文章目录
- 一、背景
- 二、bilibili下载姬
- 三、ffmpeg提取音频
- 四、在线音频提取文字ASR
- [五、使用LLM 进行整理笔记](#五、使用LLM 进行整理笔记)
- 六、参考链接
一、背景
bilibili当前有越来越多高质量的教学视频,但是B站上没有直接下载视频的按钮,以及视频资料不利于复现回归,所以最好整理成笔记方便后续回顾。本文介绍一种B站视频下载、音频提取、使用ASR将音频转成文字,并且利用LLM大语言模型将文本生成学习笔记。
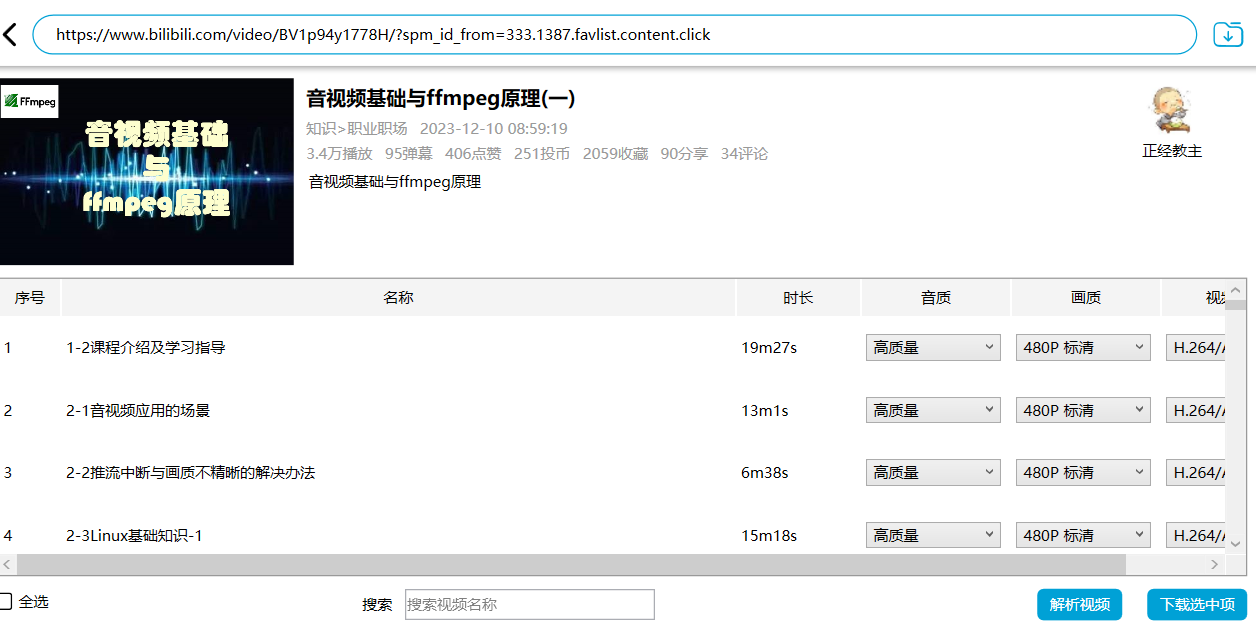
二、bilibili下载姬
B站视频下载,这里推荐开源工具bilibili下载姬,源码链接如下:
https://github.com/leiurayer/downkyi
下载v1.6版本的可执行文件,downkyi是基于aria工具实现。
三、ffmpeg提取音频
mp4文件可能比较大,我们仅仅需要提取音频即可,使用ffmpeg工具提取音频mp3文件。
# 使用原始码率
ffmpeg -i input.mp4 -codec:a libmp3lame output.mp3可以指定码率,一般不需要
ffmpeg -i input.mp4 -vn -acodec libmp3lame -ar 44100 -ac 2 -ab 192k output.mp3对于语音识别ASR模型,可能音频文件太大,需要截取音频长度,使用如下命令:
ffmpeg -i input.mp3 -ss 00:00:10 -t 00:00:20 output.mp3- -ss 00:00:10:设置开始时间为 10 秒。
- -t 00:00:20:设置持续时间为 20 秒。
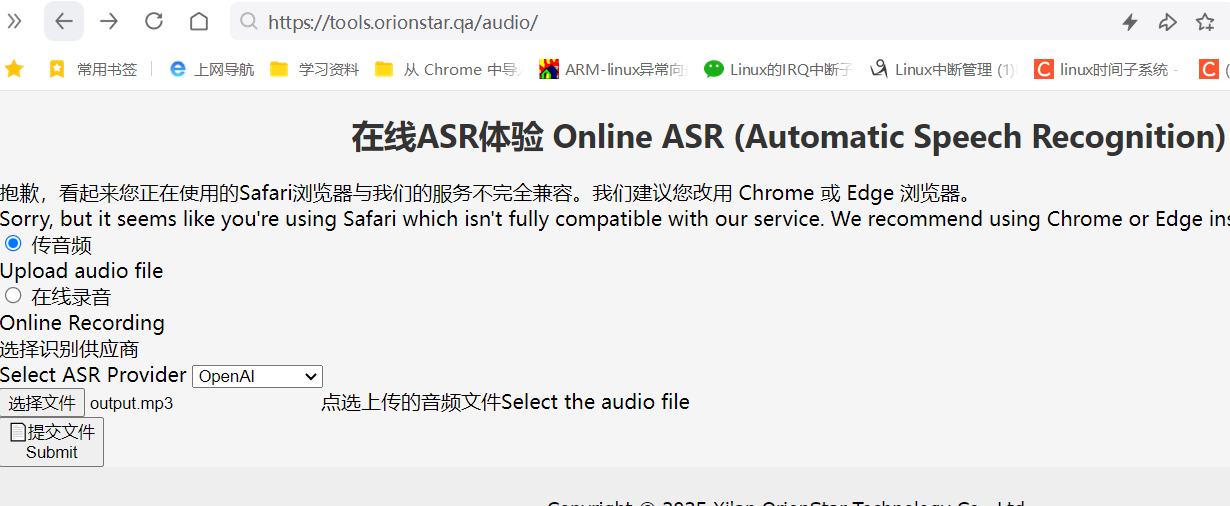
四、在线音频提取文字ASR
ASR模型是用于语音识别的,这里推荐一款在线ASR工具进行语音转文字网站,注意该网站生成的文本是没有标点符号的。
https://tools.orionstar.qa/audio/
五、使用LLM 进行整理笔记
最后一步使用LLM对上述生成的文本进行整合,并形成正式文档,补充标点符号,注意不要改变原文意思。这里prompt如下,使用任意LLM大语言模型即可。
我这里有一份没有标点符号的学习草稿文件,请在不改变原文意思的情况下帮忙整理成一份条例清晰的正式文档,以markdown形式输出,不要进行内容延展,仅进行格式整合。