背景需求:
之前做了每周通讯上传的Python文字稿整理代码,事半功倍
https://blog.csdn.net/reasonsummer/article/details/151897670?spm=1011.2415.3001.5331 https://blog.csdn.net/reasonsummer/article/details/151897670?spm=1011.2415.3001.5331
https://blog.csdn.net/reasonsummer/article/details/151897670?spm=1011.2415.3001.5331
本次我下载第7周周计划,发现过期了
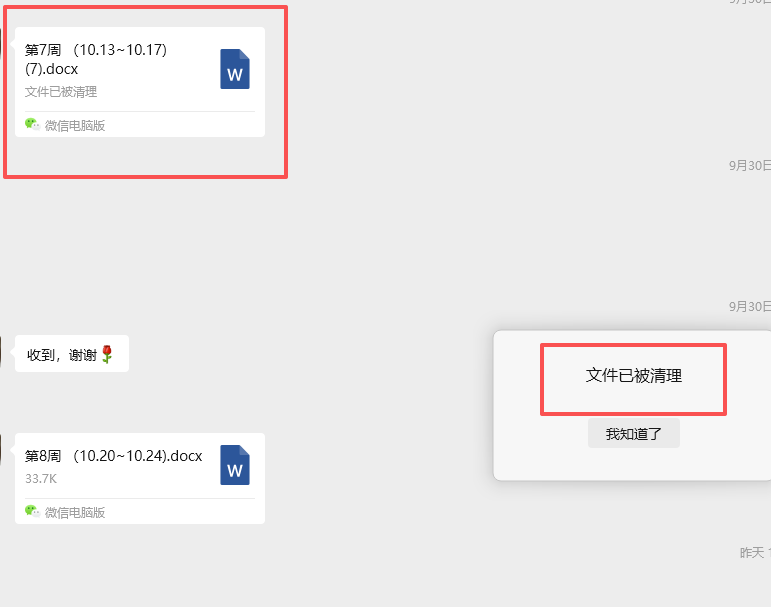
只要去总群里下载拉周计划PDF版本
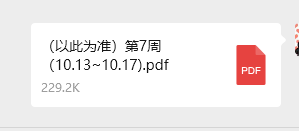
PDF转docx,可以用付过费的WPS转,但是我没有,所以需要用Python代码将PDF转docx


代码展示
'''
周计划PDF转docx
Deepseek,阿夏
20251018
'''
import os
from pdf2docx import Converter
import argparse
import sys
def batch_convert_pdf_to_docx(input_folder, output_folder=None):
"""
批量将文件夹中的 PDF 文件转换为 DOCX
"""
# 检查输入文件夹是否存在
if not os.path.exists(input_folder):
print(f"错误: 文件夹 '{input_folder}' 不存在")
return False
# 设置输出文件夹
if output_folder is None:
output_folder = os.path.join(input_folder)
# 创建输出文件夹
os.makedirs(output_folder, exist_ok=True)
# 获取所有 PDF 文件
pdf_files = [f for f in os.listdir(input_folder)
if f.lower().endswith('.pdf')]
if not pdf_files:
print(f"在文件夹 '{input_folder}' 中未找到 PDF 文件")
return False
print(f"找到 {len(pdf_files)} 个 PDF 文件")
print(f"输入文件夹: {input_folder}")
print(f"输出文件夹: {output_folder}")
print("=" * 50)
success_count = 0
failed_files = []
for i, pdf_file in enumerate(pdf_files, 1):
pdf_path = os.path.join(input_folder, pdf_file)
docx_filename = pdf_file.replace('.pdf', '.docx').replace('.PDF', '.docx')
docx_path = os.path.join(output_folder, docx_filename)
print(f"[{i}/{len(pdf_files)}] 正在转换: {pdf_file}")
try:
# 执行转换
cv = Converter(pdf_path)
cv.convert(docx_path)
cv.close()
success_count += 1
print(f" ✓ 成功: {docx_filename}")
except Exception as e:
failed_files.append((pdf_file, str(e)))
print(f" ✗ 失败: {str(e)}")
# 输出总结
print("=" * 50)
print(f"转换完成!")
