目录
项目介绍
日志是在程序运行过程中记录程序运行的状态信息,以便于程序员能够随时根据状态信息,对系统的运行状态进行分析。
本项目主要实现一个日志系统,其主要支持以下功能:
- 支持多级别日志消息。
- 支持同步日志和异步日志。同步日志:将日志写入到文件或数据库的操作由业务线程自己完成;异步日志:将日志写入到内存中,但是日志写入文件或数据库的操作不由业务线程来完成,这样就可以避免磁盘满了、数据库连接有问题等引发的问题,因为出现这些问题时会导致程序卡在这里,这样就没办法继续进行业务处理了。
- 支持可靠写入日志到控制台、文件以及滚动文件中。若日志一直往一个文件当作写入,这样会导致这个文件非常大,这样是不好的。所以,我们要提供文件的切换功能,当一个文件的大小达到某一个预设的值,就进行切换,将日志保存到切换后的文件当中。另外,不仅仅可以根据文件大小切换,还可以根据日期进行切换,如每天切换一个文件。这样做还有一个好处,删除一个文件时,可以根据不同的文件进行删除。比如我们可以设置一个定时任务,让这个任务每天删除3天以前的日志文件。
- 支持多线程程序并发写日志。我们的日志系统是一个线程安全的日志系统,也就是说,是支持多个线程同时向一个文件当中写入日志的。
- 支持拓展不同的日志落地目标地。这个项目支持扩展不同的落地目标地。如果不想保存到文件中,也可以将日志保存到数据库中,或者将日志发送给日志分析服务器等,支持由用户进行扩展。
日志系统存在的必要性
- 生产环境的产品为了保证其稳定性及安全性是不允许开发人员附加调试器去排查问题,可以借助日志系统来打印一些日志帮助开发人员解决问题。
- 上线客户端的产品出现bug无法复现并解决,可以借助日志系统打印日志并上传到服务端帮助开发人员进行分析。
- 对于一些高频操作(如定时器、心跳包)在少量调试次数下可能无法触发我们想要的行为,通过断点的暂停方式,我们不得不重复操作几十次、上百次甚至更多,导致排查问题效率是非常低下,可以借助打印日志的方式查问题。
- 在分布式、多线程/多进程代码中,出现bug比较难以定位,可以借助日志系统打印log帮助定位bug。
- 帮助首次接触项目代码的新开发人员理解代码的运行流程。
日志系统实现思想
日志系统的技术实现主要包括三种类型:
- 利用printf、std::cout等输出函数将日志信息打印到控制台
- 对于大型商业化项目,为了方便排查问题,我们一般会将日志输出到文件或者是数据库系统方便查询和分析日志,主要分为同步日志和异步日志。
同步写日志
同步日志是指当输出日志时,必须等待日志输出语句执行完毕后,才能执行后面的业务逻辑语句,日志输出语句与程序的业务逻辑语句将在同一个线程运行。每次调用一次打印日志API就对应一次系统调用write写日志文件。

在高并发场景下,随着日志数量不断增加,同步日志系统容易产生系统瓶颈:
- 一方面,大量的日志打印陷入等量的write系统调用,有一定系统开销
- 另一方面,使得打印日志的进程附带了大量同步的磁盘IO,影响程序性能
异步写日志
异步日志是指在进行日志输出时,日志输出语句与业务逻辑语句并不是在同一个线程中运行,而是有专门的线程用于进行日志输出操作。业务线程只需要将日志放到一个内存缓冲区中不用等待即可继续执行后续业务逻辑(作为日志的生产者),而日志的落地操作交给单独的日志线程去完成(作为日志的消费者),这是一个典型的生产 - 消费模型。
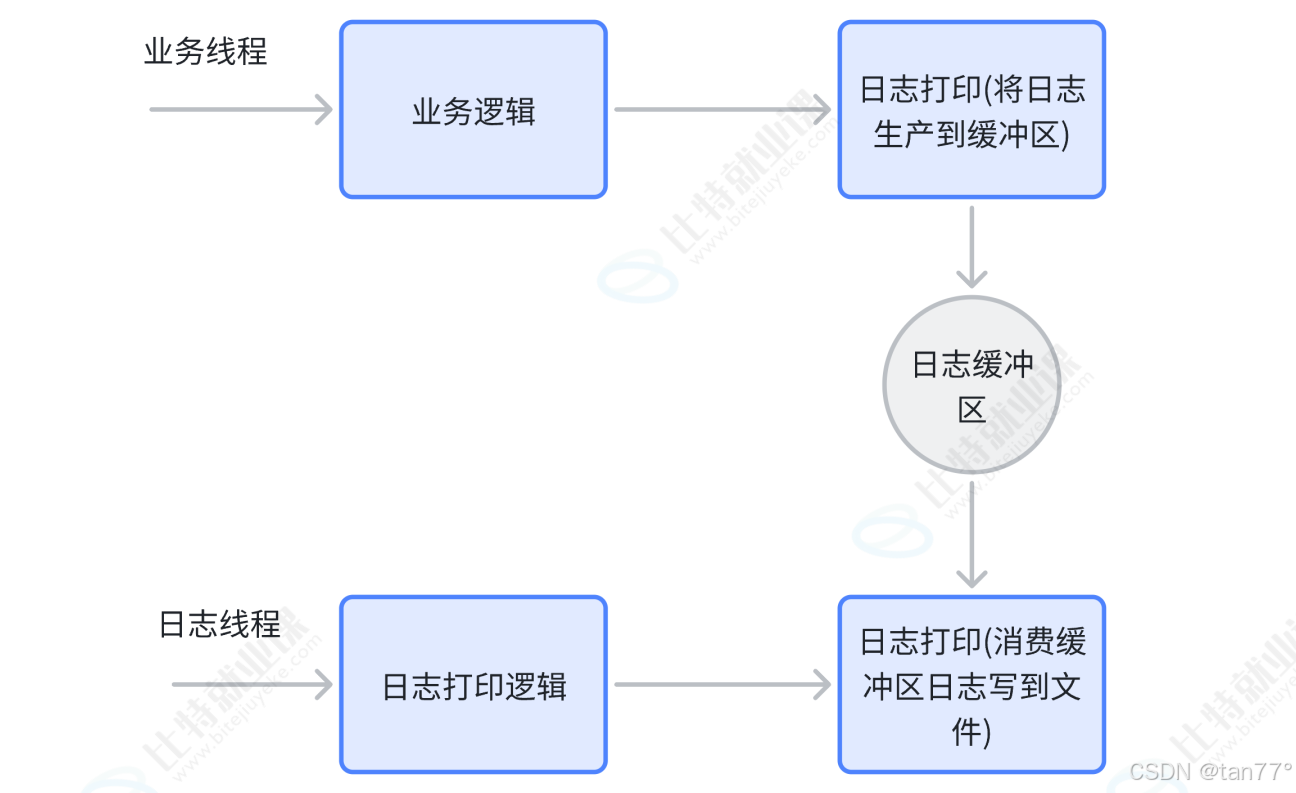
这样做的好处是即使日志没有真的地完成输出也不会影响程序的主业务,可以提高程序的性能:
- 主线程调用日志打印接口成为非阻塞操作
- 同步的磁盘1O从主线程中剥离出来交给单独的线程完成
不定参函数
不定参宏函数实现
在初学C语言的时候,我们都用过printf函数进行打印。其中printf函数就是一个不定参函数,在函数内部可以根据格式化字符串中格式化字符分别获取不同的参数进行数据的格式化。
而这种不定参函数在实际的使用中也非常多见,在这里简单做一介绍:
cpp
#define LOG(fmt, ...) printf("[%s: %d]" fmt "\n", __FILE__, __LINE__, ##__VA_ARGS__);
int main()
{
int age = 19;
std::string name = "张三";
