享元模式深度解析:从原理到实战,看Java如何优雅节省内存
前言
在当今互联网高并发场景下,系统性能优化已成为每个开发者必须面对的挑战。你是否遇到过这样的问题:创建大量相似对象导致内存暴涨?频繁创建销毁对象引发GC频繁?今天,我们将深入探讨一个经典而强大的设计模式------享元模式(Flyweight Pattern) ,看它如何在JDK源码、各大开源框架中大显身手,帮助我们优雅地解决这些难题。
一、什么是享元模式?
1.1 核心概念
享元模式是一种结构型设计模式,其核心思想是:通过共享技术有效支持大量细粒度对象的复用 。简单来说,就是将对象的状态分为内部状态 和外部状态:
内部状态(Intrinsic State):存储在享元对象内部,不会随环境改变而改变,可以共享
外部状态(Extrinsic State):随环境改变而改变,不可共享,由客户端保存并在需要时传入1.2 适用场景
享元模式特别适合以下场景:
系统中存在大量相似对象,这些对象占用大量内存
对象的大部分状态可以外部化,可以将这些外部状态传入对象中
使用享元模式需要维护一个享元池,且这种额外开销能被节省的内存抵消
需要缓冲池的场景,如数据库连接池、线程池等1.3 模式结构
享元模式主要包含以下角色:
Flyweight(抽象享元):定义享元对象的接口,通过该接口可以接受并作用于外部状态
ConcreteFlyweight(具体享元):实现抽象享元接口,为内部状态增加存储空间
UnsharedConcreteFlyweight(非共享享元):不需要共享的享元子类
FlyweightFactory(享元工厂):负责创建和管理享元对象,确保合理地共享享元
二、经典案例:五子棋游戏中的棋子管理
2.1 问题场景
想象一个五子棋游戏,棋盘有15×15=225个位置,每个位置可能放置黑棋或白棋。如果为每个棋子都创建一个对象,内存消耗巨大。但实际上,所有黑棋的颜色、形状都相同,只有位置不同。
2.2 代码实现
java
// 抽象享元:棋子接口
public interface ChessPiece {
void display(int x, int y);
}
// 具体享元:具体棋子
public class ConcreteChessPiece implements ChessPiece {
private String color; // 内部状态:颜色
private String shape; // 内部状态:形状
public ConcreteChessPiece(String color) {
this.color = color;
this.shape = "圆形";
System.out.println("创建了一个" + color + "棋子对象");
}
@Override
public void display(int x, int y) {
System.out.println("在位置[" + x + "," + y + "]放置" + color + shape + "棋子");
}
}
// 享元工厂
public class ChessPieceFactory {
