一、抛砖引玉
1. 被需要
当大语言模型(LLM)从 "对话工具" 进化为 "应用引擎",开发者们面临的核心挑战早已不是 "如何调用模型",而是 "如何让模型连接数据、协同工具、落地成可复用的产品"。在这场从 "模型能力" 到 "应用价值" 的跨越中,LangChain 作为 "AI 应用开发三剑客" 的核心成员,正以 "连接器" 与 "工具箱" 的双重身份,撑起 LLM 应用开发的技术基石。
那么,这款被称作 LLM 应用 "基础设施" 的框架,究竟凭什么成为三剑客的核心?它的底层逻辑如何解决 AI 开发的痛点?今天我们就深入拆解 LangChain 的核心能力,看它如何为 LLM 应用搭建起从 "想法" 到 "产品" 的桥梁。
2. 应用场景
LangChain 提供了灵活工具链,高效连接了 LLM 与外部资源(计算、数据),助力构建能理解和生成自然语言的智能应用。其核心是打破模型 "信息孤岛",让模型可调用工具、融合私有数据。
以下是 LangChain 的典型使用场景:
- 聊天机器人
- 代码分析
- 工作流自动化
- 个人助理
- 内容创作
- 教育赋能,学习辅助
- 数据分析以及报告
- 语言翻译,纠错
- 情感分析,市场分析
- 私有知识库问答
- ...
3. 价值方向
LLM 从核心能力出发,可在效率提升、体验跨越、问题解决、产业赋能 为我们提供价值,覆盖个人、企业到行业的多维度需求(满满的获得感)。
- 效率提升:简化重复与复杂工作
- 体验跨越:优化人机交互与个性化服务
- 问题解决:应对复杂与专业领域需求
- 产业赋能:推动各行业数字化与智能化升级
而这一切的一切,都要从 LangChain 开始说起!
二、牛刀小试
1. 话不多说,直接撸
python
# pip install langchain_openai
from langchain_openai import ChatOpenAI
# 从模型厂商获取的配置信息
ai_config = {
"model": "deepseek-r1-distill-qwen-7b-250120",
"url": "https://ark.cn-beijing.volces.com/api/v3/chat/completions",
"key": "3b396c47-aace-xxxx-xxxx-99739adb4808"
}
"""
初始化模型
@params base_url 模型地址
@params api_key 访问模型的 API_KEY
@params temperature 温度(控制生成文本 "随机性" 与 "确定性" 的核心参数,范围 0 -> 1,趋近 0 模型输出 更精准;趋近于 1,更泛化,创造力更强)
"""
llm = ChatOpenAI(
base_url=ai_config['url'].replace('chat/completions', ''),
api_key=ai_config['key'],
model=ai_config['model'],
temperature=0.3
)
res = llm.invoke("你好,你是谁?你能为我做什么?")
print(res.content)
--------------------封装 create_llm --------------------
from ai_configs import ai_configs # 封装的配置文件
def create_llm(model_name='deepseek', temperature=0.3):
ai_config = ai_configs[model_name]
if ai_config is None:
raise Exception('Unknown model_name', model_name)
return ChatOpenAI(
base_url=ai_config['url'].replace('chat/completions', ''),
api_key=ai_config['key'],
model=ai_config['model'],
temperature=temperature
)上面这段代码只是简单创建了个大模型,并使用。如果我们需要约束大模型怎么办?回答:加入提示词(简单又不简单)
2. 提示词 + 模型 + 输出解析器
python
# pip install langchain_core
from langchain_core.prompts import ChatPromptTemplate
from create_llm import create_llm
from langchain_core.output_parsers import StrOutputParser
# 初始化模型
llm = create_llm("deepseek")
