起因
最近打包了一个MATLAB的算法,由于是帮忙给别人打包的,所以无法做太多的数据处理,一切从简。MATLAB的源程序是直接读csv表格,读入数据,再进行计算处理,理论上,应该把数据读入和解析这部分放到后端,算法只进行计算,但是由于还得重写很多MATLAB代码,所以就放弃了,直接就是让MATLAB读取表格这个逻辑保持不变去用的,但是打包的过程中出现了一个问题,写代码的人用的是2020版本的MATLAB,但是我用的是2022版本的MATLAB,所以由于版本差异,造成了相同的代码,高版本的那个读表格的库不支持读csv了,反正就是读失败了,只能读xlsx,所以需要把csv格式的原始数据转换成xlsx格式的。程序没问题后,就正常打包了。我本来以为不会有什么问题了,但是还是出问题了。问题是csv转换成xlsx后,计算后的结果是NAN,我本来以为这就是一个简单的数据转换处理,不会出问题,但是没想到,最后还是出bug了。但是由于打包过程太麻烦,所以放弃了重新打包的念头,最终还是决定,自己去实现一下格式转换这部分。
思路
了解到xlsx的结构其实是个压缩包,这里真是涨知识了,第一次了解到了xlsx,pptx这些带x的都是压缩包,所以直接改后缀成zip,然后解压,注意这里不要用提取,提取出来的还原不回去,直接就是改后缀,然后解压,解压出来后可以看到xlsx的基本结构
经过测试发现,用wps另存后的xlsx放到程序里面运行结果正常,那这里就采用对比法,准备一个wps另存前的xlsx,再准备一个另存后的xlsx,都改后缀解压,然后用vscode打开,安装一个xml的插件,右键选择格式化文档,把xml文件变成可读的格式,然后对比两个文件夹内的文件差异,可以先通过大范围的文件替换,来确定是哪个文件差异影响的报错,然后定位到文件后再去找文件中的内容哪个影响的报错,这里其实是有可以对比文件差异的工具的。经过对比筛选,最终确定
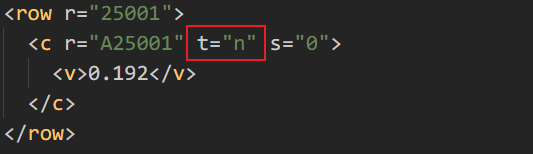
这个t="n"是造成报错的主要原因,只需要全局替换这个为空就不会报错了,那么这个时候就可以搜一下这个代表什么含义,然后在转换的时候避免生成这个就可以了。
最后用Python写了一个小Demo,用于转换测试(PS:这个程序仅适合我的需求,仅做参考)
import pandas as pd
from openpyxl import load_workbook
from openpyxl.styles import NamedStyle
# 读取 CSV 文件
csv_file = '11.csv' # 替换为你的 CSV 文件路径
df = pd.read_csv(csv_file, header=None)
# 强制转换为数值类型,如果无法转换的将保持原样
def safe_to_numeric(value):
try:
# 尝试转换为数字,如果成功返回数字
return pd.to_numeric(value)
except (ValueError, TypeError):
# 如果无法转换为数字,返回原始值
return value
# 对每一列应用 safe_to_numeric 方法
for col in df.columns:
df[col] = df[col].apply(safe_to_numeric)
# 将数据保存为 XLSX 文件
xlsx_file = 'output.xlsx'
# 使用 Pandas 将 DataFrame 保存为 Excel
df.to_excel(xlsx_file, index=False, header=False)
# 使用 openpyxl 加载刚才保存的 Excel 文件
wb = load_workbook(xlsx_file)
ws = wb.active
# 设置数值格式为常规
number_style = NamedStyle(name="number_style", number_format="General") # 常规格式
# 为所有列应用常规格式
for row in ws.iter_rows():
for cell in row:
# 保持原始格式,设置为常规格式
cell.style = number_style # 应用常规格式
# 保存修改后的 XLSX 文件
wb.save(xlsx_file)
print(f"CSV 文件成功转换为 XLSX 文件,数值格式已设置:{xlsx_file}")然后终于解决了,不会再返回NAN了
这里其实还有个想法,就是如果我实在写不出转换的程序,那么就用最笨的方法,通过程序重命名然后解压,然后读文件,删除t="n",最后写回去,然后压缩,再改后缀,应该也是可以实现的,虽然麻烦一些,但是最后没用到这个方法。
感悟
这次主要是解决问题思路的积累,AI只能当成工具,他不能给你定位那么深的去解决实际问题,看事物要看本质,从本质入手。csv转xlsx的本质就是把逗号分隔的数据转换成xml格式的最后压缩。