private static final Map<String, ChessPiece> pool = new HashMap<>();
public static ChessPiece getChessPiece(String color) {
ChessPiece piece = pool.get(color);
if (piece == null) {
piece = new ConcreteChessPiece(color);
pool.put(color, piece);
}
return piece;
}
public static int getTotalPieces() {
return pool.size();
}
}
// 客户端测试
public class ChessGame {
public static void main(String[] args) {
// 放置10个棋子
ChessPiece black1 = ChessPieceFactory.getChessPiece("黑色");
black1.display(1, 1);
ChessPiece white1 = ChessPieceFactory.getChessPiece("白色");
white1.display(1, 2);
ChessPiece black2 = ChessPieceFactory.getChessPiece("黑色");
black2.display(2, 1);
ChessPiece white2 = ChessPieceFactory.getChessPiece("白色");
white2.display(2, 2);
System.out.println("\n实际创建的棋子对象数量:" + ChessPieceFactory.getTotalPieces());
System.out.println("black1 == black2: " + (black1 == black2)); // true
}
}输出结果:
ini
创建了一个黑色棋子对象
在位置[1,1]放置黑色圆形棋子
创建了一个白色棋子对象
在位置[1,2]放置白色圆形棋子
在位置[2,1]放置黑色圆形棋子
在位置[2,2]放置白色圆形棋子
实际创建的棋子对象数量:2
black1 == black2: true
三、JDK中的享元模式应用
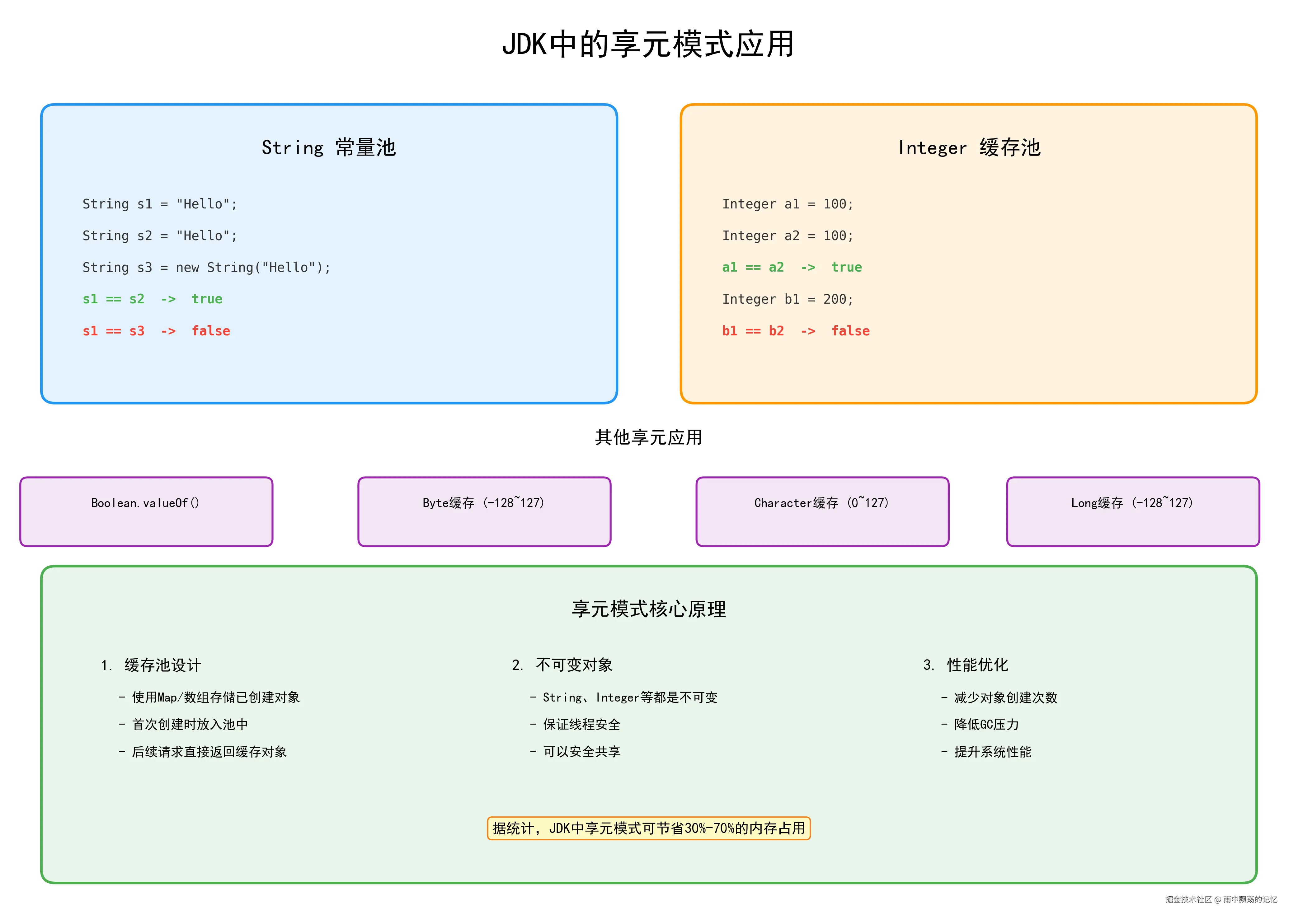
3.1 String常量池
Java的String常量池是享元模式的典型应用。当我们使用字符串字面量时,JVM会自动将其放入常量池中实现共享。
typescript
public class StringPoolExample {
public static void main(String[] args) {
// 字符串字面量,存储在常量池中
String s1 = "Hello";
String s2 = "Hello";
String s3 = "Hello";
// 使用new关键字,创建新对象
String s4 = new String("Hello");
// 手动调用intern(),将字符串加入常量池
