英文原地址:Chapter 6: Planning
智能行为往往不仅仅是对即时输入作出反应。它需要前瞻性,将复杂任务拆解为更小、可管理的步骤,并制定实现期望结果的策略。这正是"规划"模式发挥作用的地方。本质上,规划是指智能体或智能体系统制定一系列行动,从初始状态朝目标状态前进的能力。
概述
在人工智能的语境中,把规划型智能体视为你将复杂目标委托给的一位专家会更有帮助。当你让它"组织一次团队团建",你定义的是"做什么"------目标及其约束------而不是"如何做"。该智能体的核心任务是自主规划通往该目标的路径。它必须首先理解初始状态(例如预算、参与人数、期望日期)和目标状态(一次成功预订的团建活动),然后找出将二者连接起来的最优行动序列。计划并非事先已知;而是对请求作出的响应中被创建出来的。
这一过程的标志在于适应性。初始计划只是起点,而非僵化的剧本。智能体的真正力量在于其整合新信息并引导项目绕开障碍的能力。比如,如果首选场地突然不可用,或选定的餐饮供应商已经被预订满,一名有能力的智能体不会就此失败。它会进行调整。它记录新的约束,重新评估选项,并制定新的计划,比如建议替代的场地或日期。
然而,必须认识到灵活性与可预测性之间的权衡。动态规划是一种特定的工具,而非万能解。当某个问题的解决方案已被充分理解且可重复时,将智能体约束在预先设定的固定工作流程中更为有效。这种做法限制智能体的自主性,以降低不确定性和不可预测行为的风险,从而确保可靠且一致的结果。因此,选择使用规划型智能体还是简单的任务执行型智能体,取决于一个问题:是需要发现"如何做",还是已经知道"如何做"?
实际应用与使用场景
规划模式是自主系统中的核心计算过程,使智能体能够综合一系列行动以实现特定目标,尤其是在动态或复杂环境中。该过程将高层目标转化为由离散且可执行步骤组成的结构化计划。
在诸如流程化任务自动化等领域中,规划被用于编排复杂的工作流。比如,将新员工入职这样的业务流程分解为有向的子任务序列,如创建系统账户、分配培训模块以及与不同部门协调。智能体会生成一个以逻辑顺序执行这些步骤的计划,并调用必要的工具或与各类系统交互以管理依赖关系。
在机器人和自主导航领域,规划是进行状态空间遍历的基础。系统------无论是实体机器人还是虚拟实体------都必须生成一条路径或一系列动作,以从初始状态过渡到目标状态。这涉及在遵守环境约束(例如避开障碍物或遵循交通法规)的同时,优化时间或能耗等指标。
这种模式对结构化信息综合同样至关重要。当需要生成诸如研究报告等复杂输出时,智能体可以制定一个包含信息收集、数据摘要、内容结构化以及迭代完善等不同阶段的计划。类似地,在涉及多步骤问题解决的客户支持场景中,智能体可以创建并遵循一个用于诊断、解决方案实施和升级处理的系统化计划。
本质上,规划模式使智能体能够超越简单的、反应式的动作,转向以目标为导向的行为。它提供了解决需要连贯且相互依赖的一系列操作的问题所必需的逻辑框架。
实战代码示例(Crew AI)
以下部分将展示使用 Crew AI 框架实现 Planner 模式的示例。该模式包含一个智能体,它会先为复杂查询制定一个多步骤计划,然后按顺序执行该计划。
python
import os
from dotenv import load_dotenv
from crewai import Agent, Task, Crew, Process
from langchain_openai import ChatOpenAI
# Load environment variables from .env file for security
load_dotenv()
# 1. Explicitly define the language model for clarity
llm = ChatOpenAI(model="gpt-4-turbo")
# 2. Define a clear and focused agent
planner_writer_agent = Agent(
role='Article Planner and Writer',
goal='Plan and then write a concise, engaging summary on a specified topic.',
backstory=(
'You are an expert technical writer and content strategist. '
'Your strength lies in creating a clear, actionable plan before writing, '
'ensuring the final summary is both informative and easy to digest.'
