概览
在前面的章节中,我们探讨了用于顺序工作流的提示链(Prompt Chaining)以及用于动态决策和不同路径间转换的路由(Routing)。虽然这些模式至关重要,但许多复杂的智能体任务包含多个子任务,这些子任务可以同时执行,而不是按顺序一个接一个地进行。这正是并行化模式发挥关键作用的地方。
并行化涉及并发执行多个组件,例如 LLM 调用、工具使用,甚至整个子智能体(见图 1)。与其等待一个步骤完成再开始下一个步骤,并行执行允许相互独立的任务同时运行,从而显著减少可以拆分为独立部分的任务的总体执行时间。
考虑一个旨在研究某个主题并总结其发现的智能体。一个顺序式的方法可能会:
- 搜索来源 A。
- 总结来源 A。
- 搜索来源 B。
- 总结来源 B。
- 从摘要 A 和摘要 B 综合出最终答案
一种并行的方法可以是:
- 同时搜索来源 A 和来源 B。
- 一旦两项搜索都完成,同时对来源 A 进行总结并对来源 B 进行总结。
- 从总结 A 和总结 B 综合出最终答案(这一步通常是顺序执行,需等待并行步骤完成)。
核心思想是识别工作流程中不依赖其他部分输出的部分,并将它们并行执行。这在处理具有延迟的外部服务(例如 API 或数据库)时特别有效,因为你可以同时发出多个请求。
实现并行化通常需要支持异步执行或多线程/多进程的框架。现代的智能体框架在设计时就考虑了异步操作,使你能够轻松定义可以并行运行的步骤。
图 1. 使用子代理进行并行化的示例 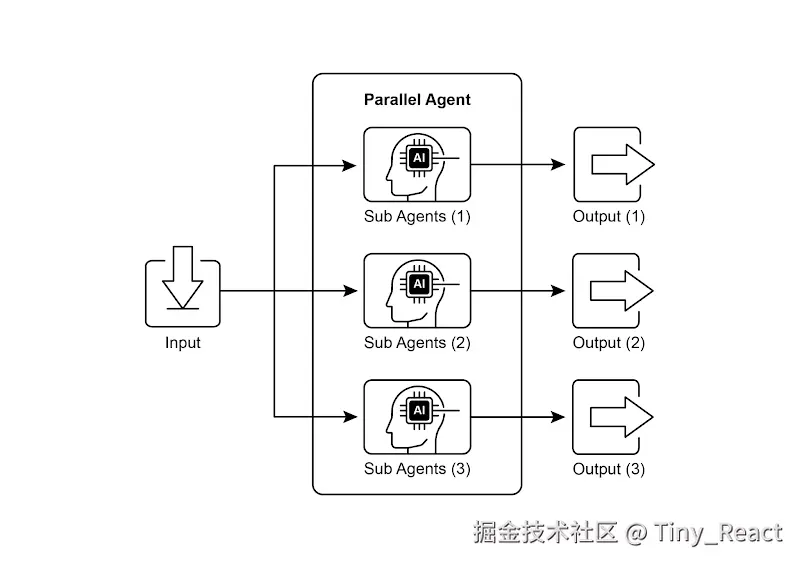
像 LangChain、LangGraph 和 Google ADK 这样的框架都提供了并行执行的机制。在 LangChain Expression Language(LCEL)中,你可以通过使用诸如 |(用于顺序执行)等运算符组合 runnable 对象,并通过将链或图结构化为可并发执行的分支来实现并行执行。LangGraph 通过其图结构,允许你从单个状态转换中定义多个可执行的节点,从而在工作流中有效地启用并行分支。Google ADK 提供了强大、原生的机制来促进和管理智能体的并行执行,大幅提升复杂多智能体系统的效率与可扩展性。ADK 框架这一内在能力使开发者能够设计和实现多智能体并发运行而非顺序运行的解决方案。
并行化模式对于提升智能体系统的效率和响应性至关重要,尤其在处理涉及多个相互独立的查询、计算或与外部服务交互的任务时更是如此。它是优化复杂智能体工作流性能的关键技术。
实际应用与使用场景
并行化是一种在各类应用中优化智能体性能的强大模式:
1. 信息收集与研究
同时从多个来源收集信息是一个经典用例。
- 用例: 一个正在研究一家公司的代理。
- 并行任务: 同时搜索新闻文章、获取股票数据、检查社交媒体提及,并查询公司数据库。
- 好处: 比按顺序查询更快地获得全面视图。
2. 数据处理与分析
并行应用不同的分析技术,或同时处理不同的数据片段。
- 用例: 一个用于分析客户反馈的代理。
- 并行任务: 在一批反馈条目上同时运行情感分析、提取关键词、分类反馈,并识别紧急问题。
- 好处: 能快速提供多角度的分析。
3. 多 API 或工具交互
调用多个独立的 API 或工具来收集不同类型的信息或执行不同的操作。
- 用例: 旅行规划智能体。
- 并行任务: 同时检查机票价格、搜索酒店空房、查询本地活动,并寻找餐厅推荐。
