本文根据 2025云栖大会演讲整理而成,演讲信息如下:
演讲人: 张治国 阿里云智能计算平台事业部MaxCompute 负责人 于得水 阿里云智能集团资深技术专家 谢德军 阿里云智能集团资深技术专家
在云栖大会的ODPS分论坛上,阿里云MaxCompute迎来了十五周年的重大技术发布。从云原生到AI原生,MaxCompute正式宣告迈入一个全新的发展阶段,推出AI原生数据仓库核心能力,构建面向AI时代的大数据基础设施。
此次升级不仅是对过去十五年技术沉淀的总结,更是对未来企业智能化转型的系统性回应。随着生成式AI的快速演进,海量、多模态、高复杂度的数据处理需求成为常态,传统大数据平台面临开发割裂、算力不足、管理混乱等多重挑战。为应对这一趋势,MaxCompute围绕统一数据底座、异构算力调度、模型与数据融合三大方向全面升级,实现从"传统数据仓库"向"AI原生数仓"的跃迁。
AI时代的挑战:数据、算力与模型的协同困境
在人工智能驱动的今天,数据的价值不再局限于统计分析和报表呈现,而是直接参与模型训练、推理决策与业务闭环。然而,企业在落地AI应用时普遍面临四大核心痛点。
首先是数据形态的多样化,图像、音频、视频、PDF等非结构化内容大量涌现,存储分散于不同系统,元数据不统一,难以形成全局视图。其次是开发流程的割裂。数据工程师依赖SQL进行ETL处理,而算法科学家则使用Python进行建模,两个群体在不同平台、不同语言、不同环境中工作,导致数据流转频繁、协作成本高昂。
与此同时,AI任务的计算负载具有显著的"脉冲式"特征------某段时间内需要爆发式算力完成全量数据预处理,其余时间仅需少量资源处理增量任务。传统架构难以实现秒级弹性扩缩,资源利用率低,成本居高不下。更深层次的问题在于工程化能力薄弱:自建集群运维复杂,开源组件集成困难,缺乏统一的模型管理机制,安全合规风险突出。 
面对这些挑战,企业需要一个能够整合数据处理与AI计算、兼顾性能与成本、支持敏捷开发与高效运维的一体化平台。这也是MaxCompute此次全面升级的核心出发点。
能力体系重塑:AI原生数据仓库的四大核心方向
