前言:
1、把这个kafka源码clone到本地,用idea打开文件夹(安装了scala、gradle等)
2、这是自己读源码的时候一个记事本,我把这个当成word当成.md文件用,内容是供我自己读源码方便实用的
3、我读源码的主要目的是要搞清楚数据是怎么流转的,就是站在kafka的角度看数据是如何从生产者到消费者的,从应用到kafka,从kafka到应用的
4、当前文件还在持续更新中......
这个是他的这个流程图
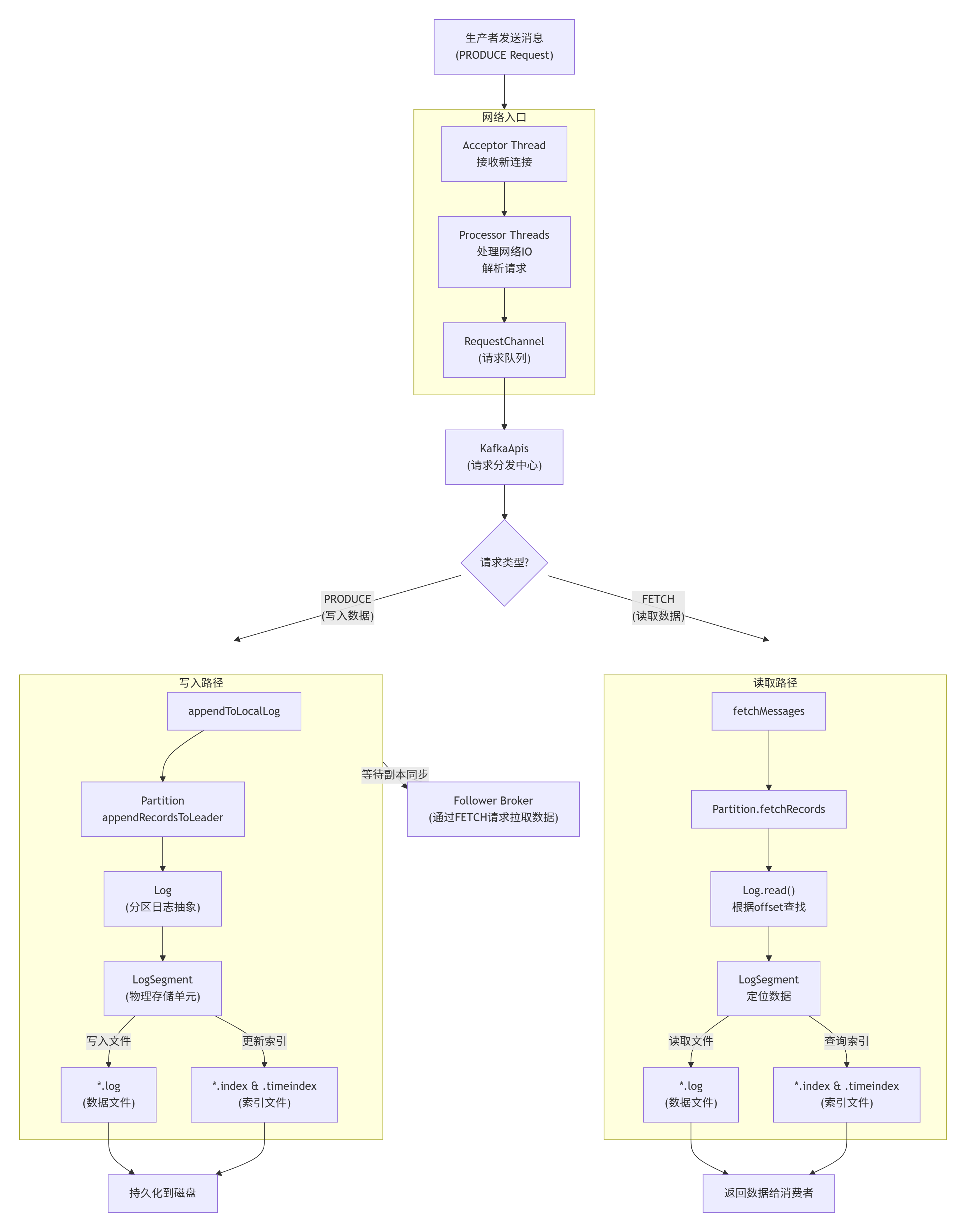
a. 那么我想根据这个流程去看kafka的源码我从那个类或者方法入手?
