目录
kubernetes集群规划
| 主机IP | 主机名 | 主机配置 | 角色 |
|---|---|---|---|
| 10.0.0.110 | master01 | 2C/4G | 管理节点 |
| 10.0.0.111 | master02 | 2C/4G | 管理节点 |
| 10.0.0.112 | master03 | 2C/4G | 管理节点 |
| 10.0.0.113 | node01 | 2C/4G | 工作节点 |
| 10.0.0.114 | node02 | 2C/4G | 工作节点 |
| 10.0.0.115 | k8s-ha1 | 1C/2G | LB |
| 10.0.0.116 | k8s-ha2 | 1C/2G | LB |
集权前期环境准备
以下前期环境准备需要在所有节点都执行
1.修改每个节点主机名
hostnamectl set-hostname master01
hostnamectl set-hostname master02
hostnamectl set-hostname master03
hostnamectl set-hostname worker01
hostnamectl set-hostname worker02
hostnamectl set-hostname k8s-ha1
hostnamectl set-hostname k8s-ha2
2.配置集群本地解析
echo "10.0.0.110 master01" >> /etc/hosts
echo "10.0.0.111 master02" >> /etc/hosts
echo "10.0.0.112 master03" >> /etc/hosts
echo "10.0.0.113 worker01" >> /etc/hosts
echo "10.0.0.114 worker02" >> /etc/hosts
echo "10.0.0.115 k8s-ha1" >> /etc/hosts
echo "10.0.0.116 k8s-ha2" >> /etc/hosts
3.开启bridge网桥过滤
bash
cat > /etc/sysctl.d/k8s.conf <<EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
加载br_netfilter模块
modprobe br_netfilter && lsmod | grep br_netfilter
加载配置文件,使上述配置生效
[root@master01 ~]#sysctl -p /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 14.配置ipvs功能
bash
下载软件包
yum -y install ipset ipvsadm
写入ipvs模块到文件中
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack
EOF
执行文件
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack5.关闭SWAP分区
bash
临时关闭
swapoff -a
永久关闭
sed -ri 's/.*swap.*/#&/' /etc/fstab
grep ".*swap.*" /etc/fstabdocker环境准备
所有集群节点安装,不包括负载均衡节点
1.安装docker
bash
安装yum-utils创建docker存储库(阿里)
yum install -y yum-utils && yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
安装指定版本并设置启动及开机自启动
yum -y install docker-ce-20.10.9-3.el72.配置Cgroup驱动程序
bash
在/etc/docker/daemon.json添加如下内容
cat > /etc/docker/daemon.json <<EOF
{
"exec-opts": ["native.cgroupdriver=systemd"]
}
EOFHAProxy及keepalived部署
此处的haproxy为api server提供反向代理,集群的管理请求通过VIP进行接收,haproxy将所有管理请求轮询转发到每个master节点上。
Keepalived为haproxy提供vip(192.168.0.100)在二个haproxy实例之间提供主备,降低当其中一个haproxy失效时对服务的影响。
以下操作只需要在ha1和ha2上配置
1.下载软件
bash
yum -y install haproxy keepalived2.修改haproxy配置文件
该配置文件,在ha1和ha2都要修改
bash
[root@k8s-ha1 /opt]#vim /etc/haproxy/haproxy.cfg
#---------------------------------------------------------------------
