16 Dubbo Serialize 层:多种序列化算法,总有一款适合你
通过前面课时的介绍,我们知道一个 RPC 框架需要通过网络通信实现跨 JVM 的调用。既然需要网络通信,那就必然会使用到序列化与反序列化的相关技术,Dubbo 也不例外。下面我们从 Java 序列化的基础内容开始,介绍一下常见的序列化算法,最后再分析一下 Dubbo 是如何支持这些序列化算法的。
Java 序列化基础
Java 中的序列化操作一般有如下四个步骤。
第一步,被序列化的对象需要实现 Serializable 接口,示例代码如下:
java
public class Student implements Serializable {
private static final long serialVersionUID = 1L;
private String name;
private int age;
private transient StudentUtil studentUtil;
}在这个示例中我们可以看到transient 关键字 ,它的作用就是:在对象序列化过程中忽略被其修饰的成员属性变量。一般情况下,它可以用来修饰一些非数据型的字段以及一些可以通过其他字段计算得到的值。通过合理地使用 transient 关键字,可以降低序列化后的数据量,提高网络传输效率。
第二步,生成一个序列号 serialVersionUID,这个序列号不是必需的,但还是建议你生成。serialVersionUID 的字面含义是序列化的版本号,只有序列化和反序列化的 serialVersionUID 都相同的情况下,才能够成功地反序列化。如果类中没有定义 serialVersionUID,那么 JDK 也会随机生成一个 serialVersionUID。如果在某些场景中,你希望不同版本的类序列化和反序列化相互兼容,那就需要定义相同的 serialVersionUID。
第三步,根据需求决定是否要重写 writeObject()/readObject() 方法,实现自定义序列化。
最后一步,调用 java.io.ObjectOutputStream 的 writeObject()/readObject() 进行序列化与反序列化。
既然 Java 本身的序列化操作如此简单,那为什么市面上还依旧出现了各种各样的序列化框架呢?因为这些第三方序列化框架的速度更快、序列化的效率更高,而且支持跨语言操作。
常见序列化算法
为了帮助你快速了解 Dubbo 支持的序列化算法,我们这里就对其中常见的序列化算法进行简单介绍。
Apache Avro 是一种与编程语言无关的序列化格式。Avro 依赖于用户自定义的 Schema,在进行序列化数据的时候,无须多余的开销,就可以快速完成序列化,并且生成的序列化数据也较小。当进行反序列化的时候,需要获取到写入数据时用到的 Schema。在 Kafka、Hadoop 以及 Dubbo 中都可以使用 Avro 作为序列化方案。
FastJson 是阿里开源的 JSON 解析库,可以解析 JSON 格式的字符串。它支持将 Java 对象序列化为 JSON 字符串,反过来从 JSON 字符串也可以反序列化为 Java 对象。FastJson 是 Java 程序员常用到的类库之一,正如其名,"快"是其主要卖点。从官方的测试结果来看,FastJson 确实是最快的,比 Jackson 快 20% 左右,但是近几年 FastJson 的安全漏洞比较多,所以你在选择版本的时候,还是需要谨慎一些。
Fst(全称是 fast-serialization)是一款高性能 Java 对象序列化工具包,100% 兼容 JDK 原生环境,序列化速度大概是JDK 原生序列化的 4~10 倍,序列化后的数据大小是 JDK 原生序列化大小的 1⁄3 左右。目前,Fst 已经更新到 3.x 版本,支持 JDK 14。
Kryo 是一个高效的 Java 序列化/反序列化库,目前 Twitter、Yahoo、Apache 等都在使用该序列化技术,特别是 Spark、Hive 等大数据领域用得较多。Kryo 提供了一套快速、高效和易用的序列化 API。无论是数据库存储,还是网络传输,都可以使用 Kryo 完成 Java 对象的序列化。Kryo 还可以执行自动深拷贝和浅拷贝,支持环形引用。Kryo 的特点是 API 代码简单,序列化速度快,并且序列化之后得到的数据比较小。另外,Kryo 还提供了 NIO 的网络通信库------KryoNet,你若感兴趣的话可以自行查询和了解一下。
Hessian2 序列化是一种支持动态类型、跨语言的序列化协议,Java 对象序列化的二进制流可以被其他语言使用。Hessian2 序列化之后的数据可以进行自描述,不会像 Avro 那样依赖外部的 Schema 描述文件或者接口定义。Hessian2 可以用一个字节表示常用的基础类型,这极大缩短了序列化之后的二进制流。需要注意的是,在 Dubbo 中使用的 Hessian2 序列化并不是原生的 Hessian2 序列化,而是阿里修改过的 Hessian Lite,它是 Dubbo 默认使用的序列化方式。其序列化之后的二进制流大小大约是 Java 序列化的 50%,序列化耗时大约是 Java 序列化的 30%,反序列化耗时大约是 Java 序列化的 20%。
Protobuf(Google Protocol Buffers)是 Google 公司开发的一套灵活、高效、自动化的、用于对结构化数据进行序列化的协议。但相比于常用的 JSON 格式,Protobuf 有更高的转化效率,时间效率和空间效率都是 JSON 的 5 倍左右。Protobuf 可用于通信协议、数据存储等领域,它本身是语言无关、平台无关、可扩展的序列化结构数据格式。目前 Protobuf提供了 C++、Java、Python、Go 等多种语言的 API,gRPC 底层就是使用 Protobuf 实现的序列化。
dubbo-serialization
Dubbo 为了支持多种序列化算法,单独抽象了一层 Serialize 层,在整个 Dubbo 架构中处于最底层,对应的模块是 dubbo-serialization 模块。 dubbo-serialization 模块的结构如下图所示:
dubbo-serialization-api 模块中定义了 Dubbo 序列化层的核心接口,其中最核心的是 Serialization 这个接口,它是一个扩展接口,被 @SPI 接口修饰,默认扩展实现是 Hessian2Serialization。Serialization 接口的具体实现如下:
java
@SPI("hessian2") // 被@SPI注解修饰,默认是使用hessian2序列化算法
public interface Serialization {
// 每一种序列化算法都对应一个ContentType,该方法用于获取ContentType
String getContentType();
// 获取ContentType的ID值,是一个byte类型的值,唯一确定一个算法
byte getContentTypeId();
// 创建一个ObjectOutput对象,ObjectOutput负责实现序列化的功能,即将Java
// 对象转化为字节序列
@Adaptive
ObjectOutput serialize(URL url, OutputStream output) throws IOException;
// 创建一个ObjectInput对象,ObjectInput负责实现反序列化的功能,即将
// 字节序列转换成Java对象
@Adaptive
ObjectInput deserialize(URL url, InputStream input) throws IOException;
}Dubbo 提供了多个 Serialization 接口实现,用于接入各种各样的序列化算法,如下图所示:

这里我们以默认的 hessian2 序列化方式为例,介绍 Serialization 接口的实现以及其他相关实现。 Hessian2Serialization 实现如下所示:
java
public class Hessian2Serialization implements Serialization {
public byte getContentTypeId() {
return HESSIAN2_SERIALIZATION_ID; // hessian2的ContentType ID
}
public String getContentType() { // hessian2的ContentType
return "x-application/hessian2";
}
public ObjectOutput serialize(URL url, OutputStream out) throws IOException { // 创建ObjectOutput对象
return new Hessian2ObjectOutput(out);
}
public ObjectInput deserialize(URL url, InputStream is) throws IOException { // 创建ObjectInput对象
return new Hessian2ObjectInput(is);
}
}Hessian2Serialization 中的 serialize() 方法创建的 ObjectOutput 接口实现为 Hessian2ObjectOutput,继承关系如下图所示:

在 DataOutput 接口中定义了序列化 Java 中各种数据类型的相应方法,如下图所示,其中有序列化 boolean、short、int、long 等基础类型的方法,也有序列化 String、byte\[\] 的方法。

ObjectOutput 接口继承了 DataOutput 接口,并在其基础之上,添加了序列化对象的功能,具体定义如下图所示,其中的 writeThrowable()、writeEvent() 和 writeAttachments() 方法都是调用 writeObject() 方法实现的。

Hessian2ObjectOutput 中会封装一个 Hessian2Output 对象,需要注意,这个对象是 ThreadLocal 的,与线程绑定。在 DataOutput 接口以及 ObjectOutput 接口中,序列化各类型数据的方法都会委托给 Hessian2Output 对象的相应方法完成,实现如下:
java
public class Hessian2ObjectOutput implements ObjectOutput {
private static ThreadLocal<Hessian2Output> OUTPUT_TL = ThreadLocal.withInitial(() -> {
// 初始化Hessian2Output对象
Hessian2Output h2o = new Hessian2Output(null); h2o.setSerializerFactory(Hessian2SerializerFactory.SERIALIZER_FACTORY);
h2o.setCloseStreamOnClose(true);
return h2o;
});
private final Hessian2Output mH2o;
public Hessian2ObjectOutput(OutputStream os) {
mH2o = OUTPUT_TL.get(); // 触发OUTPUT_TL的初始化
mH2o.init(os);
}
public void writeObject(Object obj) throws IOException {
mH2o.writeObject(obj);
}
... // 省略序列化其他类型数据的方法
}Hessian2Serialization 中的 deserialize() 方法创建的 ObjectInput 接口实现为 Hessian2ObjectInput,继承关系如下所示:

Hessian2ObjectInput 具体的实现与 Hessian2ObjectOutput 类似:在 DataInput 接口中实现了反序列化各种类型的方法,在 ObjectInput 接口中提供了反序列化 Java 对象的功能,在 Hessian2ObjectInput 中会将所有反序列化的实现委托为 Hessian2Input。
了解了 Dubbo Serialize 层的核心接口以及 Hessian2 序列化算法的接入方式之后,你就可以亲自动手,去阅读其他序列化算法对应模块的代码。
总结
在本课时,我们首先介绍了 Java 序列化的基础知识,帮助你快速了解序列化和反序列化的基本概念。然后,介绍了常见的序列化算法,例如,Arvo、Fastjson、Fst、Kryo、Hessian、Protobuf 等。最后,深入分析了 dubbo-serialization 模块对各个序列化算法的接入方式,其中重点说明了 Hessian2 序列化方式。
17 Dubbo Remoting 层核心接口分析:这居然是一套兼容所有 NIO 框架的设计?
在本专栏的第二部分,我们深入介绍了 Dubbo 注册中心的相关实现,下面我们开始介绍 dubbo-remoting 模块,该模块提供了多种客户端和服务端通信的功能。在 Dubbo 的整体架构设计图中,我们可以看到最底层红色框选中的部分即为 Remoting 层,其中包括了 Exchange、Transport和Serialize 三个子层次。这里我们要介绍的 dubbo-remoting 模块主要对应 Exchange 和 Transport 两层。
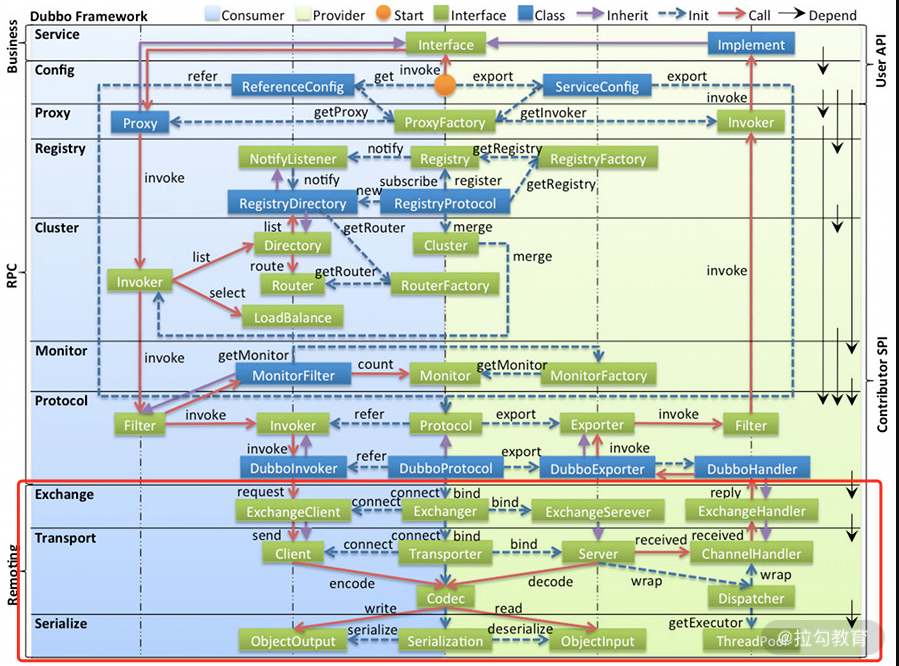
Dubbo 整体架构设计图
Dubbo 并没有自己实现一套完整的网络库,而是使用现有的、相对成熟的第三方网络库,例如,Netty、Mina 或是 Grizzly 等 NIO 框架。我们可以根据自己的实际场景和需求修改配置,选择底层使用的 NIO 框架。
下图展示了 dubbo-remoting 模块的结构,其中每个子模块对应一个第三方 NIO 框架,例如,dubbo-remoting-netty4 子模块使用 Netty4 实现 Dubbo 的远程通信,dubbo-remoting-grizzly 子模块使用 Grizzly 实现 Dubbo 的远程通信。
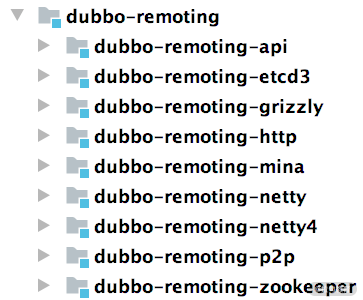
其中的 dubbo-remoting-zookeeper,我们在前面第 15 课时介绍基于 Zookeeper 的注册中心实现时已经讲解过了,它使用 Apache Curator 实现了与 Zookeeper 的交互。
dubbo-remoting-api 模块
需要注意的是,Dubbo 的 dubbo-remoting-api 是其他 dubbo-remoting-* 模块的顶层抽象,其他 dubbo-remoting 子模块都是依赖第三方 NIO 库实现 dubbo-remoting-api 模块的,依赖关系如下图所示:
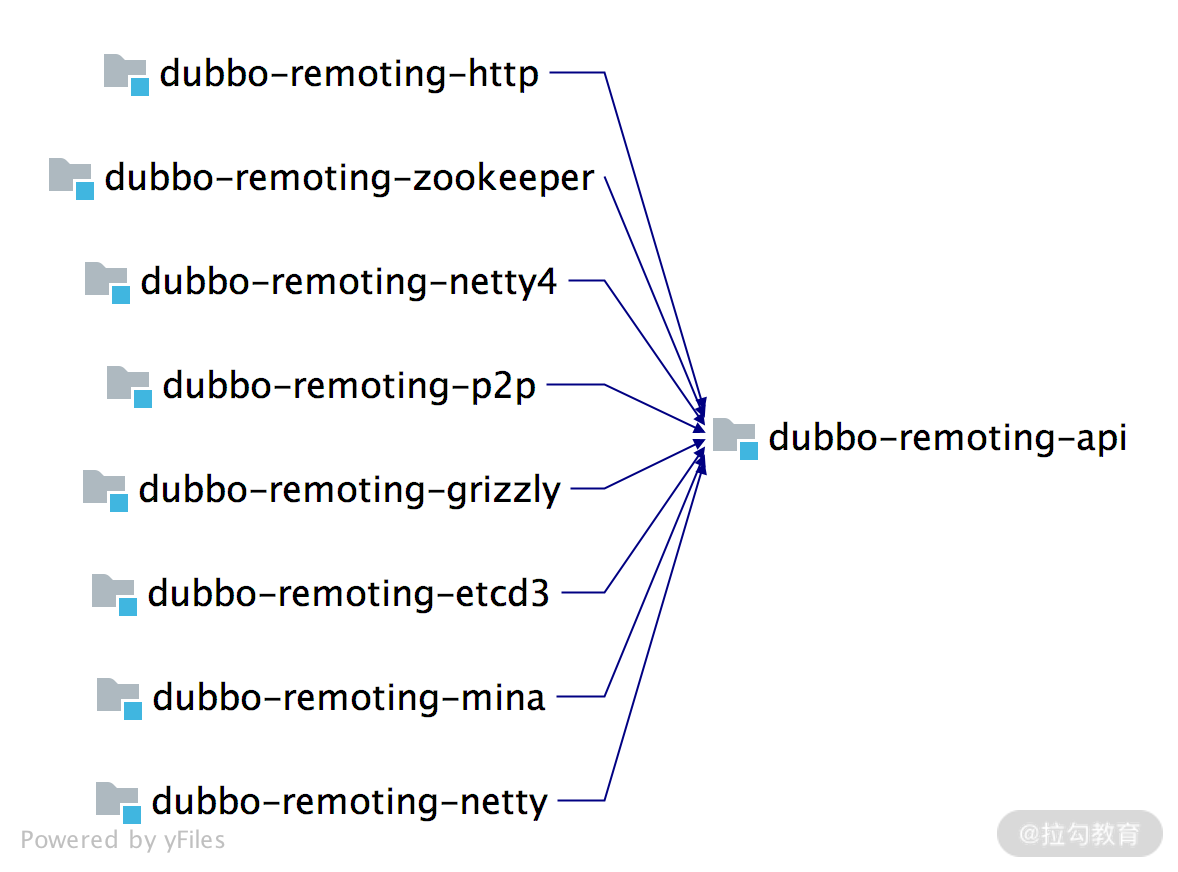
我们先来看一下 dubbo-remoting-api 中对整个 Remoting 层的抽象,dubbo-remoting-api 模块的结构如下图所示:
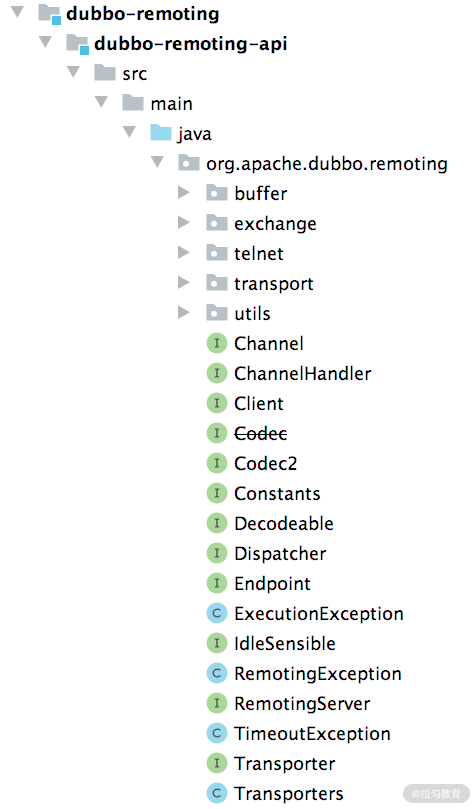
一般情况下,我们会将功能类似或是相关联的类放到一个包中,所以我们需要先来了解 dubbo-remoting-api 模块中各个包的功能。
- buffer 包:定义了缓冲区相关的接口、抽象类以及实现类。缓冲区在NIO框架中是一个不可或缺的角色,在各个 NIO 框架中都有自己的缓冲区实现。这里的 buffer 包在更高的层面,抽象了各个 NIO 框架的缓冲区,同时也提供了一些基础实现。
- exchange 包:抽象了 Request 和 Response 两个概念,并为其添加很多特性。这是整个远程调用非常核心的部分。
- transport 包:对网络传输层的抽象,但它只负责抽象单向消息的传输,即请求消息由 Client 端发出,Server 端接收;响应消息由 Server 端发出,Client端接收。有很多网络库可以实现网络传输的功能,例如 Netty、Grizzly 等, transport 包是在这些网络库上层的一层抽象。
- 其他接口:Endpoint、Channel、Transporter、Dispatcher 等顶层接口放到了org.apache.dubbo.remoting 这个包,这些接口是 Dubbo Remoting 的核心接口。
下面我们就来介绍 Dubbo 是如何抽象这些核心接口的。
传输层核心接口
在 Dubbo 中会抽象出一个"端点(Endpoint) "的概念,我们可以通过一个 ip 和 port 唯一确定一个端点,两个端点之间会创建 TCP 连接,可以双向传输数据。Dubbo 将 Endpoint 之间的 TCP 连接抽象为通道(Channel) ,将发起请求的 Endpoint 抽象为客户端(Client) ,将接收请求的 Endpoint 抽象为服务端(Server)。这些抽象出来的概念,也是整个 dubbo-remoting-api 模块的基础,下面我们会逐个进行介绍。
Dubbo 中Endpoint 接口的定义如下:
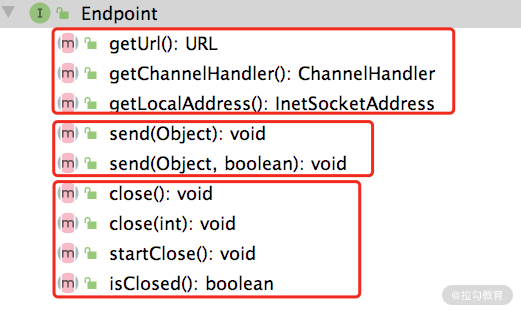
如上图所示,这里的 get*() 方法是获得 Endpoint 本身的一些属性,其中包括获取 Endpoint 的本地地址、关联的 URL 信息以及底层 Channel 关联的 ChannelHandler。send() 方法负责数据发送,两个重载的区别在后面介绍 Endpoint 实现的时候我们再详细说明。最后两个 close() 方法的重载以及 startClose() 方法用于关闭底层 Channel ,isClosed() 方法用于检测底层 Channel 是否已关闭。
Channel 是对两个 Endpoint 连接的抽象,好比连接两个位置的传送带,两个 Endpoint 传输的消息就好比传送带上的货物,消息发送端会往 Channel 写入消息,而接收端会从 Channel 读取消息。这与第 10 课时介绍的 Netty 中的 Channel 基本一致。
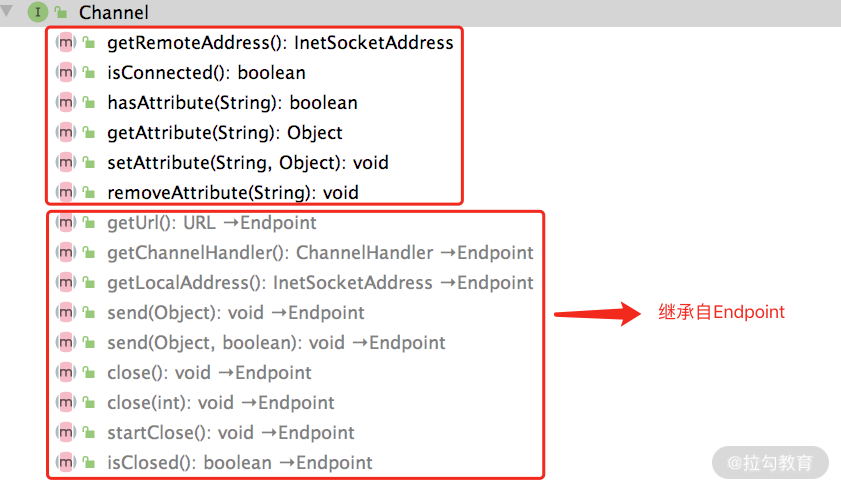
下面是Channel 接口的定义,我们可以看出两点:一个是 Channel 接口继承了 Endpoint 接口,也具备开关状态以及发送数据的能力;另一个是可以在 Channel 上附加 KV 属性。
ChannelHandler 是注册在 Channel 上的消息处理器,在 Netty 中也有类似的抽象,相信你对此应该不会陌生。下图展示了 ChannelHandler 接口的定义,在 ChannelHandler 中可以处理 Channel 的连接建立以及连接断开事件,还可以处理读取到的数据、发送的数据以及捕获到的异常。从这些方法的命名可以看到,它们都是动词的过去式,说明相应事件已经发生过了。

需要注意的是:ChannelHandler 接口被 @SPI 注解修饰,表示该接口是一个扩展点。
在前面课时介绍 Netty 的时候,我们提到过有一类特殊的 ChannelHandler 专门负责实现编解码功能,从而实现字节数据与有意义的消息之间的转换,或是消息之间的相互转换。在dubbo-remoting-api 中也有相似的抽象,如下所示:
java
@SPI
public interface Codec2 {
@Adaptive({Constants.CODEC_KEY})
void encode(Channel channel, ChannelBuffer buffer, Object message) throws IOException;
@Adaptive({Constants.CODEC_KEY})
Object decode(Channel channel, ChannelBuffer buffer) throws IOException;
enum DecodeResult {
NEED_MORE_INPUT, SKIP_SOME_INPUT
}
}这里需要关注的是 Codec2 接口被 @SPI 接口修饰了,表示该接口是一个扩展接口,同时其 encode() 方法和 decode() 方法都被 @Adaptive 注解修饰,也就会生成适配器类,其中会根据 URL 中的 codec 值确定具体的扩展实现类。
DecodeResult 这个枚举是在处理 TCP 传输时粘包和拆包使用的,之前简易版本 RPC 也处理过这种问题,例如,当前能读取到的数据不足以构成一个消息时,就会使用 NEED_MORE_INPUT 这个枚举。
接下来看Client 和 RemotingServer 两个接口,分别抽象了客户端和服务端,两者都继承了 Channel、Resetable 等接口,也就是说两者都具备了读写数据能力。
