ChatGPT 于 2022 年 11 月下旬发布。到次年 1 月,这款应用的月活用户估计已达 1 亿,成为史上增长最快的消费者应用。(作一对比,TikTok 花了 9 个月才达到 1 亿用户,Instagram 则用了 2.5 年。)而且,尊敬的读者,你一定也会认可------这份公众赞誉当之无愧!像支持 ChatGPT 的这类 LLM 正在彻底改变我们的工作方式。与其跑去 Google 进行传统的网页搜索找答案,你完全可以让一个 LLM 来谈论某个主题。与其翻 Stack Overflow 或在博客里东翻西找以解答技术问题,你可以让 LLM 针对你的确切问题域写一篇个性化教程,然后再补上一组关于该主题的问答(Q&A)。与其按传统步骤去构建一个编程库,你可以与一个基于 LLM 的助手"结对",让它在你编码时搭好脚手架、自动补全代码,从而大幅加速进度!
致未来的读者:你会以我们------这些来自 2024 年的谦卑作者------难以想象的方式来使用 LLM 吗?如果当前趋势持续下去,你很可能在日常的一天里多次与 LLM 对话------当你的有线电视断线时,它以 IT 支持助理的声音出现;与街角 ATM 的友好对话;甚至,是一个让人挠头的"逼真"机器人拨号器。还有其他交互:LLM 会为你策划新闻,概括你最可能感兴趣的头条,并移除(或也许添加)带偏见的评论。你会用 LLM 来协助沟通,比如撰写与摘要邮件;而办公室与家用助手甚至会"伸手"到现实世界,代表你去互动。在一天的不同时段,你的个人 AI 助手可能先扮演旅行代理人,帮你做旅行计划、订机票、订酒店;随后又化身购物助理,帮你寻找并购买所需物品。
为什么 LLM 如此神奇?因为它们"像魔法"!正如未来学家 Arthur C. Clarke 著名所言:"任何足够先进的技术都与魔法无异。"我们认为,一个你可以与之对话的机器当然称得上"魔法",但本书的目标是揭开这层"魔法"。我们将展示:无论 LLM 有时看起来多么离奇、直觉、像人类,其核心不过是一个在一段文本中预测"下一个词"的模型------仅此而已!因此,LLM 只是帮助用户完成某项任务的工具,而你与这些工具交互的方式,就是编写提示(prompt)------也就是那段供模型续写的文本。这正是我们所说的"提示工程(prompt engineering)"。贯穿全书,我们将构建一套实用框架,用于开展提示工程,并最终用于构建 LLM 应用------而这将为你的用户带来"如同魔法般"的体验。
本章为你即将开始的提示工程之旅奠定背景。但在此之前,让我们先讲讲我们两位作者如何亲身遇见这份"魔法"。
LLM 像魔法
本书两位作者都曾是 GitHub Copilot 代码补全产品的早期研究型开发者。Albert 是创始团队成员;当他转向更远期的 LLM 研究项目时,John 加入并投入到这台"车辆"的试驾之中。
Albert 在 2020 年年中第一次"遇见魔法"。他这样回忆:
每隔半年左右,在我们"ML-on-code"小组的创意会里,总会有人提到"代码合成"这个话题。答案总是一样:它将来会很惊艳,但至少还要五年。这就像我们的"冷核聚变"。
这种说法一直成立,直到我第一次上手那个后来成为 OpenAI Codex 雏形的早期原型。我看到"未来已来":冷核聚变终于实现了。
很快就能看出,这个模型与我们此前见过的蹩脚"代码合成"尝试完全不同。它不仅能有机会预测下一个词------它能从一个 docstring 直接生成整段语句、整段函数。还能跑得通的函数!
