0 引言
随着遥感技术的快速发展,卫星和无人机等平台获取的遥感数据量呈现指数级增长。这些数据为地球表面的监测和研究提供了丰富的信息,但如何从这些遥感数据中提取有用的物理、化学或生态参数(如叶绿素含量、地表温度、土壤湿度等),仍然是遥感应用中的关键挑战。参数反演作为遥感研究的核心任务之一,旨在通过遥感数据与地面实测数据之间的关系,建立模型并估算地表参数。
传统的遥感参数反演方法主要依赖于物理模型,这些模型通常基于辐射传输方程,假设地表和大气的物理特性。然而,由于地表的复杂性和大气的不确定性,物理模型往往难以准确描述所有场景,且计算成本较高,限制了其在实际应用中的推广。近年来,机器学习技术的快速发展为遥感参数反演提供了新的解决方案。机器学习方法通过数据驱动的方式,能够自动学习数据中的非线性关系,从而在复杂场景下表现出更强的适应性和更高的精度。
站点数据作为地面实测数据的重要来源,是遥感参数反演中不可或缺的组成部分。通过将站点数据与遥感数据结合,可以有效提升模型的训练效果和预测能力。基于站点数据的机器学习参数反演方法,不仅能够提高反演结果的准确性,还能在一定程度上减少对物理模型的依赖,为遥感研究提供了新的思路和工具。
本教程旨在帮助读者理解基于站点数据的遥感机器学习参数反演的基本原理和实践方法。通过理论与实践相结合的方式,我们将介绍如何利用机器学习算法(如回归、随机森林、XGBOOST等)建立遥感参数反演模型,并结合实际案例展示从数据预处理、模型训练到结果验证的完整流程。无论您是遥感领域的研究者、学生,还是对机器学习感兴趣的开发者,本教程都将为您提供有价值的指导和参考。
整体内容如下:
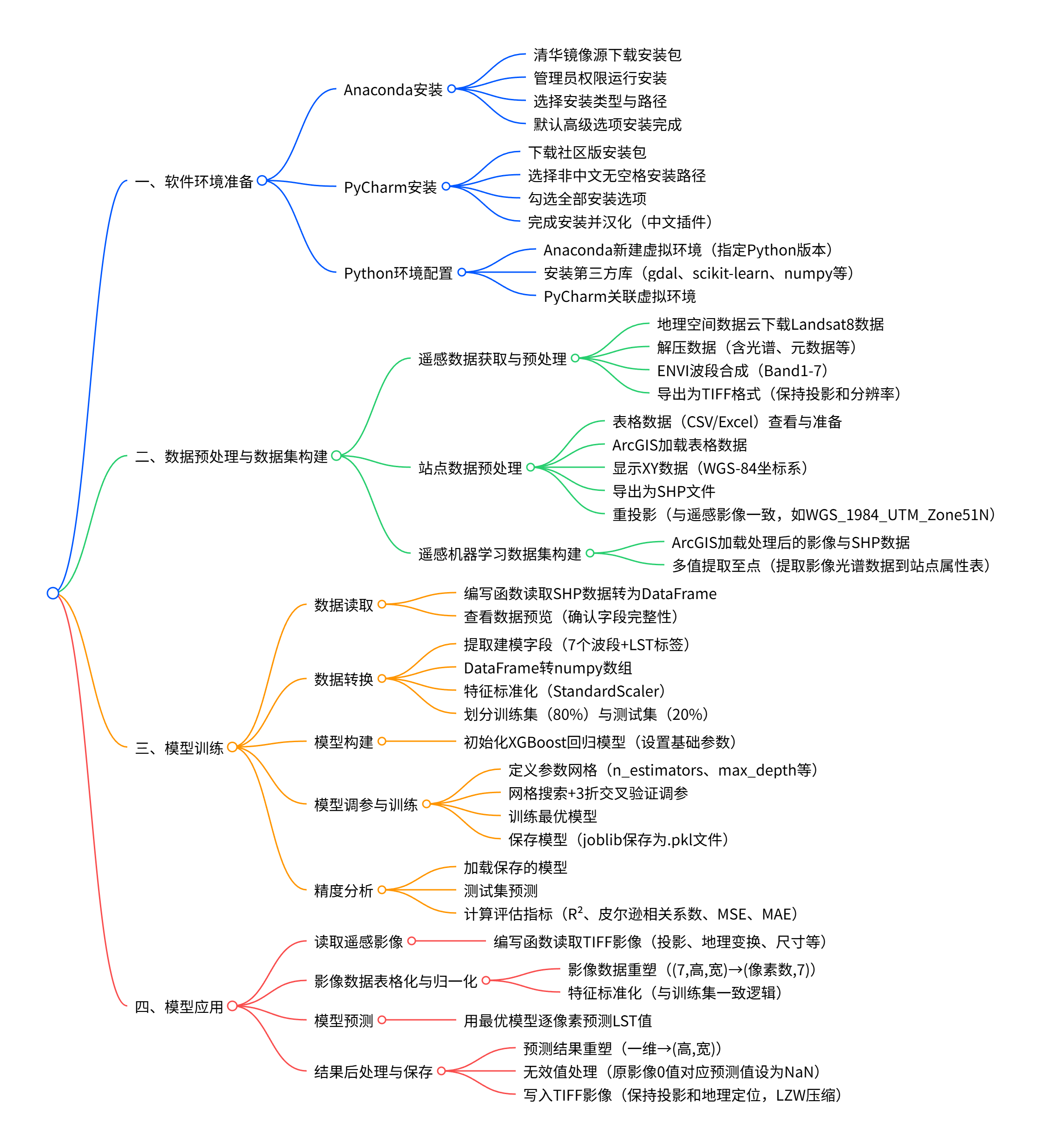
1 软件环境准备
1.1 anconda安装
1、下载安装包
推荐使用通过清华镜像源下载,下载速度较快,链接如下,可根据date选择最新版本
https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/?C=M&O=D
2、安装anconda
推荐使用管理员权限运行安装,避免不必要的麻烦
点击Next
I agree 同意
两个选择,我在使用时影响不大,可选择默认选项all users,点击next
选择安装路径,如果C盘空间充足建议默认路径,next
默认选项即可,install,然后稍定几分钟。。。。
next,next然后完成了安装!!!