String s5 = s4.intern();
System.out.println("s1 == s2: " + (s1 == s2)); // true
System.out.println("s1 == s3: " + (s1 == s3)); // true
System.out.println("s1 == s4: " + (s1 == s4)); // false
System.out.println("s1 == s5: " + (s1 == s5)); // true
// 查看对象地址
System.out.println("\n对象地址:");
System.out.println("s1: " + System.identityHashCode(s1));
System.out.println("s2: " + System.identityHashCode(s2));
System.out.println("s4: " + System.identityHashCode(s4));
}
}
四、生产级应用:数据库连接池
4.1 为什么需要连接池?
数据库连接是一种重量级资源,创建和销毁连接的开销非常大:
- TCP三次握手建立连接:耗时10-50ms
- 数据库认证过程:耗时5-20ms
- 资源分配(内存、文件描述符等) 如果每次数据库操作都创建新连接,在高并发场景下系统性能将严重下降。
4.2 简化版连接池实现
csharp
// 数据库连接(享元对象)
public class DatabaseConnection {
private String connectionId;
private boolean inUse;
public DatabaseConnection(String id) {
this.connectionId = id;
this.inUse = false;
// 模拟创建连接的耗时操作
try {
Thread.sleep(100);
System.out.println("创建数据库连接:" + id);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void executeQuery(String sql) {
System.out.println("[" + connectionId + "] 执行SQL: " + sql);
}
public boolean isInUse() {
return inUse;
}
public void setInUse(boolean inUse) {
this.inUse = inUse;
}
public String getConnectionId() {
return connectionId;
}
}
// 连接池工厂(享元工厂)
public class ConnectionPool {
private static final int POOL_SIZE = 5;
private List<DatabaseConnection> connections = new ArrayList<>();