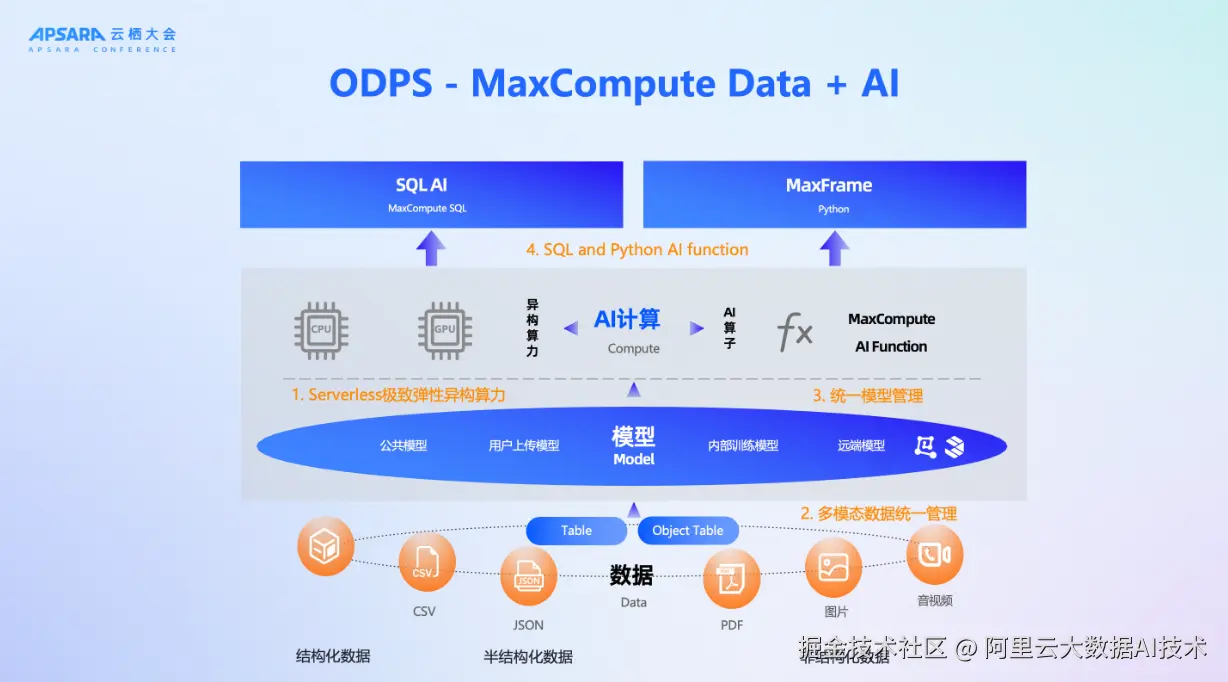 为解决上述问题,MaxCompute基于"Data+AI一体化"的设计理念,构建了一套覆盖数据、算力、模型与融合层的能力体系,旨在打造真正意义上的AI原生数据仓库。
为解决上述问题,MaxCompute基于"Data+AI一体化"的设计理念,构建了一套覆盖数据、算力、模型与融合层的能力体系,旨在打造真正意义上的AI原生数据仓库。
一、Serverless极致弹性异构算力:满足突发算力极致需求
MaxCompute始终以"Serverless"为核心理念,提供共享的计算资源池,支持按需使用、按量计费。在此基础上,平台进一步强化了自动弹性与异构算力支持能力。
通过AutoScaling,用户可配置分时弹性或启用全自动扩缩容策略,系统将基于历史负载与预测模型动态调整资源规模。更重要的是,平台已全面支持GPU资源的集成使用。用户可通过控制台一键开通GU配额,MC提供云上弹性的CPU与GPU的异构计算能力。
实测表明,MaxCompute 可在10秒内拉起10万CU计算资源,真正实现"用多少,付多少",满足AI任务对突发算力的极致需求。
二、多模态数据管理:打通"湖"与"仓"的边界
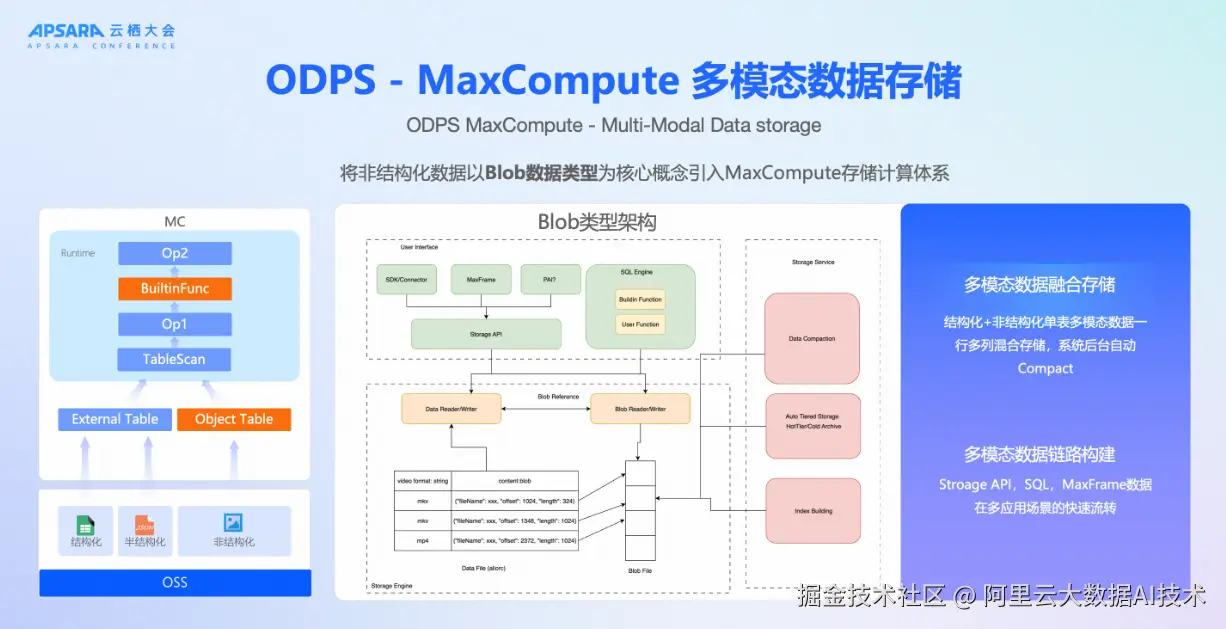 针对非结构化数据治理难题,MaxCompute提出了分层解决方案实现从数据发现到融合计算的完整链路。
针对非结构化数据治理难题,MaxCompute提出了分层解决方案实现从数据发现到融合计算的完整链路。
对于仍存于OSS等对象存储中的原始文件,平台提供Object Table能力,可将图片、音视频、PDF等非结构化文件映射为表对象,纳入统一元数据管理体系。用户可通过标准SQL查询其路径、大小、格式等信息,实现对湖上资产的集中治理。
而对于需要深度参与分析与训练的数据,平台推出了Blob数据类型,允许将非结构化内容直接写入MaxCompute内部表中,与STRING、STRUCT等结构化字段共存于同一行。这种混合存储模式,使得图像与其标签、文本与其嵌入向量可在同一记录中管理,为后续的联合查询与AI训练提供了坚实基础。
此外,平台还支持Schema-on-Read机制,对未定义Schema的湖上数据自动推断结构,降低接入门槛。这两种能力------Object Table用于湖上资产管理,Blob类型用于仓内融合计算------共同构成了MaxCompute多模态数据管理的核心支撑。
