在数据驱动的商业时代,企业数据如同埋藏在地底的石油,其价值在于能否被高效、精准地开采并输送至需要的地方。南大通用GBase数据库作为国产数据库的佼佼者,承载着大量企业的核心数据资产。在国产信创化的背景下,打通传统数据库与南大通用数据库的功能非常关键,接下来演示如何通过ETL工具ETLCloud来构建PostgreSql与南大通用数据库的数据同步管道。
一、配置平台与数据库的连接
我们要配置两个数据源连接,分别是目标端GBase与源端PostgreSql的数据源。
首先来配置GBase的数据源。
来到系统首页,进入数据源管理模块。
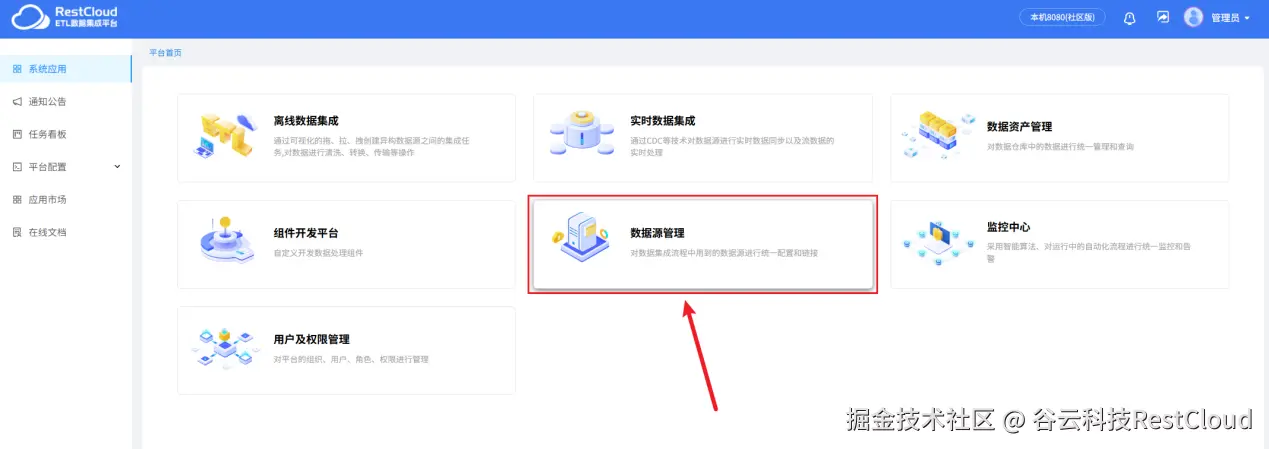