在我们决定"用它能造什么"之前(剧透:后来成了 GitHub 的 Copilot 代码补全),我们想先量化这模型到底有多好。所以我们众包了一群 GitHub 工程师,让他们想出一些自包含的编码任务。有些任务相对简单------但这群人都是硬核码农,许多任务其实挺复杂。有不少任务属于初级开发会去 Google 的那种,但也有些会逼得资深开发去 Stack Overflow。可只要给模型几次尝试,大多数任务它都能解出来。
那时我们就知道了------这就是将引领编程进入新时代的引擎。我们要做的只是围绕它造出合适的"车辆"。
对 John 而言,神奇时刻则出现在两年后、2023 年初,他在"试驾"这台车辆。他这样讲述:
我开启了屏幕录制,摆出打算挑战的题:写一个函数,输入整数,返回该数字的英文文本。比如输入 10,输出 "ten";输入 1,004,712,输出 "one million four thousand seven hundred twelve"。这比想象难,因为英语里怪例外一堆:10 到 20 的"eleven""twelve""teens"都不遵循其他十位的规律。十位数字也很"跳"------既然 90 是 "ninety"、80 是 "eighty",那为什么 30 不是 "threety"、20 不是 "twoty"?而我的真正"加难点"是:我想用一个我完全没经验的语言来实现------Rust。Copilot 顶得住吗?
学新语言时,我通常会查一些基本"如何做":如何创建变量?如何创建列表?如何遍历列表?如何写 if?但这次我只是先写了个 docstring:
// GOAL: Create a function that prints a string version of any number
// supplied to the function.
// 1 -> "one"
// 2034 -> "two thousand thirty four"
// 11 -> "eleven"
fn
goCopilot 看到 `fn` 就开始帮我了:fn number_to_string(number: i32) -> String {
rust完美!我本来不懂如何给函数入参和返回值做类型标注,但在我们继续协作的过程中,我用注释来指挥高层流程,比如"把输入数字按三位一组切分",而 Copilot 实际上在"教我"语言构造:例如如何创建向量并赋值给变量(`let mut number_string_vec = Vec::new();`),如何写循环(`while number > 0 {`)等等。
体验非常棒。我在持续推进、同时学习这门语言,而且不被频繁查教程分心------我的项目就是我的教程。然后,在实验第 20 分钟时,Copilot 给了我当头一棒。我输入了注释并开始下一个我知道必需的控制循环:
// iterate through number_string_vec, assemble the name of the number
// for each order of magnitude, and concatenate to number_string
for
稍作停顿后,Copilot 一口气补了 30 行代码!在录屏里你甚至能听到我倒吸一口气。代码能编译------语法全对------而且还能跑。答案有点小毛病:输入 5,034,012 得到 "five thirty four thousand twelve million",但说真的,我也不指望人类第一次就完全正确;这个 bug 也很容易定位修正。到 40 分钟配对结束时,我已经做成了几乎不可能的事------在一门我完全陌生的语言里写出了非平凡的代码!Copilot 不仅引导我掌握了 Rust 语法基础,还对我的目标形成更抽象的把握,并在多个节点主动帮我补足细节。要是我自己干,我估计得花上好几个小时。
我们的"魔法时刻"并不独特。你既然在读这本书,很可能也与 LLM 有过令人惊叹的交互。也许你是从 ChatGPT 见识到 LLM 的威力;也许你的首次体验来自 2023 年初以来铺天盖地的第一代应用:如微软 Bing、谷歌 Bard 这类互联网搜索助理,或微软更广泛的 Copilot 办公套件这类文档助理。但抵达这个技术拐点,绝非一夜之间发生。要真正理解 LLM,了解我们如何走到今天至关重要。
语言模型:我们如何走到今天?
要理解我们为何来到技术史上的这个有趣时刻,首先需要弄清什么是"语言模型",以及它到底做什么。问谁更合适呢?当然是当今最流行的 LLM 应用:ChatGPT(见图 1-1)。

图 1-1. 什么是语言模型?
看到了吗?正如本章开头所说:语言模型的首要目标是预测下一个词出现的概率。其实你以前见过这种功能,对吧?当你在 iPhone 上编写短信时,键盘上方会出现一个"候选词条"的补全栏(见图 1-2)。你也许从没在意过......因为它并不是那么好用。如果语言模型只会做这些,那它们又怎么可能在当下引发一场全球风暴呢?
