在你已经搭建好数据平台基础之后------无论是 Microsoft Fabric 还是 Azure Databricks------就可以开始构建 Bronze 层了。Bronze 层是所有原始数据(raw data)最先落地的地方,数据保持来源本来的形态;它既充当历史归档,也是一处可靠的单一来源(single source)。
在搭建这一层的过程中,你会完成一系列任务,例如建立连接、构建第一条数据流水线、以及探索如何处理数据摄取与模式(schema)管理。文中会穿插一些代码片段:有些用于讲解思路,有些可以直接在练习中使用。需要注意的是,这些示例为了教学目的做了简化,落地到生产时可能需要按实际情况做调整。
读完本章,你将全面理解如何构建与实现 Medallion 架构中的 Bronze 层,包括摄取与管理 Bronze 层数据的各种细节。这个扎实的基础会为后续的 Silver 与 Gold 阶段做好准备。下面从构建数据流水线开始。
构建数据流水线
本节我们将使用 Data Factory 构建一条数据流水线,并在过程中集成 Spark 与 Delta Lake。通过这次实操,你将掌握这些工具在真实场景中的衔接方式。
说明
使用 Azure Data Factory 时,你可能会发现少数配置对话与 Microsoft Fabric 中的 Data Factory 略有差异。如果你使用 Azure Databricks 并遇到不一致之处,请参考其初始配置步骤。
流程从部署 AdventureWorks 示例数据库这一前置条件开始------它将作为你的首个数据源。随后,你会通过 Data Factory 将该数据接入 Bronze 层,这将涉及配置连接信息、创建新流水线以及设置多种流水线活动。随着推进,你会看到详细指引,包含操作步骤、截图以及关键参数。该章节的中间成果如图 5-1 所示。
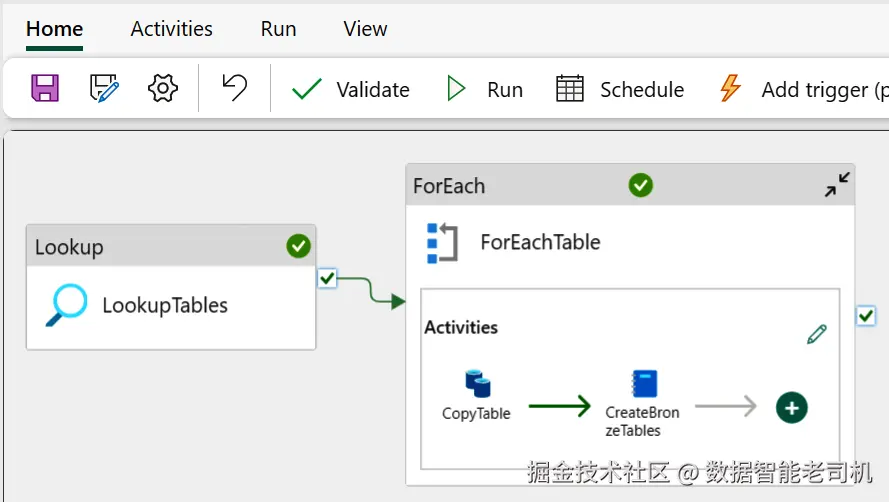
图 5-1. Data Factory 中流水线的概览
完成本节后,你将获得有关实现 Lakehouse 表的宝贵见解与建议。之后我们会继续讨论模式管理。
部署 AdventureWorks 示例数据库
本练习使用 AdventureWorks 示例数据库,展示如何把真实数据源接入你的新环境。AdventureWorks 广泛用于演示与培训,非常适合学习数据摄取、数据质量修复,以及构建数据集成作业。
AdventureWorks 示例包含在 Azure SQL 中------Azure SQL 是 Microsoft Azure 提供的云端关系型数据库服务。它常被用于构建云原生应用,具备高安全性、可伸缩性与高可用性。
要在 Azure SQL 中部署 AdventureWorks,请参考"快速入门:创建单一数据库(Quickstart: Create a Single Database) "与"AdventureWorks Sample Database"的指南。完成快速入门并部署成功后,你就可以开始用 Data Factory 构建第一条流水线。接下来的章节会先配置连接,然后使用 Data Factory 将数据加载到 Bronze 层并按"加载日期"分区;数据加载完成后,你会在同一条流水线中触发一个 Spark 作业来创建 Bronze 表。
配置 Azure SQL 数据库连接
要从 AdventureWorks 示例数据库读取数据并写入 Bronze 层,需要在 Data Factory 中设置必要的连接信息。这些配置定义了连接到目标源或目标端所需的属性与凭据。
在界面右上角点击 设置(Settings) 的齿轮图标,选择 Manage Connections and Gateways 。接着在功能区顶部点击 New 新增数据源。右侧会打开一个新连接的面板,你可以在此选择要创建的连接类型。
为了使用 AdventureWorks 示例数据库,你需要创建 SQL Server 类型的连接。更详细的引导可参见"Set up Your Azure SQL Database Connection "。此外,建议使用 服务主体(service principal) 进行身份验证------这是让 Data Factory 访问 Azure 服务最安全且最具可扩展性的方式。图 5-2 展示了概览界面。
注意
各类数据源往往伴随各自的特殊挑战,你可能需要采用与此处不同的设置与活动。关于这一点将在"配置 CopyTable 活动"部分进一步讨论。另外,本示例的命名约定沿用了 AdventureWorks 的表与字段命名,你可以按自己的数据源情况进行调整。
完成连接信息配置后,就可以在 Data Factory 中新建一个流水线。该数据流水线将成为后续步骤(包括 Lookup 、ForEach 、Copy Tables 与 Notebook 活动)的基础。
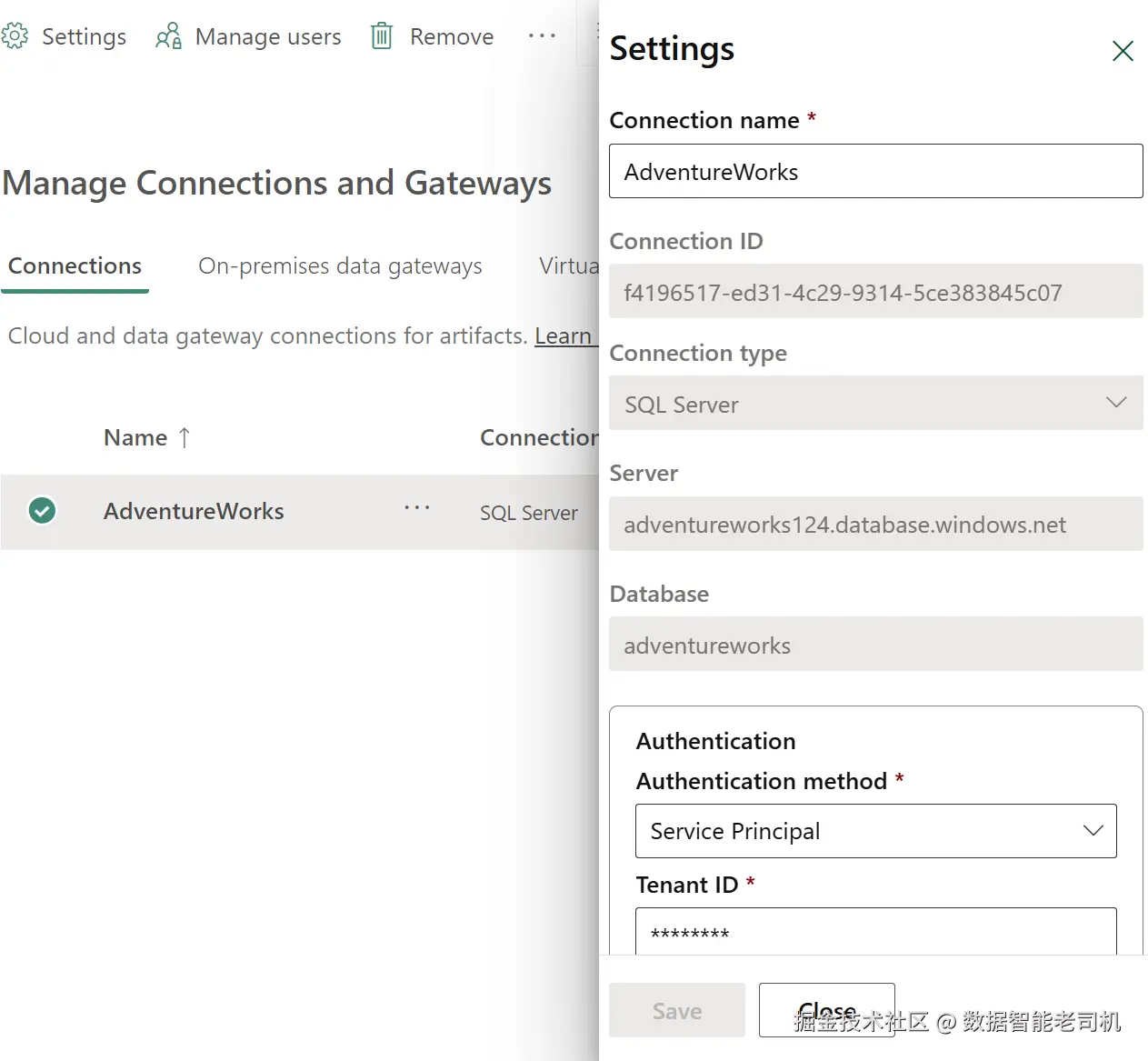
图 5-2. Data Factory 中连接信息的概览界面
创建新的数据管道