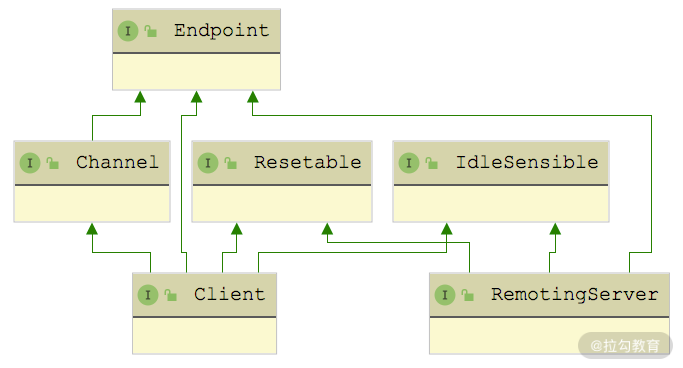
Client 和 Server 本身都是 Endpoint,只不过在语义上区分了请求和响应的职责,两者都具备发送的能力,所以都继承了 Endpoint 接口。Client 和 Server 的主要区别是 Client 只能关联一个 Channel,而 Server 可以接收多个 Client 发起的 Channel 连接。所以在 RemotingServer 接口中定义了查询 Channel 的相关方法,如下图所示:

Dubbo 在 Client 和 Server 之上又封装了一层Transporter 接口,其具体定义如下:
java
@SPI("netty")
public interface Transporter {
@Adaptive({Constants.SERVER_KEY, Constants.TRANSPORTER_KEY})
RemotingServer bind(URL url, ChannelHandler handler) throws RemotingException;
@Adaptive({Constants.CLIENT_KEY, Constants.TRANSPORTER_KEY})
Client connect(URL url, ChannelHandler handler) throws RemotingException;
}我们看到 Transporter 接口上有 @SPI 注解,它是一个扩展接口,默认使用"netty"这个扩展名,@Adaptive 注解的出现表示动态生成适配器类,会先后根据"server""transporter"的值确定 RemotingServer 的扩展实现类,先后根据"client""transporter"的值确定 Client 接口的扩展实现。
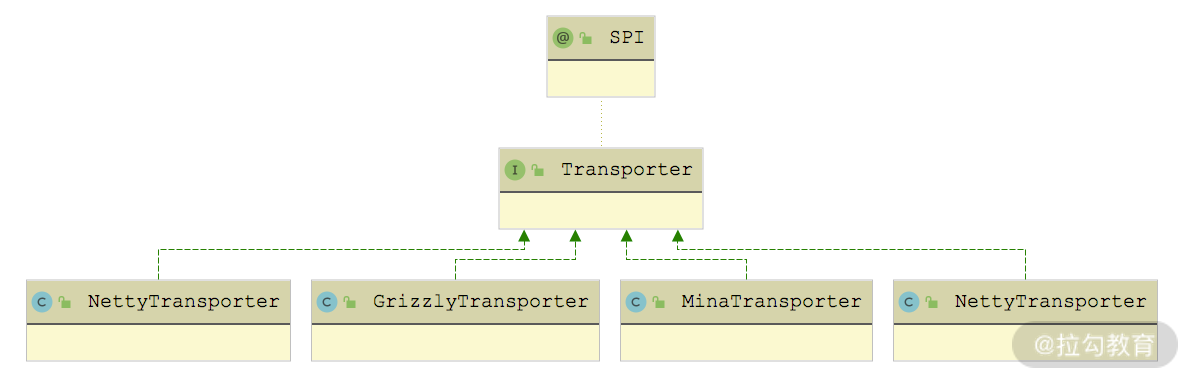
Transporter 接口的实现有哪些呢?如下图所示,针对每个支持的 NIO 库,都有一个 Transporter 接口实现,散落在各个 dubbo-remoting-* 实现模块中。
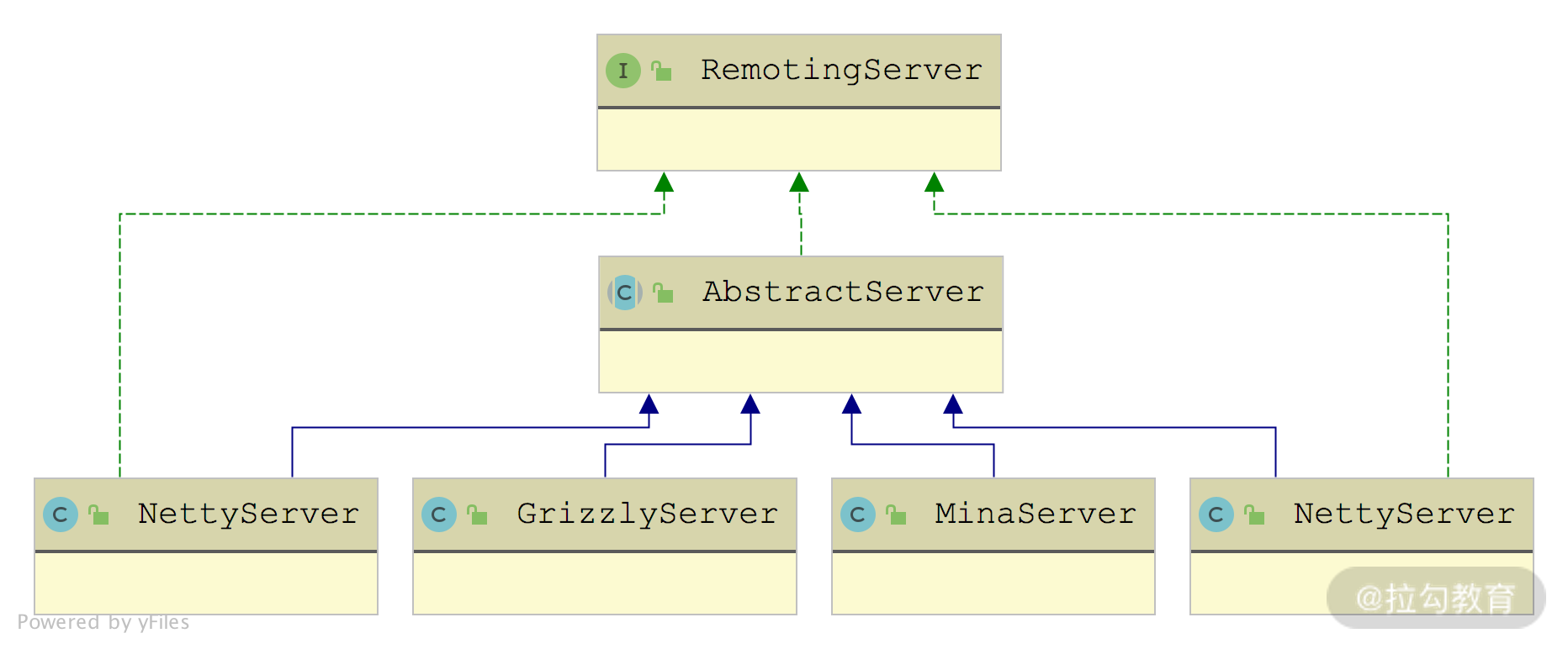
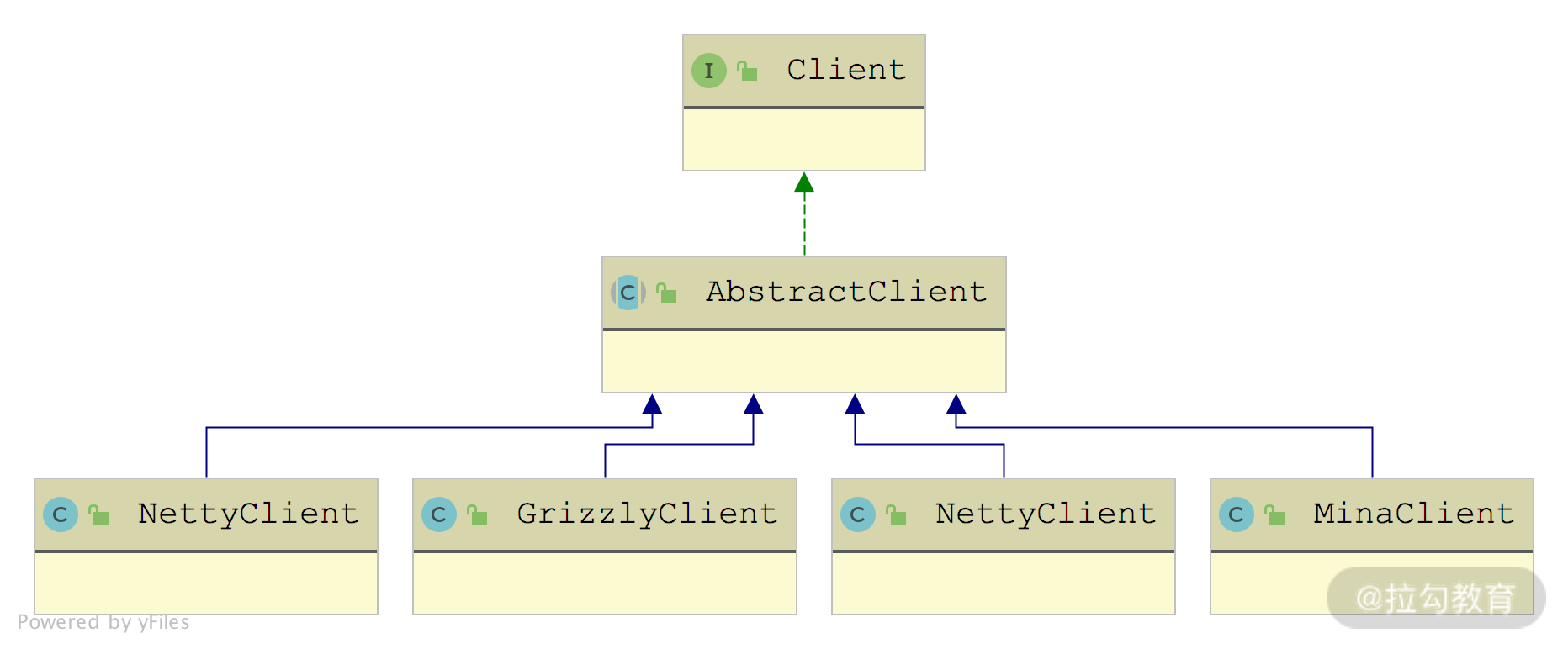
这些 Transporter 接口实现返回的 Client 和 RemotingServer 具体是什么呢?如下图所示,返回的是 NIO 库对应的 RemotingServer 实现和 Client 实现。
相信看到这里,你应该已经发现 Transporter 这一层抽象出来的接口,与 Netty 的核心接口是非常相似的。那为什么要单独抽象出 Transporter层,而不是像简易版 RPC 框架那样,直接让上层使用 Netty 呢?
其实这个问题的答案也呼之欲出了,Netty、Mina、Grizzly 这个 NIO 库对外接口和使用方式不一样,如果在上层直接依赖了 Netty 或是 Grizzly,就依赖了具体的 NIO 库实现,而不是依赖一个有传输能力的抽象,后续要切换实现的话,就需要修改依赖和接入的相关代码,非常容易改出 Bug。这也不符合设计模式中的开放-封闭原则。
有了 Transporter 层之后,我们可以通过 Dubbo SPI 修改使用的具体 Transporter 扩展实现,从而切换到不同的 Client 和 RemotingServer 实现,达到底层 NIO 库切换的目的,而且无须修改任何代码。即使有更先进的 NIO 库出现,我们也只需要开发相应的 dubbo-remoting-* 实现模块提供 Transporter、Client、RemotingServer 等核心接口的实现,即可接入,完全符合开放-封闭原则。
在最后,我们还要看一个类------Transporters ,它不是一个接口,而是门面类,其中封装了 Transporter 对象的创建(通过 Dubbo SPI)以及 ChannelHandler 的处理,如下所示:
java
public class Transporters {
private Transporters() {
// 省略bind()和connect()方法的重载
public static RemotingServer bind(URL url, ChannelHandler... handlers) throws RemotingException {
ChannelHandler handler;
if (handlers.length == 1) {
handler = handlers[0];
} else {
handler = new ChannelHandlerDispatcher(handlers);
}
return getTransporter().bind(url, handler);
}
public static Client connect(URL url, ChannelHandler... handlers) throws RemotingException {
ChannelHandler handler;
if (handlers == null || handlers.length == 0) {
handler = new ChannelHandlerAdapter();
} else if (handlers.length == 1) {
handler = handlers[0];
} else { // ChannelHandlerDispatcher
handler = new ChannelHandlerDispatcher(handlers);
}
return getTransporter().connect(url, handler);
}
public static Transporter getTransporter() {
// 自动生成Transporter适配器并加载
return ExtensionLoader.getExtensionLoader(Transporter.class)
.getAdaptiveExtension();
}
}在创建 Client 和 RemotingServer 的时候,可以指定多个 ChannelHandler 绑定到 Channel 来处理其中传输的数据。Transporters.connect() 方法和 bind() 方法中,会将多个 ChannelHandler 封装成一个 ChannelHandlerDispatcher 对象。
ChannelHandlerDispatcher 也是 ChannelHandler 接口的实现类之一,维护了一个 CopyOnWriteArraySet 集合,它所有的 ChannelHandler 接口实现都会调用其中每个 ChannelHandler 元素的相应方法。另外,ChannelHandlerDispatcher 还提供了增删该 ChannelHandler 集合的相关方法。
到此为止,Dubbo Transport 层的核心接口就介绍完了,这里简单总结一下:
- Endpoint 接口抽象了"端点"的概念,这是所有抽象接口的基础。
- 上层使用方会通过 Transporters 门面类获取到 Transporter 的具体扩展实现,然后通过 Transporter 拿到相应的 Client 和 RemotingServer 实现,就可以建立(或接收)Channel 与远端进行交互了。
- 无论是 Client 还是 RemotingServer,都会使用 ChannelHandler 处理 Channel 中传输的数据,其中负责编解码的 ChannelHandler 被抽象出为 Codec2 接口。
整个架构如下图所示,与 Netty 的架构非常类似。
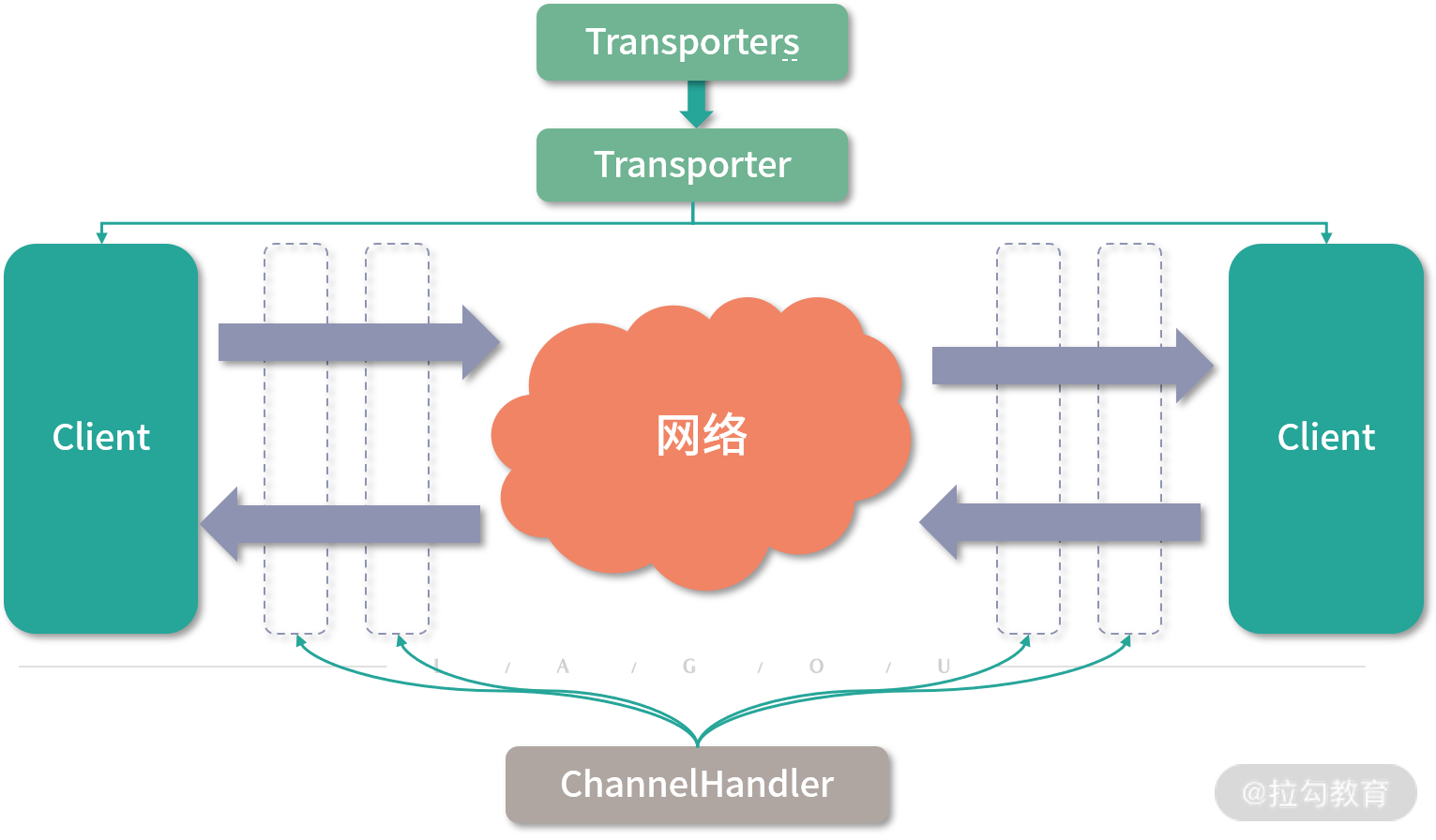
Transporter 层整体结构图
总结
本课时我们首先介绍了 dubbo-remoting 模块在 Dubbo 架构中的位置,以及 dubbo-remoting 模块的结构。接下来分析了 dubbo-remoting 模块中各个子模块之间的依赖关系,并重点介绍了 dubbo-remoting-api 子模块中各个包的核心功能。最后我们还深入分析了整个 Transport 层的核心接口,以及这些接口抽象出来的 Transporter 架构。
18 Buffer 缓冲区:我们不生产数据,我们只是数据的搬运工
Buffer 是一种字节容器,在 Netty 等 NIO 框架中都有类似的设计,例如,Java NIO 中的ByteBuffer、Netty4 中的 ByteBuf。Dubbo 抽象出了 ChannelBuffer 接口对底层 NIO 框架中的 Buffer 设计进行统一,其子类如下图所示:
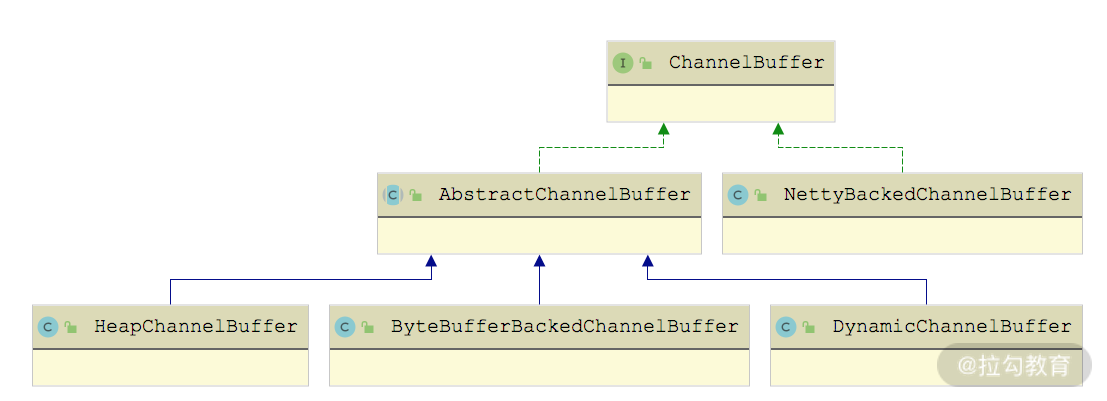
ChannelBuffer 继承关系图
下面我们就按照 ChannelBuffer 的继承结构,从顶层的 ChannelBuffer 接口开始,逐个向下介绍,直至最底层的各个实现类。
ChannelBuffer 接口
ChannelBuffer 接口的设计与 Netty4 中 ByteBuf 抽象类的设计基本一致,也有 readerIndex 和 writerIndex 指针的概念,如下所示,它们的核心方法也是如出一辙。
- getBytes()、setBytes() 方法:从参数指定的位置读、写当前 ChannelBuffer,不会修改 readerIndex 和 writerIndex 指针的位置。
- readBytes() 、writeBytes() 方法:也是读、写当前 ChannelBuffer,但是 readBytes() 方法会从 readerIndex 指针开始读取数据,并移动 readerIndex 指针;writeBytes() 方法会从 writerIndex 指针位置开始写入数据,并移动 writerIndex 指针。
- markReaderIndex()、markWriterIndex() 方法:记录当前 readerIndex 指针和 writerIndex 指针的位置,一般会和 resetReaderIndex()、resetWriterIndex() 方法配套使用。resetReaderIndex() 方法会将 readerIndex 指针重置到 markReaderIndex() 方法标记的位置,resetwriterIndex() 方法同理。
- capacity()、clear()、copy() 等辅助方法用来获取 ChannelBuffer 容量以及实现清理、拷贝数据的功能,这里不再赘述。
- factory() 方法:该方法返回创建 ChannelBuffer 的工厂对象,ChannelBufferFactory 中定义了多个 getBuffer() 方法重载来创建 ChannelBuffer,如下图所示,这些 ChannelBufferFactory的实现都是单例的。

ChannelBufferFactory 继承关系图
AbstractChannelBuffer 抽象类实现了 ChannelBuffer 接口的大部分方法,其核心是维护了以下四个索引。
- readerIndex、writerIndex(int 类型):通过 readBytes() 方法及其重载读取数据时,会后移 readerIndex 索引;通过 writeBytes() 方法及其重载写入数据的时候,会后移 writerIndex 索引。
- markedReaderIndex、markedWriterIndex(int 类型):实现记录 readerIndex(writerIndex)以及回滚 readerIndex(writerIndex)的功能,前面我们已经介绍过markReaderIndex() 方法、resetReaderIndex() 方法以及 markWriterIndex() 方法、resetWriterIndex() 方法,你可以对比学习。
AbstractChannelBuffer 中 readBytes() 和 writeBytes() 方法的各个重载最终会通过 getBytes() 方法和 setBytes() 方法实现数据的读写,这些方法在 AbstractChannelBuffer 子类中实现。下面以读写一个 byte 数组为例,进行介绍:
java
public void readBytes(byte[] dst, int dstIndex, int length) {
// 检测可读字节数是否足够
checkReadableBytes(length);
// 将readerIndex之后的length个字节数读取到dst数组中dstIndex~
// dstIndex+length的位置
getBytes(readerIndex, dst, dstIndex, length);
// 将readerIndex后移length个字节
readerIndex += length;
}
public void writeBytes(byte[] src, int srcIndex, int length) {
// 将src数组中srcIndex~srcIndex+length的数据写入当前buffer中
// writerIndex~writerIndex+length的位置
setBytes(writerIndex, src, srcIndex, length);
// 将writeIndex后移length个字节
writerIndex += length;
}Buffer 各实现类解析
了解了 ChannelBuffer 接口的核心方法以及 AbstractChannelBuffer 的公共实现之后,我们再来看 ChannelBuffer 的具体实现。
HeapChannelBuffer 是基于字节数组的 ChannelBuffer 实现,我们可以看到其中有一个 array(byte\[\]数组)字段,它就是 HeapChannelBuffer 存储数据的地方。HeapChannelBuffer 的 setBytes() 以及 getBytes() 方法实现是调用 System.arraycopy() 方法完成数组操作的,具体实现如下:
java
public void setBytes(int index, byte[] src, int srcIndex, int length) {
System.arraycopy(src, srcIndex, array, index, length);
}
public void getBytes(int index, byte[] dst, int dstIndex, int length) {
System.arraycopy(array, index, dst, dstIndex, length);
}HeapChannelBuffer 对应的 ChannelBufferFactory 实现是 HeapChannelBufferFactory,其 getBuffer() 方法会通过 ChannelBuffers 这个工具类创建一个指定大小 HeapChannelBuffer 对象,下面简单介绍两个 getBuffer() 方法重载:
java
@Override
public ChannelBuffer getBuffer(int capacity) {
// 新建一个HeapChannelBuffer,底层的会新建一个长度为capacity的byte数组
return ChannelBuffers.buffer(capacity);
}
@Override
public ChannelBuffer getBuffer(byte[] array, int offset, int length) {
// 新建一个HeapChannelBuffer,并且会拷贝array数组中offset~offset+lenght
// 的数据到新HeapChannelBuffer中
return ChannelBuffers.wrappedBuffer(array, offset, length);
}其他 getBuffer() 方法重载这里就不再展示,你若感兴趣的话可以参考源码进行学习。 DynamicChannelBuffer 可以认为是其他 ChannelBuffer 的装饰器,它可以为其他 ChannelBuffer 添加动态扩展容量的功能。DynamicChannelBuffer 中有两个核心字段:
- buffer(ChannelBuffer 类型),是被修饰的 ChannelBuffer,默认为 HeapChannelBuffer。
- factory(ChannelBufferFactory 类型),用于创建被修饰的 HeapChannelBuffer 对象的 ChannelBufferFactory 工厂,默认为 HeapChannelBufferFactory。
DynamicChannelBuffer 需要关注的是 ensureWritableBytes() 方法,该方法实现了动态扩容的功能,在每次写入数据之前,都需要调用该方法确定当前可用空间是否足够,调用位置如下图所示:
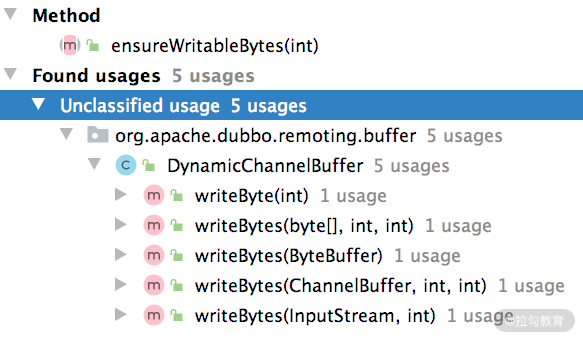
ensureWritableBytes() 方法如果检测到底层 ChannelBuffer 对象的空间不足,则会创建一个新的 ChannelBuffer(空间扩大为原来的两倍),然后将原来 ChannelBuffer 中的数据拷贝到新 ChannelBuffer 中,最后将 buffer 字段指向新 ChannelBuffer 对象,完成整个扩容操作。ensureWritableBytes() 方法的具体实现如下:
java
public void ensureWritableBytes(int minWritableBytes) {
if (minWritableBytes <= writableBytes()) {
return;
}
int newCapacity;
if (capacity() == 0) {
newCapacity = 1;
} else {
newCapacity = capacity();
}
int minNewCapacity = writerIndex() + minWritableBytes;
while (newCapacity < minNewCapacity) {
newCapacity <<= 1;
}
ChannelBuffer newBuffer = factory().getBuffer(newCapacity);
newBuffer.writeBytes(buffer, 0, writerIndex());
buffer = newBuffer;
}ByteBufferBackedChannelBuffer 是基于 Java NIO 中 ByteBuffer 的 ChannelBuffer 实现,其中的方法基本都是通过组合 ByteBuffer 的 API 实现的。下面以 getBytes() 方法和 setBytes() 方法的一个重载为例,进行分析:
java
public void getBytes(int index, byte[] dst, int dstIndex, int length) {
ByteBuffer data = buffer.duplicate();
try {
// 移动ByteBuffer中的指针
data.limit(index + length).position(index);
} catch (IllegalArgumentException e) {
throw new IndexOutOfBoundsException();
}
// 通过ByteBuffer的get()方法实现读取
data.get(dst, dstIndex, length);
}
public void setBytes(int index, byte[] src, int srcIndex, int length) {
ByteBuffer data = buffer.duplicate();
// 移动ByteBuffer中的指针
data.limit(index + length).position(index);
// 将数据写入底层的ByteBuffer中
data.put(src, srcIndex, length);
}ByteBufferBackedChannelBuffer 的其他方法实现比较简单,这里就不再展示,你若感兴趣的话可以参考源码进行学习。
