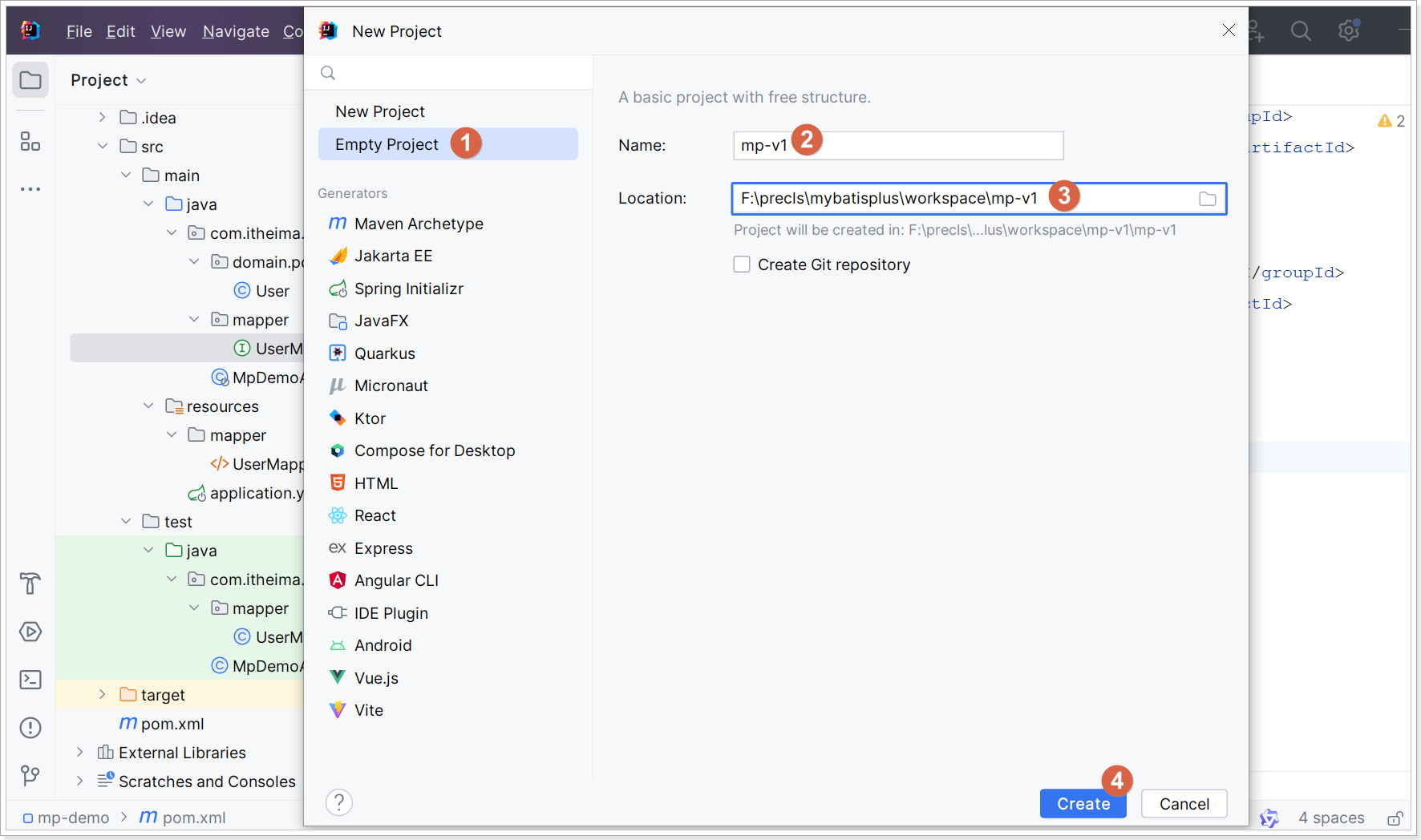
使用IDEA创建一个空工程;


1.1.2、初始化数据
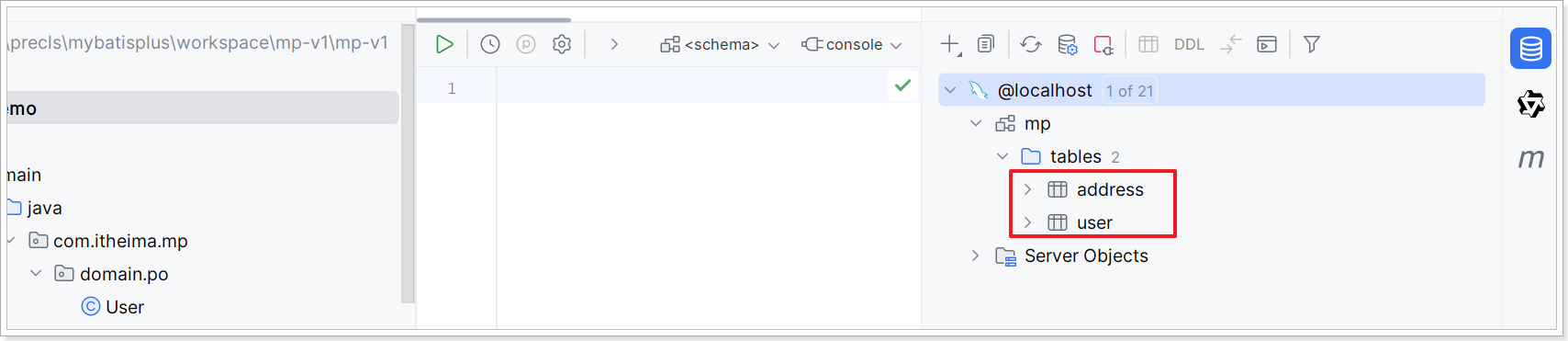
将 资料\mp.sql 文件使用 MySQL 图形界面工具导入并执行里面的数据库脚本;创建如下两张表:
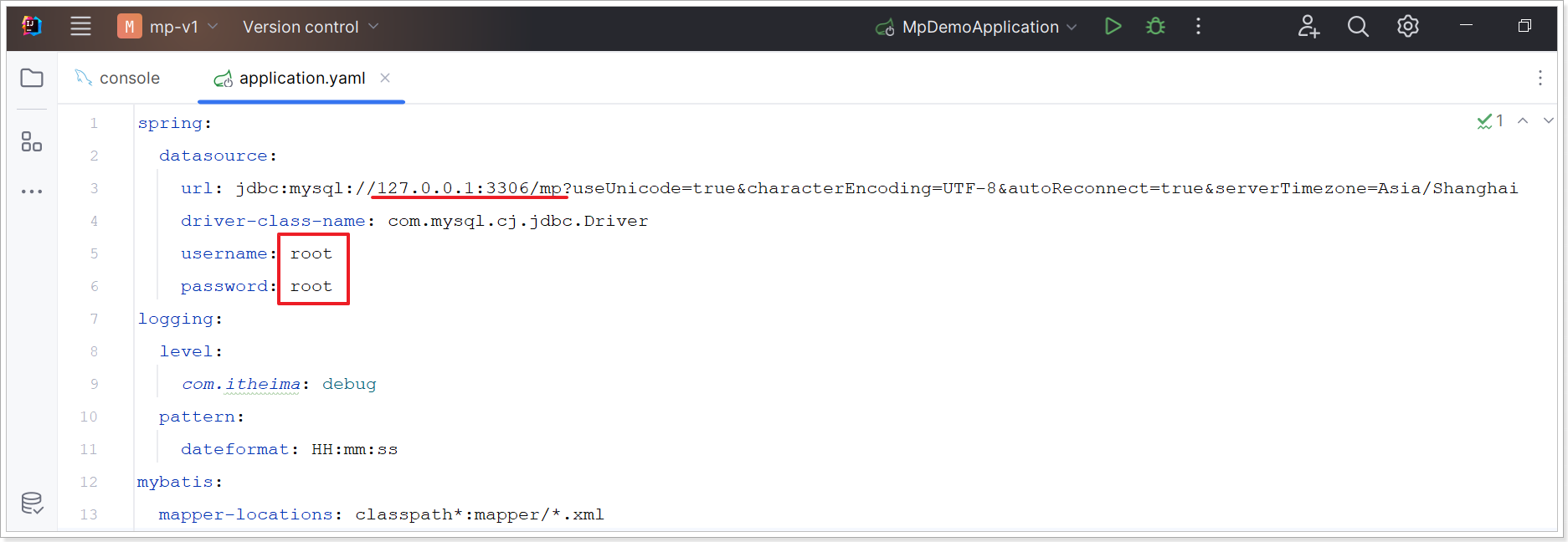
1.1.3、修改数据库连接
在刚刚导入的工程中;找到 application.yaml文件;修改jdbc连接参数为自己数据库信息。
1.2、快速开始
比如我们要实现User表的CRUD,只需要下面几步:
-
引入MybatisPlus依赖
-
定义Mapper
1.2.1、引入依赖
MybatisPlus提供了starter,实现了自动Mybatis以及MybatisPlus的自动装配功能,坐标如下:
XML
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.3.2</version>
</dependency>由于这个starter包含对mybatis的自动装配,因此完全可以替换掉Mybatis的starter。
1.2.2、改造Mapper
为了简化单表CRUD,MybatisPlus提供了一个基础的BaseMapper接口,其中已经实现了单表的CRUD:
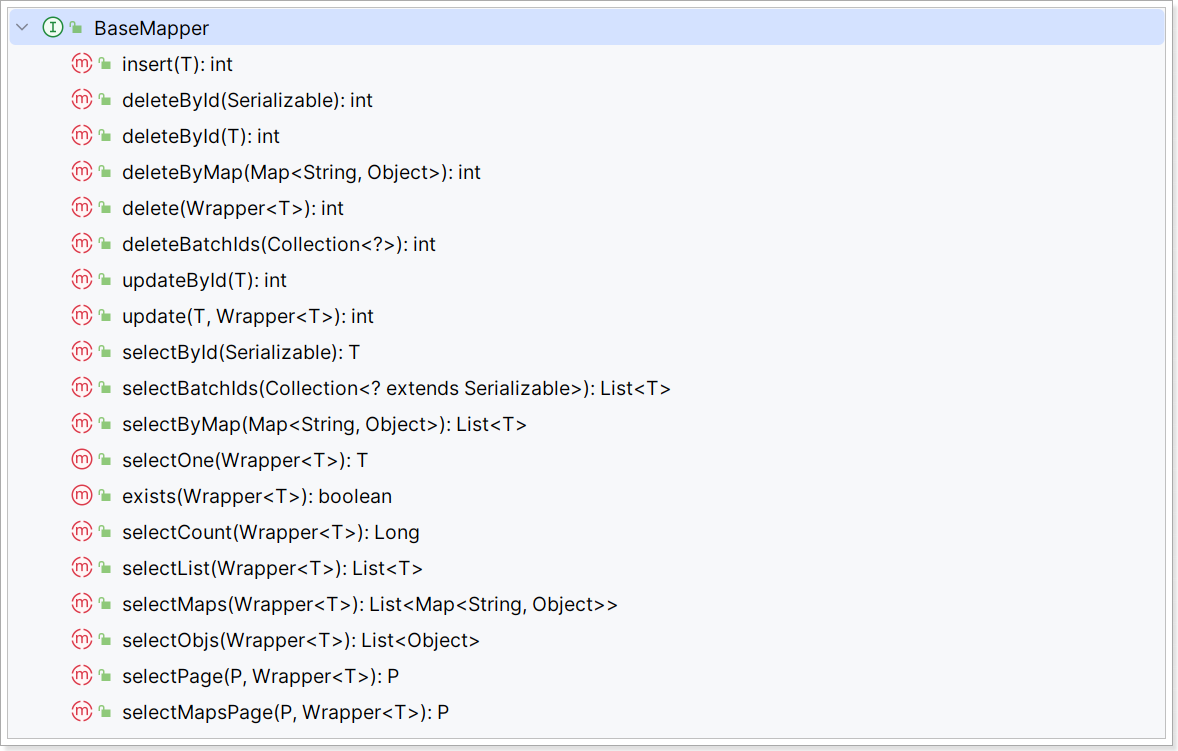
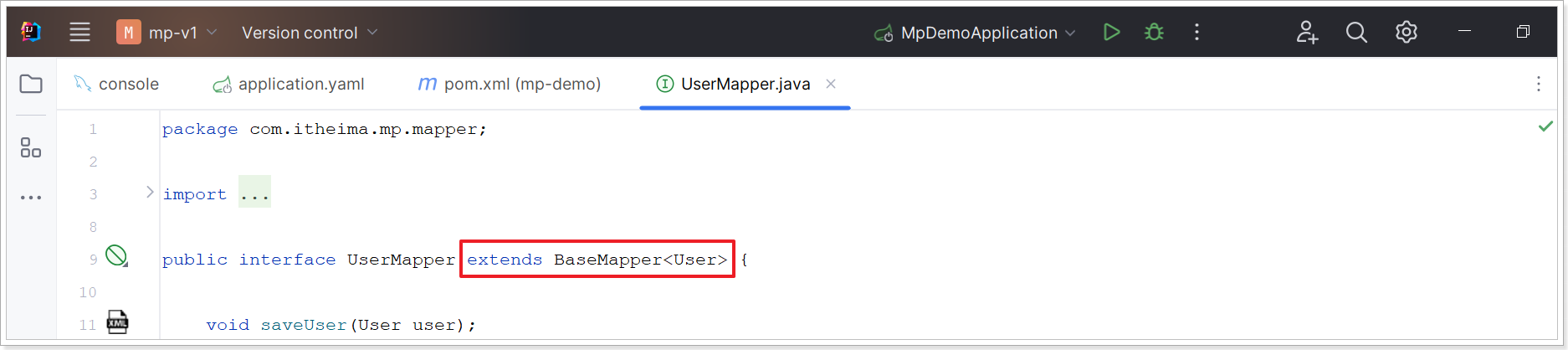
因此我们自定义的Mapper只要实现了这个BaseMapper,就无需自己实现单表CRUD了。 修改mp-demo中的com.itheima.mp.mapper包下的UserMapper接口,让其继承BaseMapper:
1.2.3、测试
删除 UserMapper.xml文件内容;并修改 com.itheima.mp.mapper.UserMapperTest 改造原有的方法都为 BaseMapper里面的方法来测试基本的CRUD方法。
java
package com.itheima.mp.mapper;
import com.itheima.mp.domain.po.User;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.time.LocalDateTime;
import java.util.List;
@SpringBootTest
class UserMapperTest {
@Autowired
private UserMapper userMapper;
@Test
void testInsert() {
User user = new User();
// user.setId(5L);
user.setUsername("Lucy4");
user.setPassword("123");
user.setPhone("18688990011");
user.setBalance(200);
user.setInfo("{\"age\": 24, \"intro\": \"英文老师\", \"gender\": \"female\"}");
user.setCreateTime(LocalDateTime.now());
user.setUpdateTime(LocalDateTime.now());
userMapper.insert(user);
}
@Test
void testSelectById() {
User user = userMapper.selectById(5L);
System.out.println("user = " + user);
}
@Test
void testQueryByIds() {
List<User> users = userMapper.selectBatchIds(List.of(1L, 2L, 3L, 4L));
users.forEach(System.out::println);
}
@Test
void testUpdateById() {
User user = new User();
user.setId(5L);
user.setBalance(20000);
userMapper.updateById(user);
}
@Test
void testDeleteUser() {
userMapper.deleteById(5L);
}
}可以看到,在运行过程中打印出的SQL日志,非常标准:
java
15:36:59 DEBUG 3464 --- [ main] c.i.mp.mapper.UserMapper.selectById : ==> Preparing: SELECT id,username,password,phone,info,status,balance,create_time,update_time FROM user WHERE id=?
15:36:59 DEBUG 3464 --- [ main] c.i.mp.mapper.UserMapper.selectById : ==> Parameters: 5(Long)
15:36:59 DEBUG 3464 --- [ main] c.i.mp.mapper.UserMapper.selectById : <== Total: 1
user = User(id=5, username=Lucy, password=123, phone=18688990011, info={"age": 24, "intro": "英文老师", "gender": "female"}, status=1, balance=200, createTime=2023-12-05T15:37, updateTime=2023-12-05T15:37)只需要继承BaseMapper就能省去所有的单表CRUD,非常简单!
1.3、常见注解
在刚刚的入门案例中,我们仅仅引入了依赖,继承了BaseMapper就能使用MybatisPlus,非常简单。但是问题来了: MybatisPlus如何知道我们要查询的是哪张表?表中有哪些字段呢?