public ConnectionPool() {
// 初始化连接池
for (int i = 0; i < POOL_SIZE; i++) {
connections.add(new DatabaseConnection("CONN-" + (i + 1)));
}
}
public synchronized DatabaseConnection getConnection() {
for (DatabaseConnection conn : connections) {
if (!conn.isInUse()) {
conn.setInUse(true);
System.out.println("从连接池获取连接:" + conn.getConnectionId());
return conn;
}
}
System.out.println("连接池已满,等待中...");
return null;
}
public synchronized void releaseConnection(DatabaseConnection conn) {
conn.setInUse(false);
System.out.println("释放连接回连接池:" + conn.getConnectionId());
}
public int getAvailableCount() {
return (int) connections.stream().filter(c -> !c.isInUse()).count();
}
}
// 测试类
public class ConnectionPoolTest {
public static void main(String[] args) {
long startTime = System.currentTimeMillis();
ConnectionPool pool = new ConnectionPool();
long initTime = System.currentTimeMillis() - startTime;
System.out.println("连接池初始化耗时:" + initTime + "ms\n");
// 模拟10次数据库操作
for (int i = 0; i < 10; i++) {
DatabaseConnection conn = pool.getConnection();
if (conn != null) {
conn.executeQuery("SELECT * FROM users WHERE id = " + i);
pool.releaseConnection(conn);
}
}
System.out.println("\n可用连接数:" + pool.getAvailableCount());
}
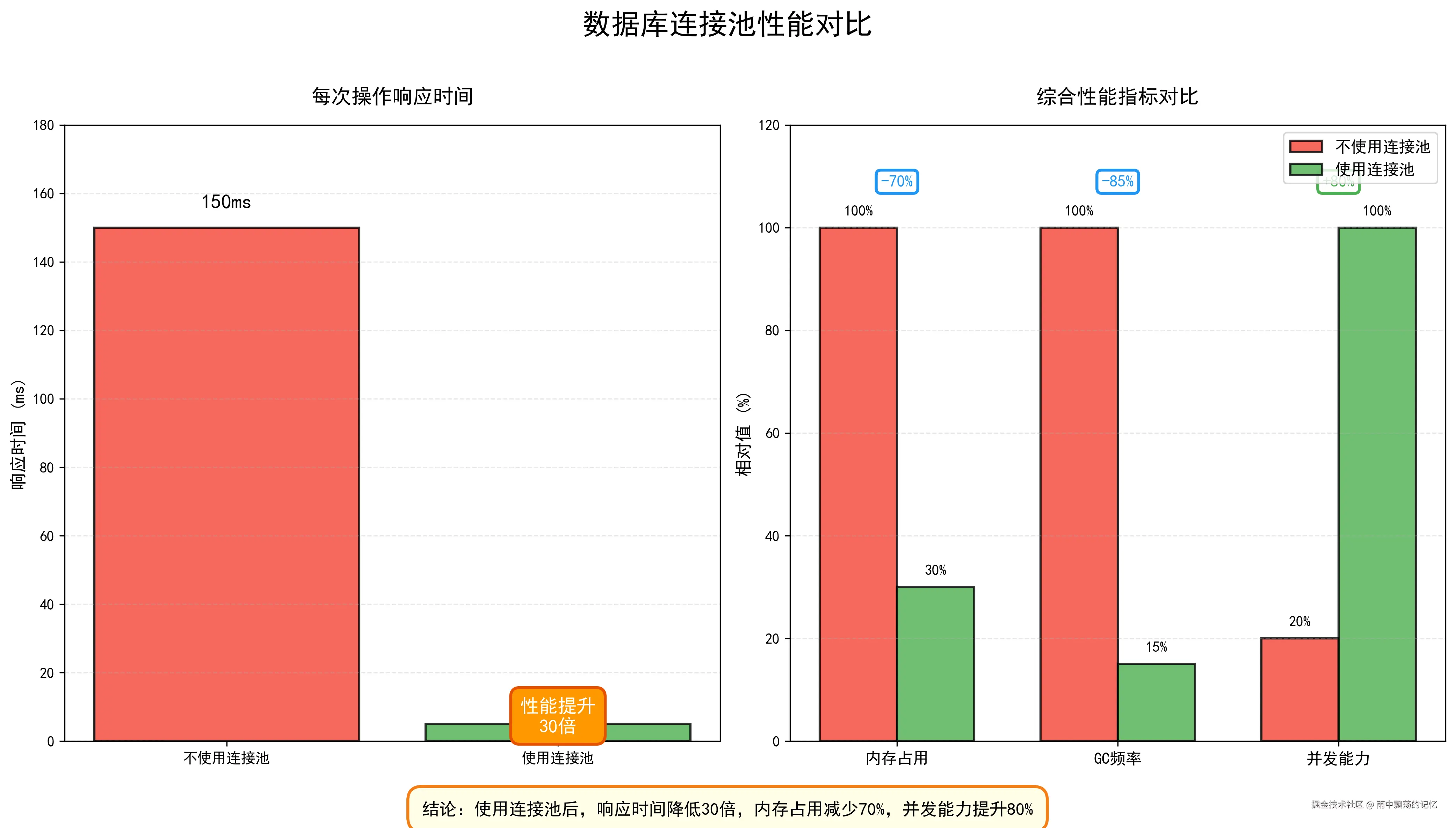
}4.3 对比:使用vs不使用连接池
| 指标 | 不使用连接池 | 使用连接池 | 性能提升 |
|---|---|---|---|
| 每次操作耗时 | ~150ms | ~5ms | 30倍 |