print(f"成功: {success_count}/{len(pdf_files)}")
print(f"失败: {len(failed_files)}/{len(pdf_files)}")
if failed_files:
print("\n失败的文件:")
for file, error in failed_files:
print(f" - {file}: {error}")
return True
def main():
"""主函数"""
# 直接在这里设置路径
input_folder = r'C:\Users\jg2yXRZ\OneDrive\桌面\20250901每周计划\第07周通讯'
# 可选:设置输出文件夹
# output_folder = r'C:\Users\jg2yXRZ\OneDrive\桌面\转换结果'
output_folder = None # 使用默认输出位置
batch_convert_pdf_to_docx(input_folder, output_folder)
if __name__ == "__main__":
main()
后续的修改都和之前一样
'''
复制第01周.docx,只要其中"精彩亮点"单元格的文字。同时把"信息提供|撰稿"部分改成学校名字+作者名
Deepseek,阿夏
20250920
'''
import os
import re
from docx import Document
def process_weekly_highlight_direct():
"""
直接处理:提取精彩亮点内容并处理供稿信息,直接生成修改3文件
"""
# 设置文件夹路径
folder_path = r"C:\Users\jg2yXRZ\OneDrive\桌面\20250901每周计划\第07周通讯"
# 检查文件夹是否存在
if not os.path.exists(folder_path):
print(f"文件夹不存在: {folder_path}")
return None
# 查找文件夹中的原始docx文件
docx_files = [f for f in os.listdir(folder_path) if f.endswith('.docx') and not f.endswith('(修改).docx')]
if not docx_files:
print("文件夹中没有找到原始docx文件")
return None
# 处理第一个找到的docx文件
original_file = docx_files[0]
original_path = os.path.join(folder_path, original_file)
# 创建直接输出的文件(修改3)
base_name = os.path.splitext(original_file)[0]
final_file = f"{base_name}(修改).docx"
final_path = os.path.join(folder_path, final_file)
try:
# 打开原始文档
doc = Document(original_path)
# 创建新文档
new_doc = Document()
# 查找包含"精彩亮点"的表格或段落
found_highlight = False
collecting = False
# 先检查表格
for table in doc.tables:
for row in table.rows:
for cell in row.cells:
cell_text = cell.text.strip()
if "精彩亮点" in cell_text:
found_highlight = True
# 提取这个单元格的所有文本并处理供稿信息
for paragraph in cell.paragraphs:
text = paragraph.text
if text.strip():
# 处理供稿信息
processed_text = process_contribution_info(text)
new_doc.add_paragraph(processed_text)
break
if found_highlight:
break
if found_highlight:
break
# 如果没有在表格中找到,在段落中查找
if not found_highlight:
for paragraph in doc.paragraphs:
text = paragraph.text.strip()
if "精彩亮点" in text and not collecting:
collecting = True
# 处理供稿信息
processed_text = process_contribution_info(paragraph.text)
new_doc.add_paragraph(processed_text)
continue
if collecting:
if (text.startswith("第") and "周" in text) or text.startswith("====="):
break
if text:
# 处理供稿信息
processed_text = process_contribution_info(paragraph.text)
new_doc.add_paragraph(processed_text)
# 保存最终文档
new_doc.save(final_path)
print(f"✅ 已直接创建修改文件: {final_file}")
print("✅ 已提取精彩亮点内容并处理供稿信息")
# 显示处理结果预览
print("\n📋 处理结果预览(包含供稿信息的行):")
final_doc = Document(final_path)
for i, paragraph in enumerate(final_doc.paragraphs):
if paragraph.text.strip() and re.search(r'闵行区景谷第二幼儿园', paragraph.text):