图 1-2. John 指着手机上的补全集栏
早期语言模型
语言模型其实已经存在很久了。如果你在本书出版后不久阅读这些文字,那么驱动 iPhone"猜下一个词"功能的语言模型,是基于 1948 年首次提出的马尔可夫模型。不过,还有一些更近代的语言模型,才直接为当下正在上演的 AI 革命奠定了舞台。
到了 2014 年,最强大的语言模型基于 Google 提出的序列到序列(seq2seq)架构。Seq2seq 是一种循环神经网络 (RNN)。从理论上,它很适合文本处理:一次处理一个 token,并循环更新其内部状态,这让它能处理任意长度的文本序列。通过专门的网络结构与训练,seq2seq 可以胜任多种自然语言任务:分类、实体抽取、翻译、摘要,等等。但这些模型有一个阿喀琉斯之踵 ------一个信息瓶颈限制了它们的能力。
Seq2seq 由两个主要组件构成:编码器 与解码器 (见图 1-3)。处理流程是:将一串 token 逐个送入编码器;随着 token 的输入,编码器更新一个隐藏状态向量,不断累积输入序列的信息。当最后一个 token 处理完毕,隐藏状态的最终值(即所谓的思想向量 thought vector )被送给解码器。随后解码器据此生成输出 token。问题在于,这个思想向量是固定且有限 的。对于较长的文本,它往往"遗忘"关键信息,导致解码器可用的信息不足------这正是信息瓶颈。
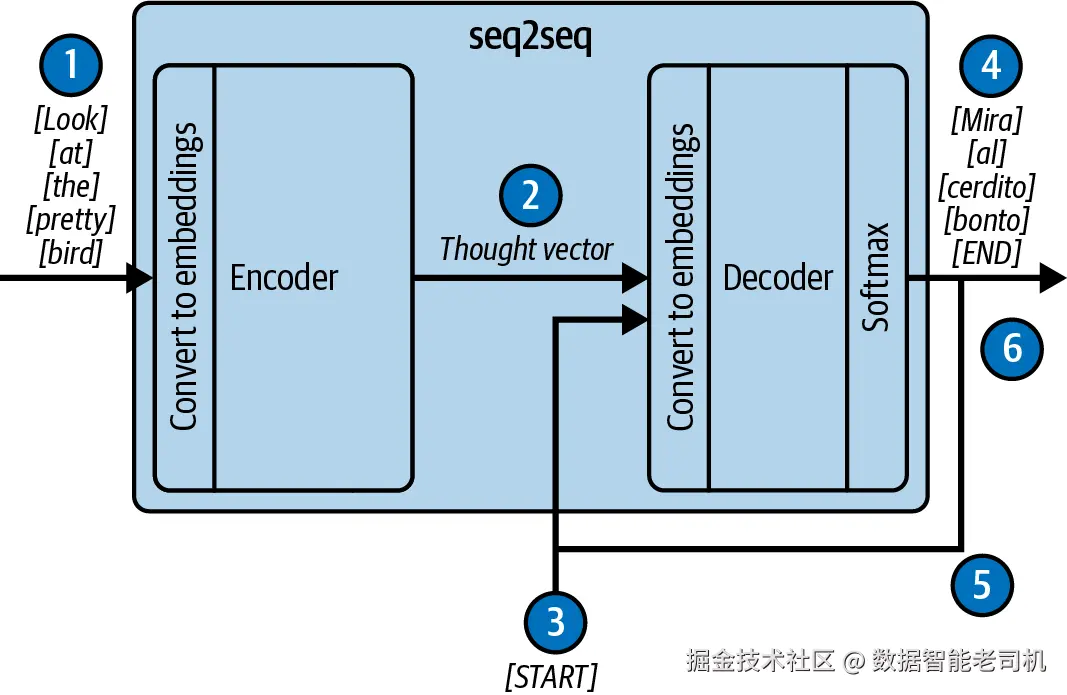
图 1-3. 一个翻译用的 seq2seq 模型
该图中的模型工作流程如下:
- 源语言的 token 逐个送入编码器并被映射为嵌入向量,同时更新编码器的内部状态。
- 内部状态被打包为思想向量并传给解码器。
- 向解码器发送一个特殊的"开始"token,指示输出序列的起点。
- 在思想向量条件下,更新解码器状态并输出目标语言的第一个 token。
- 将刚输出的 token 作为下一步的输入送回解码器;此后在第 4 步与第 5 步之间循环往复。
- 最终,解码器输出一个特殊的"结束"token,表示解码完成。受限于思想向量的容量,传给解码器的信息量也受限。
2015 年的论文《Neural Machine Translation by Jointly Learning to Align and Translate》提出了缓解该瓶颈的新方法:编码器不再只提供一个思想向量,而是保留编码过程中每个 token 所对应的全部隐藏状态向量 ,并允许解码器在这些向量上进行**"软搜索"(soft search) 。论文用英译法语模型展示了这种软搜索能显著提升翻译质量。这个软搜索技术很快以注意力机制(attention)**之名流行开来。