NettyBackedChannelBuffer 是基于 Netty 中 ByteBuf 的 ChannelBuffer 实现,Netty 中的 ByteBuf 内部维护了 readerIndex 和 writerIndex 以及 markedReaderIndex、markedWriterIndex 这四个索引,所以 NettyBackedChannelBuffer 没有再继承 AbstractChannelBuffer 抽象类,而是直接实现了 ChannelBuffer 接口。
NettyBackedChannelBuffer 对 ChannelBuffer 接口的实现都是调用底层封装的 Netty ByteBuf 实现的,这里就不再展开介绍,你若感兴趣的话也可以参考相关代码进行学习。
相关 Stream 以及门面类
在 ChannelBuffer 基础上,Dubbo 提供了一套输入输出流,如下图所示:
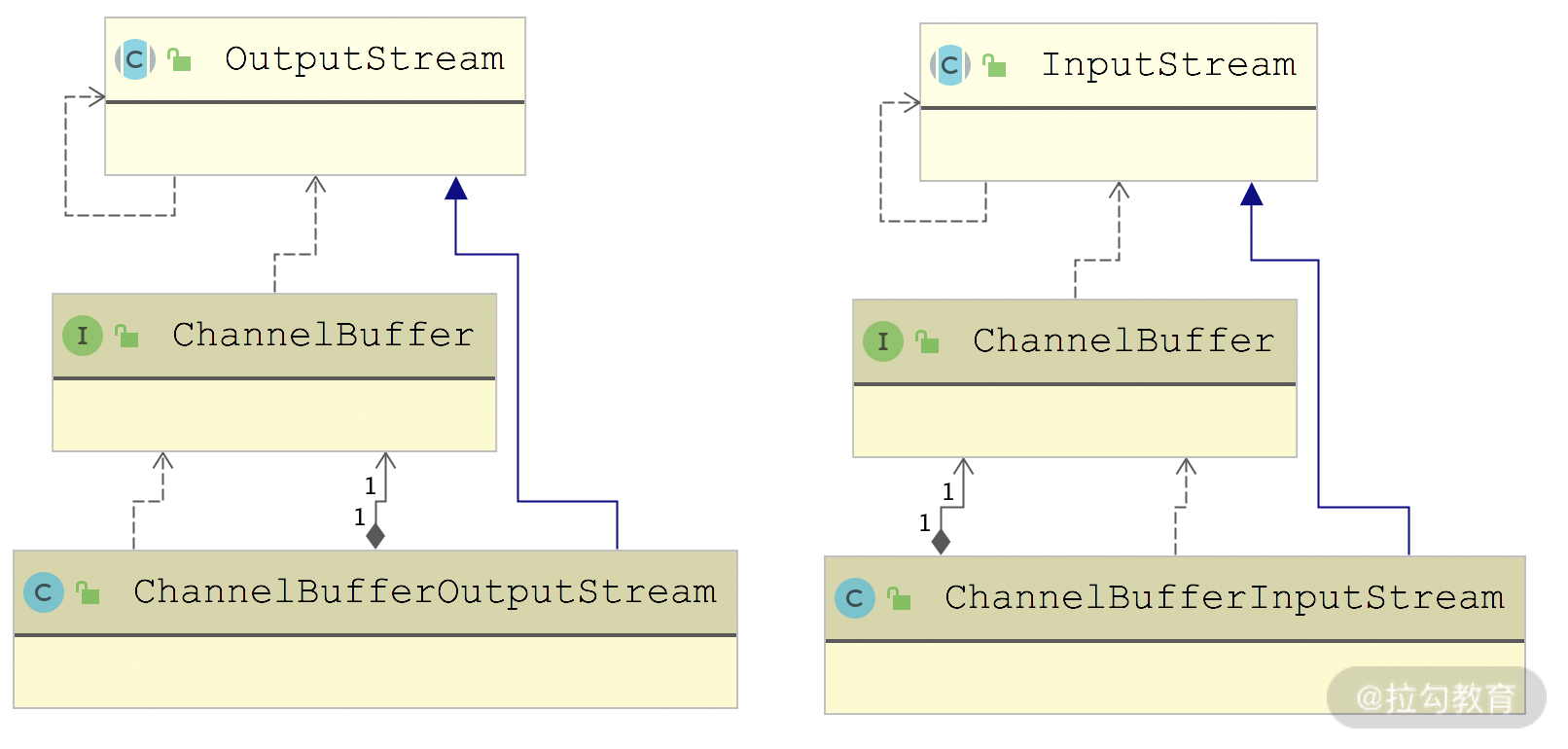
ChannelBufferInputStream 底层封装了一个 ChannelBuffer,其实现 InputStream 接口的 read*() 方法全部都是从 ChannelBuffer 中读取数据。ChannelBufferInputStream 中还维护了一个 startIndex 和一个endIndex 索引,作为读取数据的起止位置。ChannelBufferOutputStream 与 ChannelBufferInputStream 类似,会向底层的 ChannelBuffer 写入数据,这里就不再展开,你若感兴趣的话可以参考源码进行分析。
最后要介绍 ChannelBuffers 这个门面类,下图展示了 ChannelBuffers 这个门面类的所有方法:

对这些方法进行分类,可归纳出如下这些方法。
- dynamicBuffer() 方法:创建 DynamicChannelBuffer 对象,初始化大小由第一个参数指定,默认为 256。
- buffer() 方法:创建指定大小的 HeapChannelBuffer 对象。
- wrappedBuffer() 方法:将传入的 byte\[\] 数字封装成 HeapChannelBuffer 对象。
- directBuffer() 方法:创建 ByteBufferBackedChannelBuffer 对象,需要注意的是,底层的 ByteBuffer 使用的堆外内存,需要特别关注堆外内存的管理。
- equals() 方法:用于比较两个 ChannelBuffer 是否相同,其中会逐个比较两个 ChannelBuffer 中的前 7 个可读字节,只有两者完全一致,才算两个 ChannelBuffer 相同。其核心实现如下示例代码:
java
public static boolean equals(ChannelBuffer bufferA, ChannelBuffer bufferB) {
final int aLen = bufferA.readableBytes();
if (aLen != bufferB.readableBytes()) {
return false; // 比较两个ChannelBuffer的可读字节数
}
final int byteCount = aLen & 7; // 只比较前7个字节
int aIndex = bufferA.readerIndex();
int bIndex = bufferB.readerIndex();
for (int i = byteCount; i > 0; i--) {
if (bufferA.getByte(aIndex) != bufferB.getByte(bIndex)) {
return false; // 前7个字节发现不同,则返回false
}
aIndex++;
bIndex++;
}
return true;
}- compare() 方法:用于比较两个 ChannelBuffer 的大小,会逐个比较两个 ChannelBuffer 中的全部可读字节,具体实现与 equals() 方法类似,这里就不再重复讲述。
总结
本课时重点介绍了 dubbo-remoting 模块 buffers 包中的核心实现。我们首先介绍了 ChannelBuffer 接口这一个顶层接口,了解了 ChannelBuffer 提供的核心功能和运作原理;接下来介绍了 ChannelBuffer 的多种实现,其中包括 HeapChannelBuffer、DynamicChannelBuffer、ByteBufferBackedChannelBuffer 等具体实现类,以及 AbstractChannelBuffer 这个抽象类;最后分析了 ChannelBufferFactory 使用到的 ChannelBuffers 工具类以及在 ChannelBuffer 之上封装的 InputStream 和 OutputStream 实现。
19 Transporter 层核心实现:编解码与线程模型一文打尽(上)
在第 17 课时中,我们详细介绍了 dubbo-remoting-api 模块中 Transporter 相关的核心抽象接口,本课时将继续介绍 dubbo-remoting-api 模块的其他内容。这里我们依旧从 Transporter 层的 RemotingServer、Client、Channel、ChannelHandler 等核心接口出发,介绍这些核心接口的实现。
AbstractPeer 抽象类
首先,我们来看 AbstractPeer 这个抽象类,它同时实现了 Endpoint 接口和 ChannelHandler 接口,如下图所示,它也是 AbstractChannel、AbstractEndpoint 抽象类的父类。
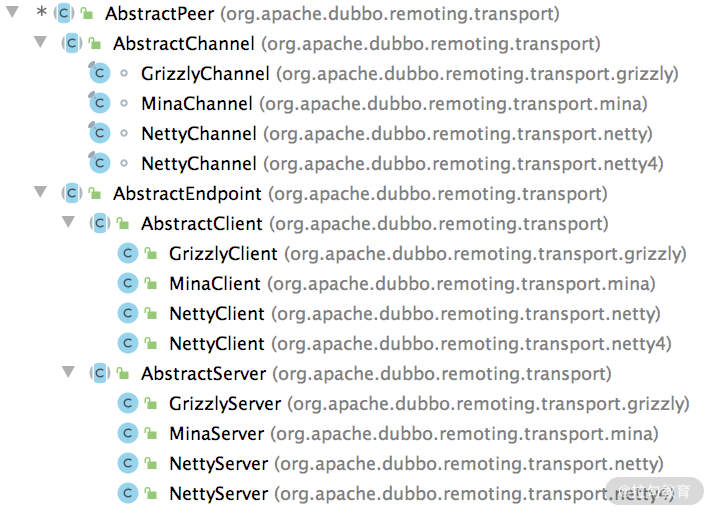
AbstractPeer 继承关系
Netty 中也有 ChannelHandler、Channel 等接口,但无特殊说明的情况下,这里的接口指的都是 Dubbo 中定义的接口。如果涉及 Netty 中的接口,会进行特殊说明。
AbstractPeer 中有四个字段:一个是表示该端点自身的 URL 类型的字段,还有两个 Boolean 类型的字段(closing 和 closed)用来记录当前端点的状态,这三个字段都与 Endpoint 接口相关;第四个字段指向了一个 ChannelHandler 对象,AbstractPeer 对 ChannelHandler 接口的所有实现,都是委托给了这个 ChannelHandler 对象。从上面的继承关系图中,我们可以得出这样一个结论:AbstractChannel、AbstractServer、AbstractClient 都是要关联一个 ChannelHandler 对象的。
AbstractEndpoint 抽象类
我们顺着上图的继承关系继续向下看,AbstractEndpoint 继承了 AbstractPeer 这个抽象类。AbstractEndpoint 中维护了一个 Codec2 对象(codec 字段)和两个超时时间(timeout 字段和 connectTimeout 字段),在 AbstractEndpoint 的构造方法中会根据传入的 URL 初始化这三个字段:
java
public AbstractEndpoint(URL url, ChannelHandler handler) {
super(url, handler); // 调用父类AbstractPeer的构造方法
// 根据URL中的codec参数值,确定此处具体的Codec2实现类
this.codec = getChannelCodec(url);
// 根据URL中的timeout参数确定timeout字段的值,默认1000
this.timeout = url.getPositiveParameter(TIMEOUT_KEY,DEFAULT_TIMEOUT);
// 根据URL中的connect.timeout参数确定connectTimeout字段的值,默认3000
this.connectTimeout = url.getPositiveParameter(
Constants.CONNECT_TIMEOUT_KEY, Constants.DEFAULT_CONNECT_TIMEOUT);
}在第 17 课时介绍 Codec2 接口的时候提到它是一个 SPI 扩展点,这里的 AbstractEndpoint.getChannelCodec() 方法就是基于 Dubbo SPI 选择其扩展实现的,具体实现如下:
java
protected static Codec2 getChannelCodec(URL url) {
// 根据URL的codec参数获取扩展名
String codecName = url.getParameter(Constants.CODEC_KEY, "telnet");
if (ExtensionLoader.getExtensionLoader(Codec2.class).hasExtension(codecName)) { // 通过ExtensionLoader加载并实例化Codec2的具体扩展实现
return ExtensionLoader.getExtensionLoader(Codec2.class).getExtension(codecName);
} else { // Codec2接口不存在相应的扩展名,就尝试从Codec这个老接口的扩展名中查找,目前Codec接口已经废弃了,所以省略这部分逻辑
}
}另外,AbstractEndpoint 还实现了 Resetable 接口(只有一个 reset() 方法需要实现),虽然 AbstractEndpoint 中的 reset() 方法比较长,但是逻辑非常简单,就是根据传入的 URL 参数重置 AbstractEndpoint 的三个字段。下面是重置 codec 字段的代码片段,还是调用 getChannelCodec() 方法实现的:
java
public void reset(URL url) {
// 检测当前AbstractEndpoint是否已经关闭(略)
// 省略重置timeout、connectTimeout两个字段的逻辑
try {
if (url.hasParameter(Constants.CODEC_KEY)) {
this.codec = getChannelCodec(url);
}
} catch (Throwable t) {
logger.error(t.getMessage(), t);
}
}Server 继承路线分析
AbstractServer 和 AbstractClient 都实现了 AbstractEndpoint 抽象类,我们先来看 AbstractServer 的实现。AbstractServer 在继承了 AbstractEndpoint 的同时,还实现了 RemotingServer 接口,如下图所示:
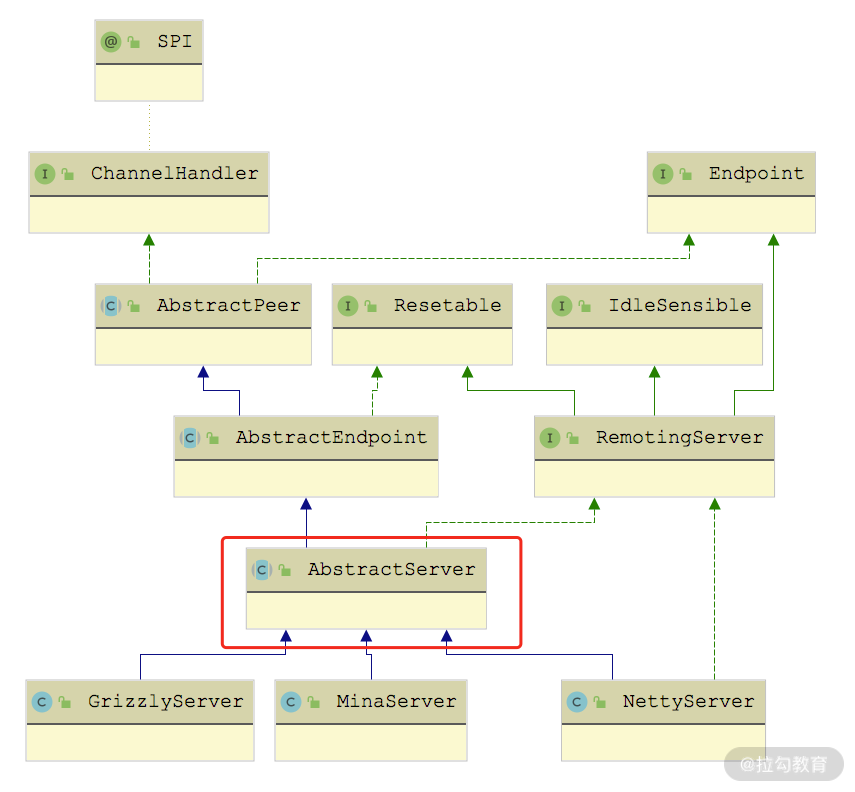
AbstractServer 继承关系图
AbstractServer 是对服务端的抽象,实现了服务端的公共逻辑。AbstractServer 的核心字段有下面几个。
- localAddress、bindAddress(InetSocketAddress 类型):分别对应该 Server 的本地地址和绑定的地址,都是从 URL 中的参数中获取。bindAddress 默认值与 localAddress 一致。
- accepts(int 类型):该 Server 能接收的最大连接数,从 URL 的 accepts 参数中获取,默认值为 0,表示没有限制。
- executorRepository(ExecutorRepository 类型):负责管理线程池,后面我们会深入介绍 ExecutorRepository 的具体实现。
- executor(ExecutorService 类型):当前 Server 关联的线程池,由上面的 ExecutorRepository 创建并管理。
在 AbstractServer 的构造方法中会根据传入的 URL初始化上述字段,并调用 doOpen() 这个抽象方法完成该 Server 的启动,具体实现如下:
java
public AbstractServer(URL url, ChannelHandler handler) {
super(url, handler); // 调用父类的构造方法
// 根据传入的URL初始化localAddress和bindAddress
localAddress = getUrl().toInetSocketAddress();
String bindIp = getUrl().getParameter(Constants.BIND_IP_KEY, getUrl().getHost());
int bindPort = getUrl().getParameter(Constants.BIND_PORT_KEY, getUrl().getPort());
if (url.getParameter(ANYHOST_KEY, false) || NetUtils.isInvalidLocalHost(bindIp)) {
bindIp = ANYHOST_VALUE;
}
bindAddress = new InetSocketAddress(bindIp, bindPort);
// 初始化accepts等字段
this.accepts = url.getParameter(ACCEPTS_KEY, DEFAULT_ACCEPTS);
this.idleTimeout = url.getParameter(IDLE_TIMEOUT_KEY, DEFAULT_IDLE_TIMEOUT);
try {
doOpen(); // 调用doOpen()这个抽象方法,启动该Server
} catch (Throwable t) {
throw new RemotingException("...");
}
// 获取该Server关联的线程池
executor = executorRepository.createExecutorIfAbsent(url);
}ExecutorRepository
在继续分析 AbstractServer 的具体实现类之前,我们先来了解一下 ExecutorRepository 这个接口。
ExecutorRepository 负责创建并管理 Dubbo 中的线程池,该接口虽然是个 SPI 扩展点,但是只有一个默认实现------ DefaultExecutorRepository。在该默认实现中维护了一个 ConcurrentMap> 集合(data 字段)缓存已有的线程池,第一层 Key 值表示线程池属于 Provider 端还是 Consumer 端,第二层 Key 值表示线程池关联服务的端口。
DefaultExecutorRepository.createExecutorIfAbsent() 方法会根据 URL 参数创建相应的线程池并缓存在合适的位置,具体实现如下:
java
public synchronized ExecutorService createExecutorIfAbsent(URL url) {
// 根据URL中的side参数值决定第一层key
String componentKey = EXECUTOR_SERVICE_COMPONENT_KEY;
if (CONSUMER_SIDE.equalsIgnoreCase(url.getParameter(SIDE_KEY))) {
componentKey = CONSUMER_SIDE;
}
Map<Integer, ExecutorService> executors = data.computeIfAbsent(componentKey, k -> new ConcurrentHashMap<>());
// 根据URL中的port值确定第二层key
Integer portKey = url.getPort();
ExecutorService executor = executors.computeIfAbsent(portKey, k -> createExecutor(url));
// 如果缓存中相应的线程池已关闭,则同样需要调用createExecutor()方法
// 创建新的线程池,并替换掉缓存中已关闭的线程持,这里省略这段逻辑
return executor;
}在 createExecutor() 方法中,会通过 Dubbo SPI 查找 ThreadPool 接口的扩展实现,并调用其 getExecutor() 方法创建线程池。ThreadPool 接口被 @SPI 注解修饰,默认使用 FixedThreadPool 实现,但是 ThreadPool 接口中的 getExecutor() 方法被 @Adaptive 注解修饰,动态生成的适配器类会优先根据 URL 中的 threadpool 参数选择 ThreadPool 的扩展实现。ThreadPool 接口的实现类如下图所示:
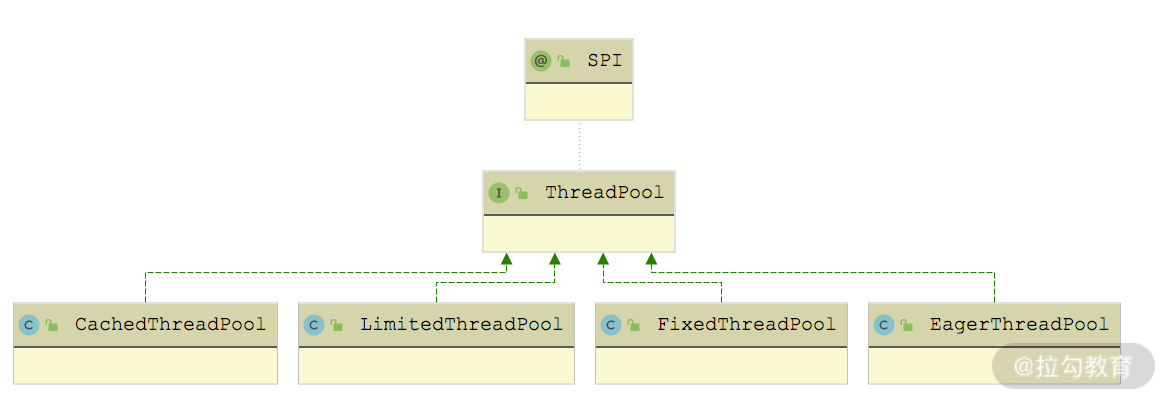
ThreadPool 继承关系图
不同实现会根据 URL 参数创建不同特性的线程池,这里以CacheThreadPool为例进行分析:
java
public Executor getExecutor(URL url) {
String name = url.getParameter(THREAD_NAME_KEY, DEFAULT_THREAD_NAME);
// 核心线程数量
int cores = url.getParameter(CORE_THREADS_KEY, DEFAULT_CORE_THREADS);
// 最大线程数量
int threads = url.getParameter(THREADS_KEY, Integer.MAX_VALUE);
// 缓冲队列的最大长度
int queues = url.getParameter(QUEUES_KEY, DEFAULT_QUEUES);
// 非核心线程的最大空闲时长,当非核心线程空闲时间超过该值时,会被回收
int alive = url.getParameter(ALIVE_KEY, DEFAULT_ALIVE);
// 下面就是依赖JDK的ThreadPoolExecutor创建指定特性的线程池并返回
return new ThreadPoolExecutor(cores, threads, alive, TimeUnit.MILLISECONDS,
queues == 0 ? new SynchronousQueue<Runnable>() :
(queues < 0 ? new LinkedBlockingQueue<Runnable>()
: new LinkedBlockingQueue<Runnable>(queues)),
new NamedInternalThreadFactory(name, true), new AbortPolicyWithReport(name, url));
}再简单说一下其他 ThreadPool 实现创建的线程池。
- LimitedThreadPool:与 CacheThreadPool 一样,可以指定核心线程数、最大线程数以及缓冲队列长度。区别在于,LimitedThreadPool 创建的线程池的非核心线程不会被回收。
- FixedThreadPool:核心线程数和最大线程数一致,且不会被回收。
上述三种类型的线程池都是基于 JDK ThreadPoolExecutor 线程池,在核心线程全部被占用的时候,会优先将任务放到缓冲队列中缓存,在缓冲队列满了之后,才会尝试创建新线程来处理任务。
EagerThreadPool 创建的线程池是 EagerThreadPoolExecutor(继承了 JDK 提供的 ThreadPoolExecutor),使用的队列是 TaskQueue(继承了LinkedBlockingQueue)。该线程池与 ThreadPoolExecutor 不同的是:在线程数没有达到最大线程数的前提下,EagerThreadPoolExecutor 会优先创建线程来执行任务,而不是放到缓冲队列中;当线程数达到最大值时,EagerThreadPoolExecutor 会将任务放入缓冲队列,等待空闲线程。
EagerThreadPoolExecutor 覆盖了 ThreadPoolExecutor 中的两个方法:execute() 方法和 afterExecute() 方法,具体实现如下,我们可以看到其中维护了一个 submittedTaskCount 字段(AtomicInteger 类型),用来记录当前在线程池中的任务总数(正在线程中执行的任务数+队列中等待的任务数)。
java
public void execute(Runnable command) {
// 任务提交之前,递增submittedTaskCount