),
verbose=True,
allow_delegation=False,
llm=llm # Assign the specific LLM to the agent
)
# 3. Define a task with a more structured and specific expected output
topic = "The importance of Reinforcement Learning in AI"
high_level_task = Task(
description=(
f"1. Create a bullet-point plan for a summary on the topic: '{topic}'.\n"
f"2. Write the summary based on your plan, keeping it around 200 words."
),
expected_output=(
"A final report containing two distinct sections:\n\n"
"### Plan\n"
"- A bulleted list outlining the main points of the summary.\n\n"
"### Summary\n"
"- A concise and well-structured summary of the topic."
),
agent=planner_writer_agent,
)
# Create the crew with a clear process
crew = Crew(
agents=[planner_writer_agent],
tasks=[high_level_task],
process=Process.sequential,
)
# Execute the task
print("## Running the planning and writing task ##")
result = crew.kickoff()
print("\n\n---\n## Task Result ##\n---")
print(result)这段代码使用 CrewAI 库创建一个能够对给定主题进行规划并撰写摘要的 AI 智能体。它首先导入必要的库,包括 Crew.ai 和 langchain_openai,并从 .env 文件加载环境变量。为该智能体显式定义了一个 ChatOpenAI 语言模型。创建了一个名为 planner_writer_agent 的智能体,赋予了特定的角色与目标:先规划再撰写简明摘要。该智能体的背景故事强调其在规划与技术写作方面的专长。定义了一个 Task,明确要求先创建计划,再就主题"The importance of Reinforcement Learning in AI"撰写摘要,并对预期输出的格式作出具体规定。随后组建了一个包含该智能体与任务的 Crew,并设置为按顺序处理。最后调用 crew.kickoff() 方法执行定义的任务,并打印结果。