基于刚才的流程图,我为您规划一个循序渐进的源码阅读路径,从入口到核心,让您能够系统地理解 Kafka 的数据流转。
🗺️ Kafka 源码阅读路线图(按数据流顺序)
第一阶段:启动入口和网络层
目标:理解 Kafka Broker 如何启动和接收网络请求
1. 启动入口 - Kafka.scala
// 文件:core/src/main/scala/kafka/Kafka.scala
object Kafka {
def main(args: Array[String]): Unit = {
// 这是整个 Kafka Broker 的启动入口
}
}
阅读 main()方法,看如何解析配置
跟踪到 KafkaServerStartable或直接到 KafkaServer
2. 服务核心 - KafkaServer.scala
// 文件:core/src/main/scala/kafka/server/KafkaServer.scala
class KafkaServer {
def startup(): Unit = {
// 重点关注这些组件的初始化顺序
socketServer = new SocketServer(...) // 网络服务器
replicaManager = new ReplicaManager(...) // 副本管理器
kafkaApis = new KafkaApis(...) // API处理器
// ... 其他组件
}
}
重点方法:startup()- 看各个核心组件的初始化顺序
理解 SocketServer, ReplicaManager, KafkaApis的创建和启动
3. 网络接收 - SocketServer.scala
// 文件:core/src/main/scala/kafka/network/SocketServer.scala
class SocketServer {
// Reactor 模式实现
private val acceptors = ... // 接收器
private val processors = ... // 处理器线程池
}
研究 Acceptor和 Processor类
理解 RequestChannel请求队列的作用
推荐调试方法:在 KafkaServer.startup()设置断点,启动一个 Broker,观察启动流程。
第二阶段:请求分发和处理(2-3天)
目标:理解请求如何被路由到具体的业务逻辑
4. 请求分发中心 - KafkaApis.scala
// 文件:core/src/main/scala/kafka/server/KafkaApis.scala
class KafkaApis {
def handle(request: RequestChannel.Request): Unit = {
request.header.apiKey match {
case ApiKeys.PRODUCE => handleProduceRequest(request)
case ApiKeys.FETCH => handleFetchRequest(request)
// ... 其他API类型
}
}
}
重点方法:handle()- 请求路由逻辑
分别跟踪 handleProduceRequest()和 handleFetchRequest()
5. 副本管理层 - ReplicaManager.scala
// 文件:core/src/main/scala/kafka/server/ReplicaManager.scala
class ReplicaManager {
def appendToLocalLog(...): Unit = { ... } // 写入路径
def fetchMessages(...): Unit = { ... } // 读取路径
}
写入入口:appendToLocalLog()→ appendRecords()
读取入口:fetchMessages()
理解如何通过分区找到对应的 Log对象
推荐调试方法:启动生产者发送一条消息,在 handleProduceRequest()设置断点跟踪。
第三阶段:存储引擎核心(3-5天)
目标:深入理解消息如何被持久化存储
6. 分区抽象 - Partition.scala
// 文件:core/src/main/scala/kafka/cluster/Partition.scala
class Partition {
def appendRecordsToLeader(records: MemoryRecords): LogAppendInfo = {
log.append(records) // 委托给Log对象
}
}
理解 Partition与 Log的关系
跟踪写入和读取如何委托给底层的 Log
7. 日志管理 - Log.scala
// 文件:core/src/main/scala/kafka/log/Log.scala
class Log {
def append(records: MemoryRecords): LogAppendInfo = {
// 验证消息、分配偏移量、写入活跃段
val segment = activeSegment // 当前活跃段
segment.append(...) // 委托给LogSegment
}
def read(startOffset: Long, maxLength: Int): LogReadInfo = {
// 查找消息、读取数据
}
}
重点方法:append()和 read()
理解日志分段(LogSegment)的管理
8. 物理存储 - LogSegment.scala(您刚才读的)
