前言

暑期,B站多媒体实验室带队参与了 ICCV MIPI (Mobile Intelligent Photography and Imaging) Workshop 的细粒度图像质量定位 (Detailed Image Quality Assessment Track) 国际挑战赛,提出创新的多模态训练策略,将综合指标提升了13.5%,最终获得了第二名的好成绩。本次参赛经历阶段性地验证了实验室在视频质量评价 (Video Quality Assessment,后文统称为 VQA) ,MLLM (Multimodal Large Language Model,多模态大语言模型) 以及强化学习上的成果积累,因此借本文的机会总结下比赛以及在以上领域一路以来的积累过程。

图1 B站带队联合上海交大提出多模态画质评价与诊断新方法
背景
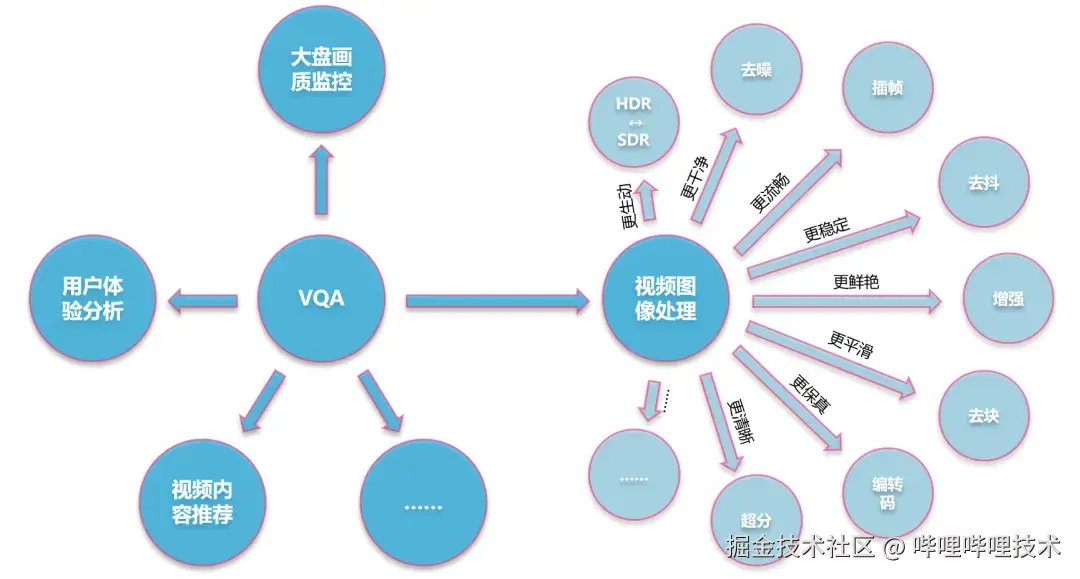
图2 视频质量评价在B站视频生产链路中可以发挥的作用
自从2023年秋上线 BILIVQA 2.0 视频质量评价算法以来,我们实验室一直致力于提升视频质量评价和视频图像处理之间的协同效应,期望能够借助 VQA 实现"视频画质预分析-自动化视频图像处理-自动化结果验收"的全链路系统。
但在业务实际使用过程中我们发现,视频画质失真类型多种多样,同时失真位置也不尽相同,难以通过单一 MOS (Mean Opinion Score,平均意见分数)来描述并指导视频图像处理。此外,我们的视频图像处理工具链中的模型算法对于不同失真类型的处理效果各有侧重,如果能够给出更细粒度的视频画质诊断结果,应用工具链时便能达到事半功倍的效果。因此,从去年开始,我们实验室就开始着手研究通过 MLLM 的强大理解能力来对视频画面进行语义 (high-level) 和画质 (low-level) 层面的细粒度分析。

图3 主流开源多模态大模型的图像动态分辨率处理方案
目前开源多模态大模型中的先进 (state of the art,后文统称为 SOTA) 且社区较为活跃的方案主要为 Qwen-VL 和 InternVL 系列,这两者在输入图像尺寸方面都有着非常灵活的调节机制,其中 Qwen-VL 更是对于视频数据专门设计了时域位置编码,天然契合视频画质分析任务。遗憾的是,Qwen-VL 和 InternVL 的技术报告中并没有体现在预训练阶段加入足够多的画质评估相关数据,因此我们需要手动收集这方面的数据对预训练模型做知识迁移。