# Global settings
#---------------------------------------------------------------------
global #全局配置
maxconn 2000 #单个进程最大并发连接数
ulimit-n 16384 #每个进程可以打开的文件数量
log 127.0.0.1 local0 err #日志输出配置,所有日志都记录在本机系统日志,通过 local0 输出
stats timeout 30s #连接socket超时时间
defaults
log global #定义日志为global(全局)
mode http #使用的连接协议
option httplog #日志记录选项,httplog表示记录与HTTP会话相关的日志
timeout connect 5000 #定义haproxy将客户端请求转发至后端服务器所等待的超时时长
timeout client 50000 #客户端非活动状态的超时时长
timeout server 50000 #客户端与服务器端建立连接后,等待服务器端的超时时长
timeout http-request 15s #客户端建立连接但不请求数据时,关闭客户端连接超时时间
timeout http-keep-alive 15s # session 会话保持超时时间
frontend monitor-in #监控haproxy服务本身
bind *:33305 #监听的端口
mode http #使用的连接协议
option httplog #日志记录选项,httplog表示记录与HTTP会话相关的日志
monitor-uri /monitor #监控URL路径
frontend k8s-master #接收请求的前端名称,名称自定义,类似于Nginx的一个虚拟主机server。
bind 0.0.0.0:6443 #监听客户端请求的 IP地址和端口(以包含虚拟IP)
bind 127.0.0.1:6443
mode tcp #使用的连接协议
option tcplog #日志记录选项,tcplog表示记录与tcp会话相关的日志
tcp-request inspect-delay 5s #等待数据传输的最大超时时间
default_backend k8s-master #将监听到的客户端请求转发到指定的后端
backend k8s-master #后端服务器组,要与前端中设置的后端名称一致
mode tcp #使用的连接协议
option tcplog #日志记录选项,tcplog表示记录与tcp会话相关的日志
option tcp-check #tcp健康检查
balance roundrobin #负载均衡方式为轮询
default-server inter 10s downinter 5s rise 2 fall 2 slowstart 60s maxconn 250 maxqueue 256 weight 100
server master01 10.0.0.110:6443 check # 根据自己环境修改后端实例IP
server master02 10.0.0.111:6443 check # 根据自己环境修改后端实例IP
server master03 10.0.0.112:6443 check # 根据自己环境修改后端实例IP3.启动haproxy
ha1和ha2启动haproxy
bash
systemctl start haproxy
systemctl enable haproxy
systemctl status haproxy4.修改keepalived配置文件
1)修改ha1节点的keepalived配置文件
bash
[root@k8s-ha1 /opt]#cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
# 全局配置
global_defs {
router_id k8s-ha1 #标识身份
script_user root #指定脚本执行用户
enable_script_security
}
#定义一个自定义脚本,名称为chk_apiserver
vrrp_script chk_apiserver {
#脚本所在的路径及名称
script "/etc/keepalived/check_apiserver.sh"
#检查的时间间隔
interval 5
#检查失败时,当前节点的优先级减少 5
weight -5
#健康检查连续失败两次,则标记为不监控
fall 2
#健康检查成功一次,标记为健康
rise 1
}
#配置了一个名为VI_1的VRRP实例组
vrrp_instance VI_1 {
#该节点在VRRP组中的身份,Master节点负责处理请求并拥有虚拟IP地址
state MASTER
#实例绑定的网络接口,实例通过这个网络接口与其他VRRP节点通信,以及虚拟IP地址的绑定
interface eth0
#虚拟的路由ID,范围1到255之间的整数,用于在一个网络中区分不同的VRRP实例组,但是在同一个VRRP组中的节点,该ID要保持一致
virtual_router_id 51
#实例的优先级,范围1到254之间的整数,用于决定在同一个VRRP组中哪个节点将成为Master节点,数字越大优先级越>高