Google DeepResearch
Google Gemini DeepResearch(见图 1)是一种基于智能体的系统,旨在实现自主的信息检索与综合。它通过一个多步骤的智能体流水线运作,动态且迭代地查询 Google 搜索,以系统性地探索复杂主题。该系统旨在处理大量基于网页的来源,评估收集到的数据的相关性与知识空白,并执行后续检索以加以弥补。最终输出将经过核验的信息整合为带有原始来源引用的结构化多页摘要。
进一步而言,该系统的运行并非一次性的查询-响应事件,而是一个受控的、长时间运行的过程。它首先将用户的提示分解为一个多点的研究计划(见图 1),随后呈现给用户以供审阅与修改。这样便可在执行前以协作方式塑造研究轨迹。一旦计划获批,智能体流水线便启动其迭代的搜索与分析循环。这不仅仅是执行一系列预定义的搜索;智能体会根据收集到的信息动态地制定并优化其查询,主动识别知识空白、核实数据点并解决不一致之处。
图 1:Google Deep Research 智能体生成使用 Google 搜索作为工具的执行计划 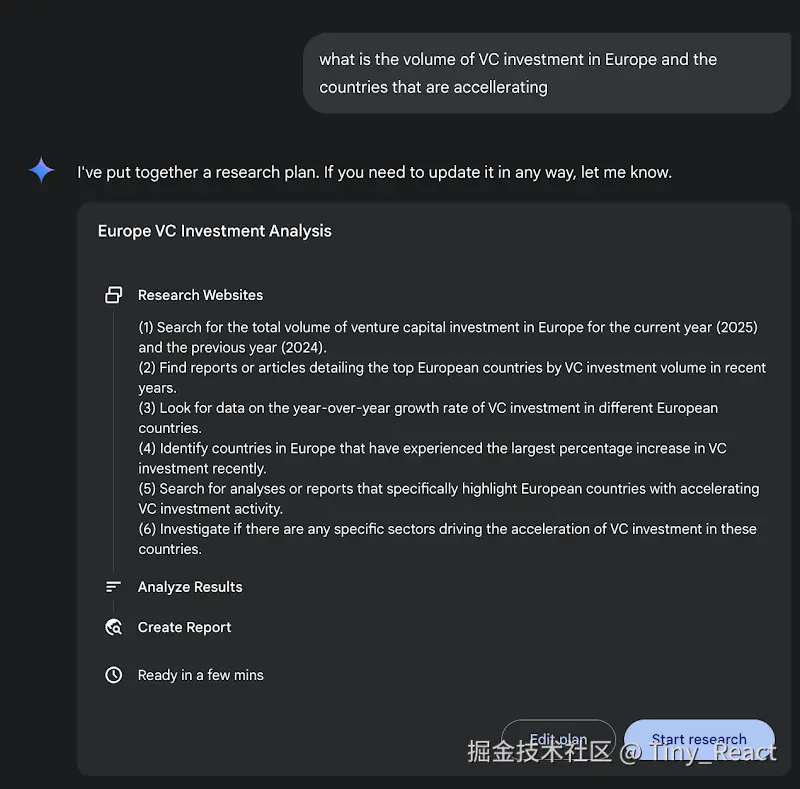
一个关键的架构组件是系统能够以异步方式管理这一流程。该设计确保调查过程(可能涉及分析数百个来源)对单点故障具备韧性,并允许用户在过程中退出并在完成时收到通知。系统还可以整合用户提供的文档,将私有来源的信息与其基于网络的研究相结合。最终输出不只是发现的简单拼接列表,而是一份结构化的多页报告。在综合阶段,模型会对收集到的信息进行关键性评估,识别主要主题,并将内容组织成具有逻辑分节的连贯叙事。该报告被设计为可交互的,通常包含音频概览、图表以及指向原始引用来源的链接等功能,便于用户进行验证和进一步探索。除了综合结果之外,模型还会明确返回其搜索和参考的完整来源列表(见图 2)。这些以引文的形式呈现,提供完全透明度并可直接访问原始信息。 这一整个过程将一个简单查询转化为一套全面且经过综合的知识体系。
图 2:Deep Research 计划执行的示例,结果显示使用 Google 搜索作为工具检索各类网络来源。 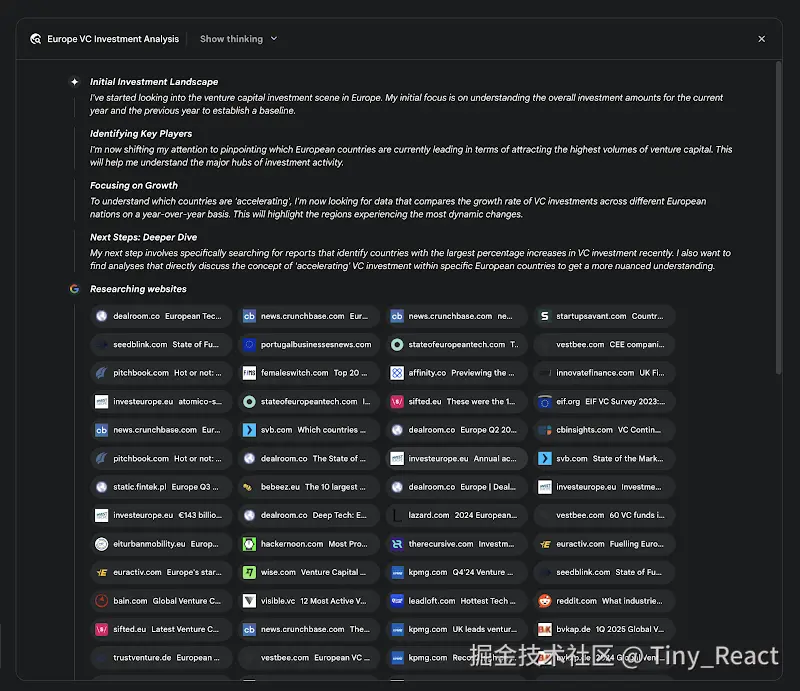
通过降低手动获取与综合数据所需的大量时间与资源投入,Gemini DeepResearch 提供了一种更有条理且更全面的信息发现方法。该系统的价值在跨领域的复杂、多层面研究任务中尤为显著。
例如,在竞品分析中,可以指导智能体系统有条不紊地收集并整理市场趋势、竞争对手产品规格、来自多种在线来源的公众舆论,以及营销策略等数据。该自动化流程取代了人工跟踪多个竞争对手的繁重工作,使分析师能够将精力集中于更高层次的战略性解读,而非数据收集(见图 3)。
图 3:由 Google Deep Research 智能体生成的最终输出,代表我们使用 Google 搜索作为工具获取来源并进行分析。 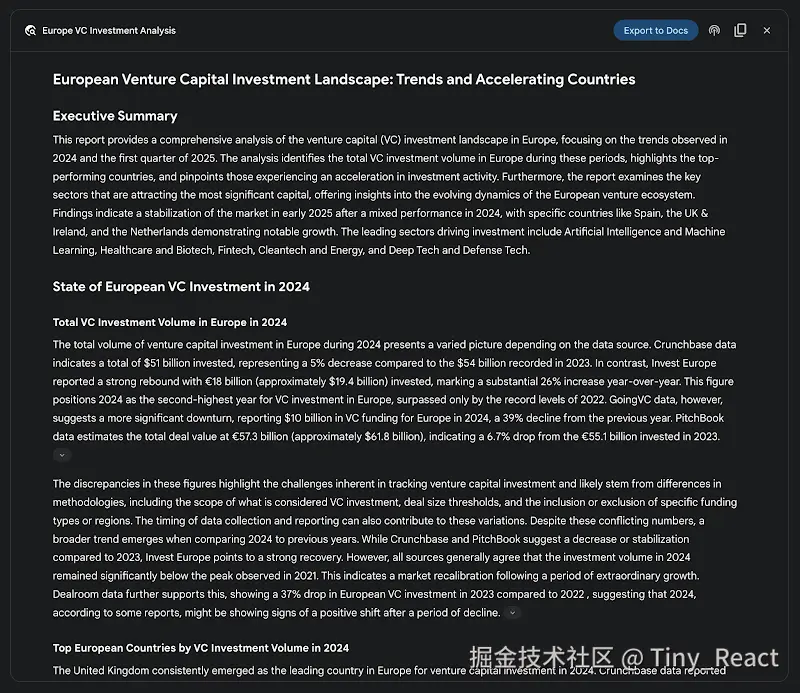