注意力机制很快在 AI 社区掀起热潮,并在 2017 年 Google Research 的论文《Attention Is All You Need》中达到高潮------论文提出了Transformer 架构 (见图 1-4)。Transformer 延续了高层结构:前有接收输入 token 的编码器,后有生成输出 token 的解码器。但与 seq2seq 不同的是,它移除了全部循环结构 ,而完全依赖注意力机制 。这一架构更加灵活、也更擅长对训练数据建模。不过,seq2seq 可处理任意长序列,而 Transformer 只能处理固定、有限长度的输入与输出。由于 Transformer 是 GPT 模型的直接"祖先",我们自此一直在对抗这一限制。
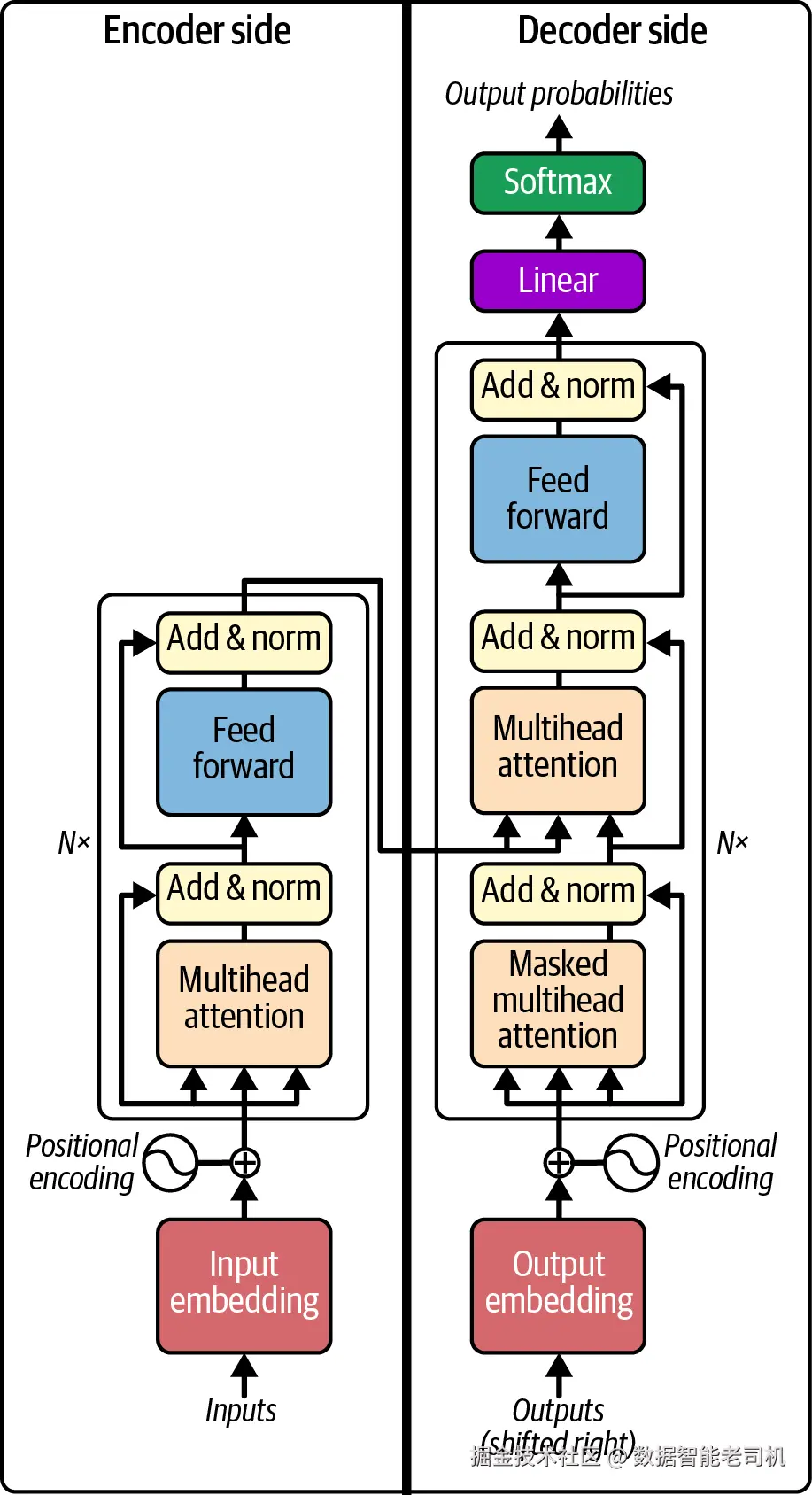
图 1-4. Transformer 架构
GPT 登场
生成式预训练 Transformer (GPT)架构诞生于 2018 年的论文《Improving Language Understanding by Generative Pre-Training》。其架构并不特别新奇:其实就是把 Transformer 的编码器"撕掉",只保留了解码器一侧。然而,正是这种简化,带来了随后几年才被充分认识到的意外可能性。正是这种 GPT 架构,引燃了随后持续至今的 AI 革命。
不过在 2018 年,这一点并不明显。当时的标准做法是:先用无标签数据(比如来自互联网的文本片段)进行预训练 ,然后修改模型架构并进行针对性微调 ,使最终模型在单一任务 上表现卓越。GPT 也是如此:论文证明了该范式在 GPT 上同样奏效------先在无标签文本上预训练,再对具体任务进行有监督微调,能在分类、文档相似度衡量、多选问答等多种任务上得到很好的效果。需要强调的是:一旦完成微调,GPT 仅在其被微调的那个任务上表现出色。
GPT-2 本质上就是放大的 GPT。2019 年推出时,研究者开始意识到 GPT 架构的不同凡响。OpenAI 介绍 GPT-2 的博文第二段就清楚地反映了这一点:
我们的模型名为 GPT-2(GPT 的继任者),它仅仅被训练来在 40GB 的互联网文本上预测下一个词。出于对该技术可能被恶意使用的担忧,我们不发布训练好的模型。
哇!怎么会把这两句话放在一起?看似无害的"预测下一个词" ------就像你在 iPhone 写短信时那样------怎么会引发如此严重的"滥用担忧"?查看对应学术论文《Language Models Are Unsupervised Multitask Learners》后答案渐明:GPT-2 具有 15 亿 参数,而 GPT 是 1.17 亿 ;它训练于 40GB 文本,而 GPT 是 4.5GB 。仅仅 在模型规模与训练集大小上做了一个数量级的提升,却带来了前所未有的"涌现"特性:很多情况下,你无需再为单一任务微调 ,直接将预训练 的模型用于任务,往往就能超越那些专门为该任务微调过的最先进模型。这包括理解歧义代词、预测文本缺词、词性标注等基准。即便在阅读理解、摘要、翻译与问答等任务上未达最强水平,GPT-2 的表现也令人惊讶地接近,并且对比对象还是那些为每个任务专门微调的模型。
