目录
-
- 前言
- [1. Mixtrue of experts overview](#1. Mixtrue of experts overview)
-
- [1.1 What is a MoE?](#1.1 What is a MoE?)
- [1.2 Why are MoEs getting popular?](#1.2 Why are MoEs getting popular?)
- [1.3 Some MoE results](#1.3 Some MoE results)
- [1.4 Why haven't MoEs been more popular?](#1.4 Why haven’t MoEs been more popular?)
- [1.5 What MoEs generally look like](#1.5 What MoEs generally look like)
- [1.6 MoE -- what varies?](#1.6 MoE – what varies?)
- [2. Routing function](#2. Routing function)
-
- [2.1 Routing type](#2.1 Routing type)
- [2.2 Common routing variants](#2.2 Common routing variants)
- [2.3 Top-K routing in detail](#2.3 Top-K routing in detail)
- [2.4 Recent variations](#2.4 Recent variations)
- [3. Expert sizes](#3. Expert sizes)
- [4. Training objectives](#4. Training objectives)
-
- [4.1 RL for MoEs](#4.1 RL for MoEs)
- [4.2 Stochastic approximations](#4.2 Stochastic approximations)
- [4.3 Heuristic balancing losses](#4.3 Heuristic balancing losses)
- [4.4 Training MoEs -- the systems side](#4.4 Training MoEs – the systems side)
- [5. Issues with MoEs](#5. Issues with MoEs)
-
- [5.1 Z-loss stability for the router](#5.1 Z-loss stability for the router)
- [5.2 Upcycling for fine-tuning](#5.2 Upcycling for fine-tuning)
- [6. DeepSeek MoE v1-v2-v3](#6. DeepSeek MoE v1-v2-v3)
- [7. MoE summary](#7. MoE summary)
- 结语
- 参考
前言
学习斯坦福的 CS336 课程,本篇文章记录课程第四讲:混合专家模型,记录下个人学习笔记,仅供自己参考😄
website:https://stanford-cs336.github.io/spring2025
video:https://www.youtube.com/playlist?list=PLoROMvodv4rOY23Y0BoGoBGgQ1zmU_MT_
materials:https://github.com/stanford-cs336/spring2025-lectures
course material:https://github.com/stanford-cs336/spring2025-lectures/tree/main/nonexecutable/4-MoEs.pdf
1. Mixtrue of experts overview
这次讲座我们将讲解混合专家模型 MoE(Mixture of experts),最后我们将深入剖析 DeepSeek-V3 架构,并尝试理解构成这个顶尖开源系统的所有组件,至少从架构设计的角度看看它的完整样貌。

MoE 正是当下众多最先进、高性能系统的构建和部署方式,有趣的是,NVIDIA 泄露的信息暗示 GPT-4 可能实为 GPT-MoE-1 BT 架构,更广泛来看,包括 Grok、DeepSeek 和 LLaMA 4 在内的众多系统如今都已采用混合专家架构。
时至 2025 年,混合专家架构相对密集架构的优势已变得极为显著,只要方法得当,几乎所有计算规模的混合专家模型训练都能带来优于密集模型的性能提升。如今东西方科技界似乎都在采用这种架构,因此,若想在有限算力条件下打造最优模型,深入理解这一架构至关重要。
1.1 What is a MoE?
混合专家模型的原理其实非常简单,这个命名其实相当糟糕,听到 "混合专家" 这个词,人们往往会联想到:哦,这肯定是指不同领域的专家,各司其职、分工协作。比如有编程专家、英语专家和其他语言专家各司其职,实际情况与这种想象相差甚远
混合专家模型本质上是一种特殊架构,它包含多个被称为 "专家" 的子模块,这些子模块采用稀疏激活机制工作。具体来说,当我们讨论混合专家模型时,核心关注点其实在于其中的多层感知机(MLPs),这才是整个系统的精髓所在。
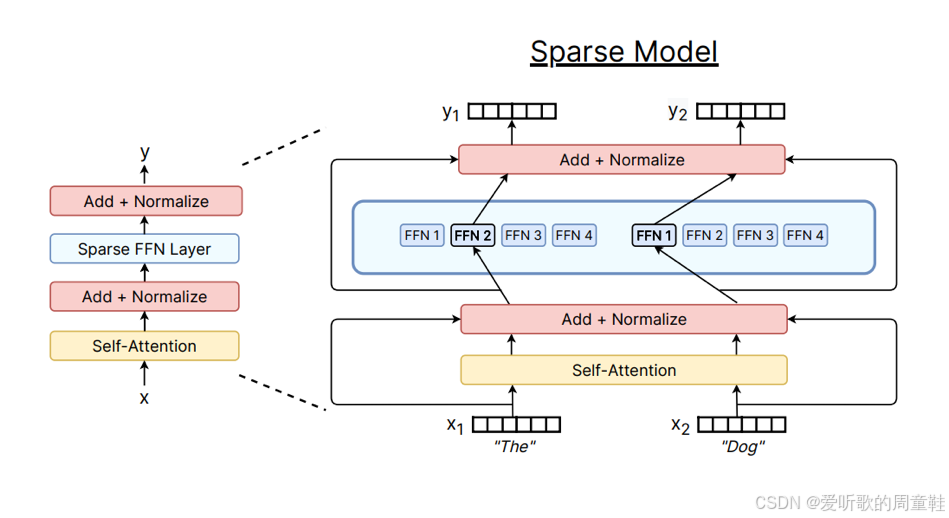
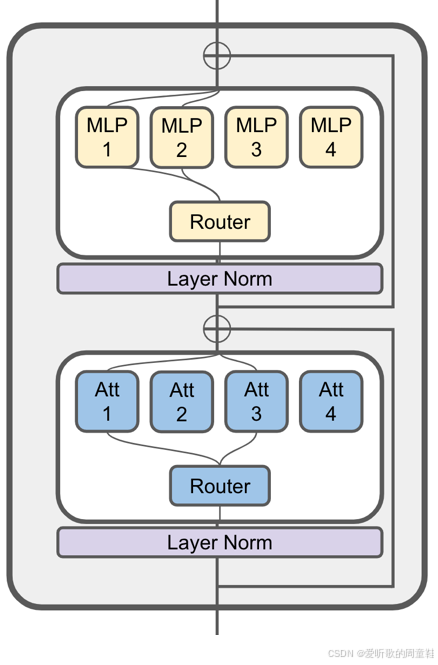
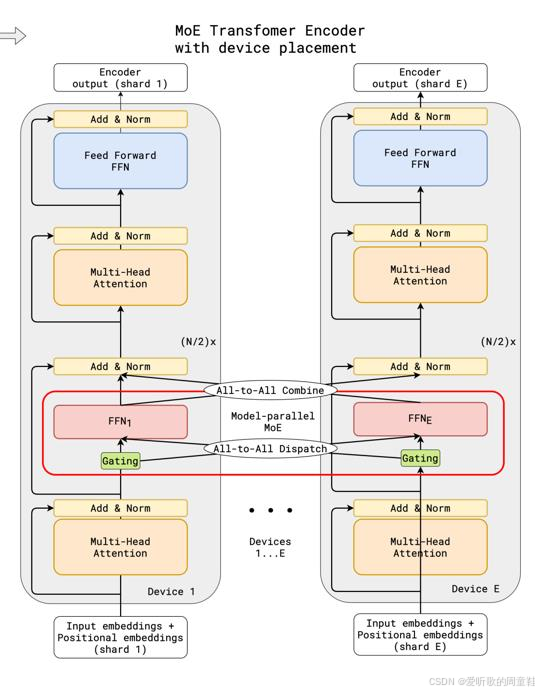
混合专家架构与非混合专家架构在绝大多数组件上都高度相似,唯一的区别在于下面示意图所示:
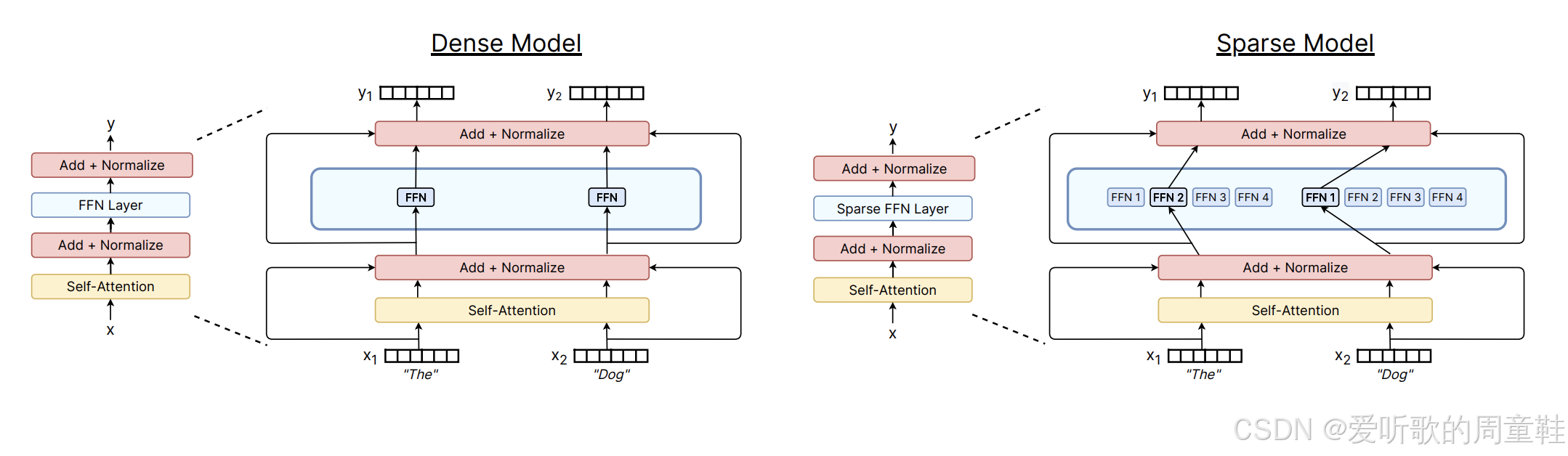
在上图左侧部分展示的是标准 Transformer 的各个组件,包含自注意力机制和前馈神经网络两大核心模块,在密集模型中,前馈网络模块就是简单直接地存在于此,它就是一个完整地整体模块。而稀疏模型则不同(图示右侧部分),我们会将这个前馈神经网络进行拆分或复制。
具体操作取决于混合专家模型的架构设计,模型会复制多份全连接网络(FFN),并通过路由机制在每次前向传播或推理时,从中筛选出少量网络进行激活,这就是混合专家模型的核心原理。
我们将用选择层和多个小型前馈网络来替代左侧这个庞大的单一前馈结构,这种架构的优势在哪里呢?关键在于稀疏激活机制。假设每次仅激活一个专家模块(每个专家模块的参数量与原密集前馈网络相当),那么左侧的密集模型与右侧的混合专家模型它们的浮点运算量(FLOPs)是完全相同的,二者的前向传播执行着完全相同的矩阵运算。因此,我们可以在不增加浮点运算量的前提下,显著提升模型参数量
如果你认同模型性能提升的关键在于扩展参数量(例如增强世界知识的记忆能力),那么这种架构无疑是理想之选,由此可见混合专家架构的设计精妙之处。
1.2 Why are MoEs getting popular?
相信这些原理已经阐述得非常清晰了,你可能会思考:增加单位浮点运算对应的参数量确实合理,但这真的能提升实际训练模型的性能吗?
