Kafka
是一个分布式的发布-订阅消息系统,可以快速的处理高吞吐量的数据流,并将数据实时的分发到多个消费者中。
特点
- 数据吞吐量大:需要能够快速收集各个渠道的海量日志
- 集群容错性高:允许集群中少量节点崩溃
- 功能柜不需要太复杂:高吞吐,低延迟和可扩展
- 允许少量数据丢失:在海量日志中,少量的日志丢失是不会影响结果的。
kafka的基础工作机制是消息发送者可以将消息发送到kafka上指定的topic,而消息消费者,可以从指定的topic上消费消息。
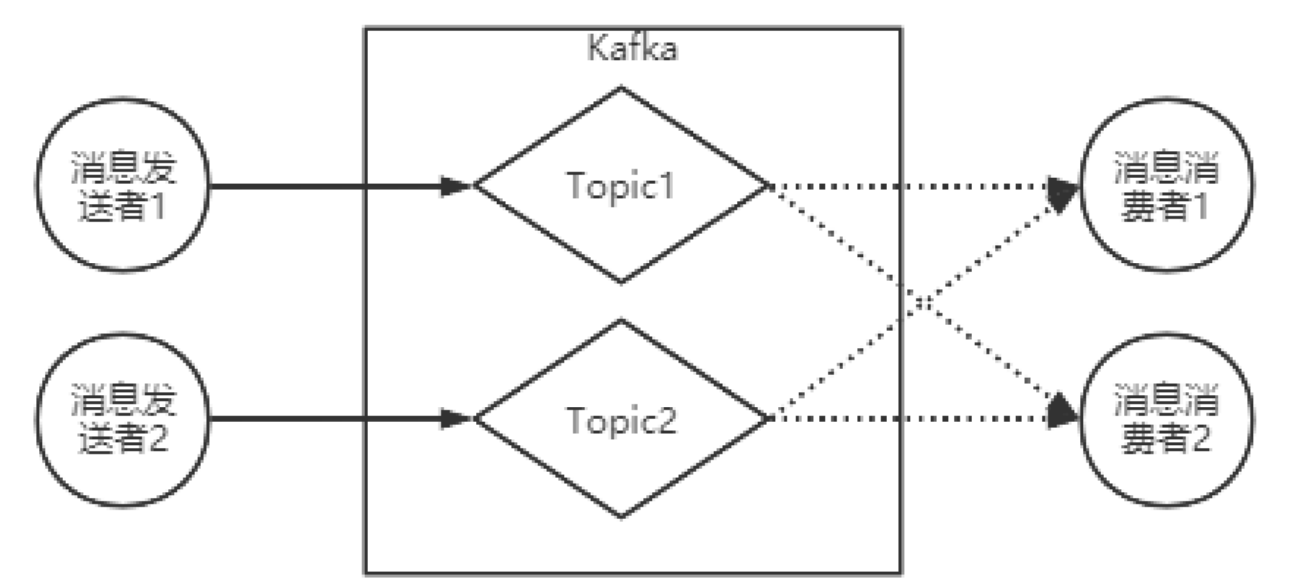
- 客户端Client:包括消息生产者和消费者
- 消费者组:每个消费者可以指定一个所属的消费者组,想通消费者组的消费者共同构成一个逻辑消费者组。但一个消息只会在内部被消费一次;
- 服务端Broker:一个kafka服务器就是一个Broker
- 话题Topic:这是一个逻辑概念,一个Topic被认为是业务含义相同的一组消息。并不存储数据
- 分区Partition:Topic只是一个逻辑概念,而Partition就是一个实际存储消息的组件。每个Partition就是一个队列结构。
Topic下的消息是如何存储的
kafka都会以追加的方式写入到log日志文件中,kafka中的消息日志,只允许追加,不可以删除或者修改。
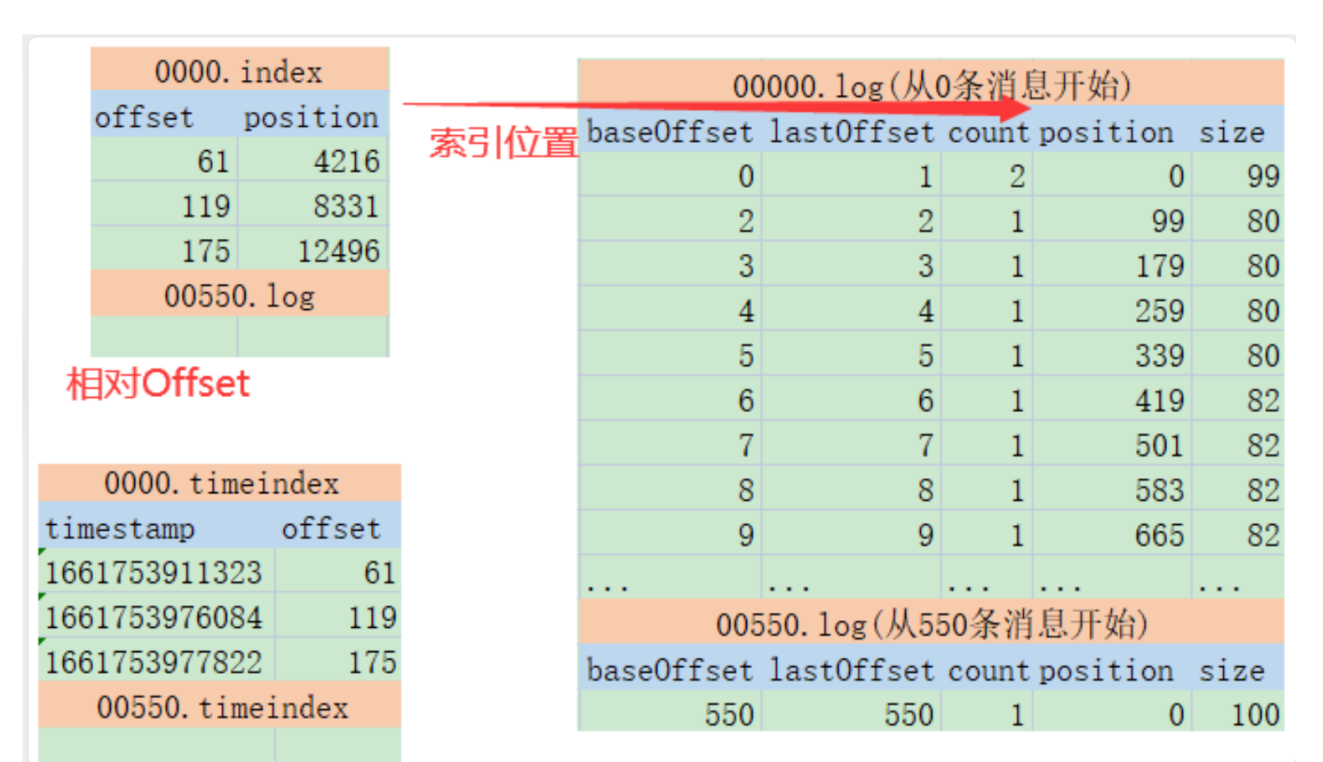
首先:index和timeindex都是以相对偏移量的方式建立log消息日志的数据索引。比如说 0000.index和0550.index中记录的索引数字,都是从0开始的。表示相对日志文件起点的消息偏移量。而绝对的消息偏移量可以通过日志文件名 + 相对偏移量得到。
然后:这两个索引并不是对每一条消息都建立索引。而是Broker每写入40KB的数据,就建立一条index索引。由参数log.index.interval.bytes定制。
kafka中大量的运用了零拷贝机制来加速文件读写。