print(f"{i+1}. {paragraph.text.strip()}")
return final_path
except Exception as e:
print(f"❌ 处理文件时出错: {e}")
return None
def process_contribution_info(text):
"""
处理供稿信息,替换为指定格式
"""
# 检查是否包含供稿信息
if re.search(r'信息提供|撰稿', text):
# 提取名字部分并保留
info_match = re.search(r'信息提供[::]\s*([^)]*)', text)
author_match = re.search(r'撰稿[::]\s*([^)]*)', text)
if info_match and author_match:
author_name = author_match.group(1).strip()
# 替换为:闵行区景谷第二幼儿园 名字
text = re.sub(r'信息提供[^)]*撰稿[^)]*', f'闵行区景谷第二幼儿园 {author_name}', text)
elif info_match:
info_name = info_match.group(1).strip()
text = re.sub(r'信息提供[^)]*', f'闵行区景谷第二幼儿园 {info_name}', text)
elif author_match:
author_name = author_match.group(1).strip()
text = re.sub(r'撰稿[^)]*', f'闵行区景谷第二幼儿园 {author_name}', text)
# 处理括号格式
if re.search(r'(信息提供[^)]*撰稿[^)]*)', text):
author_name = author_match.group(1).strip() if author_match else ""
text = re.sub(r'(信息提供[^)]*撰稿[^)]*)', f'(闵行区景谷第二幼儿园 {author_name})', text)
elif re.search(r'(信息提供[^)]*)', text):
info_name = info_match.group(1).strip() if info_match else ""
text = re.sub(r'(信息提供[^)]*)', f'(闵行区景谷第二幼儿园 {info_name})', text)
elif re.search(r'(撰稿[^)]*)', text):
author_name = author_match.group(1).strip() if author_match else ""
text = re.sub(r'(撰稿[^)]*)', f'(闵行区景谷第二幼儿园 {author_name})', text)
# 检查是否包含供稿信息
if re.search(r'组室|撰稿', text):
# 提取名字部分并保留
info_match = re.search(r'组室[::]\s*([^)]*)', text)
author_match = re.search(r'撰稿[::]\s*([^)]*)', text)
if info_match and author_match:
author_name = author_match.group(1).strip()
# 替换为:闵行区景谷第二幼儿园 名字
text = re.sub(r'组室[^)]*撰稿[^)]*', f'闵行区景谷第二幼儿园 {author_name}', text)
elif info_match:
info_name = info_match.group(1).strip()
text = re.sub(r'组室[^)]*', f'闵行区景谷第二幼儿园 {info_name}', text)
elif author_match:
author_name = author_match.group(1).strip()
text = re.sub(r'撰稿[^)]*', f'闵行区景谷第二幼儿园 {author_name}', text)
# 处理括号格式
if re.search(r'(组室[^)]*撰稿[^)]*)', text):
author_name = author_match.group(1).strip() if author_match else ""
text = re.sub(r'(组室[^)]*撰稿[^)]*)', f'(闵行区景谷第二幼儿园 {author_name})', text)
elif re.search(r'(组室[^)]*)', text):
info_name = info_match.group(1).strip() if info_match else ""
text = re.sub(r'(组室[^)]*)', f'(闵行区景谷第二幼儿园 {info_name})', text)
elif re.search(r'(撰稿[^)]*)', text):
author_name = author_match.group(1).strip() if author_match else ""
text = re.sub(r'(撰稿[^)]*)', f'(闵行区景谷第二幼儿园 {author_name})', text)
return text
def main():
"""
主函数:执行完整的处理流程
"""
print("=" * 50)
print("📝 开始处理周通讯文档(直接生成修改)")
print("=" * 50)
# 直接处理:提取精彩亮点内容并处理供稿信息
print("\n🎯 直接处理:提取精彩亮点内容并处理供稿信息")
final_path = process_weekly_highlight_direct()
if final_path:
print("\n" + "=" * 50)
print("✅ 处理完成!")