priority 101
#Master节点广播VRRP报文的时间间隔,用于通知其他Backup节点Master节点的存在和状态,在同一个VRRP组中,所有>节点的advert_int参数值必须相同
advert_int 2
#实例之间通信的身份验证机制
authentication {
#PASS为密码验证
auth_type PASS
#此密码必须为1到8个字符,在同一个VRRP组中,所有节点必须使用相同的密码,以确保正确的身份验证和通信
auth_pass abc123
}
#定义虚拟ip地址
virtual_ipaddress {
10.0.0.3/24
}
#引用自定义脚本,名称与上方vrrp_script中定义的名称保持一致
track_script {
chk_apiserver
}
}2)修改ha2节点的keepalived配置文件
bash
[root@k8s-ha2 /opt]#cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
# 全局配置
global_defs {
router_id k8s-ha2 #标识身份
script_user root #指定脚本执行用户
enable_script_security
}
#定义一个自定义脚本,名称为chk_apiserver
vrrp_script chk_apiserver {
#脚本所在的路径及名称
script "/etc/keepalived/check_apiserver.sh"
#检查的时间间隔
interval 5
#检查失败时,当前节点的优先级减少 5
weight -5
#健康检查连续失败两次,则标记为不监控
fall 2
#健康检查成功一次,标记为健康
rise 1
}
#配置了一个名为VI_1的VRRP实例组
vrrp_instance VI_1 {
#该节点在VRRP组中的身份,Master节点负责处理请求并拥有虚拟IP地址
state BACKUP #需要修改节点身份
#实例绑定的网络接口,实例通过这个网络接口与其他VRRP节点通信,以及虚拟IP地址的绑定
interface eth0
#虚拟的路由ID,范围1到255之间的整数,用于在一个网络中区分不同的VRRP实例组,但是在同一个VRRP组中的节点,该ID要保持一致
virtual_router_id 51
#实例的优先级,范围1到254之间的整数,用于决定在同一个VRRP组中哪个节点将成为Master节点,数字越大优先级越>高
priority 99 #需要修改优先级
#Master节点广播VRRP报文的时间间隔,用于通知其他Backup节点Master节点的存在和状态,在同一个VRRP组中,所有节点的advert_int参数值必须相同
advert_int 2
#实例之间通信的身份验证机制
authentication {
#PASS为密码验证
auth_type PASS
#此密码必须为1到8个字符,在同一个VRRP组中,所有节点必须使用相同的密码,以确保正确的身份验证和通信
auth_pass abc123
}
#定义虚拟ip地址
virtual_ipaddress {
10.0.0.3/24
}
#引用自定义脚本,名称与上方vrrp_script中定义的名称保持一致
track_script {
chk_apiserver
}
}3)编写检测haproxy脚本(ha1和ha2都需要)
bash
[root@k8s-ha1 /opt]#cat /etc/keepalived/check_apiserver.sh
#!/bin/bash
err=0
for k in $(seq 3)
do
check_code=$(pgrep haproxy) #过滤haproxy进程
if [[ $check_code == "" ]]; then
let err++
sleep 1
continue
else
err=0
break
fi
done
if [[ $err -ne 0 ]]; then
echo "systemctl stop keepalived"
/usr/bin/systemctl stop keepalived
exit 1
else
exit 0
fi
#脚本添加执行权限
chmod +x /etc/keepalived/check_apiserver.sh
#两个节点启动keepalived
systemctl start keepalived
systemctl enable keepalived
systemctl status keepalived4)查看集群VIP地址
bash
[root@k8s-ha1 /opt]#ip a s eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:99:ca:56 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.115/24 brd 10.0.0.255 scope global eth0
valid_lft forever preferred_lft forever