// 文件:core/src/main/scala/kafka/log/LogSegment.scala
class LogSegment {
def append(...): Unit = {
log.append(records) // 写入.log文件
offsetIndex.append(...) // 更新偏移量索引
timeIndex.maybeAppend(...) // 更新时间戳索引
}
}
这是数据最终落地的地方
理解索引机制和文件操作
第四阶段:深入特性和优化(可选,持续学习)
9. 副本同步机制
研究 Follower 如何通过 Fetch 请求同步数据
理解 ISR 列表维护和高水位线更新
10. 事务消息实现
研究 TransactionCoordinator和事务日志
理解 exactly-once 语义的实现
🔧 实用的源码阅读技巧
1. 调试环境设置
在 IDEA 中创建运行配置:
Main class: kafka.Kafka
Program arguments: config/server.properties
VM options: -Dlog4j.configuration=file:config/tools-log4j.properties
2. 关键断点位置
// 网络接收
SocketServer.accept() // 新连接接收
Processor.run() // 请求处理
// 业务处理
KafkaApis.handle() // 请求路由
KafkaApis.handleProduceRequest() // 生产者请求
KafkaApis.handleFetchRequest() // 消费者请求
// 存储引擎
ReplicaManager.appendToLocalLog() // 写入入口
Log.append() // 日志写入
LogSegment.append() // 物理写入
3. 跟踪一条消息的完整路径
启动本地 Kafka,然后:
在 KafkaApis.handleProduceRequest()设置断点
使用 kafka-console-producer 发送一条测试消息
逐步调试,跟踪整个调用栈
4. 实用的搜索命令
在源码目录中搜索关键方法:
# 查找所有调用某个方法的地方
grep -r "appendToLocalLog" . --include="*.scala"
# 查找类定义
find . -name "*.scala" -exec grep -l "class ReplicaManager" {} \;今天(2025.10.15)重新回顾了一下自己读源码的根本目的,是为了过段时间公司数据迁移这个大任务做知识储备,自己现在的学习准备方向有点偏离了
我现在算是处于第一阶段吧,会写对应的kafka的接口,但是谈不上高效使用。调整目标先做到2、3这两点,以及第四点中的部分关键源码(下面这个阶段是我自己定义的,找AI补充的)
| 阶段 | 描述 | 对应能力 |
|---|---|---|
| 1. 使用Kafka | 会安装配置、基本API调用 | 知道怎么让Kafka跑起来 |
| 2. 高效使用Kafka | 理解配置参数调优、监控指标 | 能让Kafka跑得又快又稳 |
| 3. 懂Kafka的原理 | 理解副本机制、ISR、控制器选举等 | 知道Kafka为什么快、为什么可靠 |
| 4. 读Kafka的源码 | 深入代码层面理解实现细节 | 能从代码层面排查问题 |
| 5. 清楚Kafka的设计方式 | 理解架构决策背后的设计哲学 | 知道Kafka为什么这样设计 |
| 6. 清楚源码中为什么这样用 | 理解具体编码实现的取舍 | 具备参与Kafka开发的能力 |
高效使用kafka:
这文章写的太好了。高效使用这部分我看的这个https://blog.csdn.net/sjdgehi/article/details/146180933
kafka中消息从哪来到哪去:
Producer 将消息发送到指定的 Topic。
消息被分配到 Partition 中。
消息会被持久化存储在磁盘中,通常以 Log 的形式存储。
Consumer 通过订阅 Topic 来消费消息。Kafka 会记录消费者的消费位置(offset)。
Consumer Group:多个消费者可以组成一个 Consumer Group,以实现负载均衡。
4.5 常见问题与解决方案
问题 解决方案
消息丢失 调整 acks 配置,确保消息被所有副本确认
消费者消费速度慢 调整 max.poll.records 和 fetch.min.bytes 配置
Kafka 集群不可用或崩溃 确保 Kafka 集群的副本机制和 Zookeeper 配置正确kafka原理:
-
当数据积压时,你知道是生产者瓶颈、网络瓶颈还是消费者瓶颈
-
当出现数据丢失时,你知道是
acks配置问题、ISR收缩问题还是磁盘问题 -
当消费延迟时,你知道该调整
fetch.min.bytes还是增加分区数 -
当需要保证精确一次语义时,你知道如何配置事务和幂等性
读关键源码:
十几PB的数据迁移肯定会遇到各种诡异问题,而官方文档和网络文章无法覆盖所有边界情况。
// 比如你想知道为什么消费突然变慢 // 阅读 Fetcher.sendFetches() 和 Fetcher.fetchedRecords() 源码 // 你会发现有复杂的异步抓取和批次处理逻辑
// 配置说 max.poll.records=500,但实际可能一次只拉取到10条 // 阅读源码你会发现还有 fetch.min.bytes 和 fetch.max.wait.ms 的限制
// 通过阅读 ReplicaManager 的源码,你知道如何监控真正的同步延迟 // 而不是依赖表面的监控指标