那么,为何对"恶意应用"如此担忧?因为该模型已相当擅长模仿自然文本。正如 OpenAI 博文所示,这种能力可被用于"生成误导性新闻、在网上冒充他人、自动化批量生产恶意或虚假内容并发布到社交平台、以及自动化生成垃圾/钓鱼内容"。如果说 2019 年这种可能性还只是隐忧,那么今天它更真实、更令人担心。
GPT-3 再次在模型规模与训练数据上实现数量级跃升,并带来相应能力飞跃。2020 年论文《Language Models Are Few-Shot Learners》显示:只要提供少量你希望模型完成的任务样例(即"少样本(few-shot) "),模型就能忠实再现输入模式,从而完成几乎任何你能想象的基于语言的任务------而且往往质量惊人。也正是在此时我们发现:你可以通过**修改输入(提示,prompt)**来"条件化"模型,使其执行你当前需要的任务------**提示工程(prompt engineering)**自此诞生。
ChatGPT 于 2022 年 11 月发布,底座为 GPT-3.5 ------后面的故事家喻户晓!而且,这段历史仍在快速书写中(见表 1-1)。到 2023 年 3 月,GPT-4 发布;尽管细节未正式披露,但据传该模型在规模与训练数据量上再次实现数量级提升,能力亦远胜前辈。此后,更多模型接踵而至:既有 OpenAI 的新品,也有行业巨头的模型,比如 Meta 的 Llama 、Anthropic 的 Claude 、Google 的 Gemini 。我们持续看到质量飞跃,并且越来越多的更小、更快 的模型也能达到相近质量。若有定论的话,只能说:进步仍在加速。
表 1-1. GPT 系列模型细节,显示各指标呈指数式增长
| 模型 | 发布日期 | 参数量 | 训练数据 | 训练开销 |
|---|---|---|---|---|
| GPT-1 | 2018-06-11 | 1.17 亿 | BookCorpus:来自 7,000 本未出版书籍、共 4.5GB 文本 | 1.7e19 FLOP |
| GPT-2 | 2019-02-14(初版);2019-11-05(完整版) | 15 亿 | WebText:40GB 文本、8 百万文档、来自 4,500 万个被 Reddit 点赞的网页 | 1.5e21 FLOP |
| GPT-3 | 2020-05-28 | 1,750 亿 | 4,990 亿 token:包括 Common Crawl(570GB)、WebText、英文维基百科、两套书籍语料(Books1、Books2) | 3.1e23 FLOP |