- 好处: 更快地呈现完整的旅行计划。
4. 由多个组件进行内容生成
并行生成复杂内容的不同部分。
- 用例: 一个正在写市场营销邮件的智能体。
- 并行任务: 同时生成邮件主题、撰写邮件正文、寻找相关图片,并创建号召性用语按钮文本。
- 好处: 更高效地组装最终邮件。
5. 验证与核实
同时执行多个独立的检查或验证。
- 用例: 一个正在验证用户输入的智能体。
- 并行任务: 同时检查电子邮件格式、验证电话号码、将地址与数据库进行比对,并检查是否包含不当用语。
- 好处: 可更快速地反馈输入的有效性。
6. 多模态处理
并行处理同一输入的不同模态(文本、图像、音频)。
- 用例: 一个同时分析包含文本和图像的社交媒体帖子的智能体。
- 并行任务: 同时对文本进行情感与关键词分析,并对图像进行物体识别与场景描述分析。
- 好处: 更快速地整合来自不同模态的洞见。
7. A/B 测试或多选项生成
并行生成多个响应或输出的变体,以选择最佳方案。
- 用例: 一个生成不同的创意文本选项的智能体。
- 并行任务: 使用略有不同的提示词或模型,同时为一篇文章生成三个不同的标题。
- 好处: 可快速比较并选择最佳选项。
并行化是代理式设计中的一种基础优化技术,它通过为相互独立的任务启用并发执行,帮助开发者构建性能更高、响应更及时的应用。
实战代码示例(LangChain)
在 LangChain 框架中,并行执行由 LangChain 表达式语言(LCEL)提供支持。主要方法是将多个可运行组件构造成字典或列表。当这组集合作为输入传递给链中后续的组件时,LCEL 运行时会并发执行其中的可运行单元。
在 LangGraph 的语境下,这一原则被应用于图的拓扑结构。通过对图进行架构设计,使多个不存在直接顺序依赖的节点可以从同一个公共节点启动,从而定义并行工作流。这些并行路径独立执行,其结果会在图中后续的汇合点进行聚合。
以下实现展示了一个使用 LangChain 框架构建的并行处理工作流。该工作流旨在针对单个用户请求同时执行两个相互独立的操作。这些并行过程被实例化为独立的链或函数,其各自的输出随后被汇总为一个统一的结果。
该实现的前提条件包括安装必要的 Python 包,如 langchain、langchain-community,以及一个模型提供方库(例如 langchain-openai)。此外,还需在本地环境中配置所选语言模型的有效 API 密钥以进行身份验证。
python
import os
import asyncio
from typing import Optional
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import Runnable, RunnableParallel, RunnablePassthrough
# --- Configuration ---
# Ensure your API key environment variable is set (e.g., OPENAI_API_KEY)
try:
llm: Optional[ChatOpenAI] = ChatOpenAI(model="gpt-4o-mini", temperature=0.7)
except Exception as e:
print(f"Error initializing language model: {e}")