inet 10.0.0.3/24 scope global secondary eth0
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe99:ca56/64 scope link
valid_lft forever preferred_lft foreverk8s集群部署
集群所有节点都安装,不包括负载均衡节点
1.配置yum源
bash
cat > /etc/yum.repos.d/k8s.repo <<EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF2.集群软件安装
bash
yum install -y kubeadm-1.23.0-0 kubelet-1.23.0-0 kubectl-1.23.0-03.配置kubelet
bash
#启用Cgroup控制组
cat > /etc/sysconfig/kubelet <<EOF
KUBELET_EXTRA_ARGS="--cgroup-driver=systemd"
EOF
#设置kubelet开机自启
systemctl enable kubelet4.集群初始化
bash
#创建初始化配置文件
[root@master01 /opt]#kubeadm config print init-defaults > kubeadm-config.yaml
#修改配置文件
[root@master01 /opt]#cat kubeadm-config.yaml
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 10.0.0.110 #master01的ip地址
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
imagePullPolicy: IfNotPresent
name: master01 #master01主机名
taints: null
---
apiServer:
certSANs:
- 10.0.0.3 #在证书中指定的可信IP地址,负载均衡的VIP
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controlPlaneEndpoint: 10.0.0.3:6443 #负载均衡器的IP,主要让Kubernetes知道生成主节点令牌
controllerManager: {}
dns: {}
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers #集群组件镜像仓库地址
kind: ClusterConfiguration
kubernetesVersion: 1.23.0
networking:
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12
scheduler: {}
#初始化集群
[root@master01 ~]# kubeadm init --config /root/kubeadm-config.yaml --upload-certs
#选项说明:
--upload-certs //初始化过程将生成证书,并将其上传到etcd存储中,否则节点无法加入集群初始化成功后,按照要求执行命令
bash
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
export KUBECONFIG=/etc/kubernetes/admin.conf5.master节点加入集群
bash
根据提示,复制命令,在其他master节点执行
You can now join any number of the control-plane node running the following command on each as root:
kubeadm join 10.0.0.3:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:1a7e5ec095055b7e0b309c09042d1188fda43f61500531a7a2485084c9e04a9f \
--control-plane --certificate-key 72b4164c77fc7f64a104965165caa7dfaddf5d52d983079d0725d452b0f1f9f8
#master02节点(master03节点类似)
[root@master02 /opt]#kubeadm join 10.0.0.3:6443 --token abcdef.0123456789abcdef \
> --discovery-token-ca-cert-hash sha256:1a7e5ec095055b7e0b309c09042d1188fda43f61500531a7a2485084c9e04a9f \
> --control-plane --certificate-key 72b4164c77fc7f64a104965165caa7dfaddf5d52d983079d0725d452b0f1f9f8