# 提示词 {user_content} 为占位符
prompt = ChatPromptTemplate.from_template("请将用户的内容翻译为俄语:{user_content}")
# 文本解析器,将大模型返回的内容解析为字符串
txt_parser = StrOutputParser()
# 不用文本解析器
res = llm.invoke(prompt.invoke({"user_content": "你好,你是谁?你能为我做什么?"}))
print(res.content)
# 文本解析器
content = txt_parse.invoke(llm.invoke(prompt.invoke({"user_content": "你好,你是谁?你能为我做什么?"})))
print(content)
# 完全体 LCEL(LangChain Expression Language)是LangChain框架定义的一种声明式编程语言
_chain = prompt | llm | txt_parser
print(_chain.invoke({"user_content": "你好,你是谁?你能为我做什么?"}))LCEL 链式表达式简化了复杂的流出构建、提升了代码可读性与可维护性、增强了组件复用性,让 llm 应用开发更高效、灵活。而且LCEL 原生支持并行执行 (RunnableParallel)、条件分支 (RunnableBranch)等复杂逻辑,无需手动管理异步或分支判断。
数据流转示意图:

三、强大的 Runnable
1. 什么是 Runnable
在 LangChain 生态中,Runnable 是 LCEL(LangChain Expression Language)的核心接口,是所有可组合组件的 "通用语言"。它定义了一套标准化的方法,让不同组件(如模型、提示词、工具、解析器等)能够无缝拼接、协同工作,是实现 "组件化编排" 的基础。
简单说:Runnable 让所有组件 "说同一种语言",实现了 "即插即用" 的组合能力。
2. RunnableLambda
RunnableLambda 是 LangChain 中一个强大的工具,允许将普通的 Python 函数转换为 LangChain 可运行的组件,从而可以无缝地集成到链式调用中。
Runnable 核心:
- 统一 API:所有 Runnable 对象都实现了一组标准方法(如 invoke, batch, stream,ainvoke,abatch,astream),无论底层是 LLM、工具、函数还是其他链。
- 可组合:通过 |(管道符)、+ 等操作符或显式组合器(如 RunnableParallel)实现嵌套组合,形成 DAG(有向无环图)。
- 惰性执行:组合的链在调用 invoke() 或 stream() 时才实际运行,支持动态调整。
2.1 使用场景
- 数据预处理:在将输入传递给LLM之前进行格式化或清理
- 结果后处理:对LLM的输出进行解析或转换
- 条件逻辑:基于某些条件决定流程分支
- 自定义计算:执行特定领域的计算或转换
- 集成外部系统:与数据库、API等外部系统交互
2.2 🌰
python
from langchain.schema.runnable import RunnableLambda
# 接收一个需要处理的参数
def func(chain_input: dict):
# 构造并返回结果字典:包含原始输入和转大写的数据
return {"chain_input": chain_input, upper_txt: chain_input.content.upper()}
# 将自定义函数包装为LangChain的RunnableLambda对象,使其可作为链组件使用
# 包装后可支持 Runnable 对象的所有接口
simple_chain = RunnableLambda(func)
# 调用链的invoke方法,传入输入参数并打印结果
print(simple_chain.invoke({"content": "hello, world"})) # {"chain_input": {"content": "hello, world"}, upper_txt: "HELLO, WORLD"}3. RunnableParallel
在 LangChain 中,RunnableParallel 是一个核心组件,用于并行执行多个 Runnable 任务 ,并将各任务的结果聚合为一个字典(dict)返回。它的设计目标是提高多任务处理的效率,避免串行执行带来的时间累积,尤其适合需要同时调用多个工具、模型或处理步骤的场景。
3.1 应用场景
- 需要同时调用多个工具(如同时查询天气、获取新闻)。
- 对同一个输入进行多维度处理(如同时生成摘要、提取关键词、翻译)。
- 并行获取多个数据源的信息,再汇总处理。
3.2 🌰