三、统一AI模型管理:让模型成为可编程的数据资产
 模型作为新一代数字资产,其重要性不亚于数据本身。为此,MaxCompute建立了完整的模型生命周期管理体系,支持多种来源的模型注册与调用。
模型作为新一代数字资产,其重要性不亚于数据本身。为此,MaxCompute建立了完整的模型生命周期管理体系,支持多种来源的模型注册与调用。
MaxCompute 支持公共模型(如Qwen3、DeepSeek-R1-Distill-Qwen)、用户导入模型、远端部署模型(如PAI-EAS服务)等多种类型,并提供版本控制能力,便于灰度发布与回滚操作。更重要的是,模型可在SQL和Python两种开发范式中无缝调用。无论是通过CREATE MODEL语句创建模型,还是在MaxFrame 脚本中加载LLM实例,开发者都能获得一致的使用体验。这种统一管理机制,打破了AI平台与数据平台之间的壁垒。
四、AI Function:构建数据与AI的连接器
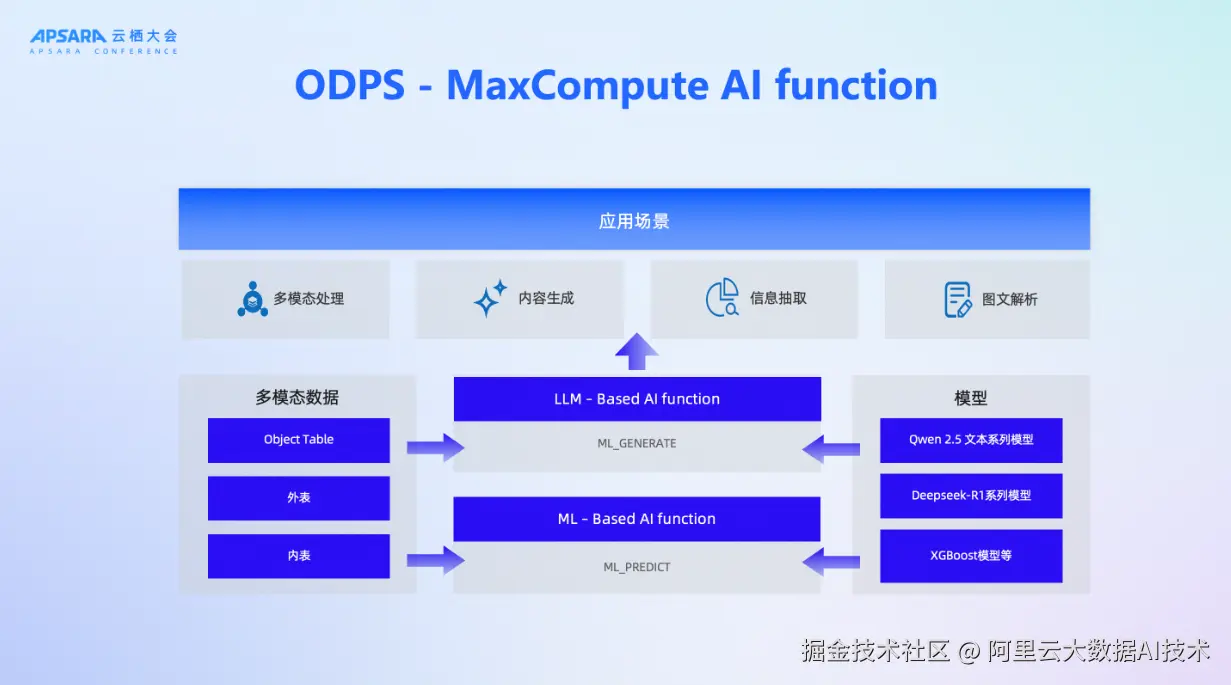 如何让大模型能力真正融入日常数据处理流程?MaxCompute推出AI Function,将大模型推理封装为可编程函数,用户无需部署、无需调参,即可在批处理作业中调用其能力。
如何让大模型能力真正融入日常数据处理流程?MaxCompute推出AI Function,将大模型推理封装为可编程函数,用户无需部署、无需调参,即可在批处理作业中调用其能力。
内置Qwen3、DeepSeek系列模型,支持结构化信息提取、文本翻译、Embedding生成等典型任务。例如,在处理非结构化就诊记录时,可通过AI_EXTRACT接口自动提取患者姓名、症状、诊断等字段;在处理跨国业务数据时,可调用AI_TRANSLATE实现高质量翻译。
这些函数不仅支持在CPU上运行轻量级模型,也可调度GPU资源执行高精度推理。实测表明,在百万行文本的结构化提取任务中,系统可在小时级稳定完成,吞吐能力达到行业领先水平。
核心技术突破:从SQL引擎到分布式Python引擎