大家回忆一下,UserMapper在继承BaseMapper的时候指定了一个泛型:

泛型中的User就是与数据库对应的PO。
MybatisPlus就是根据PO实体的信息来推断出表的信息,从而生成SQL的。默认情况下:
-
MybatisPlus会把PO实体的类名驼峰转下划线作为表名
-
MybatisPlus会把PO实体的所有变量名驼峰转下划线作为表的字段名,并根据变量类型推断字段类型
-
MybatisPlus会把名为id的字段作为主键
但很多情况下,默认的实现与实际场景不符,因此MybatisPlus提供了一些注解便于我们声明表信息。
1.3.1、@TableName
说明:
描述:表名注解,标识实体类对于的表
使用位置:实体类类名上面
示例:
java
@TableName("user")
public class User {
private Long id;
private String name;
}TableName注解除了指定表名以外,还可以指定很多其它属性:
| 属性 | 类型 | 必须指定 | 默认值 | 描述 |
|---|---|---|---|---|
| value | String | 否 | "" | 表名 |
| schema | String | 否 | "" | schema |
| keepGlobalPrefix | boolean | 否 | false | 是否保持使用全局的 tablePrefix 的值(当全局 tablePrefix 生效时) |
| resultMap | String | 否 | "" | xml 中 resultMap 的 id(用于满足特定类型的实体类对象绑定) |
| autoResultMap | boolean | 否 | false | 是否自动构建 resultMap 并使用(如果设置 resultMap 则不会进行 resultMap 的自动构建与注入) |
| excludeProperty | String\[\] | 否 | {} | 需要排除的属性名 @since 3.3.1 |
1.3.2、@TableId
说明:
描述:主键注解;用于标记实体类中的主键字段
使用位置:实体类中属性之上
示例:
java
@TableName("user")
public class User {
@TableId
private Long id;
private String name;
}TableId 注解有两个属性:
| 属性 | 类型 | 必须指定 | 默认值 | 描述 |
|---|---|---|---|---|
| value | String | 否 | "" | 表名 |
| type | Enum | 否 | IdType.NONE | 指定主键类型 |
IdType支持的类型有如下:
| 值 | 描述 |
|---|---|
| AUTO | 数据库 ID 自增 |
| NONE | 无状态,该类型为未设置主键类型(注解里等于跟随全局,全局里约等于 INPUT) |
| INPUT | insert 前自行 set 主键值 |
| ASSIGN_ID | 分配 ID(主键类型为 Number(Long 和 Integer)或 String)(since 3.3.0),使用接口IdentifierGenerator的方法nextId(默认实现类为DefaultIdentifierGenerator雪花算法) |
| ASSIGN_UUID | 分配 UUID,主键类型为 String(since 3.3.0),使用接口IdentifierGenerator的方法nextUUID(默认 default 方法) |
| ID_WORKER | 分布式全局唯一 ID 长整型类型(please use ASSIGN_ID) |
| UUID | 32 位 UUID 字符串(please use ASSIGN_UUID) |
| ID_WORKER_STR | 分布式全局唯一 ID 字符串类型(please use ASSIGN_ID) |
这里比较常见的有三种:
-
AUTO:利用数据库的id自增长 -
INPUT:手动生成id -
ASSIGN_ID:雪花算法生成Long类型的全局唯一id,这是默认的ID策略
1.3.3、@TableField
说明:
描述:普通字段注解;标记属性是否是表中的字段及哪个字段;一般特殊的字段才需要这样标记。
使用位置:实体类属性之上
示例:
java
@TableName("user")
public class User {
@TableId
private Long id;
private String name;
private Integer age;
@TableField("isMarried")
private Boolean isMarried;
@TableField("concat")
private String concat;
}一般情况下我们并不需要给字段添加@TableField注解,一些特殊情况除外:
-
成员变量名与数据库字段名不一致
-
成员变量是以
isXXX命名,按照JavaBean的规范,MybatisPlus识别字段时会把is去除,这就导致与数据库不符。 -
成员变量名与数据库一致,但是与数据库的关键字冲突。使用
@TableField注解给字段名添加 ` 转义
支持的其它属性如下:
| 属性 | 类型 | 必填 | 默认值 | 描述 |
|---|---|---|---|---|
| value | String | 否 | "" | 数据库字段名 |
| exist | boolean | 否 | true | 是否为数据库表字段 |
| condition | String | 否 | "" | 字段 where 实体查询比较条件,有值设置则按设置的值为准,没有则为默认全局的 %s=#{%s},参考(opens new window) |
| update | String | 否 | "" | 字段 update set 部分注入,例如:当在version字段上注解update="%s+1" 表示更新时会 set version=version+1 (该属性优先级高于 el 属性) |
| insertStrategy | Enum | 否 | FieldStrategy.DEFAULT | 举例:NOT_NULL insert into table_a(<if test="columnProperty != null">column</if>) values (<if test="columnProperty != null">#{columnProperty}</if>) |
| updateStrategy | Enum | 否 | FieldStrategy.DEFAULT | 举例:IGNORED update table_a set column=#{columnProperty} |
| whereStrategy | Enum | 否 | FieldStrategy.DEFAULT | 举例:NOT_EMPTY where <if test="columnProperty != null and columnProperty!=''">column=#{columnProperty}</if> |
| fill | Enum | 否 | FieldFill.DEFAULT | 字段自动填充策略 |
| select | boolean | 否 | true | 是否进行 select 查询 |
| keepGlobalFormat | boolean | 否 | false | 是否保持使用全局的 format 进行处理 |
| jdbcType | JdbcType | 否 | JdbcType.UNDEFINED | JDBC 类型 (该默认值不代表会按照该值生效) |
| typeHandler | TypeHander | 否 | 类型处理器 (该默认值不代表会按照该值生效) | |
| numericScale | String | 否 | "" | 指定小数点后保留的位数 |
1.4、常见配置
MybatisPlus也支持基于yaml文件的自定义配置,详见官方文档:使用配置 | MyBatis-Plus
大多数的配置都有默认值,因此我们都无需配置。但还有一些是没有默认值的,例如:
-
实体类的别名扫描包
-
全局id类型
java
mybatis-plus:
type-aliases-package: com.itheima.mp.domain.po
global-config:
db-config:
id-type: auto # 全局id类型为自增长需要注意的是,MyBatisPlus也支持手写SQL的,而mapper文件的读取地址可以自己配置:
java
mybatis-plus:
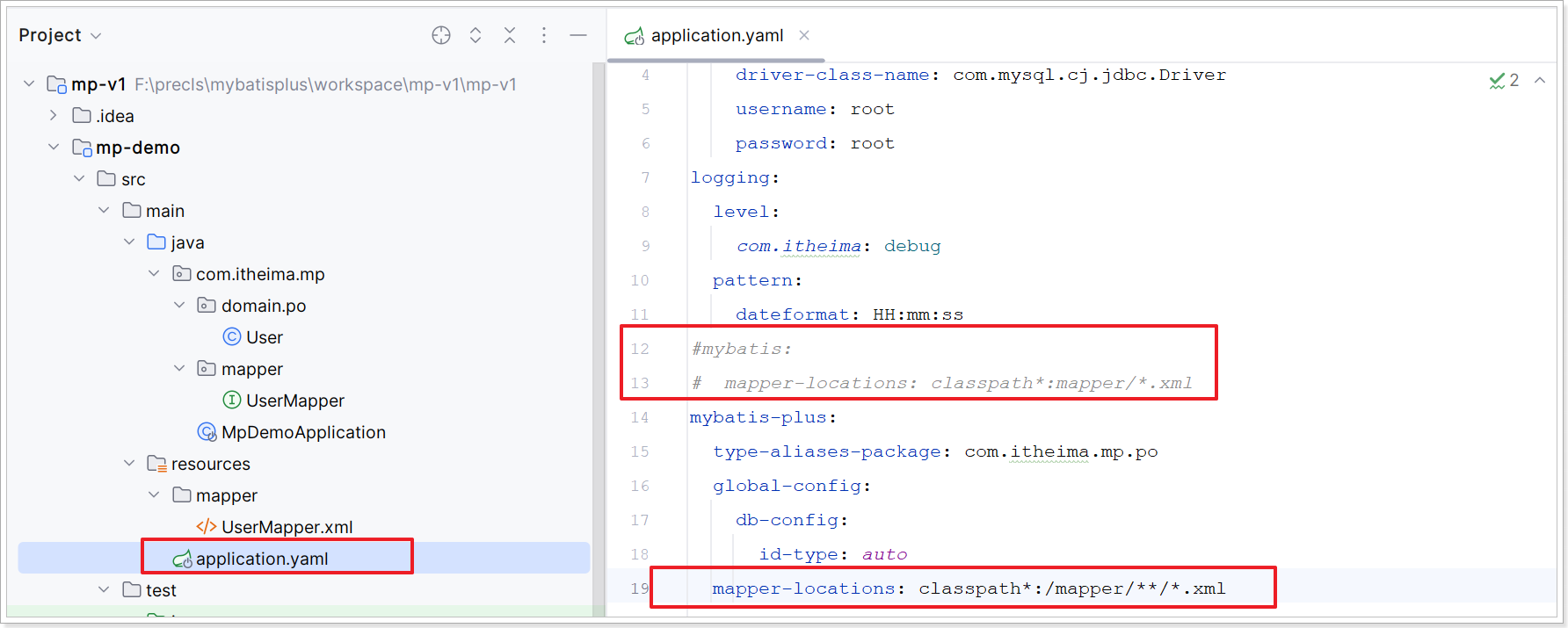
mapper-locations: "classpath*:/mapper/**/*.xml" # Mapper.xml文件地址,当前这个是默认值。可以看到默认值是classpath*:/mapper/**/*.xml,也就是说我们只要把mapper.xml文件放置这个目录下就一定会被加载。
在示例工程中可以将原有的映射文件配置项注释或删除,然后再添加mybatisPlus配置项如下:
2、核心功能
刚才的案例中都是以id为条件的简单CRUD,一些复杂条件的SQL语句就要用到一些更高级的功能了。
2.1、条件构造器
除了新增以外,修改、删除、查询的SQL语句都需要指定where条件。因此BaseMapper中提供的相关方法除了以id作为where条件以外,还支持更加复杂的where条件。
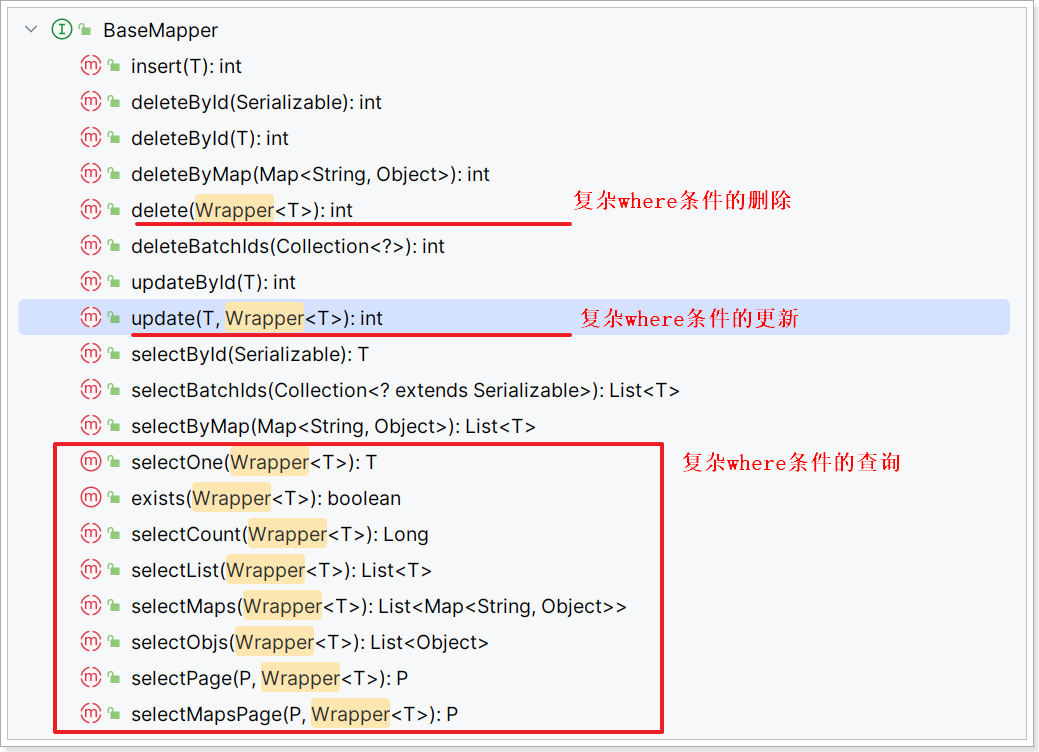
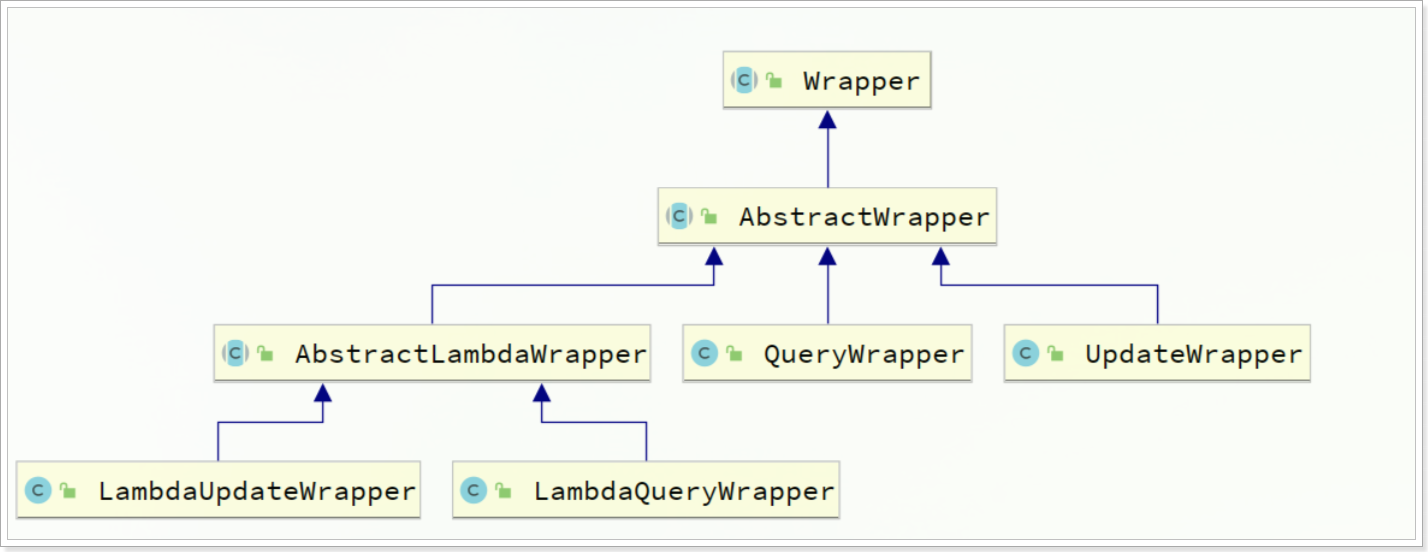
参数中的Wrapper就是条件构造的抽象类,其下有很多默认实现,继承关系如图:
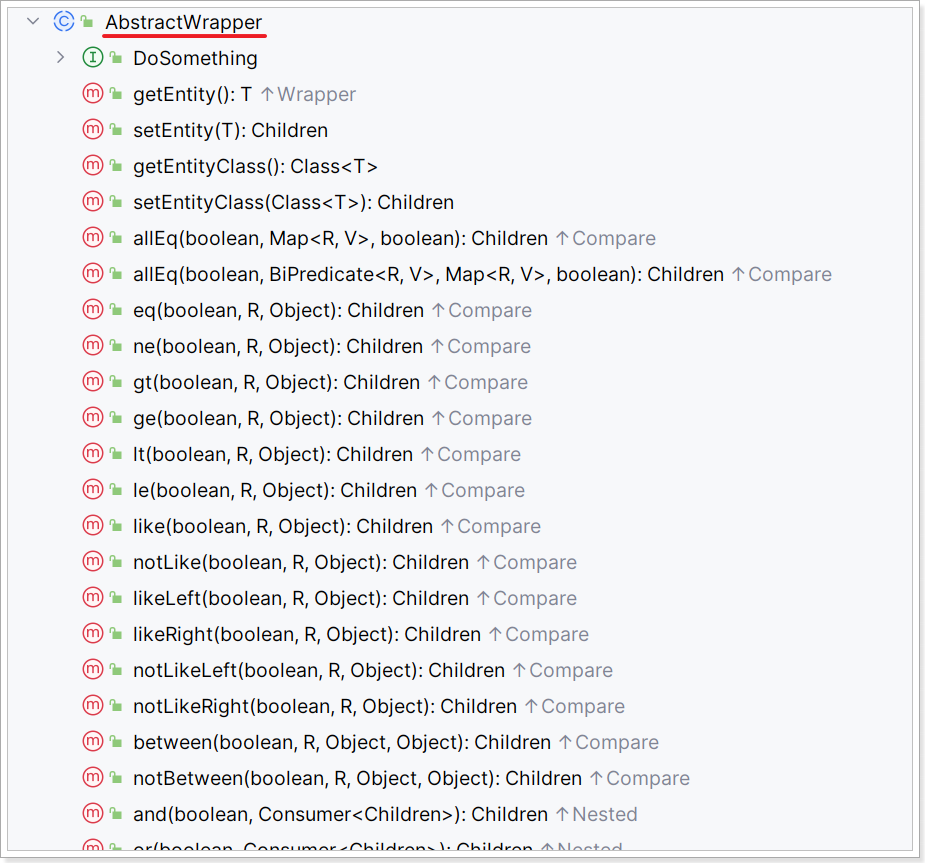
Wrapper的子类AbstractWrapper提供了where中包含的所有条件构造方法:
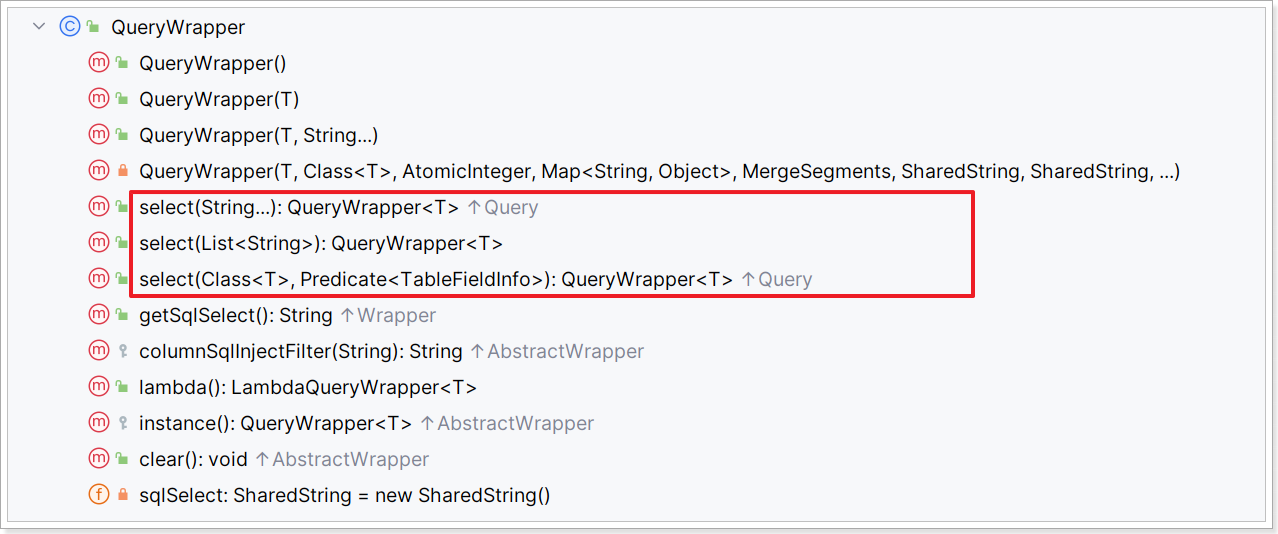
而QueryWrapper在AbstractWrapper的基础上拓展了一个select方法,允许指定查询字段:
而UpdateWrapper在AbstractWrapper的基础上拓展了一个set方法,允许指定SQL中的SET部分:
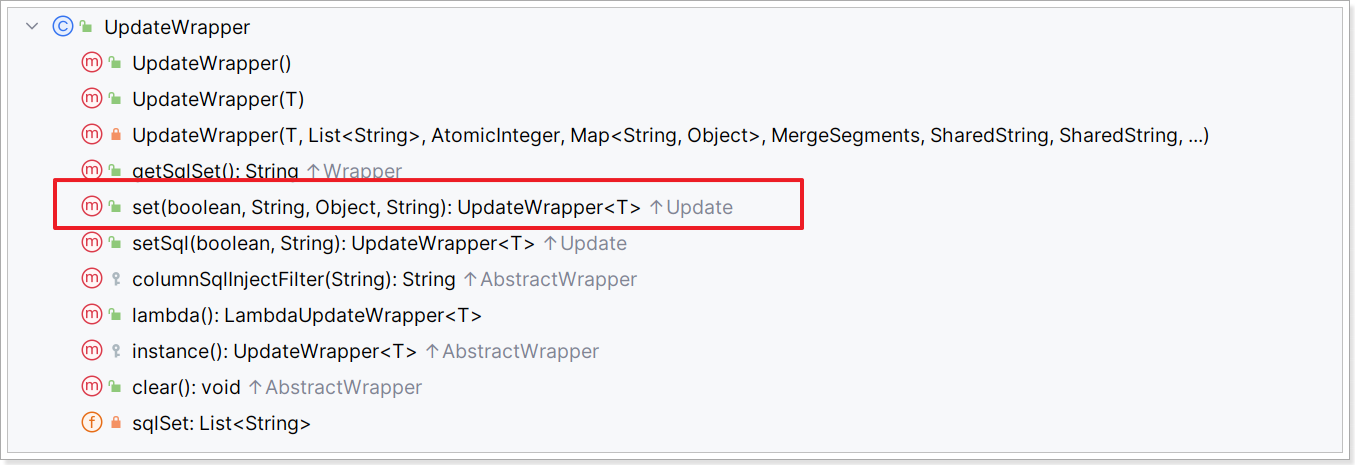
接下来,我们就来看看如何利用Wrapper实现复杂查询。
2.1.1、QueryWrapper
无论是修改、删除、查询,都可以使用QueryWrapper来构建查询条件。接下来看一些例子:
1) 查询 :查询出名字中带o的,存款大于等于1000元的人(id,username,info,balance)。代码如下:
java
/**
* 查询出名字中带'o'的,存款大于等于1000元的人(id,username,info,balance)
*
* select id,username,info,balance from user where username like '%o%' and balance >= 1000
*/
@Test
public void testQueryWrapper1() {
//创建条件构造器
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
//查询的列
queryWrapper.select("id", "username", "info", "balance");
//查询条件:名字中带'o'
queryWrapper.like("username", "o");
//查询条件:存款大于等于1000元
queryWrapper.ge("balance", 1000);
//查询
List<User> userList = userMapper.selectList(queryWrapper);
//输出
for (User user : userList) {
System.out.println(user);
}
}2)更新:更新用户名为jack的用户的余额为2000,代码如下:
java
//更新用户为jack的用户的余额为2000
@Test
public void testQueryWrapperUpdate() {
User user = new User();
user.setBalance(2000);
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.eq("username","jack");
userMapper.update(user,queryWrapper);
}2.1.2、UpdateWrapper
基于BaseMapper中的update方法更新时只能直接赋值,对于一些复杂的需求就难以实现。
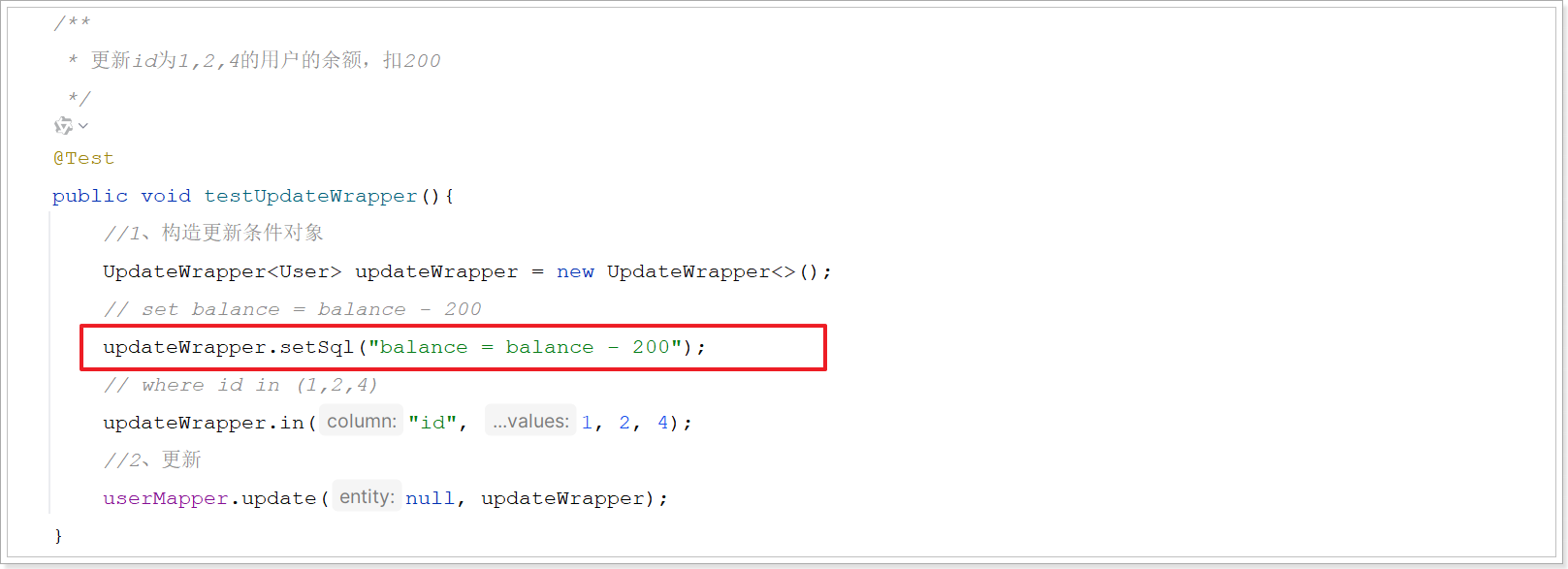
例如 :更新id为1,2,4的用户的余额,扣200,对应的SQL应该是:
java
UPDATE user SET balance = balance - 1 where id in(1,2,4)SET的赋值结果是基于字段现有值的,这个时候就要利用 UpdateWrapper 中的setSql功能了:
java
//更新id为'1,2,4'的用户的余额,扣200
//update user set balance = balance - 200 where id in (1,2,4)
@Test
public void testUpdateWrapper() {
UpdateWrapper<User> updateWrapper = new UpdateWrapper<>();
//自定义更新的语句,设置的是set---set balance = balance - 200
updateWrapper.setSql("balance = balance - 200");
//id为'1,2,4'的用户---where id in (1,2,4)
updateWrapper.in("id",1,2,4);
userMapper.update(null,updateWrapper);
}2.1.3、LambdaQueryWrapper
无论是QueryWrapper还是UpdateWrapper在构造条件的时候都需要写死字段名称,会出现字符串魔法值。这在编程规范中显然是不推荐的。 那怎么样才能不写字段名,又能知道字段名呢?
其中一种办法是基于变量的gettter方法结合反射技术。因此我们只要将条件对应的字段的getter方法传递给MybatisPlus,它就能计算出对应的变量名了。而传递方法可以使用JDK8中的方法引用和Lambda表达式。 因此MybatisPlus又提供了一套基于Lambda的Wrapper,包含两个:
-
LambdaQueryWrapper
-
LambdaUpdateWrapper
分别对应QueryWrapper和UpdateWrapper
其使用方式如下:同样的查询需求:查询出名字中带o的,存款大于等于1000元的人(id,username,info,balance)
java
/**
* 查询出名字中带'o'的,存款大于等于1000元的人(id,username,info,balance)
*
* select id,username,info,balance from user where username like '%o%' and balance >= 1000
*/
@Test
public void testQueryWrapper1() {
//创建条件构造器
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
//查询的列
queryWrapper.select("id", "username", "info", "balance");
//查询条件:名字中带'o'
queryWrapper.like("username", "o");
//查询条件:存款大于等于1000元
queryWrapper.ge("balance", 1000);
//查询
List<User> userList = userMapper.selectList(queryWrapper);
//输出
for (User user : userList) {
System.out.println(user);
}
}
@Test
public void testLambdaQueryWrapper1() {
//创建条件构造器
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
//查询的列
lambdaQueryWrapper.select(User::getId, User::getUsername, User::getInfo, User::getBalance);
//查询条件:名字中带'o'
lambdaQueryWrapper.like(User::getUsername, "o");
//查询条件:存款大于等于1000元
lambdaQueryWrapper.ge(User::getBalance, 1000);
//查询
List<User> userList = userMapper.selectList(lambdaQueryWrapper);
//输出
for (User user : userList) {
System.out.println(user);
}
}
2.2、自定义拼接SQL
在演示UpdateWrapper的案例中,我们在代码中编写了更新的SQL语句:
这种写法在某些企业也是不允许的,因为SQL语句最好都维护在持久层,而不是业务层。就当前案例来说,由于条件是in语句,只能将SQL写在Mapper.xml文件,利用foreach来生成动态SQL。 这实在是太麻烦了。假如查询条件更复杂,动态SQL的编写也会更加复杂。
所以,MybatisPlus提供了自定义SQL功能,可以让我们利用Wrapper生成查询条件,再结合Mapper.xml拼接SQL。
以当前案例来说,我们可以这样写:
java
//更新id为'1,2,4'的用户的余额,扣200
//update user set balance = balance - 200 where id in (1,2,4)
@Test