LOG("用户姓名: %s, 用户年龄: %d", name.c_str(), age);
return 0;
}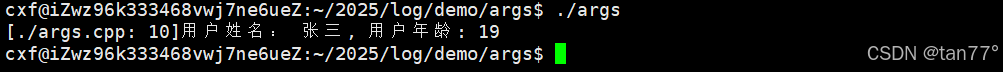
在宏中,使用格式字符串,也就是这里的fmt进行不定参输出,C语言中,使用 ... 表示不定参。使用LOG时,第一个逗号前面的内容就会匹配到fmt,剩下的参数会匹配到...。在宏内部,可以使用__VA__ARGS__使用...内部的对象。加上##是为了防止...内部一个对象都没有的情况,没加上是会报错的。
C语言不定参函数使用
C语言中,要定义出不定参函数需要使用到下面几个宏:
cpp
#include <stdarg.h>
void va_start(va_list ap, last);
type va_arg(va_list ap, type);
void va_end(va_list ap);
void va_copy(va_list dest, va_list src);这4个都是宏:
- va_start可以获取第一个参数的地址。第一个参数是va_list类型的,第二个参数传入要获取哪一个参数之后第一个不定参的地址。不定参的其实地址会放在ap中。
- va_arg是根据地址,将地址的内容当成一个type类型的数据,并返回。
- va_end是将va_list类型变量置空。获取完所有不定参后,就需要将valist类型变量置空。
cpp
// count表示不定参的数量,打印出所有的不定参
void printNum(int count, ...)
{
va_list ap;
va_start(ap, count);
for(int i = 0;i < count;i ++)
{
int num = va_arg(ap, int);
printf("param[%d]: %d ", i, num);
}
printf("\n");
va_end(ap);
}
int main()
{
printNum(5, 7, 77, 777, 7777, 77777);
return 0;
}
可是,传入的参数不一定都是相同类型的。我们此时可以模仿printf,通过格式说明符来完成操作。同样使用va_start获取不定参的起始地址,此时可以根据fmt内的格式说明符对va_start后面的内容进行处理,此时就变成了字符串处理,我们不这样做。
cpp
int vasprintf(char **strp, const char *fmt, va_list ap);传入一个一级指针的地址,再传入fmt,最后传入不定参的起始地址。返回值:调用成功,返回格式化数据的长度,调用失败,返回-1。注意:一级指针指向的空间需要手动释放。
cpp
void myprintf(const char *fmt, ...)
{
va_list ap;
va_start(ap, fmt);
char *res;
int ret = vasprintf(&res, fmt, ap);
if(ret != -1)
{
fputs(res, stdout);
free(res);
}
va_end(ap);
}
int main()
{
int age = 18;
std::string name = "张三";
myprintf("姓名: %s, 年龄: %d\n", name.c_str(), age);
return 0;
}
fputs(res, stdout)可以替换成printf(res),但是替换后会有警告。
C++不定参函数使用
同样模拟实现一个printf。
cpp
template<typename T, typename ...Args>
void xprintf(T &v, Args &&...args)
{
std::cout << v;
if(sizeof ...(args) > 0)
{
xprintf(std::forward<Args>(args)...);
}
else
{
std::cout << std::endl;
}
}使用递归的思想,假设有4个参数,先输出一个,再递归处理剩下的。此时是会报错的,因为最终args中只有一个参数时,再调用这一个参数会匹配到v,就不会匹配到Args了,导致Args为空。所以,需要对这个函数进行特化。
cpp
void xprintf()