此外,开源的画质评估数据集基本都只有 MOS 标注,缺乏更细粒度的失真类型、失真细节等标注,如果手工标注需要耗费大量人力成本,靠模型生成又缺乏准确性。如果能够有一种无监督 or 弱监督的训练方法能够让模型拟合 MOS 的同时让其涌现生成推理过程 (chain of thought,后文统称为 CoT) 从而描述细节的能力,将非常有利于我们研发细粒度画质评估模型,因此我们注意到了当时横空出世的 GRPO 算法。
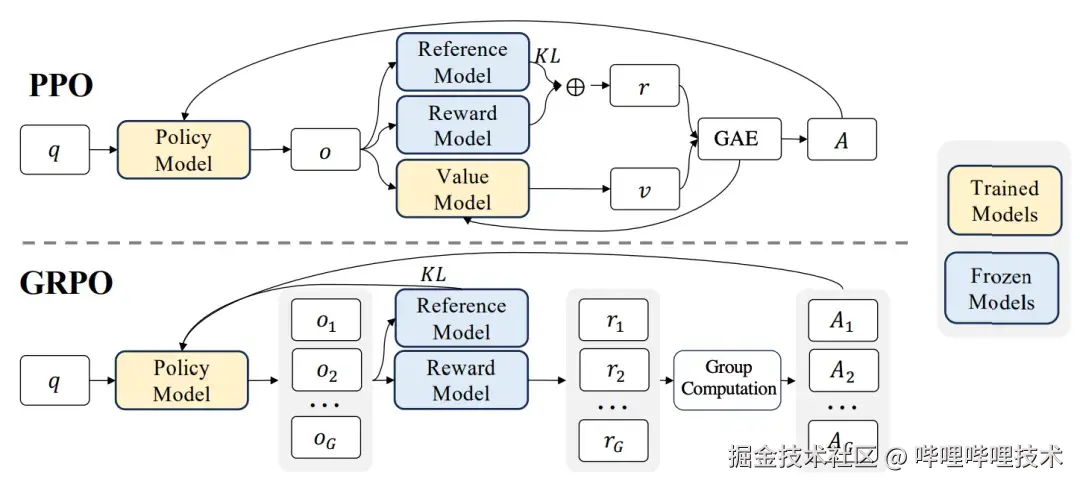
图4 GRPO 与 PPO 的区别
GRPO (Group Relative Policy Optimization,组相对策略优化)作为 PPO (Proximal Policy Optimization,近端策略优化)的简化版本,是由 Deepseek 提出的一种资源有限情况下的强化学习策略。通过对一个 prompt 采取较高的温度超参数来进行采样控制,获得一组 G 个不同的回答,同时利用奖励函数 (reward function) 替代奖励模型 (Reward Model) 计算奖励值(因为通常在数学和编程领域,有一套固定规则可以评价回答的好坏),进一步计算每个回答的相对优势 (Advance),从而驱动策略模型 (Policy Model,又称 Actor Model,这里指 LLM/MLLM) 的更新。相较于 PPO,GRPO 直接省略了价值模型 (Critic Model,预测状态价值参与优势的计算)和奖励模型,代价是动作 (Action) 和奖励 (Reward) 的不一致性可能会导致策略模型的优化过程过于稀疏,因为 GRPO 中的奖励是序列级别(根据模型完整输出确定奖励)而动作是 token 级别(模型预测的每一个 token 都依赖于上一个 token)。然而目前大部分语义理解任务的奖励都具有稀疏性,因此 GRPO 这样的极简化版本的 PPO 算法依旧可以发挥作用,进一步激发 LLM/MLLM 的能力。
今年2月份,业界陆续出现了一些将 GRPO 算法应用于 MLLM 的项目,彼时恰逢我们的 SDR2HDR 能力已基本覆盖动漫、纪录片等品类,业务方提出了自动化模型选择的需求,因此我们就以该项目作为出发点,实践 MLLM+GRPO 在视频画质及内容分析上的落地能力。本项目的核心需求是从内容相关的画面颜色与亮度的角度出发对视频进行分析,例如根据动漫视频多个镜头中人物脸部与周围环境的亮度差去判断整个视频的动态范围等级,最终选择合适的 SDR2HDR 模型进行生产。起初我们希望借助 GRPO 的特性赋予 MLLM 预测 CoT 的能力,从而能够详细描述视频画质内容细节,但在多次实验后发现对于小参数量模型(<=7b),虽然能够在 GRPO 过程中涌现生成较为合理的推理过程的能力,但是对可量化指标(例如终端模型选择准确率)的优化起到了一定程度的反作用。