python
from create_llm import create_llm
from langchain.schema.runnable import RunnableParallel, RunnableLambda
from langchain_core.output_parsers import StrOutputParser
llm = create_llm("deepseek")
# 文本解析器,将大模型返回的内容解析为字符串
txt_parser = StrOutputParser()
_chain = llm | txt_parser
# 定义两个子任务(均为 Runnable)
summarize = RunnableLambda(
lambda text: _chain.invoke(f"总结以下文本:{text}")
)
extract_keywords = RunnableLambda(
lambda text: _chain.invoke(f"提取以下文本的关键词:{text}")
)
# 用 RunnableParallel 组合任务,指定每个任务的键(用于聚合结果)
parallel_chain = RunnableParallel(
summary=summarize,
keywords=extract_keywords
)
# 执行并行任务(输入会同时传递给所有子任务)
text = "LangChain 是一个用于构建 LLM 应用的框架,支持多种工具集成和流程编排。"
result = parallel_chain.invoke(text)
print(result)
# 输出:
# {
# "summary": "LangChain 是一个支持工具集成和流程编排的 LLM 应用构建框架。",
# "keywords": "LangChain, LLM 应用, 工具集成, 流程编排"
# }3.3 运行实例

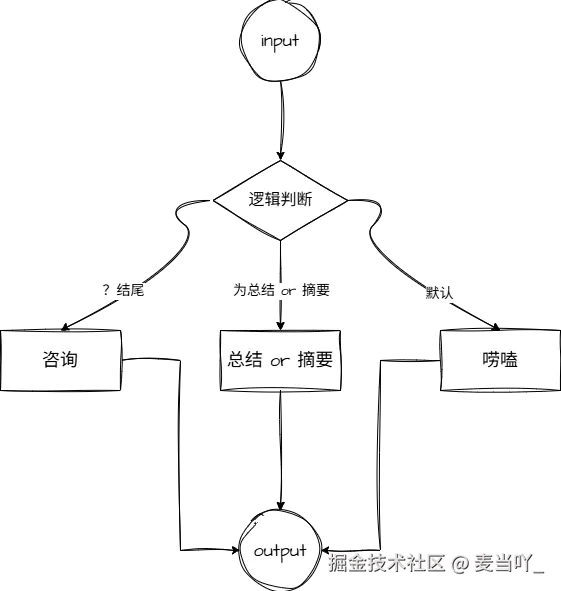
4. RunnableBranch
在 LangChain 中,RunnableBranch 是用于条件分支执行 的组件,它允许根据输入内容动态选择不同的 Runnable 任务执行。简单来说,它类似编程中的 if-elif-else 逻辑,能根据预设的条件判断输入,然后路由到对应的处理流程。
4.1 应用场景
- 根据用户问题的类型(如 "事实查询""创作需求""闲聊")路由到不同的处理链。
- 对输入内容进行过滤(如判断是否包含敏感信息,再决定拒绝或处理)。
- 基于输入的格式(如文本、JSON、指令)选择对应的解析或处理逻辑。
4.2 🌰
python
from create_llm import create_llm
from langchain.schema.runnable import RunnableBranch, RunnableLambda
from langchain_core.output_parsers import StrOutputParser
llm = create_llm("deepseek")
# 文本解析器,将大模型返回的内容解析为字符串
txt_parser = StrOutputParser()
_chain = llm | txt_parser
# 定义三个子任务
qa_task = RunnableLambda(
lambda question: _chain.invoke((f"回答问题:{question}")
)
summary_task = RunnableLambda(
lambda text: _chain.invoke((f"总结这段文字:{text}")
)
default_chat = RunnableLambda(
lambda input: _chain.invoke((f"闲聊回应:{input}")
)
# 定义条件(判断输入属于哪种类型)
def is_question(input_str):
return input_str.endswith("?") # 以问号结尾的视为问题
def is_summary_request(input_str):
return "总结" in input_str or "摘要" in input_str # 包含"总结"或"摘要"的视为摘要需求
# 构建 RunnableBranch:条件-任务对 + 默认任务
branch = RunnableBranch(
(is_question, qa_task), # 若满足 is_question,执行 qa_task
(is_summary_request, summary_task), # 若满足 is_summary_request,执行 summary_task
default_chat # 所有条件不满足时,执行默认任务
)