1.2 pycharm安装
1.下载安装包https://www.jetbrains.com/pycharm/download/?section=windows 下载社区版就基本够用
2.安装pycharm
找到你下载PyCharm的路径,双击.exe文件进行安装。
点击 Next 后,我们进行选择安装路径页面(尽量不要选择带中文和空格的目录)选择好路径后,点击 Next 进行下一步
进入 Installation Options(安装选项)页面,全部勾选上。点击 Next
进入 Choose Start Menu Folder 页面,直接点击 Install 进行安装

5.等待安装完成后出现下图界面,我们点击 Finish 完成。
3.汉化
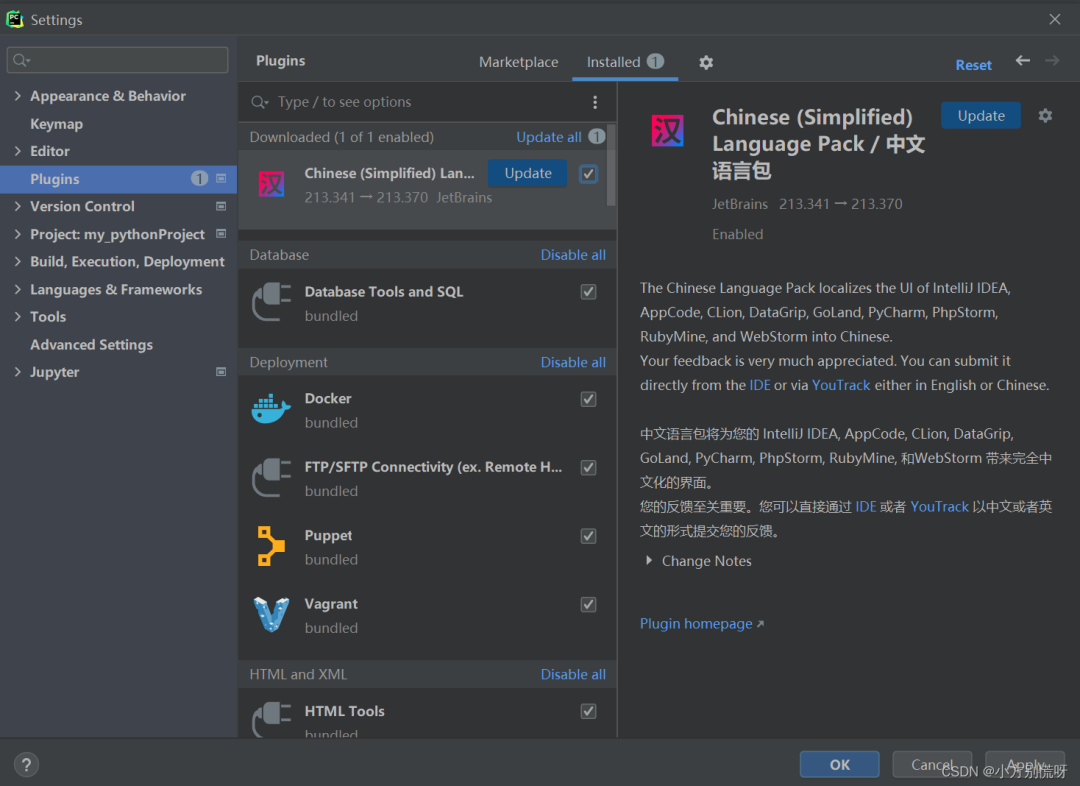
File->Settings->Plugins(插件)在搜索栏中输入Chinese(Simplified)下载中文插件并安装重启PyCharm即出现汉化
1.3 Python环境配置
1.anconda环境配置
打开anconda,点击environment
新安装后的anconda只有一个base环境,如果新建环境点击create
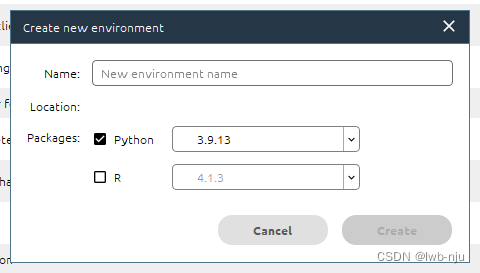
给环境起一个名称,选择python的版本 ,填写好后点击create 稍定几分钟就创建好了
2、在虚拟环境中安装第三方库(界面化操作)
把左上方下拉框选为 not installed 在右上方搜索,这里需要安装gdal、Scikit learn、numpy、xgboost等