public void testUpdateWrapper() {
UpdateWrapper<User> updateWrapper = new UpdateWrapper<>();
//自定义更新的语句,设置的是set---set balance = balance - 200
updateWrapper.setSql("balance = balance - 200");
//id为'1,2,4'的用户---where id in (1,2,4)
updateWrapper.in("id",1,2,4);
userMapper.update(null,updateWrapper);
}
//自定义sql:更新id为1,2,4的用户的余额,扣200
@Test
public void testCustomSqlSeqment() {
//构造条件
//调用mapper方法实现功能
LambdaQueryWrapper<User> lamdaQueryWrapper = new LambdaQueryWrapper<>();
lamdaQueryWrapper.in(User::getId,List.of(1,2,4));
//调用mapper方法实现功能
userMapper.updateBalanceByWrapper(200,lamdaQueryWrapper);
}在 UserMapper 中添加如下方法:
java
/**
* 根据条件更新余额
* @param amount
* @param queryWrapper
*/
@Update("UPDATE user set balance = balance - #{amount} ${ew.customSqlSegment}")
void updateBalanceByWrapper(@Param("amount") int amount, @Param("ew") LambdaQueryWrapper<User> queryWrapper);注意:上述的执行语句中 ew 及 customSqlSegment 都不能修改;
1、queryWrapper 查询条件对象相当于对要执行的语句进行了语句的拼接
2、${ew.customSqlSegment} 可以使用在注解中,也可以使用在 Mapper.xml文件中进行SQL语句的拼接
2.3、Service接口
MybatisPlus不仅提供了BaseMapper,还提供了通用的Service接口及默认实现,封装了一些常用的service模板方法。 通用接口为IService,默认实现为ServiceImpl,其中封装的方法可以分为以下几类:
-
save:新增 -
remove:删除 -
update:更新 -
get:查询单个结果 -
list:查询集合结果 -
count:计数 -
page:分页查询
2.3.1、基本方法说明
新增:
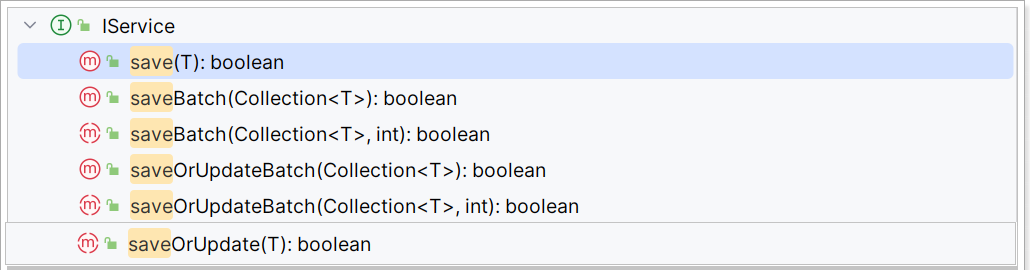
-
save是新增单个元素 -
saveBatch是批量新增 -
saveOrUpdate是根据id判断,如果数据存在就更新,不存在则新增 -
saveOrUpdateBatch是批量的新增或修改
删除:
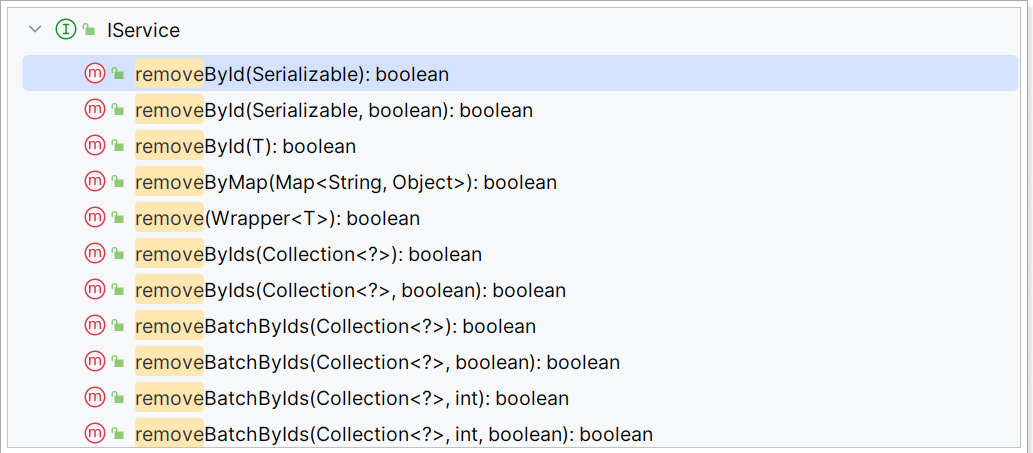
-
removeById:根据id删除 -
removeByIds:根据id批量删除 -
removeByMap:根据Map中的键值对为条件删除 -
remove(Wrapper):根据Wrapper条件删除
修改:
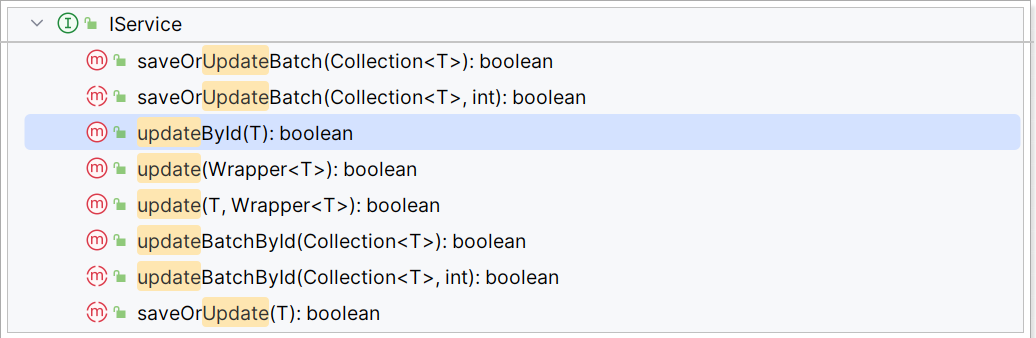
-
updateById:根据id修改 -
update(Wrapper):根据UpdateWrapper修改,Wrapper中包含set和where部分 -
update(T,Wrapper):按照T内的数据修改与Wrapper匹配到的数据 -
updateBatchById:根据id批量修改
Get:
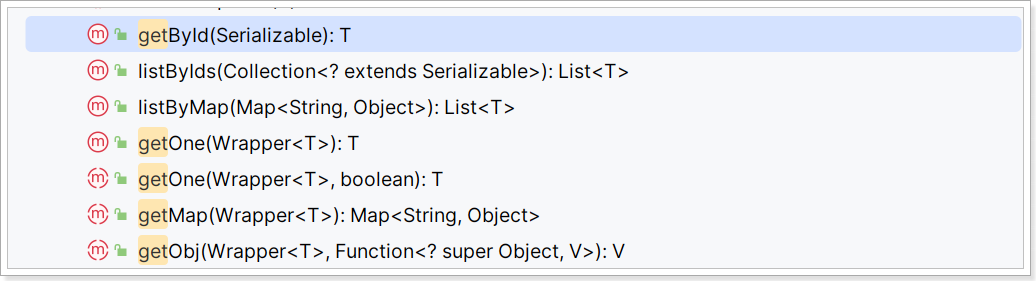
-
getById:根据id查询1条数据 -
getOne(Wrapper):根据Wrapper查询1条数据 -
getBaseMapper:获取Service内的BaseMapper实现,某些时候需要直接调用Mapper内的自定义SQL时可以用这个方法获取到Mapper
List:
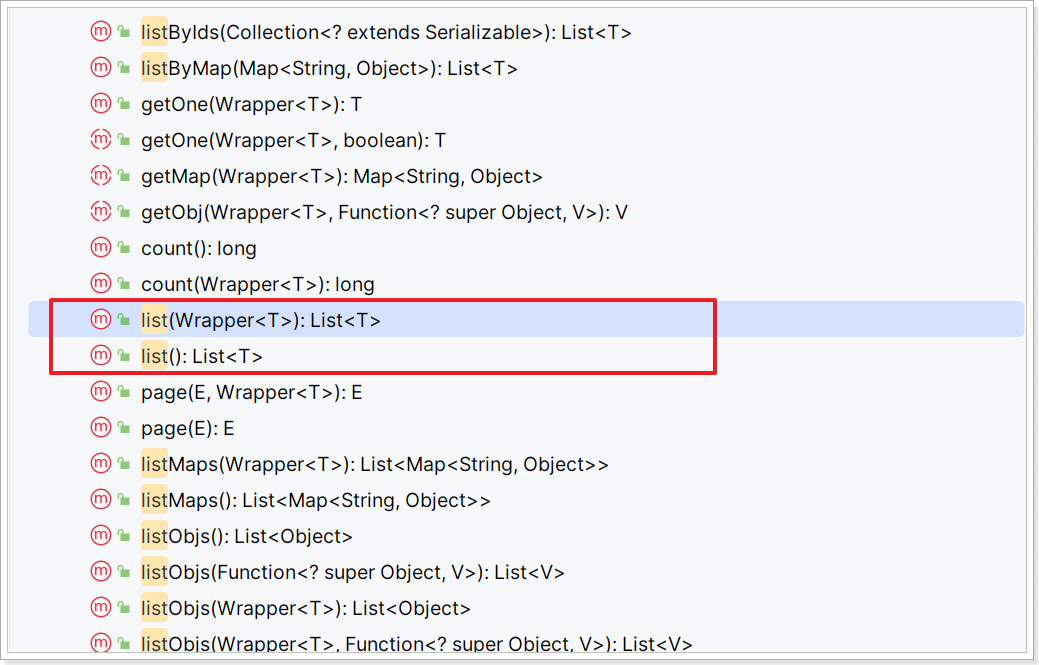
-
listByIds:根据id批量查询 -
list(Wrapper):根据Wrapper条件查询多条数据 -
list():查询所有
Count:

-
count():统计所有数量 -
count(Wrapper):统计符合Wrapper条件的数据数量
getBaseMapper:
当我们在service中要调用Mapper中自定义SQL时,就必须获取service对应的Mapper,就可以通过这个方法

2.3.2、基本用法
由于Service中经常需要定义与业务有关的自定义方法,因此我们不能直接使用IService,而是自定义Service接口,然后继承IService以拓展方法。同时,让自定义的Service实现类继承ServiceImpl,这样就不用自己实现IService中的接口了。
首先,定义IUserService,继承IService:
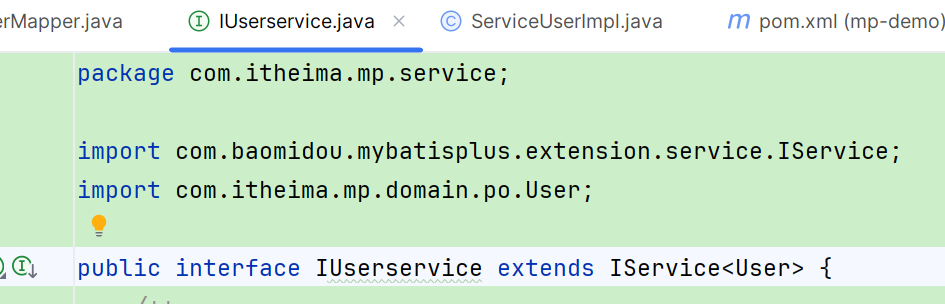
然后,编写UserServiceImpl类,继承ServiceImpl,实现IUserService:

项目结构如下:
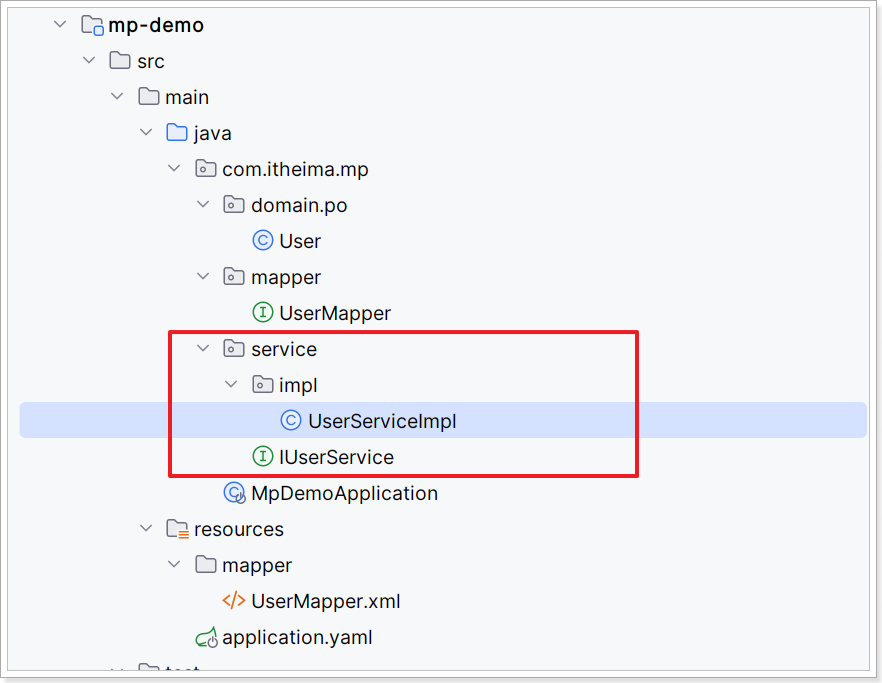
2.3.3、案例
接下来,我们快速实现下面4个接口:
| 编号 | 接口 | 请求方式 | 请求路径 | 请求参数 | 返回值 |
|---|---|---|---|---|---|
| 1 | 新增用户 | POST | /user | 用户表单实体 | 无 |
| 2 | 删除用户 | DELETE | /user/{id} | 用户id | 无 |
| 3 | 根据id查询用户 | GET | /user/{id} | 用户id | 用户VO |
| 4 | 根据id批量查询 | GET | /user | 用户id集合 | 用户VO集合 |
1)配置
首先,希望可以在图形界面中用方便测试案例中的接口的话;可以引入knife4j。我们在项目中引入几个依赖:
XML
<!--swagger-->
<dependency>
<groupId>com.github.xiaoymin</groupId>
<artifactId>knife4j-openapi2-spring-boot-starter</artifactId>
<version>4.1.0</version>
</dependency>
<!--web-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>然后需要在 application.yaml 配置swagger信息如下:
java
knife4j:
enable: true
openapi:
title: 用户管理接口文档
description: 用户管理接口文档
version: 1.0
concat: 黑马
url: http://www.itheima.com
email: itcast@itheima.com
group:
default:
group-name: default
api-rule: package
api-rule-resources:
- com.itheima.mp.controller2)DTO与VO
然后,接口需要两个实体:
-
UserFormDTO:代表新增时的用户表单
-
UserVO:代表查询的返回结果
3)UserController
按照Restful风格编写UserController接口方法:
java
@Api("用户接口管理")
@RestController
@RequestMapping("/users")
@RequiredArgsConstructor
public class UserController {
// @Autowired
// private IUserservice userService;
private final IUserservice userService;
@ApiOperation("新增用户")
@PostMapping
public void saveUser(@RequestBody UserFormDTO userFormDTO) {
//转换为User
User user = BeanUtil.copyProperties(userFormDTO, User.class);
userService.save(user);
}
@ApiOperation("删除用户")
@DeleteMapping("/{id}")
public void deleteUser(@PathVariable("id") Long id) {
userService.removeById(id);
}
@ApiOperation("根据id查询用户")
@GetMapping("/{id}")