目前已有大量研究论文证实:在相同浮点运算量(FLOPs)和相同训练成本下,混合专家模型的性能表现始终优于密集型模型。本次讲座我们将重点解读几篇奠定该领域基础的经典谷歌论文
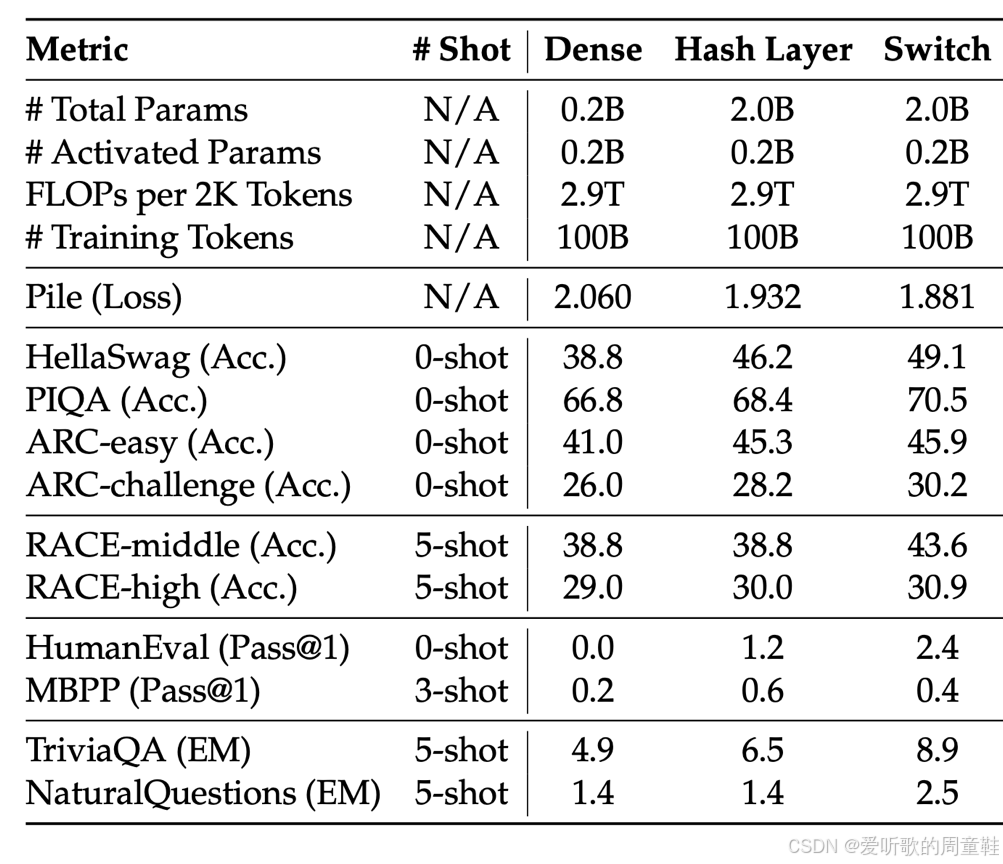
这篇由 Fedus 等人于 2022 年发表的论文 Fedus+ 2022 正是其中之一,他们通过实验证明:在浮点运算量(FLOPs)相同的情况下(训练浮点运算量相同,意味着投入的训练算力完全一致),随着专家数量的增加,语言模型的训练损失呈现持续下降趋势,专家越多,效果越好。
当然,专家模块并非零成本,这些专家模块需要占用额外的存储空间,在进行并行计算时,还需要考虑如何将数据路由到 256 个独立的专家模块中,因此系统复杂度会显著提升。
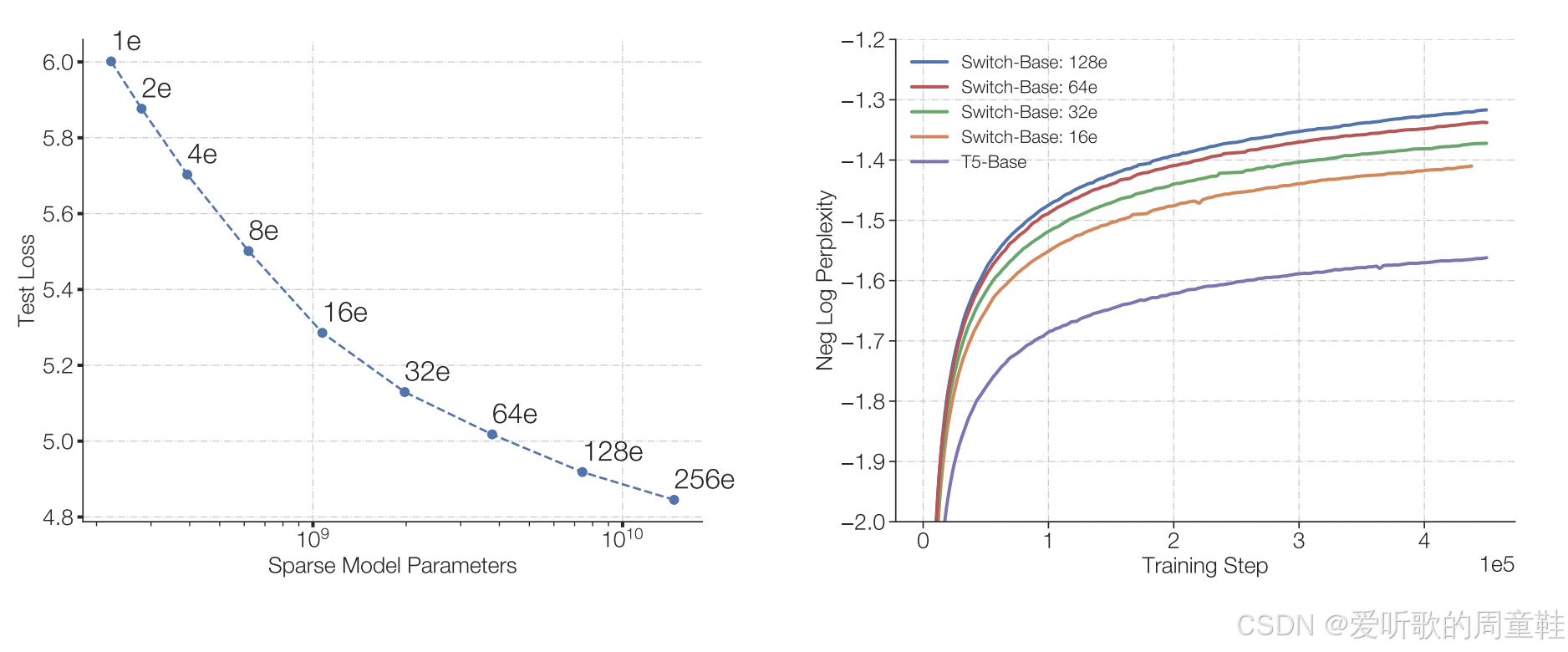
但如果仅考虑浮点运算量,上面左侧图表极具参考价值---在保持相同运算量的情况下,测试损失实现了显著降低。右侧图表也呈现相同的趋势,随着训练时长不断增加,采用 128 个专家模型的 Switch 基础架构展现出更优的性能,这种多专家模型能以更快速度降低困惑度。
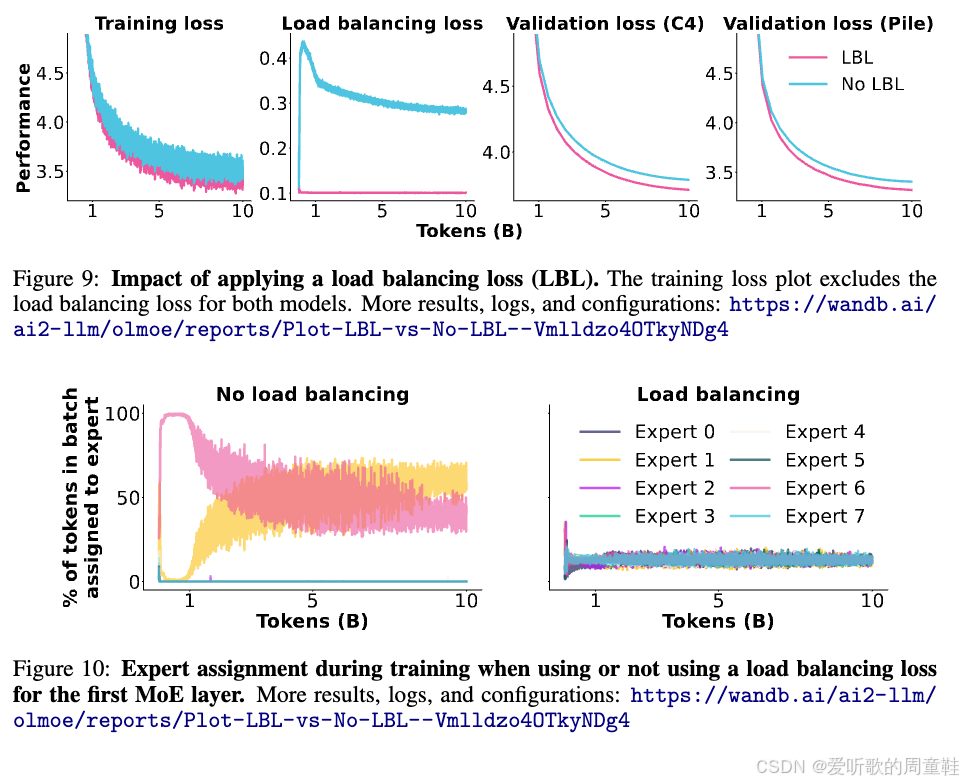
相信现在这个原理已经非常清晰了,或许有人会说:这不过是 2022 年的论文成果,这种优势在现代架构和大规模模型中是否依然成立呢?这一优势至今依旧显著存在,Al2 研究所在 OlMoE 项目中发表了一篇极具价值的论文 Muennighoff+ 2024,通过大量消融实验和严格控制变量对比了密集架构与 MoE 等不同架构的表现,最终得出了完全一致的结论
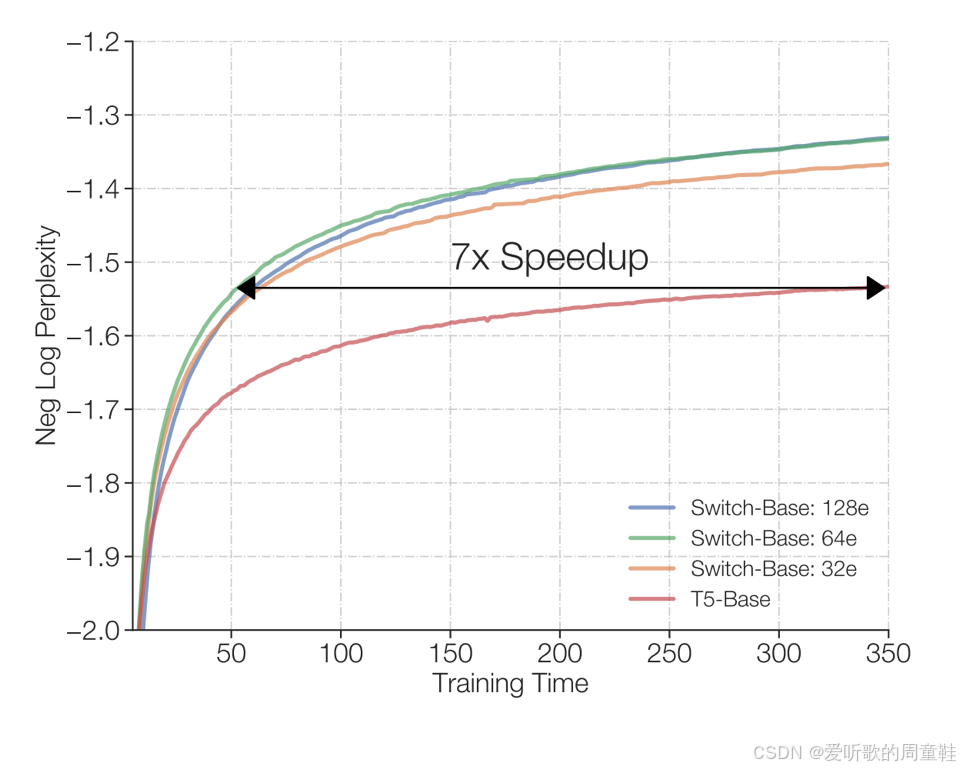
如上图所示(数据仍引自 Fedus 等人的研究)采用多专家架构可以实现 7 倍加速效果
下图则展示了 OlMoE 架构的对比数据:
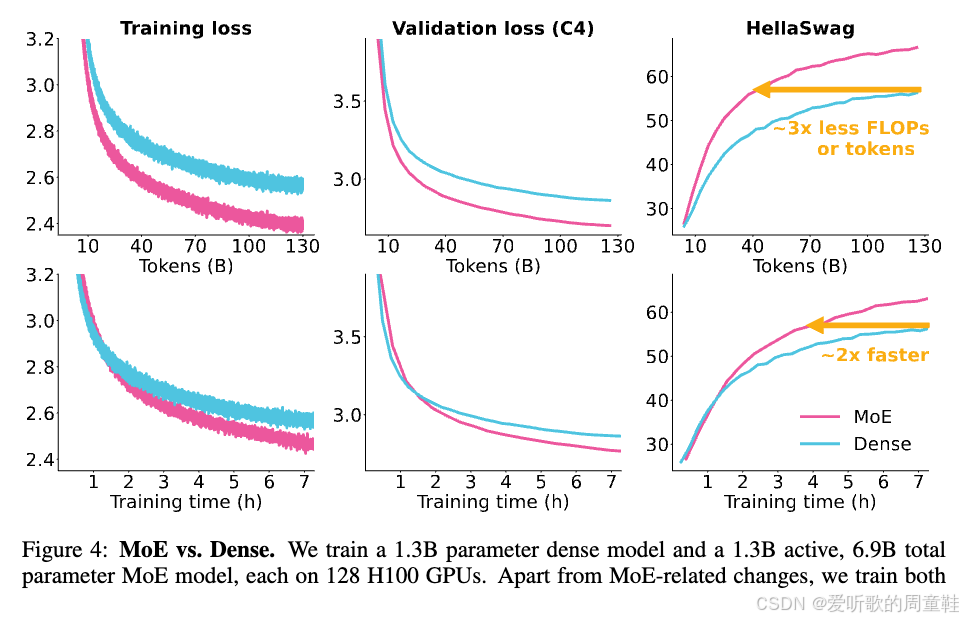
如图所示,粉色曲线代表混合专家架构,蓝绿色曲线对应密集架构,密集架构的训练损失下降速度明显滞后于混合专家架构。通过以上分析,相信大家已经认识到混合专家架构作为一种创新架构在机器学习领域的独特价值。不过,这种架构优势并非没有代价,但至少在浮点运算量层面,其性能表现确实令人瞩目。
最后想要展示的是,众多企业之所以青睐混合专家模型,是因为它能生成极具说服力的性能曲线图,例如下面这张:
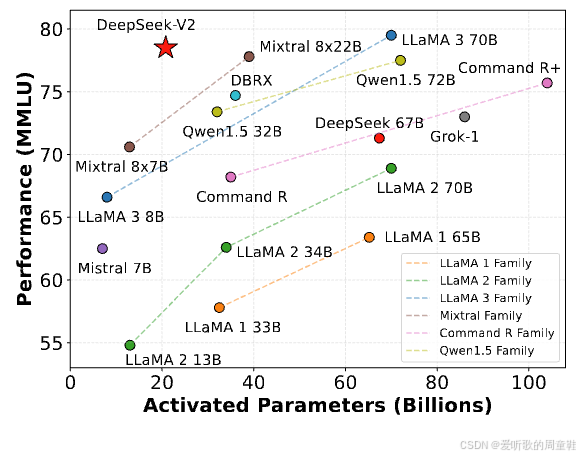
这张图表引自 DeepSeek-V2 的研究论文,在横轴上---这里其实玩了个小把戏,这里仅指被激活的参数,因此,这里仅涉及实际参与计算的参数,也就是说我们不考虑未被激活的专家参数,而纵轴表示 MMLU 性能表现
我们看到 DeepSeek-V2 的表现:实际激活的参数非常少,MMLU 性能表现确实非常出色。因此,如果你只关注训练和推理的浮点运算量,那么激活参数量才是关键指标,这个模型的性能表现确实非常出色
从系统架构的角度来看,混合专家模型还带来一项重要优势:它为我们提供了另一种并行化维度。关于并行化的详细探讨,我们会在系统专题讲座中深入展开讲解,我们将详细讲解如何将模型拆分成多个小型模块,并将这些模块分布式部署到不同计算设备上的具体方法,我们将在宏观层面进行概述性讲解
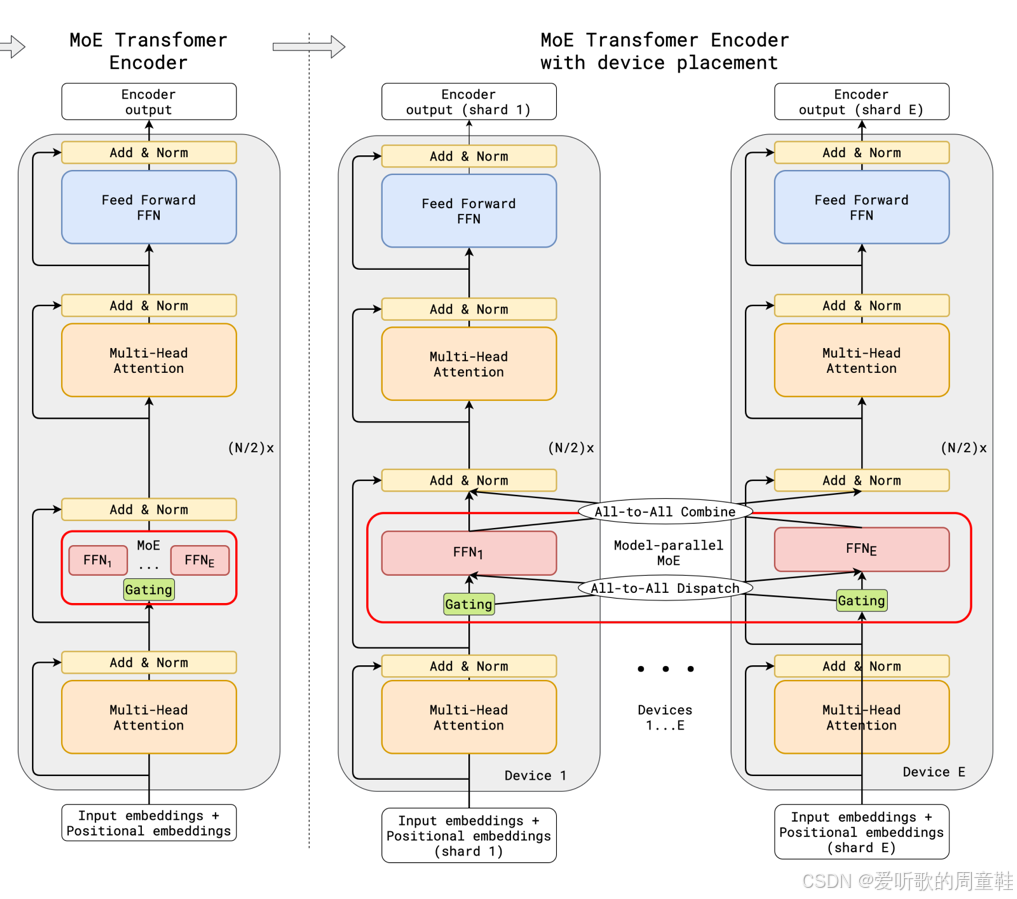
采用专家架构时,专家层级的并行化就呈现出天然的实现路径,因此系统中会存在多个独立的前馈计算模块,我们可以将每个专家模块部署到独立的计算设备上。由于专家模块采用稀疏激活机制,只需将输入 token 路由至对应设备,所有计算即可在该设备上完成
这种架构天然具备模型分片能力,可轻松将模型拆分部署到不同设备上,这种分布式计算模型被称为 专家并行化。这也正是混合专家模型广受欢迎的另一大优势,要真正实现超大规模模型的并行化计算,专家并行化是必经之路。
1.3 Some MoE results
有趣的是,MoE 最初由谷歌研发,随后众多前沿实验室(包括许多封闭研究机构)都相继采用了这项技术,但值得注意的是,最引入瞩目的是开源成果往往来自中国研究机构。去年,Qwen 和 DeepSeek 在 MoE 领域取得了大量突破性进展,直到最近,西方开源社区才真正开始加大在 MoE 领域的投入。
因此我们看到 Mixtral、Grok(虽然 Grok 并未开源)相继问世,如今 Llama 也采用了混合专家架构,前段时间 Llama 4 正式发布,它同样采用了稀疏混合专家架构。在接下来的课程讲解中,我们也会详细讨论 Llama 4 的相关内容
正如我们前面提到的,中国研究团队,特别是 Qwen 和 DeepSeek 在这方面做了非常出色的基础性工作,他们通过详尽的基准测试和系统评估为 MoE 的性能研究提供了重要洞见
这些混合专家模型中,Qwen-1.5 是首批实现大规模部署、经过充分测试和完整文档记录的混合专家系统模型之一,他们的创新做法是:基于 Qwen-1.5 的稠密模型,通过巧妙地模型升级技术将其转化为混合专家架构,这种将稠密模型转化为混合专家架构的做法确实非常巧妙。
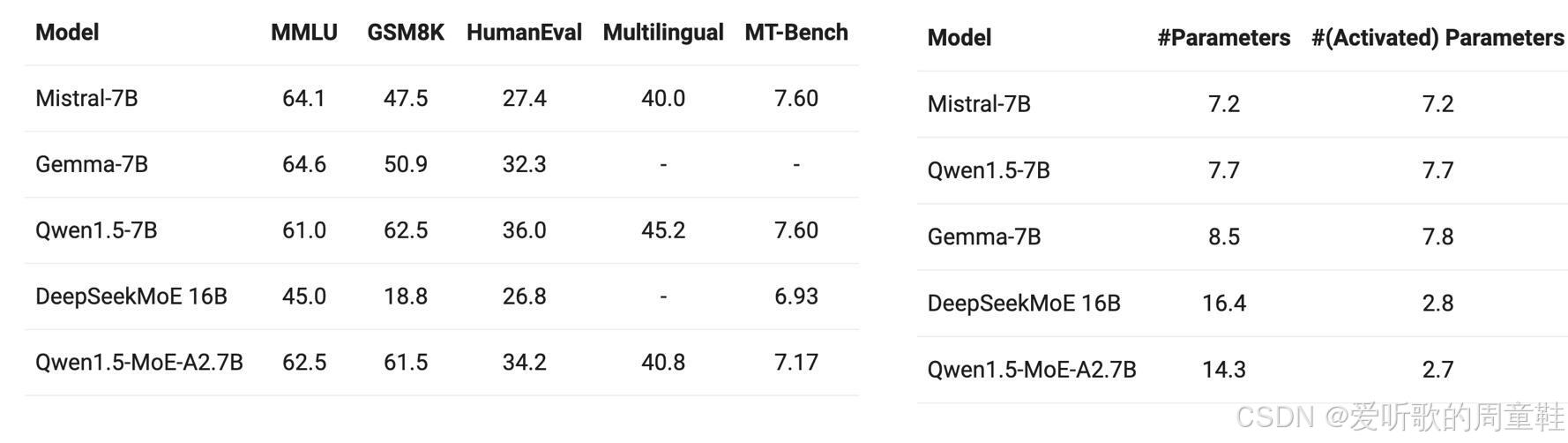
他们的实验数据表明:相较于原有的 70 亿参数稠密模型,这种改造方案在显著提升计算效率的同时还实现了参数总量的下降,这种 "减量增效" 的效果确实令人印象深刻
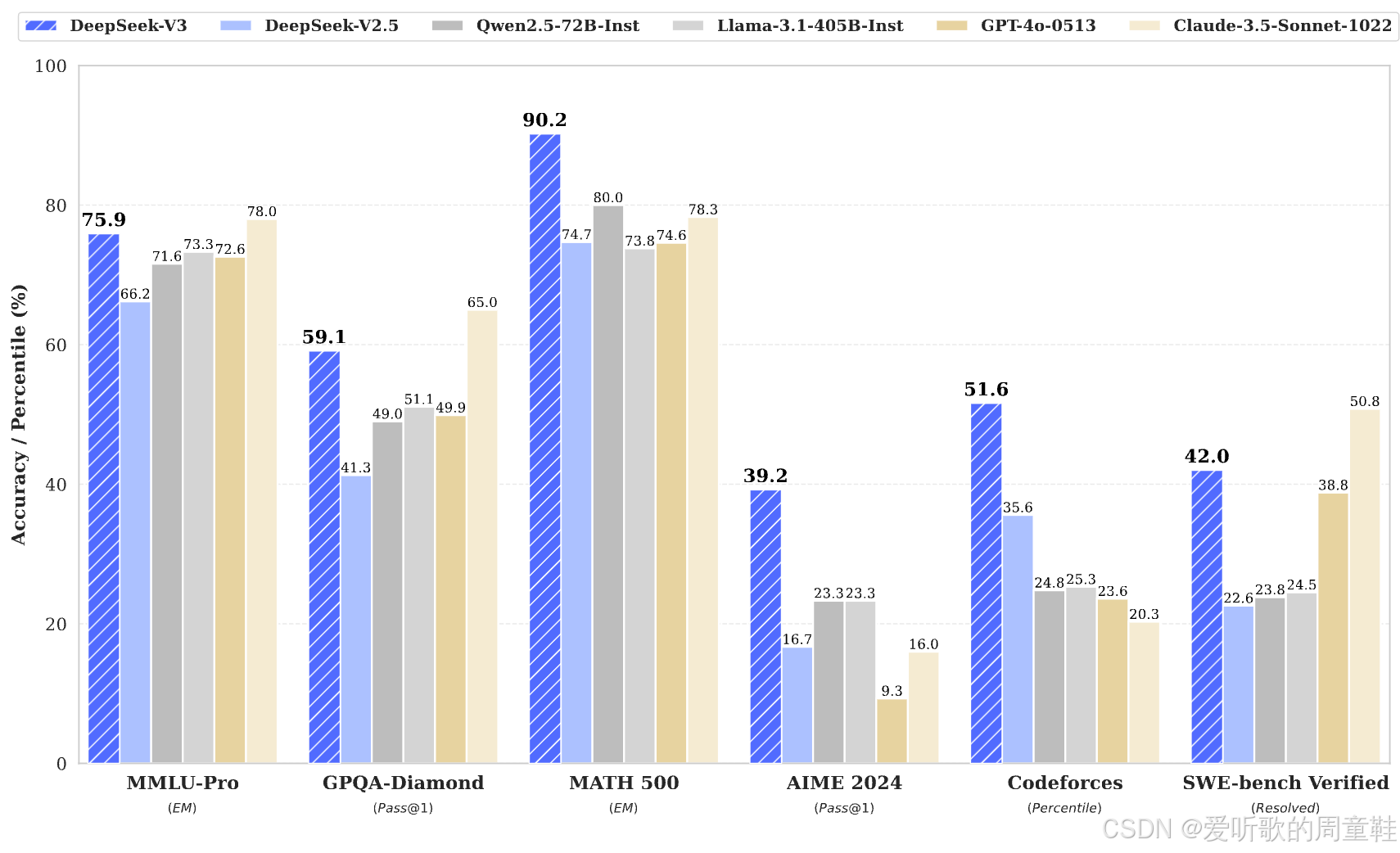
DeepSeek 前段时间声名远扬,但在其论文最初发表时还不太为人所知,正是他们完成了开源领域真正具有奠基意义的混合专家架构研究。本次讲座的核心内容正是要系统梳理 DeepSeek 混合专家架构的技术演进路径,但细读他们最初的 DeepSeek 混合专家论文就会发现其中包含极具说服力的对比实验,比如当使用特定量级的浮点运算训练稠密模型时,性能表现会发生怎样的变化呢?而采用原始路由策略的基础版混合专家模型在同等计算量下又会有怎样的表现呢?若改用更智能的 Switch 混合专家路由机制,效果又将如何?
通过上面这些精心设计的对照实验,我们可以清晰观察到模型性能从稠密架构到稀疏架构的演进轨迹。这种性能演进从左至右逐列呈现(左列为稠密架构,右列则为稀疏架构),在保持 FLOPs 恒定的前提下,所有基准测试指标均呈现稳定提升,这一趋势具有高度一致性
说到这里,相信大家应该都听说过 DeepSeek-V3,某种程度上,它正是这一系列研究成果的集大成者。但如果你并非一直关注混合专家模型,却对神经网络与语言建模这一领域充满热情的话,其实早在 DeepSeek-V3 爆火之前,这个项目就已在业内崭露头角
在本次讲座的最后部分我们会发现,与最早的 DeepSeek 混合专家模型其实并没有太大差异,从架构设计的角度来看,早在训练这些仅 20 亿参数的小型模型时,他们就已经掌握了关键技术,他们在工程实现上确实做到了极致,最终打造出了性能卓越的 V3 模型
1.4 Why haven't MoEs been more popular?