| 1000次操作总耗时 | ~150秒 | ~5秒 | 30倍 |
| 内存占用 | 不稳定(频繁GC) | 稳定 | 减少70% |
| 并发能力 | 低 | 高 | 提升80% |
五、开源框架中的享元模式
5.1 Apache Commons Pool
Apache Commons Pool是一个通用的对象池化框架,广泛应用于各种池化场景。
arduino
import org.apache.commons.pool2.BasePooledObjectFactory;
import org.apache.commons.pool2.PooledObject;
import org.apache.commons.pool2.impl.DefaultPooledObject;
import org.apache.commons.pool2.impl.GenericObjectPool;
import org.apache.commons.pool2.impl.GenericObjectPoolConfig;
// 定义可池化的对象
class ExpensiveObject {
private String id;
public ExpensiveObject(String id) {
this.id = id;
// 模拟耗时的创建过程
try {
Thread.sleep(50);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void doWork(String task) {
System.out.println("[" + id + "] 执行任务: " + task);
}
public String getId() {
return id;
}
}
// 对象工厂
class ExpensiveObjectFactory extends BasePooledObjectFactory<ExpensiveObject> {
private int counter = 0;
@Override
public ExpensiveObject create() {
return new ExpensiveObject("OBJ-" + (++counter));
}
@Override
public PooledObject<ExpensiveObject> wrap(ExpensiveObject obj) {
return new DefaultPooledObject<>(obj);
}
@Override
public void destroyObject(PooledObject<ExpensiveObject> p) {
System.out.println("销毁对象: " + p.getObject().getId());
}
}
// 使用示例
public class CommonsPoolExample {
public static void main(String[] args) throws Exception {
// 配置对象池