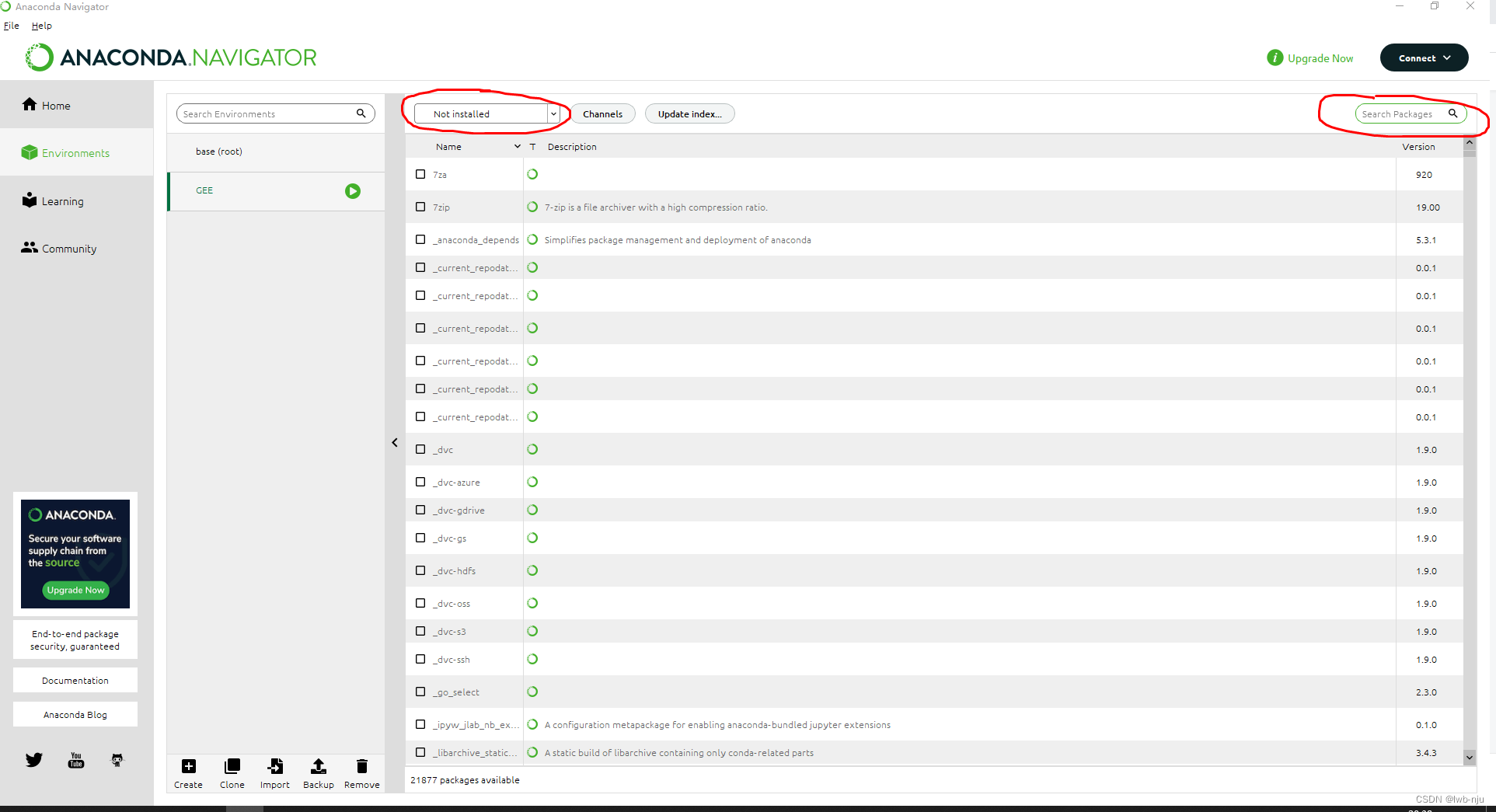
然后勾选需要的库
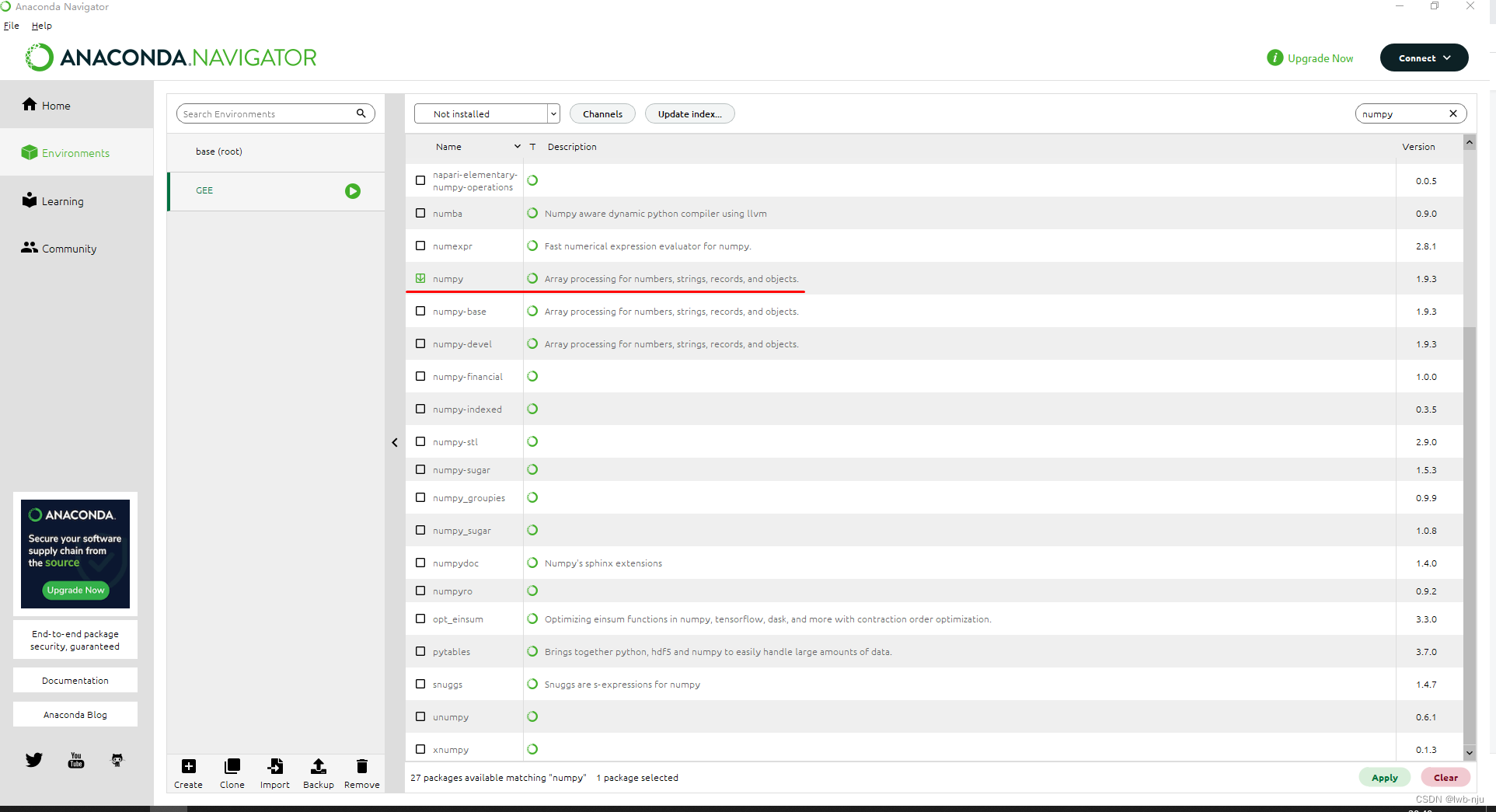
点击apply 进行安装
3、虚拟环境的使用(pycharm内使用)
打开pycharm
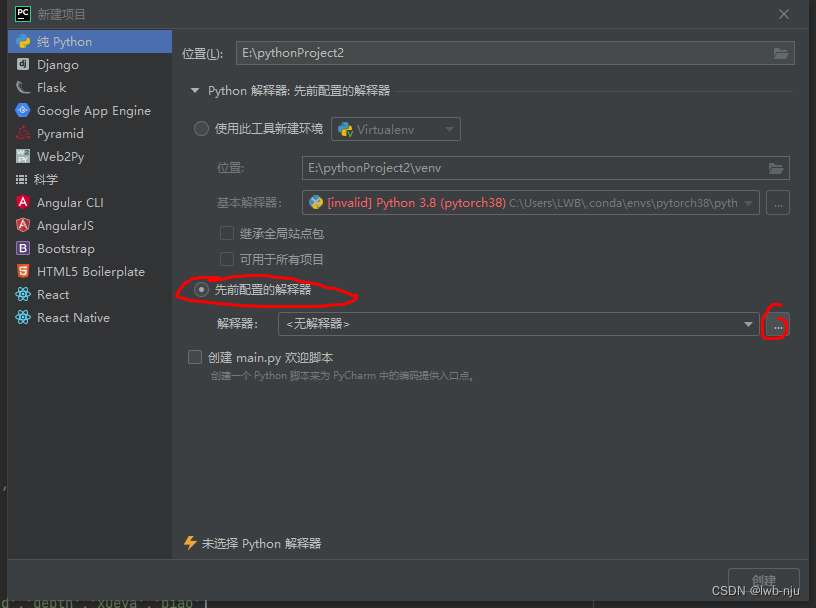
新建项目,使用先前配置的解释器
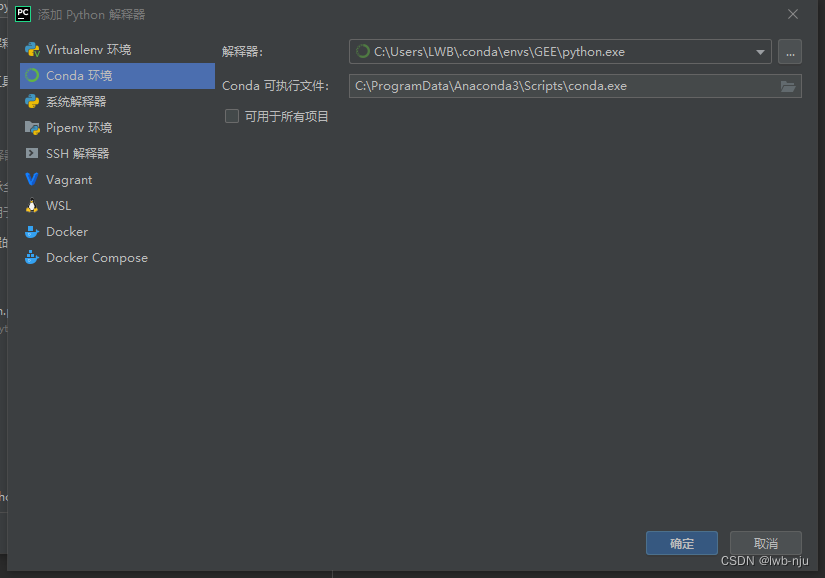
使用conda环境,确定,就可使用
2 数据预处理与数据集构建
这里我们需要准备,遥感数据与站点数据,要求遥感数据与站点数据是相同日期,相同空间范围,相同坐标系。本教程使用的影像是20230120的,站点数据也是该日期的(模拟数据)。
2.1遥感数据获取与预处理
常用遥感地学数据下载网站见下方链接,此处我们以地理空间数据云下载Landsat8数据为例
https://blog.csdn.net/nju_zjy/article/details/84866666
1.需要注册一个地理空间数据云(https://www.gscloud.cn/#page1/4)账号并登录
2.在数据资源中可以查看地理空间数据云提供的各种数据
3.在公开数据中我们可以看到对landsat8数据的解释
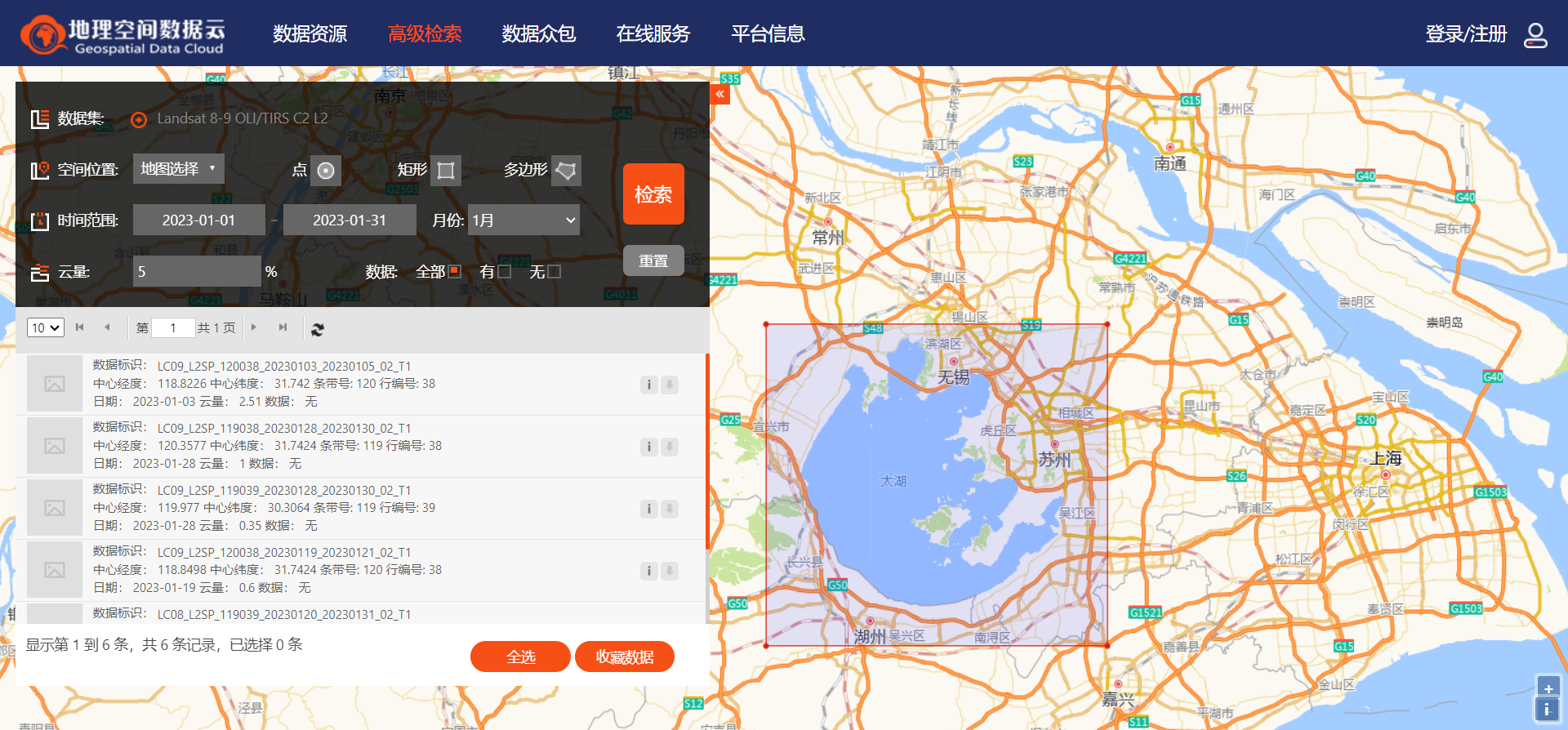
4.在高级检索中使用空间范围和时间信息检索以及云量等信息检索合适的影像
5.这里空间范围以太湖附近为例,选择2023年一月份云量小于5%的影像,可以看到有6景影像被筛选出,选择喜欢的一景下载,进行后续处理与实验