{
std::cout << std::endl;
}
template<typename T, typename ...Args>
void xprintf(T &v, Args &&...args)
{
std::cout << v;
if(sizeof ...(args) > 0)
{
xprintf(std::forward<Args>(args)...);
}
else
{
xprintf();
}
}
int main()
{
int age = 18;
std::string name = "张三";
xprintf("姓名: ", name, ", 年龄: ", age);
return 0;
}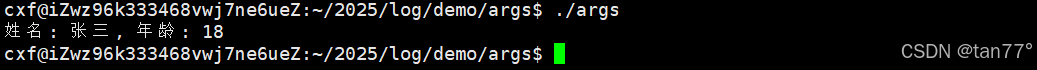
设计模式
设计模式是前辈们对代码开发经验的总结,是解决特定问题的一系列套路。设计模式一种规定,而是一种设计思想、设计经验,提高了代码的可复用性、可维护性、可读性、稳健性,以及安全性的解决方案。
六大原则
- 单一职责原则
- 类的职责应该单一,一个方法只做一件事。职责划分清晰了,每次改动到最小单位的方法或类。
- 使用建议:两个完全不一样的功能不应该放一个类中,一个类中应该是一组相关性很高的函数、数据的封装。
- 用例:网络聊天:网络通信&聊天,应该分割成为网络通信类&聊天类。
- 开闭原则
- 对扩展开放,对修改封闭
- 使用建议:对软件实体的改动,最好用扩展而非修改的方式。
- 用例:超时卖货:商品价格---不是修改商品的原来价格,而是新增促销价格。
- 里氏替换原则
- 通俗点讲,就是只要父类能出现的地方,子类就可以出现,而且替换为子类也不会产生任何错误或异常。
- 在继承类时,务必重写父类中所有的方法,尤其需要注意父类的protected方法,子类尽量不要暴露自己的public方法供外界调用。
- 使用建议:子类必须完全实现父类的方法,孩子类可以有自己的个性。覆盖或实现父类的方法时,输入参数可以被放大,输出可以缩小
- 用例:跑步运动员类-会跑步,子类长跑运动员-会跑步且擅长长跑,子类短跑运动员-会跑步且擅长短跑
- 依赖倒置原则
- 高层模块不应该依赖低层模块,两者都应该依赖其抽象.不可分割的原子逻辑就是低层模式,原子逻辑组装成的就是高层模块。
- 模块间依赖通过抽象(接口)发生,具体类之间不直接依赖
- 使用建议:每个类都尽量有抽象类,任何类都不应该从具体类派生。尽量不要重写基类的方法。结合里氏替换原则使用。
- 用例:奔驰车司机类--只能开奔驰;司机类--给什么车,就开什么车;开车的人:司机--依赖于抽象
- 迪米特法则,又叫"最少知道法则"
- 尽量减少对象之间的交互,从而减小类之间的耦合。一个对象应该对其他对象有最少的了解。对类的低耦合提出了明确的要求:只和直接的朋友交流,朋友之间也是有距离的。自己的就是自己的(如果一个方法放在本类中,既不增加类间关系,也对本类不产生负面影响,那就放置在本类中))。
- 用例:老师让班长点名--老师给班长一个名单,班长完成点名勾选,返回结果,而不是班长点名,老师勾选
- 接口隔离原则
- 客户端不应该依赖它不需要的接口,类间的依赖关系应该建立在最小的接口上
- 使用建议:接口设计尽量精简单一,但是不要对外暴露没有实际意义的接口。
- 用例:修改密码,不应该提供修改用户信息接口,而就是单一的最小修改密码接口,更不要暴露数据库操作
从整体上来理解六大设计原则,可以简要的概括为一句话,用抽象构建框架,用实现扩展细节,具体到每一条设计原则,则对应一条注意事项:
- 单一职责原则告诉我们实现类要职责单一;
- 里氏替换原则告诉我们不要破坏继承体系;
- 依赖倒置原则告诉我们要面向接口编程;
- 接口隔离原则告诉我们在设计接口的时候要精简单一;
- 迪米特法则告诉我们要降低耦合;
- 开闭原则是总纲,告诉我们要对扩展开放,对修改关闭。
单例模式的理解和实现
一个类只能创建一个对象,即单例模式,该设计模式可以保证系统中该类只有一个实例,并提供一个访问它的全局访问点,该实例被所有程序模块共享。比如在某个服务器程序中,该服务器的配置信息存放在一个文件中,这些配置数据由一个单例对象统一读取,然后服务进程中的其他对象再通过这个单例对象获取这些配置信息,这种方式简化了在复杂环境下的配置管理。单例模式有两种实现模式:饿汉模式和懒汉模式。