llm = None
# --- Define Independent Chains ---
# These three chains represent distinct tasks that can be executed in parallel.
summarize_chain: Runnable = (
ChatPromptTemplate.from_messages([
("system", "Summarize the following topic concisely:"),
("user", "{topic}")
])
| llm
| StrOutputParser()
)
questions_chain: Runnable = (
ChatPromptTemplate.from_messages([
("system", "Generate three interesting questions about the following topic:"),
("user", "{topic}")
])
| llm
| StrOutputParser()
)
terms_chain: Runnable = (
ChatPromptTemplate.from_messages([
("system", "Identify 5-10 key terms from the following topic, separated by commas:"),
("user", "{topic}")
])
| llm
| StrOutputParser()
)
# --- Build the Parallel + Synthesis Chain ---
# 1. Define the block of tasks to run in parallel. The results of these,
# along with the original topic, will be fed into the next step.
map_chain = RunnableParallel(
{
"summary": summarize_chain,
"questions": questions_chain,
"key_terms": terms_chain,
"topic": RunnablePassthrough(), # Pass the original topic through
}
)
# 2. Define the final synthesis prompt which will combine the parallel results.
synthesis_prompt = ChatPromptTemplate.from_messages([
("system", """Based on the following information:
Summary: {summary}
Related Questions: {questions}
Key Terms: {key_terms}
Synthesize a comprehensive answer."""),
("user", "Original topic: {topic}")
])
# 3. Construct the full chain by piping the parallel results directly
# into the synthesis prompt, followed by the LLM and output parser.
full_parallel_chain = map_chain | synthesis_prompt | llm | StrOutputParser()
# --- Run the Chain ---
async def run_parallel_example(topic: str) -> None:
"""
Asynchronously invokes the parallel processing chain with a specific topic
and prints the synthesized result.
Args:
topic: The input topic to be processed by the LangChain chains.
"""
if not llm:
print("LLM not initialized. Cannot run example.")
return
print(f"\n--- Running Parallel LangChain Example for Topic: '{topic}' ---")
try:
# The input to `ainvoke` is the single 'topic' string,
# then passed to each runnable in the `map_chain`.
response = await full_parallel_chain.ainvoke(topic)
print("\n--- Final Response ---")
print(response)
except Exception as e:
print(f"\nAn error occurred during chain execution: {e}")
if __name__ == "__main__":
test_topic = "The history of space exploration"
# In Python 3.7+, asyncio.run is the standard way to run an async function.
asyncio.run(run_parallel_example(test_topic))所提供的 Python 代码实现了一个 LangChain 应用,通过并行执行高效处理给定主题。请注意,asyncio 提供的是并发而非并行。它通过在单线程上使用事件循环来实现:当某个任务处于空闲状态(例如等待网络请求)时,事件循环会智能地在任务之间切换。这会产生多个任务同时推进的效果,但代码本身仍然只由一个线程执行,并受到 Python 全局解释器锁(GIL)的限制。
代码首先从 langchain_openai 和 langchain_core 导入必要的模块,包括用于语言模型、提示、输出解析和可运行结构的组件。代码尝试初始化一个 ChatOpenAI 实例,具体使用 "gpt-4o-mini" 模型,并设置 temperature 以控制创造性。在语言模型初始化过程中使用了 try-except 块以提高健壮性。随后定义了三个独立的 LangChain "chain",每个都针对输入主题执行不同的任务。第一个 chain 用于简明扼要地总结主题,使用系统消息和包含主题占位符的用户消息。第二个 chain 用于生成三个与该主题相关的有趣问题。第三个 chain 用于从输入主题中识别 5 到 10 个关键术语,并要求以逗号分隔。每个独立的 chain 都由一个针对其特定任务定制的 ChatPromptTemplate、已初始化的语言模型,以及一个将输出格式化为字符串的 StrOutputParser 组成。
随后构建了一个 RunnableParallel 模块,将这三个链打包在一起,使它们能够同时执行。这个并行 runnable 还包含一个 RunnablePassthrough,以确保原始输入的主题可用于后续步骤。为最终综合步骤定义了一个单独的 ChatPromptTemplate,它将摘要、问题、关键术语以及原始主题作为输入,以生成一份全面的答案。完整的端到端处理链被命名为 full_parallel_chain,通过将 map_chain(并行模块)串联到综合提示中,然后接入语言模型和输出解析器来创建。提供了一个异步函数 run_parallel_example,用于演示如何调用这个 full_parallel_chain。该函数以主题作为输入,并使用 invoke 来运行异步链。最后,标准的 Python if name == "main": 代码块展示了如何使用示例主题(在本例中为 "The history of space exploration")来执行 run_parallel_example,并通过 asyncio.run 来管理异步执行。