同样地,在学术探索中,该系统是开展广泛文献综述的强大工具。它能够识别并总结奠基性论文,追踪概念在众多出版物中的发展脉络,并绘制特定领域内新兴研究前沿,从而加速学术研究中最初且最耗时的阶段。
这种方法的效率源自对迭代式"搜索---筛选"循环的自动化,而这正是人工研究的核心瓶颈。系统通过处理比人类研究者在相当时间内通常可掌握的更大量与更多样的信息来源来实现全面性。更广的分析范围有助于降低选择偏差的可能性,并提高发现不那么显而易见但可能至关重要信息的概率,从而对研究对象形成更稳健且有充分支持的理解。
OpenAI Deep Research API
OpenAI Deep Research API 是一款专门用于自动化复杂研究任务的工具。它使用先进的智能体模型,能够独立进行推理、规划,并从真实世界的来源中综合信息。不同于简单的问答模型,它可以接收一个高层次的查询,自动将其分解为子问题,使用内置工具执行网页搜索,并输出结构化、引用充分的最终报告。该 API 提供对整个过程的直接编程访问,在撰写时使用诸如 o3-deep-research-2025-06-26 之类的模型进行高质量综合,以及更快的 o4-mini-deep-research-2025-06-26 模型用于对延迟敏感的应用。。
Deep Research API 的价值在于,它能够自动化原本需要数小时的手动研究工作,输出专业级、数据驱动的报告,可用于制定业务战略、投资决策或政策建议。其主要优势包括:
- 结构化、带引用的输出: 它生成组织良好的报告,包含链接至来源元数据的内联引用,确保论断可被验证并有数据支持。
- 透明性: 不同于 ChatGPT 中被抽象化的流程,API 会公开所有中间步骤,包括智能体的推理、其执行的具体网页搜索查询以及运行过的任何代码。这使得详细调试、分析以及更深入地理解最终答案的构建过程成为可能。
- 可扩展性: 它支持 Model Context Protocol(MCP),使开发者能够将智能体连接到私有知识库和内部数据源,将公共的网页研究与专有信息相融合。
要使用该 API,你需要向 client.responses.create 端点发送请求,指定模型、输入提示词以及智能体可用的工具。输入通常包括定义智能体人设和期望输出格式的 system_message,以及 user_query。你还必须包含 web_search_preview 工具,并可选地添加诸如 code_interpreter 或自定义 MCP 工具(参见第 10 章)以访问内部数据。
python
from openai import OpenAI
# Initialize the client with your API key
client = OpenAI(api_key="YOUR_OPENAI_API_KEY")
# Define the agent's role and the user's research question
system_message = """You are a professional researcher preparing a structured, data-driven report.