- 饿汉模式:程序启动时就会创建一个唯一的实例对象。因为单例对象已经确定,所以比较适用于多线程环境中,多线程获取单例对象不需要加锁,可以有效的避免资源竞争,提高性能。
- 懒汉模式:第一次使用要使用单例对象的时候创建实例对象。如果单例对象构造特别耗时或者耗费济源(加载插件、加载网络资源等),可以选择懒汉模式,在第一次使用的时候才创建对象。
饿汉模式
让一个类只能实例化出一个对象,核心思想就是只能在类内实例化对象,而不能在类外实例化对象,所以,要在类内声明一个对象,且将构造函数、拷贝构造定义为私有的。为了让所有人能够拿到同一个对象,需要将这个对象定义为static。一般还会将析构函数也定义为私有。
cpp
class Singleton
{
public:
// 程序在任意地方都可以通过getInstance获取单例对象
// 一般来说,单例对象的数据都会从配置文件中读取
static Singleton &getInstance()
{
return _eton;
}
int getData() { return _data; }
private:
// 静态对象的生命周期随进程
static Singleton _eton;
Singleton():_data(99) {}
Singleton(const Singleton&) = delete;
~Singleton(){}
int _data;
};
Singleton Singleton::_eton;
int main()
{
std::cout << Singleton::getInstance().getData() << std::endl;
return 0;
}懒汉模式
懒汉模式是一种懒加载、延迟加载的思想,一个对象在用的时候才会被实例化。一种实现思想是在类内定义一个静态指针,在调用的函数中判断以下这个指针是否为空,若为空,则进行实例化。但是,此时是线程不安全的,因为多线程并发初始化单例时可能导致多次创建,此时需要一把锁,保证初始化过程的的原子性,确保只有一个线程能完成实例的创建。这种方法会导致效率比较低,我们不使用这种方法。
cpp
// 懒汉模式
class Singleton
{
public:
static Singleton &getInstance()
{
static Singleton _eton;
return _eton;
}
int getData() { return _data; }
private:
Singleton():_data(99)
{
std::cout << "单例对象构造" << std::endl;
}
Singleton(const Singleton&) = delete;
~Singleton(){}
int _data;
};
int main()
{
std::cout << Singleton::getInstance().getData() << std::endl;
return 0;
}这种方法只能在C++11之后使用,因为C++11之后,静态变量才能在满足线程安全的前提下唯一地被构造和析构。也就是说,C++11之后,如果多个线程试图同时初始化一个局部静态变量,则初始化只会发生一次。
工厂模式的理解和实现
工厂模式是一种创建型设计模式,它提供了一种创建对象的最佳方式。在工厂模式中,我们创建对象时不会对上层暴露创建逻辑,而是通过使用一个共同结构来指向新创建的对象,以此实现创建-使用的分离。也就是将对象实例化的过程进行封装,这样未来当一个类实例化对象的参数等改变时,就不需要整个项目都修改,只需要修改实例化对象的函数即可。工厂模式可分为:
- 简单工厂模式
- 工厂方法模式
- 抽象工厂模式
简单工厂模式
简单工厂模式:简单工厂模式实现由一个工厂对象通过类型决定创建出来指定产品类的实例,就是告诉工厂类要生产的对象类型,工厂类再返回这个类型的对象。假设有个工厂能生产出水果,当客户需要产品的时候明确告知工厂生产哪类水果,工厂需要接收用户提供的类别信息,当新增产品的时候,工厂内部去添加新产品的生产方式。一个工厂可以生产多种产品。
cpp
class Fruit
{
public:
virtual void name() = 0;
};
class Apple : public Fruit
{
public:
void name() override
{
std::cout << "苹果" << std::endl;
}
};
class Banana : public Fruit
{
public:
void name() override
{
std::cout << "香蕉" << std::endl;
}
};
class FruitFactory
{
public:
// 程序类框架,不要与具体的类产生关联,应该与抽象类产生关联,所以返回的应该是水果类
static std::shared_ptr<Fruit> create(const std::string &name)
{
if(name == "苹果") return std::make_shared<Apple>();
else return std::make_shared<Banana>();
}
};
int main()
{
std::shared_ptr<Fruit> fruit = FruitFactory::create("苹果");
fruit->name();
fruit = FruitFactory::create("香蕉");
fruit->name();
return 0;
}
优点:简单粗暴,直观易懂,使用一个工厂生产同一等级结果下的任意产品。
缺点:
- 所有对象生产在一起,产品太多会导致代码量庞大
- 违背了开闭原则,要新增产品就必须修改工厂方法。假设现在这个水果工厂又可以创建橘子对象,此时是需要修改这个水果工厂类的代码。
这个模式的结构和管理产品对象的方式十分简单,但是它的扩展性非常差,当我们需要新增产品的时候,就需要去修改工厂类新增一个类型的产品创建逻辑,违背了开闭原则。
工厂方法模式
工厂方法模式:在简单工厂模式下新增多个工厂,多个产品,每个产品对应一个工厂。假设现在有A、B两种产品,则开两个工厂,工厂A负责生产产品A,工厂B负责生产产品B,用户只知道产品的工厂名,而不知道具体的产品信息,工厂不需要再接收客户的产品类别,而只负责生产产品。一个工厂只能生产一种产品。
cpp
class Fruit
{
public:
virtual void name() = 0;
};
class Apple : public Fruit
{
public:
void name() override
{
std::cout << "苹果" << std::endl;
}
};
class Banana : public Fruit
{
public:
void name() override
{
std::cout << "香蕉" << std::endl;
}
};
// 工厂方法模式
class FruitFactory
{
public:
virtual std::shared_ptr<Fruit> create() = 0;
};
class AppleFactory : public FruitFactory
{
public:
std::shared_ptr<Fruit> create() override
{
return std::make_shared<Apple>();
}
};
class BananaFactory : public FruitFactory
{
public:
std::shared_ptr<Fruit> create() override
{
return std::make_shared<Banana>();
}
};
int main()
{
std::shared_ptr<FruitFactory> ff(new AppleFactory());
std::shared_ptr<Fruit> fruit = ff->create();
fruit->name();
ff.reset(new BananaFactory());
fruit = ff->create();
fruit->name();
return 0;
}
优点:
- 减轻了工厂类的负担,将某类产品的生产交给指定的工厂类进行
- 开闭原则遵循的较好,添加新产品只需要新增产品的工厂即可,不需要修改原先的工厂类
缺点:对于某种可以形成一组产品族的情况处理较为复杂,需要创建大量的工厂类。
工厂方法模式每次增加一个产品时,都需要增加一个具体产品类和工厂类,这会使得系统中类的个数成倍增加,在一定程度上增加了系统的耦合度。