OK,现在我们已经花了不少时间来详细介绍 MoE 的优势了,混合专家模型确实值得这样推崇,它们确实表现出色,但值得思考的是:为何它们尚未得到更广泛的应用呢?为什么它还没有称为自然语言处理和语言建模课程中的标准教学内容?
关键在于它们的架构过于复杂且难以驾驭,期待未来几年能出现更简化的实现方案,但就目前而言,这套系统仍然相当棘手,基础设施的复杂性是主要障碍之一。
MoE 的真正优势往往在多节点训练时才能充分显现,当模型必须进行分布式处理时,将专家模块拆分成不同模型节点就显现出独特价值。这种架构设计完全符合分布式计算的本质需求,但在达到这种规模之前,MoE 的优势可能并不明显

正如早期谷歌论文所述,这里存在一个关键取舍:只有当模型规模庞大到必须进行分布式处理时,专家模块的独特优势才会真正凸显。此外还存在若干技术难点,仔细推敲就会发现,token 路由至哪个专家模块的决策机制本身就是一个极难优化的学习问题。
深度学习领域特别青睐可微分目标函数,这类平滑的数学表达能让我们顺畅地进行梯度计算。路由决策本质上不可微分,因为系统必须做出离散选择并锁定特定专家模块,这就导致我们面临一个极其棘手的优化难题。
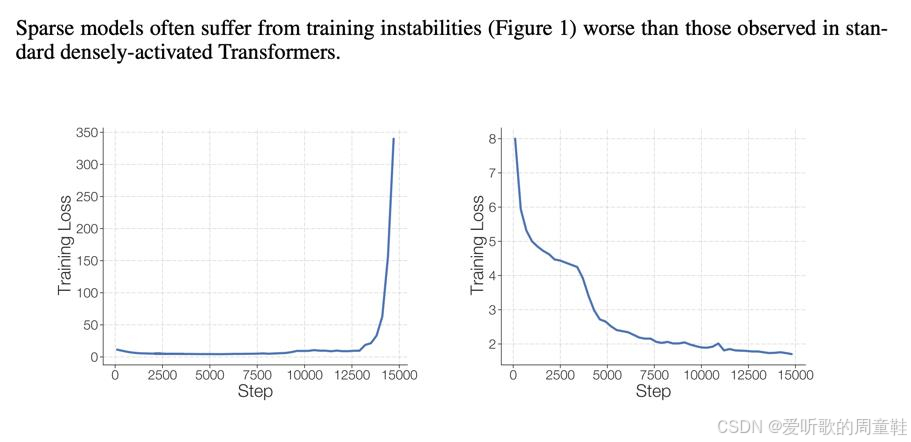
而要实现这种机制,训练目标要么依赖启发式规则,要么存在稳定性隐患,因此我们必须对这些组件进行极其精细的工程化设计才能确保其可靠运行。这正是一般情况下人们不愿采用该方案的两大关键原因
1.5 What MoEs generally look like
那么 MoE 的实际架构是怎样的呢?正如我们在讲座开头提到的---经典 MoE 的核心架构是将全连接层(即前馈网络 FFN)进行拆分或复制,在这些专家模块之间建立稀疏路由决策机制
当然,这种设计理念同样可以延伸应用,确实可以构建稀疏路由的注意力层,已有研究者 JotMoE 实现了这种架构:
虽然有若干论文和模型采用了这种设计思路,但在主流大模型发布中,这种架构确实较为罕见。网络上有观点认为,这种架构实际上存在更强的训练不稳定性,要实现稳定收敛确实极具挑战性。虽然尚未见到系统的消融实验验证这一说法,但确实鲜有团队真正尝试训练这种结合 MoE 的注意力层架构
1.6 MoE -- what varies?
以上就是基础架构的核心要点。这个架构其实非常简单,本质上就是通过某种路由机制进行分配,然后连接不同的多层感知机(MLP)模块。那么,不同 MoE 方案之间可能存在哪些差异呢?
你可能会问:路由机制是如何实现的?路由函数的选择显然至关重要。专家数量与单个专家模型的规模该如何确定?这同样是个需要取舍的决策。最后一个关键问题:如何训练这个路由模块?面对这个看似难以优化的不可微分目标,我们该采用什么方法?这些确实是至关重要的设计考量
下面我们将逐一探讨这些问题,力求全面覆盖 MoE 的设计空间
2. Routing function
若想了解混合专家模型的全貌,Fedus 等人撰写的综述论文 Fedus+ 2022 是非常好的参考资料,这篇 2022 年的论文全面涵盖了 MoE 的诸多方面,课程中的许多图表都引自该论文
当我们考虑如何将 token 路由(或者说匹配)到专家模块时,这正是 MoE 的核心机制。当 token 流输入时,系统需要完成以下关键操作:在处理序列时,系统会将序列中的各个 token 动态分配给不同的专家模块,并非所有专家模块都会处理每个 token,这正是稀疏路由混合专家模型的核心设计理念
2.1 Routing type
那么问题来了,这些路由决策究竟是如何制定的?路由决策主要存在三种实现方式:
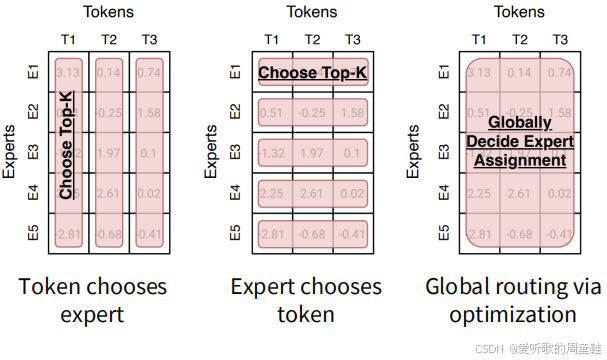
第一种是 token 级路由选择,每个 token 会生成对不同专家的偏好权重,系统则为每个 token 选取偏好度最高的前 K 个专家进行处理。
第二种是专家级路由选择,每个专家会对所有 token 进行优先级排序,然后为每个专家分配其最偏好的前 K 个 token 进行处理,这种机制的最大优势在于能实现专家间的负载均衡。
第三种方案则是通过求解复杂优化问题,确保专家与 token 之间的分配关系始终保持均衡状态,这属于全局分配策略。
这里先透露一个关键信息:当前绝大多数混合专家模型采用的都是 token 选择 Top-K 路由机制。
在 MoE 发展初期,研究者们尝试过形形色色的路由方案,几乎探索了整个 token 路由的设计空间,纵观主流模型的重大版本更新,业界已基本统一采用 token 选择 Top-K 这类路由机制,每个 token 都会根据亲和度对专家进行排序,然后从中选出 Top-K 个最优专家进行分配
本次讲座我们会反复提及 OlMoE 的研究成果,他们做了非常漂亮的一系列消融实验,堪称绝佳的教学案例,其中就包含下面这个路由机制的对比实验:
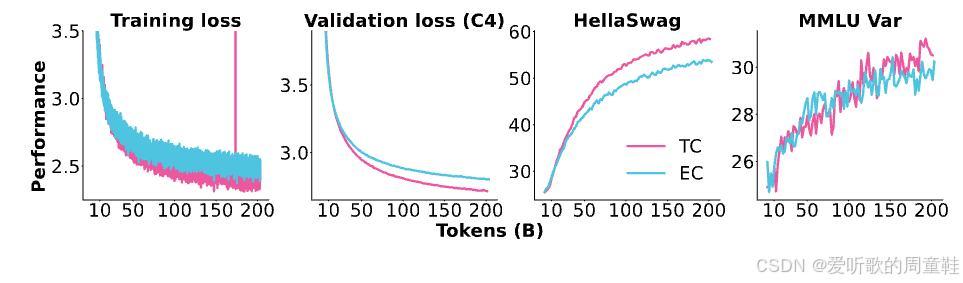
他们专门对比了 token 选择路由与专家选择路由两种机制的性能差异,实验数据显示(观察验证损失曲线可知),token 选择路由的表现明显更优,其损失值下降速度要快得多
2.2 Common routing variants
下面我们会介绍几种变体方案,实际上,要掌握高性能的混合专家系统,掌握 Top-K 机制就够了,不过考虑到其他方案也是自然衍生的思路,我们会一并介绍。
Top-K 路由选择是当前大多数 MoE 系统采用的核心机制,即基于 token 的 Top-K 路由策略
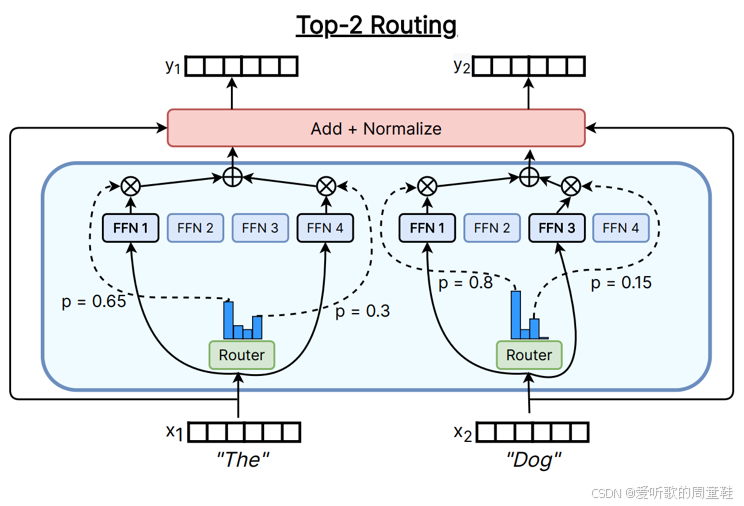
具体实现流程是:将残差流输入向量 x x x 送入路由模块,正如前面所说,路由机制本质上类似于注意力运算的工作方式,其核心计算包含线性内积运算与随后的 σ \sigma σ 归一化处理,系统会筛选出激活度最高的 K 个专家模块,随后对这些模块的输出进行门控加权
根据具体实现方案的不同,系统可能会基于路由权重对输出结果进行加权处理,也可能直接采用等权重整合。最终输出会根据 MoE 的具体实现方式,采用加权平均或直接求和的方式进行整合
因此,多数 MoE 的研究论文与方法都采用了 Top-K 筛选机制,Switch Transformer(k=1)、GShard(k=2)、Grok(2)、Mixtral(2)、Qwen(4)、DBRX(4)以及 DeepSeek(7)系列各版本均采用了不同的 Top-K 变体实现方案
有个令人惊讶的事实,这可能会颠覆你对 MoE 的认知,大量实验结果表明:实际上我们根本不需要设计复杂的路由机制,事实上,你完全可以直接采用最基础的哈希函数,将输入特征 x x x 映射到对应的专家模块上
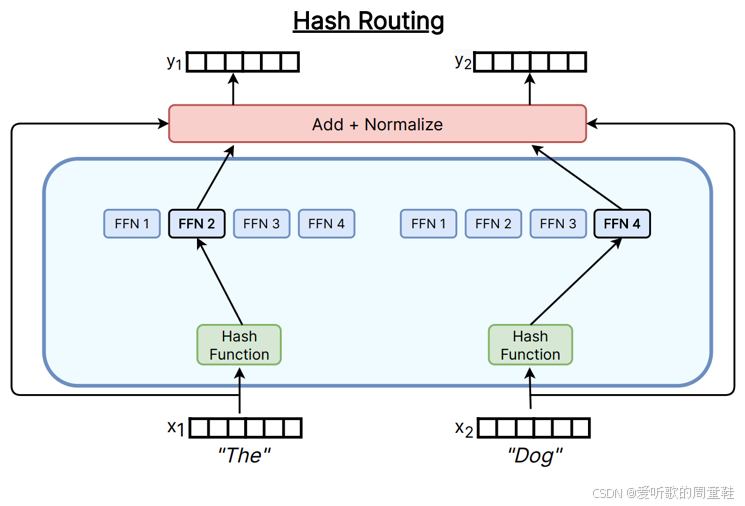
更令人惊讶的是,即便采用完全不含语义信息的哈希路由机制,基于哈希的 MoE 依然能带来性能提升,这个现象确实相当反直觉
在 MoE 系统的早期研究中,有个极具前瞻性的思路,如果从顶层设计角度考虑,这至今仍是正确方向,那就是 通过强化学习来训练路由决策机制。
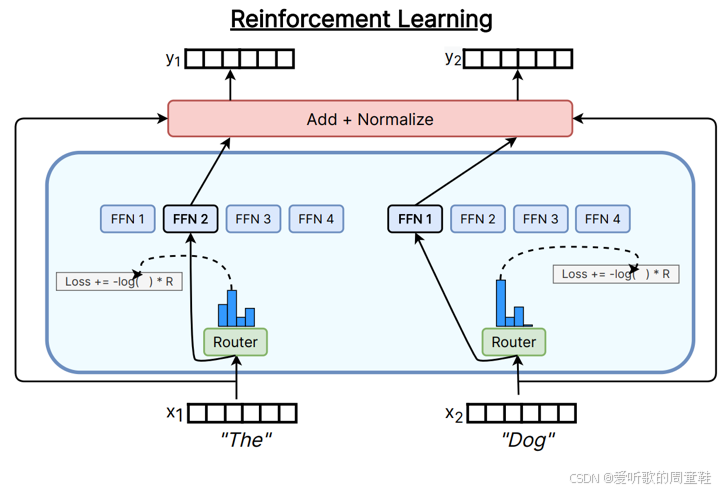
当然,路由目标的选取本质上属于离散决策问题,而强化学习恰好擅长处理这类离散决策任务。那为什么不用强化学习来训练路由机制呢?