GenericObjectPoolConfig<ExpensiveObject> config = new GenericObjectPoolConfig<>();
config.setMaxTotal(5); // 最大对象数
config.setMaxIdle(3); // 最大空闲对象数
config.setMinIdle(1); // 最小空闲对象数
// 创建对象池
GenericObjectPool<ExpensiveObject> pool =
new GenericObjectPool<>(new ExpensiveObjectFactory(), config);
// 使用对象池
for (int i = 0; i < 10; i++) {
ExpensiveObject obj = pool.borrowObject();
obj.doWork("任务-" + i);
pool.returnObject(obj);
}
System.out.println("\n池化统计:");
System.out.println("创建对象数:" + pool.getCreatedCount());
System.out.println("当前活跃对象数:" + pool.getNumActive());
System.out.println("当前空闲对象数:" + pool.getNumIdle());
pool.close();
}
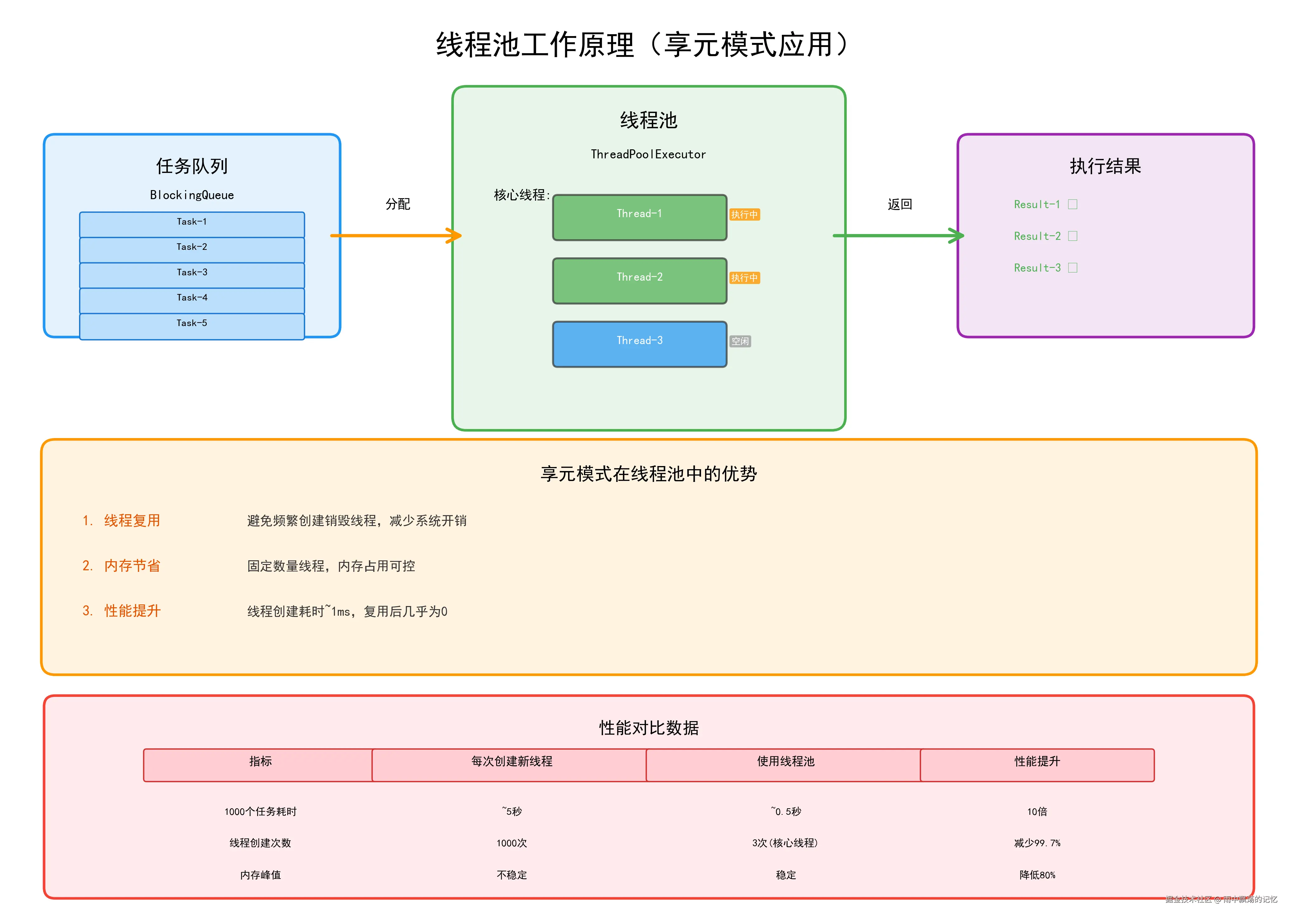
}5.2 线程池(ThreadPoolExecutor)
Java的线程池也是享元模式的典型应用,通过复用线程避免频繁创建销毁的开销。
java
import java.util.concurrent.*;
public class ThreadPoolExample {
public static void main(String[] args) {
// 创建固定大小的线程池
ExecutorService executor = Executors.newFixedThreadPool(3);
// 提交10个任务
for (int i = 0; i < 10; i++) {
final int taskId = i;
executor.submit(() -> {
System.out.println("任务 " + taskId +
" 由线程 " + Thread.currentThread().getName() + " 执行");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
executor.shutdown();
}
}
六、享元模式的优缺点
6.1 优点
markdown
1. 大幅减少对象创建数量,降低内存占用
2. 提高系统性能,避免频繁GC
3. 提高对象复用率,减少创建销毁开销
4. 外部状态独立,不会影响内部状态6.2 缺点
markdown
1. 增加系统复杂度,需要分离内部和外部状态
2. 读取外部状态的开销,可能抵消部分性能提升
3. 线程安全问题,共享对象需要考虑并发访问
4. 不适合状态经常变化的对象七、最佳实践
7.1 何时使用享元模式?