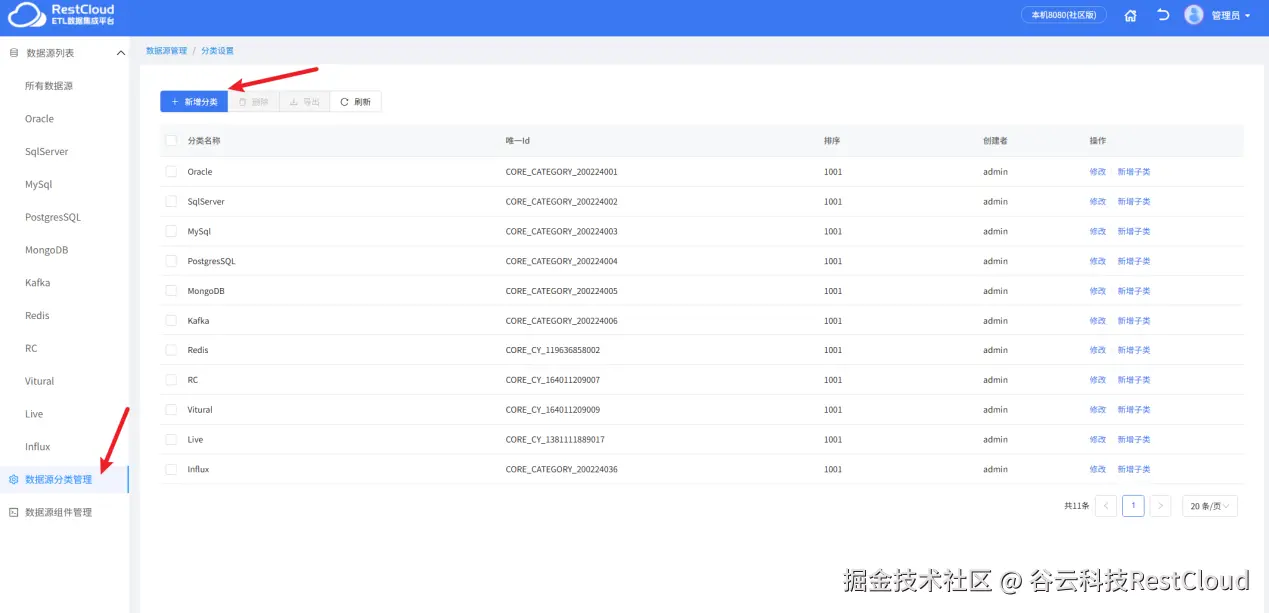
系统初始化只有部分分类,数据源连接必须创建在某个分类下,可以放在任意的分类,为了方便后续数据源的维护,建议将数据源根据数据库类型、环境等维度放在某个分类下,比如GBase的数据源就放在GBase