在 MoE 的早期研究中,确实采用过这种方法,但现在几乎没人采用这种方案了,这种方案的计算成本实在太高,况且系统本身已经存在稳定性问题,这么做可能不太明智
确实有几篇论文 Clark+ 2020 探讨过采用线性分配问题或最优传输类问题的解决方案,这些方法确实非常精妙
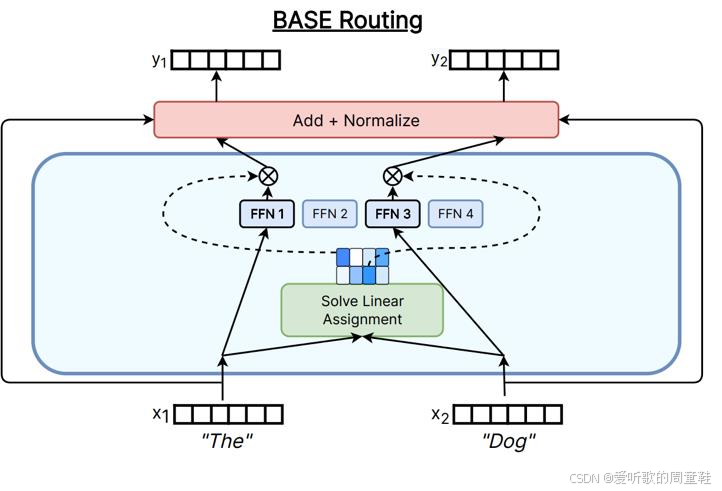
但话说回来,实际应用中这么做的成本远高于它带来的收益,这种方案至今仍未得到实际应用。不过学界确实涌现了不少提升路由机制的创新思路
2.3 Top-K routing in detail
现在我们可以来深入剖析路由机制的具体工作原理,这种 Top-K 路由机制已成为当前业界普遍共识
h t l = ∑ i = 1 N ( g i , t F F N i ( u t l ) ) + u t l , g i , t = { s i , t , s i , t ∈ T o p k ( { s j , t ∣ 1 ⩽ j ⩽ N } , K ) , 0 , o t h e r w i s e , s i , t = S o f t m a x i ( u t l T e i l ) , \begin{split}\mathbf{h}{t}^{l}&=\sum{i=1}^{N} \left(g_{i,t} \mathrm{FFN}{i}\left(\mathbf{u}{t}^{l}\right)\right)+\mathbf{ u}{t}^{l},\\ g{i,t}&=\begin{cases}s_{i,t},&s_{i,t}\in \mathrm{Topk}(\{s_{j,t}|1\leqslant j\leqslant N\},K),\\ 0,&\mathrm{otherwise},\end{cases}\\ s_{i,t}&=\mathrm{Softmax}{i}\left(\mathbf{u}{t}^{l^{T}}\mathbf{e}_{i}^{l} \right),\end{split} htlgi,tsi,t=i=1∑N(gi,tFFNi(utl))+utl,={si,t,0,si,t∈Topk({sj,t∣1⩽j⩽N},K),otherwise,=Softmaxi(utlTeil),
上面展示的公式正是 DeepSeek V1-2 版本采用的路由机制,Qwen 和 Grok 采用的路由机制与此几乎完全一致。与直接在底层使用 softmax 不同,DeepSeek-V3、Mixtral 和 DBRX 采用了另一种处理方式---它们不对底层结果做 softmax 归一化,而是对 g i , t g_{i,t} gi,t 进行 softmax 运算,不过这种差异其实微乎其微
现在让我们逐步解析这个机制的工作原理,并尝试推演其行为特征。当前机制的核心流程是:最底层接收输入数据,这里的 u t l \mathbf{u}_{t}^{l} utl 就是我们的输入层,现在我们需要将这个残差连接输入通过 MoE 进行处理
首先需要确定激活哪些专家模块,这是通过门控机制完成的:输入向量经过线性变换后生成专家权重,再通过 top-k 筛选激活权重最高的 k 个专家
那么,我们该如何实现这个目标呢?其实它的做法和注意力机制非常相似,先用残差流输入向量 u t l \mathbf{u}{t}^{l} utl 与各个专家向量 e i l \mathbf{e}{i}^{l} eil 做内积运算,这些是每个专家对应的学习向量, e i \mathbf{e}_{i} ei 的指向代表着该专家的专业领域方向,因此通过这个内积运算,我们实际上是在计算专家与输入之间的匹配度。
接着计算一个 softmax 函数,以确定每个 token 最适合由哪些专家处理,所以会进行归一化处理,这就是 s i , t s_{i,t} si,t。现在,我们将 s i , t s_{i,t} si,t 输入 top-K 函数进行处理,只选取前 K 个最优权重,并将其作为门控值使用,其他权重置零。并计算各专家输出的加权平均值,最后将这个结果叠加到原始残差流上并返回输出
相信大家对这套流程应该非常熟悉,这正是 Transformer 的标准工作方式,唯一的区别就在于这个 top-K 路由机制。从某种意义上说,这种路由机制的前向传播过程其实非常简单,真正令人惊叹的是,这种机制竟然能够被训练得如此出色。从某种程度上说,这套机制包含着一系列相当复杂的环节,要让模型学会完美掌握实属不易
2.4 Recent variations
DeepSeek MoE 最具突破性的创新就是 同时采用了共享专家和细粒度专家的架构思路,这个设计很快被其他中国团队发布的 MoE 模型采用
最初提出的基础 MoE 架构,本质上是将稠密模型结构复制出多个专家副本,这种情况下,假设采用 top-2 路由机制,那么被激活的参数总量将达到原始稠密模型的两倍,这样构建 MoE 模型时,只需复制专家模块并设置激活参数 K=2 即可,这可以视为最基础的标准 MoE 架构,也是大多数研究的初始方案
研究者们很快发现,增加专家数量能显著提升模型性能,很自然地,研究重点转向了如何在增加专家数量的同时避免参数规模膨胀的问题,因此 DeepSeek 团队提出创新方案:将专家模块拆分为更细粒度的子单元。
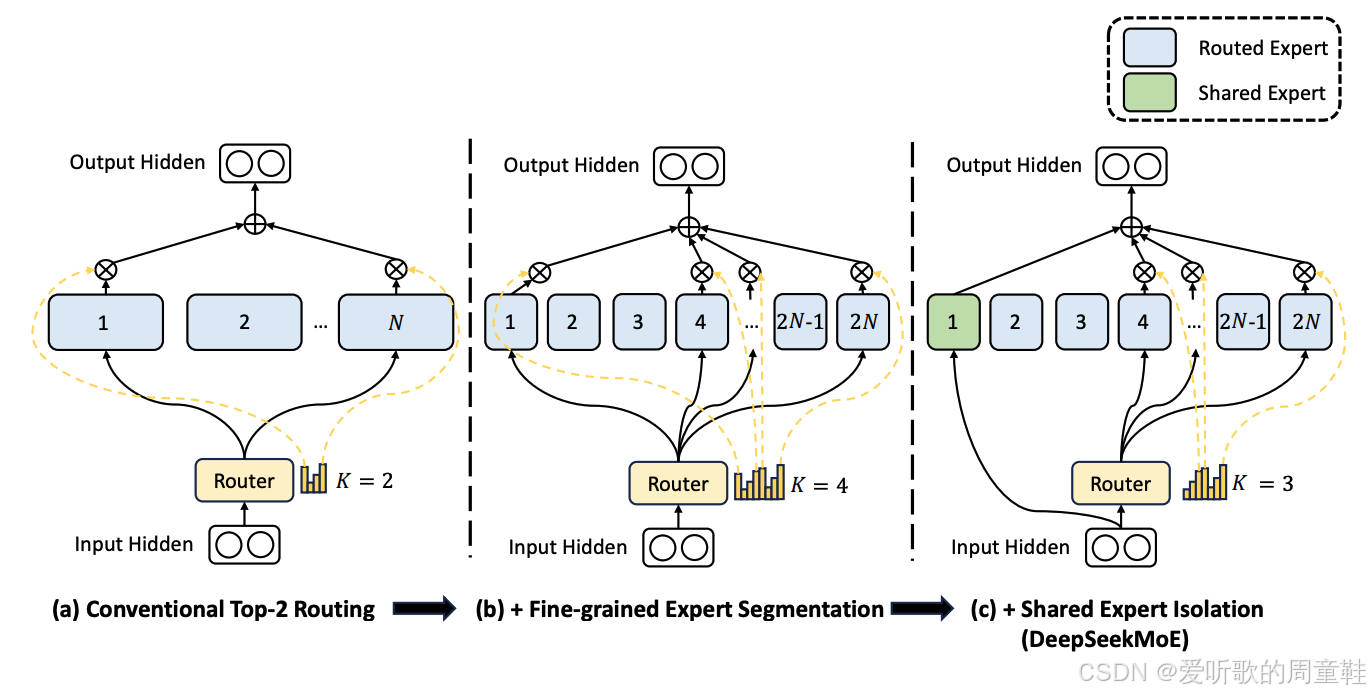
还记得上次讲座提到的黄金法则吗?隐藏层的维度乘以 4 就能得到投影层的理想尺寸。现在我们的做法有所调整,不再采用 4 倍乘数,而是改用 2 倍比例,这样就能得到更精简的矩阵结构,专家模型的粒度因此变得更加精细,专家数量可以轻松实现翻倍。
这种设计思路还能进一步推向极致,投影维度可以持续压缩,四倍、八倍甚至更高倍数地规约都成为可能,这就是细粒度专家的精髓所在。不过后续我们会详述这种设计存在的弊端,这种设计并非没有代价,因此必须谨慎设计这些组件的架构
另一个被研究证实的重要发现是:保留至少一个能捕捉共享结构的 MLP 可能大有裨益,或许这仅仅是数据处理的需要,无论处理哪个 token,这些操作都是必经步骤。这种情况下,若将所有参数分散配置并执行复杂的路由决策,反而显得效率低下,更合理的做法是设置一个或少数共享专家,专门处理这些必须的通用计算任务,因此便有了共享专家的设计,这种结合细粒度专家与共享专家的架构最初由 DeepSeek MoE 提出,但设计灵感可追溯至 DeepSeek MoE 的研究成果。
通义千问(Qwen)等后续模型,事实上自 DeepSeek 之后几乎所有开源的 MoE 模型,都不同程度地吸收了这些创新设计。原因显而易见:特别是细粒度专家机制,其实际效用确实非常突出,这种做法如今已成为行业标配
阅读 DeepSeek 的论文时最令人欣赏的一点,就是他们始终坚持做消融实验,这可不是那种敷衍了事的技术宣传稿,他们真正在意的是方法是否切实有效
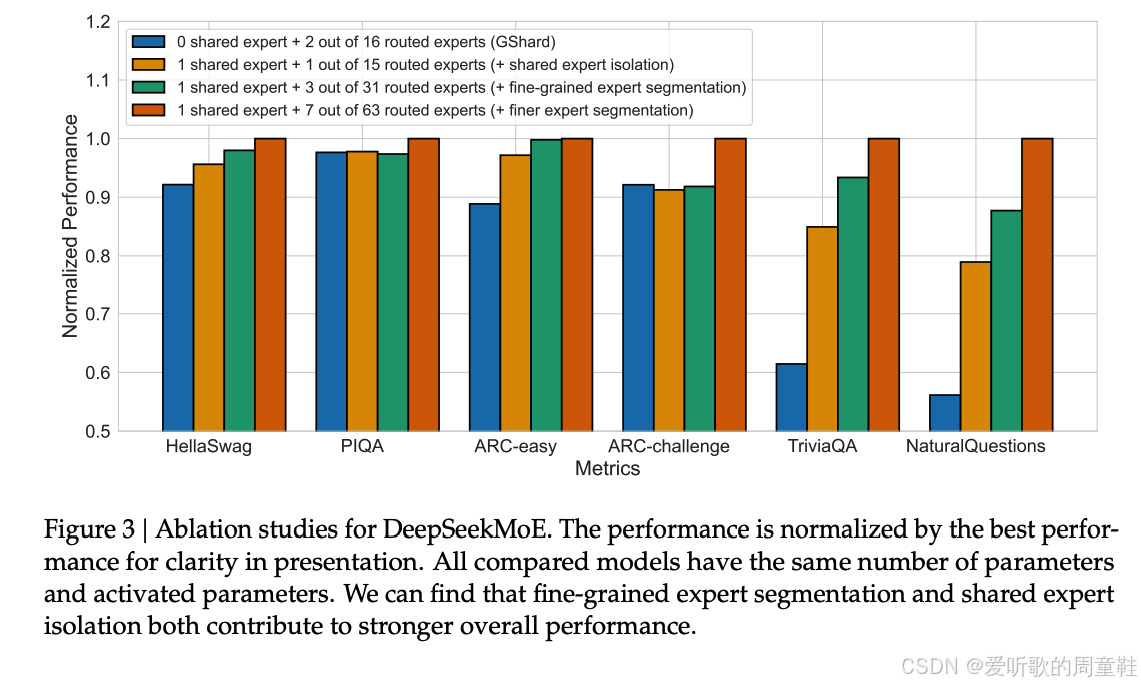
在 DeepSeek MoE 论文中,他们精心设计了消融实验,如图所示,这里的蓝色柱状图代表 GShard 的表现,这是混合专家模型最基础的标准实现方案;图中橙色条代表共享专家模块,它能显著提升某些任务的性能,但对其他任务则毫无增益效果;可以采用细粒度专家架构,图中绿色与橙色柱状图所示,采用该架构还能带来进一步的性能提升。
如果将蓝色柱状图与橙色柱状图进行对比,这些差异的叠加效应最终带来了远超其他方案的显著性能提升。由此可见,增加共享专家中的专家数量通常能带来性能提升
OlMoE 模型提供的实证证据充分验证了这些机制的有效性:
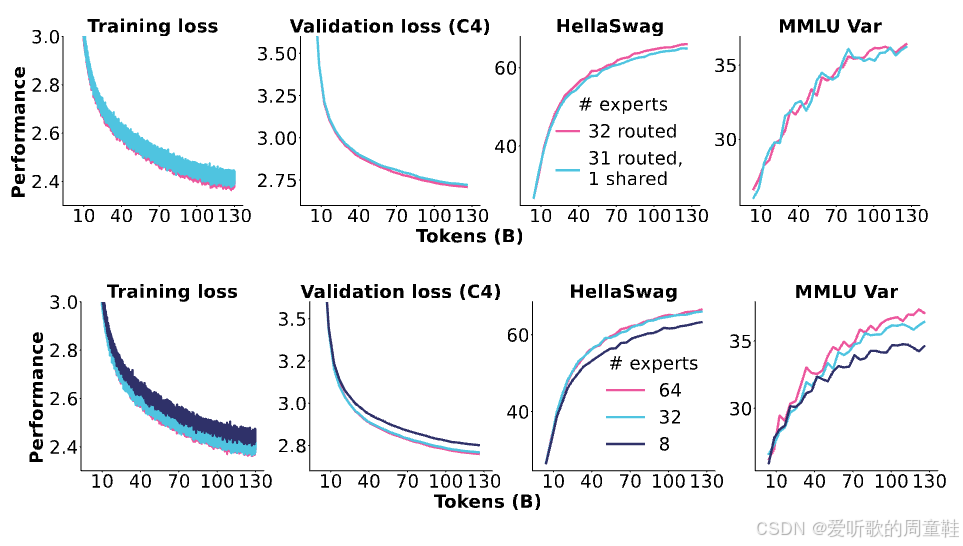
让我们先看最下方的实验结果,这部分更具说服力,它展示了细粒度专家数量从 8 个逐步增加到 32 个再到 64 个时的性能变化,这个实验设计在某种程度上与 DeepSeek 团队的消融研究形成了呼应,各项损失指标和其他评估参数都呈现出明显的优化趋势,从 8 个到 32 个再到 64 个细粒度专家的扩展过程中,细粒度专家模块确实表现出色
在图表最上方用紫色与青绿色标注的共享专家对比实验中,至少基于 OlMoE 的架构设置来看,我们并未观测到显著的性能提升,因此他们最终选择完全不采用共享专家架构,尽管 DeepSeek 论文的实验数据曾显示出该架构的增益效果
由此可见,考虑到后续研究和第三方团队对这些理念的复现效果,共享专家架构的实际效果其实存在较大争议
3. Expert sizes
说到这里,你可能会好奇:目前业界常用的配置方案究竟是怎样的?我们可以通过梳理近期发布的模型架构,分析业界实际采用的方案,并尝试总结其中显现的技术规律
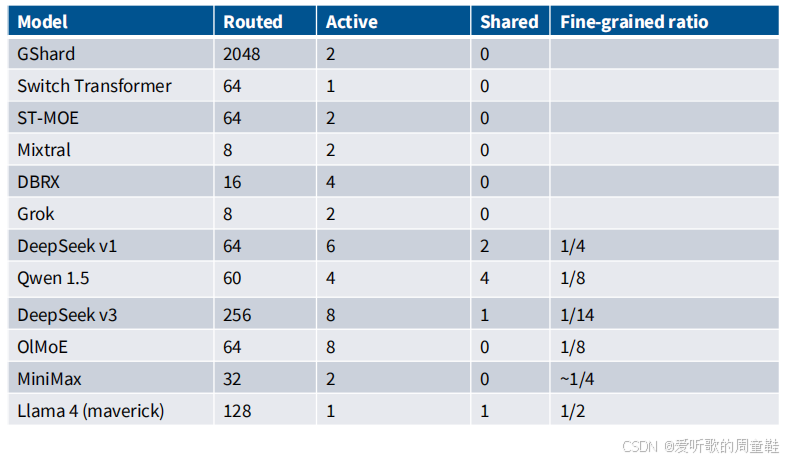
早期谷歌发表的几篇论文 GSharedSwitch TransformerST-MoE 都采用了数量庞大的路由专家架构,这些论文确实提出了许多极具创新性的技术方案,建议大家仔细研读这些论文,其中部分创新思路最早出现在 LSTM 等传统架构中。
但很快业界就进入了 8 到 16 个专家的主流配置阶段,比如 Mixtral、DBEX 和 Grok 都采用了双活跃专家的模式,这些架构在实际应用中表现相当出色
但随后 DeepSeek MoE 横空出世,它采用了之前提到的经典架构配置:包含 64 个细粒度专家(其中 6 个处于活跃路由状态)和 2 个共享专家,每个专家的参数量仅为标准专家规模的 1/4,最后一列数据仅供参考,因为这些数值是通过逆向解析配置文件等方式推算出来的,因此具体的比例参数并非完全确定