markdown
1. 对象数量巨大:系统中存在大量相似对象
2. 内存压力大:对象占用内存导致频繁GC
3. 对象可共享:大部分状态可以外部化
4. 创建开销大:对象创建消耗大量资源7.2 实现要点
typescript
public class FlyweightBestPractice {
// 1. 使用线程安全的容器
private static final ConcurrentHashMap<String, Object> pool =
new ConcurrentHashMap<>();
// 2. 使用双重检查锁确保线程安全
public static Object getFlyweight(String key) {
Object obj = pool.get(key);
if (obj == null) {
synchronized (pool) {
obj = pool.get(key);
if (obj == null) {
obj = createObject(key);
pool.put(key, obj);
}
}
}
return obj;
}
// 3. 设置池的大小上限
private static final int MAX_POOL_SIZE = 100;
public static Object getFlyweightWithLimit(String key) {
if (pool.size() >= MAX_POOL_SIZE) {
// 可以使用LRU策略移除最少使用的对象
return createObject(key);
}
return getFlyweight(key);
}
// 4. 提供清理机制
public static void clear() {
pool.clear();
}
private static Object createObject(String key) {
return new Object();
}
}7.3 与其他模式的协作
与工厂模式结合:享元工厂负责创建和管理享元对象
与单例模式结合:享元工厂通常设计为单例
与状态模式结合:享元对象的状态变化可以用状态模式管理
与组合模式结合:可以将享元对象组合成更复杂的结构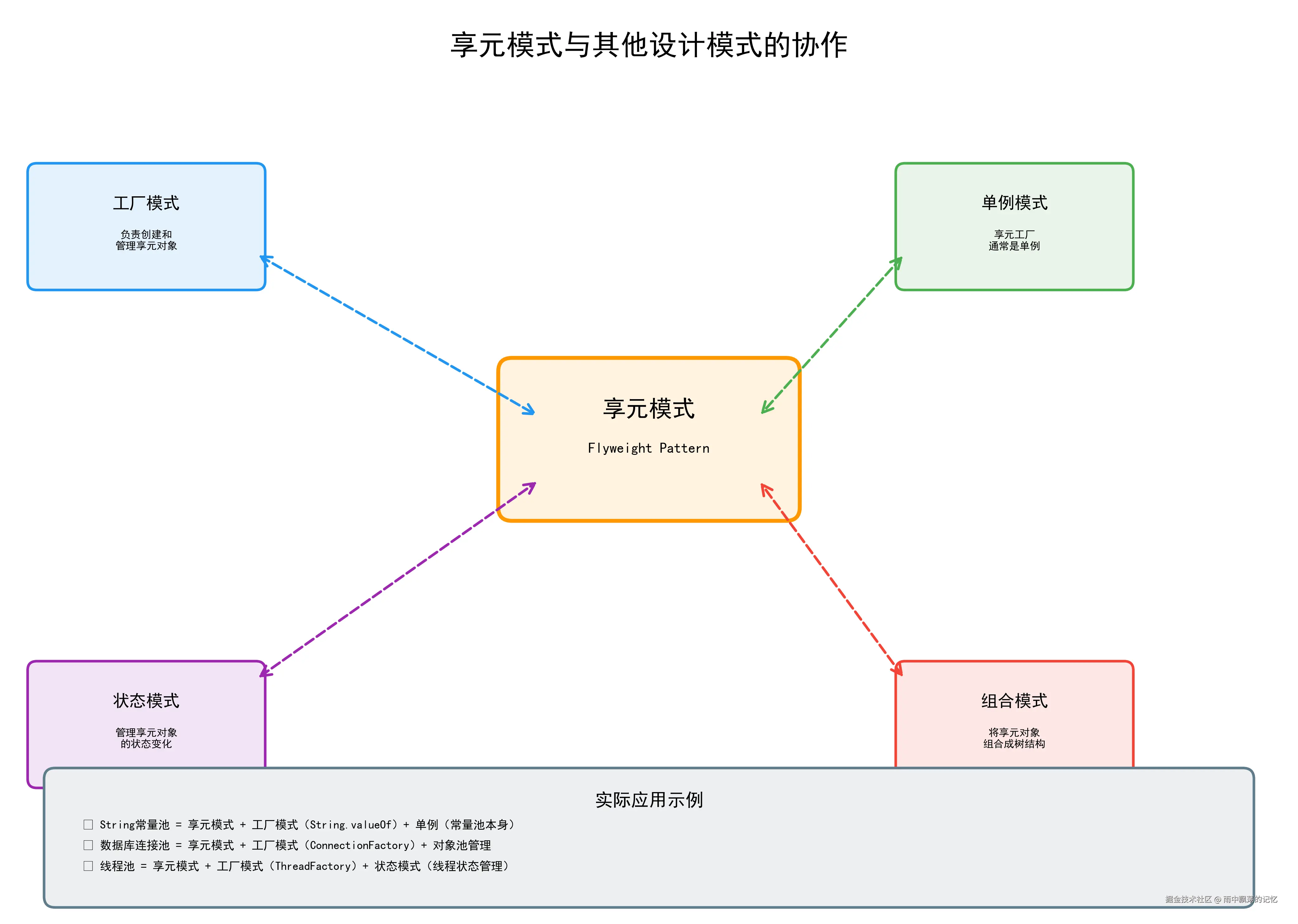
八、性能对比
8.1 内存对比测试
csharp
public class MemoryComparisonTest {
static class HeavyObject {
private byte[] data = new byte[1024]; // 1KB
private String type;
public HeavyObject(String type) {
this.type = type;
}
}
public static void main(String[] args) {
Runtime runtime = Runtime.getRuntime();