submittedTaskCount.incrementAndGet();
try {
super.execute(command); // 提交任务
} catch (RejectedExecutionException rx) {
final TaskQueue queue = (TaskQueue) super.getQueue();
try {
// 任务被拒绝之后,会尝试再次放入队列中缓存,等待空闲线程执行
if (!queue.retryOffer(command, 0, TimeUnit.MILLISECONDS)) {
// 再次入队被拒绝,则队列已满,无法执行任务
// 递减submittedTaskCount
submittedTaskCount.decrementAndGet();
throw new RejectedExecutionException("Queue capacity is full.", rx);
}
} catch (InterruptedException x) {
// 再次入队列异常,递减submittedTaskCount
submittedTaskCount.decrementAndGet();
throw new RejectedExecutionException(x);
}
} catch (Throwable t) { // 任务提交异常,递减submittedTaskCount
submittedTaskCount.decrementAndGet();
throw t;
}
}
protected void afterExecute(Runnable r, Throwable t) {
// 任务指定结束,递减submittedTaskCount
submittedTaskCount.decrementAndGet();
}看到这里,你可能会有些疑惑:没有看到优先创建线程执行任务的逻辑啊。其实重点在关联的 TaskQueue 实现中,它覆盖了 LinkedBlockingQueue.offer() 方法,会判断线程池的 submittedTaskCount 值是否已经达到最大线程数,如果未超过,则会返回 false,迫使线程池创建新线程来执行任务。示例代码如下:
java
public boolean offer(Runnable runnable) {
// 获取当前线程池中的活跃线程数
int currentPoolThreadSize = executor.getPoolSize();
// 当前有线程空闲,直接将任务提交到队列中,空闲线程会直接从中获取任务执行
if (executor.getSubmittedTaskCount() < currentPoolThreadSize) {
return super.offer(runnable);
}
// 当前没有空闲线程,但是还可以创建新线程,则返回false,迫使线程池创建
// 新线程来执行任务
if (currentPoolThreadSize < executor.getMaximumPoolSize()) {
return false;
}
// 当前线程数已经达到上限,只能放到队列中缓存了
return super.offer(runnable);
}线程池最后一个相关的小细节是 AbortPolicyWithReport ,它继承了 ThreadPoolExecutor.AbortPolicy,覆盖的 rejectedExecution 方法中会输出包含线程池相关信息的 WARN 级别日志,然后进行 dumpJStack() 方法,最后才会抛出RejectedExecutionException 异常。
我们回到 Server 的继承线上,下面来看基于 Netty 4 实现的 NettyServer,它继承了前文介绍的 AbstractServer,实现了 doOpen() 方法和 doClose() 方法。这里重点看 doOpen() 方法,如下所示:
java
protected void doOpen() throws Throwable {
// 创建ServerBootstrap
bootstrap = new ServerBootstrap();
// 创建boss EventLoopGroup
bossGroup = NettyEventLoopFactory.eventLoopGroup(1, "NettyServerBoss");
// 创建worker EventLoopGroup
workerGroup = NettyEventLoopFactory.eventLoopGroup(
getUrl().getPositiveParameter(IO_THREADS_KEY, Constants.DEFAULT_IO_THREADS),
"NettyServerWorker");
// 创建NettyServerHandler,它是一个Netty中的ChannelHandler实现,
// 不是Dubbo Remoting层的ChannelHandler接口的实现
final NettyServerHandler nettyServerHandler = new NettyServerHandler(getUrl(), this);
// 获取当前NettyServer创建的所有Channel,这里的channels集合中的
// Channel不是Netty中的Channel对象,而是Dubbo Remoting层的Channel对象
channels = nettyServerHandler.getChannels();
// 初始化ServerBootstrap,指定boss和worker EventLoopGroup
bootstrap.group(bossGroup, workerGroup)
.channel(NettyEventLoopFactory.serverSocketChannelClass())
.option(ChannelOption.SO_REUSEADDR, Boolean.TRUE)
.childOption(ChannelOption.TCP_NODELAY, Boolean.TRUE)
.childOption(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT)
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
protected void initChannel(SocketChannel ch) throws Exception {
// 连接空闲超时时间
int idleTimeout = UrlUtils.getIdleTimeout(getUrl());
// NettyCodecAdapter中会创建Decoder和Encoder
NettyCodecAdapter adapter = new NettyCodecAdapter(getCodec(), getUrl(), NettyServer.this);
ch.pipeline()
// 注册Decoder和Encoder
.addLast("decoder", adapter.getDecoder())
.addLast("encoder", adapter.getEncoder())
// 注册IdleStateHandler
.addLast("server-idle-handler", new IdleStateHandler(0, 0, idleTimeout, MILLISECONDS))
// 注册NettyServerHandler
.addLast("handler", nettyServerHandler);
}
});
// 绑定指定的地址和端口
ChannelFuture channelFuture = bootstrap.bind(getBindAddress());
channelFuture.syncUninterruptibly(); // 等待bind操作完成
channel = channelFuture.channel();
}看完 NettyServer 实现的 doOpen() 方法之后,你会发现它和简易版 RPC 框架中启动一个 Netty 的 Server 端基本流程类似:初始化 ServerBootstrap、创建 Boss EventLoopGroup 和 Worker EventLoopGroup、创建 ChannelInitializer 指定如何初始化 Channel 上的 ChannelHandler 等一系列 Netty 使用的标准化流程。
其实在 Transporter 这一层看,功能的不同其实就是注册在 Channel 上的 ChannelHandler 不同,通过 doOpen() 方法得到的 Server 端结构如下:
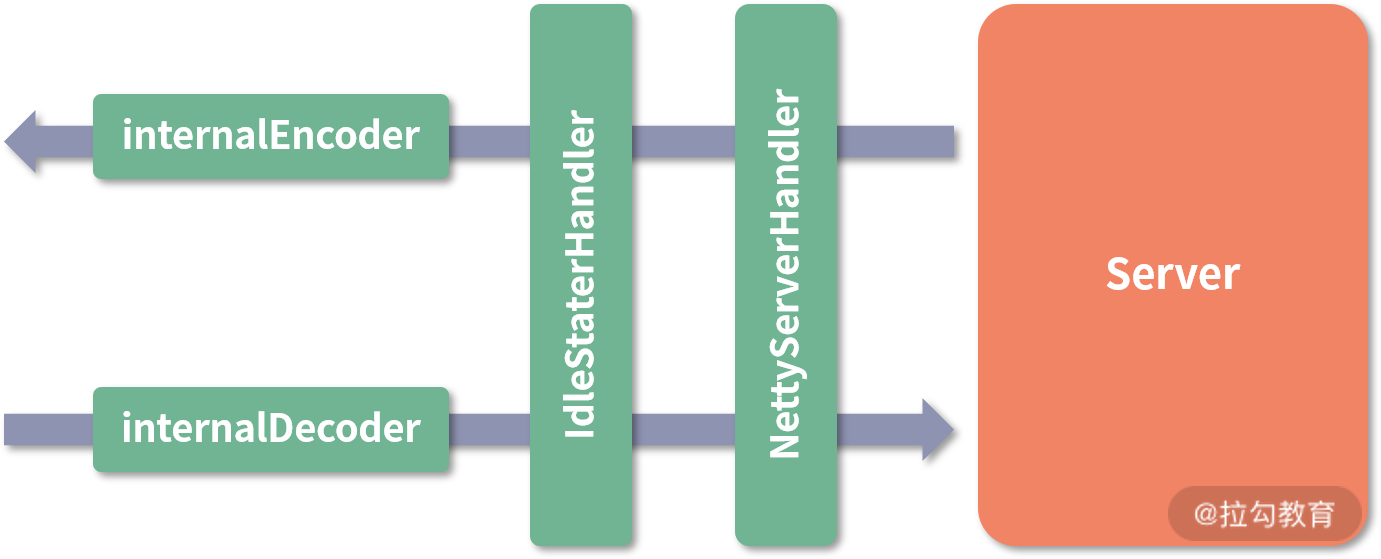
NettyServer 模型
核心 ChannelHandler
下面我们来逐个看看这四个 ChannelHandler 的核心功能。
首先是decoder 和 encoder,它们都是 NettyCodecAdapter 的内部类,如下图所示,分别继承了 Netty 中的 ByteToMessageDecoder 和 MessageToByteEncoder:
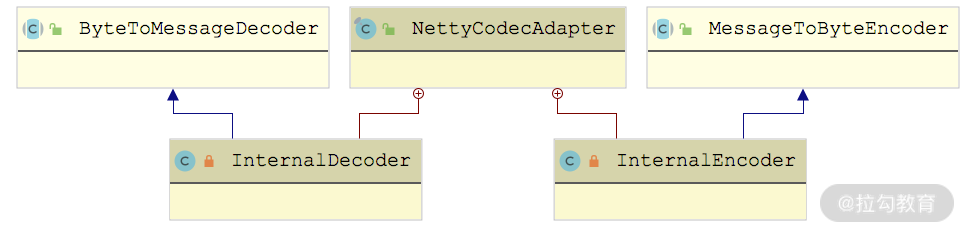
还记得 AbstractEndpoint 抽象类中的 codec 字段(Codec2 类型)吗?InternalDecoder 和 InternalEncoder 会将真正的编解码功能委托给 NettyServer 关联的这个 Codec2 对象去处理,这里以 InternalDecoder 为例进行分析:
java
private class InternalDecoder extends ByteToMessageDecoder {
protected void decode(ChannelHandlerContext ctx, ByteBuf input, List<Object> out) throws Exception {
// 将ByteBuf封装成统一的ChannelBuffer
ChannelBuffer message = new NettyBackedChannelBuffer(input);
// 拿到关联的Channel
NettyChannel channel = NettyChannel.getOrAddChannel(ctx.channel(), url, handler);
do {
// 记录当前readerIndex的位置
int saveReaderIndex = message.readerIndex();
// 委托给Codec2进行解码
Object msg = codec.decode(channel, message);
// 当前接收到的数据不足一个消息的长度,会返回NEED_MORE_INPUT,
// 这里会重置readerIndex,继续等待接收更多的数据
if (msg == Codec2.DecodeResult.NEED_MORE_INPUT) {
message.readerIndex(saveReaderIndex);
break;
} else {
if (msg != null) { // 将读取到的消息传递给后面的Handler处理
out.add(msg);
}
}
} while (message.readable());
}
}你是不是发现 InternalDecoder 的实现与我们简易版 RPC 的 Decoder 实现非常相似呢?
InternalEncoder 的具体实现就不再展开讲解了,你若感兴趣可以翻看源码进行研究和分析。
接下来是IdleStateHandler,它是 Netty 提供的一个工具型 ChannelHandler,用于定时心跳请求的功能或是自动关闭长时间空闲连接的功能。它的原理到底是怎样的呢?在 IdleStateHandler 中通过 lastReadTime、lastWriteTime 等几个字段,记录了最近一次读/写事件的时间,IdleStateHandler 初始化的时候,会创建一个定时任务,定时检测当前时间与最后一次读/写时间的差值。如果超过我们设置的阈值(也就是上面 NettyServer 中设置的 idleTimeout),就会触发 IdleStateEvent 事件,并传递给后续的 ChannelHandler 进行处理。后续 ChannelHandler 的 userEventTriggered() 方法会根据接收到的 IdleStateEvent 事件,决定是关闭长时间空闲的连接,还是发送心跳探活。
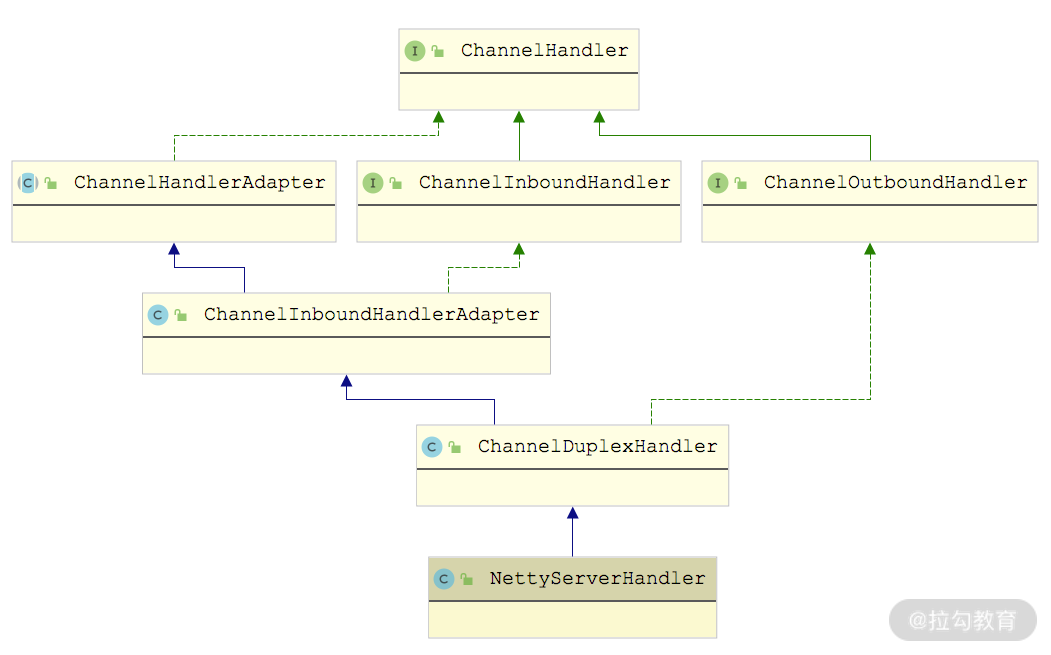
最后来看NettyServerHandler,它继承了 ChannelDuplexHandler,这是 Netty 提供的一个同时处理 Inbound 数据和 Outbound 数据的 ChannelHandler,从下面的继承图就能看出来。
NettyServerHandler 继承关系图
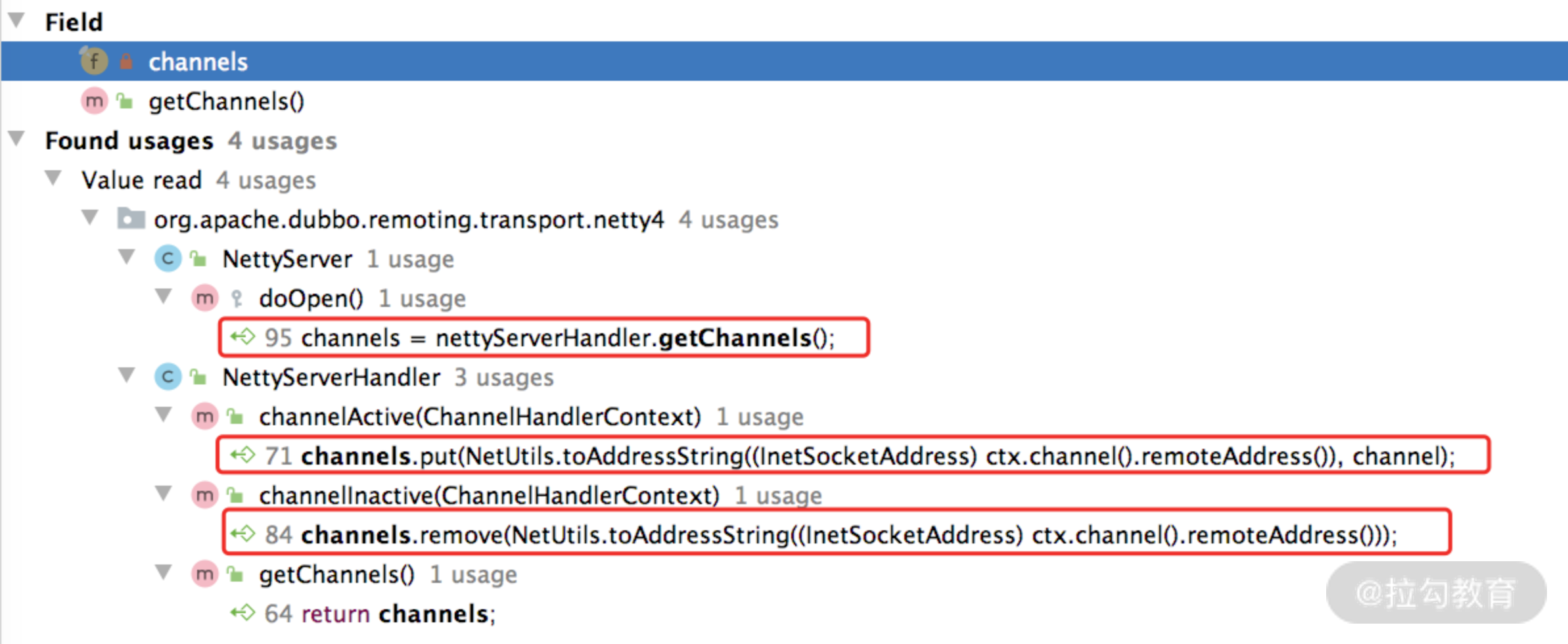
在 NettyServerHandler 中有 channels 和 handler 两个核心字段。
- channels(Map集合):记录了当前 Server 创建的所有 Channel,从下图中可以看到,连接创建(触发 channelActive() 方法)、连接断开(触发 channelInactive()方法)会操作 channels 集合进行相应的增删。
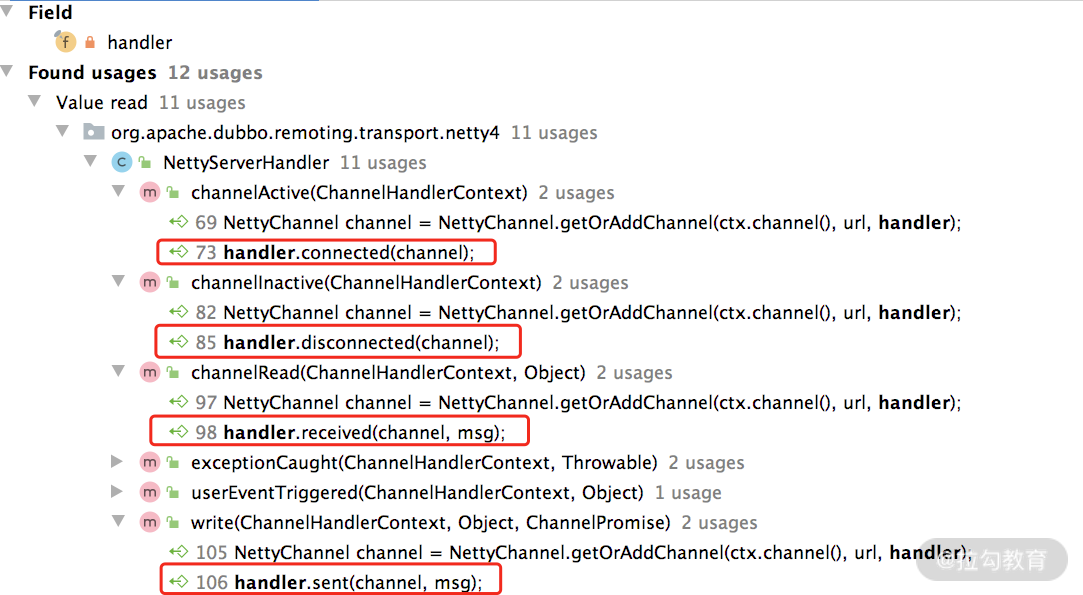
- handler(ChannelHandler 类型):NettyServerHandler 内几乎所有方法都会触发该 Dubbo ChannelHandler 对象(如下图)。
这里以 write() 方法为例进行简单分析:
java
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
super.write(ctx, msg, promise); // 将发送的数据继续向下传递
// 并不影响消息的继续发送,只是触发sent()方法进行相关的处理,这也是方法
// 名称是动词过去式的原因,可以仔细体会一下。其他方法可能没有那么明显,
// 这里以write()方法为例进行说明
NettyChannel channel = NettyChannel.getOrAddChannel(ctx.channel(), url, handler);
handler.sent(channel, msg);
}在 NettyServer 创建 NettyServerHandler 的时候,可以看到下面的这行代码:
java
final NettyServerHandler nettyServerHandler = new NettyServerHandler(getUrl(), this);其中第二个参数传入的是 NettyServer 这个对象,你可以追溯一下 NettyServer 的继承结构,会发现它的最顶层父类 AbstractPeer 实现了 ChannelHandler,并且将所有的方法委托给其中封装的 ChannelHandler 对象,如下图所示:
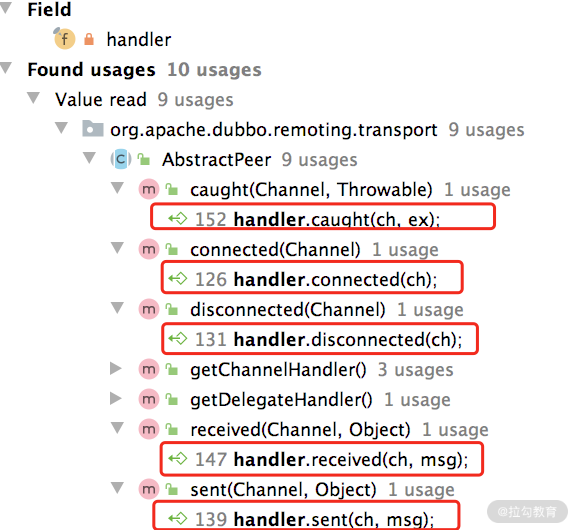
也就是说,NettyServerHandler 会将数据委托给这个 ChannelHandler。
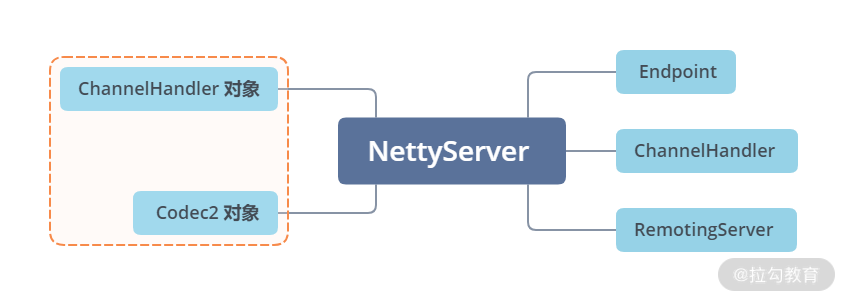
到此为止,Server 这条继承线就介绍完了。你可以回顾一下,从 AbstractPeer 开始往下,一路继承下来,NettyServer 拥有了 Endpoint、ChannelHandler 以及RemotingServer多个接口的能力,关联了一个 ChannelHandler 对象以及 Codec2 对象,并最终将数据委托给这两个对象进行处理。所以,上层调用方只需要实现 ChannelHandler 和 Codec2 这两个接口就可以了。
总结
本课时重点介绍了 Dubbo Transporter 层中 Server 相关的实现。
首先,我们介绍了 AbstractPeer 这个最顶层的抽象类,了解了 Server、Client 和 Channel 的公共属性。接下来,介绍了 AbstractEndpoint 抽象类,它提供了编解码等 Server 和 Client 所需的公共能力。最后,我们深入分析了 AbstractServer 抽象类以及基于 Netty 4 实现的 NettyServer,同时,还深入剖析了涉及的各种组件,例如,ExecutorRepository、NettyServerHandler 等。
20 Transporter 层核心实现:编解码与线程模型一文打尽(下)
在上一课时中,我们深入分析了 Transporter 层中 Server 相关的核心抽象类以及基于 Netty 4 的实现类。本课时我们继续分析 Transporter 层中剩余的核心接口实现,主要涉及 Client 接口、Channel 接口、ChannelHandler 接口,以及相关的关键组件。
Client 继承路线分析
在上一课时分析 AbstractEndpoint 的时候可以看到,除了 AbstractServer 这一条继承线之外,还有 AbstractClient 这条继承线,它是对客户端的抽象。AbstractClient 中的核心字段有如下几个。
- connectLock(Lock 类型):在 Client 底层进行连接、断开、重连等操作时,需要获取该锁进行同步。
- needReconnect(Boolean 类型):在发送数据之前,会检查 Client 底层的连接是否断开,如果断开了,则会根据 needReconnect 字段,决定是否重连。
- executor(ExecutorService 类型):当前 Client 关联的线程池,线程池的具体内容在上一课时已经详细介绍过了,这里不再赘述。
在 AbstractClient 的构造方法中,会解析 URL 初始化 needReconnect 字段和 executor字段,如下示例代码:
java
public AbstractClient(URL url, ChannelHandler handler) throws RemotingException {
super(url, handler); // 调用父类的构造方法
// 解析URL,初始化needReconnect值
needReconnect = url.getParameter("send.reconnect", false);
initExecutor(url); // 解析URL,初始化executor
doOpen(); // 初始化底层的NIO库的相关组件
// 创建底层连接
connect(); // 省略异常处理的逻辑
}与 AbstractServer 类似,AbstractClient 定义了 doOpen()、doClose()、doConnect()和doDisConnect() 四个抽象方法给子类实现。
下面来看基于 Netty 4 实现的 NettyClient,它继承了 AbstractClient 抽象类,实现了上述四个 do*() 抽象方法,我们这里重点关注 doOpen() 方法和 doConnect() 方法。在 NettyClient 的 doOpen() 方法中会通过 Bootstrap 构建客户端,其中会完成连接超时时间、keepalive 等参数的设置,以及 ChannelHandler 的创建和注册,具体实现如下所示:
java
protected void doOpen() throws Throwable {
// 创建NettyClientHandler
final NettyClientHandler nettyClientHandler = new NettyClientHandler(getUrl(), this);
bootstrap = new Bootstrap(); // 创建Bootstrap
bootstrap.group(NIO_EVENT_LOOP_GROUP)
.option(ChannelOption.SO_KEEPALIVE, true)
.option(ChannelOption.TCP_NODELAY, true)
.option(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT)
.channel(socketChannelClass());
// 设置连接超时时间,这里使用到AbstractEndpoint中的connectTimeout字段