要创建新管道,先通过左侧导航返回到 Workspace(工作区) 并打开开发环境的工作区。点击 New Item ,选择 Data pipeline ,将新建的管道命名为例如 "AdventureWorks"。页面会刷新并显示一张空白画布,用来搭建管道。在这张画布上,你将把 Lookup 、ForEach 、CopyTable 和 Notebook 等活动加入到管道中。这些活动可在页面上方的 Activities 面板中找到。
先将 Lookup 活动拖入管道。Lookup 用于从 AdventureWorks 示例数据库中检索架构(schema)信息。随后会遍历数据库表清单,对每个表执行复制操作------也就是说,每张表都会被动态复制到 Bronze Lakehouse。
接着点击该活动进行配置:在设置中,选择之前创建的 AdventureWorks Connection 作为读取数据库信息的连接。然后转到 details 部分,在 "Use query" 行选择 Query 单选项以获取所有相关的表名。确保 First row only 不要勾选,以便返回表中的所有行。参见图 5-3 获取更多细节。
用于查询的 SQL 语句如下,它只从 INFORMATION_SCHEMA 视图中检索功能性表名。该视图提供与系统表无关的数据库元数据视图,能以更标准化的方式获取关于表、列、域、检查约束、权限等对象的信息。由于大多数现代数据库都支持系统表,这种方式常被用来查询元数据:
sql
SELECT * FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_TYPE = 'BASE TABLE' AND TABLE_SCHEMA = 'SalesLT'点击 Preview data 按钮验证是否正常工作。如果能按预期显示数据并看到表的概览,就可以继续添加 ForEach 活动来开发管道了。
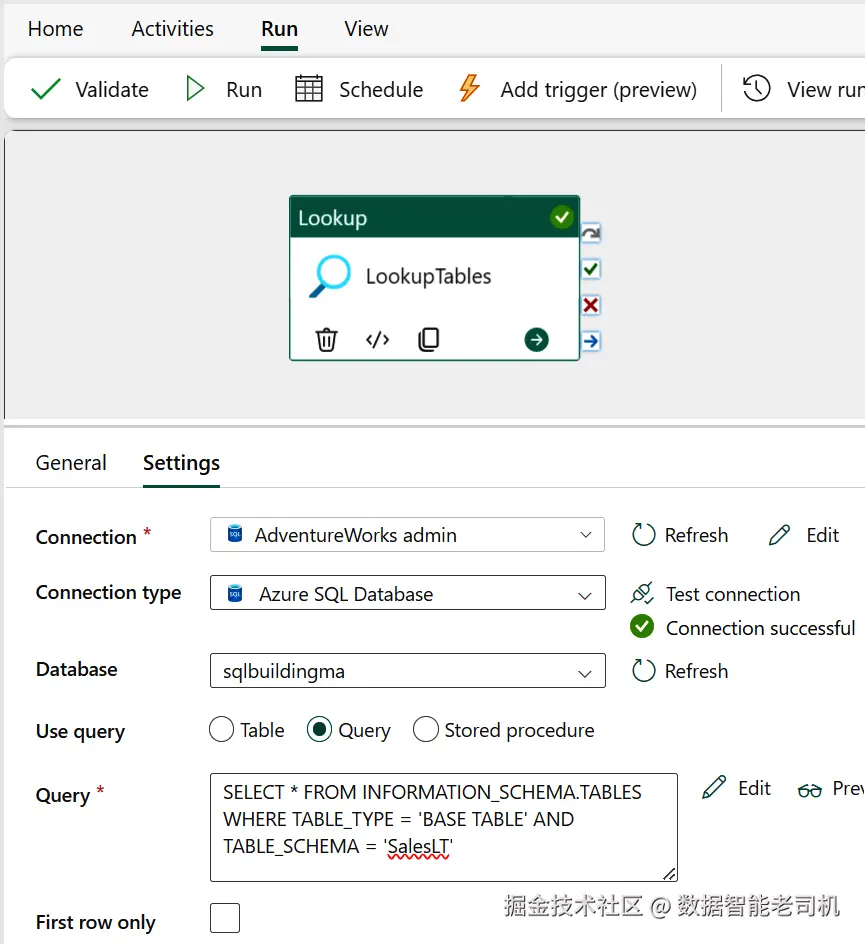
图 5-3. 仅检索相关架构信息所用的查询
构建 ForEach 循环
ForEach 是一种控制流活动,用于遍历一个集合并按特定顺序对集合中的每个项执行操作。它常用于数据工程项目,对一组文件或表执行一系列(重复性)操作。在本例中,ForEach 将遍历从 AdventureWorks 示例数据库返回的系统对象信息,并据此把这些表复制到 Bronze Lakehouse。
要遍历来自 AdventureWorks 的系统对象信息,请在 ForEach 活动的 Items 选项中添加以下内容:²
kotlin
@activity('LookupTables').output.value该配置使 ForEach 活动能够从 Lookup 的查询输出中提取架构名与表名,并将其作为循环内的参数使用。配置 ForEach 时,务必确保输入名称与上一个活动的名称完全一致。例如,如果参考图 5-4 的示例,则输入必须直接关联到名为 LookupTables 的作业。
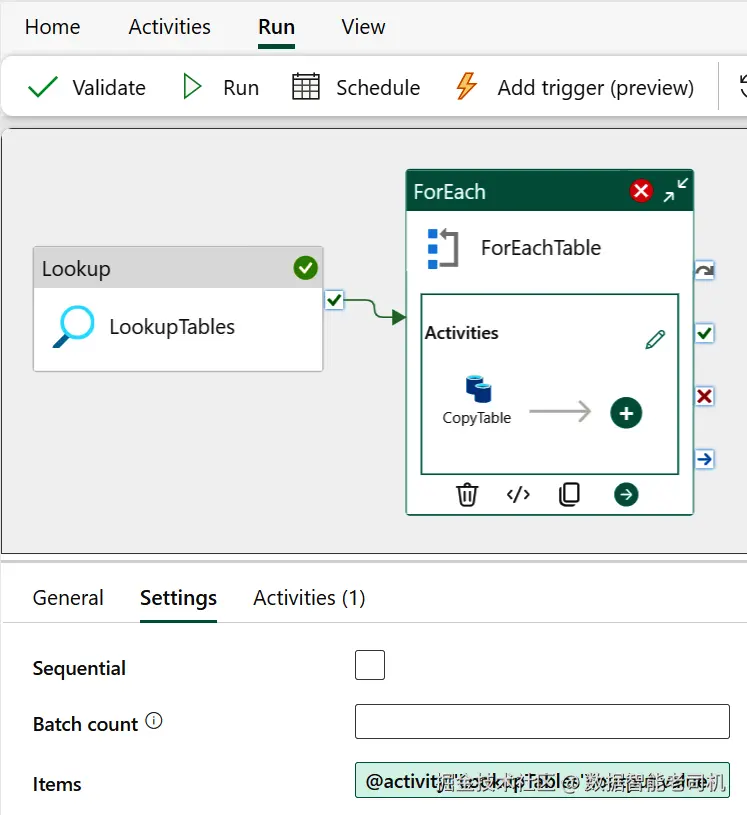
图 5-4. 使用 ForEach 活动遍历所有表
完成 ForEach 配置后,就可以集成 CopyTable 活动了。
配置 CopyTable 活动
打开 ForEach 循环,将 CopyTable 活动拖入其中。该活动用于在源与目标之间复制数据。在这里,它会把 AdventureWorks 示例数据库中的表复制到 Bronze Lakehouse。要配置 CopyTable ,需要填写 Source 与 Destination 属性(见图 5-5)。
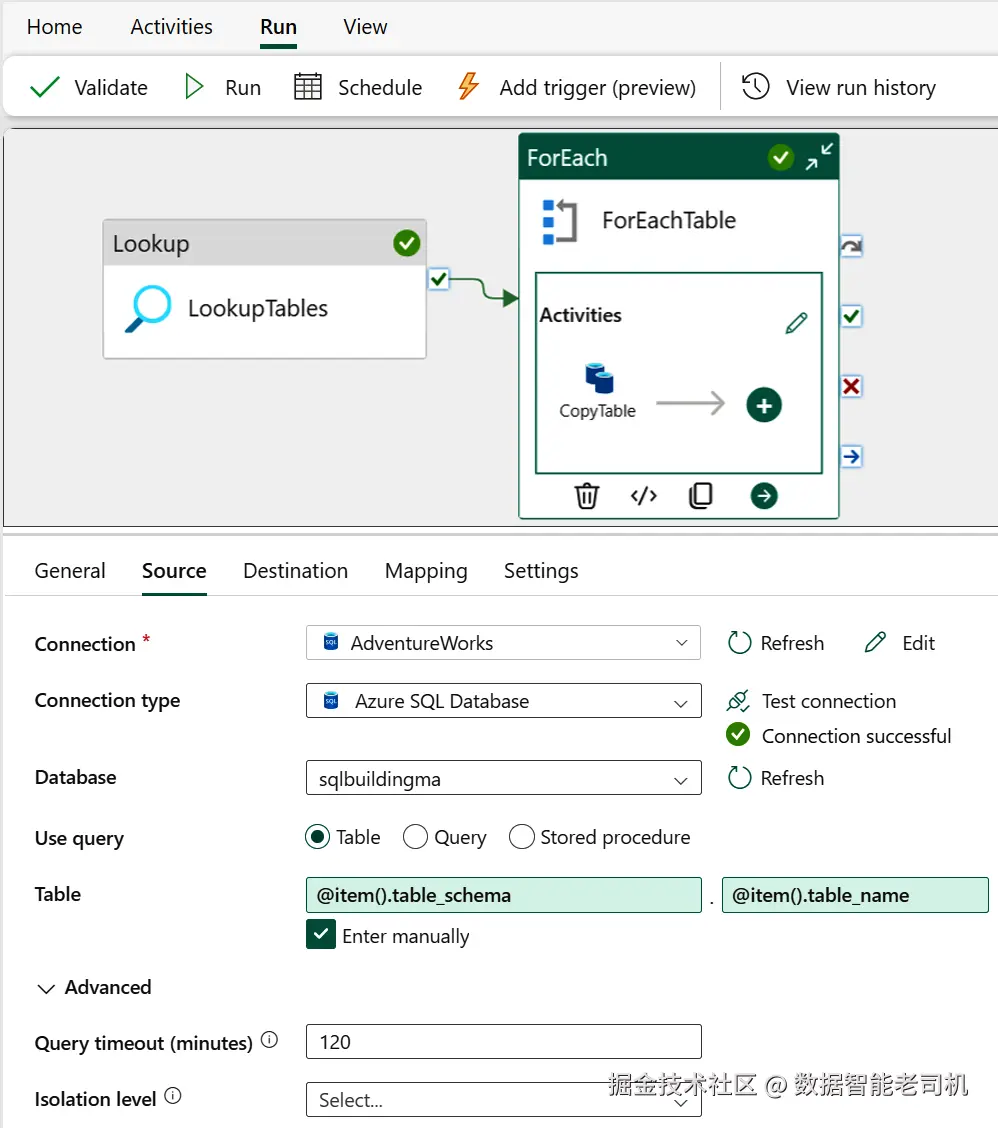
图 5-5. CopyTable 活动的 Source 属性详情
在 Source 属性中,选择 AdventureWorks Connection 以及对应数据库。确保把 TableName 与 SchemaName 指定为输入参数。这些项的值来自 Lookup 活动检索到的元数据:
less
@item().table_name
@item().table_schema然后转到 Destination 属性。Connection 选择 Bronze Lakehouse 。在 filepath 对话框中,添加以下两个属性:
less
@concat('adventureworks/', formatDateTime(utcnow(), 'yyyyMMdd'))
@concat(item().table_name,'.parquet')图 5-6 展示了 Destination 的配置细节。
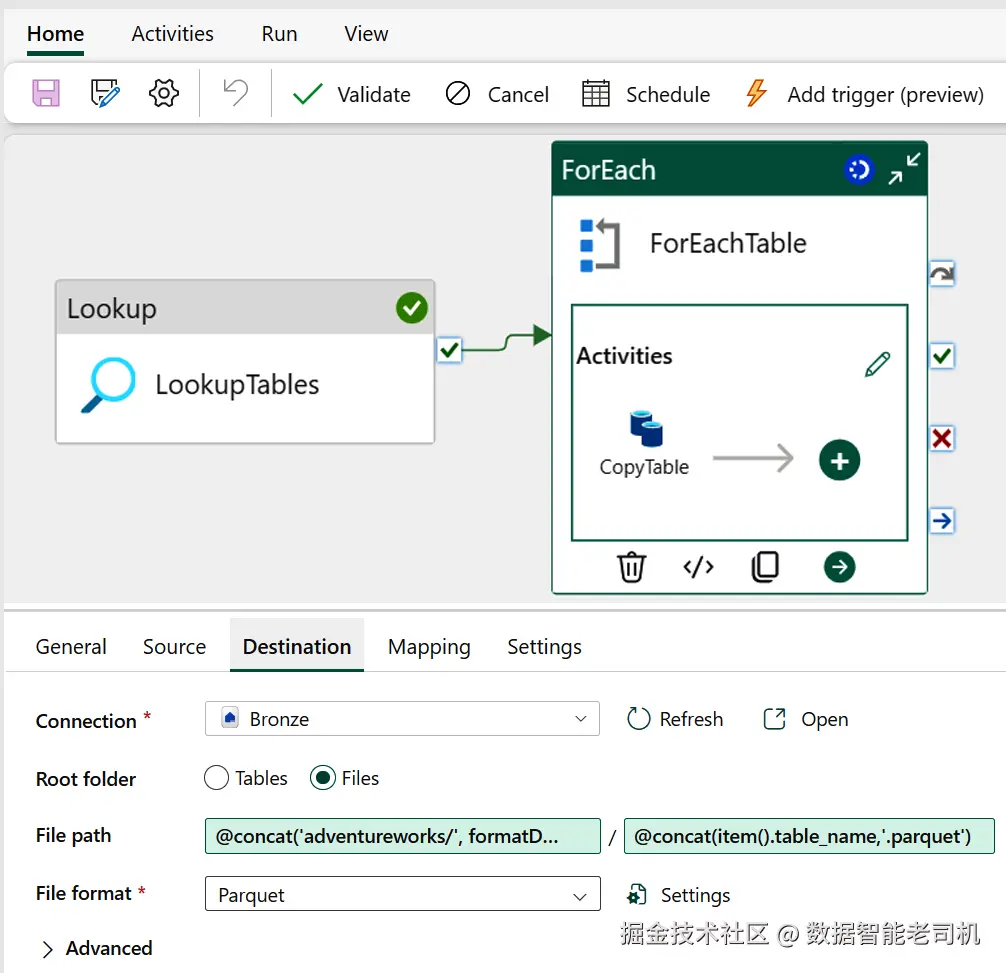
图 5-6. CopyTable 活动的 Destination 属性详情
如果一切配置无误,你应能在工具栏找到 Run 按钮来触发管道并监控过程。成功运行后,在 Bronze 容器中会出现一个文件夹(如图 5-7),其名称为当天日期。
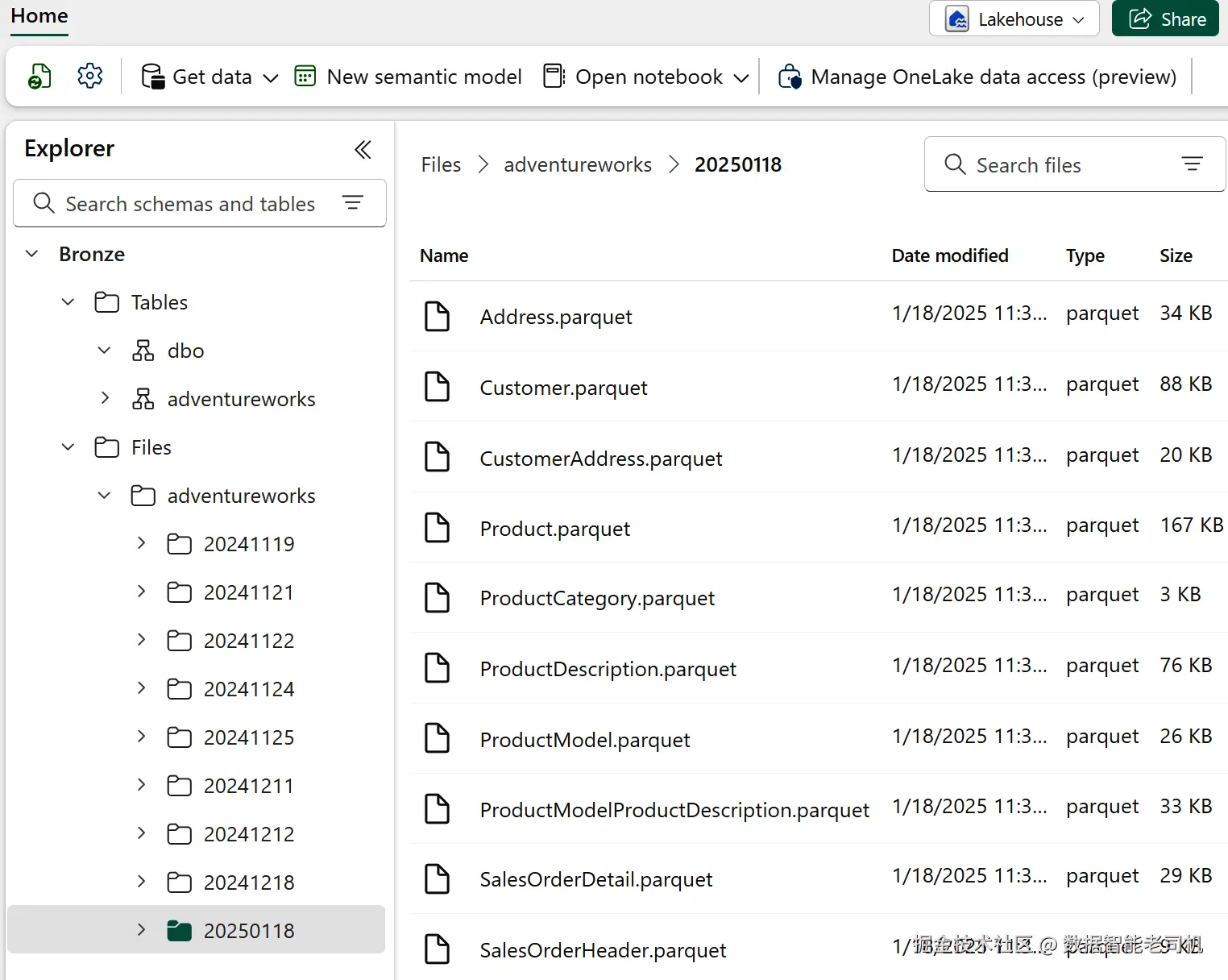
图 5-7. 存储于 Bronze 层的文件概览
通过该配置,AdventureWorks 数据将以如下路径格式存储并在 Bronze Lakehouse 中按天分区:
Files/adventureworks/YYYYMMDD/TableName.parquet。这种方式的好处是以"日"为时间窗归档所有数据,形成结构化、基于时间的存储方案。通过系统性地历史化数据,为后续的 Spark 处理作业准备了良好的输入,同时也满足审计需求,并在发生错误时提供可供恢复的历史记录。
至此,你已经完成了创建新数据管道所需的资源与配置,并通过 Data Factory 将首个数据源接入了 Bronze 层。在继续讨论摄取模式之前,我们先回顾一下构建该数据管道的关键要点。
其他注意事项
务必认识到:数据抽取与摄取方式会因源系统而大相径庭。本教程中的体验之所以顺利,是因为你对数据源有直接访问权限且没有复杂的网络要求。但在其它场景下,数据采集方式可能截然不同。
例如,数据可能会先落在一个临时存储区,或以某种需要技术性转换的格式到达。有时访问数据还需要额外步骤,如部署集成运行时(Integration Runtime)服务或使用虚拟专用网络(VPN)。在另一些情况下,可能需要借助 Azure Functions 等专用工具从某个 API 端点取数。
这里的核心经验是:摄取流程的细节高度取决于源系统的特性以及你要处理的数据性质。理解这些因素,是设计有效数据摄取策略的前提。不存在"银弹"方案------每种场景都需要量身定制。
各组织对 Bronze 层的实施与管理差异很大。这取决于对灵活性的需求、数据源的性质,以及具体的组织要求。这些因素会带来不同的建表与模式管理做法。后续我们会考虑以下几点:
日期分区结构
将平铺的 YYYYMMDD 改为分层的 YYYY/MM/DD 结构,有助于改进数据管理与查询性能。它支持更精确的分区裁剪,减少单目录下超多文件带来的开销,并通过把数据组织成可管理的小块,简化删除与归档等操作。
日志与指标
在摄取数据时,出于审计与排障目的,必须对过程进行监控。一种实用做法是在 Bronze 层为每个处理的数据集记录指标。比如在 Data Factory 中,可从 .output.runStatus.metrics 属性读取并记录"读取行数、写入行数、写入端处理时间"等信息。
对于流式或实时数据,可使用 Apache Spark Structured Streaming 的 QueryProgress 指标,它提供了每秒输入/处理行数、批处理时长、落库提交延迟等关键信息。利用这些指标有助于理解并优化流式管道性能。
此外,实施后处理作业,对源数据以及 Medallion 各层之间的行数与合计进行校验也很有益。这些校验有助于发现数据不一致或错误。建议在每次增量更新之后执行此类校验,以确保数据完整性。
实施日志框架
当前设置缺少完善的日志,这与上一条的监控密切相关。为实现可扩展与更强健的处理能力,建议实施一个日志框架,捕获监控与排障所需的关键信息。可使用 Azure Monitor 或 Azure Log Analytics 等服务,也可用 Azure SQL 自建定制方案。
设置自动触发器
通过某些功能改进管道编排,例如在有新数据到达时自动触发摄取管道。可参考"Create a Trigger that Runs a Pipeline in Response to a Storage Event"的实践示例。
建立共享库
带有完善文档与测试的共享库能大幅提升企业内各数据团队的效率。为提升可扩展性,建议编写可复用脚本,处理技术性文件格式转换、复杂结构扁平化、Append 追加操作等,并将这些脚本托管在共享代码仓库中。
构建"元数据驱动"的通用管道
与其为每种数据单独创建管道,不如采用元数据驱动框架,按提供的元数据自动调整通用管道的行为。这样可显著减少代码编写与维护量。第 6 章会给出具体示例。
让链接服务在运行时接收动态参数
可以将链接服务参数化,使其在运行时接收动态值。比如要连接到同一逻辑 SQL 服务器下的不同数据库,可在链接服务定义中将数据库名参数化。详见"Metadata-Driven Approach"与"Parameterize Linked Services in Azure Data Factory and Azure Synapse Analytics"。
利用 Data Factory 模板
Data Factory 自带模板提供了预定义的管道,帮助你快速上手。更多信息可在 GitHub 获取。
部署集成运行时以满足特定网络要求
网络要求可能使你的设置更为复杂。例如,若需访问本地数据源或其他虚拟网络内的服务,可能需要将集成运行时部署到虚拟网络中。详见"Data Factory Integration Runtime"。
处理数据安全问题
在处理 PII 或其它敏感数据时,安全问题会使摄取流程更复杂。你可能需要过滤敏感数据,或应用加密、动态数据脱敏等。详见"PII Detection and Masking"。
为性能问题考虑重构
若出现性能问题,可能需要重设摄取策略。可考虑启用 Data Factory 的 CopyActivity 中的 "Parallel Copy" 以提升吞吐,或采用增量加载与 Delta 处理替代全量抽取。