抽象工厂模式
抽象工厂模式:工厂方法模式通过引入工厂等级结构,解决了简单工厂模式中工厂类职责太重的问题,但由于工厂方法模式中的每个工厂只生产一类产品,可能会导致系统中存在大量的工厂类,势必会增加系统的开销。此时,我们可以考虑将一些相关的产品组成一个产品族(位于不同产品等级结构中功能相关联的产品组成的家族),由同一个工厂来统一生产,这就是抽象工厂模式的基本思想。
会有一个超级工厂,这个超级工厂生产普通工厂,普通工厂就是前面的简单工厂,一个普通工厂负责生产某一类型的产品。前面是水果类,现在增加一个动物类。
cpp
class Fruit
{
public:
virtual void name() = 0;
};
class Apple : public Fruit
{
public:
void name() override
{
std::cout << "苹果" << std::endl;
}
};
class Banana : public Fruit
{
public:
void name() override
{
std::cout << "香蕉" << std::endl;
}
};
class Animal
{
public:
virtual void name() = 0;
};
class cat : public Animal
{
public:
void name() override
{
std::cout << "猫" << std::endl;
}
};
class dog : public Animal
{
public:
void name() override
{
std::cout << "狗" << std::endl;
}
};
// 抽象工厂
class Factory
{
public:
virtual std::shared_ptr<Fruit> getFruit(const std::string &name) = 0;
virtual std::shared_ptr<Animal> getAnimal(const std::string &name) = 0;
};
// 具体工厂,生产水果
class FruitFactory : public Factory
{
public:
std::shared_ptr<Animal> getAnimal(const std::string &name) override
{
return std::shared_ptr<Animal>();
}
std::shared_ptr<Fruit> getFruit(const std::string &name) override
{
if(name == "苹果") return std::make_shared<Apple>();
else return std::make_shared<Banana>();
}
};
// 具体工厂,生产动物
class AnimalFactory : public Factory
{
public:
std::shared_ptr<Fruit> getFruit(const std::string &name) override
{
return std::shared_ptr<Fruit>();
}
std::shared_ptr<Animal> getAnimal(const std::string &name) override
{
if(name == "猫") return std::make_shared<cat>();
else return std::make_shared<dog>();
}
};
// 工厂生产者,生产工厂
class FactoryProducer
{
public:
static std::shared_ptr<Factory> create(const std::string &name)
{
if(name == "水果") return std::make_shared<FruitFactory>();
else return std::make_shared<AnimalFactory>();
}
};
int main()
{
// 先通过工厂生产者生产一个工厂,再通过这个工厂去生产产品
