从PaddleOCR到PaddleOCR-VL
 今年6月份的时候,我接到一个需求,要从2000多张手机应用截屏中提取用户ID(由字母、数字、符号组成)。我尝试了多种OCR工具,如EasyOCR和Tesseract等主流模型,但效果都不理想。主要问题包括关键信息识别错误或准确性低,例如"l"与"1"、"G"与"6"、"_"与"-"、"8"与"0"等字符难以区分,严重影响了实际使用价值。后来请教了一位从事视觉识别的朋友,了解到百度的PaddleOCR,发现它不仅准确率高,而且开源免费,非常强大且实用。
今年6月份的时候,我接到一个需求,要从2000多张手机应用截屏中提取用户ID(由字母、数字、符号组成)。我尝试了多种OCR工具,如EasyOCR和Tesseract等主流模型,但效果都不理想。主要问题包括关键信息识别错误或准确性低,例如"l"与"1"、"G"与"6"、"_"与"-"、"8"与"0"等字符难以区分,严重影响了实际使用价值。后来请教了一位从事视觉识别的朋友,了解到百度的PaddleOCR,发现它不仅准确率高,而且开源免费,非常强大且实用。
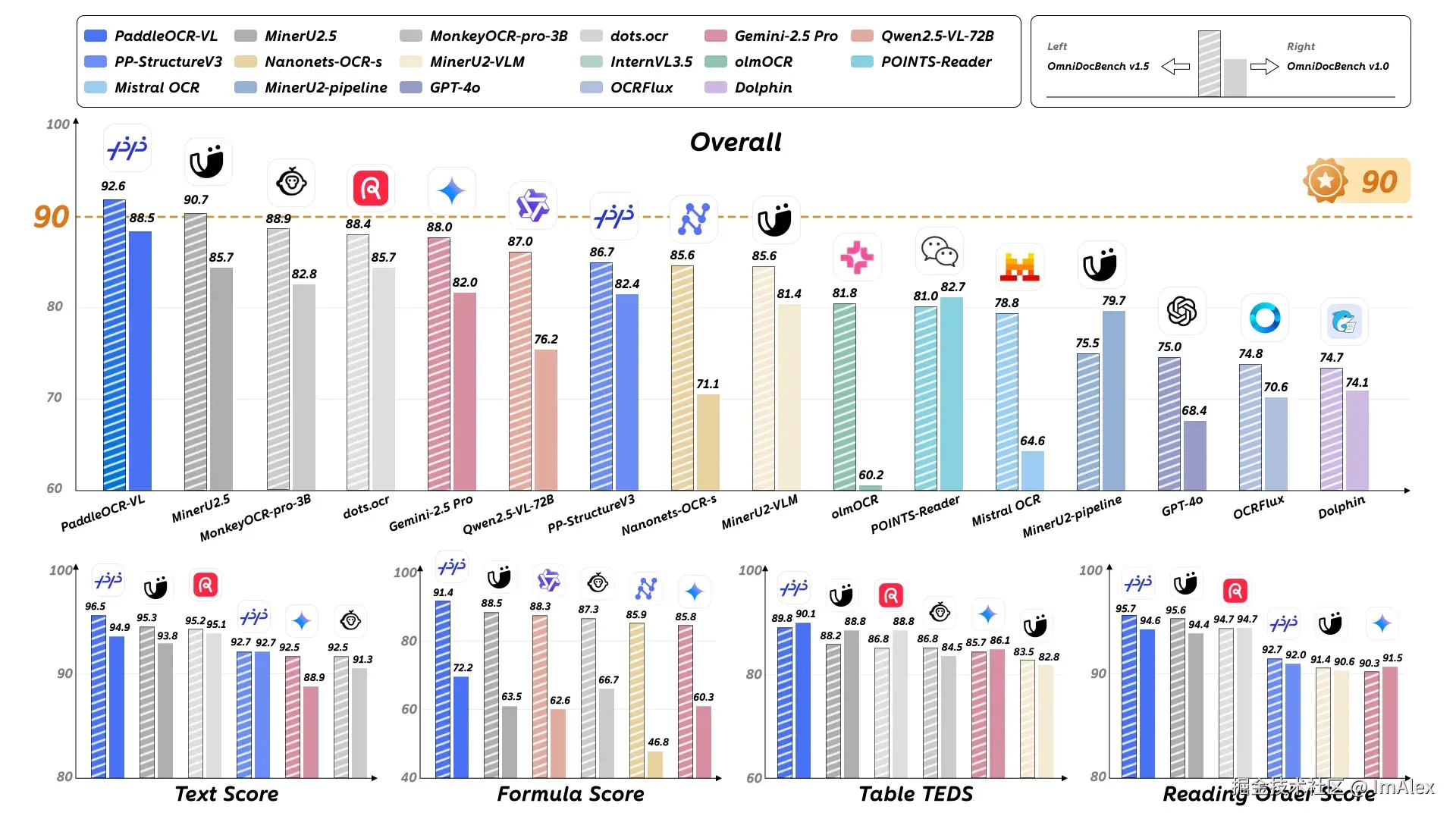
昨天(2025年10月16日)睡前刷推特时,偶然看到一个话题:百度开源了一款全新的多模态文档解析模型------PaddleOCR-VL。这款被称为"PDF之神"的文心4.5最强衍生模型,基于ERNIE-4.5-0.3B语言模型训练而来,参数量仅为0.9B,但却以92.6分的成绩登顶OmniDocBench V1.5榜单,综合性能全球第一。它在文本识别、公式解析、表格重建和阅读顺序四大核心领域均达到SOTA(当前最佳)水平,刷新了OCR VL模型的性能纪录。HuggingFace官网显示,百度昨晚发布的自研多模态文档解析模型PaddleOCR-VL,发布20小时内即登顶HuggingFace Trending全球第一。出于之前对PaddleOCR的好感,我深入研究并测试了这款全新的OCR模型,下面带大家看看它是否真的如传闻般强大。
PaddleOCR-VL的技术亮点和架构优势
如果说优秀的表现是 "结果",那 PaddleOCR-VL 的技术设计与架构创新就是 "原因"。深入拆解后会发现,这款文心 4.5 最强衍生模型,从底层就解决了传统 OCR 和普通多模态模型的核心痛点,既保证了性能天花板,又兼顾了产业落地的实用性。
四大技术亮点:从 "能识别" 到 "善处理" 的跨越
不同于传统 OCR 仅聚焦 "文字识别",PaddleOCR-VL 以 "全场景文档解析" 为目标,打造了四大核心技术优势:
轻量架构下的高性能突破
作为参数仅 0.9B 的模型,它在OmniDocBench V1.5 榜单实现 "双超越"------ 既超越 GPT-4o、Gemini-2.5 Pro 等百亿级参数多模态大模型,又碾压 InternVL1.5、MinerU2.5 等 OCR 专业小模型,更创下文本编辑距离 0.035、公式识别 CDM 91.43、表格 TEDS 93.52、阅读顺序预测误差 0.043 的纪录级精度。这种 "小模型大能力" 的背后,是文心 4.5 生态的技术赋能:集成 aNaViT 动态分辨率视觉编码器(精准捕捉文档细节)与 ERNIE-4.5-0.3B 语言模型(理解内容逻辑),让模型在 "看清楚" 的同时能 "读明白"。