#执行完成后,也需要根据提示执行以下命令
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config6.worker节点加入集群
bash
#根据提示复制,在工作节点执行
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 10.0.0.3:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:1a7e5ec095055b7e0b309c09042d1188fda43f61500531a7a2485084c9e04a9f
#worker01节点(worker02节点类似)
[root@worker01 /opt]#kubeadm join 10.0.0.3:6443 --token abcdef.0123456789abcdef \
> --discovery-token-ca-cert-hash sha256:1a7e5ec095055b7e0b309c09042d1188fda43f61500531a7a2485084c9e04a9f
#查看集群节点
[root@master01 /opt]#kubectl get nodes
NAME STATUS ROLES AGE VERSION
master01 NotReady control-plane,master 12m v1.23.0
master02 NotReady control-plane,master 5m48s v1.23.0
master03 NotReady control-plane,master 5m2s v1.23.0
worker01 NotReady <none> 23s v1.23.0
worker02 NotReady <none> 20s v1.23.0部署calico网络
在master01节点安装calico即可
bash
#下载calico文件
[root@master01 /opt]#wget https://raw.githubusercontent.com/projectcalico/calico/v3.24.1/manifests/calico.yaml
#创建calico网络
[root@master01 /opt]#kubectl apply -f calico.yaml
#查看calico的pod状态是否为Running
[root@master01 /opt]#kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-66966888c4-5wlvp 1/1 Running 0 5m48s
calico-node-k7f9f 1/1 Running 0 5m48s
calico-node-kt5p8 1/1 Running 0 5m48s
calico-node-m59qh 1/1 Running 0 5m48s
calico-node-mm6ph 1/1 Running 0 5m48s
calico-node-vrkdr 1/1 Running 0 5m48s
#验证集群可用性
[root@master01 /opt]#kubectl get nodes
NAME STATUS ROLES AGE VERSION
master01 Ready control-plane,master 21m v1.23.0
master02 Ready control-plane,master 15m v1.23.0
master03 Ready control-plane,master 14m v1.23.0
worker01 Ready <none> 9m55s v1.23.0
worker02 Ready <none> 9m52s v1.23.0部署Nginx测试
bash
#部署nginx程序
[root@master01 /opt]#kubectl create deployment nginx --image=nginx:latest
#查看pod
[root@master01 /opt]#kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-7c658794b9-r76f2 1/1 Running 0 40s
#暴露pod端口
[root@master01 /opt]#kubectl expose deployment nginx --port=80 --type=NodePort
service/nginx exposed
#查看service
[root@master01 /opt]#kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 32m
nginx NodePort 10.105.141.241 <none> 80:31729/TCP 26s浏览器访问测试:http://集群任意节点:31729/
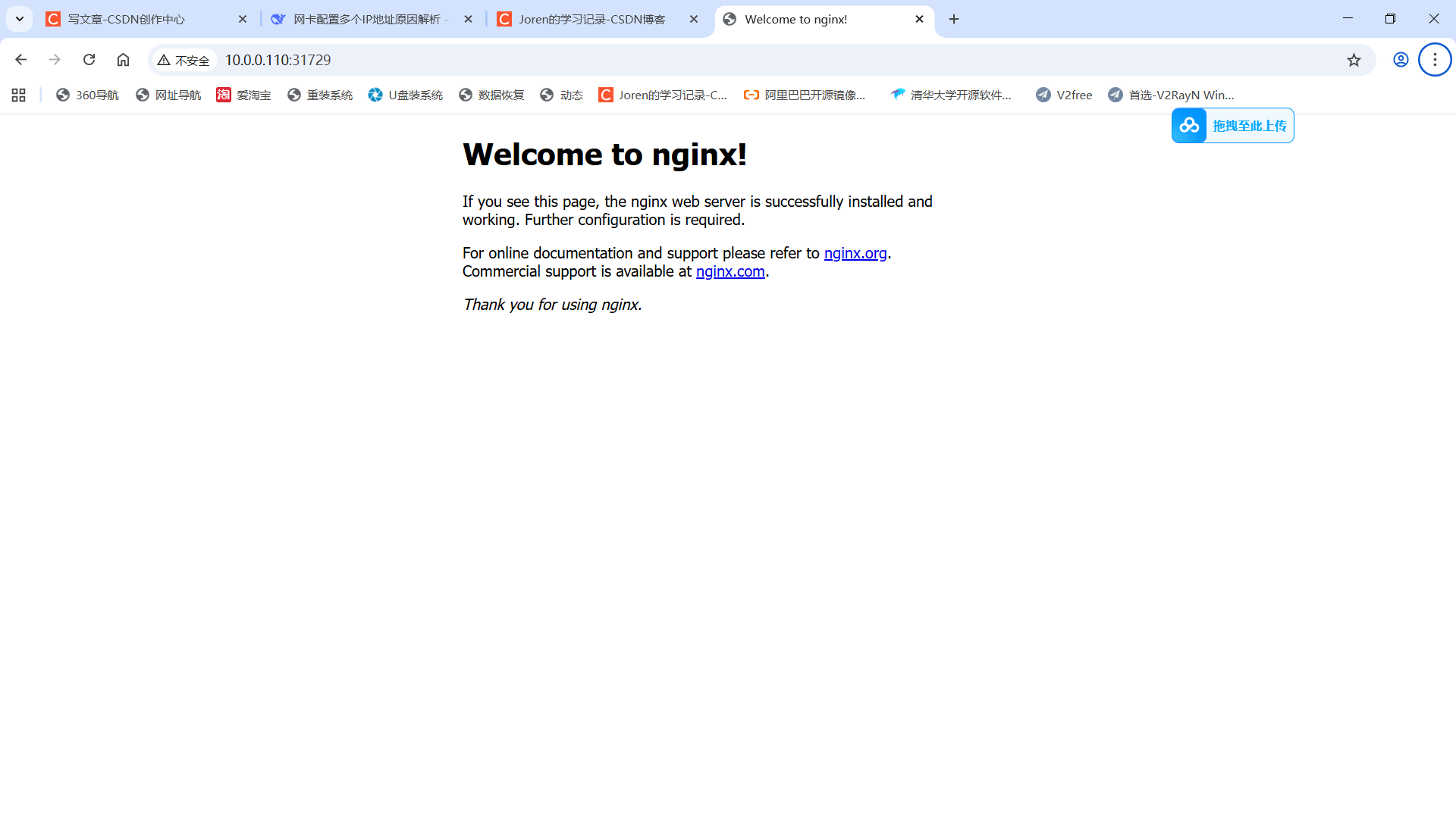
这个时候的三台master节点,可以down掉任何一台,但是不能down两台