你已经完成了管道中的关键配置,并将原始 Parquet 文件导入到 Bronze Lakehouse 实体。但工作尚未结束。下一步,是让这些数据更易访问并为更广泛的处理做好准备。接下来我们将继续本章内容:先建立真正的 Lakehouse 表,然后处理模式(Schema)管理。
实现 Lakehouse 表
到目前为止,我们通过 Parquet 文件捕获了数据。然而,Bronze 层不仅仅是文件的存储空间;它在让数据规范统一、易于访问方面起着关键作用。因此,下一步需要进行更多的数据处理,使数据可被查询并为后续使用做好准备。
接下来的小节将探讨多种数据摄取、转换与建表模式。全面理解这些模式,将有助于你根据自身的具体需求与目标,设计合适的数据摄取策略。请牢记:Bronze 层的主要职能,是以原始、未转换的状态摄入数据,并构建一个可查询层,便于探索与临时分析,同时作为后续数据处理的基础来源。
我们将先学习如何读取数据并直接输出为 Delta 表;随后考察在其它基于 Spark 的服务上使用外部表;再继续探索实时数据摄取技术(例如 Spark Structured Streaming 与 CDC),以便更快地更新 Bronze 层。完成本节后,你将对让数据可查询的不同模式及其影响有扎实的理解。
将遍历的 Parquet 文件转为托管 Delta 表
到目前为止,我们专注的是批处理:一次性处理海量数据,而非逐条或持续处理。我们用 Data Factory 将 AdventureWorks 示例数据库中的表转存为 Parquet 文件。这一步本身并不能让数据开箱即用、即可查询。为了让数据能在新环境中直接被查询与分析,我们将创建 Delta 表。
创建 Delta 表可确保 ACID 事务,从而在并发读写时保证数据完整性与可靠性。Delta 表还支持"时光回溯(time travel)"、高效 upsert 与删除等高级能力,使数据管理更稳健、更灵活。
在 Microsoft Fabric(以及 Azure Databricks)中创建 Delta 表,需要编写一个可由数据管道调用的脚本。回到屏幕左侧导航,进入你在前一部分创建的数据管道。打开 ForEach 活动,并拖入一个新的 Notebook 活动。然后在 Notebook 活动的 Base parameters 区域配置以下参数:
- schemaName :设为
adventureworks - tableName :设为
@item().table_name,以动态传入表名 - filePath :使用
@formatDateTime(utcnow(), 'yyyyMMdd')生成包含当日日期的路径,便于按日期组织/分区数据
更多 Notebook 活动配置见图 5-8。
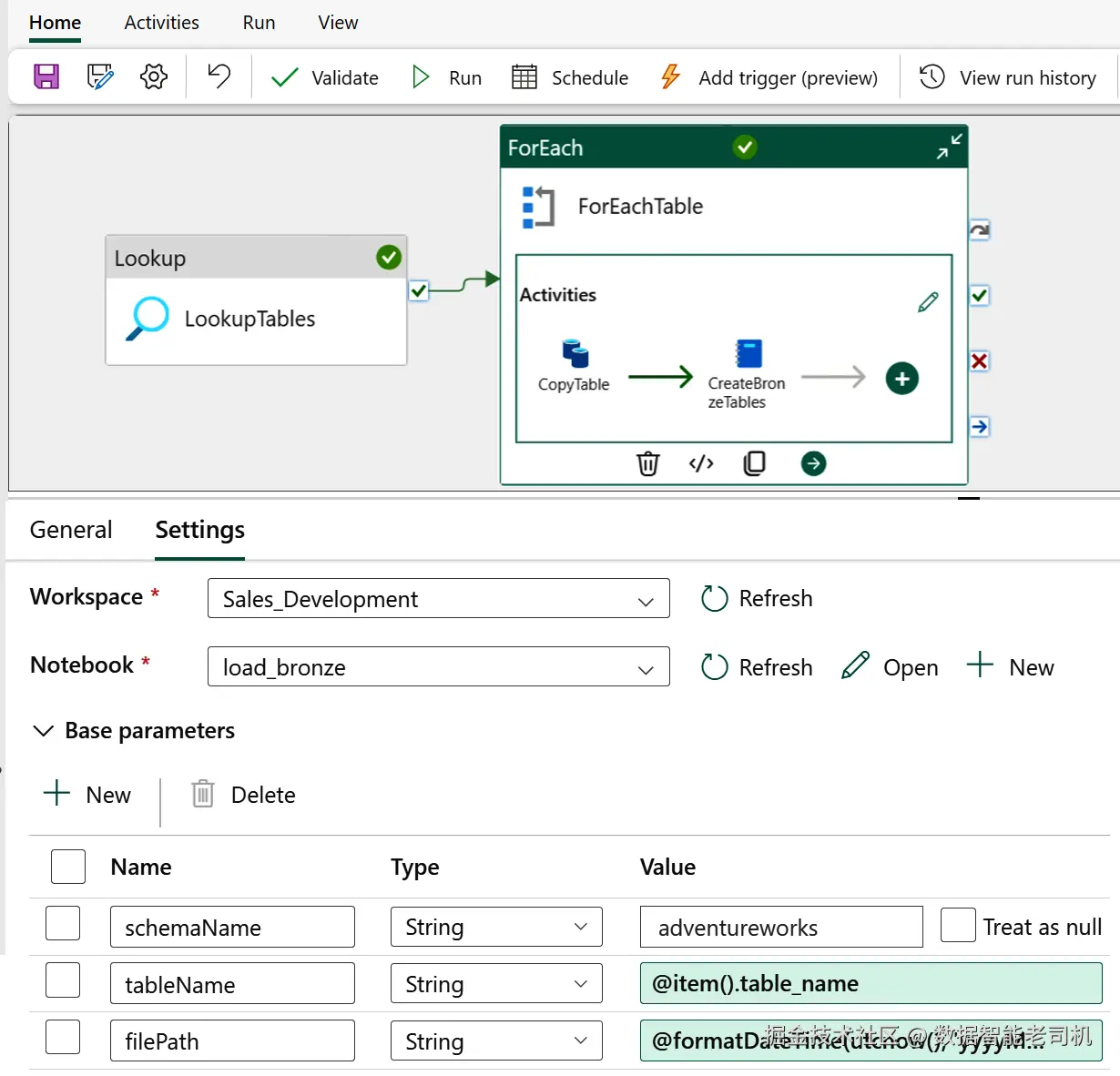
图 5-8. Notebook 活动的配置详情
接着回到 Workspace,新建一个 notebook,用于编写创建 Delta 表的脚本。该脚本按如下顺序执行任务:
- 从 Data Factory 传入的参数中读取
schemaName、tableName、filePath。 - 使用给定的
schemaName创建 Lakehouse 架构(若不存在则创建)。 - 删除已存在的同名表。
- 从 Parquet 文件读取数据加载为 DataFrame。
- 为 Bronze 层中的每个数据集新增一列
loading_date,记录数据摄入的当前日期时间。该时间戳有助于变更追踪与审计,对于实现 SCD2 等需要精确记录版本变更时间的场景尤为关键。本示例只新增一个列;在真实项目中,通常还会加入source_system、lineage_id等更多元数据列。 - 使用 Data Factory 传入的参数,将 DataFrame 内容写入 Delta 表;
mode("overwrite")确保若目标表已存在则用新数据覆盖。
TIP
本节采用"删表 + 全量覆盖"的方式,适合处理全量交付 。它能清理过时数据,但不 适用于只包含增量的"delta 交付"。针对增量/累积数据的替代方法,见"无显式定义模式的建表"。
新建的 notebook 会在几秒后打开,并显示一个单元格。notebook 由一个或多个单元格组成,可包含代码或 Markdown。打开后,将 notebook 重命名为 load_bronze (点击左上角标题处修改)。请在左侧菜单选择 Bronze Lakehouse,确认当前环境无误。
NOTE
所有代码与脚本已托管在 GitHub。
在第一个单元格粘贴以下代码:
ini
# Infer base parameters from the pipeline context
schemaName = ""
tableName = ""
filePath = ""粘贴后,点击单元格右上角"三点"菜单,打开 Toggle parameter cell(必须执行,以便在该单元格设置参数)。随后点击底部"+"新建代码块,并粘贴以下代码:^3
python
# Import functions
from pyspark.sql.functions import current_date
# Create schema
spark.sql(f'CREATE SCHEMA IF NOT EXISTS {schemaName}')