复杂文档的全类型解析能力
针对手写文本、历史档案、复杂表格、数学公式等 "高难度场景",模型做了专项优化:实测中,无论是字迹潦草的课堂笔记(识别准确率超 92%)、字体模糊的竖排古籍(如民国《生意经》期刊),还是包含多层合并单元格的财报表格,它都能精准处理,避免了传统 OCR "遇复杂就错""见特殊就卡" 的问题。
图表到结构化数据的直接转换
这是 PaddleOCR-VL 的 "独家优势"------ 传统 OCR 只能识别图表中的文字,却无法提取数据逻辑,而它能将条形图、折线图、饼图等可视化图表,直接转换为机器可读的结构化表格。
多语种支持与高效推理兼顾
模型覆盖 100 + 种语言(含中文、英语、法语、日语、阿拉伯语等),能应对全球化文档处理需求。

同时推理效率极高:在单张 A100 GPU 上,每秒可处理 1881 个 Token,推理速度较 MinerU2.5 提升 14.2%,较 dots.ocr 提升 253.01%,即使在普通 RTX 3090 显卡上,单页 A4 文档处理也仅需 0.3 秒,满足产业场景 "高并发、快响应" 的需求。
两阶段架构:解决多模态模型 "幻觉与错位" 的核心
PaddleOCR-VL 采用创新的 "两阶段处理流程",彻底摆脱了端到端方案在复杂版面中的不稳定问题,成为其 "高精度 + 高可靠" 的关键。
第一阶段:版面分析与阅读顺序预测
由 PP-DocLayoutV2 模型负责。它会先对文档进行 "全局扫描",定位标题、正文、表格、公式、图注等语义区域,并预测出符合人类阅读习惯的顺序(比如多栏论文 "从左到右、从上到下",竖排文档 "从右到左")。实测处理三栏学术论文时,这一步就能避免传统 OCR "把左栏末尾文字接右栏开头" 的错位问题。
第二阶段:细粒度识别与内容结构化
由 PaddleOCR-VL-0.9B 模型执行。基于第一阶段的 "区域划分",模型对不同类型内容做针对性识别:文字区域提取字符并修正语序,表格区域还原行列结构,公式区域输出 LaTeX 格式,图表区域转换为结构化数据。
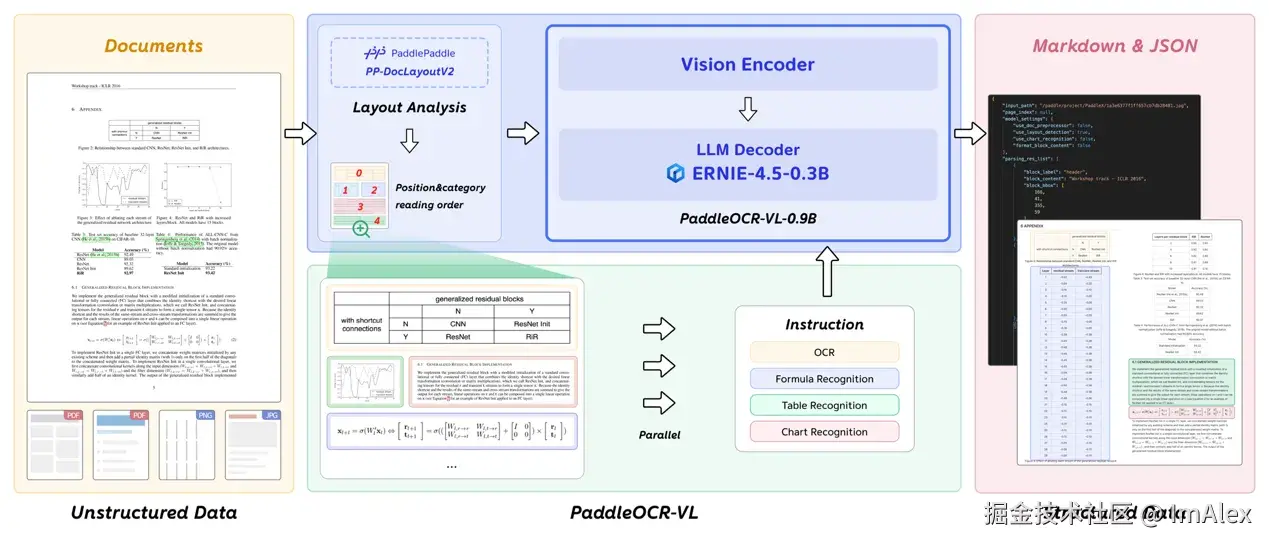
最后通过轻量级后处理模块,将两阶段结果聚合整合,输出 Markdown 或 JSON 格式的结构化文件 ------ 这种 "先划分、再识别、后整合" 的逻辑,既保证了每个环节的精度,又避免了多模态模型常见的 "内容幻觉"(如无中生有公式、错配表格数据),让解析结果可直接用于 RAG、数据录入等下游任务。
部分场景实测