Focus on data-rich insights, use reliable sources, and include inline citations."""
user_query = "Research the economic impact of semaglutide on global healthcare systems."
# Create the Deep Research API call
response = client.responses.create(
model="o3-deep-research-2025-06-26",
input=[
{
"role": "developer",
"content": [{"type": "input_text", "text": system_message}]
},
{
"role": "user",
"content": [{"type": "input_text", "text": user_query}]
}
],
reasoning={"summary": "auto"},
tools=[{"type": "web_search_preview"}]
)
# Access and print the final report from the response
final_report = response.output[-1].content[0].text
print(final_report)
# --- ACCESS INLINE CITATIONS AND METADATA ---
print("--- CITATIONS ---")
annotations = response.output[-1].content[0].annotations
if not annotations:
print("No annotations found in the report.")
else:
for i, citation in enumerate(annotations):
# The text span the citation refers to
cited_text = final_report[citation.start_index:citation.end_index]
print(f"Citation {i+1}:")
print(f" Cited Text: {cited_text}")
print(f" Title: {citation.title}")
print(f" URL: {citation.url}")
print(f" Location: chars {citation.start_index}--{citation.end_index}")
print("\n" + "="*50 + "\n")
# --- INSPECT INTERMEDIATE STEPS ---
print("--- INTERMEDIATE STEPS ---")
# 1. Reasoning Steps: Internal plans and summaries generated by the model.
try:
reasoning_step = next(item for item in response.output if item.type == "reasoning")
print("\n[Found a Reasoning Step]")
for summary_part in reasoning_step.summary:
print(f" - {summary_part.text}")
except StopIteration:
print("\nNo reasoning steps found.")
# 2. Web Search Calls: The exact search queries the agent executed.
try:
search_step = next(item for item in response.output if item.type == "web_search_call")
print("\n[Found a Web Search Call]")
print(f" Query Executed: '{search_step.action['query']}'")
print(f" Status: {search_step.status}")
except StopIteration:
print("\nNo web search steps found.")
