将 JAR 包上传到 Linux 虚拟机
①确保pom.xml中添加了 Maven 打包插件,用于将项目打包成可执行 JAR
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>8</source>
<target>8</target>
<encoding>UTF-8</encoding>
<!-- <verbal>true</verbal> -->
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.6.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<minimizeJar>true</minimizeJar>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>maven-compiler-plugin的3.1版本支持JDK1.8
<source>/<target>级别写8或1.8均可,都代表同一个Java工具包
maven-shade-plugin的3.6版本支持JDK1.8
②打开 IDEA 的 Maven 面板(右侧边栏)
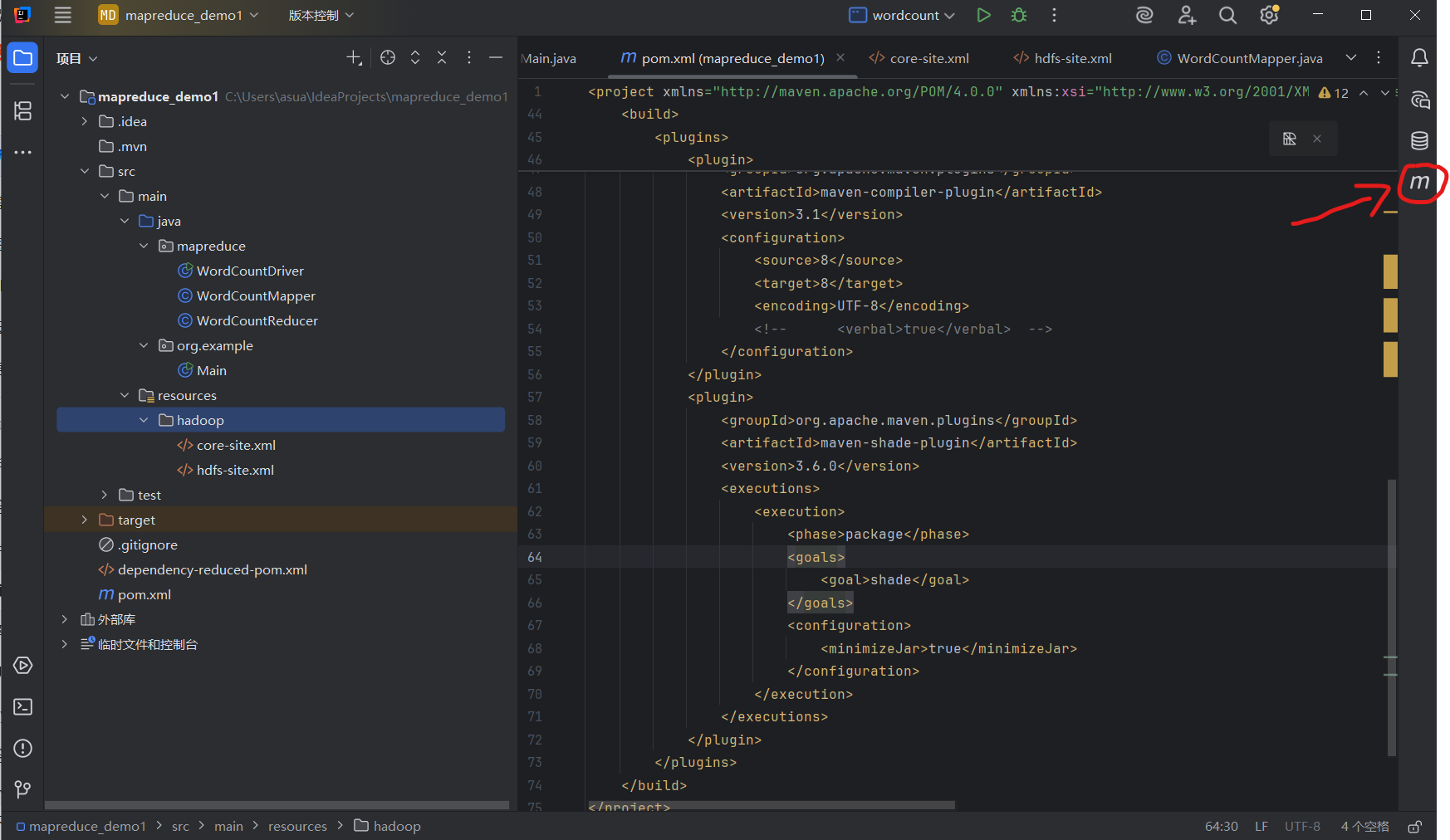
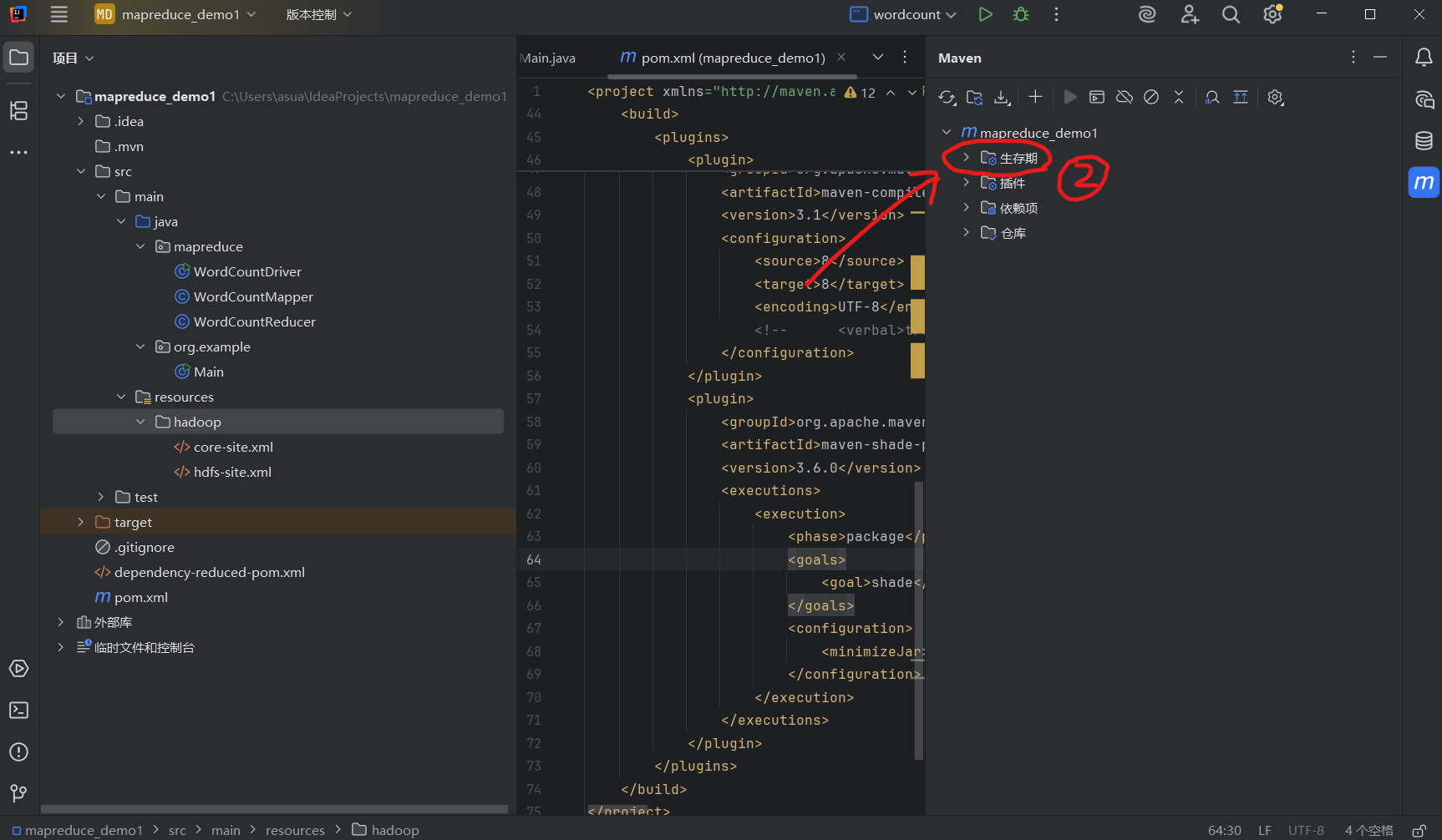
③展开生存期(Lifecycle),双击package,Maven 会自动编译并打包项目