目前主流模型阵营主要包括 Qwen1.5、DeepSeek-V3 和 MiniMax 这三大体系,这些都是中国研发的 MoE 模型,它们基本上沿袭了 DeepSeek-V1 的技术路线,具体参数配置各有差异。架构来看,这些模型都采用了细粒度专家模块,并普遍设有共享专家层,与最初 DeepSeek 提出的 MoE 模型配置高度相似。
OlMoE、MinMax 和 Llama 都是最新推出的 MoE 模型,它们确实采用了细粒度专家架构,而 Llama4 同样采用了共享专家机制,虽然具体配置各有差异,但核心架构都延续了细粒度专家这一核心理念。特别是 Llama 4 的 DeepSeek 这类大模型,其专家总数(注意不是路由专家数)规模极其庞大
4. Training objectives
通过以上讨论,相信你已经对多数 MoE 模型的路由机制及其整体架构有了基本认知,此外你应该已经完全理解了前向传播的工作机制,现在我们需要探讨训练环节,这个过程相当棘手
正如前面所说的,训练过程中的主要挑战在于:我们不能激活所有专家模块,否则就要承担全部专家计算量的 FLOPs 开销,训练成本暴涨 256 倍的模型方案根本行不通,因此我们需要在训练时保持稀疏性。
但稀疏路由决策显然是不可微分的,这就导致我们陷入了一个棘手的类强化学习问题,我们可以采取多种解决方案,比如用强化学习来优化路由策略,也可以借鉴多臂老虎机思路,通过随机策略进行探索,或者干脆采用启发式方法,通过添加平衡损失项来碰碰运气
学过各类深度学习课程的人应该都能猜到,实际应用中大家最终选择了哪种方案。接下来我们将依次讲解这三种方案
4.1 RL for MoEs
强化学习方案其实是最早被尝试的路径之一,这可能是该领域最具理论依据的研究方向。路由决策本身是不可微分的,不妨将其视为策略问题,直接套用强化学习框架来解决,遗憾的是,这种方法的表现并不比其他可行方案更出色
Clark 等人 2020 年发表的论文 Clark+ 2020 中,曾针对混合专家模型中的各类扩展性问题展开研究,在论文中确实发现了他们建立的强化学习基准方案,但遗憾的是,这种方法的表现并没有明显优于简单的哈希决策方案
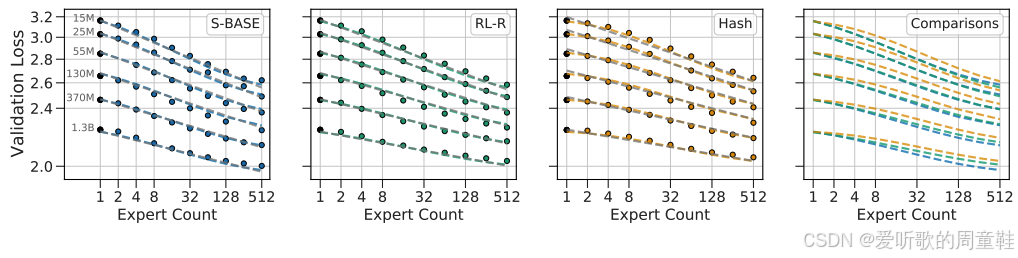
他们重点对比了左侧名为 S-BASE 的基准方法,这种基于线性分配的方案,其表现明显由于强化学习方法。在实际应用中,梯度方差和算法复杂度导致该方法使用起来相当棘手,目前还没有大规模应用真正采用基于强化学习的门控决策优化方案
4.2 Stochastic approximations
业界更普遍采用的是各类随机近似方法的大规模应用,实际操作中,他们可能会引入一些扰动机制。这里以 Shazzer+ 2017 的论文为例,作为早期混合专家模型研究的代表作,他们当时仍采用 top-K 路由机制
G ( x ) = S o f t m a x ( K e e p T o p K ( H ( x ) , k ) ) H ( x ) i = ( x ⋅ W g ) i + S t a n d a r d N o r m a l ( ) ⋅ S o f t p l u s ( ( x ⋅ W n o i s e ) i ) K e e p T o p K ( v , k ) i = { v i , if v i is in the top k elements of v . − ∞ , otherwise. G(x) = Softmax(KeepTopK(H(x), k)) \\10pt H(x)_i = (x \cdot W_g)i + StandardNormal() \cdot Softplus((x \cdot W{noise})_i) \\10pt KeepTopK(v, k)_i = \begin{cases} v_i, & \text{if } v_i \text{ is in the top } k \text{ elements of } v. \\ -\infty, & \text{otherwise.} \end{cases} G(x)=Softmax(KeepTopK(H(x),k))H(x)i=(x⋅Wg)i+StandardNormal()⋅Softplus((x⋅Wnoise)i)KeepTopK(v,k)i={vi,−∞,if vi is in the top k elements of v.otherwise.
该方案保留 H ( x ) H(x) H(x) 运算结果中 top-K 个元素,并通过 softmax 函数处理以获得门控权重,而实现这个 H ( x ) H(x) H(x) 运算的具体方法是:我们将基于原始线性亲和度(linear affinity)进行计算,这与我们之前的处理方式完全一致。本质上,我们只是计算输入 x x x 与每个门控对应的可学习权重之间的运算,因此这部分计算保持不变
但现在我们要对这个计算加入一些扰动,这里我们将加入一个正态分布的随机扰动,然后选择一个可学习的噪声缩放系数 W n o i s e W_{noise} Wnoise,这个参数将控制在此过程中注入的噪声量,这本质上是一种随机探索策略。通过特定方式调控 W n o i s e W_{noise} Wnoise 参数,比如逐步退火衰减或采用其他调节手段,这样就能精准控制混合专家模型在探索与利用之间的取舍关系
这便为解决探索-利用困境提供了一种可行方案,特别是在引入噪声扰动时,每个专家模块都可能随机接收到预期之外的 token,这种机制会降低专家模块的专精程度,但可能提升其泛化鲁棒性
整体来看,这种设计确实相当精妙,当然,随机性也意味着专家模块无法达到最佳专精程度从而导致效率损失。

研究者还尝试过另一种方法,通过对路由器逻辑值施加乘积扰动(确切地说是乘性干扰),旨在增强专家模块的鲁棒性,但后续研究中移除了这种抖动处理机制,因为它的实验表明其效果欠佳
基于启发式的损失函数优化方法同样被证明收效甚微,属于早期探索性尝试:
这种随机路由策略最早出现在谷歌早期的几篇论文中,但当前大多数模型训练者已普遍摒弃了这类方法
4.3 Heuristic balancing losses
实际应用中,人们最终采用的方案是:上面这些方法统统不用,我们不采用强化学习方案,也摒弃随机探索策略,而依靠另一套机制来维持系统合理性。
采用 top-2 路由机制时,从技术层面而言,梯度下降过程中确实能获得有效信号,因为我们能对实际评估过的两个最优专家进行比较,因此系统具备优化空间。但若忽略所有约束条件,最严重的问题就是系统会始终选择同一个专家,这个专家看似全能,而其他专家则沦为摆设,最终系统会陷入局部最优的困境---所有 token 永远只被路由到同一个专家。
因此,真正的核心挑战在于:如何突破这种局部最优困局?损失平衡(loss balancing) 正是破解这一困局的关键技巧,理解这一点至关重要,因为当前绝大多数模型训练采用的都是这种损失函数

这套方法最初源自 2022 年 Fedus 等人提出的 Switch Transformer 架构,他们在原有基础上特别增加了一项损失计算:遍历每个专家模块,计算向量 f f f 与向量 P P P 的内积运算,那么这两个向量究竟代表什么呢?
具体来说,向量 f f f 中的每个元素 f i f_i fi 表示被分配到第 i i i 个专家的 token 比例,这实际上是个概率向量,它表示在当前批次中,有多少比例的 token 被路由分配给了各个专家模块。 P i P_i Pi 则表示分配给专家 i i i 的路由概率占比,路由概率即原始通过 softmax 计算得出的预期分配决策。
因此,P i P_i Pi 衡量的是路由器原本预期的分配概率,而 f i f_i fi 表示经过 top-K 方法筛选后最终执行的实际路由决策 。这里有个有意思的点:当我们求该损失函数对 P i P_i Pi 的偏导数时,由于该函数对 P i P_i Pi 呈线性关系,我们会发现最强烈的权重削减作用恰恰发生在那些分配量最大的核心专家模块上
因此实际上,这种权重调整是与各专家模块接收到的 token 数量成比例的。这意味着,专家模块接收的 token 越多,其权重受到的抑制效应就越显著,这就是该损失函数的核心作用机制
目前业界普遍采用这种基于 f ⋅ P f \cdot P f⋅P 的优化技巧用于实现不同计算单元间的 token 负载均衡,最初需要实现负载均衡的基本单位是训练批次,虽然我们希望每个批次的样本能均匀分配给各专家模块,但实际应用中可能还需要其他维度的平衡策略
而 DeepSeek 正是采用了这类平衡机制,我们将详细讲解他们引入的所有变体方案,但首先要说的是基于批次的专家级平衡机制,每个训练批次需要确保各专家模块接收的 token 数量保持均衡
L ExpBal = α 1 ∑ i = 1 N ′ f i P i , f i = N ′ K ′ T ∑ t = 1 T 1 ( Token t selects Expert i ) , P i = 1 T ∑ t = 1 T s i , t . \begin{align*} \mathcal{L}{\text{ExpBal}} &= \alpha_1 \sum{i=1}^{N'} f_i P_i, \\8pt f_i &= \frac{N'}{K'T} \sum_{t=1}^{T} \mathbf{1}(\text{Token } t \text{ selects Expert } i), \\8pt P_i &= \frac{1}{T} \sum_{t=1}^{T} s_{i,t}. \end{align*} LExpBalfiPi=α1i=1∑N′fiPi,=K′TN′t=1∑T1(Token t selects Expert i),=T1t=1∑Tsi,t.