| GPT-3.5 | 2022-03-15 | 1,750 亿 | 未披露 | 未披露 |
| GPT-4 | 2023-03-14 | (传闻)1.8 万亿 | (传闻)13 万亿 token | 估算 2.1e25 FLOP |
注:以上为原文所给数据与流行说法的转述;"传闻"与"估算"均沿用原文描述。
提示工程(Prompt Engineering)
现在,我们来到了你踏入提示工程世界旅程的起点。从本质上说,LLM 只擅长一件事------续写文本 。输入给模型的内容称为提示(prompt) ------它是一份文档或一段文本,我们期望模型去完成它。于是,提示工程 在最简单的形式下,就是精心撰写提示,以便其补全结果恰好包含解决当前问题所需的信息。
在本书中,我们给出一个远超"单条提示"的更宏观视角,讨论整个基于 LLM 的应用 :其中提示的构造与答案的解读都通过程序实现。为了构建高质量的软件与良好的用户体验(UX),提示工程师必须为用户、应用与 LLM 之间的迭代式沟通 设计一套模式:用户向应用表达问题;应用构造一份要发送给 LLM 的"伪文档";LLM 完成该文档;最后,应用解析补全结果,并将结论反馈给用户,或代表用户执行某项操作。提示工程的"科学与艺术"在于:把这种沟通结构化,使其能在截然不同的领域之间完成最佳转换------即用户的问题空间与 LLM 的文档空间之间的转换。
提示工程有多种复杂度层级 。最基础的形式只使用很薄的一层应用外壳。比如,当你与 ChatGPT 交互时,你几乎是在直接编写提示 ;应用层只是在把对话线程包进一种特殊的 ChatML Markdown(第 3 章会详细介绍)。类似地,GitHub Copilot 在最初做代码补全时,基本只是把当前文件传给模型去续写。
在下一个复杂度层级 ,提示工程会改写与增强 用户输入。例如,LLM 处理的是文本,因此技术支持热线可以先把用户的语音转写为文本 ,再把它放入发送给 LLM 的提示中;还可以把以往工单的相关内容或支持文档中的相关片段合并进提示 。一个真实例子是:随着 GitHub Copilot 代码补全的演进,我们意识到如果把用户相邻编辑标签页 里的相关片段纳入上下文,补全质量会显著提升------这很合理,用户既然打开了这些标签页,说明里面有其参考的信息,模型同样能从中受益。另一个例子是新版 Bing 基于聊天的搜索体验:它会把传统搜索结果的内容 拉入提示,从而让助理能讨论训练数据中没有的信息(例如模型训练完成之后才发生的事件)。更重要的是,这种方法有助于 Bing 降低幻觉(hallucination) ------我们会在本书多次回到这个话题,从下一章就开始。
