一、打开软件
双击"Umi-OCR.exe"打开软件;

二、功能选择
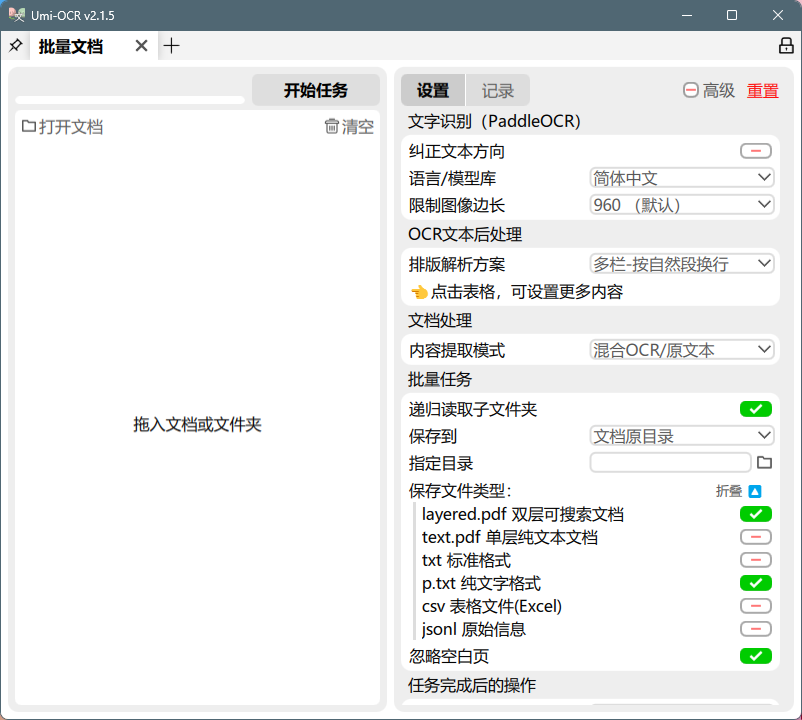
1、选择"批量文档";
2、勾选"递归读取子文件夹";
3、选择"保存到:文档原目录";
4、勾选"layered.pdf 双层可搜索文档";
5、勾选"p.txt 纯文字格式";