这一设计源自 DeepSeek 的研究论文,相信这个机制对大家来说应该非常眼熟,这正是我们之前见过的相同结构--- f ⋅ P f \cdot P f⋅P 内积形式, P i P_i Pi 的定义略有不同,这里的表达式是 s i , t s_{i,t} si,t,这就是进行 top-K 选择前的 softmax 计算
此外,还需要考虑系统层面的问题,由于专家模块会分布在不同设备上运行,因此还需要确保每个设备上的负载均衡,我们可以引入另一个结构相似的损失函数:
L DevBal = α 2 ∑ i = 1 D f i ′ P i ′ , f i ′ = 1 ∣ E i ∣ ∑ j ∈ E i f j , P i ′ = ∑ j ∈ E i p j . \begin{align*} \mathcal{L}{\text{DevBal}} &= \alpha_2 \sum{i=1}^{D} f'_i P'_i, \\8pt f'_i &= \frac{1}{|\mathcal{E}i|} \sum{j \in \mathcal{E}_i} f_j, \\8pt P'i &= \sum{j \in \mathcal{E}_i} p_j. \end{align*} LDevBalfi′Pi′=α2i=1∑Dfi′Pi′,=∣Ei∣1j∈Ei∑fj,=j∈Ei∑pj.
这里的函数 f f f 将有所不同,它是基于设备组而非单个专家进行计算的,因此现在可以设置不同的损失函数来实现设备间的平衡,对此进行优化,以确保每个 GPU 或 TPU 都能得到合理分配
token 数量为偶数时,各专家利用率保持均衡,从系统优化的角度来看,这将带来显著优势,所以本质上大家都在采用这类方法。
DeepSeek-V3 实际上做出了一些创新突破:
g i , t ′ = { s i , t , if s i , t + b i ∈ Topk ( { s j , t + b j ∣ 1 ≤ j ≤ N r } , K r ) , 0 , otherwise. g'{i,t} = \begin{cases} s{i,t}, & \text{if } s_{i,t} + b_i \in \text{Topk}(\{ s_{j,t} + b_j \mid 1 \le j \le N_r \}, K_r), \\6pt 0, & \text{otherwise.} \end{cases} gi,t′=⎩ ⎨ ⎧si,t,0,if si,t+bi∈Topk({sj,t+bj∣1≤j≤Nr},Kr),otherwise.
这个设计相当精妙,这是混合专家模型领域首个真正突破谷歌框架的创新。他们彻底摒弃了传统的每专家平衡项设计,他们现在的做法是在 softmax 得分基础上,为每个专家引入一个微调系数 b i b_i bi,这个 b i b_i bi 就是针对各个专家的动态调整参数,因此专家 i i i 的权重可能被动态调高或调低
当某个专家分配到的 token 不足时,系统会自动调高其对应的 b i b_i bi 值,从而让该专家能捕获更多 token,这个机制的工作原理是:系统会通过一个极其简洁的在线梯度方案来动态学习每个 b i b_i bi 的值
系统会在每个批次中实时监测:当前各专家分别获得了多少 token?各专家获得的 token 数量是否均衡?如果某专家获得的 token 不足,系统就会以 γ \gamma γ 学习率对 b i b_i bi 进行增量调整,从而提升其权重值。当某专家获得的 token 过多时,系统会以 γ \gamma γ 为步长进行负向调整,适度降低该专家的吸引力权重
因此系统实际上是在为每个 s i s_i si 学习微小的偏置调整量,需要特别注意的是:路由决策仅基于各 b i b_i bi 的权重值进行,实际执行时,这些偏置值并不会作为门控权重的组成部分参与计算,这一设计细节具有相当重要的意义,因此该方法被称为 无辅助损失平衡机制
如果大家去研读 DeepSeek-V3 的论文,文中会着重强调这种设计如何显著提升了训练稳定性,使其表现如此卓越。

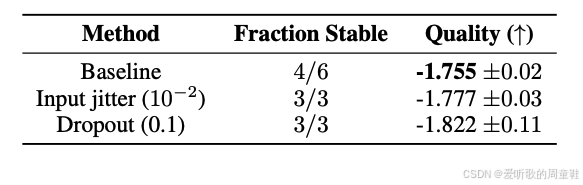
不过,但你继续往下读就会发现,作者紧接着表示:"实际上,针对每个输入序列,我们仍然需要保持某种程度的平衡性,但仅靠这种方法效果还不够理想,因此最终我们还是重新引入了启发式损失函数"
所以他们确实采用了一种名为 "互补序列级辅助损失" 的机制,这本质上正是他们认为必须引入的辅助损失机制,因为其核心目标是在单序列级别(而非批次级别)实现专家负载均衡。所以这套系统并非如宣传所言完全摆脱了辅助损失
消融实验的结果如下图所示:
如果取消专家平衡损失(expert balancing loss),模型会出现什么状况?左下角这张示意图最能说明问题,若不进行负载均衡,各专家会如何分配输入 token?
可以看到粉色和黄色的专家模块,它们几乎垄断了所有计算任务,这两个专家模块处理了约 50% 的输入 token,其余专家模块基本处于闲置状态,这些专家模块完全未被调用,此时系统中其余的六个专家模块都处于闲置状态,造成了严重的资源浪费,这实际上导致系统意外退化成了一个双专家模型
如右上角蓝绿色曲线所示,这种情况会导致模型性能显著下降,当然,这种情况可能仍优于密集型模型,毕竟至少还有两个专家模块在发挥作用,但从反事实角度来看,模型是本可以取得更优的性能表现的
4.4 Training MoEs -- the systems side
关于系统层面的深入探讨,我们暂时不会展示太多,因为目前还没有讲解核心的系统概念,比如数据中心内部的通信速度层级结构等基础知识,这些内容对于深入理解并行计算中的各类问题至关重要
正如我们之前强调的,关键要记住混合专家模型在硬件设备上的适配优势非常显著,业界所称的专家并行(expert parallel)其核心实现方式是将单个或少量专家模块部署到每个计算设备上
当你处理一个 token 时会发生什么?这时请求就会被路由层处理,经过路由层处理后,系统已选定若干专家模型,此时系统会发起集体通信调用(如全对全通信分发机制)将各 token 分派至对应计算设备,通过前馈网络完成输出计算
随后系统会将处理完毕的 token 数据精准回传至原始位置,或者说,系统会对多个专家模型的输出结果进行整合,因此需要再次发起集体通信调用来完成数据交互,只要前馈计算的任务量足够庞大,利用这种专家并行架构所付出的通信成本就是值得的,这种架构的优势在于,它为开发者提供了另一种可选的并行化方案
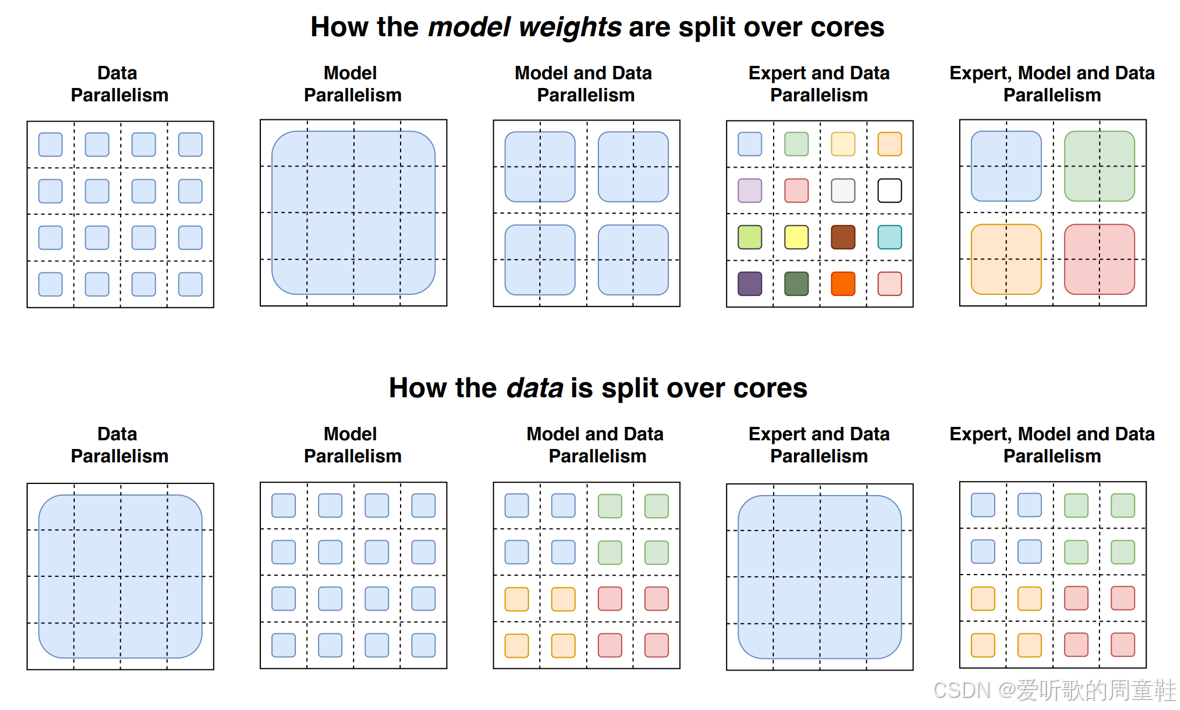
上图展示了数据并行结构以及两到三种不同的模型并行方案,此外还包含了专家并行架构,开发者可以灵活组合这些并行策略实现计算资源的最优调配。这意味着通信速度、数据规模、批量大小、专家数量以及内存容量等参数都需要纳入综合考量,具体实现细节在此不作赘述
另一个实用场景是:当单个设备部署多个专家模型时,由于计算具有稀疏性,例如首个 token 可能仅需与专家 0 进行交互,第二个 token 则与专家 1 交互,第三个 token 则交由专家 2 处理,这实际上形成了三个小型稀疏矩阵乘法运算
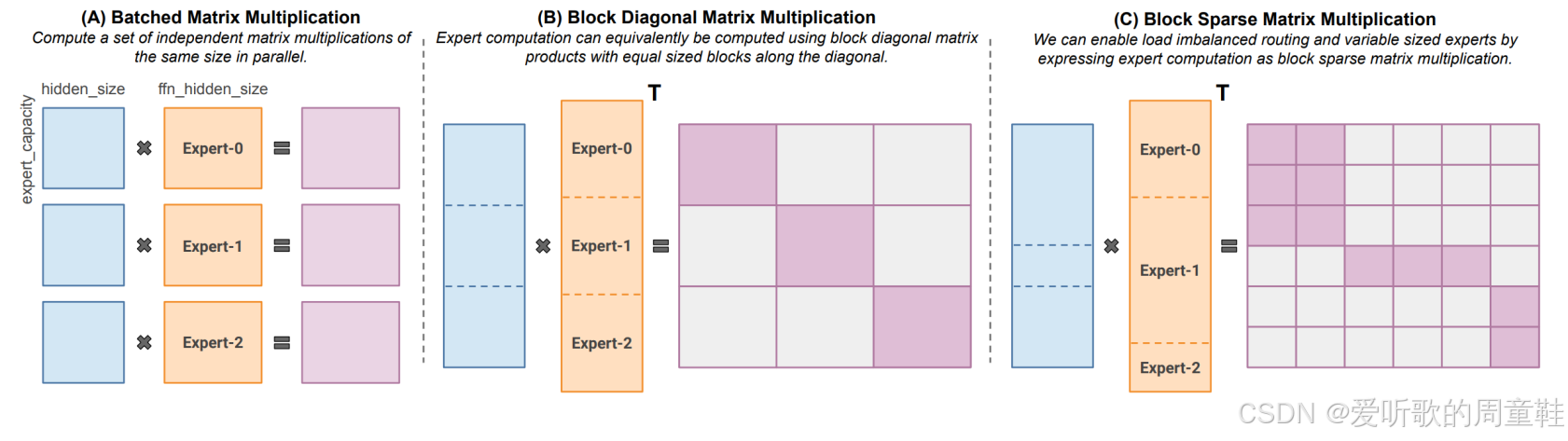
人们或许期待现代 GPU 能充分利用这类稀疏矩阵乘法的优势,确实如此,只要合理规划专家布局并以正确方式融合权重参数,现代稀疏矩阵乘法引擎就能确保在执行大规模矩阵运算时不会浪费任何浮点运算量
因此,现代计算库(如 MegaBlocks)能够充分利用硬件层面的稀疏计算支持,一次性并行完成多个专家模块的运算,这正体现了混合专家模型的另一大优势。
有个有趣的细节,那就是 GPT-4 接口刚发布时即便将温度参数设为 0,系统仍会产生不同输出响应,当时众多研究者都在推测这种现象背后的成因,混合专家模型是一个可能的原因
在混合专家模型中,想象一下会发生什么,你需要将 token 路由至专家模块,专家分布在不同的设备上,如果你对查询向量进行了批处理,这些 token 将被路由到不同的专家模型中。
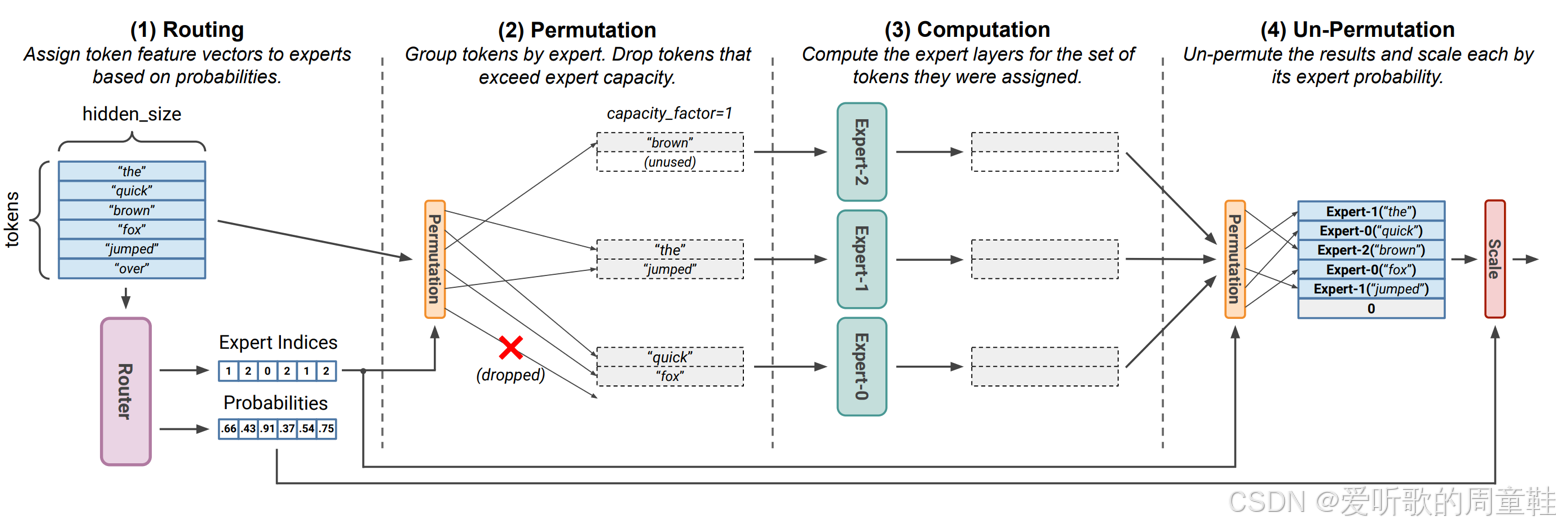
假设你手头有一批待处理的任务,这里部署了多个专家模块,但不知为何,当前这批数据特别青睐 3 号专家模块,所有 token 都涌向了 3 号专家模块,那么现在会发生什么?此时,3 号专家模块所在的设备内存将无法承载如此庞大的 token 量,于是就会出现所谓的 token 丢弃现象。
这种现象在模型训练阶段同样会出现,通常会设置一个称为负载因子的参数,用于控制每个专家模块可处理的最大 token 数量上限,当路由器向某个专家模块分配过多 token 时(无论是出于系统资源限制的考量,还是为了防止该专家在训练阶段形成垄断),这些超额 token 就会被直接丢弃。此时多层感知机(MLP)将直接输出零值计算结果,而残差连接则会直接将输入原封不动地传递至下一层,最终系统将直接返回该输出结果
因此,若某 token 被丢弃处理,其输出结果将与未被丢弃时截然不同,批次内其他样本的存在都会引入随机性。混合专家模型存在一个有趣特性:无论是训练阶段还是推理阶段,这种现象往往容易被忽视,毕竟在常规推理过程中,我们几乎不会考虑跨批次的影响效应