在整体架构升级的背后,是多项关键技术的深度优化与创新突破。  在批处理性能方面,MaxCompute SQL引擎持续打磨复杂类型处理能力。通过对STRUCT、ARRAY等嵌套结构的列式存储重构,结合UNNEST算子的内部执行计划优化,显著减少了重复扫描与中间结果膨胀。在典型客户场景中,涉及复杂类型的查询性能提升达3倍以上。同时,Auto Partition功能支持基于表达式生成分区列,并结合强大的函数理解框架实现精准分区裁剪,进一步提升了查询效率。
在批处理性能方面,MaxCompute SQL引擎持续打磨复杂类型处理能力。通过对STRUCT、ARRAY等嵌套结构的列式存储重构,结合UNNEST算子的内部执行计划优化,显著减少了重复扫描与中间结果膨胀。在典型客户场景中,涉及复杂类型的查询性能提升达3倍以上。同时,Auto Partition功能支持基于表达式生成分区列,并结合强大的函数理解框架实现精准分区裁剪,进一步提升了查询效率。
在近实时能力建设上,Delta Table已成为统一的数据底座。它不仅兼容传统的追加写入模式,还支持主键更新与删除操作,满足流批一体的加工需求。基于此构建的Delta Live MV(增量物化视图)功能,实现了声明式、免运维的数仓分层机制。用户只需定义一次SQL逻辑,系统即可自动判断是否采用增量计算,分钟级刷新结果,相比传统链路成本降低90%。
与此同时,MaxQA查询加速引擎已完成公测验证,即将正式商业化。该引擎专为交互式分析设计,支持GB至TB级数据的秒级响应,且完全兼容MaxCompute SQL语法,包括UDF、Append Delta表和增量物化视图等功能。通过专属资源池配置,保障高并发场景下的稳定性,满足BI报表、即席查询等高频访问需求。 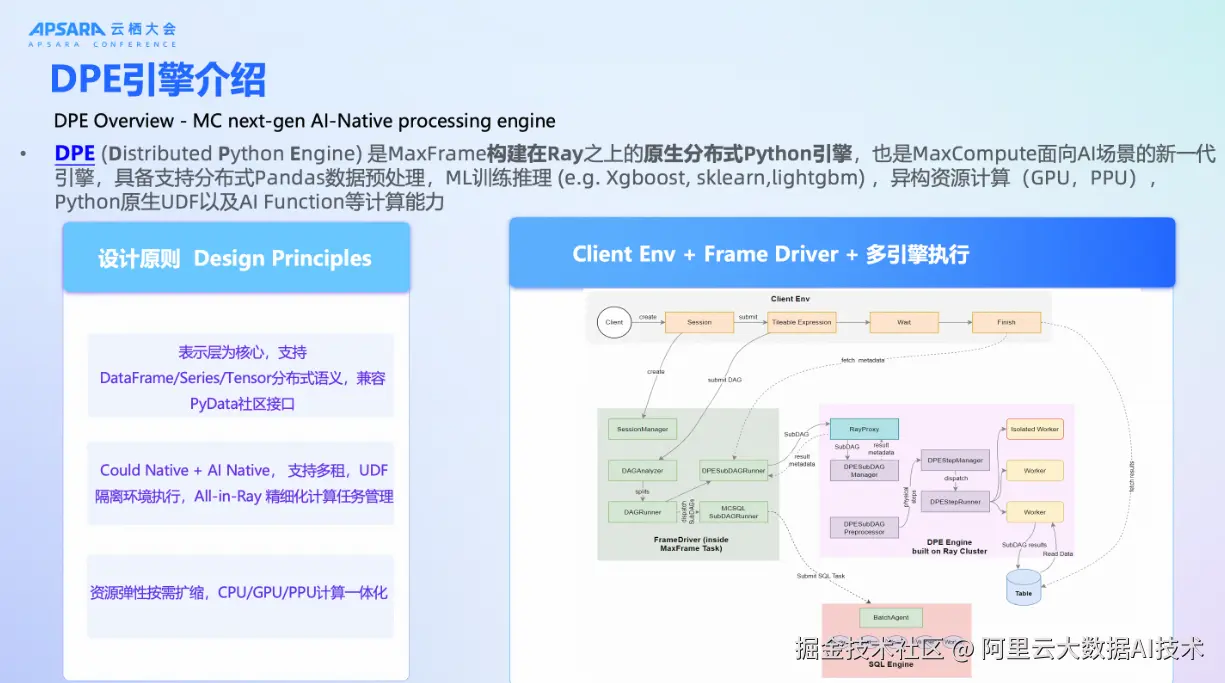 而在AI计算层面,新一代分布式Python引擎DPE(Distributed Python Engine)正式上线。该引擎基于Ray构建,但在接口层保留了MaxFrame对Pandas语义的高度兼容,开发者可像编写本地脚本一样开发分布式程序。无论是XGBoost模型训练,还是大规模Pandas数据清洗,均可在云端无缝运行。