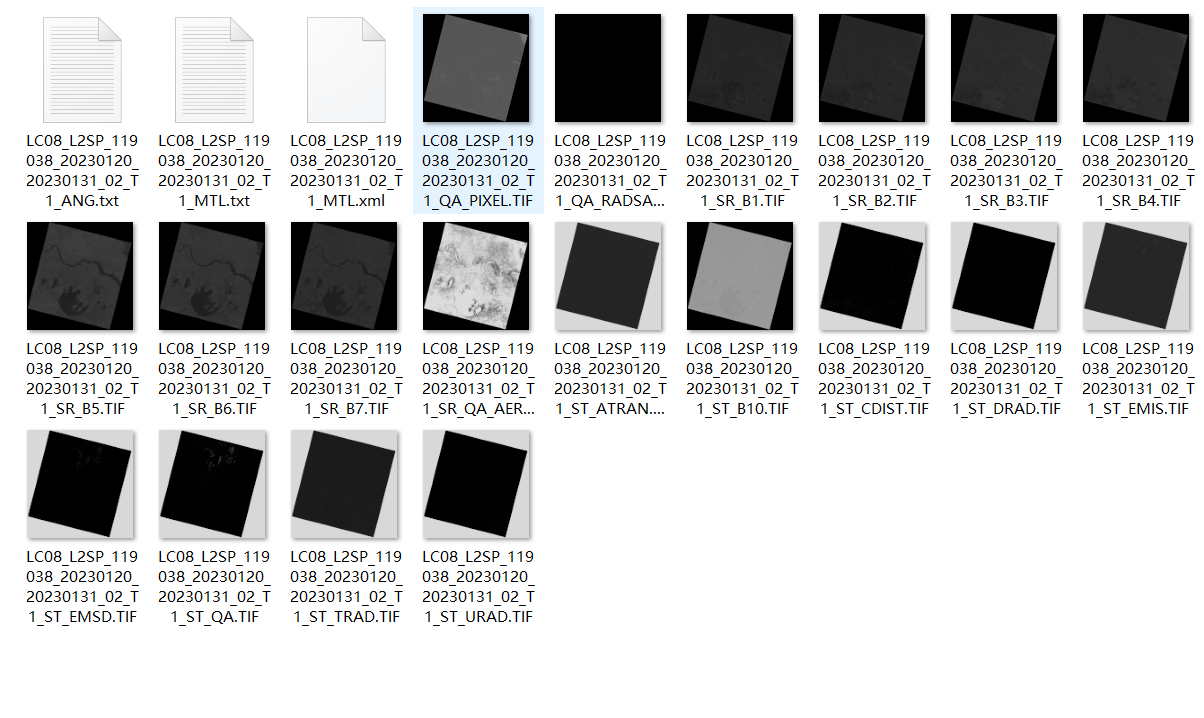
6.我们下载的数据为LC08_L2SP_119038_20230120_20230131_02_T1,数据为tar的压缩包

7.解压后的数据包括一些元数据、数据质量数据和光谱数据
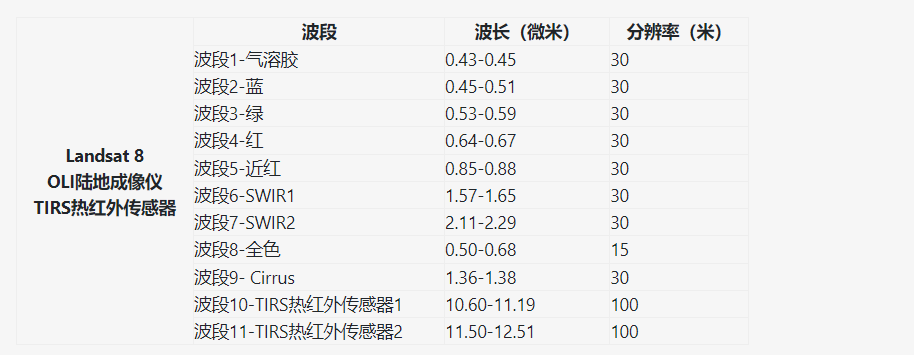
8.为方便后续将各个波段合成为一个tif(band1-7):将band1-7数据拖入envi中
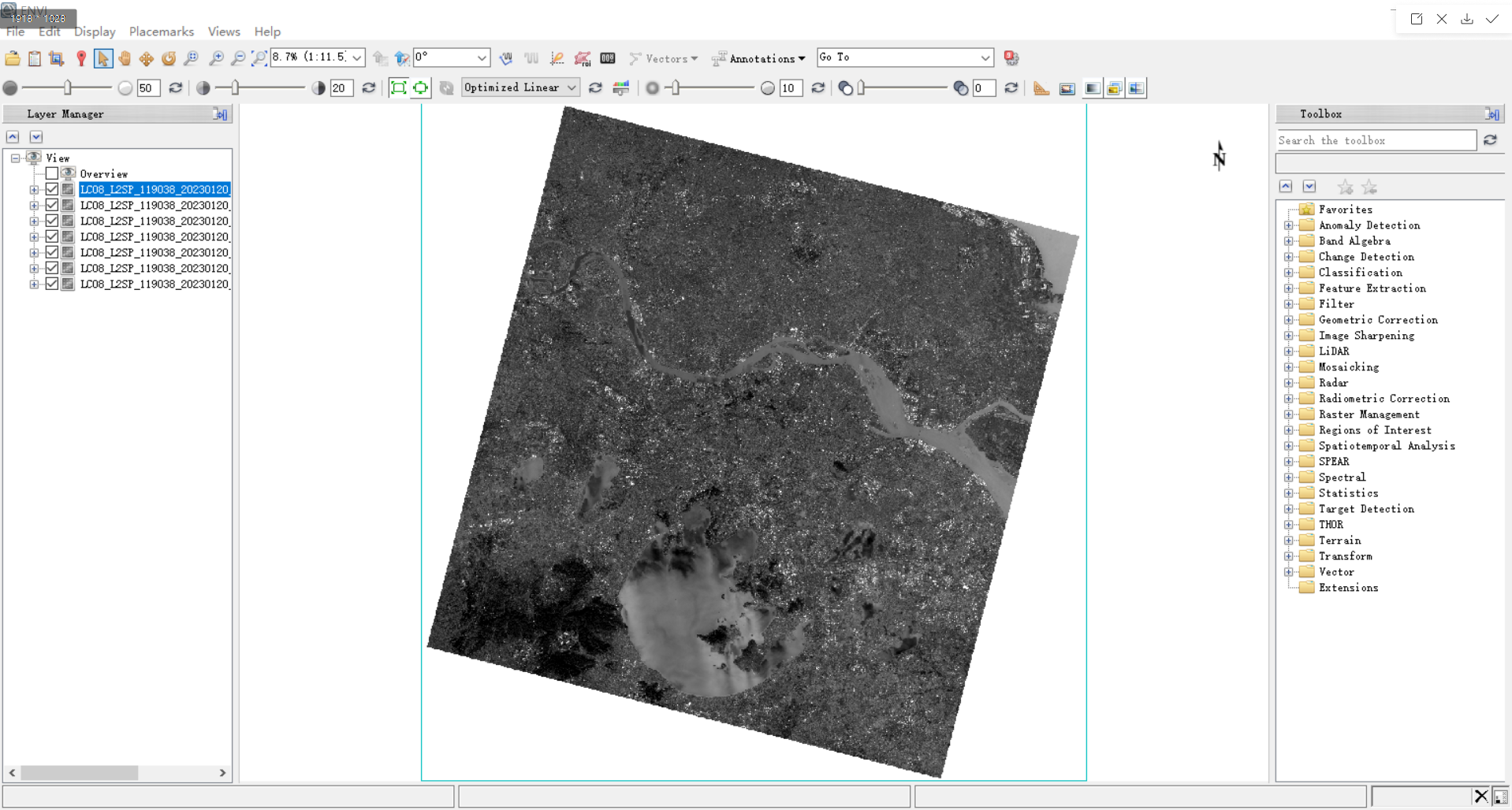
使用layer stacking将各波段数据合成到一个文件中
选择数据
调整波段顺序
选择保存位置

合成后的landsat1-7波段的band:432真彩色合成影像
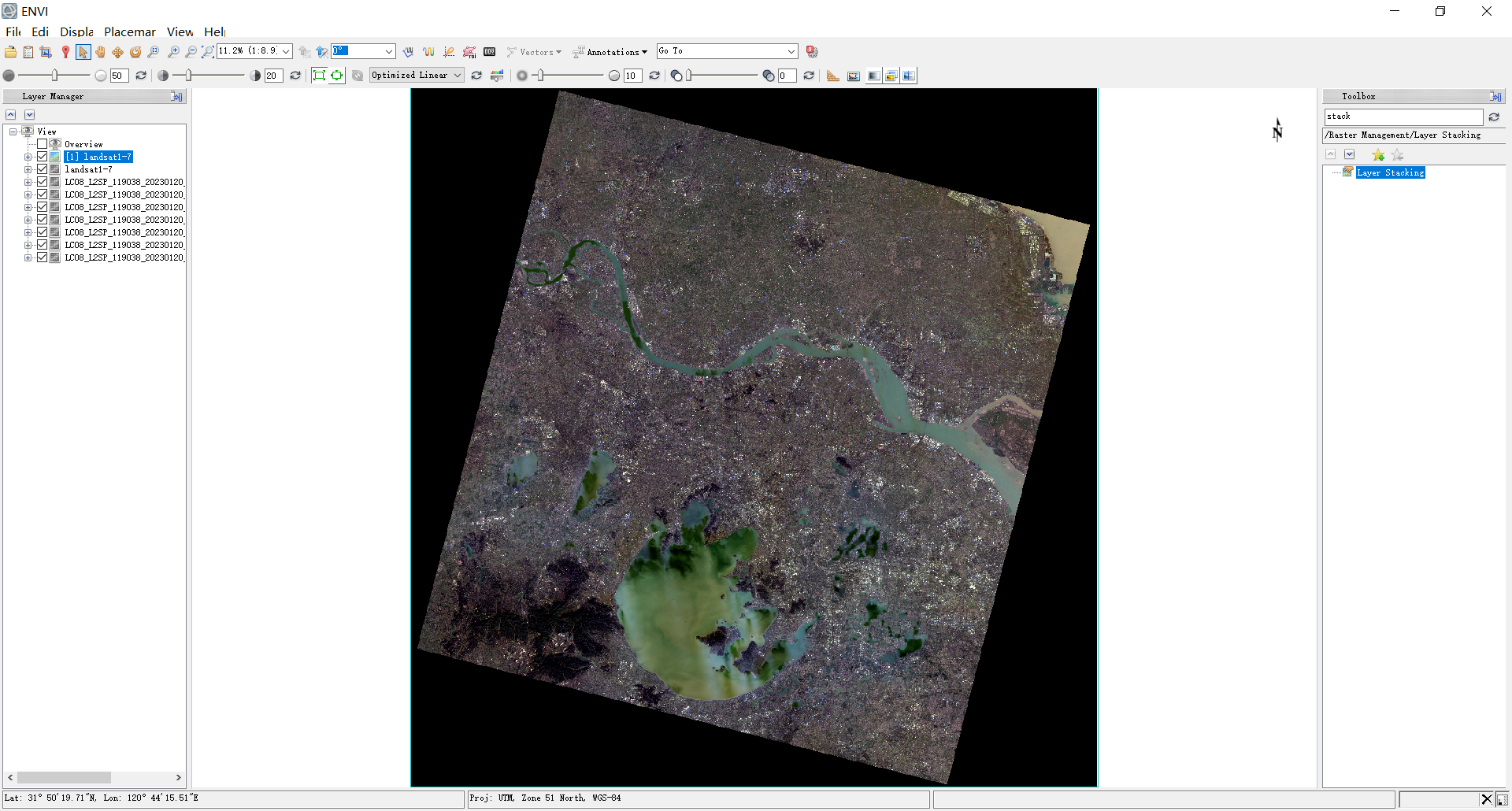
9.现在的数据还不是tif格式,是envi默认的格式,需要将其导出为tif
使用file的save as,将合成的影像导出为tif
到现在遥感影像数据已经获取并预处理完成,其坐标系为WGS_1984_UTM_Zone_51N,空间分辨率是30m。
2.2 站点数据预处理
站点数据往往是以表格的形式记录,包括.csv .xlsx等。表内记录为站点的经纬度以及站点监测的参数,坐标系统多为WGS_1984。因此我们要使用该数据需要进行一些列的处理:
- 将表格数据转为shp数据
- 统一为影像一致的坐标系
3 模型训练
由于我们已经将影像的光谱数据提取到了站点数据中,所以在模型训练环节只需要使用到站点数据。
3.1读取数据
1.右键station-rs-ml文件夹,用pycharm打开为项目