以上就是构建混合专家模型 MoE 核心组件的主要实现要点
5. Issues with MoEs
5.1 Z-loss stability for the router
如果你动手训练混合专家模型,系统层面的挑战可能会让你倍感头疼,但更令人头疼的恐怕是模型训练的稳定性问题。
混合专家模型有个恼人的特性:当你尝试微调时,它们可能会突然失控崩溃,这类模型的微调过程极具挑战性。为此,Barret Zoph 等研究者展开了深入探索,它们专门发表论文 Zoph+ 2022 系统研究了如何提升混合专家模型的稳定性
这里我们重点介绍几个业界常用的实用技巧,首先是路由器的 softmax 处理,这要追溯到上节课讨论的稳定性问题,关于稳定性问题之前提到过最需要警惕的正是 softmax 运算本身
因此在混合专家模型中,出于安全考虑,所有路由器的计算都采用 float32 精度进行,有时还会额外引入辅助性的 z-loss
L z ( x ) = 1 B ∑ i = 1 B ( log ∑ j = 1 N e x j ( i ) ) 2 L_{z}(x)=\frac{1}{B}\sum_{i=1}^{B}\left(\log\sum_{j=1}^{N}e^{x_{j}^{(i)}} \right)^{2} Lz(x)=B1i=1∑B(logj=1∑Nexj(i))2
在 softmax 运算中,我们需要计算指数化数值之和的对数,如上式所示,并将该值作为额外损失项加入,这样能确保归一化因子的值保持在 1 附近,有利于提升模型训练的稳定性,这其实是 z-loss 早期应用的场景之一,后来才在模型训练中流行开来
z-loss 效果如下图所示:
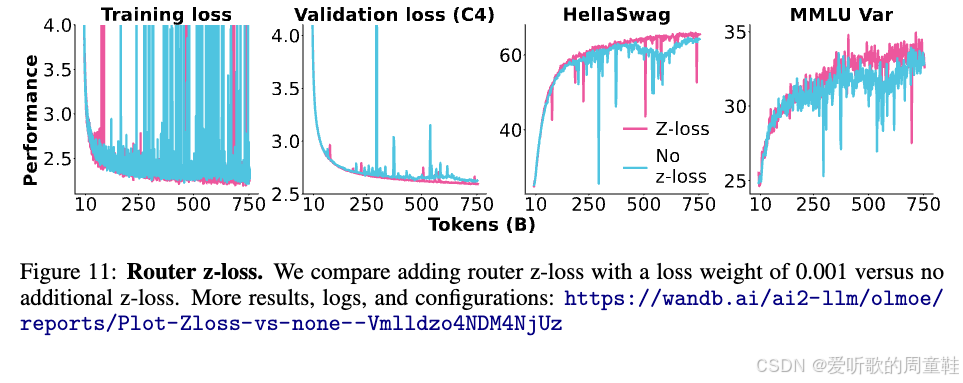
观察损失曲线时,第二张图表或许最具代表性,当从路由函数中移除 z-loss 时,验证损失会出现剧烈波动,模型会在几次迭代中陷入短暂混乱,之后才逐渐恢复稳定。当然,模型仍能正常训练,但保留 z-loss 的效果明显更优,到训练末期,验证损失会出现相当明显的差距
5.2 Upcycling for fine-tuning
当然,我们可能会对混合专家模型进行微调,若计划正式发布混合专家模型,还需通过人类反馈强化学习(RLHF)进行优化,但事实证明这种做法存在隐患。在混合专家模型研究的早期阶段,大约可追溯到 BERT 和 T5 时代,学界就曾开展过相关探索,当时研究人员进行了大量微调实验发现一个突出问题:模型出现了严重的过拟合现象
这种问题在使用稀疏模型架构时尤为明显:
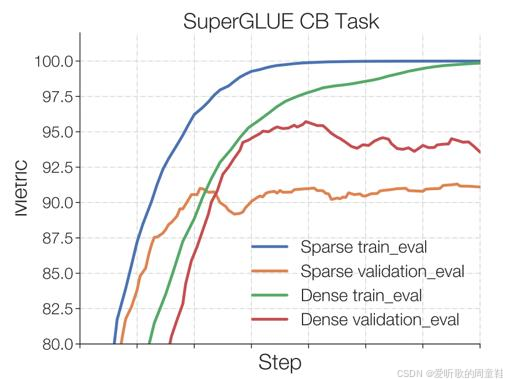
训练集与验证集之间出现了显著差距(如上图蓝线与橙线所示),而稠密模型(绿线与红线)的训练-测试差距则相对较小,当时学界对过拟合问题深感忧虑,毕竟这些参数量庞大的模型仅在小规模数据上进行微调
当时提出的解决方案之一(后面并未得到广泛采用)是设计混合专家模型时,并非每层都采用 MoE 结构,比如采用稠密层与 MoE 层交替排列的架构,此时仅需对稠密层进行微调,这样依然能取得理想效果,其表现与纯稠密模型无异,这个方案完全可行
另一个解决方案,正如我们在 DeepSeek MoE 论文中所见:

就是单纯使用海量数据,若出现过拟合问题,我们可调用海量监督微调数据来解决,把这些数据统统用上就行。以 DeepSeek-MoE 为例,该模型使用了 140 万条训练样本,这样或许就不必过分担心过拟合问题了
最后要介绍的是业界已验证有效的技巧---模型升级循环(upcycling)
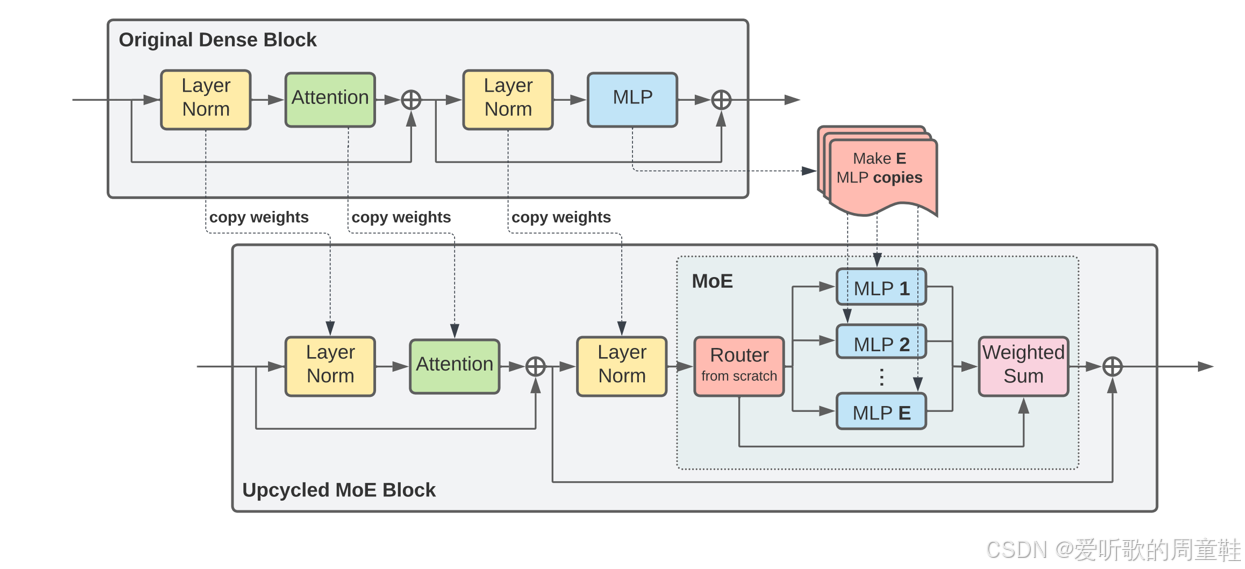
这个思路是直接采用一个稠密模型,如上图所示,然后取出其中的 MLP 部分,复制出多个相同的副本,再对这些副本进行适当扰动,同时初始化一个全新的路由模块,这样就能模拟出混合专家模型的效果
然后从这个状态开始进行训练,直接基于稠密模型初始化混合专家模型,这种技巧可称为模型升级循环(upcycling)。若能成功实现这种方法,将成为获取混合专家模型最具成本效益的途径
混合专家模型在推理阶段优势显著,因为并非所有 MLP 在推理时都会被激活,因此无需训练超大参数模型就能实际获得等效于更大参数规模的模型能力
已有不少研究者成功实现了这一目标,MiniCPM(这个模型在后续关于缩放定律的讲座中还会提及)是中国团队研发的开源大语言模型,其核心目标是打造高性能的小型语言模型,该团队成功实现了将稠密模型升级改造为混合专家模型的技术突破
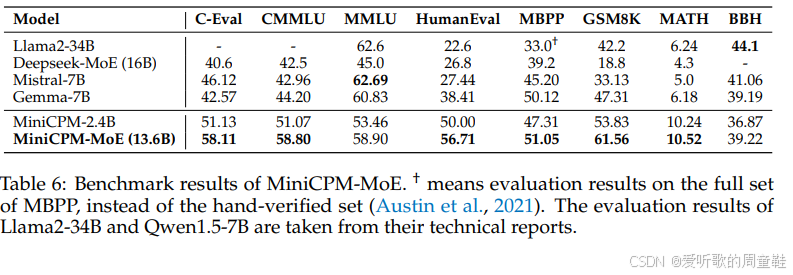
从上表的最后两行数据可以明显看出,将稠密模型转换为混合专家架构后其性能指标获得了显著提升
在本次讲座开始时,我们提到的 Qwen,他们早期尝试混合专家模型时,曾采用过一个密集模型并在此基础上改造升级为 MoE 架构。与当时较小规模的模型相比,他们获得了相当显著的性能提升,如下表所示:
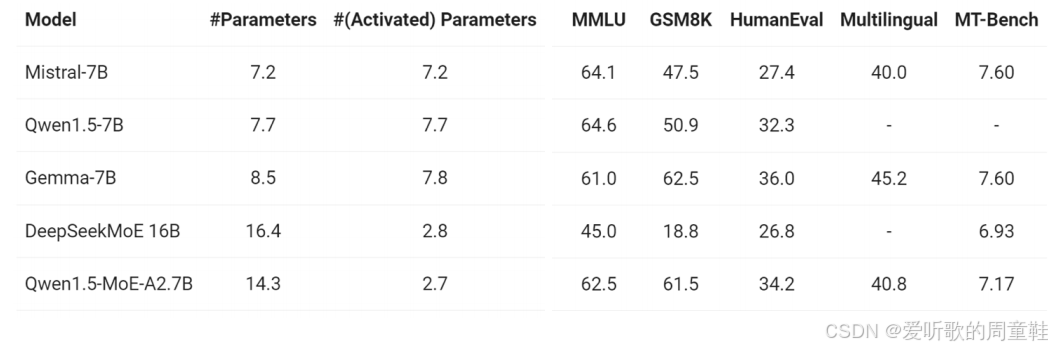
他们仅用 27 亿参数的激活模型就达到了与 70 亿参数模型相当的性能水平
6. DeepSeek MoE v1-v2-v3
最后,我们来完整梳理一遍 DeepSeek 的 MoE 架构设计,首先需要明确的是,我们要深入理解 DeepSeek-V3 的架构设计及其所有创新改进,它堪称当代高性能开源系统的典范之作。同时希望大家能注意到,架构设计往往保持着相当的稳定性,
DeepSeek v1 或者说 DeepSeek MoE v2 架构其实并不算新颖,这套架构问世大约也就一年半到两年左右的时间,但他们在当时就已经将这套架构打磨得相当完善了,让我们来看看他们从最初尝试到最终大规模训练过程中做了哪些关键改进
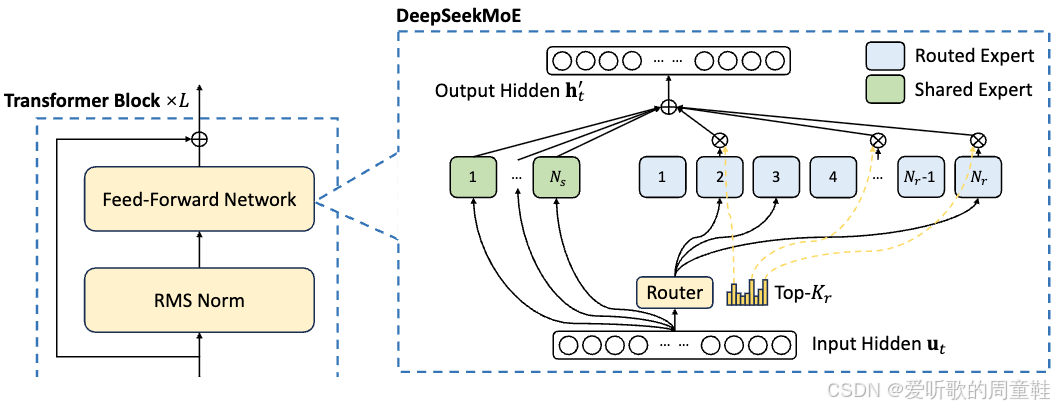
上图是最初的起点,这就是 DeepSeek 混合专家模型,我们将其称为 v1 版本,这是一个总参数量达 160 亿的模型,其中实际激活参数量为 28 亿,该架构采用 2 个共享专家加 64 个细分领域专家的设计,每次仅激活其中 4 个细分领域专家模块,或者说每次大约会激活总共 6 个专家模块
路由机制采用最经典的 Top-K 路由机制:
h t ′ = u t + ∑ i = 1 N s FFN i ( s ) ( u t ) + ∑ i = 1 N r g i , t FFN i ( r ) ( u t ) , g i , t = { s i , t , if s i , t ∈ Topk ( { s j , t ∣ 1 ≤ j ≤ N r } , K r ) , 0 , otherwise, s i , t = Softmax i ( u t T e i ) . \begin{align*} \mathbf{h}'{t} &= \mathbf{u}{t} +\sum_{i=1}^{N_s} \text{FFN}^{(s)}{i}(\mathbf{u}{t})+\sum_{i=1}^{N_r} g_{i,t} \, \text{FFN}^{(r)}{i}(\mathbf{u}{t}), \\8pt g_{i,t} &= \begin{cases} s_{i,t}, & \text{if } s_{i,t} \in \text{Topk}(\{ s_{j,t} \mid 1 \le j \le N_r \}, K_r), \\6pt 0, & \text{otherwise,} \end{cases} \\8pt s_{i,t} &= \text{Softmax}i(\mathbf{u}{t}^{T} \mathbf{e}_{i}). \end{align*} ht′gi,tsi,t=ut+i=1∑NsFFNi(s)(ut)+i=1∑Nrgi,tFFNi(r)(ut),=⎩ ⎨ ⎧si,t,0,if si,t∈Topk({sj,t∣1≤j≤Nr},Kr),otherwise,=Softmaxi(utTei).
先对底层进行 softmax 归一化操作,再执行前 L 项选择操作。在训练阶段,系统仅需添加下面这个辅助损失平衡项:
L ExpBal = α 1 ∑ i = 1 N ′ f i P i , f i = N ′ K ′ T ∑ t = 1 T 1 ( Token t selects Expert i ) , P i = 1 T ∑ t = 1 T s i , t . \begin{align*} \mathcal{L}{\text{ExpBal}} &= \alpha_1 \sum{i=1}^{N'} f_i P_i, \\8pt f_i &= \frac{N'}{K'T} \sum_{t=1}^{T} \mathbf{1}(\text{Token } t \text{ selects Expert } i), \\8pt P_i &= \frac{1}{T} \sum_{t=1}^{T} s_{i,t}. \end{align*} LExpBalfiPi=α1i=1∑N′fiPi,=K′TN′t=1∑T1(Token t selects Expert i),=T1t=1∑Tsi,t.