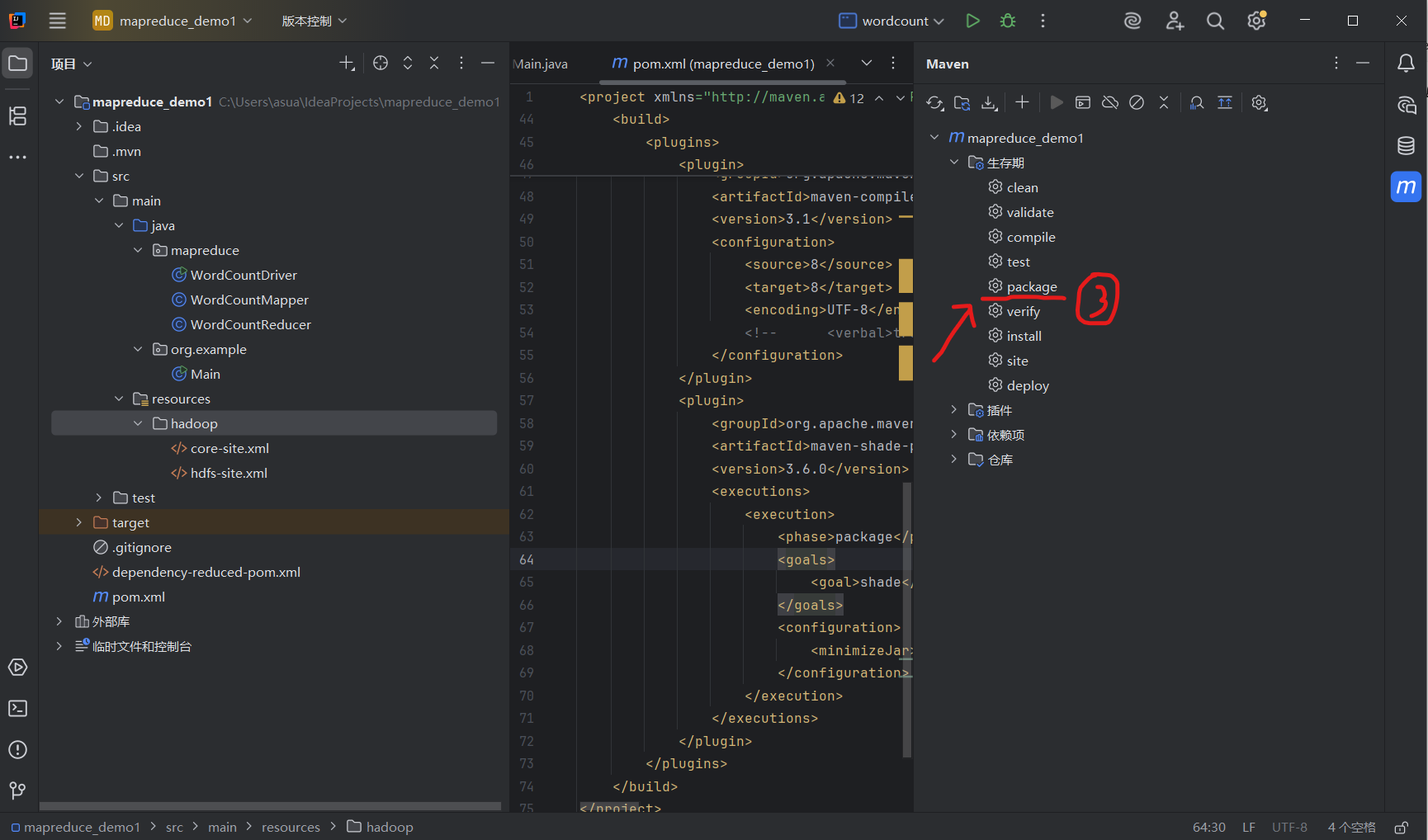
④打包完成后,JAR 包会生成在项目的target目录下,如果忘记了项目目录,光标移动到项目名上会出现
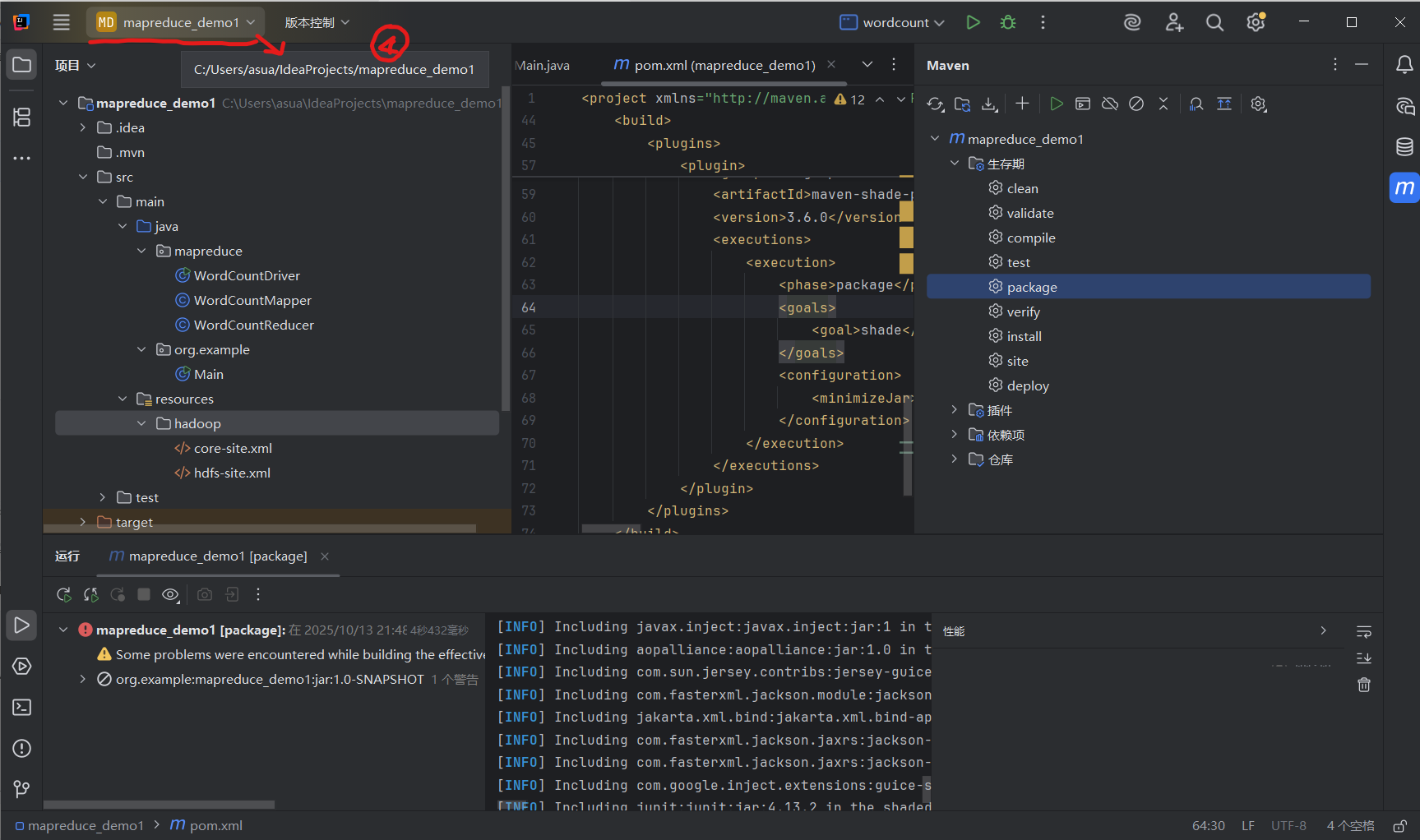
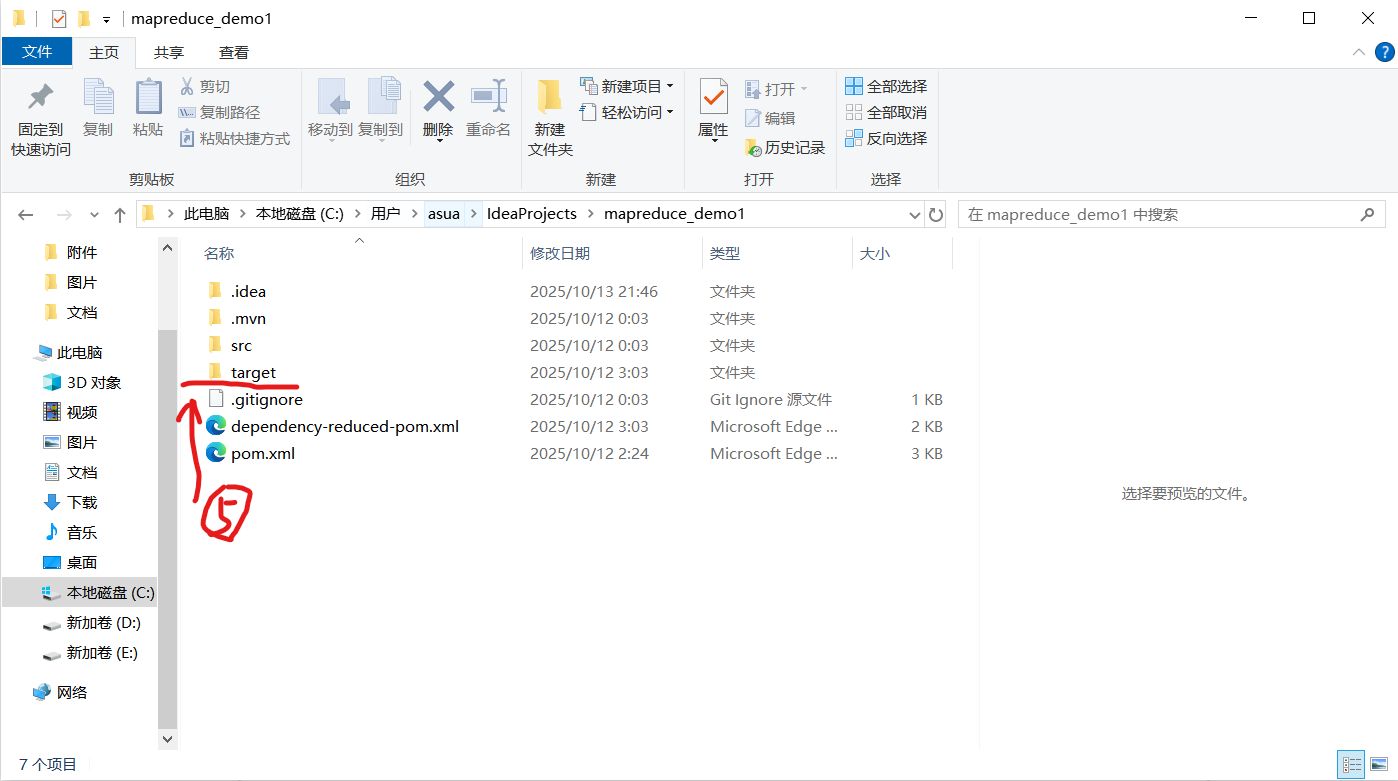
⑤选择jar包复制,到Linux系统中粘贴:
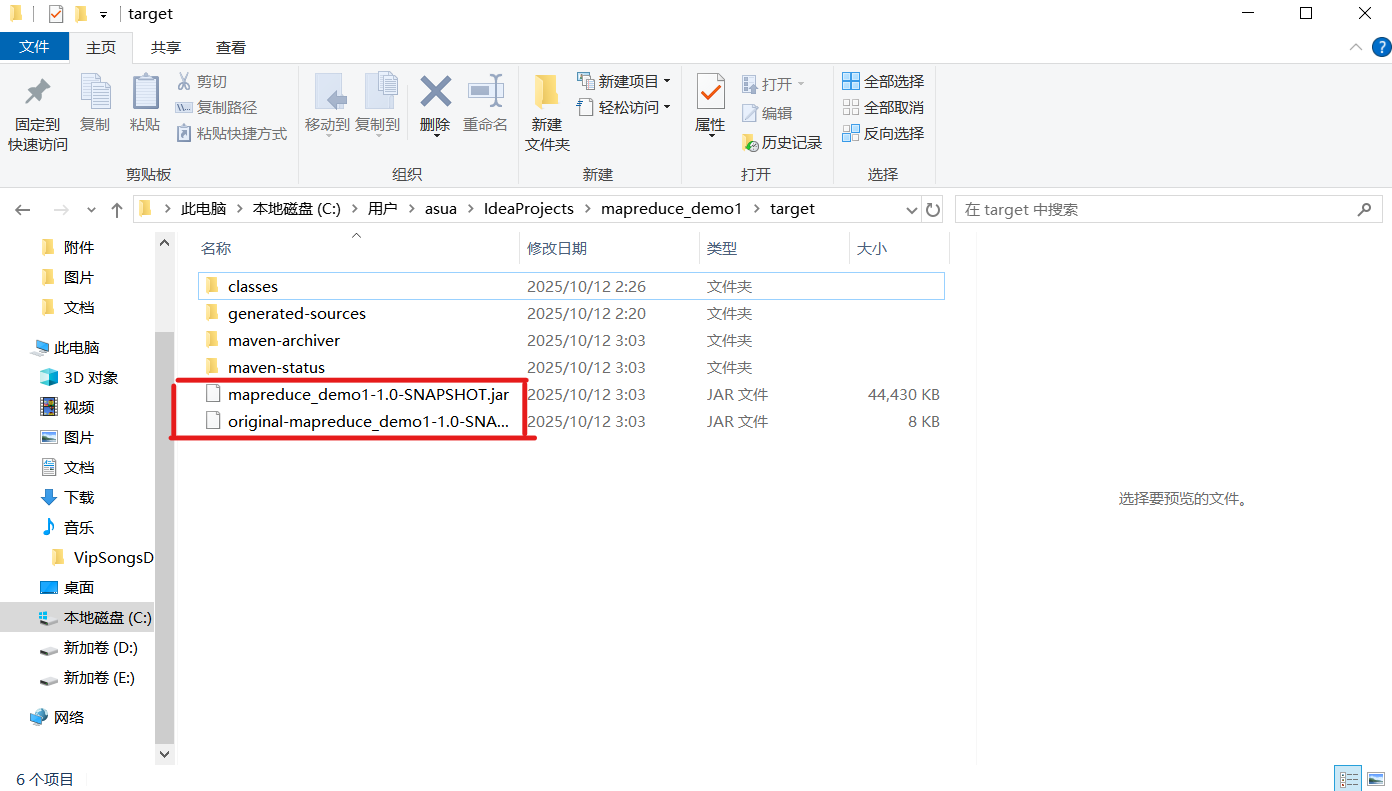
第一个jar包:
如果运行环境没有提供项目所需的依赖(比如在一个没有预装 Hadoop 相关类库的环境中运行 MapReduce 程序),就需要使用这种包含了所有依赖的胖 JAR,这样程序才能在缺少外部依赖的环境中独立运行。
original 开头的jar包:
不会包含项目所依赖的第三方库,当Linux 上的 Hadoop 集群已经提供了项目所需的所有依赖,那么只需要上传项目自身的代码 JAR 就能运行