2.在settings中设置python环境为先前配置的带GDAL、sklearn和xgboot的环境
3.新建xgboot.py用来编写代码
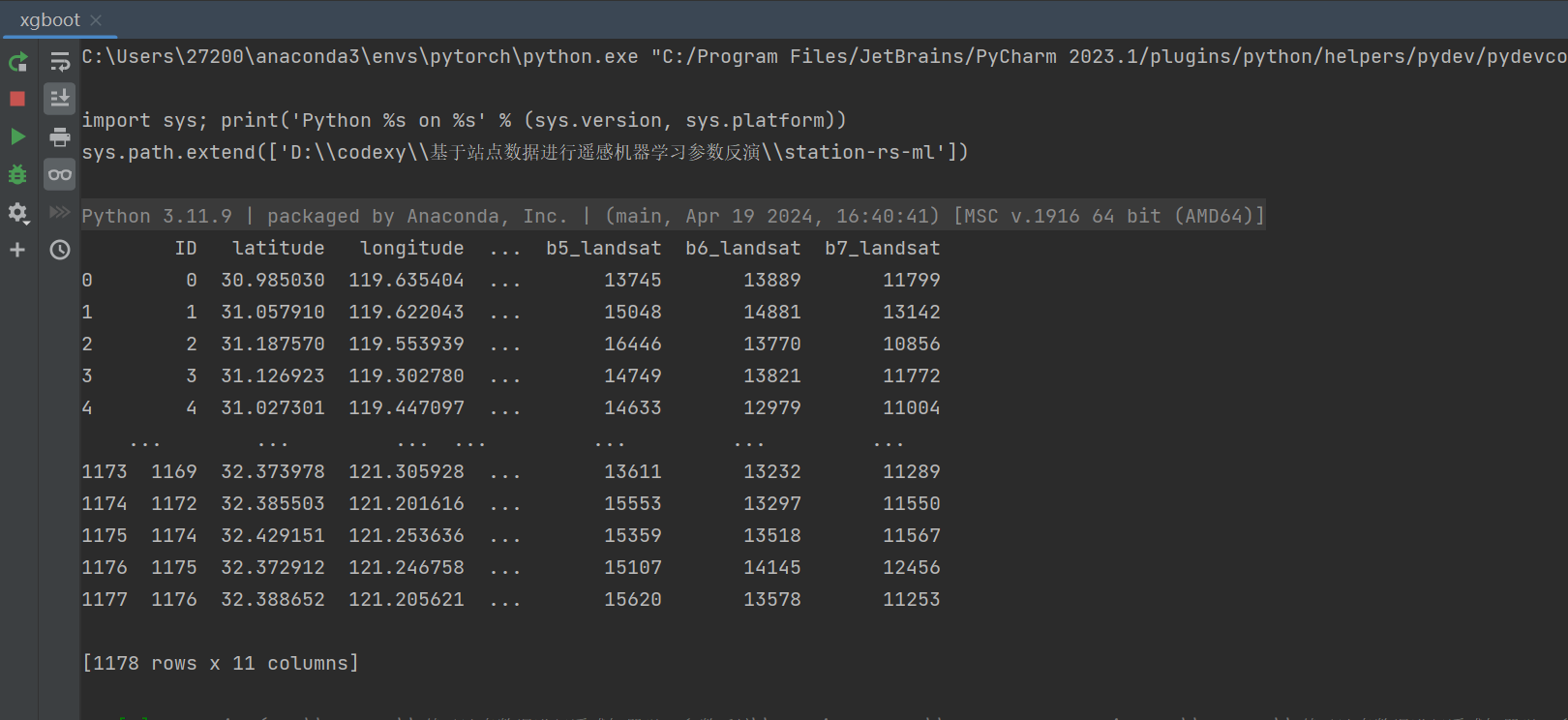
4.编写代码读取站点数据
详见文末
3.2 数据转换
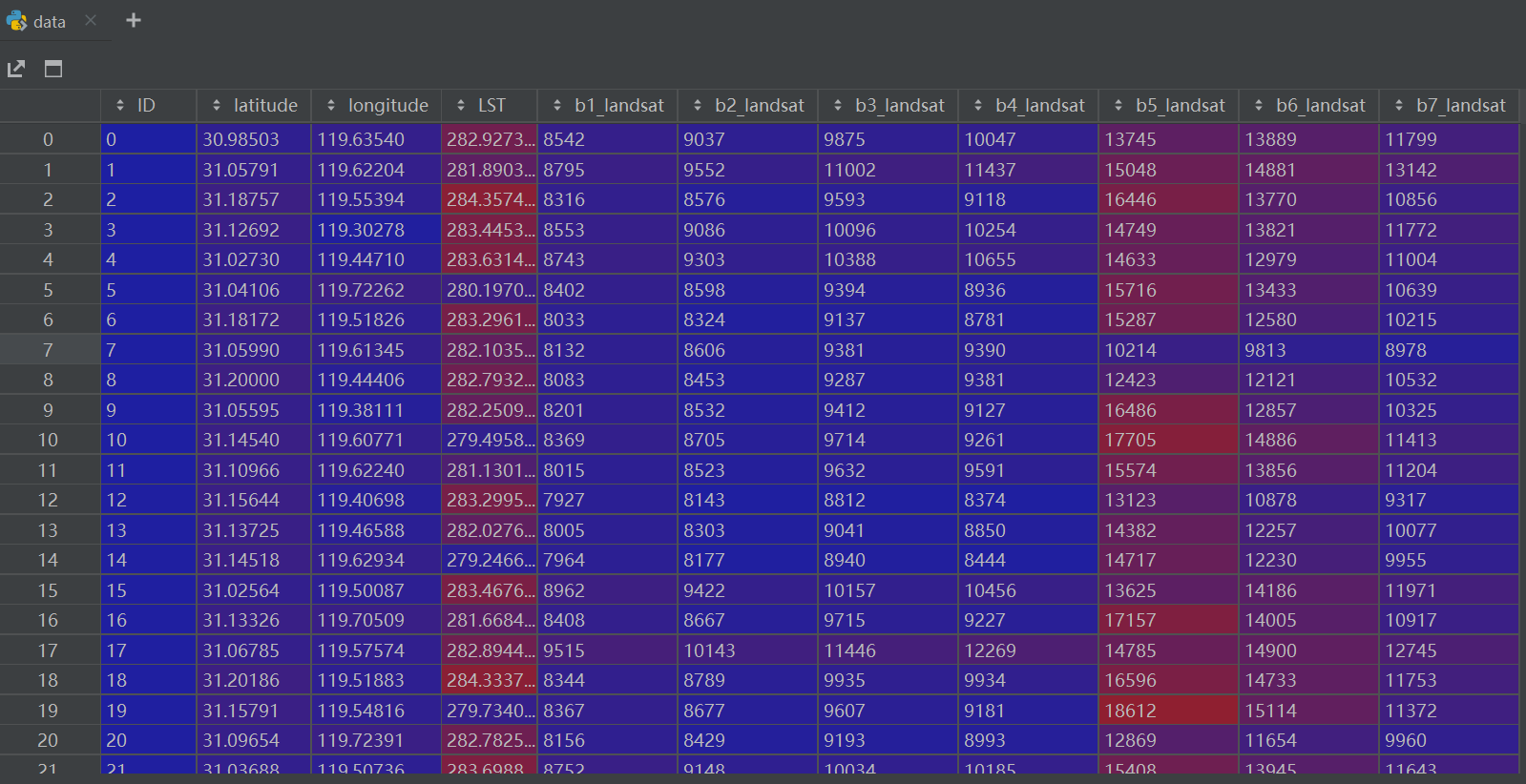
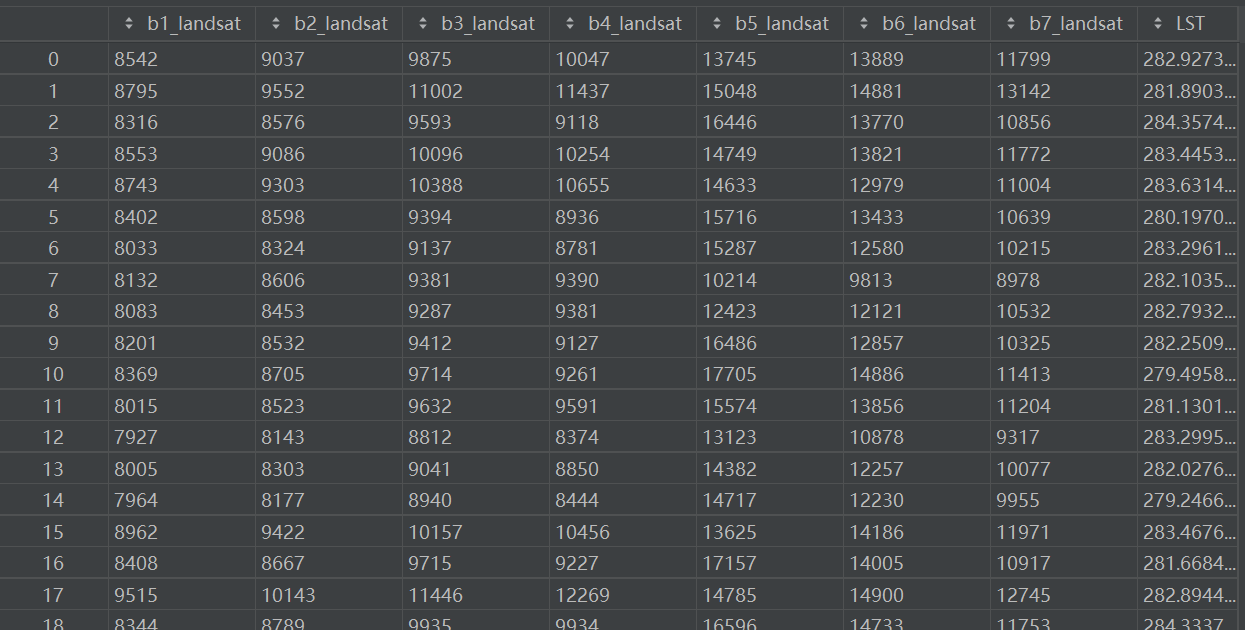
5.将对模型训练相关的字段提取出来整合成表的格式,整理成一个8列的表格,前7列是波段数据,最后一列是标签
# 从DataFrame中提取建模所需的字段:前7列为特征(7个波段),最后1列为标签(LST)
datas = data[['b1_landsat', 'b2_landsat', 'b3_landsat', 'b4_landsat', 'b5_landsat', 'b6_landsat', 'b7_landsat', 'LST']]
# 将DataFrame转换为numpy数组(机器学习模型通常接收数组输入)
datas = datas.to_numpy()
# 分割特征矩阵X(前7列,7个波段)和标签向量Y(第8列,LST)
x = datas[:, 0:7] # 特征:所有行,前7列
y = datas[:, 7] # 标签:所有行,第8列
6.将数据划分为训练集和测试集
# 初始化标准化器,对特征进行标准化(均值为0,方差为1,提升模型收敛速度和精度)
scaler = StandardScaler().fit(x) # 基于训练数据计算均值和方差
