什么是Hadoop?
Hadoop是一个框架.
- Hadoop是一个框架,可以允许分布式处理大数据集 (big data sets),而且这个数据集是横跨在集群的机器上的(clusters of computers)。也就是说数据可以分开地存储在集群中的每个机器( 节点)上,并且可以跨节点进行处理计算 ,它使用的是一种简单的编程模型(using simple programming models)。 核心价值就是解决 "海量数据怎么存、怎么算、任务调度" 的问题。
思考:怎么理解Hadoop是一个框架这句话?
框架图长啥样子?

- Hadoop HDFS :为应用程序访问提供高 吞吐量 的分布式文件系统。
- Hadoop MapReduce:可以并行处理大数据集的编程计算模型。
- Hadoop YARN :提供 任务调度 服务和 集群 资源管理的框架。
数据怎么存问题?Hadoop
HDFS 是 Hadoop 生态系统中的核心组件,全称为 Hadoop Distributed File System ,即 Hadoop 分布式文件系统 ,用于在大规模集群上 高容错、高吞吐地存储大数据文件。
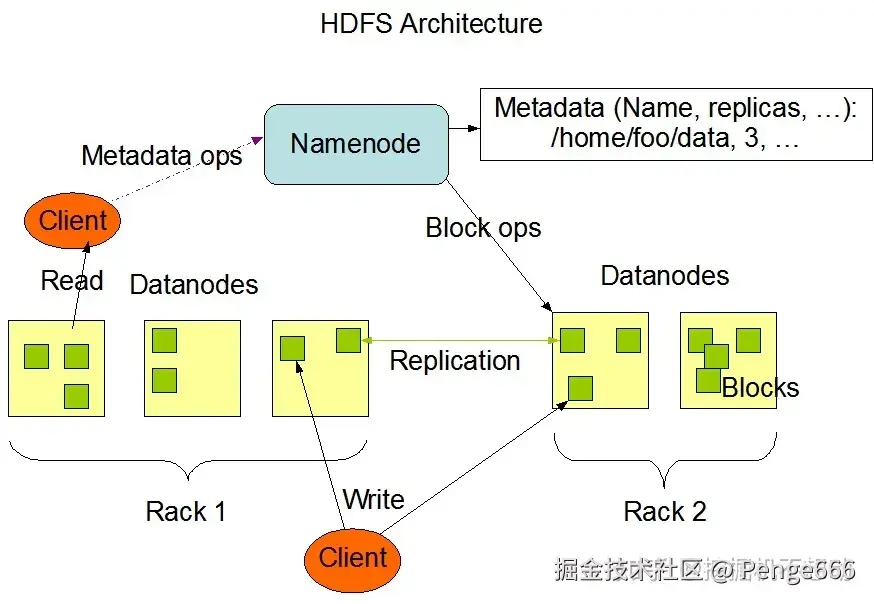
这是 HDFS (Hadoop 分布式文件系统) 的架构图,核心是 "客户端与 NameNode 交互 元数据 ,与 DataNode 交互实际数据块" ,数据流分 "写数据" 和 "读数据" 两类场景,拆解如下:
- NameNode:管理节点,维护着文件系统树及整个树内的所有文件和目录(元数据),同时负责客户端请求。
- DataNode:文件系统的工作节点,根据需要存储和检索数据块,并且定期向NameNode发送他们所存储的块的列表。
- Blocks:HDFS中的存储单元,默认为128M,通常有多个备份,默认为3。
写流程
-
客户端请求 元数据 操作(Client → NameNode)
- 客户端想写文件(比如
/home/foo/data),先给 NameNode 发请求:"我要写这个文件,块咋存?" - NameNode 负责管理 元数据(文件名称、块数量、副本数等 ),回复:"文件分成 3 个 Block,存到这些 DataNode(比如 Rack1、Rack2 的节点 )"。
- 客户端想写文件(比如
-
客户端写数据块(Client → DataNode)
-
客户端拿到 NameNode 分配的 DataNode 列表,开始写数据:
- 把文件拆成 Block(数据块) ,按 NameNode 指示,先写第一个 DataNode(比如 Rack1 的节点 );