public UserVO getUserById(@PathVariable("id") Long id) {
User user = userService.getById(id);
return BeanUtil.copyProperties(user, UserVO.class);
}
@ApiOperation("根据id批量查询用户")
@GetMapping
public List<UserVO> getUserByIds(@RequestParam("ids") List<Long> ids) {
List<User> userList = userService.listByIds(ids);
return BeanUtil.copyToList(userList,UserVO.class);
}可以看到上述接口都直接在controller即可实现,无需编写任何service代码,非常方便。启动项目之后,访问 http://localhost:8080/doc.html 进行接口测试验证。
可以发现lambdaQuery方法中除了可以构建条件,还需要在链式编程的最后添加一个
list(),这是在告诉MP我们的调用结果需要是一个list集合。这里不仅可以用list(),可选的方法有:
.one():最多1个结果
.list():返回集合结果
.count():返回计数结果MybatisPlus会根据链式编程的最后一个方法来判断最终的返回结果。
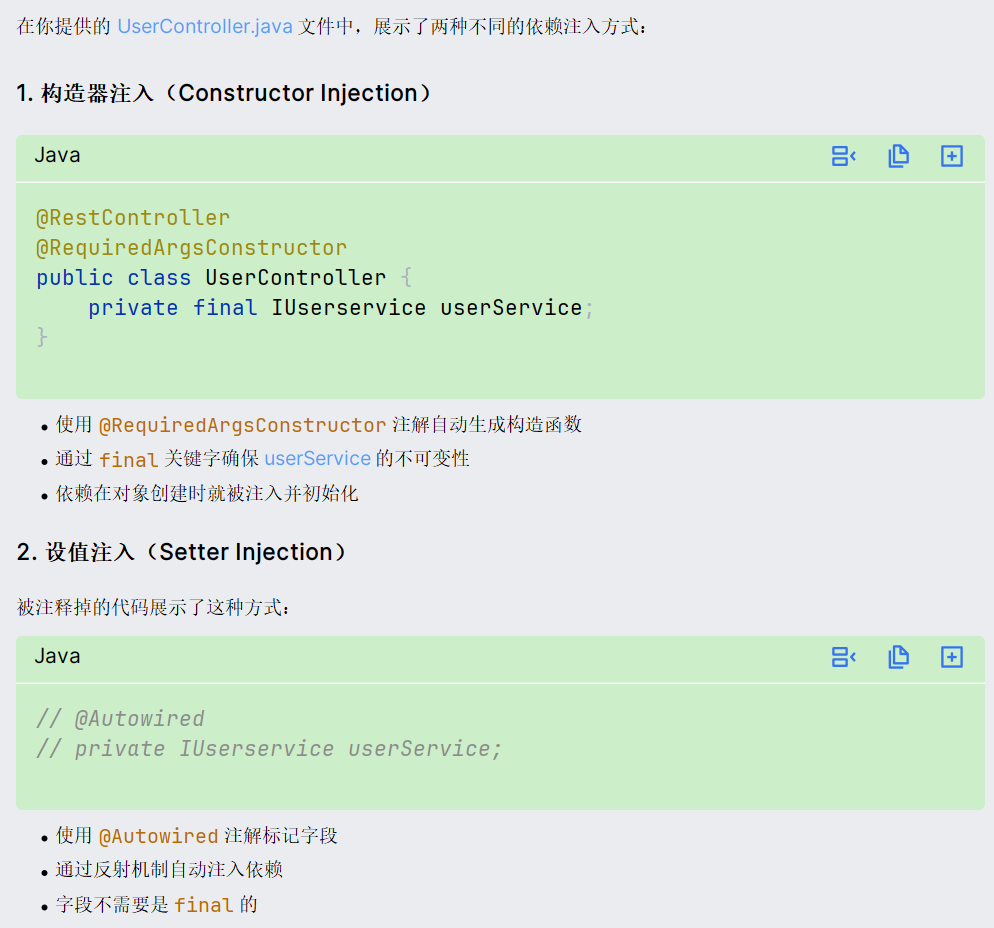
解释一下这种新的依赖注入方式:
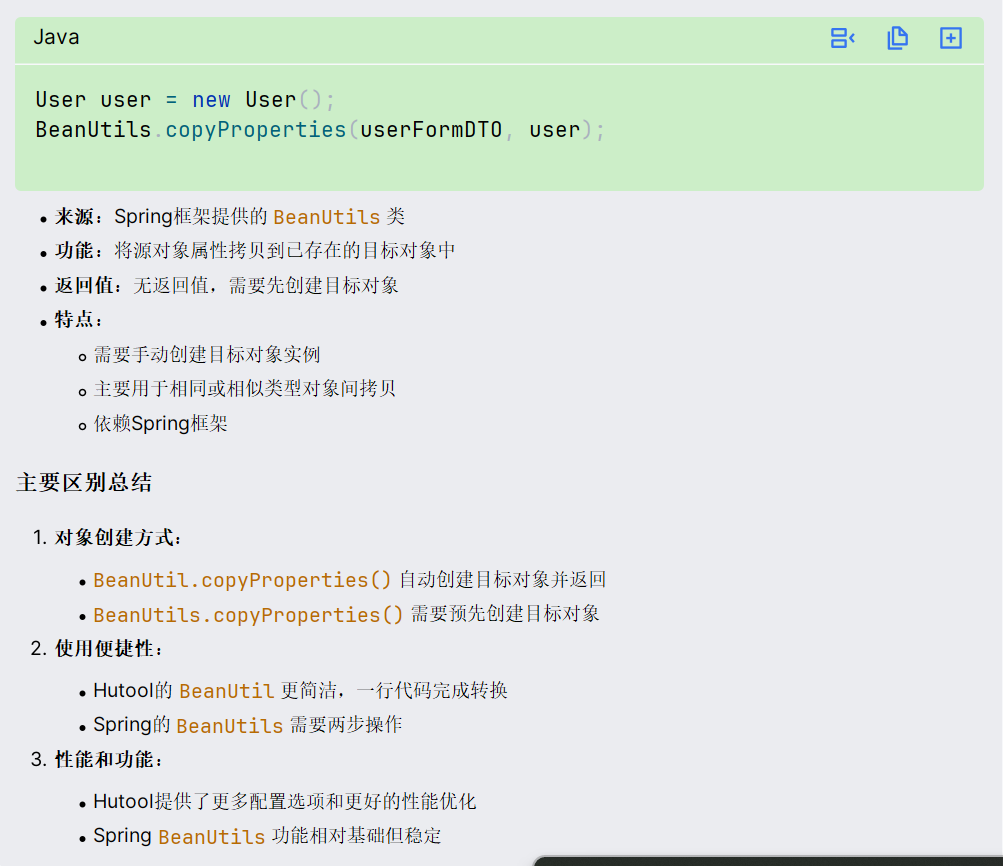
注意这里是BeanUtil拷贝有返回实体类,与BeanUtils拷贝不同
java
//转换为User
User user = BeanUtil.copyProperties(userFormDTO, User.class);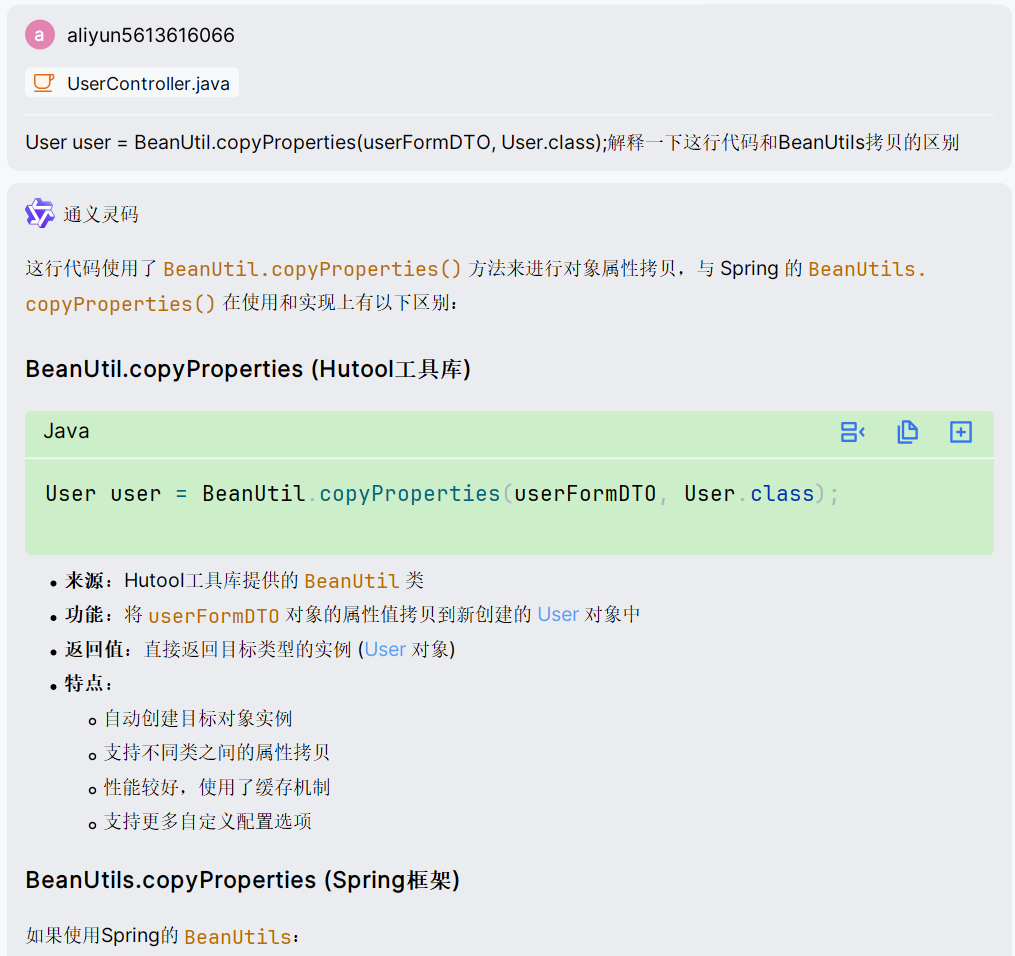
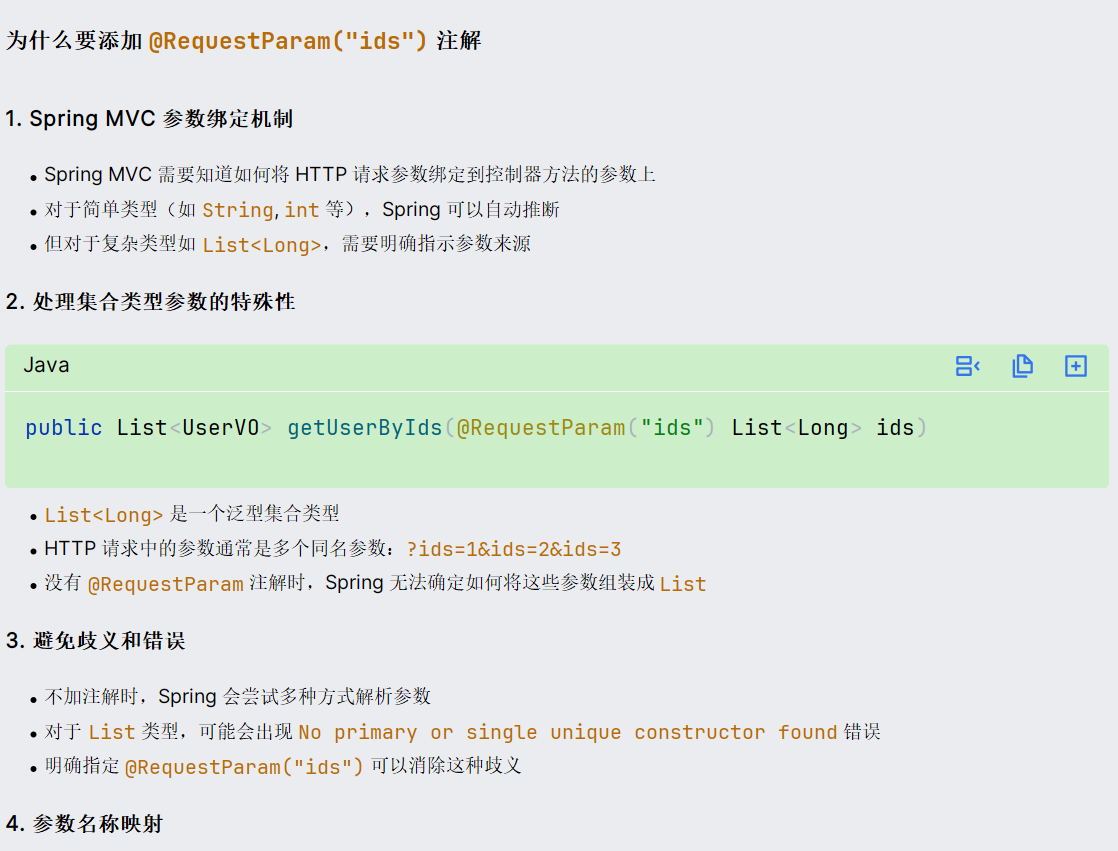
解释这里的@RequestParam("ids"),之前对这里的理解有误差
java
@ApiOperation("根据id批量查询用户")
@GetMapping
public List<UserVO> getUserByIds(@RequestParam("ids") List<Long> ids) {
List<User> userList = userService.listByIds(ids);
return BeanUtil.copyToList(userList,UserVO.class);
}
2.3.4、案例扩展
不过,一些带有业务逻辑的接口则需要在service中自定义实现了。例如下面的需求:
- 根据用户id扣减用户余额
这看起来是个简单修改功能,只要修改用户余额即可。但这个业务包含一些业务逻辑处理:
-
判断用户状态是否正常
-
判断用户余额是否充足
这些业务逻辑都要在service层来做,另外更新余额需要自定义SQL,要在mapper中来实现。因此,我们除了要编写controller以外,具体的业务还要在service和mapper中编写。
1)UserController
在 UserController 新增如下方法:
java
/**
* 根据id扣减余额
* @param id 用户id
* @param amount 扣减的金额
*/
@ApiOperation("根据id扣减余额")
@PutMapping("/{id}/deduction/{amount}")
public void updateBalanceById(@PathVariable("id") Long id, @PathVariable("amount") Integer amount) {
userService.deductBalanceById(id, amount);
}2)IUserService
在 IUserService 新增如下方法:
java
public interface IUserservice extends IService<User> {
/**
* 扣减余额
* @param id
* @param amount
*/
void deductBalanceById(Long id, Integer amount);
}3)UserServiceImpl
在 UserServiceImpl中实现方法如下:
java
@Service
@RequiredArgsConstructor
public class ServiceUserImpl extends ServiceImpl<UserMapper, User> implements IUserservice {
// @Autowired
// private UserMapper userMapper;
private final UserMapper userMapper;
@Override
public void deductBalanceById(Long id, Integer amount) {
//1.判断用户是否存在
User user = this.getById(id);
if (user == null || user.getStatus() == 2) {
throw new RuntimeException("用户不正常");
}
//2.判断余额是否充足:当前用户的余额是否大于等于要扣的金额
if (user.getBalance() < amount) {
throw new RuntimeException("余额不足");
}
//3.扣减
userMapper.deductBalanceById(id, amount);
}
}4)UserMapper
在 UserMapper中添加如下方法:
java
/**
* 根据id扣减余额
* @param id
* @param amount
*/
@Update("update user set balance = balance - #{amount} where id = #{id}")
void deductBalanceById(@Param("id") Long id,@Param("amount") Integer amount);2.3.5、Lambda优化查询用户列表
IService中还提供了Lambda功能来简化我们的复杂查询及更新功能。我们通过两个案例来学习一下。
案例一查询:实现一个根据复杂条件查询用户的接口,查询条件如下:
-
name:用户名关键字,可以为空
-
status:用户状态,可以为空
-
minBalance:最小余额,可以为空
-
maxBalance:最大余额,可以为空
可以理解成一个用户的后台管理界面,管理员可以自己选择条件来筛选用户,因此上述条件不一定存在,需要做判断。
1)引入UserQuery
我们首先需要定义一个查询条件实体,UserQuery实体。
2)新增Controller方法
在 UserController中新增如下查询方法:
java
@ApiOperation("根据条件查询用户列表")
@PostMapping("/list")
public List<UserVO> queryList(@RequestBody UserQuery userQuery) {
String username = userQuery.getName();
Integer status = userQuery.getStatus();
Integer minBalance = userQuery.getMinBalance();
Integer maxBalance = userQuery.getMaxBalance();
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
// if(StrUtil.isNotBlank(username)) {
// queryWrapper.lambda().like(User::getUsername, username);
// }
//这里我们想要不出现魔法值,可以调用lamdba会出现实体类的字段
// queryWrapper.lambda()
// //成立的条件;字段;查询的关键字; 如果第一个条件为true才会设置当前这个条件到where中
// .like(StrUtil.isNotBlank(username), User::getUsername, username)
// .eq(status != null, User::getStatus, status)
// .ge(minBalance != null, User::getBalance, minBalance)
// .le(maxBalance != null, User::getBalance, maxBalance);
//
// List<User> userList = userService.list(queryWrapper);
List<User> userList = userService.lambdaQuery()