std::shared_ptr<Factory> ff = FactoryProducer::create("水果");
std::shared_ptr<Fruit> fruit = ff->getFruit("苹果");
fruit->name();
fruit = ff->getFruit("香蕉");
fruit->name();
std::shared_ptr<Factory> factory = FactoryProducer::create("动物");
std::shared_ptr<Animal> animal = factory->getAnimal("猫");
animal->name();
animal = factory->getAnimal("狗");
animal->name();
return 0;
}
抽象工厂模式适用于生产多个工厂系列产品衍生的设计模式,增加新的产品等级结构复杂,需要对原有系统进行较大的修改,甚至需要修改抽象层代码,违背了"开闭原则"。
建造者模式的理解和实现
建造者模式是一种创建型设计模式,使用多个简单的对象一步一步构建成一个复杂的对象,能够将个复杂的对象的构建与它的表示分离,提供一种创建对象的最佳方式。主要用于解决对象的构建过于复杂的问题。
建造者模式与工厂模式的目标是相同的,都是为了创建一个对象,将对象的创建与表示分离。对象构建较为简单时,使用工厂模式;对象构建较复杂时,使用建造者模式。
建造者模式主要基于五个核心类实现:
- 抽象产品类:对真正需要生产的产品的抽象
- 具体产品类:对抽象产品的具象
- 抽象Builder类:创建一个产品对象所需的各个部件的抽象接口,这个接口的作用就是生产产品的各个零部件
- 具体产品的Builder类:实现抽象接口,构建各个零部件。对抽象Builder类中的接口进行具体实现。
- 指挥者Director类:统一组建过程,提供给调用者使用,通过指挥者来构造产品。
假设我们现在要生产一台笔记本电脑,这个电脑由主板、显示器、操作系统组成。此时可以选择先将组件生产出来,然后再组装产品。
cpp
// 抽象产品类
class Computer
{
public:
Computer() {}
void setBoard(const std::string &board)
{
_board = board;
}
void setDisplay(const std::string &display)
{
_display = display;
}
void showParamaters()
{
std::string param = "Computer Paramaters:\n";
param += "\tBoard: " + _board + "\n";
param += "\tDisplay: " + _display + "\n";
param += "\tOS: " + _os + "\n";
std::cout << param << std::endl;
}
virtual void setOS() = 0;
protected:
std::string _board;
std::string _display;
std::string _os;
};
// 具体产品类
class MacBook : public Computer
{
public:
void setOS() override
{
_os = "Mac OS x12";
}
};
// 抽象Builder类
class Builder
{
public:
virtual void buildBoard(const std::string &board) = 0;
virtual void buildDispaly(const std::string &display) = 0;
virtual void buildOS() = 0;
virtual std::shared_ptr<Computer> build() = 0;
};
// 具体产品的Builder类
class MacBookBuilder : public Builder
{
public:
MacBookBuilder():_computer(new MacBook) {}
void buildBoard(const std::string &board)