# Drop table
spark.sql(f'DROP TABLE IF EXISTS {schemaName}.{tableName}')
# Read data
df = spark.read.parquet(f"Files/{schemaName}/{filePath}/{tableName}.parquet")
# Add metadata loading_date column using current date
df = df.withColumn("loading_date", current_date().cast("string"))
# Overwrite table
df.write.mode("Overwrite").saveAsTable(f"{schemaName}.{tableName}")准备就绪后,回到 Data Factory 管道,重新运行。若一切配置正确,你应能在 Bronze Lakehouse 的 adventureworks 数据库下看到新生成的表名(见图 5-9)。
通过在 Bronze 层创建 Delta 表,你已迈出让数据可查询、可分析的重要一步。现在可以直接使用 SQL 查询这些数据,或借助 Power BI 等服务进行可视化。此外,Delta 表为后续处理提供了稳健可靠的地基,确保数据完整性,并启用时光回溯与高效 upsert/删除等高级特性。数据已以 Delta 格式存储,后续设计 Silver 层的任务也能更高效地推进。
本节至此,Bronze 层的教程告一段落。但还有其他值得考虑的做法。例如,在需要对海量数据进行查询且不希望加载到托管环境时,外部表会很有用。下一节我们就来探讨这类方法。
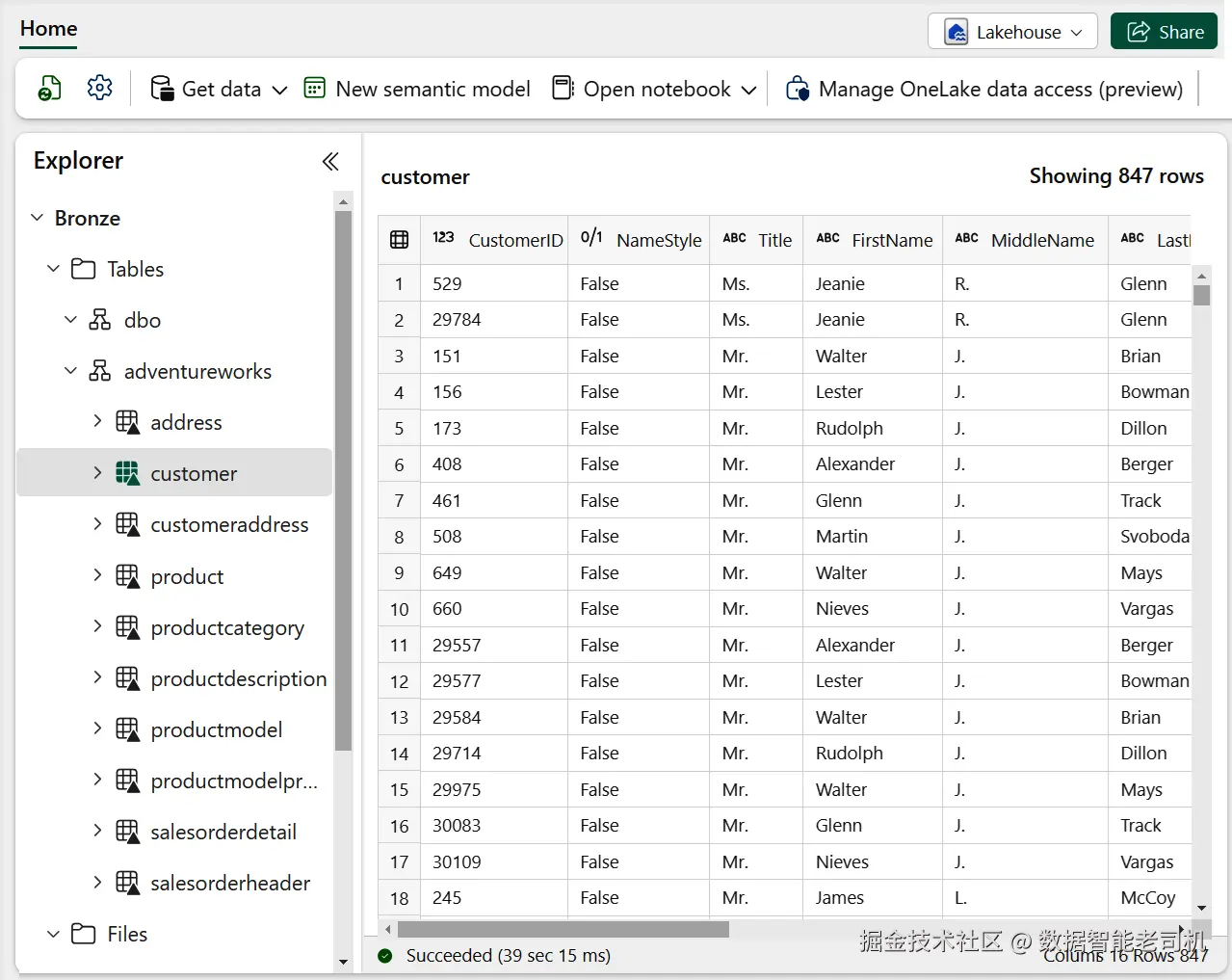
图 5-9. Bronze 层中的 Delta 表概览
使用外部表
我们在第 1 章提到过外部表。外部表允许你查询托管环境之外的数据,例如位于 HDFS 或 ADLS 的数据。
当前写作时,Microsoft Fabric 尚不支持在启用 schema 的 Lakehouse 实体 上创建外部表;^4 但许多其它基于 Spark 的平台支持此能力。以 Azure Databricks 为例,你可以在 CREATE TABLE 语句中使用 LOCATION 子句来创建外部表,只需将表位置指向 ADLS 中的 Parquet 文件路径。脚本通常先通过 Databricks Notebook Activity 获取来自 Azure Data Factory 的参数,然后创建(若不存在)新的 schema,并删除同名旧表。
下面是用 Python 创建外部表的示例:
ini
# Fetch parameters from Data Factory
schemaName=dbutils.widgets.get("schemaName")
tableName=dbutils.widgets.get("tableName")
filePath=dbutils.widgets.get("filePath")
# Create database
spark.sql(f'CREATE SCHEMA IF NOT EXISTS bronze_{schemaName}')
# Drop table
spark.sql(f'DROP TABLE IF EXISTS bronze_{schemaName}.{tableName}')
# Create new external table using latest datetime location
ddl_query = f"""
CREATE TABLE bronze_{schemaName}.{tableName}
USING PARQUET
LOCATION '/mnt/bronze/
{schemaName}/{filePath}/{tableName}.parquet'
"""
# Execute query
spark.sql(ddl_query)外部表简洁直接------不需要复制数据。但请注意以下事项:
- 相比托管的 Delta 表,从外部 Parquet 表读取通常更慢。常见原因包括分区不理想,影响数据访问与处理效率。
- 与托管 Delta 表不同,外部 Parquet 表不支持模式强制(schema enforcement)与时光回溯等高级特性,而这些能力能显著提升数据管理与分析体验。
因此,使用外部表是一种简单直接 的建管道方式,可能也恰好符合你的要求;但它并非最优方案。下一节我们将继续探讨如何更高效地读取与输出数据。
使用 MERGE 操作更新表
在前面的示例中,我们要么使用外部表,要么进行数据克隆。然而,在只需要处理变更(更新与新增)且需要复杂筛选的场景中,增量加载 是必要的,此时 merge(合并) 操作就非常有用。
Delta Lake 支持 MERGE 操作,可将新数据合并进已有表中。该能力对更新或"upsert"(更新或插入)表数据尤其有利。下面是一个使用 SQL 的 MERGE 示例脚本:
ini
MERGE INTO Bronze_Customer AS t