因此最终我们还是从提升准确率的角度出发,设计并调优了一套 SFT+GRPO 的训练 pipeline,通过 SFT 将预训练模型能力快速迁移至业务数据 domain,之后借助 GRPO 进一步提升模型预测准确率,并通过取消 KL散度、不预测 CoT 等技巧达到了最优表现。这套训练方案相较于单独进行 SFT 或者 GRPO,在同等训练长度下,终端模型选择准确率提升在3个百分点左右,至此我们初步验证了 GRPO 对于 MLLM 在视频画质内容分析这个垂类应用上的有效性。
比赛介绍
图5 ICCV MIPI Workshop
今年我们注意到了 ICCV MIPI 举办的三个赛题,其中细粒度图像质量定位赛道综合考验了 MLLM 在画面内容理解、MOS 预测、失真类型预测以及失真位置定位上的能力,基本涵盖了细粒度视频画质诊断中的所有内容,能够以此为基础构建算法原型并服务于后续的业务能力验证。
由于比赛已于5月份启动,8月初截止,而我们能够腾出人力的时间点已经来到了7月,留给我们的时间只有短短1个月,因此我们选择以已经验证过有效的 SFT+GRPO 方案为基础,结合赛题数据的特性提出"数据压缩+困难样本挖掘"的技术路径,短时间内快速提升 MLLM 在 benchmark 上的表现。
数据压缩SFT
比赛开放的训练集拥有1万多条包含 MOS 标注的图像元数据,经过主办方人工标注失真类型和位置,并通过 GPT 生成了语义内容、失真细节等详细描述,最后通过 GPT 进一步生成3大类9小类共55万条数据(按 prompt 计)。三大类为描述、定位、感知,其中描述任务需要给出图片语义内容、所有存在的失真类型及位置以及整体 MOS,定位任务可以视为描述任务的子集只需要给出失真类型及位置,而感知任务以单选题的形式回答有关图片内容和画质的问题。比赛共分为6大指标,其中描述任务占3个,定位任务占2个,感知任务占1个。
经过初步测算,Qwen2.5-VL 7b 模型在8卡 L20 上跑完55万条数据的 SFT 训练可能需要近一周时间,时间成本和试错成本难以接受,因此我们采用了数据压缩的手段,将子类数据中"单个图像,多个问题"的部分整合成一条 prompt。整合之后,55万条数据骤降为11万条左右,实测能将原本一周左右的训练时间减少至两天,同时性能基本没有受到影响。