分类下,但系统默认没有GBase分类,我们可以手动创建一个Gbase分类。
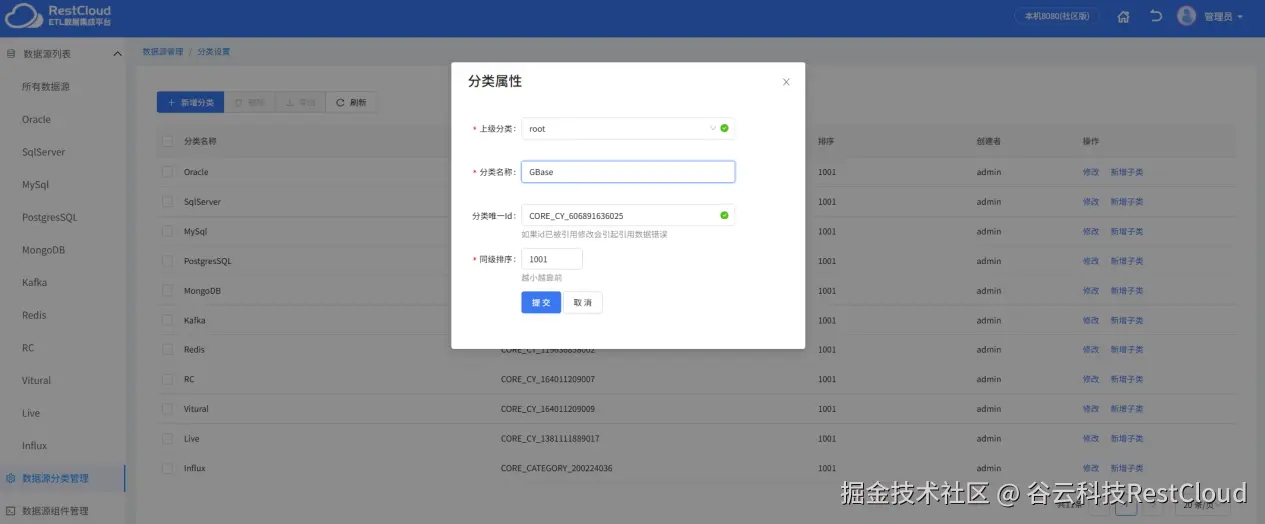
选中创建的GBase分类,点击新建数据源。
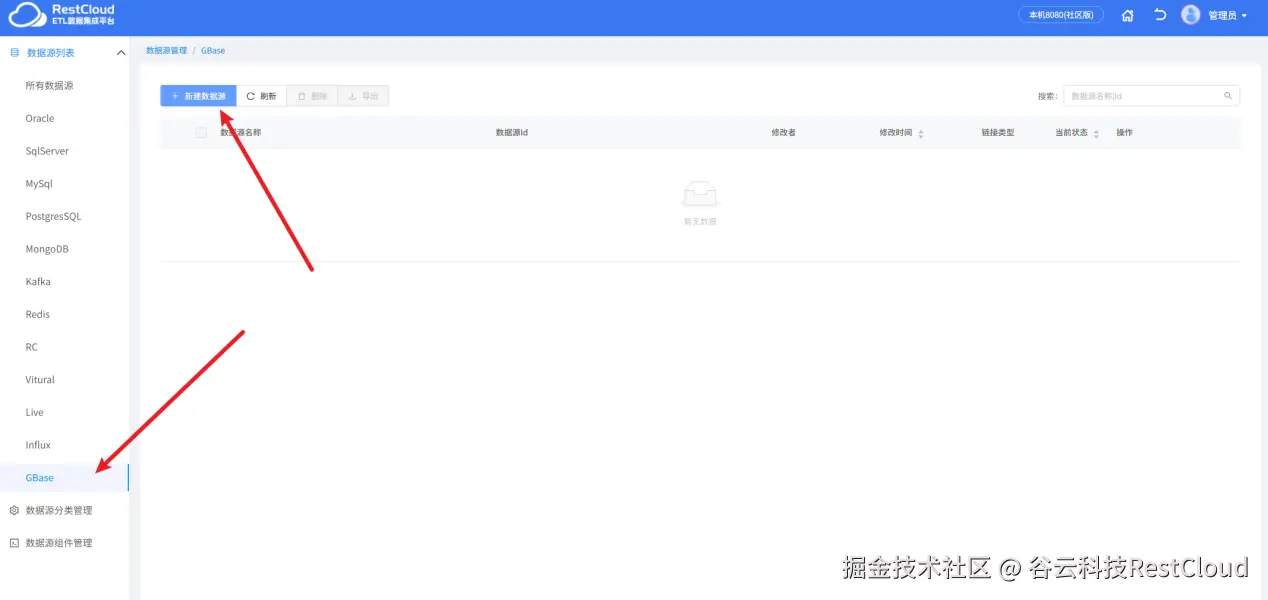
根据提示填写配置。