print(f"📁 最终文件: {os.path.basename(final_path)}")
print("=" * 50)
# 显示完整的内容预览
print("\n📋 完整内容预览(前15行):")
final_doc = Document(final_path)
for i, paragraph in enumerate(final_doc.paragraphs[:15]):
if paragraph.text.strip():
print(f"{i+1}. {paragraph.text.strip()}")
else:
print("❌ 处理失败")
# 执行主函数
if __name__ == "__main__":
main()

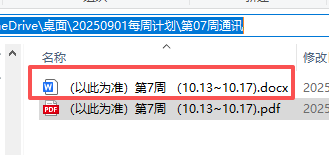
只有一页内容。因为PDF转docx后,拆分成单独的表了
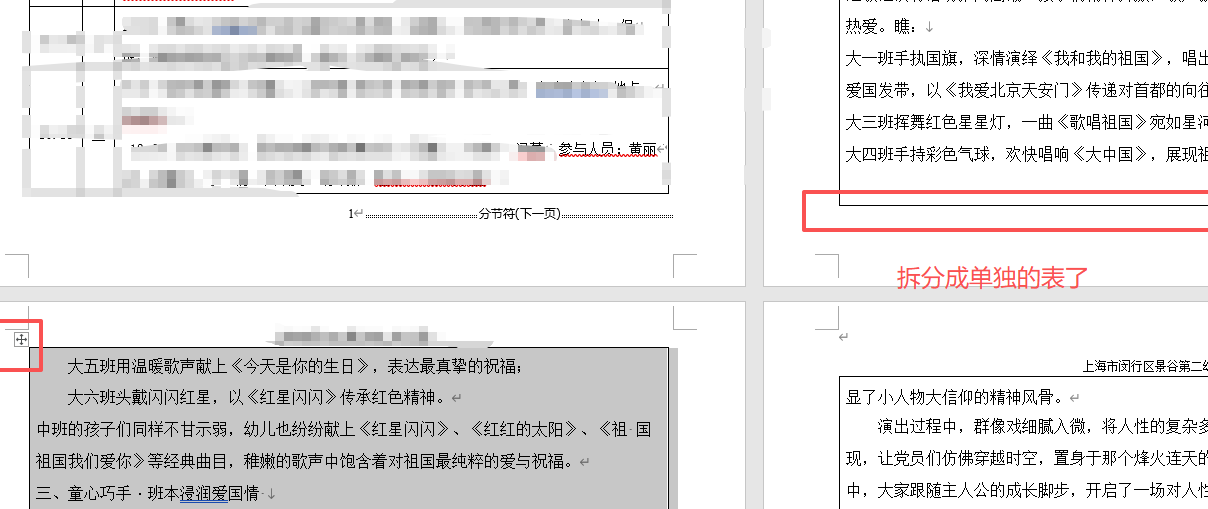
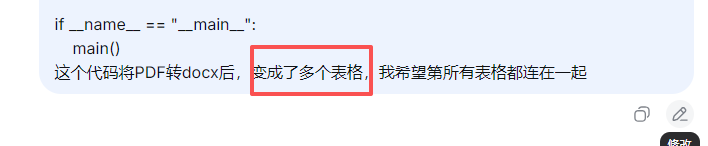
搞了半天还是解决不了这个。

最后我还是用WPS打开,然后另存了一个docx
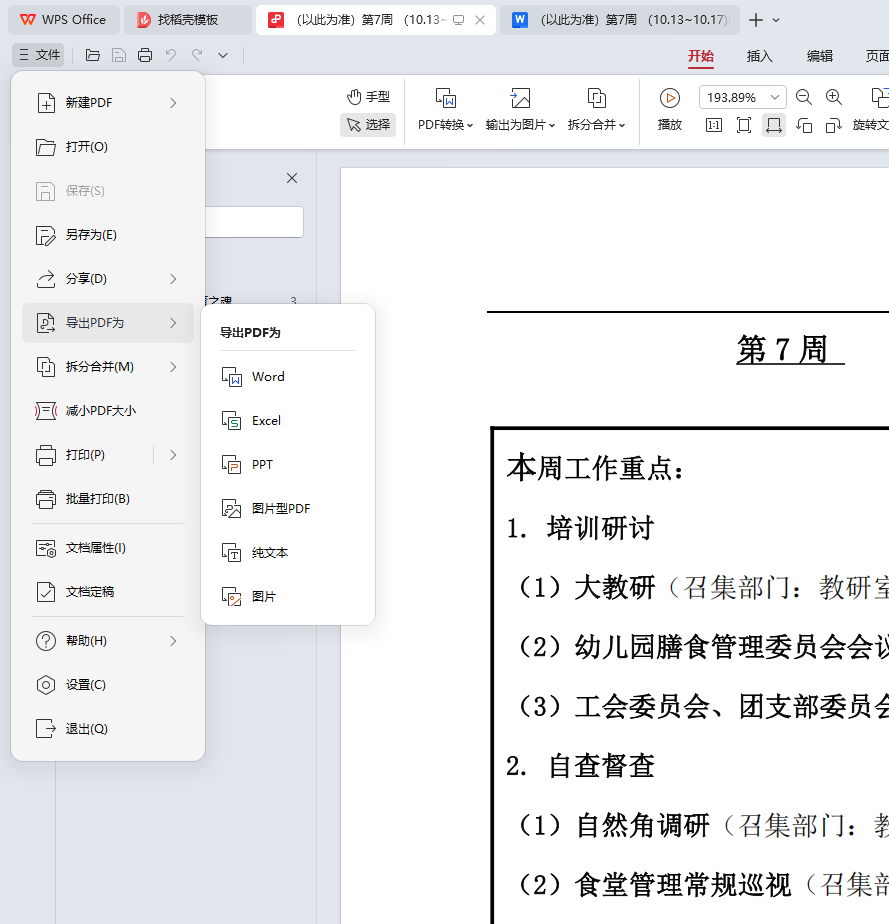
它转出的是连在一起的表格
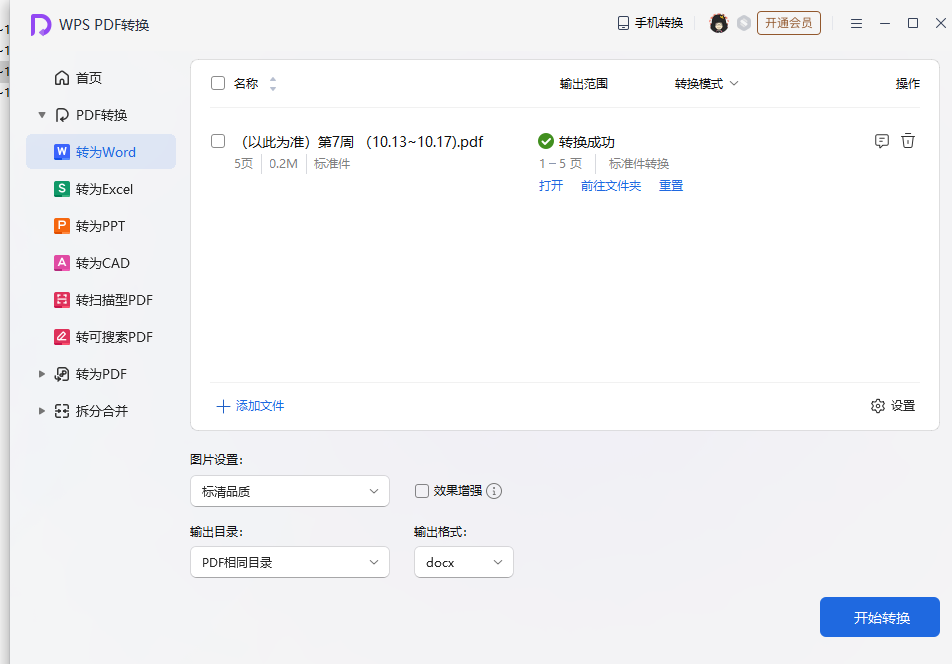
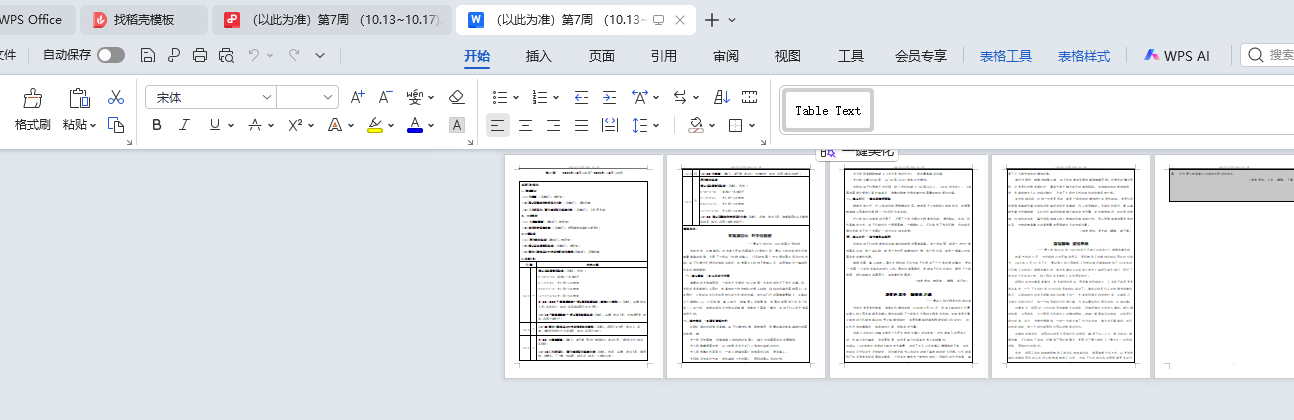
但是表格还是拆开的
解决不了,最后我把最后的三个表格剪切,黏贴为文本,然后再第一个表后面插入一行,把这些文字贴进去

'''
复制第01周.docx,只要其中"精彩亮点"单元格的文字。同时把"信息提供|撰稿"部分改成学校名字+作者名
Deepseek,阿夏
20250920
'''
import os
import re
from docx import Document
def process_weekly_highlight_direct():
"""
直接处理:提取精彩亮点内容并处理供稿信息,直接生成修改3文件
"""
# 设置文件夹路径
folder_path = r"C:\Users\jg2yXRZ\OneDrive\桌面\20250901每周计划\第07周通讯"
# 检查文件夹是否存在
if not os.path.exists(folder_path):
print(f"文件夹不存在: {folder_path}")
return None
# 查找文件夹中的原始docx文件
docx_files = [f for f in os.listdir(folder_path) if f.endswith('.docx') and not f.endswith('(修改).docx')]
if not docx_files:
print("文件夹中没有找到原始docx文件")
return None
# 处理第一个找到的docx文件
original_file = docx_files[0]
original_path = os.path.join(folder_path, original_file)
# 创建直接输出的文件(修改3)
base_name = os.path.splitext(original_file)[0]
final_file = f"{base_name}(修改).docx"