USING Landing_Customer AS s
ON t.CustomerID = s.CustomerID
WHEN MATCHED THEN
UPDATE SET
t.Name = s.Name,
t.ContactDetails = s.ContactDetails,
t.PurchaseHistory = s.PurchaseHistory
WHEN NOT MATCHED THEN
INSERT (CustomerID, Name, ContactDetails, PurchaseHistory)
VALUES (s.CustomerID, s.Name, s.ContactDetails, s.PurchaseHistory);MERGE 操作非常灵活,支持多种条件,例如 WHEN MATCHED、WHEN NOT MATCHED、WHEN MATCHED AND、WHEN NOT MATCHED BY TARGET、WHEN NOT MATCHED BY SOURCE 等。你可以基于匹配条件定义具体动作,从而强力支持增量数据加载的管理。
同样的逻辑也可以在 Python 中借助 DeltaTable API 执行,优势是可以通过参数化传入变量:
python
from delta.tables import *
dTable = DeltaTable.forPath(spark, \
f"abfss://{workspaceId}@onelake.dfs.fabric.microsoft.com/ \
{lakehouseId}/Tables/{schemaName}/{tableName}")
(dTable.alias("original")
.merge(df.alias("updates"), f"original.{primaryKey} = updates.{primaryKey}")
.whenMatchedUpdateAll()
.whenNotMatchedInsertAll()
.execute()
)MERGE 的优点是能更高效地处理数据。但当源数据不干净或连接条件不直观时,会带来复杂度。在这种情况下,常需在合并前先做额外的清洗或转换。例如,如果数据集中存在重复项,就需要在执行 MERGE 前完成去重。因此,复杂的合并操作往往放到 Medallion 架构的后续层中执行。我会在第 6 章与第 7 章给出具体示例再回到这一点。
现在我们已经探讨了多种面向批处理 的数据处理方法,接下来过渡到 Spark Structured Streaming ------一个通用的流式摄取方案。
Spark Structured Streaming
流处理 是一种以极低延迟从队列或文件中消费消息、进行处理(如查询、过滤、聚合),再将结果推送到目标(sink)的技术。它不同于按固定周期运行的批处理 或微批处理。^5
在实时流处理方案中,Spark Structured Streaming 值得重点关注,原因在于其通用性以及与任意基于 Spark 的平台的无缝集成。正如第 3 章所述,它适用于需要低延迟 响应的场景,可对来自 IoT 设备、边缘设备 ,以及金融交易、机器日志等实时数据源的数据进行处理。
例如,构建一个机队的实时监控系统 :可用 Azure Event Hubs 摄入来自各飞机上多种传感器与设备的数据,然后用 Spark Structured Streaming 实时处理。开发语言可以是 C#、Java、Python 或 Node.js。该架构示意见图 5-10。
图 5-10. 使用 Spark Structured Streaming 通过 Event Hubs 摄取数据的架构
Spark Structured Streaming 的优势之一是支持复杂事件处理(CEP) ,可处理复杂查询以及将流与静态数据或其它流进行关联 。这对诸如推荐、用户行为追踪等高级分析至关重要。延续上面的航空监控示例:当出现如恶劣天气 等突发状况时,事件流可即时告警 相关方,从而快速决策进行航线改道 或采取其它安全措施。接下来,我们将其与 Azure Event Hubs 集成以增强能力。
结合 Azure Event Hubs 的示例
在 Spark 中配置 Structured Streaming 并连接 Azure Event Hubs,可参考以下代码片段:
makefile
# Library that allows to stream content from Azure Event Hubs
%pip install azure-eventhub
ehConf = {}
# Azure Event Hubs connection configuration
connectionString = "Endpoint=sb://{NAMESPACE}.servicebus.windows.net/ \
{EVENT_HUB_NAME};EntityPath={EVENT_HUB_NAME}; \
SharedAccessKeyName={ACCESS_KEY_NAME}; \
SharedAccessKey={ACCESS_KEY}"