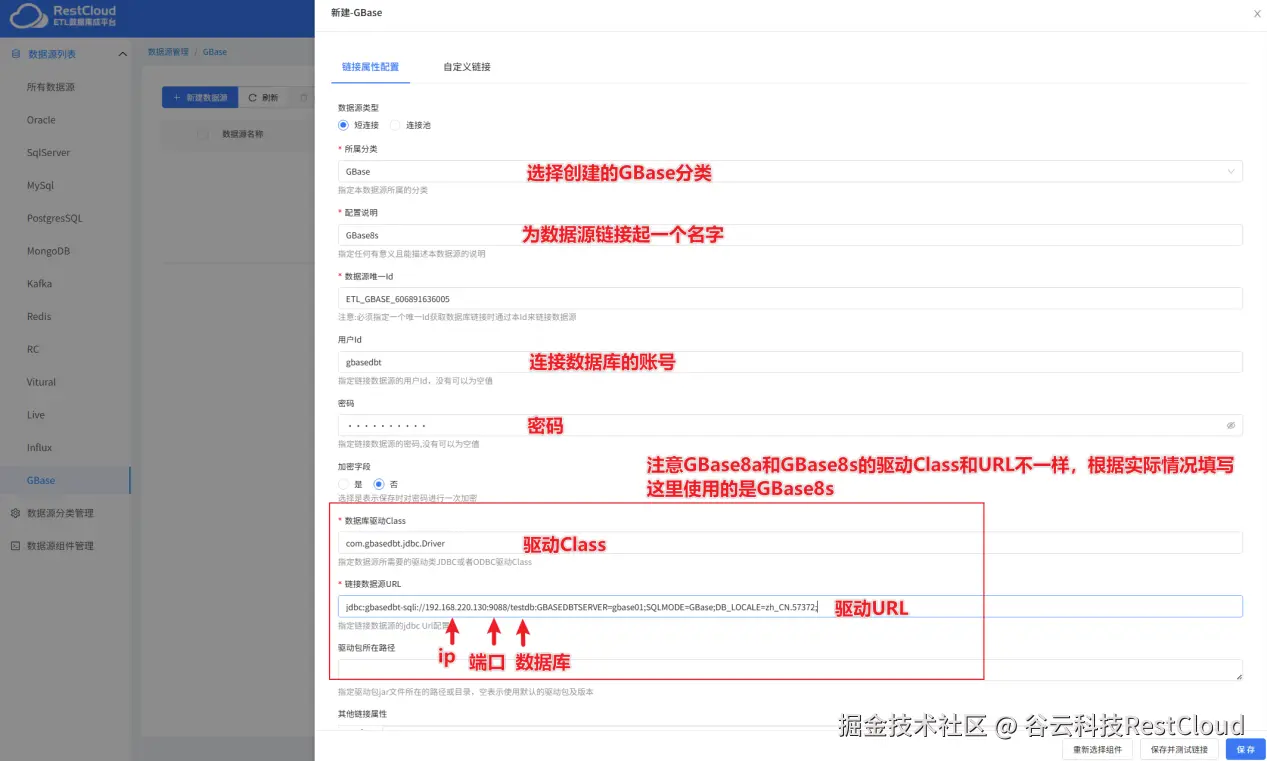
点击保存并测试按钮提示连接成功即可。
配置好了GBase的数据源,接下来配置PostgreSql的数据源。
系统自带了PostgreSql的分类,直接创建数据源连接。