6、勾选"忽略空白页";
三、运行任务
1、选择需制作PDF的文件夹,拖入程序左侧窗口,耐心等待文件载入;
2、点击"开始任务",耐心等待任务运行;
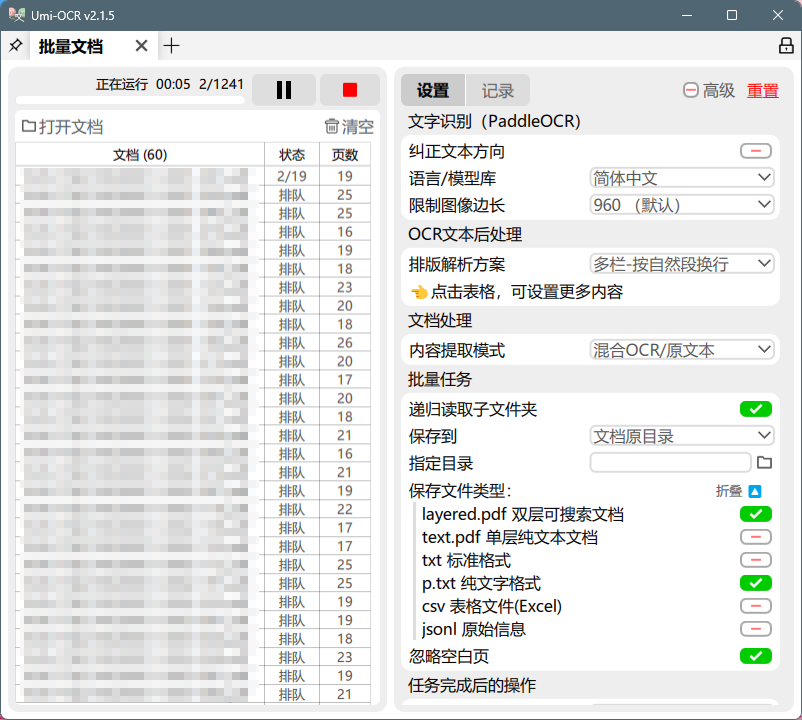
3、查看成果数据,双层PDF与同名TXT;

四、程序修改
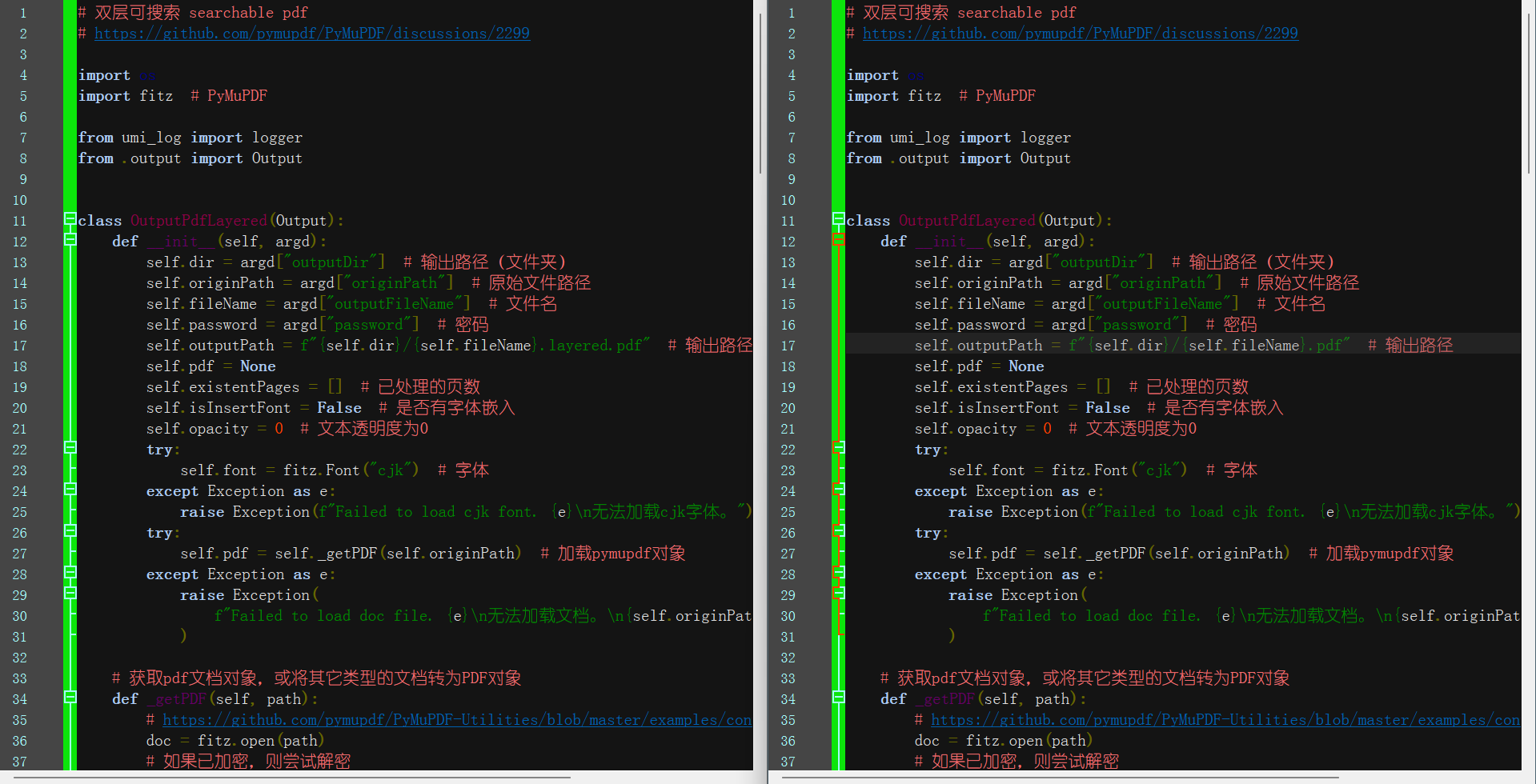