# For 2.3.15 version and above, the configuration dictionary
# requires that connection string be encrypted.
ehConf['eventhubs.connectionString'] = sc._jvm.org.apache.spark.eventhubs \
.EventHubsUtils.encrypt(connectionString)
# Streaming data from Azure Event Hubs
df = spark \
.readStream \
.format("eventhubs") \
.options(**ehConf) \
.load()
# Writing stream: Persist the streaming data to a Delta table
df.writeStream \
.option("checkpointLocation","abfss://<abfss_location>") \
.outputMode("append") \
.format("delta") \
.toTable("bronze.weather")流程为:先安装从 Azure Event Hubs 流式读取所需的库,然后配置并加密 连接串;将 Event Hubs 中的数据以流的形式读入到 DataFrame;再将其写入 Bronze 层的 Delta 表 。其中 checkpointLocation 用于保存流式查询的元数据,以实现容错 并在失败后恢复。
除了将流数据写入 Bronze 层,你还可以在 Structured Streaming 中继续对 DataFrame 做过滤、清洗、转换 ,并将精炼后的输出 直接写入 Silver 层(甚至在需要时进一步写入 Gold 层),以便更复杂的分析与报表使用。这将显著提升下游处理的数据质量与可用性。我们会在第 6 章再次讨论这一点。
虽然本节聚焦于使用 Spark Structured Streaming 进行处理与转换,但别忽略数据最初如何进入系统 。这就涉及 CDC(变更数据捕获) 的概念,它在数据处理前承担从不同数据源捕获变更的关键职责。两者都能增强数据处理能力,但 CDC 专注于变更的初始捕获,为后续处理与分析打下基础。
采用变更数据捕获(CDC)
CDC 用于跟踪数据库中的变更 。它会捕捉对数据所做的插入、更新与删除,并将这些变更记录存放到单独的表 中。CDC 尤其适合实时数据复制 :它能持续跟踪数据变化,帮助你维持一份准确且最新的数据视图。
例如,Microsoft Fabric 通过**镜像(mirroring)**支持 CDC。借助该功能,可将数据库(如 AdventureWorks 示例)直接复制到 Fabric 的 OneLake 中(参见"Tutorial: Configure Microsoft Fabric Mirrored Databases from Azure SQL Database")。
TIP
除文中提到的 CDC 机制外,在采用 Delta Lake 与 Spark 的湖仓架构中引入变更数据馈送(change data feed, CDF) ,能显著提升复制效率。CDF 以更细粒度的方式访问变更记录(包含插入、更新与删除),提供一种流式、可扩展的变更获取方法。
需要注意的是,CDC 功能强大,但实现也较为复杂:
- 需要精心实施 ,并依赖主键来完成镜像过程;
- 一旦发生架构(schema)变更 ,对应表会重新执行完整快照 并重新灌入全部数据;
- 并非所有列类型 都受支持,需要确保源与目标之间的数据类型兼容;
- 你会与实时源库结构 形成较强耦合 ,通常还需要在下游增加一层用于归档 与轻量转换(例如补充元数据)。
统筹数据处理技术
我们已回顾多种能显著提升数据管理与处理方式的技术路径:
- 从 Parquet 文件过渡到受管的 Delta 表 ,以获得更好的性能与时光回溯能力;
- 使用外部表实现数据的快速暴露与查询;
- 借助 MERGE 操作进行增量更新(仅处理必要的更新与新增);
- 通过 Spark Structured Streaming 实现实时数据转换;
- 采用 CDC 以零 ETL 模式镜像或捕捉数据库的实时变更。
这些模式在现代数据架构中各司其职。选择时应结合具体场景 与采集复杂度 权衡取舍;在实际项目里,往往会组合使用多种方式,以契合架构的独特需求。
在了解了各类数据处理技术与取舍之后,接下来需要关注另一个基础主题:架构(schema)管理 。掌握与研究架构管理策略至关重要,它将为第 6 章后续的动手实操打下坚实基础。
架构管理(Schema Management)
正如"架构演进与管理"所强调的,管理架构演进 至关重要,尤其是在 Bronze 层------这里是以原始形态存放原始数据的第一站。可以把**架构(schema)**看作数据的蓝图:它规定了数据的结构、各字段的数据类型,以及数据要素之间的关系。
在管理架构时,有多种可选方法,各有利弊。下面从最简单、最灵活 的方法讲起,再过渡到更结构化、更严格的做法。
不定义架构直接建表
在湖仓中创建表的最简方式之一,是不显式定义任何 schema ,让 Delta Lake 负责架构演进 。例如,希望避免像前面的例子那样每次流水线运行都重建表;相反,选择追加并累积数据 ,让 Delta Lake 的 schema 演进特性随时间自动适配结构变化;同时按加载日期分区以提升性能。可以使用如下代码:
python
from delta.tables import *
from pyspark.sql.functions import current_date
# 删除当日已存在的数据
if (DeltaTable.isDeltaTable(spark, f"{schemaName}.{tableName}")):
spark.sql(f"DELETE FROM {schemaName}.{tableName} \
WHERE loading_date = current_date()")
# 读取数据
df = spark.read.parquet(f"Files/{schemaName}/{filePath}/{tableName}.parquet")
# 添加加载日期列
df = df.withColumn("loading_date", current_date())
# 以合并架构方式写入 Delta 表
df.write.format("delta") \
.mode("append") \
.partitionBy("loading_date") \
.option("mergeSchema", "true") \
.saveAsTable(f"{schemaName}.{tableName}")在这个例子中,Delta Lake 会把新数据的架构与目标 Delta 表的现有架构合并 。启用 mergeSchema 后,DataFrame 中新增而目标表不存在 的列会在一次写事务中自动追加 到表 schema 的末尾。示例中的 schemaName、tableName、filePath 分别代表架构名、表名与文件路径;在 Microsoft Fabric 或 Azure Databricks 中可替换为你的实际值。
这种累积式 写法简单灵活,适合增量交付(delta deliveries)等场景------只关心变化数据即可。不过它也带来风险:数据质量可能下降、格式变更不可预期,从而削弱对结构的掌控 ,影响下游兼容性。为对冲风险,通常需要在后续层增加校验。
当你更加看重数据完整性与一致性 时,采用显式定义 schema的方式会更合适。
使用 DataFrame API 定义架构
通过 DataFrame API 定义 schema 是管理湖仓 schema 的另一种方法。例如:
python
from pyspark.sql.types import *
# 定义 schema
schema = StructType([
StructField("CustomerID", IntegerType(), True),
StructField("NameStyle", BooleanType(), True),
StructField("Title", StringType(), True),
StructField("FirstName", StringType(), True)
])
# 读取原始 JSON 并套用 schema
df = spark.read.schema(schema).json("/path/to/raw/data")
# 写入 Delta 表
df.write.format("delta").saveAsTable("adventureworks.customer")这种方式非常适合在 Spark 中处理复杂/嵌套结构 ,并支持schema-on-read :读取原始数据时即在查询侧指定列名/类型。如无法成功应用 schema,可在代码中加入错误处理逻辑。
接下来看看另一种方法:使用 SQL DDL 在笔记本里直接创建表 。这是一种 schema-on-write 的做法,与 schema-on-read 互补:在写入点 定义并强制执行数据结构。
使用 SQL DDL 语句
在 Spark 笔记本里编写 DDL 十分高效,适合强调一致性与完整性的场景。
创建 adventureworks 架构:
sql
CREATE SCHEMA adventureworks在该架构下创建 customer 表:
sql
CREATE TABLE customer (
CustomerID INT COMMENT 'Customer identifier',
NameStyle BOOLEAN COMMENT 'Style of the name',
Title STRING COMMENT 'Title of the customer',
FirstName STRING COMMENT 'First name of the customer'
)
USING delta许多(关系型)数据库都使用 SQL DDL,这让迁移/复用现有 DDL 更容易,在多平台间保持兼容 与集成也更顺畅。
注:在其他 Spark 平台上,若在
CREATE TABLE中指定了LOCATION,该表即被视为外部表。
虽说 DataFrame API 与 SQL DDL 都能灵活定制 schema,但对于错综复杂 的数据结构,维护成本仍可能不小。对此,你可以让应用在构建流程中导出 DDL ,或采用 schema-on-write + mergeSchema 的组合:先严格、后渐进。同时也可使用独立配置文件管理 schema,见下节。
使用 YAML / JSON 配置
用 YAML (或 JSON )定义 schema 是另一种有效方法,适合把 schema 存在独立文件 中以便跨笔记本或项目复用。YAML 可读性强、便于加入额外元数据 与注释,例如给列增加 PII 标记 。此外,YAML/JSON 可与代码分库版本管理,便于追踪 schema 的历史变更。
示例 schema.yaml:
yaml
columns:
- name: CustomerID
type: integer
- name: NameStyle
type: boolean
- name: Title
type: string
- name: FirstName
type: string
PII: true在笔记本中可借助 PyYAML 读取并生成 PySpark schema:
注:先执行
pip install PyYAML安装依赖。
python
import yaml
from pyspark.sql.types import *
# 读取 YAML
def load_yaml_file(yaml_file_path):
with open(yaml_file_path, 'r') as file:
schema_yaml = yaml.safe_load(file)
return schema_yaml
# 从 YAML 生成 PySpark Schema
def generate_schema_from_yaml(yaml_data):