在该层级里,提示工程的另一个方面是让与 LLM 的交互具备状态(stateful) ------也就是保留先前交互的上下文与信息 。聊天应用是典型示例:每当用户发来新消息,应用都必须回忆 先前的互动,并生成一个忠实反映对话历史 的提示。随着对话/历史变长,你需要小心不要塞满提示 或引入无关噪声 ,以免分散模型注意力。你可能会选择丢弃最早 或不太相关 的对话片段,甚至使用摘要来压缩内容。
在这个复杂度层级中,提示工程还有一项关键实践:为 LLM 应用配置工具(tools) ,使 LLM 能通过API 调用 触达现实世界,读取信息,或在互联网上创建/修改资产。比如,一个基于 LLM 的邮件应用收到用户输入:"给 Diane 发一个 5 月 5 日的会议邀请。"该应用可先用一个工具在联系人中识别 Diane ,再用日历 API 查询她的空闲时段,最后发出邮件邀请 。随着模型变得更廉价 且更强大 ,仅凭我们今天手边已有的 API,就能想象出无数可能!但此处提示工程至关重要 :模型如何知道用哪个工具 ?如何以正确方式 使用它?你的应用又如何把工具执行的结果 正确地回填给模型?当工具调用出错时怎么办?我们将在第 8 章详细讨论这些问题。
本书覆盖的最高复杂度层级 是:如何赋予 LLM 应用代理能力(agency) ------让它能围绕用户给出的宏大目标自主决策 、自主规划 完成路径。这显然处在我们当前能力的前沿,但研究与实作探索已在进行中。如今你已经可以下载 AutoGPT ,给它一个目标,它就会启动一个多步骤流程 去收集实现目标所需的信息。它总是成功吗?不会 。事实上,除非目标足够收敛,它往往失败多于成功 。但给 LLM 应用一些形式的能动与自治,仍是通往更激动人心未来可能性的关键一步。我们会在第 8 和第 9 章阐述我们的看法。
结论
正如开头所说,本章为你即将踏上的提示工程之旅 奠定了背景。我们首先回顾了语言模型的近期发展史,强调了 LLM 的独特之处与它们为何推动着我们所见的 AI 革命。随后,我们定义了本书的主题:提示工程。
需要特别理解的是:本书并非只教你如何对单条提示的措辞 吹毛求疵以获得一次"好补全"。当然,我们会覆盖这一点,并详细介绍如何生成高质量、能达成目标 的补全。但当我们说"提示工程"时,我们指的是构建整个基于 LLM 的应用 。LLM 应用充当一个转换层 :以迭代且有状态 的方式,把现实世界的需求转换成 LLM 能处理的文本,再把 LLM 给出的数据转化为真正解决现实需求的信息与行动。
在启程之前,让我们确认装备齐全。下一章,你将自上而下了解 LLM 文本补全 的工作机理------从高级 API 到底层注意力机制 。再下一章,我们会在此基础上解释 LLM 如何扩展到聊天 与工具使用 ;你会看到,在本质深处,这仍旧是同一件事------文本补全。有了这些基础观念,你就准备好踏上旅程了。