- DataNode 收到 Block 后,触发 副本复制(Replication) ,把 Block 同步到其他 DataNode(比如 Rack2 的节点 ),保证副本数(图中是 3 副本 )。
-
-
元数据 更新(DataNode → NameNode)
- DataNode 写完 Block 后,通知 NameNode:"Block 存好了,位置在这";
- NameNode 更新元数据(记录 Block 位置、副本数 ),写流程完成。
读流程
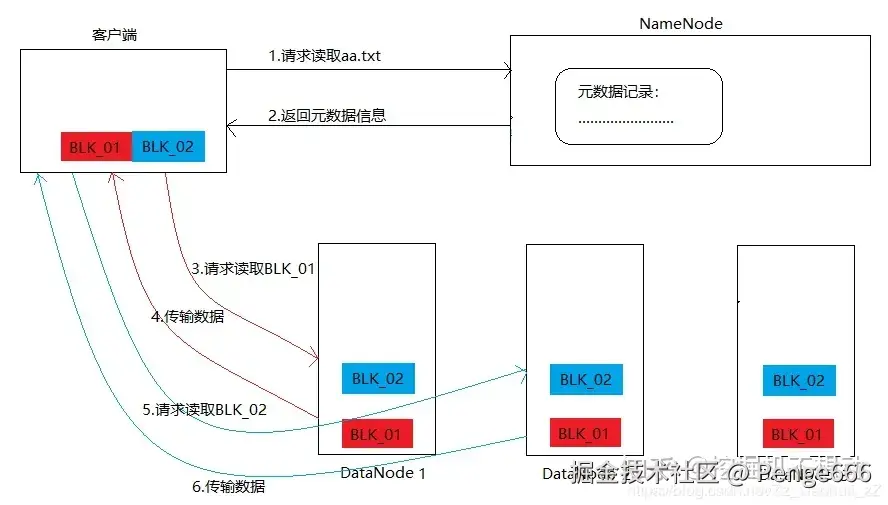
-
客户端请求 元数据(Client → NameNode)
- 客户端想读文件
/home/foo/data,先给 NameNode 发请求:"这个文件的 Block 存在哪?" - NameNode 查元数据,回复:"文件的 3 个 Block 分布在这些 DataNode(Rack1、Rack2 的节点 )"。
- 客户端想读文件
-
客户端读数据块(Client → DataNode)
- 客户端拿到 DataNode 列表,直接找距离最近的 DataNode(比如同 Rack 的节点 )读 Block;
- 读完所有 Block 后,客户端自己拼接成完整文件。
NameNode机制
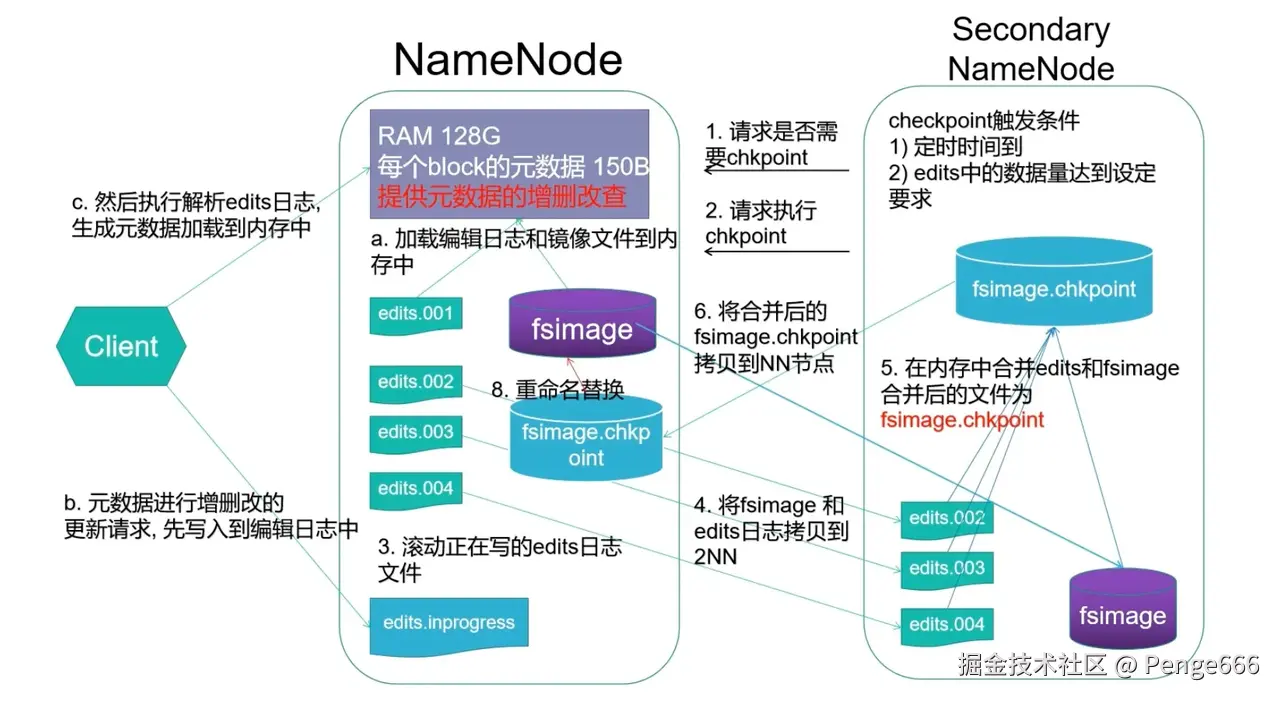
【看这个图👆】我的理解,缓解namenode文件合并速度。很像redis的思想
NameNode 是 HDFS 的核心组件,它负责维护整个文件系统的元数据信息。这些元数据以两种形式存储在本地磁盘上:
- 一部分保存在
fsimage文件中,表示某一时刻的元数据快照; - 另一部分保存在
edits日志中,记录自该快照以来所有的文件系统变更操作。
当 NameNode 启动时,会先加载 fsimage 快照文件到内存中,然后再按顺序回放 edits 日志,以恢复最新的文件系统状态。随着时间推移,edits 文件会越来越大,导致启动回放耗时严重。
为了解决这个问题,HDFS 引入了 SecondaryNameNode,它并不是热备节点,而是负责定期帮助 NameNode 做元数据快照合并的节点。它的工作流程如下:
- 定期(或定量)触发 checkpoint 操作;
- 通知 NameNode 滚动当前
edits文件,生成一份可供合并的静态日志; - 从 NameNode 拉取当前的
fsimage文件和新生成的edits文件; - 在本地将二者合并,生成一个更新后的元数据快照,通常为