# 测试不同输入
print(branch.invoke("LangChain 是什么?")) # 匹配 is_question → 执行问答
# 输出:LangChain 是一个用于构建大语言模型(LLM)应用的框架...
print(branch.invoke("请总结这段文字:LangChain 支持多种工具集成和流程编排。")) # 匹配 is_summary_request → 执行摘要
# 输出:这段文字指出 LangChain 支持工具集成和流程编排。
print(branch.invoke("今天天气不错")) # 不匹配任何条件 → 执行默认闲聊
# 输出:闲聊回应:今天天气确实不错,适合外出活动~4.3 运行实例
5. RunnableWithFallbacks
在 LangChain 中,RunnableWithFallbacks 是用于错误处理和降级策略 的组件,它允许为一个主 Runnable 任务设置备选方案(fallbacks)。当主任务执行失败(如抛出异常、超时、返回无效结果等)时,会自动尝试执行备选任务,确保流程的稳定性和容错性。
5.1 应用场景
- 模型调用容错:当主模型(如 GPT-4)调用失败时,降级到备选模型(如 GPT-3.5-turbo)。
- 工具调用降级:调用外部工具(如数据库查询、API 接口)失败时,返回默认结果或使用本地缓存数据。
- 格式校验容错:当主任务返回的结果格式不符合要求时,用备选任务进行修正或重新生成。
- 网络稳定性保障:在网络波动场景下,通过备选方案避免流程中断。
5.2 🌰
python
from create_llm import create_llm
from langchain.schema.runnable import RunnableWithFallbacks
from langchain.prompts import ChatPromptTemplate
# 定义主任务(可能不稳定的模型)
main_model = create_llm(model_name="gpt-4") # 假设该模型可能因负载过高失败
main_prompt = ChatPromptTemplate.from_template("用复杂语言回答:{question}")
main_chain = main_prompt | main_model
# 定义备选任务(更稳定的模型)
fallback_model = create_llm(model_name="deepseek") # 备选模型
fallback_prompt = ChatPromptTemplate.from_template("用简洁语言回答:{question}")
fallback_chain = fallback_prompt | fallback_model
# 定义最终的容错链条:主任务 + 备选任务
chain_with_fallback = RunnableWithFallbacks(
runnable=main_chain, # 主任务
fallbacks=[fallback_chain] # 备选任务列表(可多个,按顺序尝试)
)
# 执行任务(若主模型失败,自动触发备选模型)
result = chain_with_fallback.invoke({"question": "什么是 LangChain?"})
print(result.content)5.3 如果需要自定义异常呢?
- 默认情况下,只要主任务执行过程中抛出异常(如网络错误、模型调用失败),就会触发备选任务。
- 若需要基于返回结果内容 判断是否失败(如结果为空、格式错误),可结合
RunnableLambda自定义异常抛出逻辑:
python
# 自定义结果校验:若结果长度过短,视为失败
def validate_result(result):
if len(result.content) < 10:
raise ValueError("结果过短,视为失败")
return result
# 主任务添加结果校验
main_chain_with_validation = main_chain | RunnableLambda(validate_result)
# 容错链条:主任务(带校验)+ 备选
chain_with_fallback = RunnableWithFallbacks(
runnable=main_chain_with_validation,
fallbacks=[fallback_chain]
)6. RunnableRetry
在 LangChain 中,RunnableRetry 是用于任务重试机制 的组件,它允许为一个 Runnable 任务设置重试策略 ------ 当任务执行失败(如抛出异常)时,按照预设的条件(如重试次数、延迟时间、触发重试的异常类型)自动重试,直到任务成功或达到重试上限。
6.1 应用场景
- 网络不稳定场景:调用外部 API(如 LLM 接口、数据库、第三方工具)时,因网络波动导致的临时失败(如超时、连接中断),通过重试恢复。
- 资源竞争场景:访问共享资源(如分布式锁、限流接口)时,因瞬时负载过高导致的失败,通过延迟重试避开峰值。
- 偶发错误处理:对于非系统性的偶发错误(如模型返回格式临时异常),重试可能解决问题。
6.2 🌰
python
# pip install tenacity
from create_llm import create_llm
from langchain.schema.runnable import RunnableRetry
from langchain.prompts import ChatPromptTemplate
from tenacity import stop_after_attempt, wait_exponential # 重试策略依赖 tenacity 库
# 定义主任务(可能偶发失败的模型调用)
prompt = ChatPromptTemplate.from_template("回答问题:{question}")
model = create_llm(model_name="gpt-3.5-turbo")