.like(StrUtil.isNotBlank(username), User::getUsername, username)
.eq(status != null, User::getStatus, status)
.ge(minBalance != null, User::getBalance, minBalance)
.le(maxBalance != null, User::getBalance, maxBalance)
.list();//最终进行查询并直接返回
return BeanUtil.copyToList(userList, UserVO.class);
}在组织查询条件的时候,我们加入了 status != null 这样的参数,意思就是当条件成立时才会添加这个查询条件,类似Mybatis的mapper.xml文件中的if标签。这样就实现了动态查询条件效果了。
可以发现lambdaQuery方法中除了可以构建条件,还需要在链式编程的最后添加一个list(),这是在告诉MP我们的调用结果需要是一个list集合。这里不仅可以用list(),可选的方法有:
-
.one():最多1个结果 -
.list():返回集合结果 -
.count():返回计数结果
MybatisPlus会根据链式编程的最后一个方法来判断最终的返回结果。
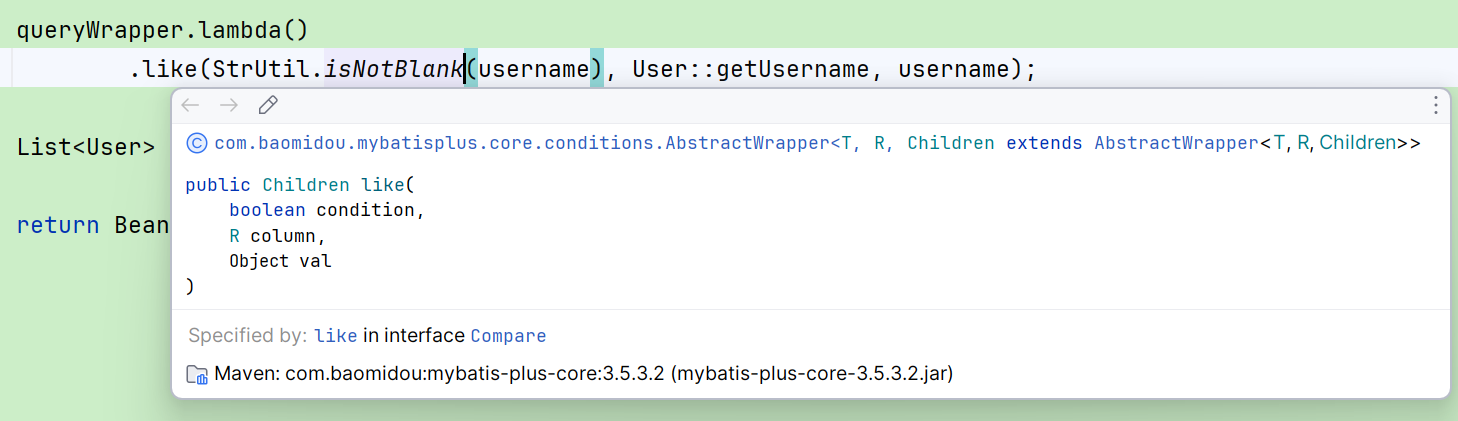
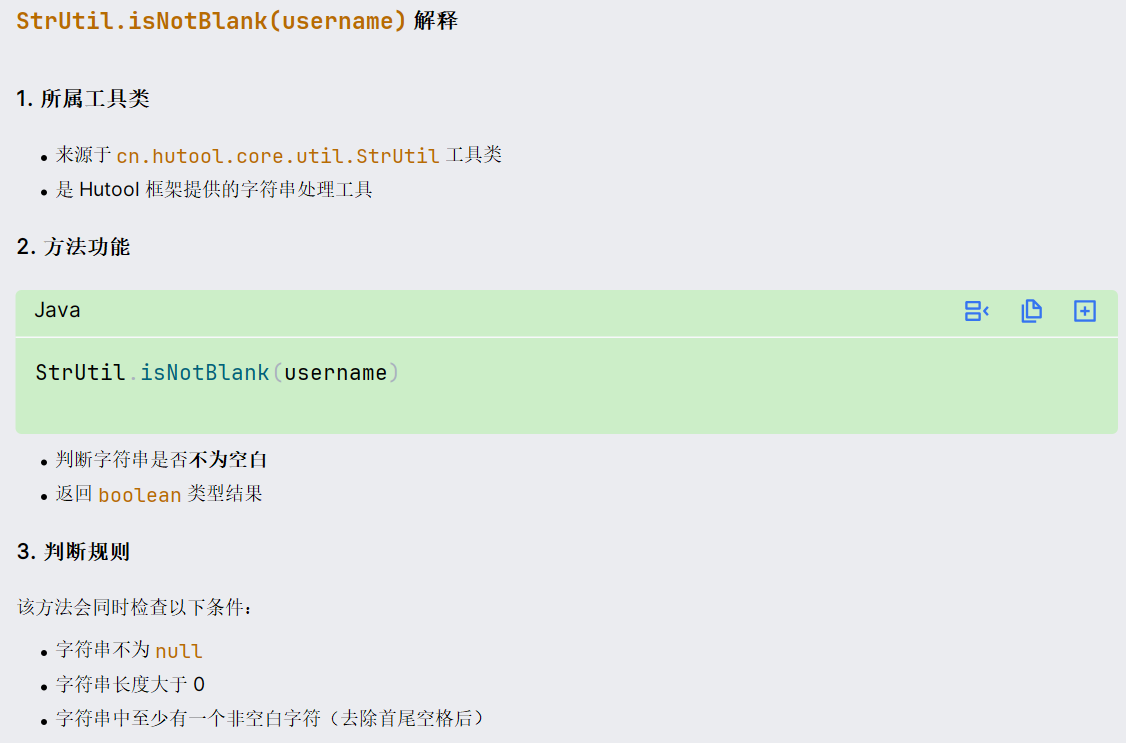
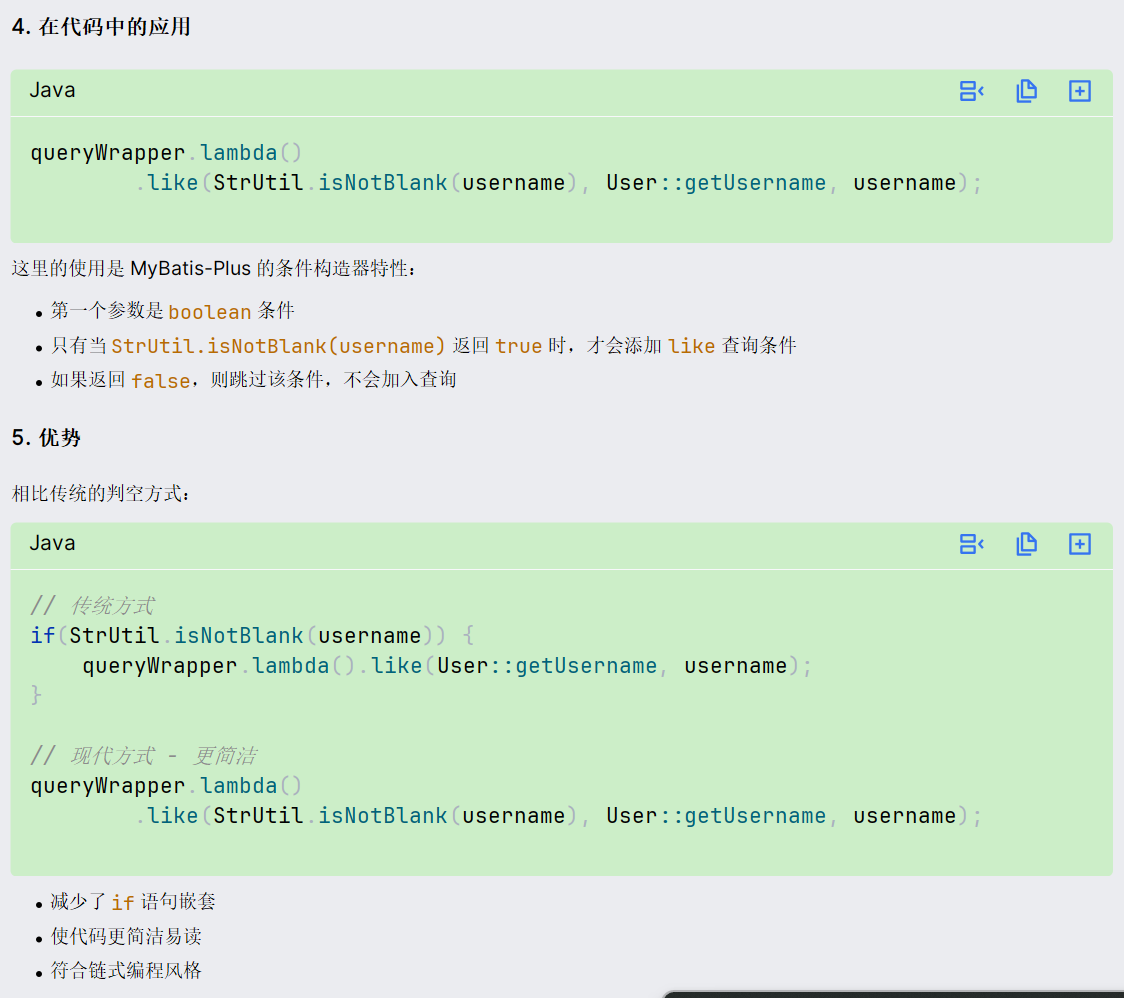
条件成立才会添加后面的like条件,与下面这种方式的作用相同:
java
if(StrUtil.isNotBlank(username)) {
queryWrapper.lambda().like(User::getUsername, username);
}
2.3.6、Lambda更新
与lambdaQuery方法类似,IService中的lambdaUpdate方法可以非常方便的实现复杂更新业务。
例如下面的需求:
需求:改造 UserServiceImpl 中原 根据id修改用户余额的接口,要求如下
完成对用户状态校验
完成对用户余额校验
如果扣减后余额为0,则将用户status修改为冻结状态(2)
也就是说我们在扣减用户余额时,需要对用户剩余余额做出判断,
如果发现剩余余额为0,则应该将status修改为2,这就是说update语句的set部分是动态的。
修改 UserServiceImpl 中方法如下:
java
@Override
public void deductBalanceById(Long id, Integer amount) {
//1.判断用户是否存在
User user = this.getById(id);
if (user == null || user.getStatus() == 2) {
throw new RuntimeException("用户不正常");
}
//2.判断余额是否充足:当前用户的余额是否大于等于要扣的金额
if (user.getBalance() < amount) {
throw new RuntimeException("余额不足");
}
//3.扣减
// 获取扣减之后的余额
int remainBanlance = user.getBalance() - amount;
//userMapper.deductBalanceById(id, amount);
//update user set balance = ?, status = ? where id = ?
//update user set balance = ? where id = ?
this.lambdaUpdate()
.set(User::getBalance, remainBanlance) //设置余额
//当余额为0的时候:用户的状态修改为2
.set(remainBanlance == 0, User::getStatus, 2)
.eq(User::getId,id)//条件
.update();//执行更新操作
}2.3.7、批量新增
IService中的批量新增功能使用起来非常方便,但有一点注意事项,我们先来测试一下。 首先我们测试逐条插入数据。创建 mp-demo\src\test\java\com\itheima\mp\service\UserServiceTest.java 如下:
java
//普通的新增10万条数据
@Test
public void testOneByOne() {
//记录开始时间
long start = System.currentTimeMillis();
for (int i = 1; i <= 100000; i++) {
userService.save(buildUser(i));
}
//记录结束时间
long end = System.currentTimeMillis();
System.out.println("普通新增10万条数据耗时:" + (end - start) + "ms");
}
private User buildUser(int i) {
User user = new User();
// user.setId(5L);
user.setUsername("user-" + i);
user.setPassword("123");
user.setPhone("18688990011");
user.setBalance(200);
user.setInfo("{\"age\": 24, \"intro\": \"英文老师\", \"gender\": \"female\"}");
user.setCreateTime(LocalDateTime.now());
user.setUpdateTime(LocalDateTime.now());
return user;
}执行结果如下:
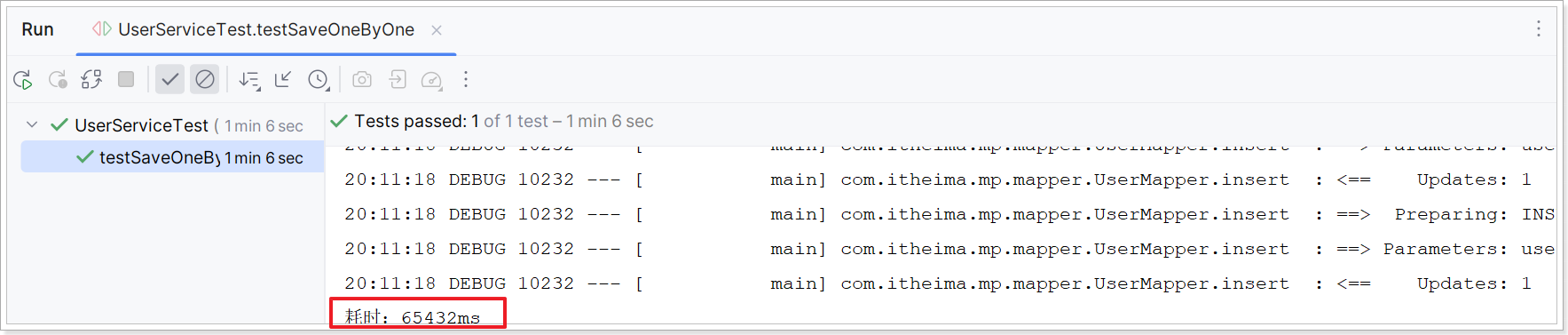
可以看到速度非常慢。
然后再试试MybatisPlus的批处理:
java
//批量一次插入1000条用户数据:总共10万
@Test
public void testBatch() {
//记录开始时间
long start = System.currentTimeMillis();
List<User> list = new ArrayList<>(1000);
for (int i = 1; i <= 1000; i++) {
list.add(buildUser(i));
if (i % 1000 == 0) {
userService.saveBatch(list);
//每次保存完之后清空集合
list.clear();
}
}
//记录结束时间
long end = System.currentTimeMillis();
System.out.println("批量插入1000条数据耗时:" + (end - start) + "ms");
}执行最终耗时如下:
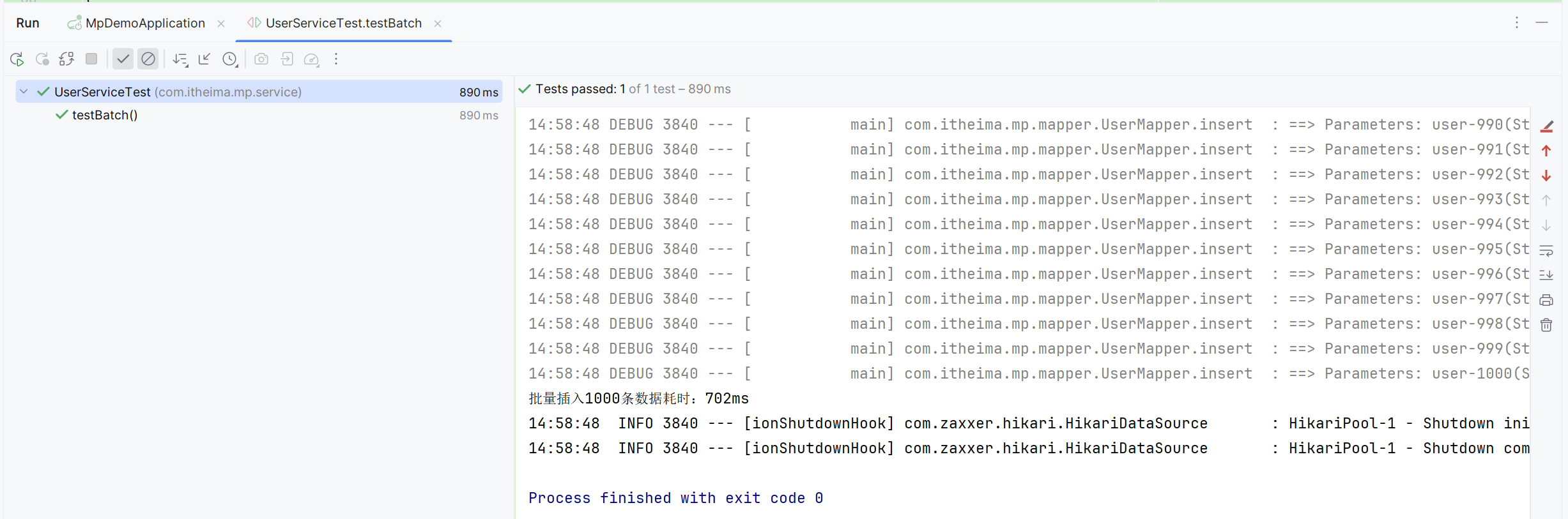
可以看到使用了批处理以后,比逐条新增效率提高了近10倍左右,性能还是不错的。
不过;我们简单查看一下 MybatisPlus的源码:
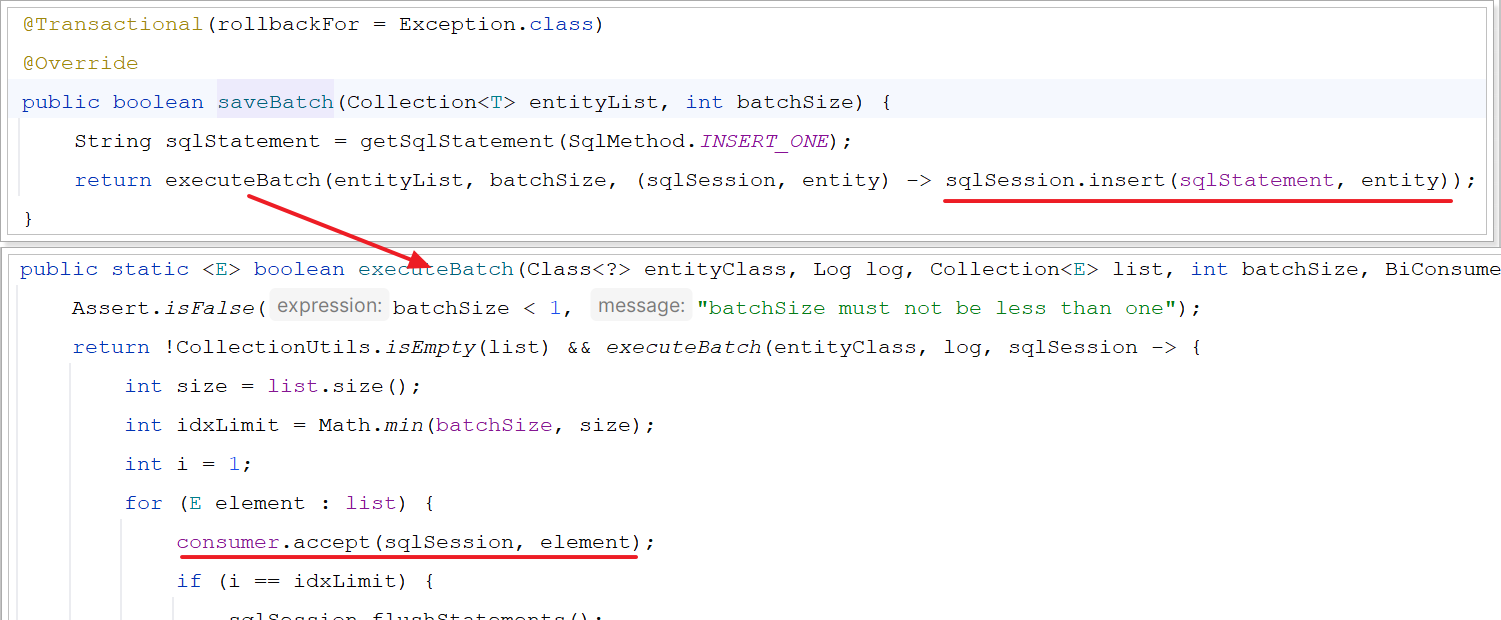
可以发现其实MybatisPlus的批处理是基于PrepareStatement的预编译模式,然后批量提交,最终在数据库执行时还是会有多条insert语句,逐条插入数据。SQL类似这样:
java
Preparing: INSERT INTO user ( username, password, phone, info, balance, create_time, update_time ) VALUES ( ?, ?, ?, ?, ?, ?, ? )
Parameters: user_1, 123, 18688190001, "", 2000, 2023-12-01, 2023-12-01
Parameters: user_2, 123, 18688190002, "", 2000, 2023-12-01, 2023-12-01
Parameters: user_3, 123, 18688190003, "", 2000, 2023-12-01, 2023-12-01而如果想要得到最佳性能,最好是将多条SQL合并为一条,像这样:
java
INSERT INTO user ( username, password, phone, info, balance, create_time, update_time )
VALUES
(user_1, 123, 18688190001, "", 2000, 2023-12-01, 2023-12-01),
(user_2, 123, 18688190002, "", 2000, 2023-12-01, 2023-12-01),
(user_3, 123, 18688190003, "", 2000, 2023-12-01, 2023-12-01),
(user_4, 123, 18688190004, "", 2000, 2023-12-01, 2023-12-01);该怎么做呢?