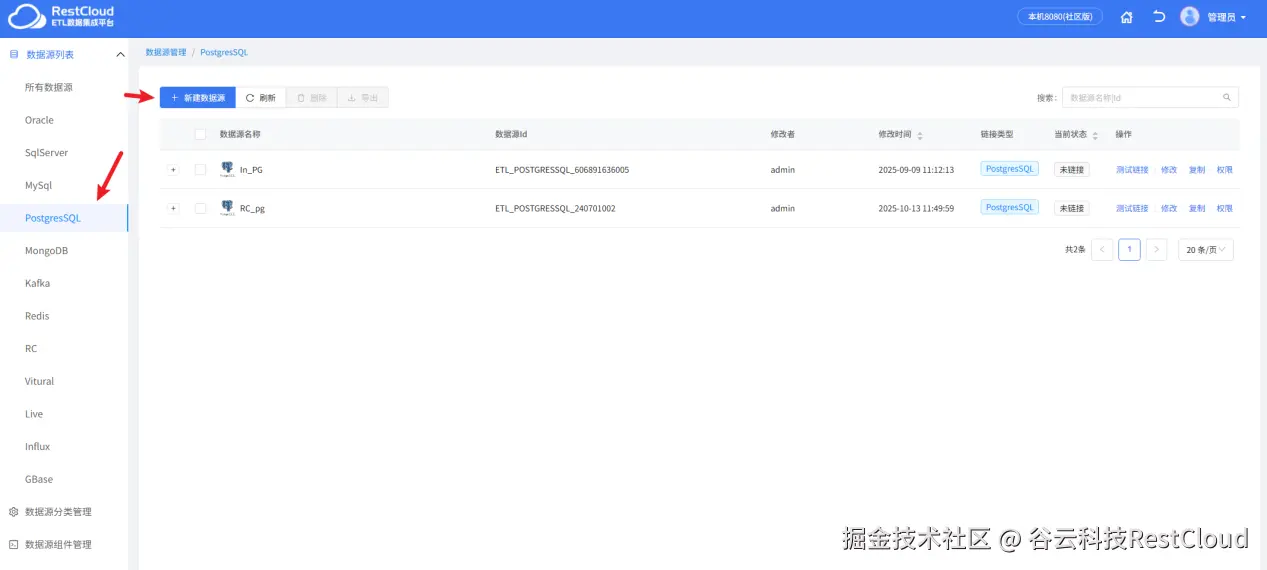
PostgreSql数据源的具体配置:
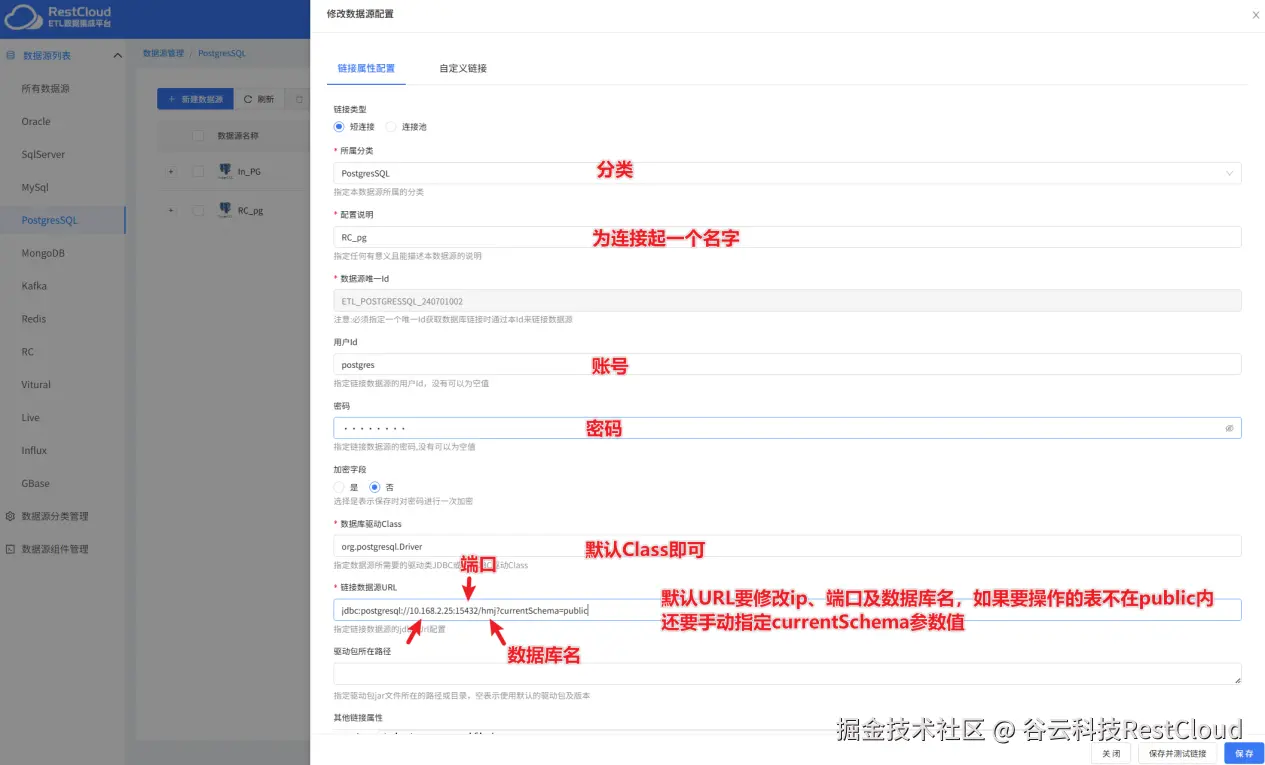
到这里,ETLCloud已经打通了源端和目标端的数据库配置,接下来配置数据同步流程。
二、配置离线全量同步流程
来到首页,进入离线数据集成模块。