在 Linux 虚拟机中运行 JAR 包
①启动Hadoop 集群,通过jps命令验证,NameNode、DataNode、ResourceManager、NodeManager均正常启动:
start-all.sh
jps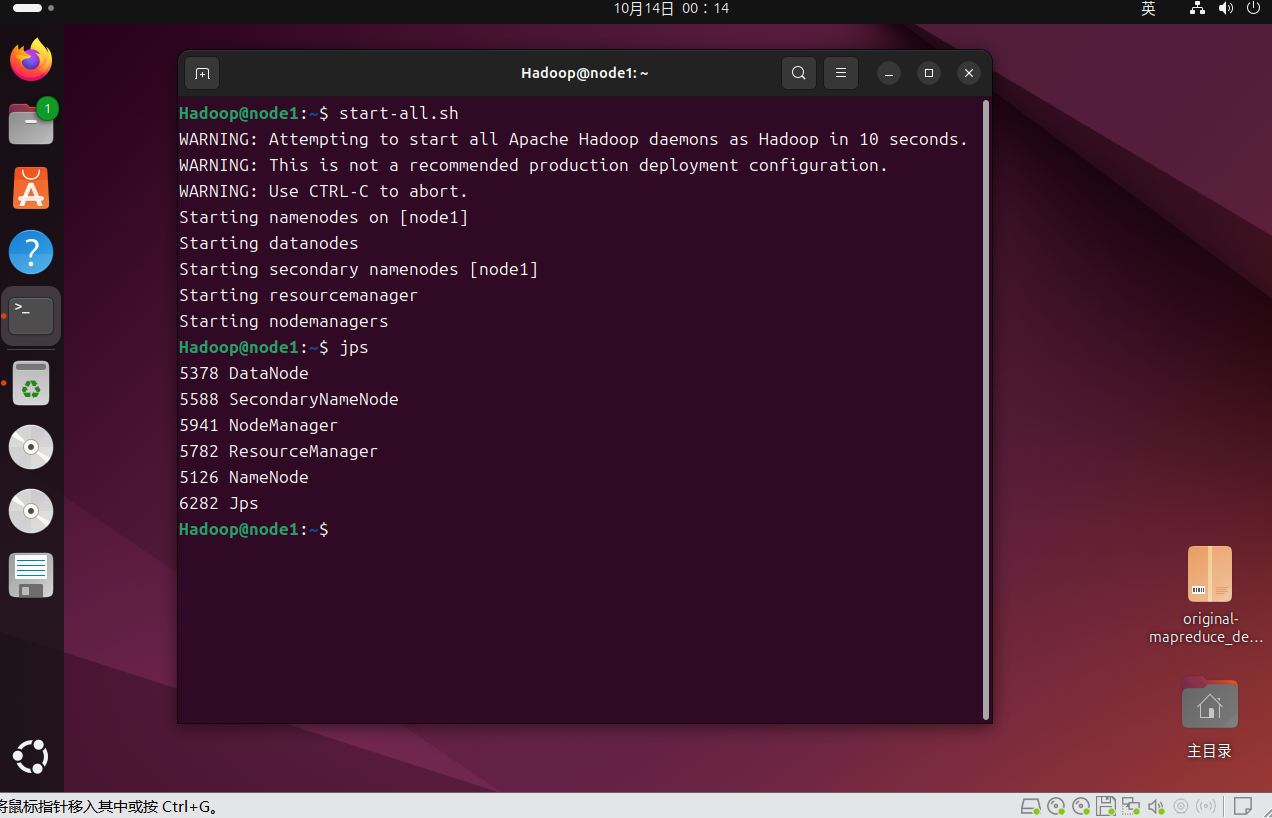
#如果是特定任务需要完成前置步骤,比如单词统计需要创建input文件并上传到hdfs上,这里是通用的关键步骤
② 运行 MapReduce JAR 包
使用 hadoop jar 命令提交作业,格式为:
hadoop jar 你的JAR包路径 主类全限定名 HDFS输入路径 HDFS输出路径
示例(假设 JAR 包为 wordcount.jar,输入路径为 /input,输出路径为 /output):
hadoop jar /home/hadoop/wordcount.jar mapreduce.WordCountDriver /input /output