SFT 阶段在我们的训练 pipeline 中起到的作用主要有两点:1.将预训练模型能力快速迁移至垂类数据的 domain,为后续 GRPO 的训练创造冷启动条件;2.配合数据压缩,尽量抑制模型的过拟合现象,为后续 GRPO 阶段预留搜索空间。SFT阶段,Qwen2.5-VL 7b 模型的全参数都参与训练。
困难样本挖掘GRPO
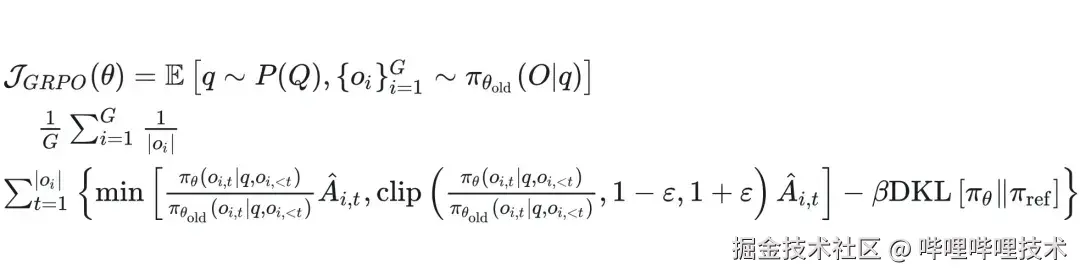
图6 GRPO目标函数
不难理解 GRPO 算法核心是依赖于策略模型 (MLLM) 本身的输出多样性,一旦策略模型随着训练逐渐收敛到较为集中的输出分布,G 个回答的方差变小甚至趋近于0,同时相对优势也会趋近于0,此时策略模型就没有足够的"探索"能力去找到更好的优化路径,就会造成所谓的"熵坍塌"。即使我们在 SFT 阶段通过一些手段尽量避免 MLLM 的熵坍塌现象,但相较于预训练模型,SFT 之后的模型(后文统称为 SFT 模型)不可避免地会有这样的问题。
因此我们提出了困难样本挖掘策略,通过 SFT 模型在训练集上进行一轮推理,筛选出其中"难度适中"(因为模型在 G 个回答全对 or 全错的样本上都无法进行学习,这也是 GRPO 算法局限性)的样本提供给后续 GRPO 阶段的训练。对于描述和定位任务类型的样本,我们通过设置合适的奖励阈值区间进行筛选;而对于感知任务类型样本,由于数据本身属于单选题,其奖励非0即1,因此我们依旧利用数据压缩策略将针对同个图片的问题回答得不全对的 prompt 整合成一条 prompt,并改造奖励函数根据答对问题数量给予奖励,避免 SFT 模型出现熵坍塌。
GRPO 阶段,我们冻结了 Qwen2.5-VL 7b 的 Vision Encoder (视觉编码器)参数,放开了 LLM 参数。
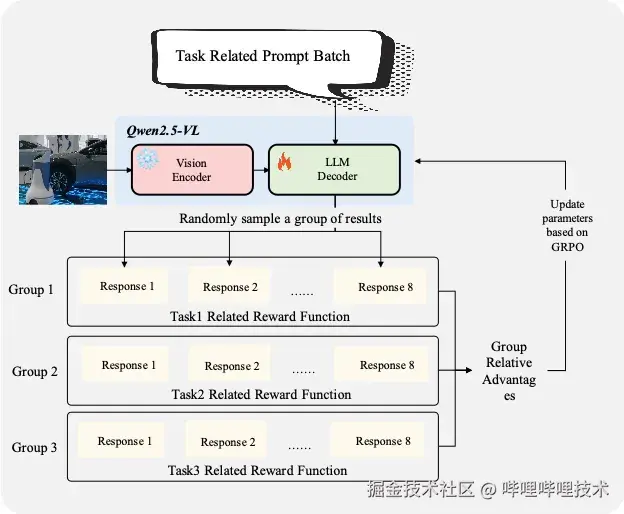
图7 我们的GRPO训练框架
比赛总结
通过上述方案,我们在 dev榜登顶,并在最终的 final榜中获得了第二名的成绩。由于参赛时间紧迫,我们只做完了 SFT+GRPO 联合优化这套方案,尽可能挖掘了 Qwen2.5-VL 7b 在赛题数据上的潜力,而没有时间去尝试迁移到诸如 InternVL3 等别的 MLLM 基座模型,这可能也是我们与第一名 (InternVL3 方案)的主要差距所在。按照 dev榜的测算,我们的数据压缩SFT模型总得分相较于基线(官方放出的 baseline,Qwen2-VL 7b SFT 模型)提升了0.22分,而通过困难样本挖掘 GRPO 进一步提升了0.13分,最终达到了2.86分(2.51->2.73->2.86)。