// 测试1:不使用享元模式
System.out.println("=== 不使用享元模式 ===");
long memBefore1 = runtime.totalMemory() - runtime.freeMemory();
List<HeavyObject> list1 = new ArrayList<>();
for (int i = 0; i < 10000; i++) {
list1.add(new HeavyObject(i % 10 == 0 ? "TypeA" : "TypeB"));
}
long memAfter1 = runtime.totalMemory() - runtime.freeMemory();
System.out.println("创建对象数:10000");
System.out.println("内存占用:" + (memAfter1 - memBefore1) / 1024 + " KB\n");
// 测试2:使用享元模式
System.out.println("=== 使用享元模式 ===");
Map<String, HeavyObject> pool = new HashMap<>();
pool.put("TypeA", new HeavyObject("TypeA"));
pool.put("TypeB", new HeavyObject("TypeB"));
long memBefore2 = runtime.totalMemory() - runtime.freeMemory();
List<HeavyObject> list2 = new ArrayList<>();
for (int i = 0; i < 10000; i++) {
String type = i % 10 == 0 ? "TypeA" : "TypeB";
list2.add(pool.get(type));
}
long memAfter2 = runtime.totalMemory() - runtime.freeMemory();
System.out.println("创建对象数:2");
System.out.println("内存占用:" + (memAfter2 - memBefore2) / 1024 + " KB");
System.out.println("\n内存节省:" +
((memAfter1 - memBefore1 - (memAfter2 - memBefore2)) * 100 /
(memAfter1 - memBefore1)) + "%");
}
}九、总结
享元模式是一个强大的性能优化工具,通过对象共享实现内存和性能的双重优化。在实际开发中,我们已经在使用它:
- JDK自带:String常量池、包装类缓存池
- 数据库领域:连接池(HikariCP、Druid)
- 并发编程:线程池(ThreadPoolExecutor)
- 缓存框架:Redis连接池、对象池。