它既包含专家级的平衡参数,也涵盖设备级的平衡系数,以上就是第一代架构的核心设计,希望你还记得之前讲解的这些要点。
随后他们见证了混合专家模型展现出的卓越成效,需要补充说明的是,DeepSeek 最初采用的是稠密模型架构,随后他们转向了混合专家模型架构,而这款混合专家模型的表现确实令人惊艳。因此在开发第二代架构时,他们直接采用了混合专家模型方案,如今,这个 2360 亿参数的模型中,实际激活的参数量达到 210 亿,因此需要极大的内存容量,但运行该模型推理所需的浮点运算量其实并不算高。
DeepSeek MoE v2 架构与 v1 完全一致,除了激活专家数量的调整外,整个架构确实原封未动。当前架构中虽然引入了一些新特性,但整体改动幅度依然保持克制,因此顶层的专家选择机制(Top-K)保持不变
大家可能一开始就会想问:细粒度专家划分存在什么缺陷?为什么不能采用更细粒度的专家划分方案?比如设置 1024 个或 2046 个专家?问题在于:当专家划分过于精细且需要激活大量专家时,路由机制将面临巨大压力,因此通信开销可能会急剧增加。当专家分布过于分散时,可能需要将大量 token 分发到众多计算设备上
但他们巧妙地引入了一个非常精妙的改进方案:

他们提出的精妙方案在于:不再简单地为每个批次选择前 K 个专家进行路由,这种原始方法可能导致 token 被分散到过多设备上,他们的创新做法是:首先筛选出前 M 个最优设备,具体实现方法是:先执行常规的评分计算,但会预先将可选设备范围限定在前 M 个最优设备子集中,在选定设备组后,再针对每个设备内的 token 进行局部前 K 个专家筛选
通过这种方式,我们实现了设备选择的精准控制,这种设计有效控制了跨设备通信开销,能显著提升模型在大规模训练时的效率
当训练参数规模达到 2360 亿时,另一个体现超大规模系统设计考虑的关键创新是引入了通信均衡损失函数:

从专家模块的工作机制来看,本质上就是处理输入与输出的过程,输入环节接收的是传入的 token,然后将其路由至对应的专家模块,而输出环节则需要将处理后的 token 准确送回其所属位置。若某个批次数据原本属于当前设备处理,最终必须将其返回至原始设备,因此我们需要同时考量输入和输出两端的通信开销
因此,他们额外引入了平衡损失机制,旨在同时优化输出端的通信开销,而不仅限于输入端,这一点值得留意。可以看出他们在系统设计的各个环节都力求周全,这种对细节的考究令人印象深刻
最后我们来看重磅的 DeepSeek-V3,其参数量高达 6710 亿,其中活跃参数为 370 亿,混合专家架构本身依旧未发生变动,不过他们确实做了几处调整:
h t ′ = u t + ∑ i = 1 N s FFN i ( s ) ( u t ) + ∑ i = 1 N r g i , t FFN i ( r ) ( u t ) , g i , t = g i , t ′ ∑ j = 1 N r g j , t ′ , g i , t ′ = { s i , t , if s i , t ∈ Topk ( { s j , t ∣ 1 ≤ j ≤ N r } , K r ) , 0 , otherwise, s i , t = Sigmoid ( u t T e i ) . \begin{align*} \mathbf{h}'{t} &= \mathbf{u}{t}+ \sum_{i=1}^{N_s} \text{FFN}^{(s)}{i}(\mathbf{u}{t})+ \sum_{i=1}^{N_r} g_{i,t} \, \text{FFN}^{(r)}{i}(\mathbf{u}{t}), \\8pt g_{i,t} &= \frac{g'{i,t}}{\sum{j=1}^{N_r} g'{j,t}}, \\8pt g'{i,t} &= \begin{cases} s_{i,t}, & \text{if } s_{i,t} \in \text{Topk}(\{ s_{j,t} \mid 1 \le j \le N_r \}, K_r), \\6pt 0, & \text{otherwise,} \end{cases} \\8pt s_{i,t} &= \text{Sigmoid}(\mathbf{u}{t}^{T} \mathbf{e}{i}). \end{align*} ht′gi,tgi,t′si,t=ut+i=1∑NsFFNi(s)(ut)+i=1∑Nrgi,tFFNi(r)(ut),=∑j=1Nrgj,t′gi,t′,=⎩ ⎨ ⎧si,t,0,if si,t∈Topk({sj,t∣1≤j≤Nr},Kr),otherwise,=Sigmoid(utTei).
他们将门控机制归一化为单位值,把 softmax 归一化操作提前,但他们并未对门控决策进行指数化处理,他们实际采用的是 sigmoid 函数,相比 softmax 这种运算更柔和且表现更稳定,但从概念上讲,这依然等同于 Top-K 路由机制决策
在损失函数方面,他们采用了下面这种无辅助损失的技巧:
g i , t ′ = { s i , t , if s i , t + b i ∈ Topk ( { s j , t + b j ∣ 1 ≤ j ≤ N r } , K r ) , 0 , otherwise. g'{i,t} = \begin{cases} s{i,t}, & \text{if } s_{i,t} + b_i \in \text{Topk}(\{ s_{j,t} + b_j \mid 1 \le j \le N_r \}, K_r), \\6pt 0, & \text{otherwise.} \end{cases} gi,t′=⎩ ⎨ ⎧si,t,0,if si,t+bi∈Topk({sj,t+bj∣1≤j≤Nr},Kr),otherwise.
通过专家负载情况动态增减 b i b_i bi 的值,此外他们还引入了序列级辅助损失函数,补充一点背景说明:为什么需要在单个序列上平衡不同专家负载呢?关键在于:在训练阶段不使用序列级平衡损失函数其实并无大碍,但在推理阶段,用户可能会输入超出训练分布范围的异常序列,这可能导致某些专家模块出现过载现象,因为在推理过程中,系统无法预先控制输入序列的分布特性,因此需要构建更强大的单序列级平衡机制,而非仅依赖批量级的整体平衡
在讲座最后,我们将简要介绍 DeepSeek 的非 MoE 架构部分,因为关于 DeepSeek-V3 的核心内容,我们已经讲解得差不多里了,既然说到这里,索性把 DeepSeek-V3 剩余得技术要点也梳理一遍,好让大家对这个系统有完整的认识
他们在注意力机制方面做了项巧妙的优化,名为 MLA(多头潜在注意力)的创新设计:
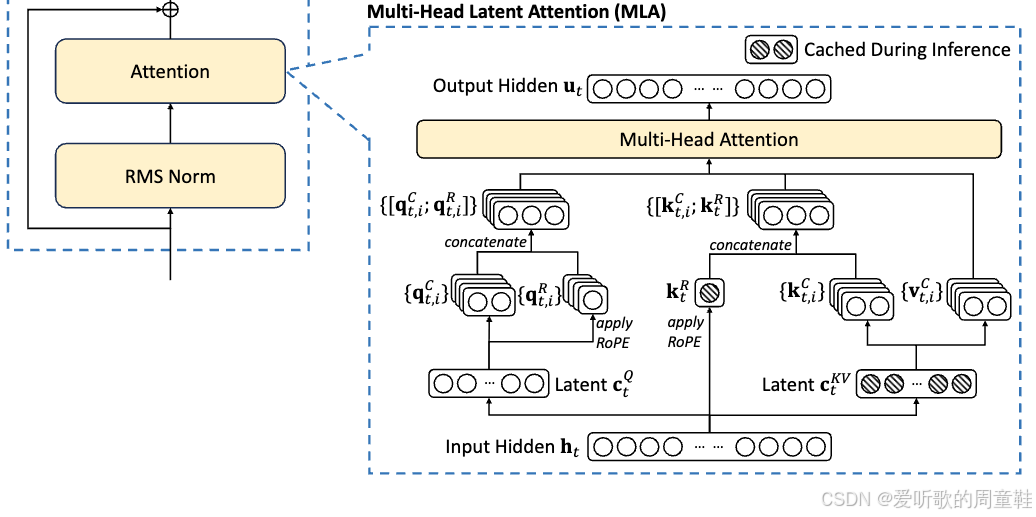
其实要理解这个机制并不是很困难,大家已经掌握了所有必备的基础知识,在上次讲座最后,我们已经讲解过分组查询注意力(GQA)和传统多头注意力(MHA)的架构原理,这些都属于推理阶段的优化手段,核心目的是压缩 KV Cache 的存储规模
DeepSeek 团队另辟蹊径,采用了一种全新的优化思路,他们没有减少注意力头的数量,而是 将这些头投影到更低维度的空间 ,假设当前输入为 h t \mathbf{h}_t ht,不同于直接从 h t \mathbf{h}_t ht 生成键值对 k 和 v,这里会先生成一个低维度的中间表征 c \mathbf{c} c,你可以将其视为 h \mathbf{h} h 的压缩版本,这个 c \mathbf{c} c 的维度更小,更易于缓存,我们只需缓存这种 c \mathbf{c} c 值即可
当需要获取 k 和 v 时,从概念上讲,可以通过这个 KV Cache 进行上投影重构,随后便可与查询向量 q 进行内积运算。由此可见,仅需存储低维的 c \mathbf{c} c 而非高维的 h t \mathbf{h}_t ht 时,KV Cache 的空间效率讲显著提升,这正是该方案的核心思想
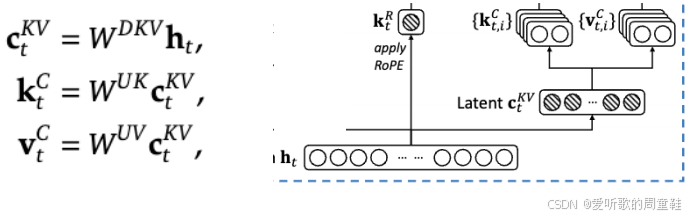
我们取当前时刻的隐状态 h t \mathbf{h}_t ht 将其投影至低维空间得到 c \mathbf{c} c,随后讲这个低维表示 c \mathbf{c} c 重新上投影,还原为键向量 k 和值向量 v。若 c \mathbf{c} c 的维度足够小便实现了 KV Cache 的高效压缩,这确实是个好方法。从计算量(FLOPs)的角度来看,你可能会觉得这个方法不够理想,毕竟需要额外计算矩阵乘法 W U K W^{UK} WUK,原本并不需要这个矩阵,这相当于要额外承担一次矩阵乘法的计算开销
但这里巧妙之处在于,当计算注意力机制中的 k ⋅ q k \cdot q k⋅q 内积时,查询向量 q q q 本身也经过投影矩阵 Q 的变换,因此这里的诀窍是可以将 W U K W^{UK} WUK 和 Q 合并为单一矩阵,这样就没有产生额外的矩阵乘法运算,我们只是将这个新矩阵乘法合并到了原有的运算中,这本质就是矩阵乘法的结合律特性,我们完全可以将二者合并计算
他们还对查询向量进行压缩以节省训练时的内存占用,但实际上这个优化并非绝对必要,因为它完全不会与 KV Cache 产生交互
这里还有个值得注意的精妙之处,最初提到的那个优化技巧实际上与旋转位置编码 RoPE 并不兼容,原因在于旋转位置编码矩阵的处理机制---本质上涉及查询向量 q 和键向量 k 的交互
Without RoPE − ⟨ Q , K ⟩ = ⟨ h W Q , W U K c t K V ⟩ = ⟨ h W Q W U K , c t K V ⟩ With RoPE − ⟨ Q R q , R k K ⟩ = ⟨ h W Q R q , R k W U K c t K V ⟩ = ⟨ h W Q R q R k W U K , c t K V ⟩ \text{Without RoPE} - \langle Q, K \rangle = \langle h W^Q, W^{UK} c_t^{KV} \rangle = \langle h {\color{red}{W^Q W^{UK}}}, c_t^{KV} \rangle \\ \text{With RoPE} - \langle Q R_q, R_k K \rangle = \langle h W^Q R_q, R_k W^{UK} c_t^{KV} \rangle = \langle h {\color{red}{W^Q R_q R_k W^{UK}}}, c_t^{KV} \rangle Without RoPE−⟨Q,K⟩=⟨hWQ,WUKctKV⟩=⟨hWQWUK,ctKV⟩With RoPE−⟨QRq,RkK⟩=⟨hWQRq,RkWUKctKV⟩=⟨hWQRqRkWUK,ctKV⟩
旋转位置编码会通过旋转矩阵 R q R_q Rq 和 R k R_k Rk 分别对查询向量 q 和键向量 k 进行旋转变换,但若实施这种旋转操作 R q R_q Rq 和 R k R_k Rk 就会位于查询投影层与潜在向量上投影矩阵之间,由于这些矩阵乘法无法重新排序,旋转位置编码反而会形成阻碍,他们最终采用的解决方案是:仅在非压缩维度上应用旋转位置编码,这算是题外话了
他们做的另一项改进是对损失函数做了微调,引入名为多 token 预测(MTP)的机制,通过并行方式同时预测多个 token:
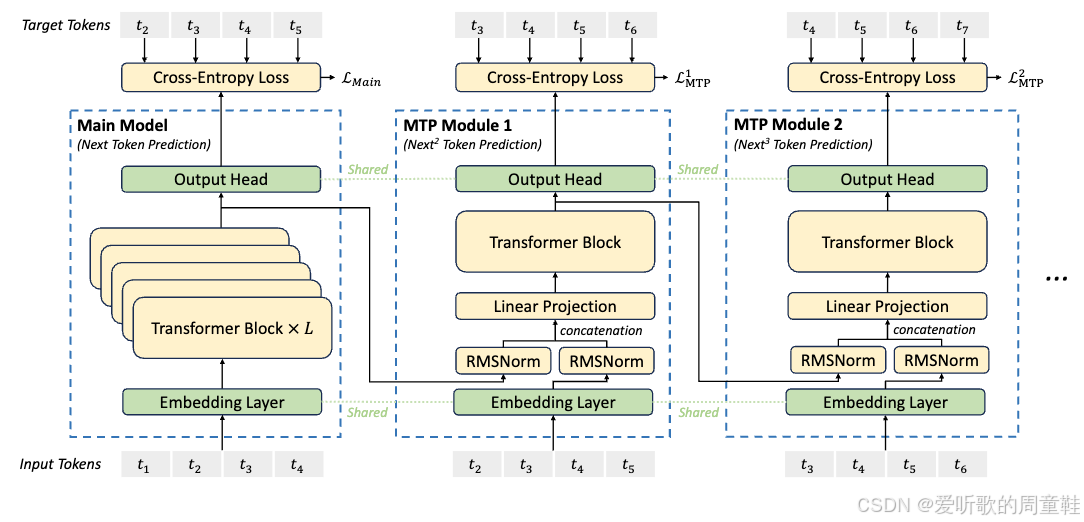
通常的处理流程是:模型接收输入数据后,将输入序列整体左移一位,这样模型就能预测下一个位置的 token,随后 Transformer 模型会同时预测所有这些目标位置的 token,这是标准 Transformer 的训练方式。
但在执行最终预测前,我们可以提取模型隐藏层的状态,将其输入一个极简的单层 Transformer 结构,这个小模型就能预测下一个位置的 token。现在,模型不仅能预测下一个 token,还能预测未来两个位置的 token,而这仅需一个轻量级的小模型就能实现
不过有个令人遗憾的事实:他们目前的多 token 预测(MTP)实际上仅支持单 token,尽管他们绘制了看似能实现多 token 预测的复杂图,但实际上仅实现了单 token 预测功能
7. MoE summary
混合专家模型 MoE 已成为构建和部署高性能、大规模系统的核心技术,它们充分利用了参数稀疏性的优势,无需时刻调用全部参数,离散路由机制才是其真正的核心难题,这正是 MoE 未能迅速普及的关键原因之一
优化这种 Top-K 路由决策机制确实令人望而生畏,但启发式方法却意外地行之有效,事实就是如此。目前大量实证研究表明,在计算资源受限的场景下,采用混合专家模型确实是明智之选,这种架构性价比极高,值得采用,绝对值得深入学习
OK,以上就是本次讲座的全部内容了
结语
第四讲我们主要讲解了 Mixtrue of experts(MoEs) 混合专家模型,混合专家架构的本质就是通过某种路由机制进行分配,然后连接不同的 MLP 模块。
MoE 难点在于路由决策机制的优化问题,决策本身是个离散问题,不可微分。路由决策主要存在 Token chooses expert、Expert chooses token 以及 Global routing via optimization 三种实现方式,当前绝大多数 MoE 模型采用的都是 token 选择 Top-K 路由机制。
MoE 模型训练的挑战性在于需要保持稀疏路由决策,常见的方法包括强化学习、随机策略进行搜索以及添加平衡损失项等启发式方法,其中损失平衡机制被绝大多数 MoE 模型所采用,通过 f ⋅ P f\cdot P f⋅P 的优化技巧来实现不同计算单元间的 token 负载均衡,避免模型陷入所有 token 永远只被路由到同一个专家的局部最优困境。
MoE 在训练过程中还存在一些稳定性问题,首先路由机制中的 softmax 本身的不稳定性,这可以通过 z-loss 来解决。此外在 MoE 模型微调过程中容易出现严重的过拟合现象,业界验证有效的技巧是模型循环升级。
最后我们还完整梳理了一遍 DeepSeek 的 MoE 架构设计,并讲解了非 MoE 的创新设计部分包括 MLA、MTP 等。
整个讲解非常通俗易懂,大家感兴趣的可以看看
下节课我们将深入探讨 GPU,敬请期待🤗