x = scaler.transform(x) # 对特征矩阵进行标准化转换
# 划分训练集和测试集:80%用于训练,20%用于测试,随机种子固定为1(保证结果可重现)
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size=0.8, random_state=1)3.3 模型构建
7.构建模型
3.4 模型调参与训练
8.模型调参
此处需要耐心等待,输出为:
1178 rows x 11 columns
Fitting 3 folds for each of 392 candidates, totalling 1176 fits
Best parameters found: {'max_depth': 3, 'min_child_weight': 7, 'n_estimators': 150}
Best RMSE score: 0.9799955550911522
9.模型保存
# 获取网格搜索得到的最优模型(性能最好的模型)
model_xgb = grid_search.best_estimator_
# 保存最优模型到本地(.pkl格式,后续可直接加载使用,无需重新训练)
joblib.dump(model_xgb, r'model_xgbr.pkl')3.5 精度分析
10.计算模型在测试数据集上的精度
# -------------------------- 模型评估(测试集) --------------------------
# 从本地加载保存的最优模型(模拟实际应用场景)
model_xgb = joblib.load(r'model_xgbr.pkl')
# 用测试集的特征预测LST值
pre_y = model_xgb.predict(x_test)
# 将测试集标签和预测结果展平为一维数组(确保维度一致,便于计算评估指标)
y_test = y_test.flatten()
pre_y = pre_y.flatten()
# 计算4个回归评估指标:R²、皮尔逊相关系数、MSE、MAE
r2 = r2_score(y_test, pre_y) # 决定系数(0-1,越接近1模型拟合越好)
r22 = scipy.stats.pearsonr(y_test, pre_y)[0] # 皮尔逊相关系数(-1~1,越接近1相关性越强)
mse = mean_squared_error(y_test, pre_y) # 均方误差(越小越好)
mae = mean_absolute_error(y_test, pre_y) # 平均绝对误差(越小越好)
# 打印评估指标结果(查看模型在测试集上的性能)
print(r2, r22, mse, mae)输出为:
0.605544516907159 0.7814613323142472 0.8021332337884101 0.7099408064150553
4 模型应用
模型应用是将训练好的模型应用到整张影像,此步使用到的是遥感影像数据以及训练好的模型。
4.1读取遥感影像
1.首先是定义读写影像的函数
2.读取影像
# -------------------------- 遥感影像预测(生成LST分布图) --------------------------
# 定义待预测的遥感影像路径(包含7个波段,与建模特征对应)
imgpath = r'data/landsat1-7.tif'