原理分析完毕,我们也已经看到了PaddleOCR-VL的诸多亮点。那么,它的实际表现究竟如何呢?为了更全面地评估这一工具的能力,我们将在本章中选取三个典型的场景进行测试:手写体识别、表格内容提取以及复杂数学教材内容的解析。每个场景都将通过一张具有代表性的图片来进行验证,从而直观地展示PaddleOCR-VL在不同任务中的实际效果。
手写体识别

如上图所示,左侧是行楷体写的一片小短文,右侧是PaddleOCR-VL识别出的文本。经我比对,一字不差,甚至连段落和文中的标点符号都全部识别出来了,效果非常棒。那些打字录入性质的传统岗位完全可以被AI取代。
表格识别
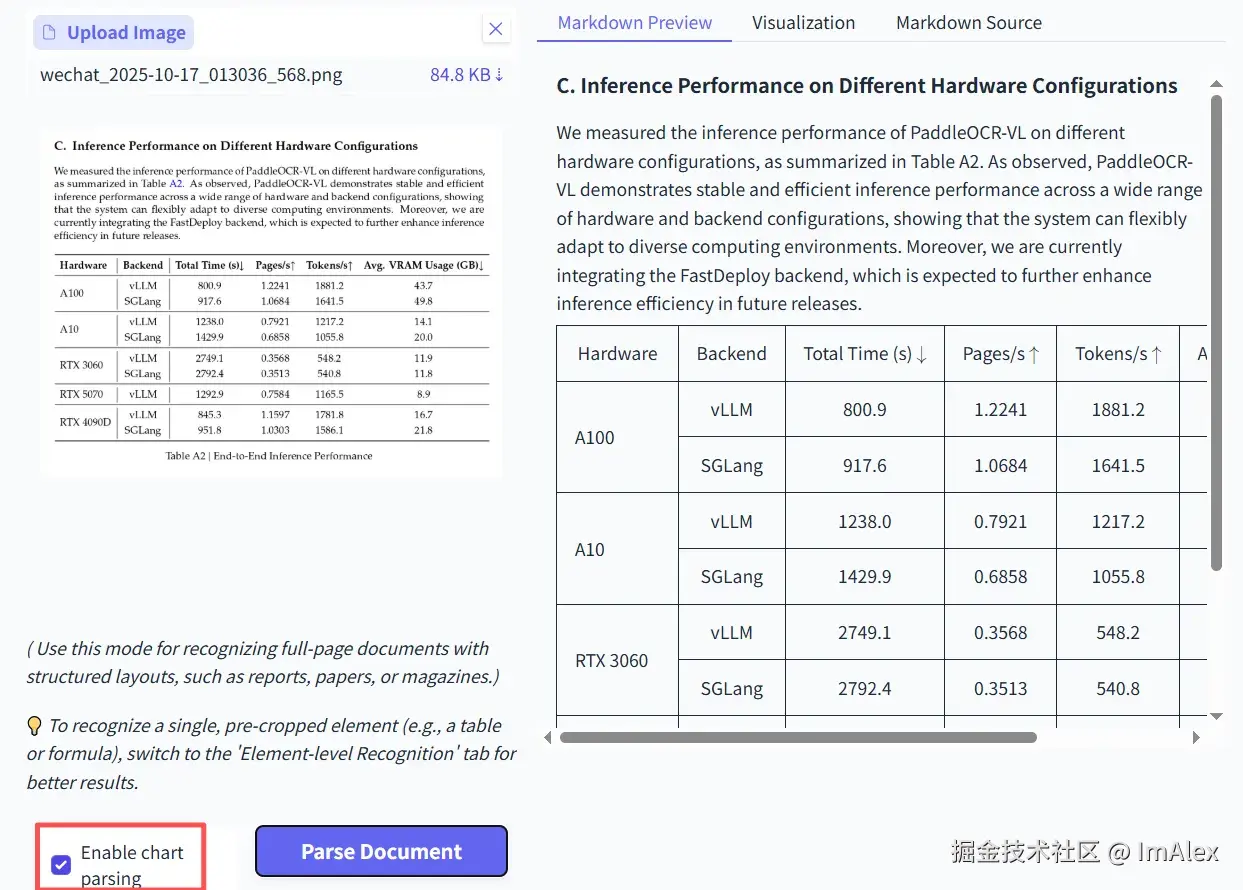
如上图所示,左侧是从某论文中截取的一页,包含标题、征文、表格、表格标题等几个元素。右侧是经PaddleOCR-VL OCR识别之后的结果,可以看到,不止精准识别到了文本内容,还真是还原了图片中的表格。
复杂板式的识别和结构化输出

如上图所示,面对更加复杂的数学教材内容,充满了各种各样的元素,比如文本、图形、公式、分栏结构、表格等等。可以看到,PaddleOCR-VL OCR的还原效果非常棒:
① 文本内容属于基本盘,毫无压力。
② 图像区域原因保留,自动切图展示。
③ 公式识别准确并真实还原。
④ 分栏版式识别正确,没有出现乱序。
⑤ 标题和表格真实还原。且单元格中的图形也实现了自动切图还原。
下面是PaddleOCR输出的markdown格式的结构化输出源码,有了它,我们就可以轻松地解析和处理文本内容,进一步将其应用于各种场景。
bash
C是第一级台阶水平面的中点。弹射器沿水平方向弹射小球,弹射器高度h和小球的初速度 $ v_{0} $ 可调节,小球被弹出前与A的水平距离也为L。某次弹射时,小球恰好没有擦到A而击中B,为了能击中C点,需调整h为 $ h' $ ,调整 $ v_{0} $ 为 $ v_{0}' $ ,下列判断正确的是()
<div style="text-align: center;"><img src="https://pplines-online.bj.bcebos.com/deploy/official/paddleocr/pp-ocr-vl//6176a4fb-5ca1-4e42-8894-d339d9a1e76d/markdown_0/imgs/img_in_image_box_75_165_231_267.jpg?authorization=bce-auth-v1%2F5cfe9a5e1454405eb2a975c43eace6ec%2F2025-10-16T17%3A53%3A12Z%2F-1%2F%2F9bd7d17c3f7675134f200be503c4060ff6882a3c07a64afd7002d129bda68b32" alt="Image" width="25%" /></div>
A. $ h' $ 的最大值为2h
B. $ h' $ 的最小值为2h
C. $ v_{0}' $ 的最大值为 $ \frac{\sqrt{15}}{6}v_{0} $
D. $ v_{0}' $ 的最小值为 $ \frac{\sqrt{15}}{6}v_{0} $