MySQL的客户端连接参数中有这样的一个参数:rewriteBatchedStatements。顾名思义,就是重写批处理的statement语句。参考文档:
MySQL :: Connectors and APIs Manual :: 3.5.3.13 Performance Extensions
这个参数的默认值是false,我们需要修改连接参数,将其配置为true
修改项目中的application.yaml文件,在jdbc的url后面添加参数&rewriteBatchedStatements=true 参考如下配置:
java
spring:
datasource:
url: jdbc:mysql://127.0.0.1:3306/mp?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai&rewriteBatchedStatements=true
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: root在ClientPreparedStatement的executeBatchInternal中,有判断rewriteBatchedStatements值是否为true并重写SQL的功能。
3、扩展功能
3.1、代码生成器
在使用MybatisPlus以后,基础的Mapper、Service、PO代码相对固定,重复编写也比较麻烦。因此MybatisPlus官方提供了代码生成器根据数据库表结构生成PO、Mapper、Service等相关代码。
3.1.1、安装插件
这里推荐大家使用一款MybatisPlus的插件,它可以基于图形化界面完成MybatisPlus的代码生成,非常简单。
方式一 :在Idea的plugins市场中搜索并安装MyBatisPlus插件(插件不太稳定,建议按照官网方式):
然后重启你的 IDEA 即可使用。
方式二 :上述的图形界面插件,存在不稳定因素;所以建议使用代码方式生成。官网安装说明。在项目中 pom.xml 添加依赖如下:
XML
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-generator</artifactId>
<version>3.5.3.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.freemarker</groupId>
<artifactId>freemarker</artifactId>
<version>2.3.32</version>
<scope>test</scope>
</dependency>3.1.2、使用
使用图形界面方式的直接打开设置数据信息和填写其它界面中需要的内容即可。
在新版IDEA中;入口在:(有些版本的idea可能在other下面)
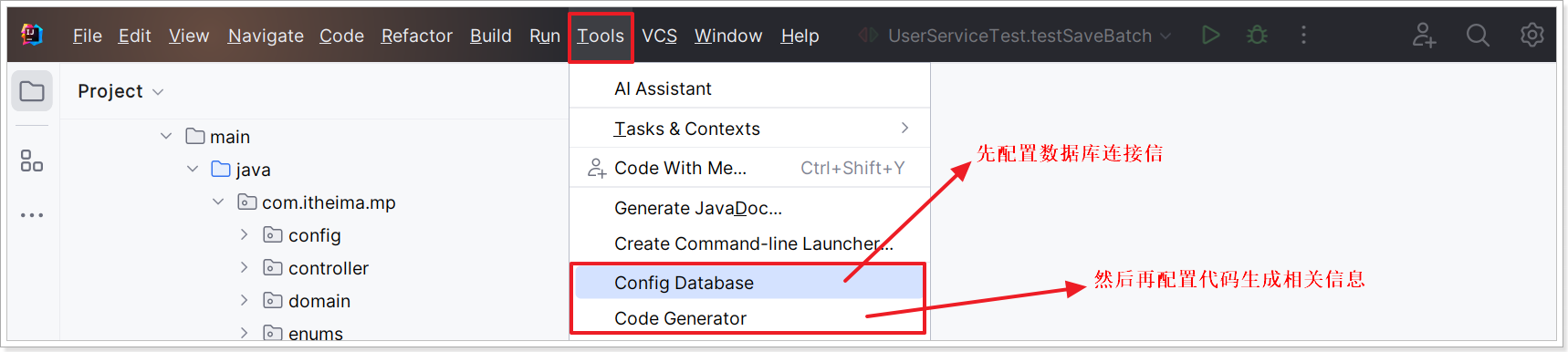
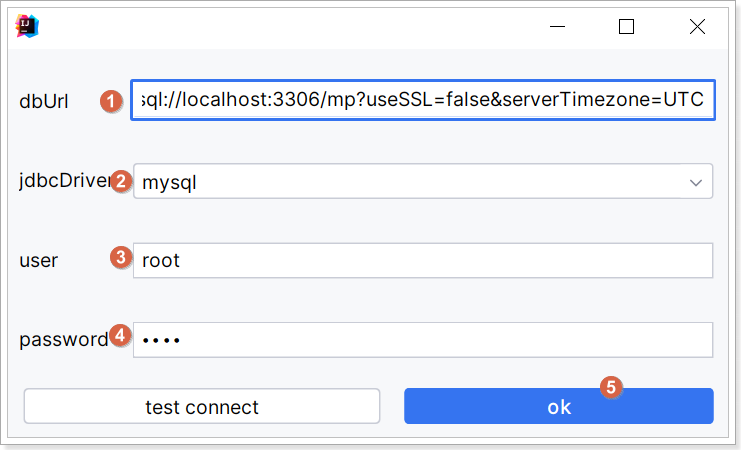
点击上述的 Config Database 配置数据库连接如下:
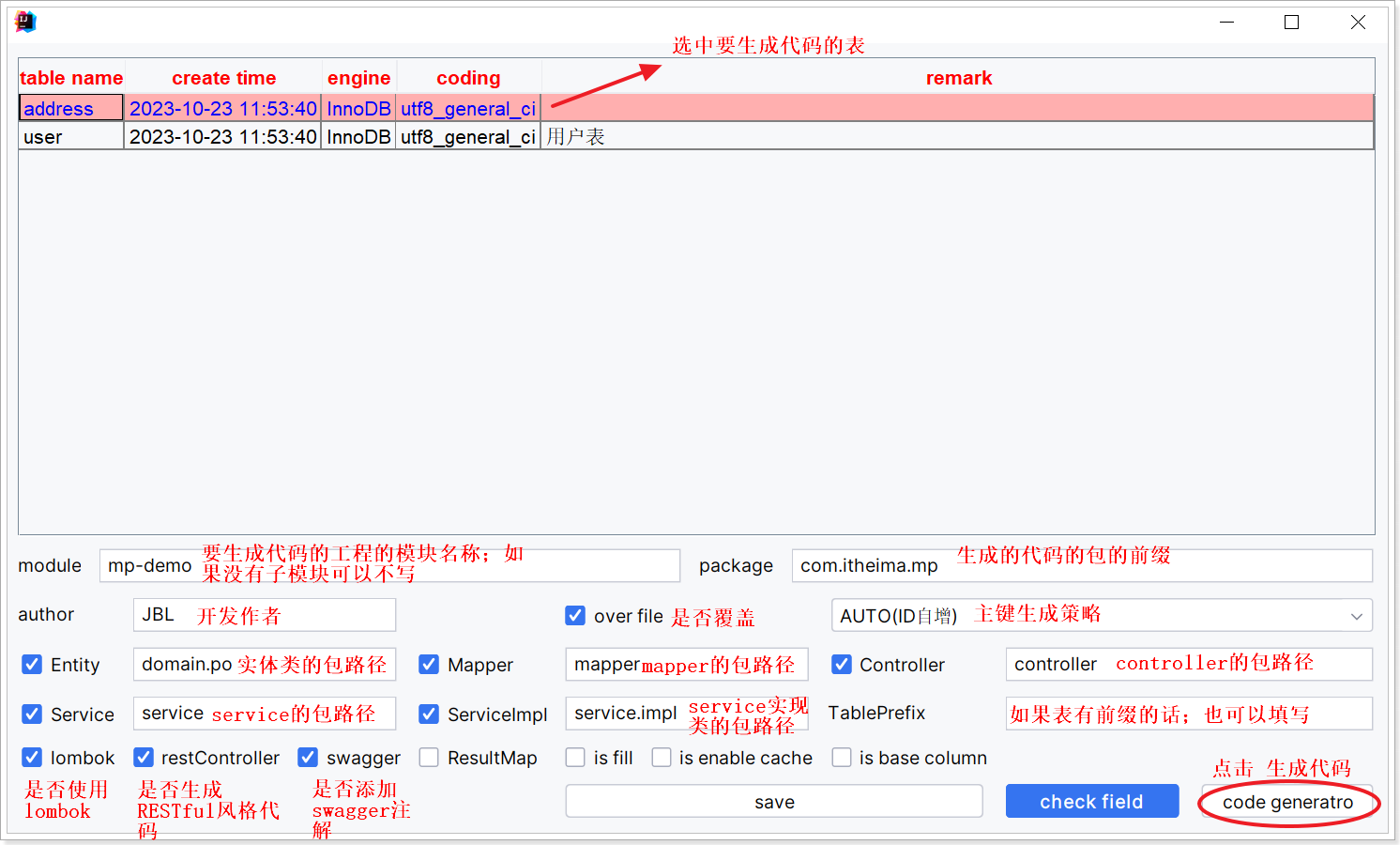
点击 Code Generator 配置代码生成信息如下:
使用代码的方式;那么创建 mp-demo\src\test\java\com\itheima\mp\MybatisPlusGeneratorTest.java 如下:
java
package com.itheima.mp;
import com.baomidou.mybatisplus.generator.FastAutoGenerator;
import com.baomidou.mybatisplus.generator.config.OutputFile;
import com.baomidou.mybatisplus.generator.config.rules.DbColumnType;
import com.baomidou.mybatisplus.generator.engine.FreemarkerTemplateEngine;
import java.sql.Types;
import java.util.Collections;
public class MybatisPlusGeneratorTest {
public static void main(String[] args) {
String url = "jdbc:mysql://127.0.0.1:3306/mp?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai&rewriteBatchedStatements=true";
FastAutoGenerator.create(url , "root", "root")
.globalConfig(builder -> {
builder.author("JBL") // 设置作者
.enableSwagger() // 开启 swagger 模式
.outputDir("D:\\itcast\\generatedCode"); // 指定输出目录
})
.dataSourceConfig(builder -> builder.typeConvertHandler((globalConfig, typeRegistry, metaInfo) -> {
int typeCode = metaInfo.getJdbcType().TYPE_CODE;
if (typeCode == Types.SMALLINT) {
// 自定义类型转换
return DbColumnType.INTEGER;
}
return typeRegistry.getColumnType(metaInfo);
}))
.packageConfig(builder -> {
builder.parent("com.itheima.mp") // 设置父包名
.controller("controller")
.entity("domain.po") // 设置实体类包名
.service("service") // 设置service包名
.serviceImpl("service.impl") // 设置service实现类包名
.mapper("mapper") // 设置mapper包名
//.moduleName("address") // 设置父包模块名
.pathInfo(Collections.singletonMap(OutputFile.xml, "D:\\itcast\\generatedCode\\mapper")); // 设置mapperXml生成路径
})
.strategyConfig(builder -> {
builder.addInclude("address") // 设置需要生成的表名
.addTablePrefix("t_", "c_") // 设置过滤表前缀
.controllerBuilder().enableRestStyle() // 开启restful风格控制器
.enableFileOverride() // 覆盖已生成文件
.entityBuilder().enableLombok(); // 开启lombok模型,默认是false
})
.templateEngine(new FreemarkerTemplateEngine()) // 使用Freemarker引擎模板,默认的是Velocity引擎模板
.execute();
}
}将生成的实体、Mapper、Service、Controller等对应的类放置到项目中。
3.2、静态工具类
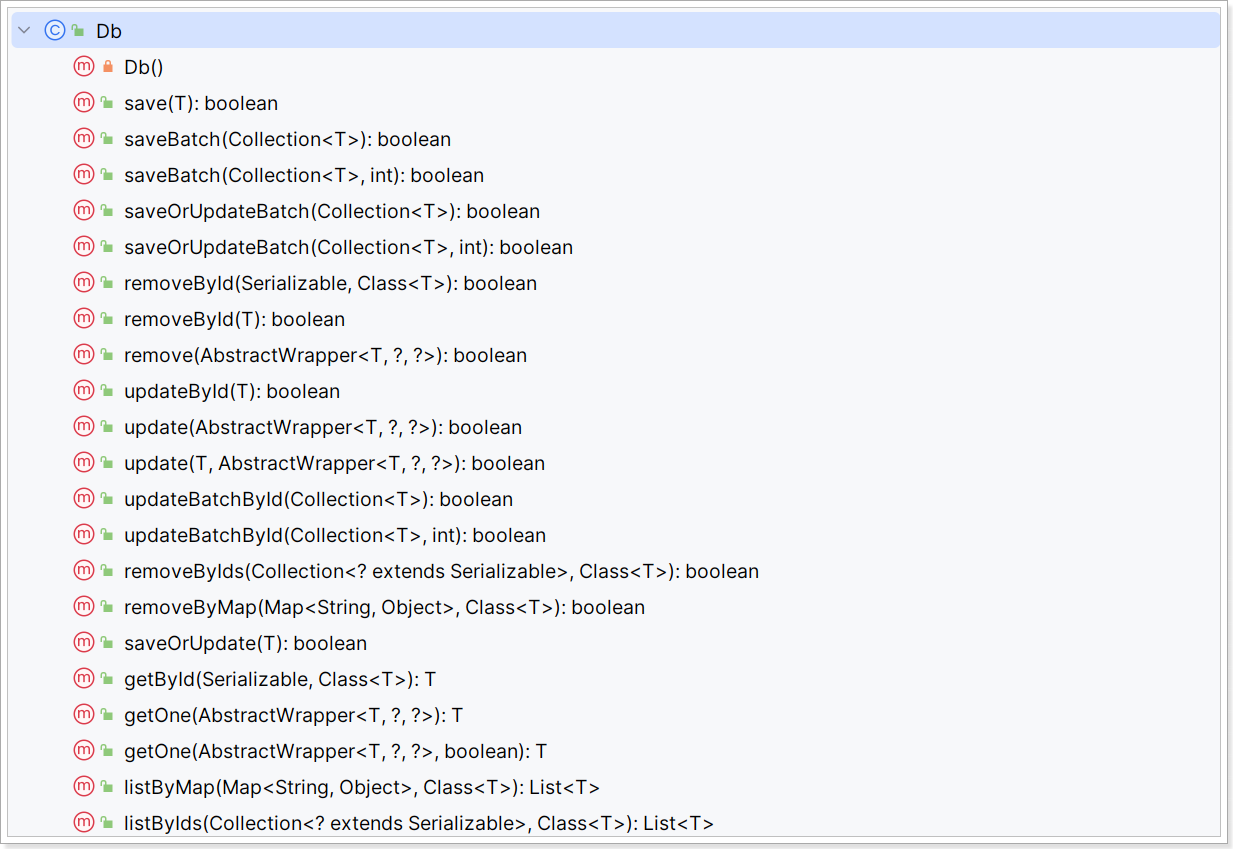
有的时候Service之间也会相互调用,为了避免出现循环依赖问题,MybatisPlus提供一个静态工具类:Db,其中的一些静态方法与IService中方法签名基本一致,也可以帮助我们实现CRUD功能:
3.2.1、基本使用
使用Db实现如下需求:
1、根据id查询用户; 2、查询名字中包含o且余额大于等于1000的用户; 3、更新用户名为Rose的余额为2000
创建 mp-demo\src\test\java\com\itheima\mp\service\DbTest.java如下:
java
package com.itheima.mp.service;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.baomidou.mybatisplus.extension.toolkit.Db;
import com.itheima.mp.domain.po.User;
import net.sf.jsqlparser.util.validation.metadata.NamedObject;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.List;
import static net.sf.jsqlparser.util.validation.metadata.NamedObject.user;
@SpringBootTest
public class DbTest {
//1.根据id查询用户
@Test
public void testQueryById() {