main_chain = prompt | model
# 定义重试策略:最多重试 3 次,每次重试间隔按指数增长(1秒、2秒、4秒...)
retry_strategy = {
"stop": stop_after_attempt(3), # 最多重试 3 次(共执行 4 次:1次初始 + 3次重试)
"wait": wait_exponential(multiplier=1, min=1, max=10), # 指数退避:1s, 2s, 4s(最大10s)
"reraise": True # 所有重试失败后,抛出最后一次异常
}
# 用 RunnableRetry 包裹主任务,应用重试策略
chain_with_retry = RunnableRetry(
runnable=main_chain,
**retry_strategy
)
# 执行任务(若失败,自动按策略重试)
try:
result = chain_with_retry.invoke({"question": "什么是 LangChain?"})
print(result.content)
except Exception as e:
print(f"所有重试失败:{e}")6.3 一些小细节
- 异步支持 :支持
ainvoke方法,适配异步任务的重试需求。 - 避免滥用 :重试仅适用于临时可恢复的错误 (如网络波动),对于系统性错误(如 API 密钥无效),重试会浪费资源,需通过
retry参数过滤。
7. 自定义 Runnable
在 LangChain 中,自定义 Runnable 可以通过继承 Runnable 抽象类并实现核心方法来完成。
7.1 应用场景
我们需要一个自定义 Runnable,功能是:
- 接收文本输入,验证输入是否为空;
- 对文本进行处理(如转为大写 + 拼接后缀);
- 支持同步(
invoke)和异步(ainvoke)执行; - 可与其他
Runnable(如 LLM)组合使用。
7.2 🌰
python
from langchain.schema.runnable import Runnable, Input, Output
from typing import Generic, TypeVar, Any
import asyncio
# 定义输入输出类型变量(用于类型提示)
T = TypeVar("T")
class CtmRunnable(Runnable[str, str], Generic[T]):
"""自定义文本处理 Runnable:转为大写并添加后缀"""
def __init__(self, suffix: str = "_PROCESSED"):
self.suffix = suffix # 可配置的后缀参数
def invoke(self, input: str, config: Any = None) -> str:
"""同步执行:验证输入 + 处理文本"""
# 1. 输入验证
if not input or input.strip() == "":
raise ValueError("输入文本不能为空!")
# 2. 文本处理(转为大写 + 拼接后缀)
processed = input.strip().upper() + self.suffix
return processed
async def ainvoke(self, input: str, config: Any = None) -> str:
"""异步执行:模拟异步处理(如调用异步API)"""
# 1. 输入验证(与同步逻辑一致)
if not input or input.strip() == "":
raise ValueError("输入文本不能为空!")
# 2. 模拟异步操作(如网络请求延迟)
await asyncio.sleep(1) # 模拟IO等待
# 3. 文本处理
processed = input.strip().upper() + self.suffix
return processed
# ...其他 runnable 对象方法8. 总结 + 展望
LangChain 是一个基于链式结构(Chain) 的开源框架,旨在快速构建复杂的大语言模型(LLM)应用。它更像是一个"模块化AI应用框架",旨在简化 LLM 与外部工具、数据、其他系统的集成,以及复杂流程的编排,通过预定义步骤顺序执行任务。
未来展望
- 低代码 / 无代码化:降低开发门槛,提供可视化流程编辑器,让非技术人员也能通过拖拽组件搭建 LLM 应用,类似 "LLM 应用的乐高平台"。
- 更强的 Agent 能力:目前 Agent 仍存在 "幻觉"、工具调用效率低等问题,未来可能通过强化学习、更好的规划算法(如分层任务规划)、外部反馈机制提升可靠性,使其能处理更复杂的真实世界任务(如自动化办公、复杂数据分析)。
- 标准化与生态融合:随着 LLM 框架竞争加剧(如 LlamaIndex、Haystack 等),LangChain 可能推动更多行业标准(如工具调用协议、内存接口),并与其他框架互补融合,形成更开放的生态。