而在AI计算层面,新一代分布式Python引擎DPE(Distributed Python Engine)正式上线。该引擎基于Ray构建,但在接口层保留了MaxFrame对Pandas语义的高度兼容,开发者可像编写本地脚本一样开发分布式程序。无论是XGBoost模型训练,还是大规模Pandas数据清洗,均可在云端无缝运行。
DPE的最大优势在于其"All-in-MaxCompute"的设计理念。所有任务均在统一管控下执行,资源调度精细化,故障恢复自动化。更重要的是,它与SQL引擎共享同一套元数据和存储服务,可在同一个作业流中自由切换执行引擎------部分逻辑由SQL处理,另一部分交由Python完成,全程无感知、无中断。
场景落地:MaxCompute 助力客户释放AI潜能
MaxCompute 新增能力目前已在多个行业场景中实现规模化落地。
在大模型训练领域,某头部厂商利用MaxFrame框架对千万级视频文件进行抽帧预处理。借助平台的海量弹性计算能力,任务在几十小时内顺利完成,相比原有方案效率提升数倍。整个过程无需搭建独立集群,开发人员通过Notebook交互式环境快速调试脚本,并通过自定义镜像确保本地与生产环境一致性,极大提升了研发效率。
在自动驾驶场景中,某汽车制造商需处理量产车与采集车回传的ROS Bag文件,包含摄像头、雷达、GPS等多源异构数据。通过MaxCompute的弹性能力,可在车辆返回后几分钟内拉起数十万CU资源完成解析,并将结构化结果写入明细表供后续分析使用。整个流程通过DataWorks编排,实现从数据接入、清洗标注到模型训练的端到端自动化。
此外,在金融、医疗、电商等行业,AI Function已被广泛用于合同信息抽取、病历结构化、用户评论情感分析等任务。以往需要数周开发周期的NLP应用,如今通过几行SQL即可实现,大幅降低了AI应用门槛。
未来展望:走向更智能的数据平台
站在十五周年的新起点,MaxCompute 不仅要成为企业最可靠的数据底座,更要成为驱动智能决策的核心引擎。从最初的离线数仓,到今天的AI原生数据仓库,MaxCompute的每一次进化,都源于对技术趋势的深刻洞察和对企业需求的精准把握。当数据与智能真正融为一体,每一个企业都将拥有前所未有的能力,去发现价值、创造价值、放大价值。
这场变革,正在发生。