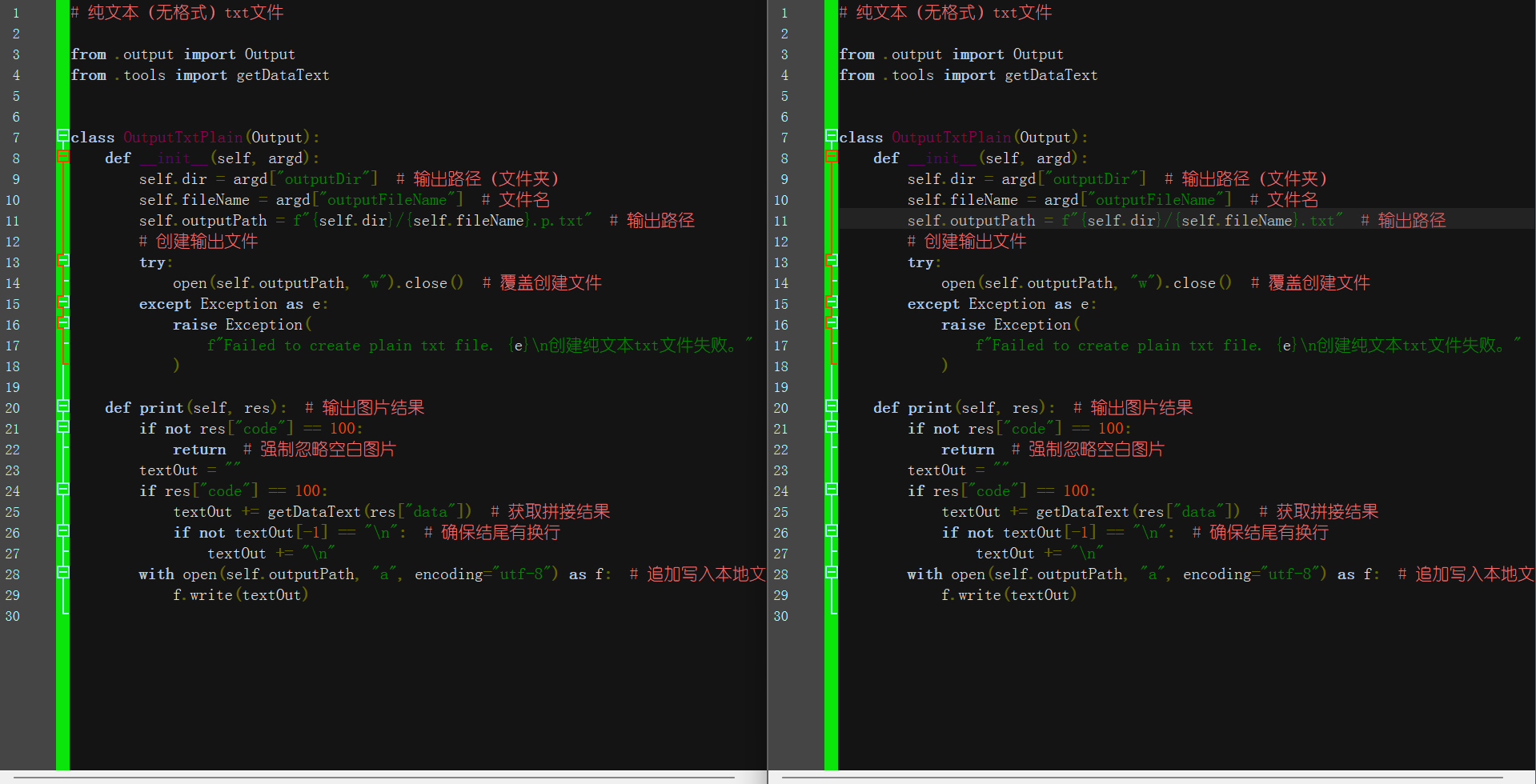
原始软件在"保存到:文档原目录"模式下,输出的双层PDF与TXT会增加前缀、后缀,通过修改PY代码实现覆盖保存需求。
1、output_pdf_layered.py;
2、output_txt_plain.py;
3、BatchDOC.py;