bootstrap.option(ChannelOption.CONNECT_TIMEOUT_MILLIS, Math.max(3000, getConnectTimeout()));
bootstrap.handler(new ChannelInitializer<SocketChannel>() {
protected void initChannel(SocketChannel ch) throws Exception {
// 心跳请求的时间间隔
int heartbeatInterval = UrlUtils.getHeartbeat(getUrl());
// 通过NettyCodecAdapter创建Netty中的编解码器,这里不再重复介绍
NettyCodecAdapter adapter = new NettyCodecAdapter(getCodec(), getUrl(), NettyClient.this);
// 注册ChannelHandler
ch.pipeline().addLast("decoder", adapter.getDecoder())
.addLast("encoder", adapter.getEncoder())
.addLast("client-idle-handler", new IdleStateHandler(heartbeatInterval, 0, 0, MILLISECONDS))
.addLast("handler", nettyClientHandler);
// 如果需要Socks5Proxy,需要添加Socks5ProxyHandler(略)
}
});
}得到的 NettyClient 结构如下图所示:
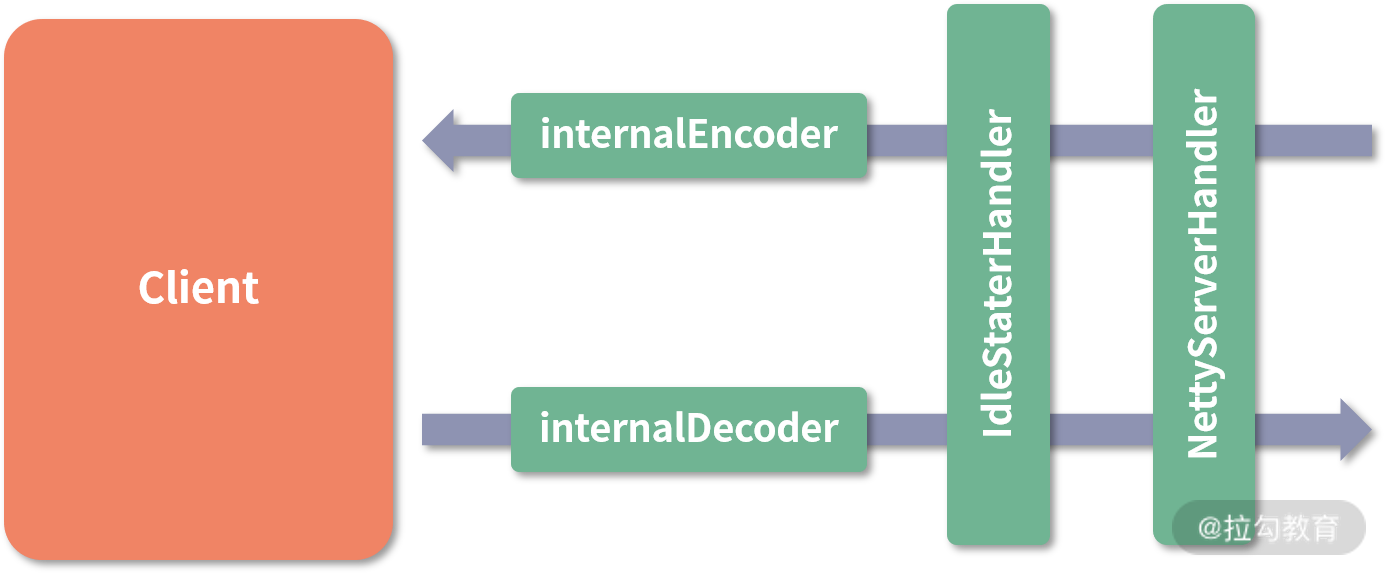
NettyClient 结构图
NettyClientHandler 的实现方法与上一课时介绍的 NettyServerHandler 类似,同样是实现了 Netty 中的 ChannelDuplexHandler,其中会将所有方法委托给 NettyClient 关联的 ChannelHandler 对象进行处理。两者在 userEventTriggered() 方法的实现上有所不同,NettyServerHandler 在收到 IdleStateEvent 事件时会断开连接,而 NettyClientHandler 则会发送心跳消息,具体实现如下:
java
public void userEventTriggered(ChannelHandlerContext ctx, Object evt) throws Exception {
if (evt instanceof IdleStateEvent) {
NettyChannel channel = NettyChannel.getOrAddChannel(ctx.channel(), url, handler);
Request req = new Request();
req.setVersion(Version.getProtocolVersion());
req.setTwoWay(true);
req.setEvent(HEARTBEAT_EVENT); // 发送心跳请求
channel.send(req);
} else {
super.userEventTriggered(ctx, evt);
}
}Channel 继承线分析
除了上一课时介绍的 AbstractEndpoint 之外,AbstractChannel 也继承了 AbstractPeer 这个抽象类,同时还继承了 Channel 接口。AbstractChannel 实现非常简单,只是在 send() 方法中检测了底层连接的状态,没有实现具体的发送消息的逻辑。
这里我们依然以基于 Netty 4 的实现------ NettyChannel 为例,分析它对 AbstractChannel 的实现。NettyChannel 中的核心字段有如下几个。
- channel(Channel类型):Netty 框架中的 Channel,与当前的 Dubbo Channel 对象一一对应。
- attributes(Map类型):当前 Channel 中附加属性,都会记录到该 Map 中。NettyChannel 中提供的 getAttribute()、hasAttribute()、setAttribute() 等方法,都是操作该集合。
- active(AtomicBoolean):用于标识当前 Channel 是否可用。
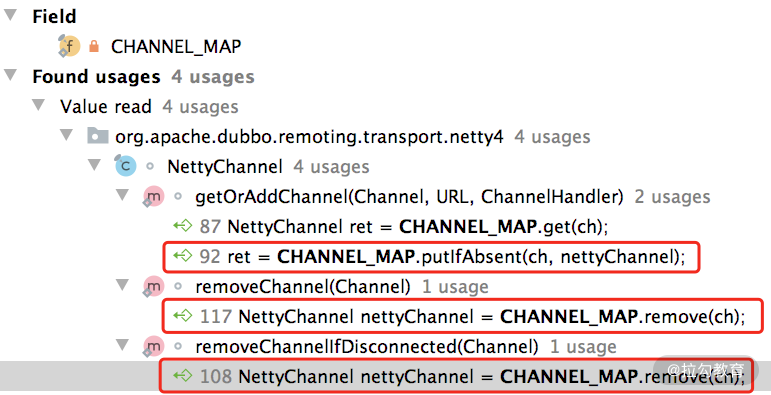
另外,在 NettyChannel 中还有一个静态的 Map 集合(CHANNEL_MAP 字段),用来缓存当前 JVM 中 Netty 框架 Channel 与 Dubbo Channel 之间的映射关系。从下图的调用关系中可以看到,NettyChannel 提供了读写 CHANNEL_MAP 集合的方法:
NettyChannel 中还有一个要介绍的是 send() 方法,它会通过底层关联的 Netty 框架 Channel,将数据发送到对端。其中,可以通过第二个参数指定是否等待发送操作结束,具体实现如下:
java
public void send(Object message, boolean sent) throws RemotingException {
// 调用AbstractChannel的send()方法检测连接是否可用
super.send(message, sent);
boolean success = true;
int timeout = 0;
// 依赖Netty框架的Channel发送数据
ChannelFuture future = channel.writeAndFlush(message);
if (sent) { // 等待发送结束,有超时时间
timeout = getUrl().getPositiveParameter(TIMEOUT_KEY, DEFAULT_TIMEOUT);
success = future.await(timeout);
}
Throwable cause = future.cause();
if (cause != null) {
throw cause;
}
// 出现异常会调用removeChannelIfDisconnected()方法,在底层连接断开时,
// 会清理CHANNEL_MAP缓存(略)
}ChannelHandler 继承线分析
前文介绍的 AbstractServer、AbstractClient 以及 Channel 实现,都是通过 AbstractPeer 实现了 ChannelHandler 接口,但只是做了一层简单的委托(也可以说成是装饰器),将全部方法委托给了其底层关联的 ChannelHandler 对象。
这里我们就深入分析 ChannelHandler 的其他实现类,涉及的实现类如下所示:
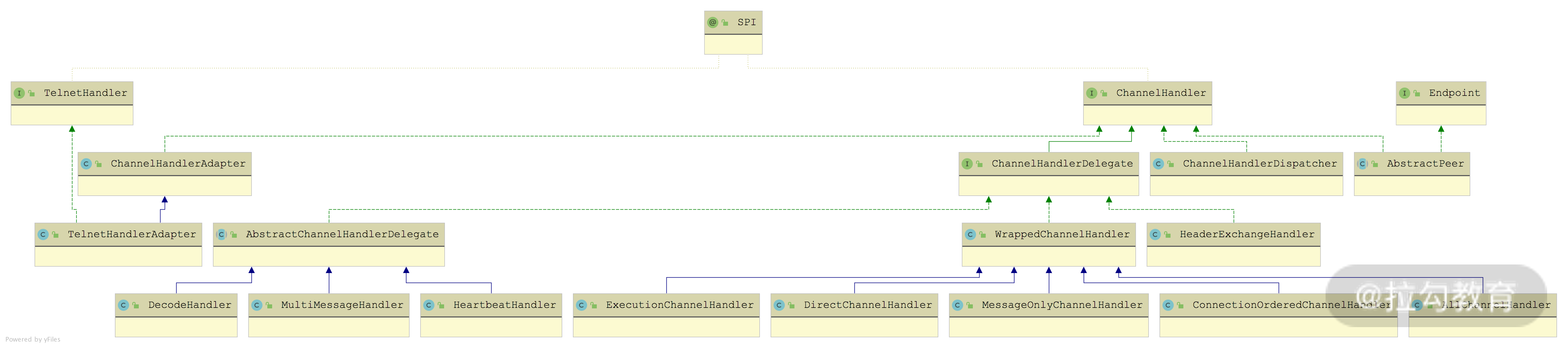
ChannelHandler 继承关系图
其中ChannelHandlerDispatcher在第 17 课时已经介绍过了,它负责将多个 ChannelHandler 对象聚合成一个 ChannelHandler 对象。
ChannelHandlerAdapter是 ChannelHandler 的一个空实现,TelnetHandlerAdapter 继承了它并实现了 TelnetHandler 接口。至于Dubbo 对 Telnet 的支持,我们会在后面的课时中单独介绍,这里就先不展开分析了。
从名字上看,ChannelHandlerDelegate接口是对另一个 ChannelHandler 对象的封装,它的两个实现类 AbstractChannelHandlerDelegate 和 WrappedChannelHandler 中也仅仅是封装了另一个 ChannelHandler 对象。
其中,AbstractChannelHandlerDelegate有三个实现类,都比较简单,我们来逐个讲解。
- MultiMessageHandler:专门处理 MultiMessage 的 ChannelHandler 实现。MultiMessage 是 Exchange 层的一种消息类型,它其中封装了多个消息。在 MultiMessageHandler 收到 MultiMessage 消息的时候,received() 方法会遍历其中的所有消息,并交给底层的 ChannelHandler 对象进行处理。
- DecodeHandler:专门处理 Decodeable 的 ChannelHandler 实现。实现了 Decodeable 接口的类都会提供了一个 decode() 方法实现对自身的解码,DecodeHandler.received() 方法就是通过该方法得到解码后的消息,然后传递给底层的 ChannelHandler 对象继续处理。
- HeartbeatHandler:专门处理心跳消息的 ChannelHandler 实现。在 HeartbeatHandler.received() 方法接收心跳请求的时候,会生成相应的心跳响应并返回;在收到心跳响应的时候,会打印相应的日志;在收到其他类型的消息时,会传递给底层的 ChannelHandler 对象进行处理。下面是其核心实现:
java
public void received(Channel channel, Object message) throws RemotingException {
setReadTimestamp(channel); // 记录最近的读写事件时间戳
if (isHeartbeatRequest(message)) { // 收到心跳请求
Request req = (Request) message;
if (req.isTwoWay()) { // 返回心跳响应,注意,携带请求的ID
Response res = new Response(req.getId(), req.getVersion());
res.setEvent(HEARTBEAT_EVENT);
channel.send(res);
return;
}
if (isHeartbeatResponse(message)) { // 收到心跳响应
// 打印日志(略)
return;
}
handler.received(channel, message);
}另外,我们可以看到,在 received() 和 send() 方法中,HeartbeatHandler 会将最近一次的读写时间作为附加属性记录到 Channel 中。
通过上述介绍,我们发现 AbstractChannelHandlerDelegate 下的三个实现,其实都是在原有 ChannelHandler 的基础上添加了一些增强功能,这是典型的装饰器模式的应用。
Dispatcher 与 ChannelHandler
接下来,我们介绍 ChannelHandlerDelegate 接口的另一条继承线------WrappedChannelHandler,其子类主要是决定了 Dubbo 以何种线程模型处理收到的事件和消息,就是所谓的"消息派发机制",与前面介绍的 ThreadPool 有紧密的联系。
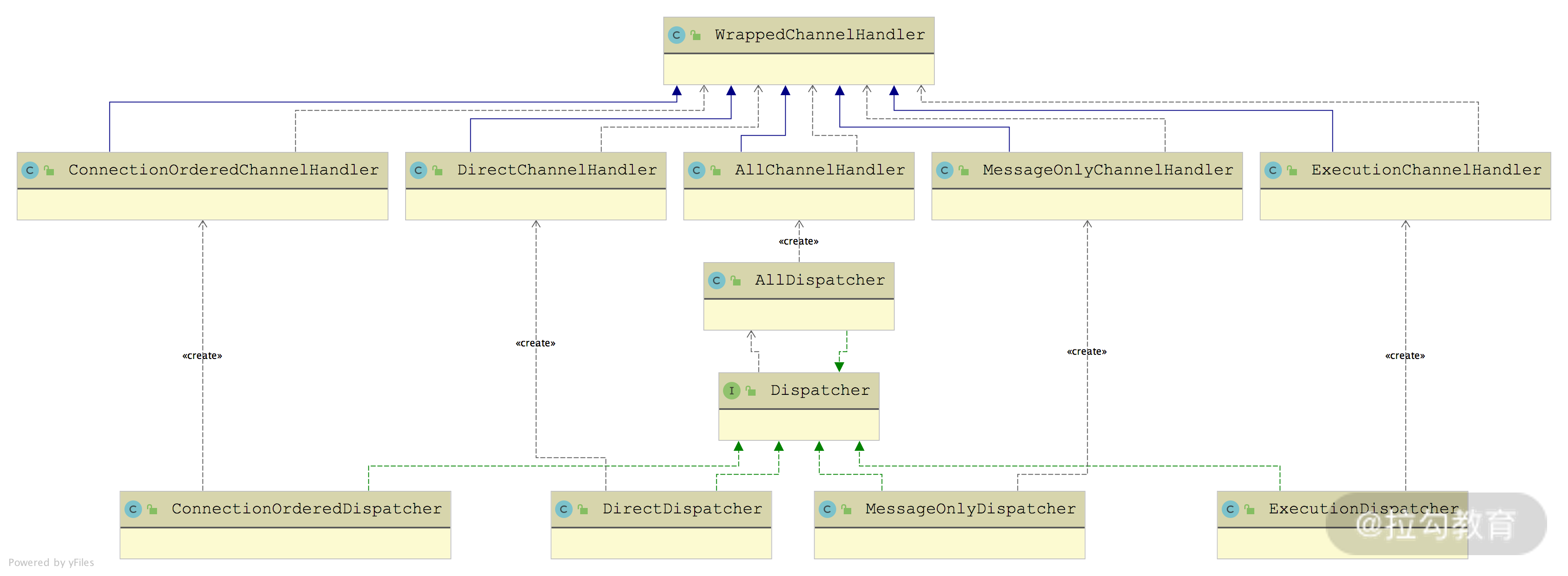
WrappedChannelHandler 继承关系图
从上图中我们可以看到,每个 WrappedChannelHandler 实现类的对象都由一个相应的 Dispatcher 实现类创建,下面是 Dispatcher 接口的定义:
java
@SPI(AllDispatcher.NAME) // 默认扩展名是all
public interface Dispatcher {
// 通过URL中的参数可以指定扩展名,覆盖默认扩展名
@Adaptive({"dispatcher", "dispather", "channel.handler"})
ChannelHandler dispatch(ChannelHandler handler, URL url);
}AllDispatcher 创建的是 AllChannelHandler 对象,它会将所有网络事件以及消息交给关联的线程池进行处理。AllChannelHandler覆盖了 WrappedChannelHandler 中除了 sent() 方法之外的其他网络事件处理方法,将调用其底层的 ChannelHandler 的逻辑放到关联的线程池中执行。
我们先来看 connect() 方法,其中会将CONNECTED 事件的处理封装成ChannelEventRunnable提交到线程池中执行,具体实现如下:
java
public void connected(Channel channel) throws RemotingException {
ExecutorService executor = getExecutorService(); // 获取公共线程池
// 将CONNECTED事件的处理封装成ChannelEventRunnable提交到线程池中执行
executor.execute(new ChannelEventRunnable(channel, handler, ChannelState.CONNECTED));
// 省略异常处理的逻辑
}这里的 getExecutorService() 方法会按照当前端点(Server/Client)的 URL 从 ExecutorRepository 中获取相应的公共线程池。
disconnected()方法处理连接断开事件,caught() 方法处理异常事件,它们也是按照上述方式实现的,这里不再展开赘述。
received() 方法会在当前端点收到数据的时候被调用,具体执行流程是先由 IO 线程(也就是 Netty 中的 EventLoopGroup)从二进制流中解码出请求,然后调用 AllChannelHandler 的 received() 方法,其中会将请求提交给线程池执行,执行完后调用 sent()方法,向对端写回响应结果。received() 方法的具体实现如下:
java
public void received(Channel channel, Object message) throws RemotingException {
// 获取线程池
ExecutorService executor = getPreferredExecutorService(message);
try {
// 将消息封装成ChannelEventRunnable任务,提交到线程池中执行
executor.execute(new ChannelEventRunnable(channel, handler, ChannelState.RECEIVED, message));
} catch (Throwable t) {
// 如果线程池满了,请求会被拒绝,这里会根据请求配置决定是否返回一个说明性的响应
if(message instanceof Request && t instanceof RejectedExecutionException) {
sendFeedback(channel, (Request) message, t);
return;
}
throw new ExecutionException("...");
}
}getPreferredExecutorService() 方法对响应做了特殊处理:如果请求在发送的时候指定了关联的线程池,在收到对应的响应消息的时候,会优先根据请求的 ID 查找请求关联的线程池处理响应。
java
public ExecutorService getPreferredExecutorService(Object msg) {
if (msg instanceof Response) {
Response response = (Response) msg;
DefaultFuture responseFuture = DefaultFuture.getFuture(response.getId()); // 获取请求关联的DefaultFuture
if (responseFuture == null) {
return getSharedExecutorService();
} else { // 如果请求关联了线程池,则会获取相关的线程来处理响应
ExecutorService executor = responseFuture.getExecutor();
if (executor == null || executor.isShutdown()) {
executor = getSharedExecutorService();
}
return executor;
}
} else { // 如果是请求消息,则直接使用公共的线程池处理
return getSharedExecutorService();
}
}这里涉及了 Request 和 Response 的概念,是 Exchange 层的概念,在后面会展开介绍,这里你只需要知道它们是不同的消息类型即可。
注意,AllChannelHandler 并没有覆盖父类的 sent() 方法,也就是说,发送消息是直接在当前线程调用 sent() 方法完成的。
下面我们来看剩余的 WrappedChannelHandler 的实现。ExecutionChannelHandler(由 ExecutionDispatcher 创建)只会将请求消息派发到线程池进行处理,也就是只重写了 received() 方法。对于响应消息以及其他网络事件(例如,连接建立事件、连接断开事件、心跳消息等),ExecutionChannelHandler 会直接在 IO 线程中进行处理。
DirectChannelHandler 实现(由 DirectDispatcher 创建)会在 IO 线程中处理所有的消息和网络事件。
MessageOnlyChannelHandler 实现(由 MessageOnlyDispatcher 创建)会将所有收到的消息提交到线程池处理,其他网络事件则是由 IO 线程直接处理。
ConnectionOrderedChannelHandler 实现(由 ConnectionOrderedDispatcher 创建)会将收到的消息交给线程池进行处理,对于连接建立以及断开事件,会提交到一个独立的线程池并排队进行处理。在 ConnectionOrderedChannelHandler 的构造方法中,会初始化一个线程池,该线程池的队列长度是固定的:
java
public ConnectionOrderedChannelHandler(ChannelHandler handler, URL url) {
super(handler, url);
String threadName = url.getParameter(THREAD_NAME_KEY, DEFAULT_THREAD_NAME);
// 注意,该线程池只有一个线程,队列的长度也是固定的,
// 由URL中的connect.queue.capacity参数指定
connectionExecutor = new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(url.getPositiveParameter(CONNECT_QUEUE_CAPACITY, Integer.MAX_VALUE)),
new NamedThreadFactory(threadName, true),
new AbortPolicyWithReport(threadName, url)
);
queuewarninglimit = url.getParameter(CONNECT_QUEUE_WARNING_SIZE, DEFAULT_CONNECT_QUEUE_WARNING_SIZE);
}在 ConnectionOrderedChannelHandler 的 connected() 方法和 disconnected() 方法实现中,会将连接建立和断开事件交给上述 connectionExecutor 线程池排队处理。
在上面介绍 WrappedChannelHandler 各个实现的时候,我们会看到其中有针对 ThreadlessExecutor 这种线程池类型的特殊处理,例如,ExecutionChannelHandler.received() 方法中就有如下的分支逻辑:
java
public void received(Channel channel, Object message) throws RemotingException {
// 获取线程池(请求绑定的线程池或是公共线程池)
ExecutorService executor = getPreferredExecutorService(message);