解析 小球做平抛运动,有 $ y=\frac{1}{2}gt^{2}, x=v_{0}t $ ,联立解得 $ v_{0}=x\sqrt{\frac{g}{2y}}, y=\frac{gxt^{2}}{2v_{0}^{2}}\propto x^{2} $ (点拨:将水平抛高之比和高度之比建立关联是关键),则调整前 $ \frac{h}{h+H}=\left(\frac{L}{2L}\right)^{2} $ ,得 $ h=\frac{1}{3}H $ ,调整后考虑临界情况,小球恰好没有擦到 A 而击中 C,则 $ \frac{h'}{h'+H}=\left(\frac{2}{3}\right)^{2} $ ,即 $ h'=\frac{4}{5}H $ ,所以 $ h'=\frac{12}{5}h $ ,从越高处抛出而击中 C 点,抛物线越陡,越不容易擦到 A 点,所以 $ h'=\frac{12}{5}h $ 是满足条件的 $ h' $ 的最小值,A、B 错误。 $ v_{0}=x\sqrt{\frac{g}{2y}} $ ,且两次平抛从抛出到 A 点过程,x 都为 L,所以 $ v_{0}'=\sqrt{\frac{h}{h'}}=\frac{\sqrt{15}}{6} $ ,即 $ v_{0}'=\frac{\sqrt{15}}{6}v_{0} $ ,由 $ v_{0}'=L\sqrt{\frac{g}{2h}} $ ,知 $ v_{0}'=\frac{\sqrt{15}}{6}v_{0} $ 是满足条件的 $ v_{0}' $ 的最大值,C 正确,D 错误。
## 答案 C
## 四、 斜抛运动
1. 分析思路:对斜上抛运动,从抛出点到最高点的运动可应用逆向思维分析,其逆过程为平抛运动;对于完整的斜上抛运动,还可根据对称性求解某些问题。
2. 斜抛运动中的几个常用结论
<div style="text-align: center;"><img src="https://pplines-online.bj.bcebos.com/deploy/official/paddleocr/pp-ocr-vl//6176a4fb-5ca1-4e42-8894-d339d9a1e76d/markdown_0/imgs/img_in_image_box_396_258_498_329.jpg?authorization=bce-auth-v1%2F5cfe9a5e1454405eb2a975c43eace6ec%2F2025-10-16T17%3A53%3A12Z%2F-1%2F%2F8132142824c4bf8b7c30c5d17b7e5c7a8742b058fe1e8b38e93ee269f459ad17" alt="Image" width="16%" /></div>
(1)运动到最高点的时间 $ t=\frac{v_{0}\sin\theta}{g} $ ;
运动的总时间 $ t_{总}=\frac{2v_{0}\sin\theta}{g} $