final_path = os.path.join(folder_path, final_file)
try:
# 打开原始文档
doc = Document(original_path)
# 创建新文档
new_doc = Document()
# 查找包含"精彩亮点"的表格或段落
found_highlight = False
collecting = False
# 先检查表格
for table in doc.tables:
for row in table.rows:
for cell in row.cells:
cell_text = cell.text.strip()
if "精彩亮点" in cell_text:
found_highlight = True
# 提取这个单元格的所有文本并处理供稿信息
for paragraph in cell.paragraphs:
text = paragraph.text
if text.strip():
# 处理供稿信息
processed_text = process_contribution_info(text)
new_doc.add_paragraph(processed_text)
break
if found_highlight:
break
if found_highlight:
break
# 如果没有在表格中找到,在段落中查找
if not found_highlight:
for paragraph in doc.paragraphs:
text = paragraph.text.strip()
if "精彩亮点" in text and not collecting:
collecting = True
# 处理供稿信息
processed_text = process_contribution_info(paragraph.text)
new_doc.add_paragraph(processed_text)
continue
if collecting:
if (text.startswith("第") and "周" in text) or text.startswith("====="):
break
if text:
# 处理供稿信息
processed_text = process_contribution_info(paragraph.text)
new_doc.add_paragraph(processed_text)
# 保存最终文档
new_doc.save(final_path)
print(f"✅ 已直接创建修改文件: {final_file}")
print("✅ 已提取精彩亮点内容并处理供稿信息")
# 显示处理结果预览
print("\n📋 处理结果预览(包含供稿信息的行):")
final_doc = Document(final_path)
for i, paragraph in enumerate(final_doc.paragraphs):
if paragraph.text.strip() and re.search(r'闵行区景谷第二幼儿园', paragraph.text):
print(f"{i+1}. {paragraph.text.strip()}")
return final_path
except Exception as e:
print(f"❌ 处理文件时出错: {e}")
return None
def process_contribution_info(text):
"""
处理供稿信息,替换为指定格式
"""
# 检查是否包含供稿信息
if re.search(r'信息提供|撰稿', text):
# 提取名字部分并保留
info_match = re.search(r'信息提供[::]\s*([^)]*)', text)
author_match = re.search(r'撰稿[::]\s*([^)]*)', text)
if info_match and author_match:
author_name = author_match.group(1).strip()
# 替换为:闵行区景谷第二幼儿园 名字
text = re.sub(r'信息提供[^)]*撰稿[^)]*', f'闵行区景谷第二幼儿园 {author_name}', text)
elif info_match:
info_name = info_match.group(1).strip()
text = re.sub(r'信息提供[^)]*', f'闵行区景谷第二幼儿园 {info_name}', text)
elif author_match:
author_name = author_match.group(1).strip()
text = re.sub(r'撰稿[^)]*', f'闵行区景谷第二幼儿园 {author_name}', text)
# 处理括号格式
if re.search(r'(信息提供[^)]*撰稿[^)]*)', text):
author_name = author_match.group(1).strip() if author_match else ""
text = re.sub(r'(信息提供[^)]*撰稿[^)]*)', f'(闵行区景谷第二幼儿园 {author_name})', text)
elif re.search(r'(信息提供[^)]*)', text):
info_name = info_match.group(1).strip() if info_match else ""
text = re.sub(r'(信息提供[^)]*)', f'(闵行区景谷第二幼儿园 {info_name})', text)
elif re.search(r'(撰稿[^)]*)', text):
author_name = author_match.group(1).strip() if author_match else ""
text = re.sub(r'(撰稿[^)]*)', f'(闵行区景谷第二幼儿园 {author_name})', text)
# 检查是否包含供稿信息
if re.search(r'组室|撰稿', text):
# 提取名字部分并保留
info_match = re.search(r'组室[::]\s*([^)]*)', text)
author_match = re.search(r'撰稿[::]\s*([^)]*)', text)
if info_match and author_match:
author_name = author_match.group(1).strip()