本质上,这段代码为某个主题建立了一个工作流:多个 LLM 调用(用于摘要、问题和术语)同时进行,随后再由最后一次 LLM 调用将它们的结果合并。这展示了在使用 LangChain 的智能体工作流中并行化的核心理念。
实战代码示例(Google ADK)
好的,现在让我们把注意力转向一个在 Google ADK 框架内阐释这些概念的具体示例。我们将考察如何应用 ADK 的原语(例如 ParallelAgent 和 SequentialAgent)来构建一个利用并发执行以提升效率的智能体流程。
python
from google.adk.agents import LlmAgent, ParallelAgent, SequentialAgent
from google.adk.tools import google_search
GEMINI_MODEL="gemini-2.0-flash"
# --- 1. Define Researcher Sub-Agents (to run in parallel) ---
# Researcher 1: Renewable Energy
researcher_agent_1 = LlmAgent(
name="RenewableEnergyResearcher",
model=GEMINI_MODEL,
instruction="""You are an AI Research Assistant specializing in energy.
Research the latest advancements in 'renewable energy sources'.
Use the Google Search tool provided.
Summarize your key findings concisely (1-2 sentences).
Output *only* the summary.
""",
description="Researches renewable energy sources.",
tools=[google_search],
# Store result in state for the merger agent
output_key="renewable_energy_result"
)
# Researcher 2: Electric Vehicles
researcher_agent_2 = LlmAgent(
name="EVResearcher",
model=GEMINI_MODEL,
instruction="""You are an AI Research Assistant specializing in transportation.
Research the latest developments in 'electric vehicle technology'.
Use the Google Search tool provided.
Summarize your key findings concisely (1-2 sentences).
Output *only* the summary.
""",
description="Researches electric vehicle technology.",
tools=[google_search],
# Store result in state for the merger agent
output_key="ev_technology_result"
)
# Researcher 3: Carbon Capture
researcher_agent_3 = LlmAgent(
name="CarbonCaptureResearcher",
model=GEMINI_MODEL,
instruction="""You are an AI Research Assistant specializing in climate solutions.
Research the current state of 'carbon capture methods'.
Use the Google Search tool provided.
Summarize your key findings concisely (1-2 sentences).
Output *only* the summary.
""",
description="Researches carbon capture methods.",
tools=[google_search],
# Store result in state for the merger agent
output_key="carbon_capture_result"
)
# --- 2. Create the ParallelAgent (Runs researchers concurrently) ---
# This agent orchestrates the concurrent execution of the researchers.
# It finishes once all researchers have completed and stored their results in state.
parallel_research_agent = ParallelAgent(
name="ParallelWebResearchAgent",
sub_agents=[researcher_agent_1, researcher_agent_2, researcher_agent_3],
description="Runs multiple research agents in parallel to gather information."
)
# --- 3. Define the Merger Agent (Runs *after* the parallel agents) ---
# This agent takes the results stored in the session state by the parallel agents
# and synthesizes them into a single, structured response with attributions.
merger_agent = LlmAgent(
name="SynthesisAgent",
model=GEMINI_MODEL, # Or potentially a more powerful model if needed for synthesis
instruction="""You are an AI Assistant responsible for combining research findings into a structured report.
Your primary task is to synthesize the following research summaries, clearly attributing findings to their source areas. Structure your response using headings for each topic. Ensure the report is coherent and integrates the key points smoothly.