if (message instanceof Request) { // 请求消息直接提交给线程池处理
executor.execute(new ChannelEventRunnable(channel, handler, ChannelState.RECEIVED, message));
} else if (executor instanceof ThreadlessExecutor) {
// 针对ThreadlessExecutor这种线程池类型的特殊处理
executor.execute(new ChannelEventRunnable(channel, handler, ChannelState.RECEIVED, message));
} else {
handler.received(channel, message);
}
}ThreadlessExecutor 优化
ThreadlessExecutor 是一种特殊类型的线程池,与其他正常的线程池最主要的区别是:ThreadlessExecutor 内部不管理任何线程。
我们可以调用 ThreadlessExecutor 的execute() 方法,将任务提交给这个线程池,但是这些提交的任务不会被调度到任何线程执行,而是存储在阻塞队列中,只有当其他线程调用 ThreadlessExecutor.waitAndDrain() 方法时才会真正执行。也说就是,执行任务的与调用 waitAndDrain() 方法的是同一个线程。
**那为什么会有 ThreadlessExecutor 这个实现呢?**这主要是因为在 Dubbo 2.7.5 版本之前,在 WrappedChannelHandler 中会为每个连接启动一个线程池。
老版本中没有 ExecutorRepository 的概念,不会根据 URL 复用同一个线程池,而是通过 SPI 找到 ThreadPool 实现创建新线程池。
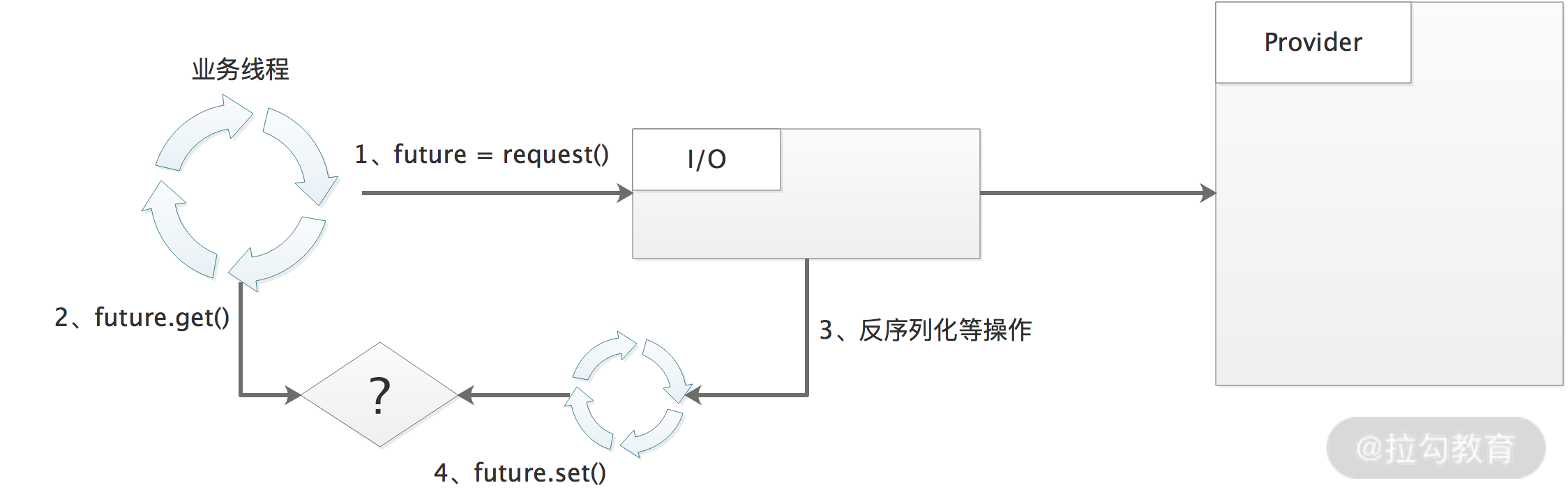
此时,Dubbo Consumer 同步请求的线程模型如下图所示:
Dubbo Consumer 同步请求线程模型
从图中我们可以看到下面的请求-响应流程:
- 业务线程发出请求之后,拿到一个 Future 实例。
- 业务线程紧接着调用 Future.get() 阻塞等待请求结果返回。
- 当响应返回之后,交由连接关联的独立线程池进行反序列化等解析处理。
- 待处理完成之后,将业务结果通过 Future.set() 方法返回给业务线程。
在这个设计里面,Consumer 端会维护一个线程池,而且线程池是按照连接隔离的,即每个连接独享一个线程池。这样,当面临需要消费大量服务且并发数比较大的场景时,例如,典型网关类场景,可能会导致 Consumer 端线程个数不断增加,导致线程调度消耗过多 CPU ,也可能因为线程创建过多而导致 OOM。
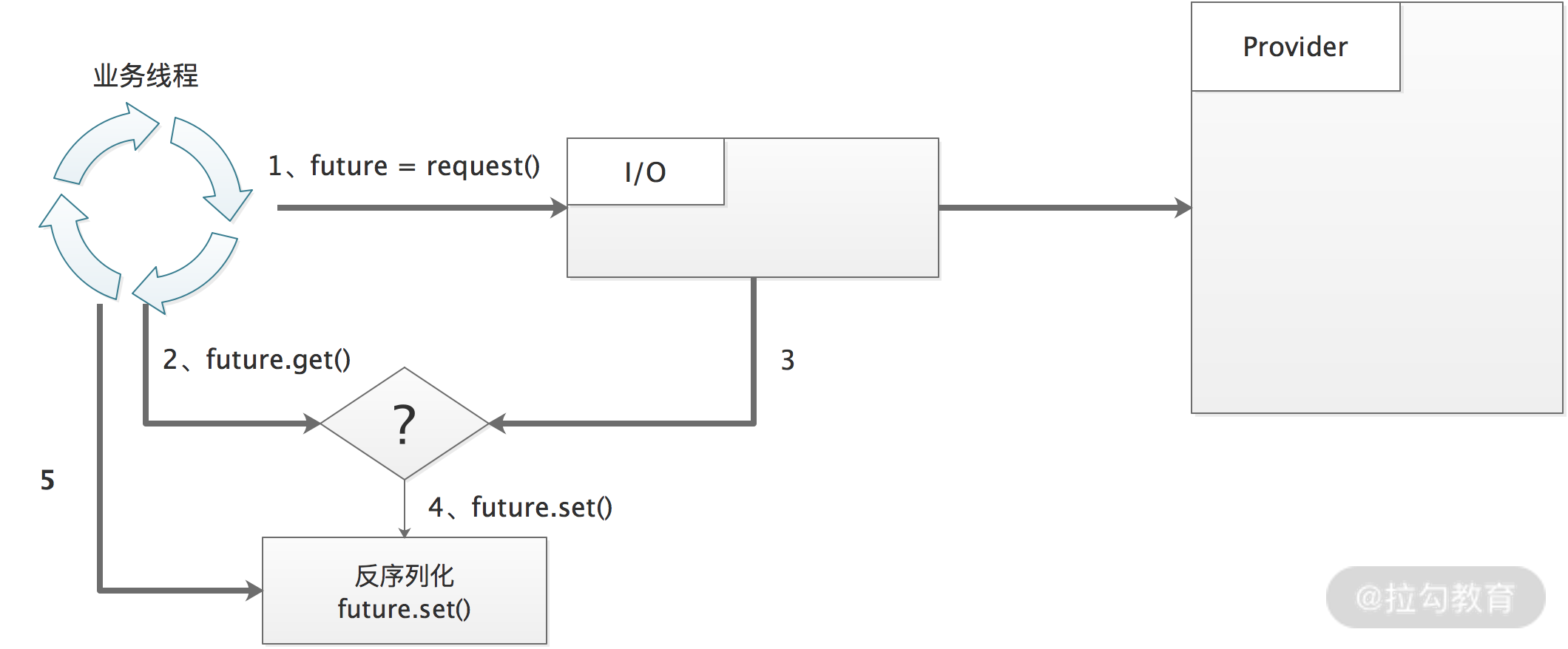
为了解决上述问题,Dubbo 在 2.7.5 版本之后,引入了 ThreadlessExecutor,将线程模型修改成了下图的样子:
引入 ThreadlessExecutor 后的结构图
- 业务线程发出请求之后,拿到一个 Future 对象。
- 业务线程会调用 ThreadlessExecutor.waitAndDrain() 方法,waitAndDrain() 方法会在阻塞队列上等待。
- 当收到响应时,IO 线程会生成一个任务,填充到 ThreadlessExecutor 队列中,
- 业务线程会将上面添加的任务取出,并在本线程中执行。得到业务结果之后,调用 Future.set() 方法进行设置,此时 waitAndDrain() 方法返回。
- 业务线程从 Future 中拿到结果值。
了解了 ThreadlessExecutor 出现的缘由之后,接下来我们再深入了解一下 ThreadlessExecutor 的核心实现。首先是 ThreadlessExecutor 的核心字段,有如下几个。
- queue(LinkedBlockingQueue类型):阻塞队列,用来在 IO 线程和业务线程之间传递任务。
- waiting、finished(Boolean类型):ThreadlessExecutor 中的 waitAndDrain() 方法一般与一次 RPC 调用绑定,只会执行一次。当后续再次调用 waitAndDrain() 方法时,会检查 finished 字段,若为true,则此次调用直接返回。当后续再次调用 execute() 方法提交任务时,会根据 waiting 字段决定任务是放入 queue 队列等待业务线程执行,还是直接由 sharedExecutor 线程池执行。
- sharedExecutor(ExecutorService类型):ThreadlessExecutor 底层关联的共享线程池,当业务线程已经不再等待响应时,会由该共享线程执行提交的任务。
- waitingFuture(CompletableFuture类型):指向请求对应的 DefaultFuture 对象,其具体实现我们会在后面的课时详细展开介绍。
ThreadlessExecutor 的核心逻辑在 execute() 方法和 waitAndDrain() 方法**。**execute() 方法相对简单,它会根据 waiting 状态决定任务提交到哪里,相关示例代码如下:
java
public void execute(Runnable runnable) {
synchronized (lock) {
if (!waiting) { // 判断业务线程是否还在等待响应结果
// 不等待,则直接交给共享线程池处理任务
sharedExecutor.execute(runnable);
} else {// 业务线程还在等待,则将任务写入队列,然后由业务线程自己执行
queue.add(runnable);
}
}
}waitAndDrain() 方法中首先会检测 finished 字段值,然后获取阻塞队列中的全部任务并执行,执行完成之后会修改finished和 waiting 字段,标识当前 ThreadlessExecutor 已使用完毕,无业务线程等待。
java
public void waitAndDrain() throws InterruptedException {
if (finished) { // 检测当前ThreadlessExecutor状态
return;
}
// 获取阻塞队列中获取任务
Runnable runnable = queue.take();
synchronized (lock) {
waiting = false; // 修改waiting状态
runnable.run(); // 执行任务
}
runnable = queue.poll(); // 如果阻塞队列中还有其他任务,也需要一并执行
while (runnable != null) {
runnable.run(); // 省略异常处理逻辑
runnable = queue.poll();
}
finished = true; // 修改finished状态
}到此为止,Transporter 层对 ChannelHandler 的实现就介绍完了,其中涉及了多个 ChannelHandler 的装饰器,为了帮助你更好地理解,这里我们回到 NettyServer 中,看看它是如何对上层 ChannelHandler 进行封装的。
在 NettyServer 的构造方法中会调用 ChannelHandlers.wrap() 方法对传入的 ChannelHandler 对象进行修饰:
java
protected ChannelHandler wrapInternal(ChannelHandler handler, URL url) {
return new MultiMessageHandler(new HeartbeatHandler(ExtensionLoader.getExtensionLoader(Dispatcher.class)
.getAdaptiveExtension().dispatch(handler, url)));
}结合前面的分析,我们可以得到下面这张图:
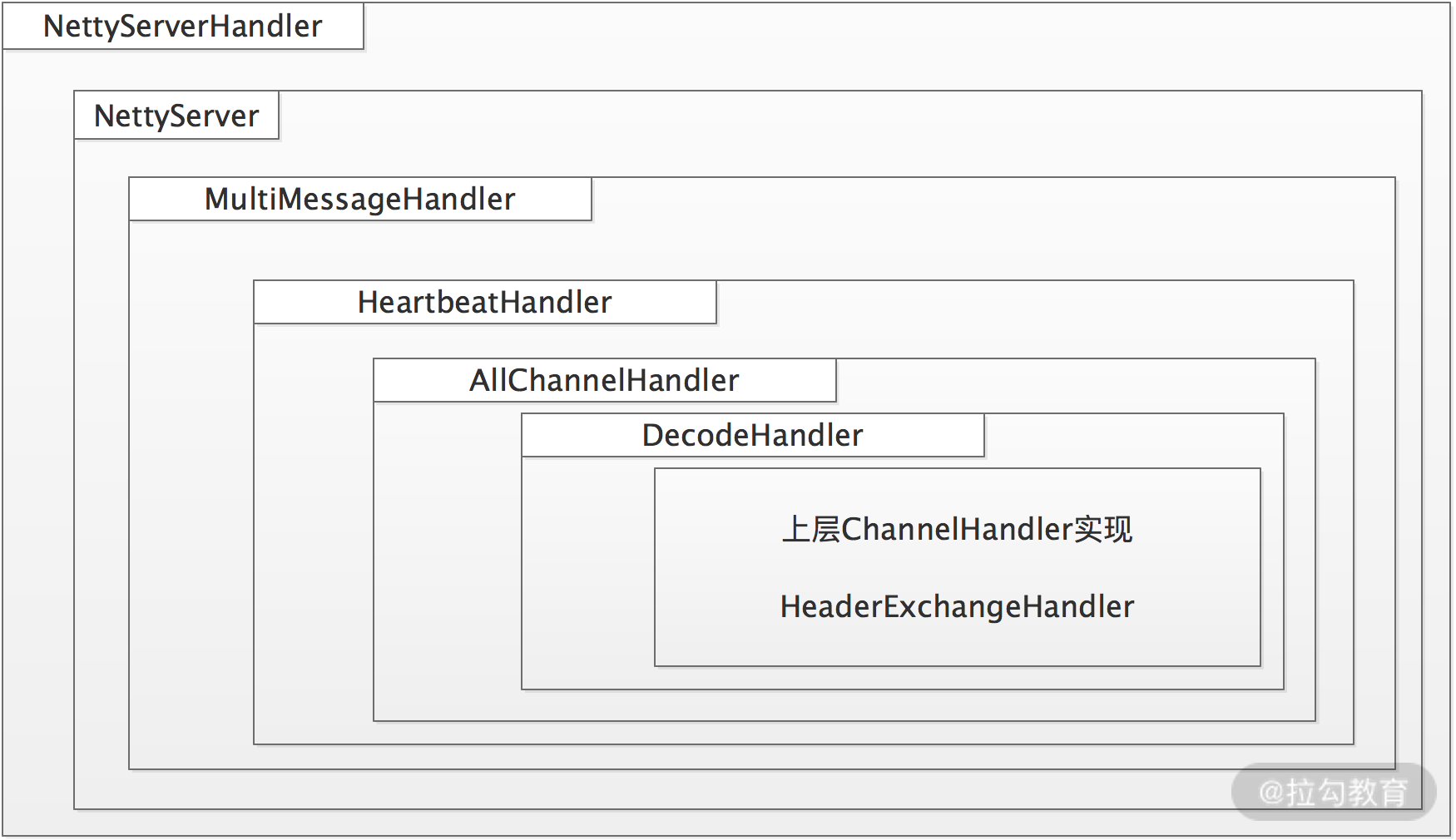
Server 端 ChannelHandler 结构图
我们可以在创建 NettyServerHandler 的地方添加断点 Debug 得到下图,也印证了上图的内容:

总结
本课时我们重点介绍了 Dubbo Transporter 层中 Client、 Channel、ChannelHandler 相关的实现以及优化。
首先我们介绍了 AbstractClient 抽象接口以及基于 Netty 4 的 NettyClient 实现。接下来,介绍了 AbstractChannel 抽象类以及 NettyChannel 实现。最后,我们深入分析了 ChannelHandler 接口实现,其中详细分析 WrappedChannelHandler 等关键 ChannelHandler 实现,以及 ThreadlessExecutor 优化。
21 Exchange 层剖析:彻底搞懂 Request-Response 模型(上)
在前面的课程中,我们深入介绍了 Dubbo Remoting 中的 Transport 层,了解了 Dubbo 抽象出来的端到端的统一传输层接口,并分析了以 Netty 为基础的相关实现。当然,其他 NIO 框架的接入也是类似的,本课程就不再展开赘述了。
在本课时中,我们将介绍 Transport 层的上一层,也是 Dubbo Remoting 层中的最顶层------ Exchange 层。Dubbo 将信息交换行为抽象成 Exchange 层,官方文档对这一层的说明是:封装了请求-响应的语义,即关注一问一答的交互模式,实现了同步转异步。在 Exchange 这一层,以 Request 和 Response 为中心,针对 Channel、ChannelHandler、Client、RemotingServer 等接口进行实现。
下面我们从 Request 和 Response 这一对基础类开始,依次介绍 Exchange 层中 ExchangeChannel、HeaderExchangeHandler 的核心实现。
Request 和 Response
Exchange 层的 Request 和 Response 这两个类是 Exchange 层的核心对象,是对请求和响应的抽象。我们先来看Request 类的核心字段:
java
public class Request {
// 用于生成请求的自增ID,当递增到Long.MAX_VALUE之后,会溢出到Long.MIN_VALUE,我们可以继续使用该负数作为消息ID
private static final AtomicLong INVOKE_ID = new AtomicLong(0);
private final long mId; // 请求的ID
private String mVersion; // 请求版本号
// 请求的双向标识,如果该字段设置为true,则Server端在收到请求后,
// 需要给Client返回一个响应
private boolean mTwoWay = true;
// 事件标识,例如心跳请求、只读请求等,都会带有这个标识
private boolean mEvent = false;
// 请求发送到Server之后,由Decoder将二进制数据解码成Request对象,
// 如果解码环节遇到异常,则会设置该标识,然后交由其他ChannelHandler根据
// 该标识做进一步处理
private boolean mBroken = false;
// 请求体,可以是任何Java类型的对象,也可以是null
private Object mData;
}接下来是 Response 的核心字段:
java
public class Response {
// 响应ID,与相应请求的ID一致
private long mId = 0;
// 当前协议的版本号,与请求消息的版本号一致
private String mVersion;
// 响应状态码,有OK、CLIENT_TIMEOUT、SERVER_TIMEOUT等10多个可选值
private byte mStatus = OK;
private boolean mEvent = false;
private String mErrorMsg; // 可读的错误响应消息
private Object mResult; // 响应体
}ExchangeChannel & DefaultFuture
在前面的课时中,我们介绍了 Channel 接口的功能以及 Transport 层对 Channel 接口的实现。在 Exchange 层中定义了 ExchangeChannel 接口,它在 Channel 接口之上抽象了 Exchange 层的网络连接。ExchangeChannel 接口的定义如下:

ExchangeChannel 接口
其中,request() 方法负责发送请求,从图中可以看到这里有两个重载,其中一个重载可以指定请求的超时时间,返回值都是 Future 对象。
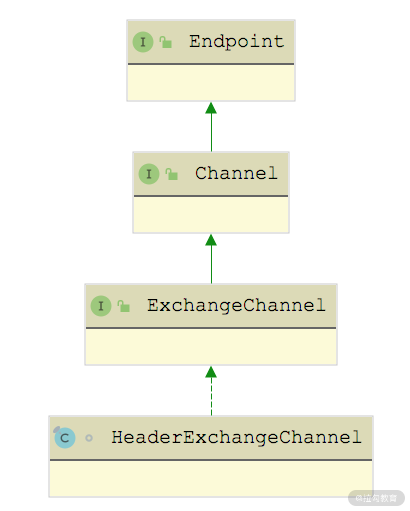
HeaderExchangeChannel 继承关系图
从上图中可以看出,HeaderExchangeChannel 是 ExchangeChannel 的实现,它本身是 Channel 的装饰器,封装了一个 Channel 对象,其 send() 方法和 request() 方法的实现都是依赖底层修饰的这个 Channel 对象实现的。
java
public void send(Object message, boolean sent) throws RemotingException {
if (message instanceof Request || message instanceof Response || message instanceof String) {
channel.send(message, sent);
} else {
Request request = new Request();
request.setVersion(Version.getProtocolVersion());
request.setTwoWay(false);
request.setData(message);
channel.send(request, sent);
}
}
public CompletableFuture<Object> request(Object request, int timeout, ExecutorService executor) throws RemotingException {
Request req = new Request(); // 创建Request对象
req.setVersion(Version.getProtocolVersion());
req.setTwoWay(true);
req.setData(request);
DefaultFuture future = DefaultFuture.newFuture(channel,
req, timeout, executor); // 创建DefaultFuture
channel.send(req);
return future;
}注意这里的 request() 方法,它返回的是一个 DefaultFuture 对象。通过前面课时的介绍我们知道,io.netty.channel.Channel 的 send() 方法会返回一个 ChannelFuture 方法,表示此次发送操作是否完成,而这里的DefaultFuture 就表示此次请求-响应是否完成,也就是说,要收到响应为 Future 才算完成。
下面我们就来深入介绍一下请求发送过程中涉及的 DefaultFuture 以及HeaderExchangeChannel的内容。
首先来了解一下 DefaultFuture 的具体实现,它继承了 JDK 中的 CompletableFuture,其中维护了两个 static 集合。
- CHANNELS(Map集合):管理请求与 Channel 之间的关联关系,其中 Key 为请求 ID,Value 为发送请求的 Channel。
- FUTURES(Map集合):管理请求与 DefaultFuture 之间的关联关系,其中 Key 为请求 ID,Value 为请求对应的 Future。
DefaultFuture 中核心的实例字段包括如下几个。
- request(Request 类型)和 id(Long 类型):对应请求以及请求的 ID。
- channel(Channel 类型):发送请求的 Channel。
- timeout(int 类型):整个请求-响应交互完成的超时时间。
- start(long 类型):该 DefaultFuture 的创建时间。
- sent(volatile long 类型):请求发送的时间。
- timeoutCheckTask(Timeout 类型):该定时任务到期时,表示对端响应超时。
- executor(ExecutorService 类型):请求关联的线程池。
DefaultFuture.newFuture() 方法创建 DefaultFuture 对象时,需要先初始化上述字段,并创建请求相应的超时定时任务:
java
public static DefaultFuture newFuture(Channel channel, Request request, int timeout, ExecutorService executor) {
// 创建DefaultFuture对象,并初始化其中的核心字段
final DefaultFuture future = new DefaultFuture(channel, request, timeout);
future.setExecutor(executor);
// 对于ThreadlessExecutor的特殊处理,ThreadlessExecutor可以关联一个waitingFuture,就是这里创建DefaultFuture对象
if (executor instanceof ThreadlessExecutor) {
((ThreadlessExecutor) executor).setWaitingFuture(future);
}
// 创建一个定时任务,用处理响应超时的情况
timeoutCheck(future);
return future;
}在 HeaderExchangeChannel.request() 方法中完成 DefaultFuture 对象的创建之后,会将请求通过底层的 Dubbo Channel 发送出去,发送过程中会触发沿途 ChannelHandler 的 sent() 方法,其中的 HeaderExchangeHandler 会调用 DefaultFuture.sent() 方法更新 sent 字段,记录请求发送的时间戳。后续如果响应超时,则会将该发送时间戳添加到提示信息中。
过一段时间之后,Consumer 会收到对端返回的响应,在读取到完整响应之后,会触发 Dubbo Channel 中各个 ChannelHandler 的 received() 方法,其中就包括上一课时介绍的 WrappedChannelHandler。例如,AllChannelHandler 子类会将后续 ChannelHandler.received() 方法的调用封装成任务提交到线程池中,响应会提交到 DefaultFuture 关联的线程池中,如上一课时介绍的 ThreadlessExecutor,然后由业务线程继续后续的 ChannelHandler 调用。(你也可以回顾一下上一课时对 Transport 层 Dispatcher 以及 ThreadlessExecutor 的介绍。)
当响应传递到 HeaderExchangeHandler 的时候,会通过调用 handleResponse() 方法进行处理,其中调用了 DefaultFuture.received() 方法,该方法会找到响应关联的 DefaultFuture 对象(根据请求 ID 从 FUTURES 集合查找)并调用 doReceived() 方法,将 DefaultFuture 设置为完成状态。
java
public static void received(Channel channel, Response response, boolean timeout) { // 省略try/finally代码块
// 清理FUTURES中记录的请求ID与DefaultFuture之间的映射关系
DefaultFuture future = FUTURES.remove(response.getId());