(2) 射高 $ y_{m}=\frac{v_{0}^{2}\sin^{2}\theta}{2g} $
(3) 射程 $ x_{m}=\frac{v_{0}^{2}\sin2\theta}{g} $ 。当 $ \theta=45^{\circ} $ 时,射程最大。
## 题型7 圆周运动中的临界极值问题
## 一、 水平面内的圆周运动的两种模型
<table border=1 style='margin: auto; width: max-content;'><tr><td style='text-align: center;'></td><td style='text-align: center;'>与弹力有关的临界问题</td><td style='text-align: center;'>与摩擦力有关的临界问题</td></tr><tr><td style='text-align: center;'>情境图示</td><td style='text-align: center;'><img src="https://pplines-online.bj.bcebos.com/deploy/official/paddleocr/pp-ocr-vl//6176a4fb-5ca1-4e42-8894-d339d9a1e76d/markdown_0/imgs/img_in_image_box_369_644_468_748.jpg?authorization=bce-auth-v1%2F5cfe9a5e1454405eb2a975c43eace6ec%2F2025-10-16T17%3A53%3A12Z%2F-1%2F%2F8d45b0e4b4b2bb74e96e23cd0b818bfa61c88e1da842d06a0ede15da592010de" ></td><td style='text-align: center;'><img src="https://pplines-online.bj.bcebos.com/deploy/official/paddleocr/pp-ocr-vl//6176a4fb-5ca1-4e42-8894-d339d9a1e76d/markdown_0/imgs/img_in_image_box_497_655_573_737.jpg?authorization=bce-auth-v1%2F5cfe9a5e1454405eb2a975c43eace6ec%2F2025-10-16T17%3A53%3A12Z%2F-1%2F%2Fdcf343dbf39b76663335dc9808ac10b36d0fb4390901a72b843796830bdeb877" ></td></tr><tr><td style='text-align: center;'>受力示意图</td><td style='text-align: center;'><img