Db.getById(1L, User.class);
System.out.println(user);
}
//2.查询名字中包含o且余额大于等于1000的用户:
@Test
public void testQueryByNameAndBalance() {
List<User> userList = Db.lambdaQuery(User.class)
.like(User::getUsername,"o")
.ge(User::getBalance,1000)
.list();
for (User user : userList) {
System.out.println(user);
}
}
//3.更新用户名为Rose的余额为2000
@Test
public void testUpdate(){
Db.lambdaUpdate(User.class)
.set(User::getBalance,2000)
.eq(User::getUsername,"Rose")
.update();
}
}3.2.2、案例
需求:改造根据id用户查询的接口,查询用户的同时返回用户收货地址列表
1)导入AddressVO
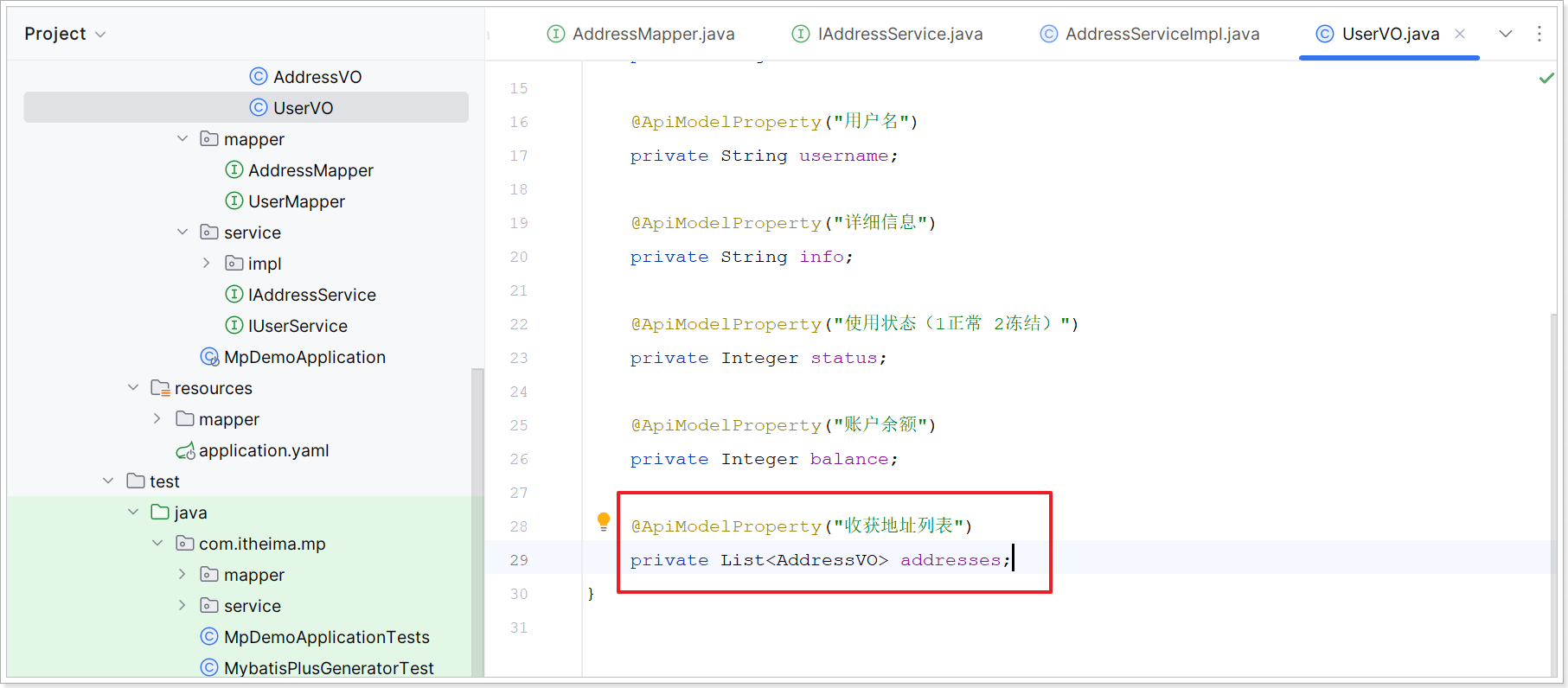
2)改造 UserVO
改造 `com.itheima.mp.domain.vo.UserVO` 添加一个地址列表属性:
3)UserController
修改 UserController 的原有方法如下:
java
@ApiOperation("根据id查询用户")
@GetMapping("/{id}")
public UserVO getUserById(@PathVariable("id") Long id) {
// User user = userService.getById(id);
// return BeanUtil.copyProperties(user, UserVO.class);
return userService.queryUserAndAddressById(id);4)IUserService
新增 IUserService 如下方法:
java
/**
* 根据id批量查询用户和地址
* @param ids
* @return
*/
List<UserVO> queryUserAndAddressByIds(List<Long> ids);5)UserServiceImpl
新增 UserServiceImpl 如下方法:
java
/**
* 根据id查询用户和地址
* @param id
* @return
*/
@Override
public UserVO queryUserAndAddressById(Long id) {
//1.查询用户信息
User user = getById(id);
UserVO userVO = BeanUtil.copyProperties(user, UserVO.class);
//2.根据用户id查询其对应的用户地址列表
List<Address> addressList = Db.lambdaQuery(Address.class)
.eq(Address::getUserId,id)
.list();
//3.转换为VO列表设置回userVO中
List<AddressVO> addressVOS = BeanUtil.copyToList(addressList, AddressVO.class);
userVO.setAddressList(addressVOS);
return userVO;
}在查询地址时,我们采用了Db的静态方法,因此避免了注入AddressService,减少了循环依赖的风险。
练习:改造根据用户id批量查询用户并返回用户的收货地址列表
java/** * 根据id批量查询用户和地址 * @param ids * @return */ @Override public List<UserVO> queryUserAndAddressByIds(List<Long> ids) { //1.根据id集合查询用户列表 List<User> userList = listByIds(ids); List<UserVO> userVOList = BeanUtil.copyToList(userList, UserVO.class); //2.根据用户id集合查询这些用户对于的地址列表 //如果一个用户有2个地址的话,会有两条记录在下面的集合中 List<Address> addressList = Db.lambdaQuery(Address.class) .in(Address::getUserId,ids) .list(); List<AddressVO> addressVOS = BeanUtil.copyToList(addressList, AddressVO.class); //希望可以将上面的列表转换为:map<用户id,用户地址列表> Map<Long, List<AddressVO>> userAddressMap = addressVOS.stream().collect(Collectors.groupingBy(AddressVO::getUserId)); //就可以循环用户列表,然后根据用户id从map中获取对应的地址列表 for (UserVO userVO : userVOList) { List<AddressVO> addressVOList = userAddressMap.get(userVO.getId()); userVO.setAddressList(addressVOList); } return userVOList; }注意:要使用Db的方法,必须有该实体对应的Mapper
4、分页插件
在未引入分页插件的情况下,MybatisPlus是不支持分页功能的,IService和BaseMapper中的分页方法都无法正常起效。 所以,我们必须配置分页插件。
4.1、配置分页插件
创建 mp-demo\src\main\java\com\itheima\mp\config\MybatisConfig.java 内容如下:
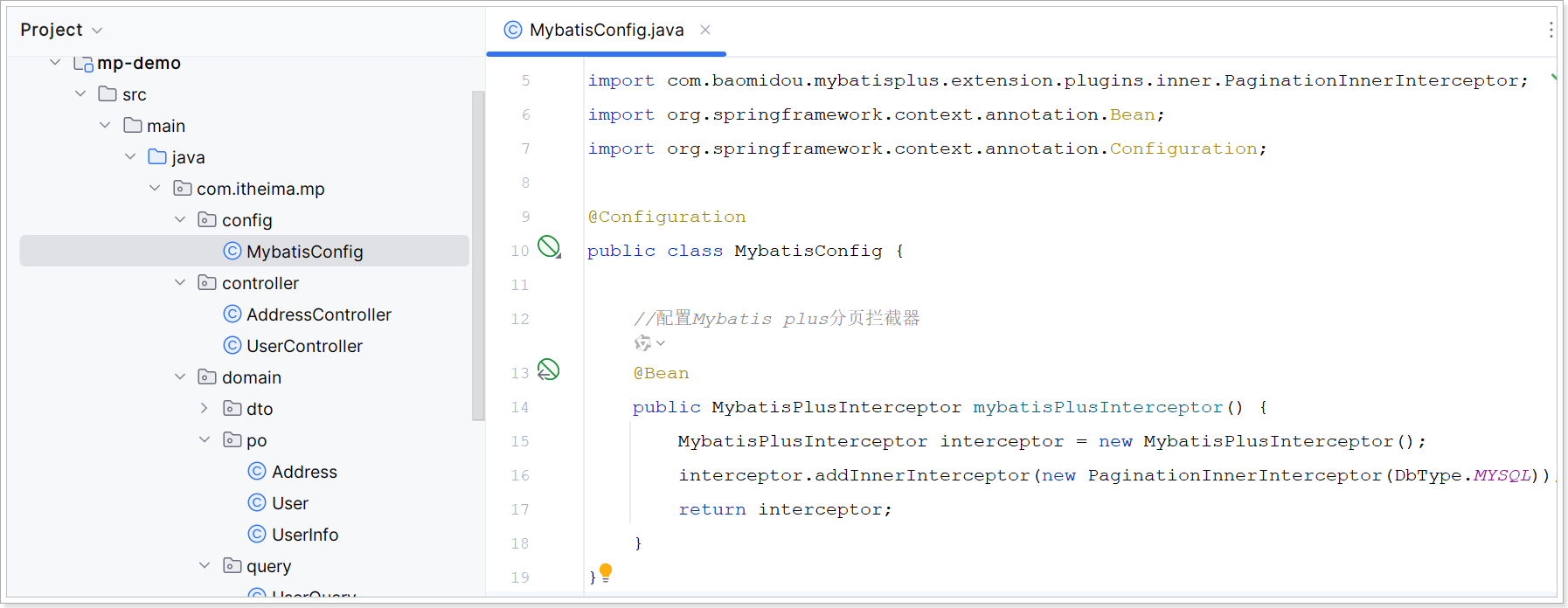
java
package com.itheima.mp.config;
import com.baomidou.mybatisplus.annotation.DbType;
import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;
import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class MybatisConfig {
//添加mybatis plus的分页插件
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor mybatisPlusInterceptor = new MybatisPlusInterceptor();
//添加分页拦截器
mybatisPlusInterceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return mybatisPlusInterceptor;
}
}4.2、分页API
新增 UserServiceTest 中测试分页的方法如下:
java
//测试分页
@Test
public void testPage() {
//创建一个分页对象
//new Page<>(当前页,每页记录数)
Page<User> page = new Page<>(2, 2);
//分页查询 select * from user limit 2,2
//limit 起始索引号 = (当前页-1)*每页记录数 每页记录数
Page<User> userPage = userService.page(page);
//输出分页的信息
System.out.println("总页码:" + userPage.getPages());
System.out.println("总记录数:" + userPage.getTotal());
for (User user : userPage.getRecords()) {
System.out.println(user);
}
}
在运行的时候能查看到分页的SQL语句。
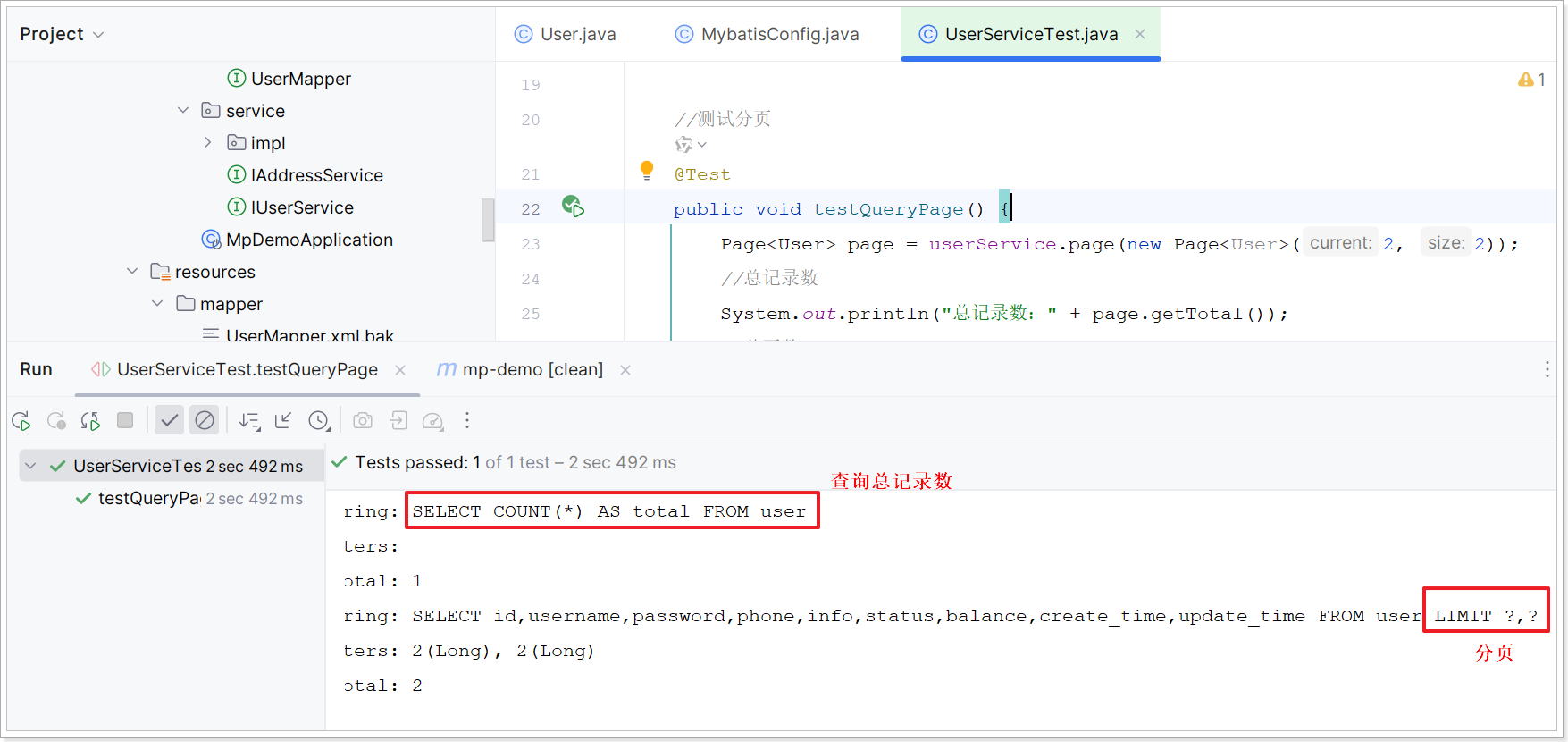
这里用到了分页参数,Page,即可以支持分页参数,也可以支持排序参数。如下:
java
//测试分页
@Test
public void testQueryPage() {
Page<User> p = new Page<>(2, 2);
//根据balance字段升序排列
p.addOrder(new OrderItem("balance", true));
Page<User> page = userService.page(p);
//总记录数
System.out.println("总记录数:" + page.getTotal());
//总页数
System.out.println("总页数:" + page.getPages());
for (User user : page.getRecords()) {
System.out.println(user);
}
}