**Crucially: Your entire response MUST be grounded *exclusively* on the information provided in the 'Input Summaries' below. Do NOT add any external knowledge, facts, or details not present in these specific summaries.**
**Input Summaries:**
* **Renewable Energy:**
{renewable_energy_result}
* **Electric Vehicles:**
{ev_technology_result}
* **Carbon Capture:**
{carbon_capture_result}
**Output Format:**
## Summary of Recent Sustainable Technology Advancements
### Renewable Energy Findings
(Based on RenewableEnergyResearcher's findings)
[Synthesize and elaborate *only* on the renewable energy input summary provided above.]
### Electric Vehicle Findings
(Based on EVResearcher's findings)
[Synthesize and elaborate *only* on the EV input summary provided above.]
### Carbon Capture Findings
(Based on CarbonCaptureResearcher's findings)
[Synthesize and elaborate *only* on the carbon capture input summary provided above.]
### Overall Conclusion
[Provide a brief (1-2 sentence) concluding statement that connects *only* the findings presented above.]
Output *only* the structured report following this format. Do not include introductory or concluding phrases outside this structure, and strictly adhere to using only the provided input summary content.
""",
description="Combines research findings from parallel agents into a structured, cited report, strictly grounded on provided inputs.",
# No tools needed for merging
# No output_key needed here, as its direct response is the final output of the sequence
)
# --- 4. Create the SequentialAgent (Orchestrates the overall flow) ---
# This is the main agent that will be run. It first executes the ParallelAgent
# to populate the state, and then executes the MergerAgent to produce the final output.
sequential_pipeline_agent = SequentialAgent(
name="ResearchAndSynthesisPipeline",
# Run parallel research first, then merge
sub_agents=[parallel_research_agent, merger_agent],
description="Coordinates parallel research and synthesizes the results."
)
root_agent = sequential_pipeline_agent这段代码定义了一个用于研究并综合可持续技术进展信息的多智能体系统。它设置了三个 LlmAgent 实例,作为具备专长的研究员。ResearcherAgent_1 专注于可再生能源,ResearcherAgent_2 研究电动汽车技术,ResearcherAgent_3 调查碳捕集方法。每个研究员智能体都被配置为使用 GEMINI_MODEL 和 google_search 工具。他们被指示将研究发现简明扼要地总结(1-2 句),并使用 output_key 将这些摘要存储在会话状态中。