if (future != null) {
Timeout t = future.timeoutCheckTask;
if (!timeout) { // 未超时,取消定时任务
t.cancel();
}
future.doReceived(response); // 调用doReceived()方法
}else{ // 查找不到关联的DefaultFuture会打印日志(略)}
// 清理CHANNELS中记录的请求ID与Channel之间的映射关系
CHANNELS.remove(response.getId());
}
// DefaultFuture.doReceived()方法的代码片段
private void doReceived(Response res) {
if (res == null) {
throw new IllegalStateException("response cannot be null");
}
if (res.getStatus() == Response.OK) { // 正常响应
this.complete(res.getResult());
} else if (res.getStatus() == Response.CLIENT_TIMEOUT || res.getStatus() == Response.SERVER_TIMEOUT) { // 超时
this.completeExceptionally(new TimeoutException(res.getStatus() == Response.SERVER_TIMEOUT, channel, res.getErrorMessage()));
} else { // 其他异常
this.completeExceptionally(new RemotingException(channel, res.getErrorMessage()));
}
// 下面是针对ThreadlessExecutor的兜底处理,主要是防止业务线程一直阻塞在ThreadlessExecutor上
if (executor != null && executor instanceof ThreadlessExecutor) {
ThreadlessExecutor threadlessExecutor = (ThreadlessExecutor) executor;
if (threadlessExecutor.isWaiting()) {
// notifyReturn()方法会向ThreadlessExecutor提交一个任务,这样业务线程就不会阻塞了,提交的任务会尝试将DefaultFuture设置为异常结束
threadlessExecutor.notifyReturn(new IllegalStateException("The result has returned..."));
}
}
}下面我们再来看看响应超时的场景。在创建 DefaultFuture 时调用的 timeoutCheck() 方法中,会创建 TimeoutCheckTask 定时任务,并添加到时间轮中,具体实现如下:
java
private static void timeoutCheck(DefaultFuture future) {
TimeoutCheckTask task = new TimeoutCheckTask(future.getId());
future.timeoutCheckTask = TIME_OUT_TIMER.newTimeout(task, future.getTimeout(), TimeUnit.MILLISECONDS);
}TIME_OUT_TIMER 是一个 HashedWheelTimer 对象,即 Dubbo 中对时间轮的实现,这是一个 static 字段,所有 DefaultFuture 对象共用一个。
TimeoutCheckTask 是 DefaultFuture 中的内部类,实现了 TimerTask 接口,可以提交到时间轮中等待执行。当响应超时的时候,TimeoutCheckTask 会创建一个 Response,并调用前面介绍的 DefaultFuture.received() 方法。示例代码如下:
java
public void run(Timeout timeout) {
// 检查该任务关联的DefaultFuture对象是否已经完成
if (future.getExecutor() != null) { // 提交到线程池执行,注意ThreadlessExecutor的情况
future.getExecutor().execute(() -> notifyTimeout(future));
} else {
notifyTimeout(future);
}
}
private void notifyTimeout(DefaultFuture future) {
// 没有收到对端的响应,这里会创建一个Response,表示超时的响应
Response timeoutResponse = new Response(future.getId());
timeoutResponse.setStatus(future.isSent() ? Response.SERVER_TIMEOUT : Response.CLIENT_TIMEOUT);
timeoutResponse.setErrorMessage(future.getTimeoutMessage(true));
// 将关联的DefaultFuture标记为超时异常完成
DefaultFuture.received(future.getChannel(), timeoutResponse, true);
}HeaderExchangeHandler
在前面介绍 DefaultFuture 时,我们简单说明了请求-响应的流程,其实无论是发送请求还是处理响应,都会涉及 HeaderExchangeHandler,所以这里我们就来介绍一下 HeaderExchangeHandler 的内容。
HeaderExchangeHandler 是 ExchangeHandler 的装饰器,其中维护了一个 ExchangeHandler 对象,ExchangeHandler 接口是 Exchange 层与上层交互的接口之一,上层调用方可以实现该接口完成自身的功能;然后再由 HeaderExchangeHandler 修饰,具备 Exchange 层处理 Request-Response 的能力;最后再由 Transport ChannelHandler 修饰,具备 Transport 层的能力。如下图所示:
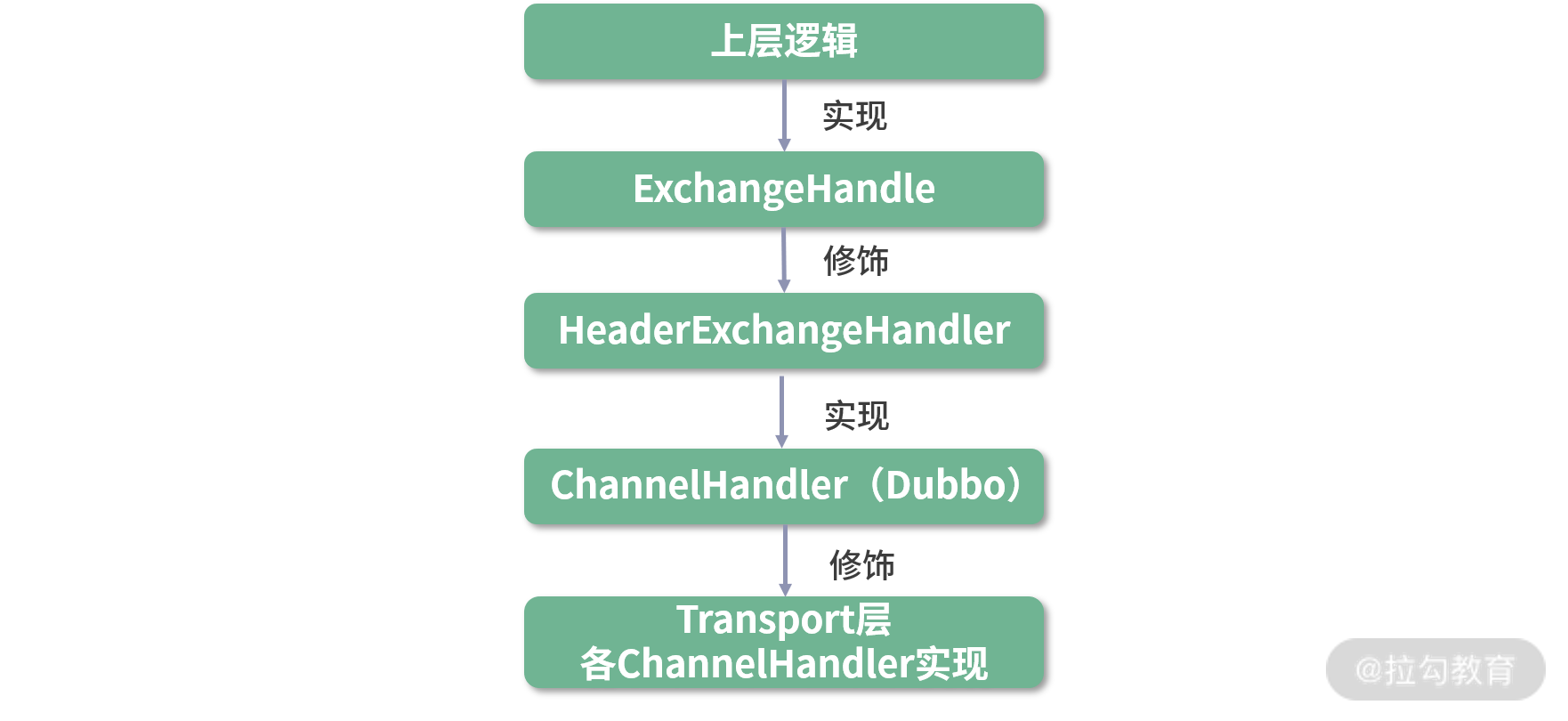
ChannelHandler 继承关系总览图
HeaderExchangeHandler 作为一个装饰器,其 connected()、disconnected()、sent()、received()、caught() 方法最终都会转发给上层提供的 ExchangeHandler 进行处理。这里我们需要聚焦的是 HeaderExchangeHandler 本身对 Request 和 Response 的处理逻辑。
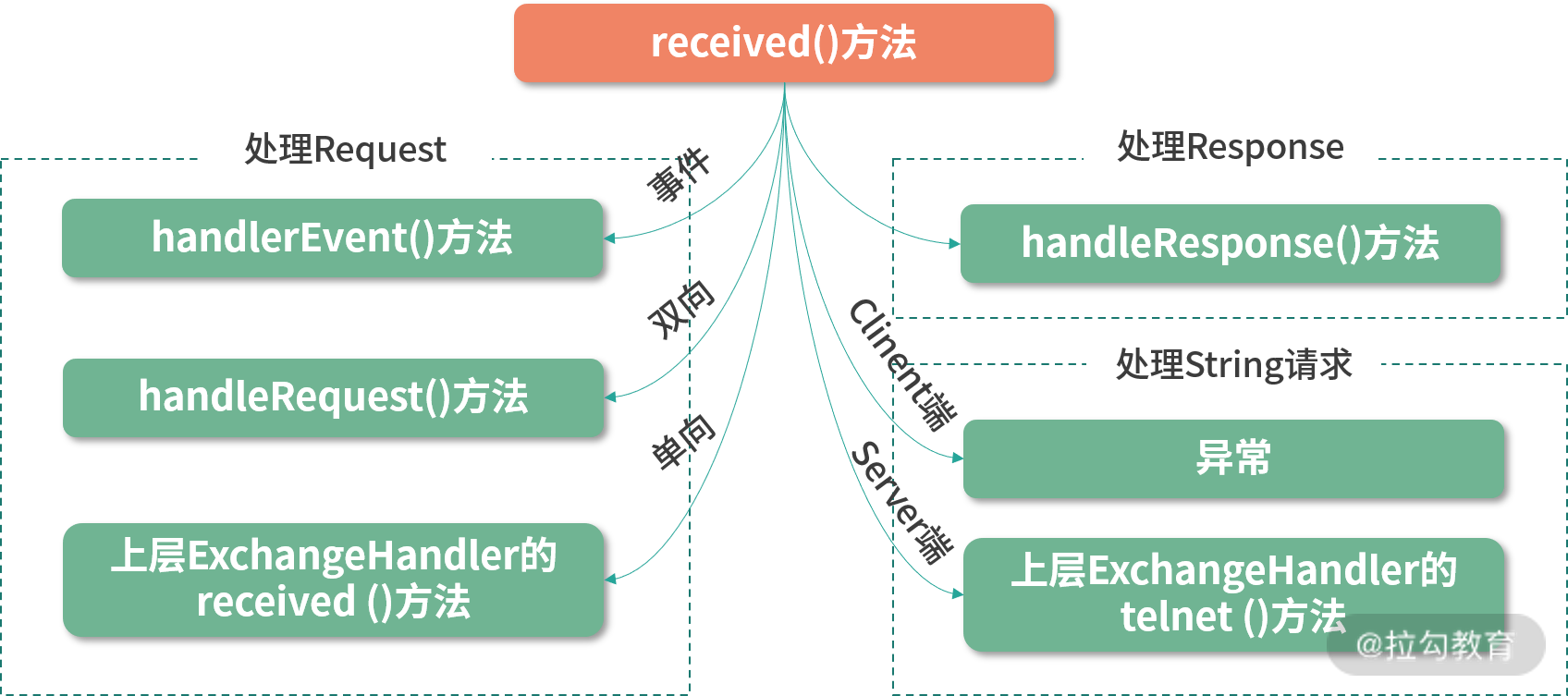
received() 方法处理的消息分类
结合上图,我们可以看到在received() 方法中,对收到的消息进行了分类处理。
- 只读请求会由handlerEvent() 方法进行处理,它会在 Channel 上设置 channel.readonly 标志,后续介绍的上层调用中会读取该值。
java
void handlerEvent(Channel channel, Request req) throws RemotingException {
if (req.getData() != null && req.getData().equals(READONLY_EVENT)) {
channel.setAttribute(Constants.CHANNEL_ATTRIBUTE_READONLY_KEY, Boolean.TRUE);
}
}- 双向请求由handleRequest() 方法进行处理,会先对解码失败的请求进行处理,返回异常响应;然后将正常解码的请求交给上层实现的 ExchangeHandler 进行处理,并添加回调。上层 ExchangeHandler 处理完请求后,会触发回调,根据处理结果填充响应结果和响应码,并向对端发送。
java
void handleRequest(final ExchangeChannel channel, Request req) throws RemotingException {
Response res = new Response(req.getId(), req.getVersion());
if (req.isBroken()) { // 请求解码失败
Object data = req.getData();
// 设置异常信息和响应码
res.setErrorMessage("Fail to decode request due to: " + msg);
res.setStatus(Response.BAD_REQUEST);
channel.send(res); // 将异常响应返回给对端
return;
}
Object msg = req.getData();
// 交给上层实现的ExchangeHandler进行处理
CompletionStage<Object> future = handler.reply(channel, msg);
future.whenComplete((appResult, t) -> { // 处理结束后的回调
if (t == null) { // 返回正常响应
res.setStatus(Response.OK);
res.setResult(appResult);
} else { // 处理过程发生异常,设置异常信息和错误码
res.setStatus(Response.SERVICE_ERROR);
res.setErrorMessage(StringUtils.toString(t));
}
channel.send(res); // 发送响应
});
}- 单向请求直接委托给上层 ExchangeHandler 实现的 received() 方法进行处理,由于不需要响应,HeaderExchangeHandler 不会关注处理结果。
- 对于 Response 的处理,前文已提到了,HeaderExchangeHandler 会通过handleResponse() 方法将关联的 DefaultFuture 设置为完成状态(或是异常完成状态),具体内容这里不再展开讲述。
- 对于 String 类型的消息,HeaderExchangeHandler 会根据当前服务的角色进行分类,具体与 Dubbo 对 telnet 的支持相关,后面的课时会详细介绍,这里就不展开分析了。
接下来我们再来看sent() 方法,该方法会通知上层 ExchangeHandler 实现的 sent() 方法,同时还会针对 Request 请求调用 DefaultFuture.sent() 方法记录请求的具体发送时间,该逻辑在前文也已经介绍过了,这里不再重复。
在connected() 方法中,会为 Dubbo Channel 创建相应的 HeaderExchangeChannel,并将两者绑定,然后通知上层 ExchangeHandler 处理 connect 事件。
在disconnected() 方法中,首先通知上层 ExchangeHandler 进行处理,之后在 DefaultFuture.closeChannel() 通知 DefaultFuture 连接断开(其实就是创建并传递一个 Response,该 Response 的状态码为 CHANNEL_INACTIVE),这样就不会继续阻塞业务线程了,最后再将 HeaderExchangeChannel 与底层的 Dubbo Channel 解绑。
总结
本课时我们重点介绍了 Dubbo Exchange 层中对 Channel 和 ChannelHandler 接口的实现。
我们首先介绍了 Exchange 层中请求-响应模型的基本抽象,即 Request 类和 Response 类。然后又介绍了 ExchangeChannel 对 Channel 接口的实现,同时还说明了发送请求之后得到的 DefaultFuture 对象,这也是上一课时遗留的小问题。最后,讲解了 HeaderExchangeHandler 是如何将 Transporter 层的 ChannelHandler 对象与上层的 ExchangeHandler 对象相关联的。
22 Exchange 层剖析:彻底搞懂 Request-Response 模型(下)
在上一课时中,我们重点分析了 Exchange 层中 Channel 接口以及 ChannelHandler 接口的核心实现,同时还介绍 Request、Response 两个基础类,以及 DefaultFuture 这个 Future 实现。本课时,我们将继续讲解 Exchange 层其他接口的实现逻辑。
HeaderExchangeClient
HeaderExchangeClient 是 Client 装饰器,主要为其装饰的 Client 添加两个功能:
- 维持与 Server 的长连状态,这是通过定时发送心跳消息实现的;
- 在因故障掉线之后,进行重连,这是通过定时检查连接状态实现的。
因此,HeaderExchangeClient 侧重定时轮资源的分配、定时任务的创建和取消。
HeaderExchangeClient 实现的是 ExchangeClient 接口,如下图所示,间接实现了 ExchangeChannel 和 Client 接口,ExchangeClient 接口是个空接口,没有定义任何方法。
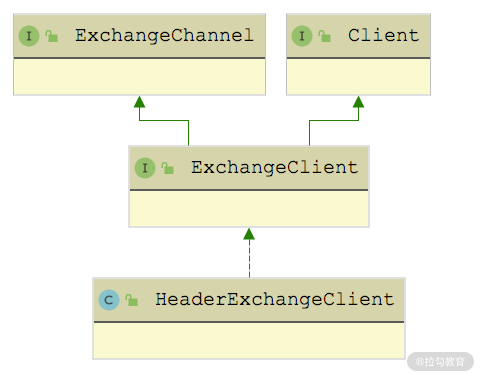
HeaderExchangeClient 继承关系图
HeaderExchangeClient 中有以下两个核心字段。
- client(Client 类型):被修饰的 Client 对象。HeaderExchangeClient 中对 Client 接口的实现,都会委托给该对象进行处理。
- channel(ExchangeChannel 类型):Client 与服务端建立的连接,HeaderExchangeChannel 也是一个装饰器,在前面我们已经详细介绍过了,这里就不再展开介绍。HeaderExchangeClient 中对 ExchangeChannel 接口的实现,都会委托给该对象进行处理。
HeaderExchangeClient 构造方法的第一个参数封装 Transport 层的 Client 对象,第二个参数 startTimer参与控制是否开启心跳定时任务和重连定时任务,如果为 true,才会进一步根据其他条件,最终决定是否启动定时任务。这里我们以心跳定时任务为例:
java
private void startHeartBeatTask(URL url) {
if (!client.canHandleIdle()) { // Client的具体实现决定是否启动该心跳任务
AbstractTimerTask.ChannelProvider cp = () -> Collections.singletonList(HeaderExchangeClient.this);
// 计算心跳间隔,最小间隔不能低于1s
int heartbeat = getHeartbeat(url);
long heartbeatTick = calculateLeastDuration(heartbeat);
// 创建心跳任务
this.heartBeatTimerTask = new HeartbeatTimerTask(cp, heartbeatTick, heartbeat);
// 提交到IDLE_CHECK_TIMER这个时间轮中等待执行
IDLE_CHECK_TIMER.newTimeout(heartBeatTimerTask, heartbeatTick, TimeUnit.MILLISECONDS);
}
}重连定时任务是在 startReconnectTask() 方法中启动的,其中会根据 URL 中的参数决定是否启动任务。重连定时任务最终也是提交到 IDLE_CHECK_TIMER 这个时间轮中,时间轮定义如下:
java
private static final HashedWheelTimer IDLE_CHECK_TIMER = new HashedWheelTimer(
new NamedThreadFactory("dubbo-client-idleCheck", true), 1, TimeUnit.SECONDS, TICKS_PER_WHEEL);其实,startReconnectTask() 方法的具体实现与前面展示的 startHeartBeatTask() 方法类似,这里就不再赘述。
下面我们继续回到心跳定时任务进行分析,你可以回顾第 20 课时介绍的 NettyClient 实现,其 canHandleIdle() 方法返回 true,表示该实现可以自己发送心跳请求,无须 HeaderExchangeClient 再启动一个定时任务。NettyClient 主要依靠 IdleStateHandler 中的定时任务来触发心跳事件,依靠 NettyClientHandler 来发送心跳请求。
对于无法自己发送心跳请求的 Client 实现,HeaderExchangeClient 会为其启动 HeartbeatTimerTask 心跳定时任务,其继承关系如下图所示:
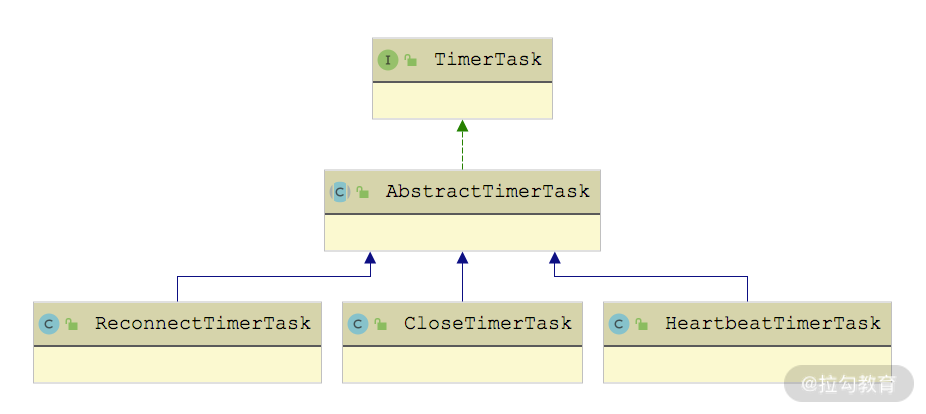
TimerTask 继承关系图
我们先来看 AbstractTimerTask 这个抽象类,它有三个字段。
- channelProvider(ChannelProvider类型):ChannelProvider 是 AbstractTimerTask 抽象类中定义的内部接口,定时任务会从该对象中获取 Channel。
- tick(Long类型):任务的过期时间。
- cancel(boolean类型):任务是否已取消。
AbstractTimerTask 抽象类实现了 TimerTask 接口的 run() 方法,首先会从 ChannelProvider 中获取此次任务相关的 Channel 集合(在 Client 端只有一个 Channel,在 Server 端有多个 Channel),然后检查 Channel 的状态,针对未关闭的 Channel 执行 doTask() 方法处理,最后通过 reput() 方法将当前任务重新加入时间轮中,等待再次到期执行。
AbstractTimerTask.run() 方法的具体实现如下:
java
public void run(Timeout timeout) throws Exception {
// 从ChannelProvider中获取任务要操作的Channel集合
Collection<Channel> c = channelProvider.getChannels();
for (Channel channel : c) {
if (channel.isClosed()) { // 检测Channel状态
continue;
}
doTask(channel); // 执行任务
}
reput(timeout, tick); // 将当前任务重新加入时间轮中,等待执行
}doTask() 是一个 AbstractTimerTask 留给子类实现的抽象方法,不同的定时任务执行不同的操作。例如,HeartbeatTimerTask.doTask() 方法中会读取最后一次读写时间,然后计算距离当前的时间,如果大于心跳间隔,就会发送一个心跳请求,核心实现如下:
java
protected void doTask(Channel channel) {
// 获取最后一次读写时间
Long lastRead = lastRead(channel);
Long lastWrite = lastWrite(channel);
if ((lastRead != null && now() - lastRead > heartbeat)
|| (lastWrite != null && now() - lastWrite > heartbeat)) {
// 最后一次读写时间超过心跳时间,就会发送心跳请求
Request req = new Request();
req.setVersion(Version.getProtocolVersion());
req.setTwoWay(true);