# 替换为:闵行区景谷第二幼儿园 名字
text = re.sub(r'组室[^)]*撰稿[^)]*', f'闵行区景谷第二幼儿园 {author_name}', text)
elif info_match:
info_name = info_match.group(1).strip()
text = re.sub(r'组室[^)]*', f'闵行区景谷第二幼儿园 {info_name}', text)
elif author_match:
author_name = author_match.group(1).strip()
text = re.sub(r'撰稿[^)]*', f'闵行区景谷第二幼儿园 {author_name}', text)
# 处理括号格式
if re.search(r'(组室[^)]*撰稿[^)]*)', text):
author_name = author_match.group(1).strip() if author_match else ""
text = re.sub(r'(组室[^)]*撰稿[^)]*)', f'(闵行区景谷第二幼儿园 {author_name})', text)
elif re.search(r'(组室[^)]*)', text):
info_name = info_match.group(1).strip() if info_match else ""
text = re.sub(r'(组室[^)]*)', f'(闵行区景谷第二幼儿园 {info_name})', text)
elif re.search(r'(撰稿[^)]*)', text):
author_name = author_match.group(1).strip() if author_match else ""
text = re.sub(r'(撰稿[^)]*)', f'(闵行区景谷第二幼儿园 {author_name})', text)
return text
def main():
"""
主函数:执行完整的处理流程
"""
print("=" * 50)
print("📝 开始处理周通讯文档(直接生成修改)")
print("=" * 50)
# 直接处理:提取精彩亮点内容并处理供稿信息
print("\n🎯 直接处理:提取精彩亮点内容并处理供稿信息")
final_path = process_weekly_highlight_direct()
if final_path:
print("\n" + "=" * 50)
print("✅ 处理完成!")
print(f"📁 最终文件: {os.path.basename(final_path)}")
print("=" * 50)
# 显示完整的内容预览
print("\n📋 完整内容预览(前15行):")
final_doc = Document(final_path)
for i, paragraph in enumerate(final_doc.paragraphs[:15]):
if paragraph.text.strip():
print(f"{i+1}. {paragraph.text.strip()}")
else:
print("❌ 处理失败")
# 执行主函数
if __name__ == "__main__":
main()
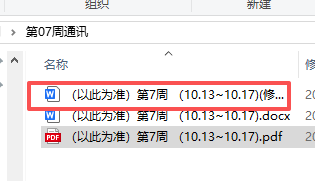
最后是多篇通讯的效果