fsimage_xxx.ckpt; - 将合并后的快照文件推送回 NameNode;
- NameNode 将其重命名为新的
fsimage并替换旧文件。
在整个合并过程中,客户端仍然可以向 NameNode 发起写入请求,新的变更会被记录到当前活跃的 edits_inprogress 文件中,确保操作不中断。
元数据有三种形式:内存、EditsLog、FsImage。
- 内存中保存的是最完整最新的元数据。
- EditsLog保存HDFS自最新的元数据检查点后的元数据变化的记录。
- FsImage保存最新的元数据检查点。
Checkpoint(检查点) 指的是在NameNode启动时候,会先将fsimage中的文件系统元数据信息加载到内存,然后根据eidts中的记录将内存中的元数据同步至最新状态(这里读的是journalnode中的editlog),将这个新版本的 FsImage 从内存中保存到本地磁盘上,然后删除旧的 Editlog。
fsimage存放上次checkpoint生成的文件系统元数据,Edits存放文件系统操作日志。checkpoint的过程,就是合并fsimage和Edits文件,然后生成最新的fsimage的过程。
任务运行过程?MapReduce
不细说,可以看经典论文
任务怎么调度?Yarn队列
YARN(Yet Another Resource Negotiator ),是 Hadoop 生态中的资源管理与调度框架
"Yet Another Resource Negotiator"(简称 YARN)直译为 "又一个资源协调者"。
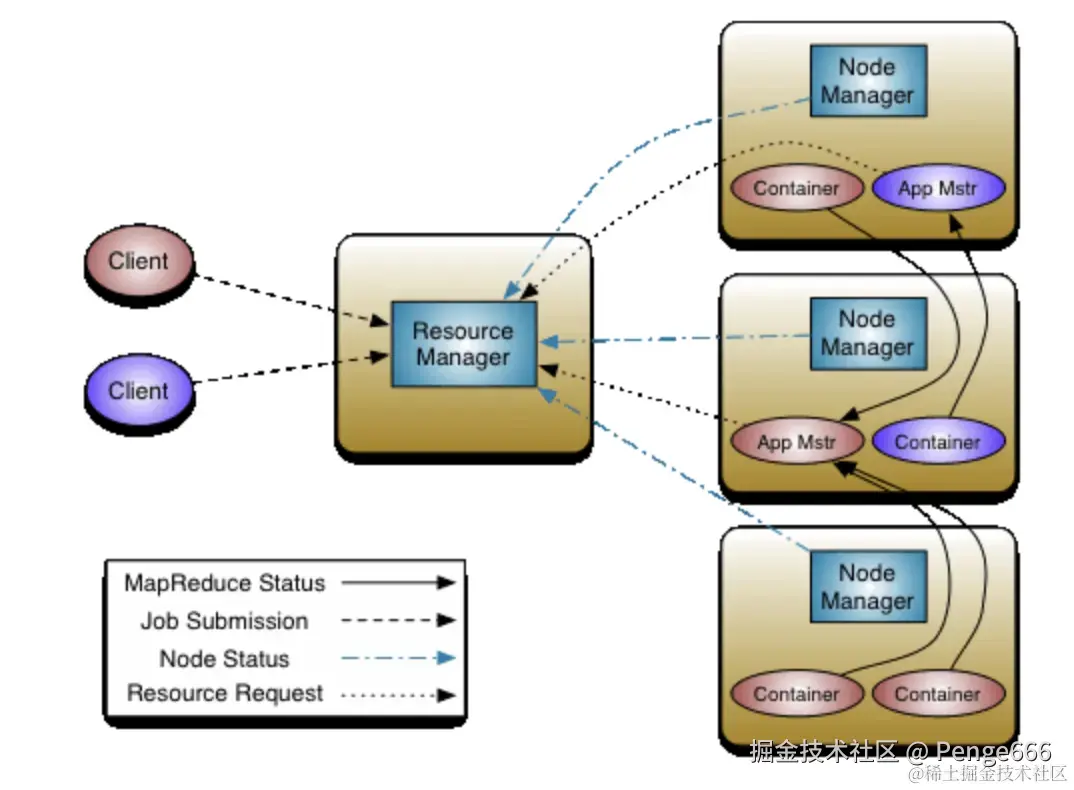
Yarn 采用传统的 master-slave 架构模式,其主要由 4 种组件组成,它们的主要功能如下:
- ResourceManager(RM):全局资源管理器,负责整个系统的资源管理和分配;
- ApplicationMaster(AM):负责应用程序(Application)的管理;
- NodeManager(NM):负责 slave 节点的资源管理和使用;
- Container(容器):对任务运行环境的一个抽象。
YARN 工作流程
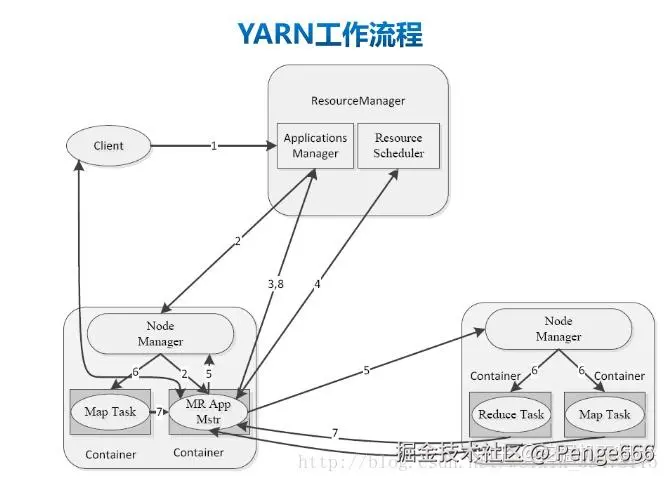
步骤:
- 1.用 户 向 YARN 中 提 交 应 用 程 序, 其 中 包 括 MRAppMaster 程 序、 启 动 MRAppMaster 的命令、用户程序等。(MRAppMstr 程序在客户端生成,这一步已经将应用程序先行程序提交到RM的Application Manager模块进行处理,但此时运行程序所需的jar包、环境变量、切片信息等提交到HDFS之上,需要等MRAPPMstr返回一个可用的Container的时候在节点提交执行。可以理解为惰性处理,减少资源占用,做到需要什么提交什么)