req.setEvent(HEARTBEAT_EVENT);
channel.send(req);
}
}这里 lastRead 和 lastWrite 时间戳,都是从要待处理 Channel 的附加属性中获取的,对应的 Key 分别是:KEY_READ_TIMESTAMP、KEY_WRITE_TIMESTAMP。你可以回顾前面课程中介绍的 HeartbeatHandler,它属于 Transport 层,是一个 ChannelHandler 的装饰器,在其 connected() 、sent() 方法中会记录最后一次写操作时间,在其 connected()、received() 方法中会记录最后一次读操作时间,在其 disconnected() 方法中会清理这两个时间戳。
在 ReconnectTimerTask 中会检测待处理 Channel 的连接状态,以及读操作的空闲时间,对于断开或是空闲时间较长的 Channel 进行重连,具体逻辑这里就不再展开了。
HeaderExchangeClient 最后要关注的是它的关闭流程,具体实现在 close() 方法中,如下所示:
java
public void close(int timeout) {
startClose(); // 将closing字段设置为true
doClose(); // 关闭心跳定时任务和重连定时任务
channel.close(timeout); // 关闭HeaderExchangeChannel
}在 HeaderExchangeChannel.close(timeout) 方法中首先会将自身的 closed 字段设置为 true,这样就不会继续发送请求。如果当前 Channel 上还有请求未收到响应,会循环等待至收到响应,如果超时未收到响应,会自己创建一个状态码将连接关闭的 Response 交给 DefaultFuture 处理,与收到 disconnected 事件相同。然后会关闭 Transport 层的 Channel,以 NettyChannel 为例,NettyChannel.close() 方法会先将自身的 closed 字段设置为 true,清理 CHANNEL_MAP 缓存中的记录,以及 Channel 的附加属性,最后才是关闭 io.netty.channel.Channel。
HeaderExchangeServer
下面再来看 HeaderExchangeServer,其继承关系如下图所示,其中 Endpoint、RemotingServer、Resetable 这三个接口我们在前面已经详细介绍过了,这里不再重复。
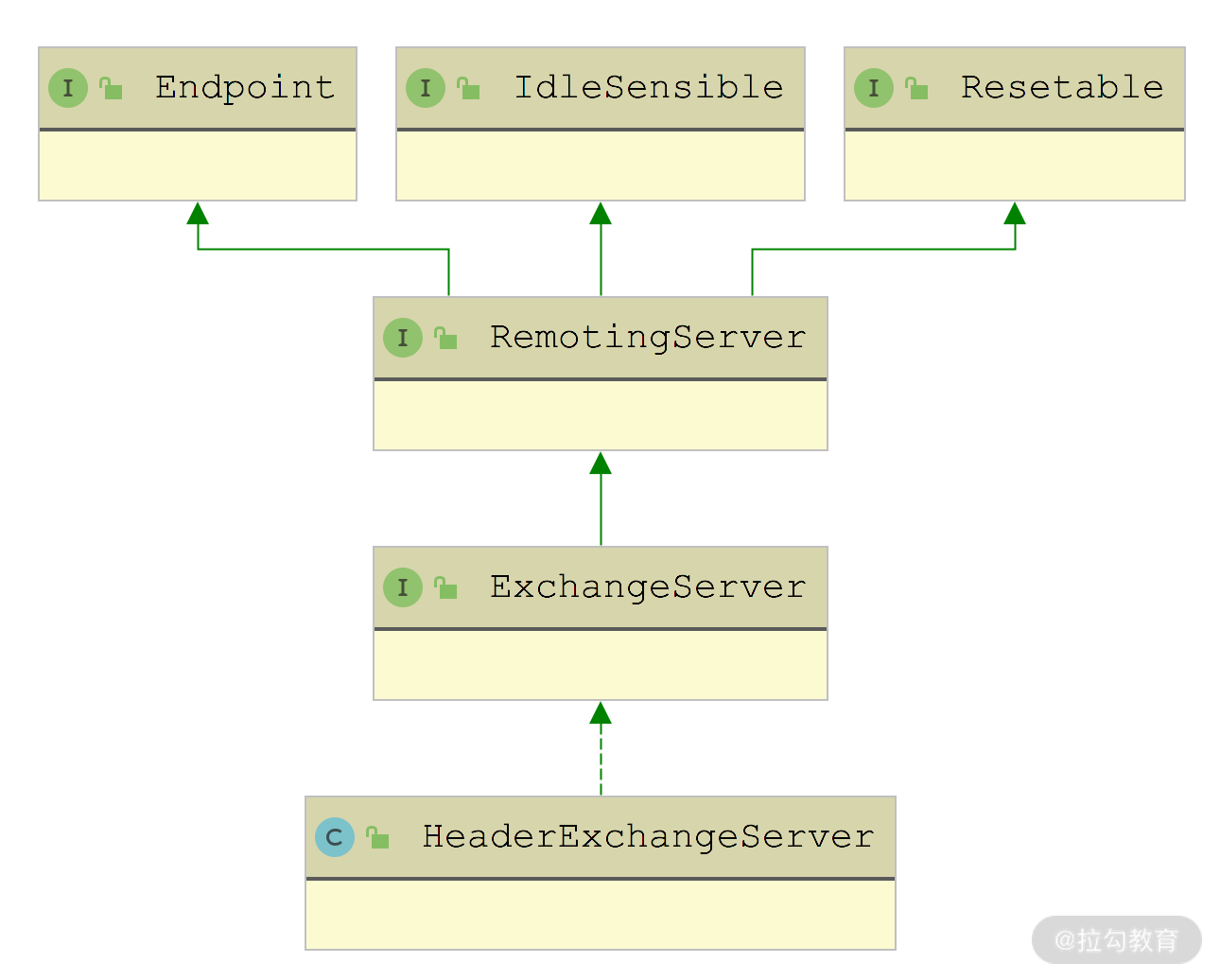
HeaderExchangeServer 的继承关系图
与前面介绍的 HeaderExchangeClient 一样,HeaderExchangeServer 是 RemotingServer 的装饰器,实现自 RemotingServer 接口的大部分方法都委托给了所修饰的 RemotingServer 对象。
在 HeaderExchangeServer 的构造方法中,会启动一个 CloseTimerTask 定时任务,定期关闭长时间空闲的连接,具体的实现方式与 HeaderExchangeClient 中的两个定时任务类似,这里不再展开分析。
需要注意的是,前面课时介绍的 NettyServer 并没有启动该定时任务,而是靠 NettyServerHandler 和 IdleStateHandler 实现的,原理与 NettyClient 类似,这里不再展开,你若感兴趣的话,可以回顾第 20课时或是查看 CloseTimerTask 的具体实现。
在 19 课时介绍 Transport Server 的时候,我们并没有过多介绍其关闭流程,这里我们就通过 HeaderExchangeServer 自顶向下梳理整个 Server 端关闭流程。先来看 HeaderExchangeServer.close() 方法的关闭流程:
- 将被修饰的 RemotingServer 的 closing 字段设置为 true,表示这个 Server 端正在关闭,不再接受新 Client 的连接。你可以回顾第 19 课时中介绍的 AbstractServer.connected() 方法,会发现 Server 正在关闭或是已经关闭时,则直接关闭新建的 Client 连接。
- 向 Client 发送一个携带 ReadOnly 事件的请求(根据 URL 中的配置决定是否发送,默认为发送)。在接收到该请求之后,Client 端的 HeaderExchangeHandler 会在 Channel 上添加 Key 为 "channel.readonly" 的附加信息,上层调用方会根据该附加信息,判断该连接是否可写。
- 循环去检测是否还存在 Client 与当前 Server 维持着长连接,直至全部 Client 断开连接或超时。
- 更新 closed 字段为 true,之后 Client 不会再发送任何请求或是回复响应了。
- 取消 CloseTimerTask 定时任务。
- 调用底层 RemotingServer 对象的 close() 方法。以 NettyServer 为例,其 close() 方法会先调用 AbstractPeer 的 close() 方法将自身的 closed 字段设置为 true;然后调用 doClose() 方法关闭 boss Channel(即用来接收客户端连接的 Channel),关闭 channels 集合中记录的 Channel(这些 Channel 是与 Client 之间的连接),清理 channels 集合;最后,关闭 bossGroup 和 workerGroup 两个线程池。
HeaderExchangeServer.close() 方法的核心逻辑如下:
java
public void close(final int timeout) {
startClose(); // 将底层RemotingServer的closing字段设置为true,表示当前Server正在关闭,不再接收连接
if (timeout > 0) {
final long max = (long) timeout;
final long start = System.currentTimeMillis();
if (getUrl().getParameter(Constants.CHANNEL_SEND_READONLYEVENT_KEY, true)) {
// 发送ReadOnly事件请求通知客户端
sendChannelReadOnlyEvent();
}
while (HeaderExchangeServer.this.isRunning() && System.currentTimeMillis() - start < max) {
Thread.sleep(10); // 循环等待客户端断开连接
}
}
doClose(); // 将自身closed字段设置为true,取消CloseTimerTask定时任务
server.close(timeout); // 关闭Transport层的Server
}通过对上述关闭流程的分析,你就可以清晰地知道 HeaderExchangeServer 优雅关闭的原理。
HeaderExchanger
对于上层来说,Exchange 层的入口是 Exchangers 这个门面类,其中提供了多个 bind() 以及 connect() 方法的重载,这些重载方法最终会通过 SPI 机制,获取 Exchanger 接口的扩展实现,这个流程与第 17 课时介绍的 Transport 层的入口------ Transporters 门面类相同。
我们可以看到 Exchanger 接口的定义与前面介绍的 Transporter 接口非常类似,同样是被 @SPI 接口修饰(默认扩展名为"header",对应的是 HeaderExchanger 这个实现),bind() 方法和 connect() 方法也同样是被 @Adaptive 注解修饰,可以通过 URL 参数中的 exchanger 参数值指定扩展名称来覆盖默认值。
java
@SPI(HeaderExchanger.NAME)
public interface Exchanger {
@Adaptive({Constants.EXCHANGER_KEY})
ExchangeServer bind(URL url, ExchangeHandler handler) throws RemotingException;
@Adaptive({Constants.EXCHANGER_KEY})
ExchangeClient connect(URL url, ExchangeHandler handler) throws RemotingException;
}Dubbo 只为 Exchanger 接口提供了 HeaderExchanger 这一个实现,其中 connect() 方法创建的是 HeaderExchangeClient 对象,bind() 方法创建的是 HeaderExchangeServer 对象,如下图所示:
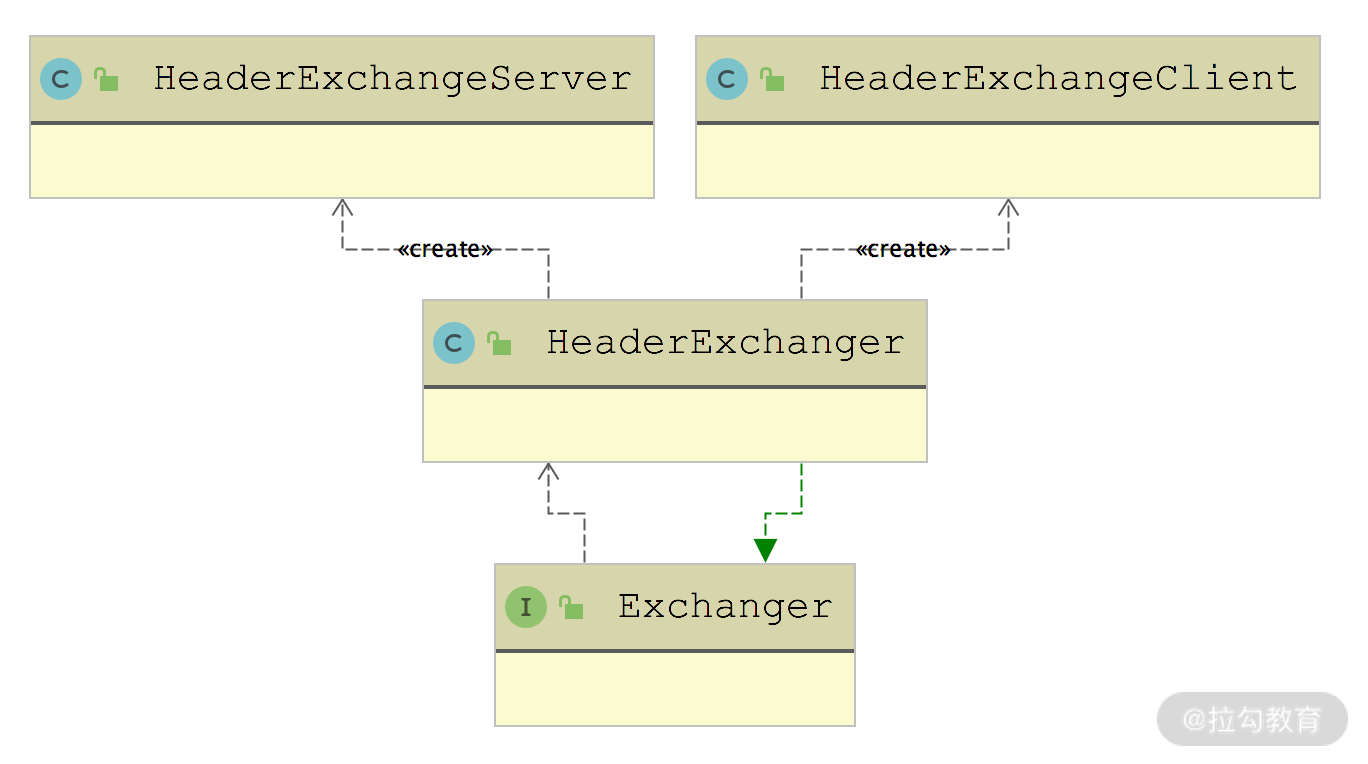
HeaderExchanger 门面类
从 HeaderExchanger 的实现可以看到,它会在 Transport 层的 Client 和 Server 实现基础之上,添加前文介绍的 HeaderExchangeClient 和 HeaderExchangeServer 装饰器。同时,为上层实现的 ExchangeHandler 实例添加了 HeaderExchangeHandler 以及 DecodeHandler 两个修饰器:
java
public class HeaderExchanger implements Exchanger {
public static final String NAME = "header";
@Override
public ExchangeClient connect(URL url, ExchangeHandler handler) throws RemotingException {
return new HeaderExchangeClient(Transporters.connect(url, new DecodeHandler(new HeaderExchangeHandler(handler))), true);
}
@Override
public ExchangeServer bind(URL url, ExchangeHandler handler) throws RemotingException {
return new HeaderExchangeServer(Transporters.bind(url, new DecodeHandler(new HeaderExchangeHandler(handler))));
}
}再谈 Codec2
在前面第 17 课时介绍 Dubbo Remoting 核心接口的时候提到,Codec2 接口提供了 encode() 和 decode() 两个方法来实现消息与字节流之间的相互转换。需要注意与 DecodeHandler 区分开来,DecodeHandler 是对请求体和响应结果的解码,Codec2 是对整个请求和响应的编解码。
这里重点介绍 Transport 层和 Exchange 层对 Codec2 接口的实现,涉及的类如下图所示:
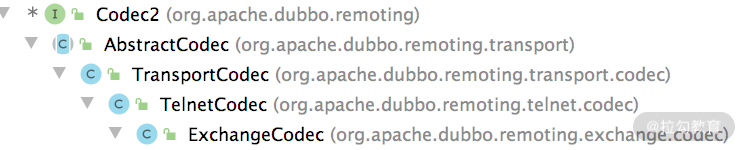
AbstractCodec抽象类并没有实现 Codec2 中定义的接口方法,而是提供了几个给子类用的基础方法,下面简单说明这些方法的功能。
- getSerialization() 方法:通过 SPI 获取当前使用的序列化方式。
- checkPayload() 方法:检查编解码数据的长度,如果数据超长,会抛出异常。
- isClientSide()、isServerSide() 方法:判断当前是 Client 端还是 Server 端。
接下来看TransportCodec,我们可以看到这类上被标记了 @Deprecated 注解,表示已经废弃。TransportCodec 的实现非常简单,其中根据 getSerialization() 方法选择的序列化方法对传入消息或 ChannelBuffer 进行序列化或反序列化,这里就不再介绍 TransportCodec 实现了。
TelnetCodec继承了 TransportCodec 序列化和反序列化的基本能力,同时还提供了对 Telnet 命令处理的能力。
最后来看ExchangeCodec,它在 TelnetCodec 的基础之上,添加了处理协议头的能力。下面是 Dubbo 协议的格式,能够清晰地看出协议中各个数据所占的位数:

Dubbo 协议格式
结合上图,我们来深入了解一下 Dubbo 协议中各个部分的含义:
- 0~7 位和 8~15 位分别是 Magic High 和 Magic Low,是固定魔数值(0xdabb),我们可以通过这两个 Byte,快速判断一个数据包是否为 Dubbo 协议,这也类似 Java 字节码文件里的魔数。
- 16 位是 Req/Res 标识,用于标识当前消息是请求还是响应。
- 17 位是 2Way 标识,用于标识当前消息是单向还是双向。
- 18 位是 Event 标识,用于标识当前消息是否为事件消息。
- 19~23 位是序列化类型的标志,用于标识当前消息使用哪一种序列化算法。
- 24~31 位是 Status 状态,用于记录响应的状态,仅在 Req/Res 为 0(响应)时有用。
- 32~95 位是 Request ID,用于记录请求的唯一标识,类型为 long。
- 96~127 位是序列化后的内容长度,该值是按字节计数,int 类型。
- 128 位之后是可变的数据,被特定的序列化算法(由序列化类型标志确定)序列化后,每个部分都是一个 byte \[\] 或者 byte。如果是请求包(Req/Res = 1),则每个部分依次为:Dubbo version、Service name、Service version、Method name、Method parameter types、Method arguments 和 Attachments。如果是响应包(Req/Res = 0),则每个部分依次为:①返回值类型(byte),标识从服务器端返回的值类型,包括返回空值(RESPONSE_NULL_VALUE 2)、正常响应值(RESPONSE_VALUE 1)和异常(RESPONSE_WITH_EXCEPTION 0)三种;②返回值,从服务端返回的响应 bytes。
可以看到 Dubbo 协议中前 128 位是协议头,之后的内容是具体的负载数据。协议头就是通过 ExchangeCodec 实现编解码的。
ExchangeCodec 的核心字段有如下几个。
- HEADER_LENGTH(int 类型,值为 16):协议头的字节数,16 字节,即 128 位。
- MAGIC(short 类型,值为 0xdabb):协议头的前 16 位,分为 MAGIC_HIGH 和 MAGIC_LOW 两个字节。
- FLAG_REQUEST(byte 类型,值为 0x80):用于设置 Req/Res 标志位。
- FLAG_TWOWAY(byte 类型,值为 0x40):用于设置 2Way 标志位。
- FLAG_EVENT(byte 类型,值为 0x20):用于设置 Event 标志位。
- SERIALIZATION_MASK(int 类型,值为 0x1f):用于获取序列化类型的标志位的掩码。
在 ExchangeCodec 的 encode() 方法中会根据需要编码的消息类型进行分类,其中 encodeRequest() 方法专门对 Request 对象进行编码,具体实现如下:
java
protected void encodeRequest(Channel channel, ChannelBuffer buffer, Request req) throws IOException {
Serialization serialization = getSerialization(channel);
byte[] header = new byte[HEADER_LENGTH]; // 该数组用来暂存协议头
// 在header数组的前两个字节中写入魔数
Bytes.short2bytes(MAGIC, header);
// 根据当前使用的序列化设置协议头中的序列化标志位
header[2] = (byte) (FLAG_REQUEST | serialization.getContentTypeId());
if (req.isTwoWay()) { // 设置协议头中的2Way标志位
header[2] |= FLAG_TWOWAY;
}
if (req.isEvent()) { // 设置协议头中的Event标志位
header[2] |= FLAG_EVENT;
}
// 将请求ID记录到请求头中
Bytes.long2bytes(req.getId(), header, 4);
// 下面开始序列化请求,并统计序列化后的字节数
// 首先使用savedWriteIndex记录ChannelBuffer当前的写入位置
int savedWriteIndex = buffer.writerIndex();
// 将写入位置后移16字节
buffer.writerIndex(savedWriteIndex + HEADER_LENGTH);
// 根据选定的序列化方式对请求进行序列化
ChannelBufferOutputStream bos = new ChannelBufferOutputStream(buffer);
ObjectOutput out = serialization.serialize(channel.getUrl(), bos);
if (req.isEvent()) { // 对事件进行序列化
encodeEventData(channel, out, req.getData());
} else { // 对Dubbo请求进行序列化,具体在DubboCodec中实现
encodeRequestData(channel, out, req.getData(), req.getVersion());
}
out.flushBuffer();
if (out instanceof Cleanable) {
((Cleanable) out).cleanup();
}
bos.flush();
bos.close(); // 完成序列化
int len = bos.writtenBytes(); // 统计请求序列化之后,得到的字节数
checkPayload(channel, len); // 限制一下请求的字节长度
Bytes.int2bytes(len, header, 12); // 将字节数写入header数组中
// 下面调整ChannelBuffer当前的写入位置,并将协议头写入Buffer中
buffer.writerIndex(savedWriteIndex);
buffer.writeBytes(header);
// 最后,将ChannelBuffer的写入位置移动到正确的位置
buffer.writerIndex(savedWriteIndex + HEADER_LENGTH + len);
}encodeResponse() 方法编码响应的方式与 encodeRequest() 方法编码请求的方式类似,这里就不再展开介绍了,感兴趣的同学可以参考源码进行学习。对于既不是 Request,也不是 Response 的消息,ExchangeCodec 会使用从父类继承下来的能力来编码,例如对 telnet 命令的编码。
ExchangeCodec 的 decode() 方法是 encode() 方法的逆过程,会先检查魔数,然后读取协议头和后续消息的长度,最后根据协议头中的各个标志位构造相应的对象,以及反序列化数据。在了解协议头结构的前提下,再去阅读这段逻辑就十分轻松了,这就留给你自己尝试分析一下。
总结
本课时我们重点介绍了 Dubbo Exchange 层中对 Client 和 Server 接口的实现。
我们首先介绍了 HeaderExchangeClient 对 ExchangeClient 接口的实现,以及 HeaderExchangeServer 对 ExchangeServer 接口的实现,这两者是在 Transport 层 Client 和 Server 的基础上,添加了新的功能。接下来,又讲解了 HeaderExchanger 这个用来创建 HeaderExchangeClient 和 HeaderExchangeServer 的门面类。最后,分析了 Dubbo 协议的格式,以及处理 Dubbo 协议的 ExchangeCodec 实现。