# 3. Code Execution: Any code run by the agent using the code interpreter.
try:
code_step = next(item for item in response.output if item.type == "code_interpreter_call")
print("\n[Found a Code Execution Step]")
print(" Code Input:")
print(f" ```python\n{code_step.input}\n ```")
print(" Code Output:")
print(f" {code_step.output}")
except StopIteration:
print("\nNo code execution steps found.")此代码片段利用 OpenAI API 执行"深度调研"任务。它首先使用你的 API 密钥初始化 OpenAI 客户端,这是进行身份验证的关键步骤。然后,它将 AI 智能体的角色设定为专业研究员,并设置用户关于 semaglutide 经济影响的研究问题。代码构造对 o3-deep-research-2025-06-26 模型的 API 调用,提供预设的 system 消息和用户查询作为输入。同时,它请求自动生成推理摘要并启用网页搜索功能。在完成 API 调用后,代码会提取并打印最终生成的报告。
随后,代码尝试从报告的注释中访问并展示内联引用和元数据,包括被引用的文本、标题、URL,以及在报告中的位置。最后,它检查并打印模型执行过程中间步骤的详细信息,例如推理步骤、网页搜索调用(包括所执行的查询),以及在使用代码解释器时的任何代码执行步骤。
回顾
是什么(What)
复杂问题往往无法通过单一动作解决,需要前瞻性才能达成预期结果。没有结构化的方法,智能体系统在处理包含多步骤和依赖关系的多面向请求时会举步维艰。这使得将高层目标分解为一系列可管理的、更小且可执行的任务变得困难。结果是,系统难以有效制定策略,在面对复杂目标时容易产生不完整或不正确的结果。
为什么(Why)
规划模式通过让智能体系统首先制定一个连贯的计划来达成目标,提供了一种标准化的解决方案。它将高层目标分解为一系列更小、可执行的步骤或子目标。这使系统能够管理复杂的工作流、编排各种工具,并按逻辑顺序处理依赖关系。LLMs 尤其适合此类任务,因为它们可以基于其庞大的训练数据生成合理且有效的计划。这种结构化方法将一个简单的反应式智能体转变为战略型执行者,使其能够主动朝复杂目标推进,并在必要时调整其计划。
经验法则(Rule of Thumb)
当用户的请求过于复杂,无法由单一操作或工具处理时,使用此模式。它非常适合自动化多步骤流程,例如生成详细的研究报告、为新员工办理入职手续或执行竞品分析。只要任务需要一系列相互依赖的操作来达成最终的综合结果,就应用"规划"模式。
规划设计模式 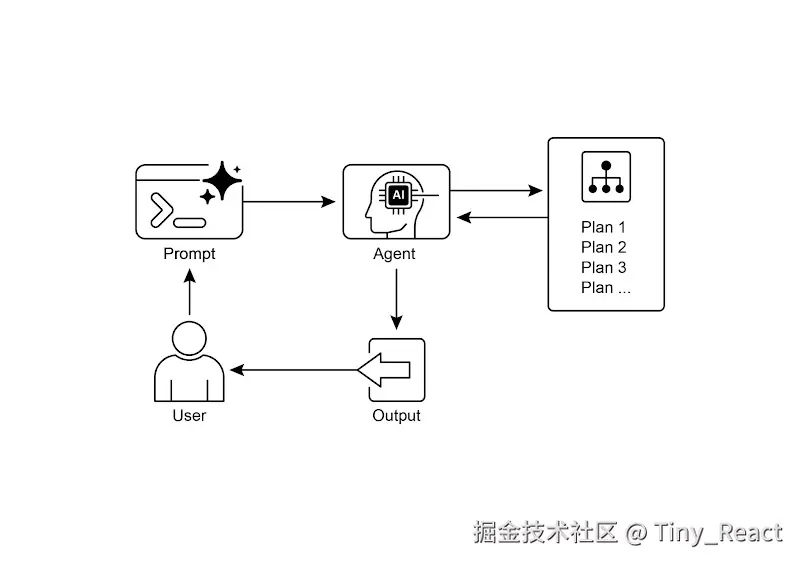
关键点
- 规划使智能体能够将复杂目标分解为可执行的、按顺序进行的步骤。
- 它对于处理多步骤任务、工作流程自动化以及在复杂环境中导航至关重要。
- LLMs 可以根据任务描述生成分步方案来执行规划。
- 在提示中明确要求或在任务设计中加入需要规划的步骤,会在智能体框架中鼓励这种行为。
- Google Deep Research 是一个智能体,它使用 Google 搜索作为工具来获取来源,并代表我们进行分析。它会进行反思、规划和执行。
总结
总之,规划模式是一个基础性组件,它将智能体系统从简单的被动响应者提升为具有战略性的、以目标为导向的执行者。现代大型语言模型为此提供了核心能力,能够自主地将高层次目标分解为连贯且可执行的步骤。该模式既适用于直接的、顺序式的任务执行(如 CrewAI 智能体创建并遵循写作计划所示),也可扩展到更复杂与动态的系统。Google 的 DeepResearch 智能体体现了这一高级应用,它会创建迭代式研究计划,并根据持续的信息收集进行自适应和演化。归根结底,规划为处理复杂问题在人类意图与自动化执行之间提供了关键桥梁。通过结构化的问题求解方法,此模式使智能体能够管理复杂的工作流,并交付全面、综合的成果。
参考资料
- Google DeepResearch (Gemini Feature): gemini.google.com
- OpenAI ,Introducing deep research openai.com/index/intro...
- Perplexity, Introducing Perplexity Deep Research, www.perplexity.ai/hub/blog/in...