- 2.ResourceManager 为该应用程序分配第一个 Container,并与对应的 Node-Manager 通信,要求它在这个 Container 中启动应用程序的MRAppMaster。(APPMaster就是先头兵,这时的操作是RM的ApplicationManager来进行处理)
- 3.MRAppMaster 首先向 ResourceManager 注册, 这样用户可以直接通过ResourceManage 查看应用程序的运行状态,然后它将为各个任务申请资源,并监控它的运行状态,直到整个应用运行结束。
- 4.MRAppMaster 采用轮询的方式通过 RPC 协议向 ResourceManager 申请和 领取资源。
- 5.一旦 MRAppMaster 申请到资源后,便与对应的 NodeManager 通信,要求 它启动任务。(理解集群中不同节点的资源动态变动,可用Container以及不同的Task可以在不同的节点运行)
- 6.NodeManager 为任务设置好运行环境(包括环境变量、JAR 包、二进制程序 等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务。(此时,客户端才真正上传具体Task需要的Jar包等等运行资源,同时NodeManager通过调用资源运行对应的Task任务);
- 7.各个任务通过某个 RPC 协议向 MRAppMaster 汇报自己的状态和进度,以 让 MRApplicationMaster 随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。 在应用程序运行过程中,用户可随时通过 RPC 向 MRAppMaster 查询应用程序的当 前运行状态。
- 步骤4~7是重复执行的
- 8.应用程序运行完成后,MRAppMaster 向 ResourceManager 注销并关闭自己。
可将 YARN 看做一个云操作系统,它负责为应用程序启 动 ApplicationMaster(相当于主线程),然后再由 ApplicationMaster 负责数据切分、任务分配、 启动和监控等工作,而由 ApplicationMaster 启动的各个 Task(相当于子线程)仅负责自己的计 算任务。当所有任务计算完成后,ApplicationMaster 认为应用程序运行完成,然后退出。