{
_computer->setBoard(board);
}
void buildDispaly(const std::string &display)
{
_computer->setDisplay(display);
}
void buildOS()
{
_computer->setOS();
}
std::shared_ptr<Computer> build()
{
return _computer;
}
private:
std::shared_ptr<Computer> _computer;
};
// 指挥者类
class Director
{
public:
Director(Builder* builder):_builder(builder) {}
void construct(const std::string &board, const std::string &display)
{
_builder->buildBoard(board);
_builder->buildDispaly(display);
_builder->buildOS();
}
private:
std::shared_ptr<Builder> _builder;
};
int main()
{
Builder* builder = new MacBookBuilder();
std::unique_ptr<Director> director(new Director(builder));
director->construct("华硕主板", "三星显示器");
std::shared_ptr<Computer> computer = builder->build();
computer->showParamaters();
return 0;
}
建造者进行具体的建造,指挥者负责进行组装。注意:组装的时候可能是有顺序的,像这里需要先组装主板、显示器,再组装操作系统。
代理模式的理解和实现
代理模式指代理控制对其他对象的访问,也就是代理对象控制对原对象的引用。在某些情况下,一个对象不适合或者不能直接被引用访问,而代理对象可以在客户端和目标对象之间起到中介的作用。例如现在有一个房东想将房子租出去,但是他没有时间,所以就将租房子这件事交给中介代理。中介不仅仅要将房子租出去,还需要做一些额外的事情,例如带人看房,对房子进行维修等,所以代理模式是会进行功能加强的。
代理模式的结构包括一个是真正的你要访问的对象(目标类)、一个是代理对象。目标对象与代理对象实现同一个接口,先访问代理类再通过代理类访问自标对象。对目标对象的访问都是通过代理对象,所以要代理类要实现目标对象对应的类的全部接口。代理模式分为静态代理、动态代理:
- 静态代理指的是,在编译时就已经确定好了代理类和被代理类的关系。也就是说,在编译时就已经确定了代理类要代理的是哪个被代理类。
- 动态代理指的是,在运行时才动态生成代理类,并将其与被代理类绑定。这意味着,在运行时才能确定代理类要代理的是哪个被代理类。
我们重点看静态代理。
cpp
class RentHouse
{
public:
virtual void rentHouse() = 0;
};
// 房东类
class Landlord : public RentHouse
{
public:
void rentHouse()
{
std::cout << "将房子租出去" << std::endl;
}
};
// 中介类
class Intermediary : public RentHouse
{
public:
void rentHouse()
{
std::cout << "发布招租启示" << std::endl;
std::cout << "带入看房" << std::endl;
// 只有将房子租出去是由房东负责,其余均由中介负责
_landlord.rentHouse();
std::cout << "负责租后维修" << std::endl;
}
private:
Landlord _landlord;
};
int main()
{
// 租房时是向中介租
Intermediary intermediary;
intermediary.rentHouse();
return 0;
}