随后创建了一个名为 ParallelWebResearchAgent 的 ParallelAgent,用于并发运行这三个研究代理。这使得研究可以并行进行,从而可能节省时间。一旦其所有子代理(研究人员)完成并将结果填充到状态中,ParallelAgent 的执行即告完成。
接着,定义了一个用于综合研究结果的 MergerAgent(同样是 LlmAgent)。该代理将并行研究代理存储在会话状态中的摘要作为输入。其指令强调输出必须严格基于所提供的输入摘要,禁止添加外部知识。MergerAgent 被设计为将合并后的发现组织成一份报告,为每个主题设置标题,并给出简要的整体结论。
最终,创建一个名为 ResearchAndSynthesisPipeline 的顺序代理(SequentialAgent)来协调整个工作流程。作为主要控制器,这个主代理首先执行 ParallelAgent 进行研究。ParallelAgent 完成后,SequentialAgent 再执行 MergerAgent 来综合收集的信息。sequential_pipeline_agent 被设为 root_agent,代表运行这一多代理系统的入口点。整个过程旨在高效地并行从多个来源收集信息,然后将其整合成一个单一、结构化的报告。
回顾
是什么(What)
许多代理式工作流涉及多个子任务,必须完成这些子任务才能实现最终目标。纯粹的顺序执行(每个任务都等待前一个任务完成)往往低效且缓慢。当任务依赖外部 I/O 操作(例如调用不同的 API 或查询多个数据库)时,这种延迟会成为一个显著的瓶颈。如果没有并发执行机制,总处理时间将是所有单个任务时长的总和,从而阻碍系统的整体性能和响应能力。
为什么(Why)
并行化模式通过使相互独立的任务同时执行,提供了一种标准化的解决方案。其工作方式是识别工作流中彼此不依赖即时输出的组件,例如工具使用或 LLM 调用。像 LangChain 和 Google ADK 这样的 Agentic 框架提供了内置结构来定义和管理这些并发操作。例如,一个主进程可以调用多个并行运行的子任务,并在进入下一步之前等待它们全部完成。通过同时运行这些独立任务而不是依次执行,该模式可大幅缩短总执行时间。
经验法则(Rule of Thumb)
当工作流包含多个可同时运行的独立操作时使用该模式,例如从多个 API 获取数据、处理不同的数据块,或生成多段内容以供后续综合。
并行化设计模式 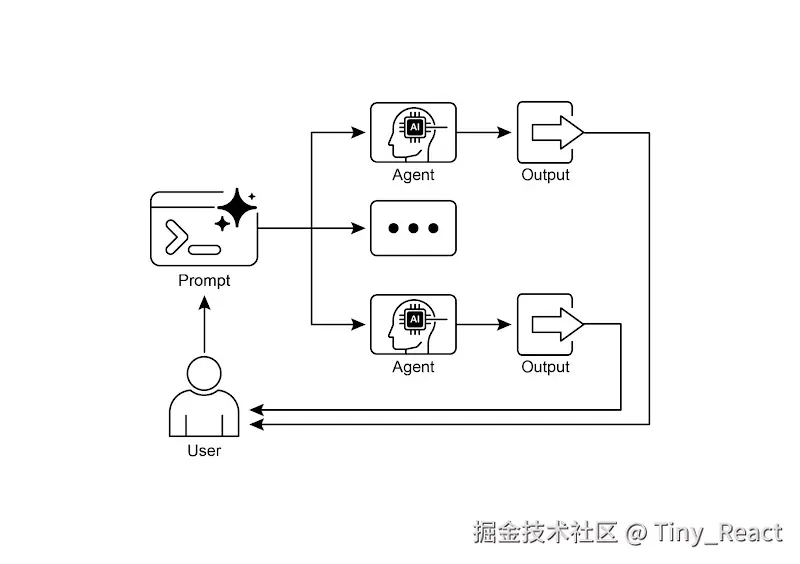
关键点
- 并行化是一种并发执行独立任务以提升效率的模式。
- 当任务需要等待外部资源(例如 API 调用)时,它尤其有用。
- 采用并发或并行架构会引入大量复杂性和成本,影响设计、调试和系统日志等关键开发阶段。
- 像 LangChain 和 Google ADK 这样的框架提供了用于定义和管理并行执行的内置支持。
- 在 LangChain 表达式语言(LCEL)中,RunnableParallel 是用于并行运行多个 runnable 的关键构造。
- Google ADK 可以通过 LLM-驱动的委派来促进并行执行,其中协调者代理的 LLM 识别独立的子任务,并触发由专业子代理对其进行并发处理。
- 并行化有助于降低整体延迟,使具备代理能力的系统在处理复杂任务时更为灵敏。
总结
并行化模式是一种通过并发执行相互独立的子任务来优化计算工作流的方法。这种方法可以降低整体延迟,尤其适用于涉及多个模型推理或对外部服务进行调用的复杂操作。
不同的框架为实现这一模式提供了各自的机制。在 LangChain 中,可以使用如 RunnableParallel 等构造来显式地定义并同时执行多条处理链。相比之下,像 Google Agent Developer Kit(ADK)这样的框架则可通过多智能体(multi-agent)分工实现并行化:由一个主要的协调模型将不同的子任务分配给可并发运行的专业化智能体。
通过将并行处理与顺序(链式)和条件(路由)控制流相结合,可以构建复杂且高性能的计算系统,从而高效管理多样且复杂的任务。
参考资料
- LangChain Expression Language (LCEL) Documentation (Parallelism): python.langchain.com/docs/concep...
- Google Agent Developer Kit (ADK) Documentation (Multi-Agent Systems): google.github.io/adk-docs/ag...
- Python asyncio Documentation: docs.python.org/3/library/a...