# 调用自定义函数,读取遥感影像的核心信息(投影、地理变换、尺寸、像素数据)
im_proj, im_geotrans, im_width, im_height, img_data = read_img(imgpath)
# 打印影像数据的形状(确认波段数和尺寸,应为(7, 高度, 宽度))
print(img_data.shape)输出:
(7, 7931, 7791),7表示有七个波段,7931, 7791分别为行列数
4.2影像数据表格化与归一化
3.将数据转换为表格格式并归一化
# 影像数据重塑:将(7, 高度, 宽度)转换为(像素总数, 7)的二维数组(每行对应一个像素的7个波段)
img_data_table = img_data.reshape(7, -1).T # reshape(7,-1)将高度×宽度合并为1列,T转置为行
# 对影像像素特征进行标准化(使用与训练集相同的标准化器逻辑)
scaler = StandardScaler().fit(img_data_table)
img_data_table = scaler.transform(img_data_table)4.3模型预测
# 用最优模型预测每个像素的LST值
pre_y = model_xgb.predict(img_data_table)4.4结果后处理与保存
预测结果如下:

landsat图

可以发现在水体和植被覆盖的地区温度偏低,建成区温度较高,还是比较符合实际情况的。
请见xy geedownload用户
或者xy搜索 基于站点数据的遥感参数反演全流程教程(附代码+数据)