src="https://pplines-online.bj.bcebos.com/deploy/official/paddleocr/pp-ocr-vl//6176a4fb-5ca1-4e42-8894-d339d9a1e76d/markdown_0/imgs/img_in_image_box_365_753_469_859.jpg?authorization=bce-auth-v1%2F5cfe9a5e1454405eb2a975c43eace6ec%2F2025-10-16T17%3A53%3A12Z%2F-1%2F%2Fb52c388e51b75eaa1f20e28af39ea8923e2f5f58eccd270e64ad9309b84cf237" ></td><td style='text-align: center;'><img src="https://pplines-online.bj.bcebos.com/deploy/official/paddleocr/pp-ocr-vl//6176a4fb-5ca1-4e42-8894-d339d9a1e76d/markdown_0/imgs/img_in_image_box_494_756_578_855.jpg?authorization=bce-auth-v1%2F5cfe9a5e1454405eb2a975c43eace6ec%2F2025-10-16T17%3A53%3A12Z%2F-1%2F%2F206ee677ab25f805cee96b8b8d1057932cbe7e351af7670b0ec872dfa7dfb97e" ></td></tr></table>通过对这三个场景的实际测试,我们可以多个维度了解PaddleOCR-VL的性能表现,包括其识别精度、泛化能力以及对复杂布局的理解水平。这些实验不仅能够帮助我们更好地认识到PaddleOCR-VL的能力和表现,也能为后续的应用开发提供有价值的参考依据。
文心生态下的文档处理新范式
实测完PaddleOCR-VL,我最大的感受是:它不仅是一个"高性能OCR模型",更是文心4.5生态赋能产业的典型样本------用大模型的理解能力重构传统OCR的技术边界,用轻量架构降低开发者落地门槛,用开源生态加速行业创新。希望通过这篇文章,能够让大家更好了解PaddleOCR-VL的能力和表现,也能为后续的应用开发提供有价值的参考依据。
目前,PaddleOCR-VL已在GitHub(github.com/PaddlePaddl...)和huggingface(huggingface.co/PaddlePaddl...)开源,还提供了可直接体验的Demo(aistudio.baidu.com/application...)。HuggingFace官网显示,百度昨晚发布的自研多模态文档解析模型PaddleOCR-VL,发布20小时内即登顶HuggingFace Trending全球第一。如果你也在被文档解析效率低、识别准确率差的问题困扰,不妨亲自试试看。或许你会和我一样,发现OCR识别原来可以这么简单。而对行业而言,这款文心4.5最强衍生模型的出现,或许正是文档处理从"人工辅助"走向"全自动化"的关键一步。