我们利用参赛模型在比赛的 dev榜测试集上做了一些可视化,如下图所示:
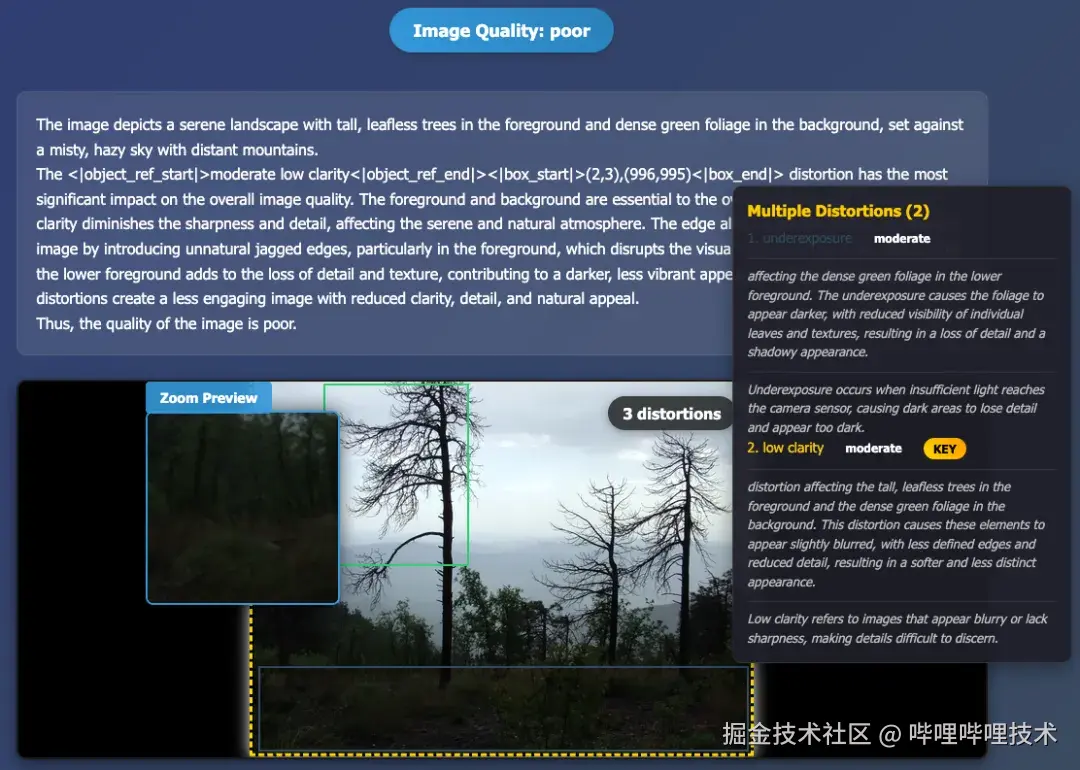
图8 参赛模型的部分结果可视化
首先模型认为整张图片的质量属于"差"的水平,并对图片内容进行了简单描述:这张图片描绘了一幅宁静的风景,前景是高大、无叶的树木,背景是茂密的绿叶,远处是薄雾弥漫的天空和山脉。之后,模型给出了图片中存在的三种失真类型,分别是绿框代表的"边缘锯齿"(描述未在图中显示),深蓝框代表的"欠曝光",以及黄框(整张图片)代表的"低清晰度";且模型认为影响图片最严重的因素是"低清晰度",在输出中会特别强调。我们在可视化中加入了 "KEY" 的标识代表关键失真。
展望未来
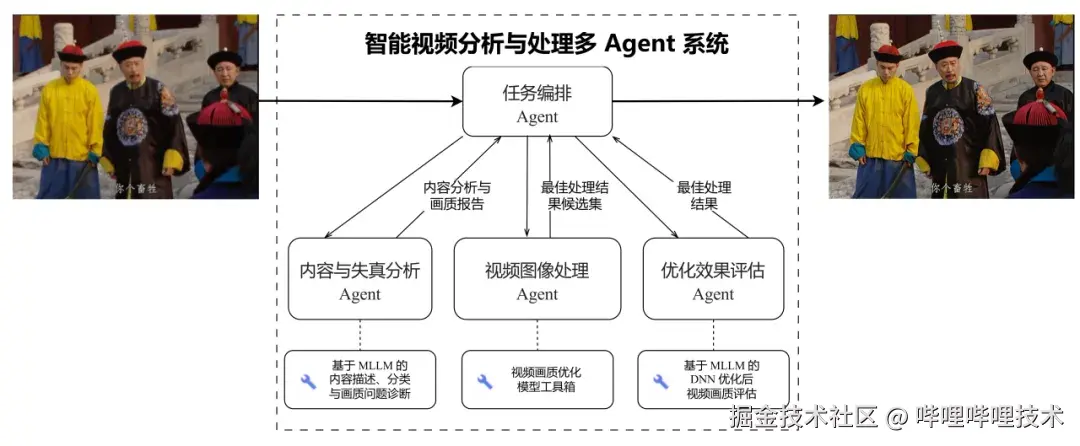
图9 智能视频处理系统
通过这次比赛,我们基本验证了 SFT+GRPO 联合优化策略在细粒度视频画质内容分析上带来的显著提升,同时也孵化了一个可用的原型模型,后续将基于此模型搭建"内容与失真分析-视频图像处理-优化效果评估"的全链路系统,并最终为 B站画质相关业务赋能。这里简单介绍下我们对于智能视频处理系统的规划,主要分为三个步骤,其中"内容与失真分析"及"优化效果评估"均交由 MLLM 处理,只是侧重点略有不同:前者侧重于对自然 (in-the-wild) 视频的评估,依靠我们目前的模型能力基本可以 cover;而后者更侧重于对处理(经由我们的画质模型工具链)后视频的评估,可能还需要进一步收集数据迭代优化。而对于中间环节"视频图像处理",目前的设计还是根据前置步骤的结果,基于规则的模式去选择画质模型工具链中的模型进行处理,但在未来可能会由经过"模型选择-画质反馈"数据训练后的 MLLM 接管。我们始终相信,只要经过合理的设计和精心的打磨,LLM/MLLM 在 AGI 尚未实现的今天,已经可以为企业和个人在提效方面做出巨大的贡献。
哔哩哔哩多媒体实验室(bilibili mlab)是一支技术驱动的年轻队伍,具备完善的多媒体技术能力,以极致卓越的多媒体体验为目标,通过对多模态视频内容分析、视频图像分析与处理、画质评价、自研视频编码器、高效转码策略等技术的持续打磨和算法创新,提出了诸多高质量的多媒体解决方案,从系统尺度提升了整个多媒体系统的性能和效率。
-End-
作者丨bilibili & SJTU