columns = yaml_data['columns']
schema = StructType()
for column in columns:
if column['type'] == 'integer':
schema.add(StructField(column['name'], IntegerType(), True))
elif column['type'] == 'string':
schema.add(StructField(column['name'], StringType(), True))
elif column['type'] == 'boolean':
schema.add(StructField(column['name'], BooleanType(), True))
elif column['type'] == 'datetime':
schema.add(StructField(column['name'], Datetime(), True)) # 需替换为合适的 TimestampType()
return schema生成并应用 schema:
ini
# 加载 YAML
schema_yaml = load_yaml_file('/path/to/schema/schema.yaml')
yaml_data = load_yaml_file(schema_yaml)
schema = generate_schema_from_yaml(yaml_data)
# 使用该 schema 构建 DataFrame
df = spark.createDataFrame(data, schema=schema)当列很多或结构复杂时,YAML/JSON 能以结构化的方式清晰表达 schema,提升一致性与完整性控制;也可扩展到嵌套结构/更多元数据 ,甚至先由 YAML 生成 SQL DDL 再创建表,以便涵盖更复杂的数据类型或约束。
唯一的不足是:对于超大/超复杂 的 schema,YAML/JSON 本身会变得冗长难管 。此时可考虑采用元数据驱动的方法来定义与管理 schema。
元数据驱动方法(Metadata-Driven Approach)
元数据驱动 是一种更高级的架构定义方式。它将架构定义存放在集中式元数据仓库 (如数据库或数据目录)中。该仓库记录数据结构的信息:列名、数据类型、约束、以及不同数据要素之间的关系。运行时可据此动态生成 架构定义,从而让同一套流程适配不同的数据源与目的端 。在第 6 章,我会示范如何用 Azure SQL 数据库实现这种元数据驱动方法。
TIP
Jaco van Gelder 发布了一个函数,可灵活添加新列到数据库架构中,同时避免重复并保持既有列的顺序。可在他的 GitHub 查看:"Jaco's Schema Evolution Function"。
实现一个元数据驱动框架可能较为复杂且耗时。作为替代方案,我们先过渡到另一项强大工具:Databricks Auto Loader 。它底层采用 Structured Streaming,并为批处理与实时处理/集成 提供了增强能力。尽管它仅适用于 Databricks,但在架构演进管理上能大幅简化工作。
Databricks Auto Loader
Auto Loader 是 Databricks 的专属能力,用于简化把数据增量摄入 到既有表中。本质上它是一个带有批量摄入 增强的 Spark 流式机制。它在发现文件时,会把文件元数据保存到流水线检查点目录 中的 RocksDB 键值存储里;借助该状态信息,它能保证exactly-once 处理,并在故障后从检查点继续。
Auto Loader 在架构演进 方面尤为出色:处理新文件时会自动推断 其架构,并将新出现的字段无缝合并 到既有架构中,避免新旧格式不匹配导致的中断。如果不希望自动演进,可设置 cloudFiles.schemaEvolutionMode=rescue:此时不会自动更新表架构,而是新增一个 _rescued_data 列,以"收容"未预料的字段。这样既不丢数据,又便于后续人工审阅并决定是否将这些新增要素纳入主表结构,减少对管道的即刻改动和冲击。
Auto Loader 支持多种数据格式:JSON、CSV、Parquet、Avro、ORC、TEXT、二进制 等。它面向云对象存储的增量摄入 ,也可以按目录增量复制全部数据到目标表。
下面的代码片段用于 Oceanic Airlines 项目的全量加载(如在 Azure Databricks 使用,可直接复用或按需调整):
python
# 从 Azure Data Factory 获取参数
catalogName="prod_sales"
schemaName=dbutils.widgets.get("schemaName")
tableName=dbutils.widgets.get("tableName")
filePath=dbutils.widgets.get("filePath")
# 从落地区(landing)读取 parquet 的 schema,并转为 DDL
jsonSchema = spark.read.parquet(f"/Volumes/{catalogName}/sources/landing/\
{schemaName}/{filePath}/{tableName}.parquet").schema.json()
ddl = spark.sparkContext._jvm.org.apache.spark.sql.types.DataType \
.fromJson(jsonSchema).toDDL()
# 使用 Auto Loader 将 parquet 迁移为 delta
(spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "parquet")
.option("cloudFiles.includeExistingFiles", "true")
.option("cloudFiles.backfillInterval", "1 day")
.option("cloudFiles.schemaLocation", f"/Volumes/{catalogName}/sources/\
landing/{schemaName}/_checkpoint/{tableName}_autoload/")
.schema(ddl)
.load(f"/Volumes/{catalogName}/sources/landing/\
{schemaName}/{filePath}/{tableName}.parquet")
.writeStream
.format("delta")
.option("checkpointLocation", f"/Volumes/{catalogName}/sources/landing/\
{schemaName}/_checkpoint/{tableName}_autoload/")
.trigger(availableNow=True) # 立即启动
.toTable(f"bronze_{schemaName}.{tableName}")
)流程要点:
-
先从落地区读取 Parquet schema 并转 DDL,据此创建目标表;
-
用 Auto Loader 将 Parquet 数据迁移到该表;
-
backfillInterval="1 day"允许回填前一日数据; -
同时配置
.schema(ddl)与.option("cloudFiles.schemaLocation", ...):- schema 强制(enforcement) :
.schema要求数据必须符合指定架构,防止异常列/类型写入。 - schema 演进(evolution) :
schemaLocation记录并维护文件架构变化;结合cloudFiles.schemaEvolutionMode(如addNewColumns、merge、failOnNewColumns)可控制演进策略。
- schema 强制(enforcement) :
第三方工具
你也可以选用具备可视化 能力的第三方工具来设计和管理 schema,如 SQLAlchemy、SqlDBM、erwin Data Modeler、Hackolade 等。此类工具为复杂环境提供完备的模型设计、数据集成、数据质量 功能。但需权衡:额外成本 、集成工作量 与厂商锁定等风险,确保与组织的长期策略相符。
处理架构演进(Best Practices)
与"临时写入时现建表"相比,预定义表 的优势在于:更好地控制列与类型 、减少错误、并提升查询性能(如基于 Region 分区以加速大表查询)。在管理架构演进、让体系更可演化时,建议遵循以下实践:
- 充分规划
在变更前做好周密计划,并记录架构版本,便于追踪演进。 - 先在安全环境测试
先在 Dev/Test 环境验证,再推生产,避免影响线上数据。 - 保持后向兼容
优先保证不破坏既有查询与应用。 - 制定回滚方案
发生问题能快速回滚到旧版 schema,降低中断与风险。 - 使用迁移工具
可用 Atlas、Liquibase 等做 schema 版本化与增量迁移;或将开发环境导出的 DDL 入库管理,遇到破坏性变更就配套迁移脚本(例如在 PR 上触发 GitHub Action 自动生成脚本并部署)。 - 采用元数据驱动 / YAML 配置
通过元数据驱动 与/或 YAML 配置自动化 schema 变更,确保多环境一致,减少人为失误。
遵循这些实践,你就能在 Medallion 架构中有效管理架构演进,保障数据的一致性、完整性与可靠性。
结论
在 Medallion 架构中构建可查询的 Bronze 层 被证明是一项多层面的挑战。这个过程需要整合众多组件与服务,每个部分都有各自的难点与要求。本章中,你已将第一个数据源成功接入 Bronze 层:你构建了一个将示例数据库中的表搬运到 Bronze 层的数据管道 ,创建了笔记本 ,并把 Parquet 文件加载为 Lakehouse 实体中的 Delta 表 。此外,你还探索了多种实现 lakehouse 表与架构(schema)管理的方法。
尽管步骤看似直观,不同场景下的数据采集方式差异很大 。由于复杂性与对稳定、可靠的强需求,数据采集始终是数据工程的基础性难题。因此,许多组织会为不同的数据源构建多条管道,每条都需定制化处理------并不存在放之四海而皆准的方案。选型取决于多种因素:数据源类型、数据量、源系统架构的波动性、处理需求;以及项目的特定要求,如实时处理或批处理,交付模式是增量(delta)还是全量装载(full load)等。
理解各类模式的细节及其适用场景,对于一致性与成功落地 至关重要。我也建议在同一组织内、不同工程团队各自运行平台实例的情况下,提供完整的规范与培训,确保大家对最佳实践保持一致。
举例来说:若需周期性批处理大体量数据 ,可以指导团队采用 Data Factory 做编排,配合 Delta 表 完成存储与处理;若是实时流式 场景,则可选择 Spark Structured Streaming ;若需要批+流混合 或直接访问 ,可将外部表 用于直接查询,同时用 Structured Streaming 完成摄取与处理。总之,需要理解权衡、把握细微差别,并在方法上保持一致。以下要点有助于你打造一个健壮的 Bronze 层:
- 认识到每个数据源在接入时都可能带来独特挑战 (结构或网络限制等),在上游接入策略上保持灵活。
- 为每个数据源 设计专用管道 ,并针对通用处理步骤使用模板,以保持一致性与复用性。
- 制定架构演进 与技术校验策略;引入**元存储(metastore)**可能会有帮助。
- 以独立的 schema 或独立的 Lakehouse 实体 来组织各数据源的数据,并与相应的数据管道一一对应。
- 明确发布指引 :Bronze 层的数据是否向终端用户开放访问。
在下一章中,我们将转向构建 Silver 层 。我们将继续使用 Microsoft Fabric,把来自 Bronze 层的数据转化 为结构化、可优化查询 的格式;这将包括清洗数据 以保证质量与可靠性。我们还会实现技术校验 ,把它作为 Bronze 与 Silver 之间的闸门(gate) ,并在第 6 章纳入整体设计。