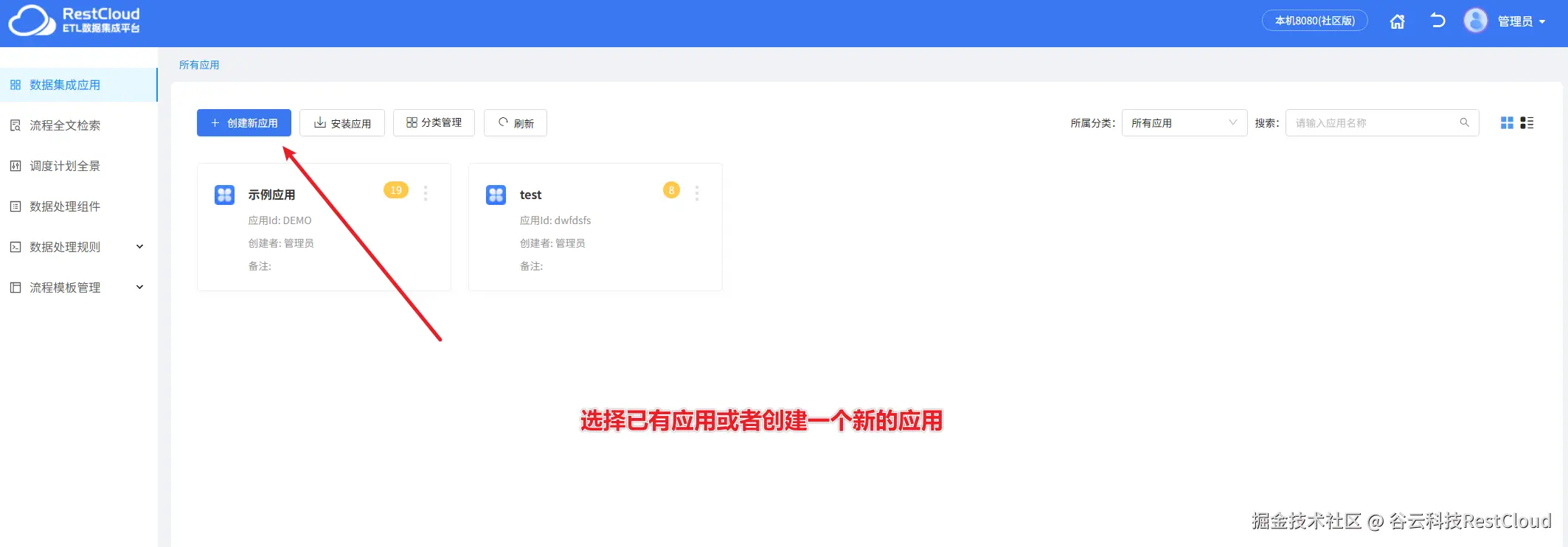
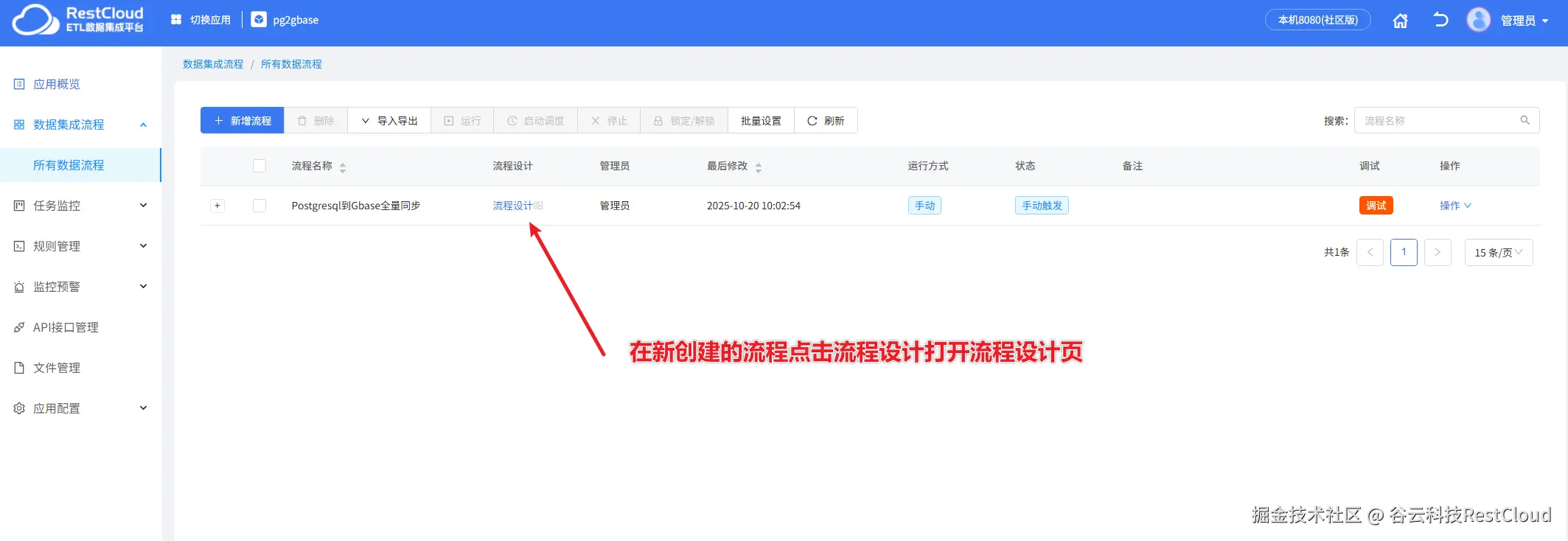
根据弹窗提示创建一个新的数据流程。
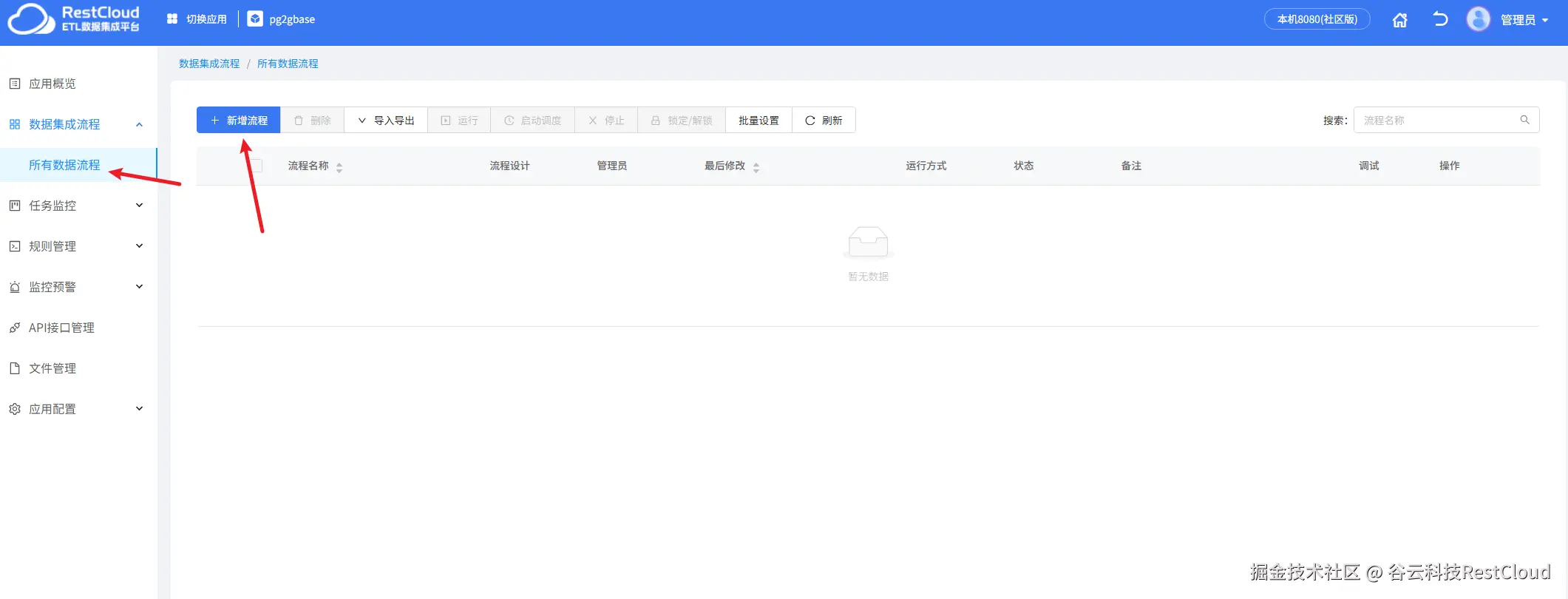
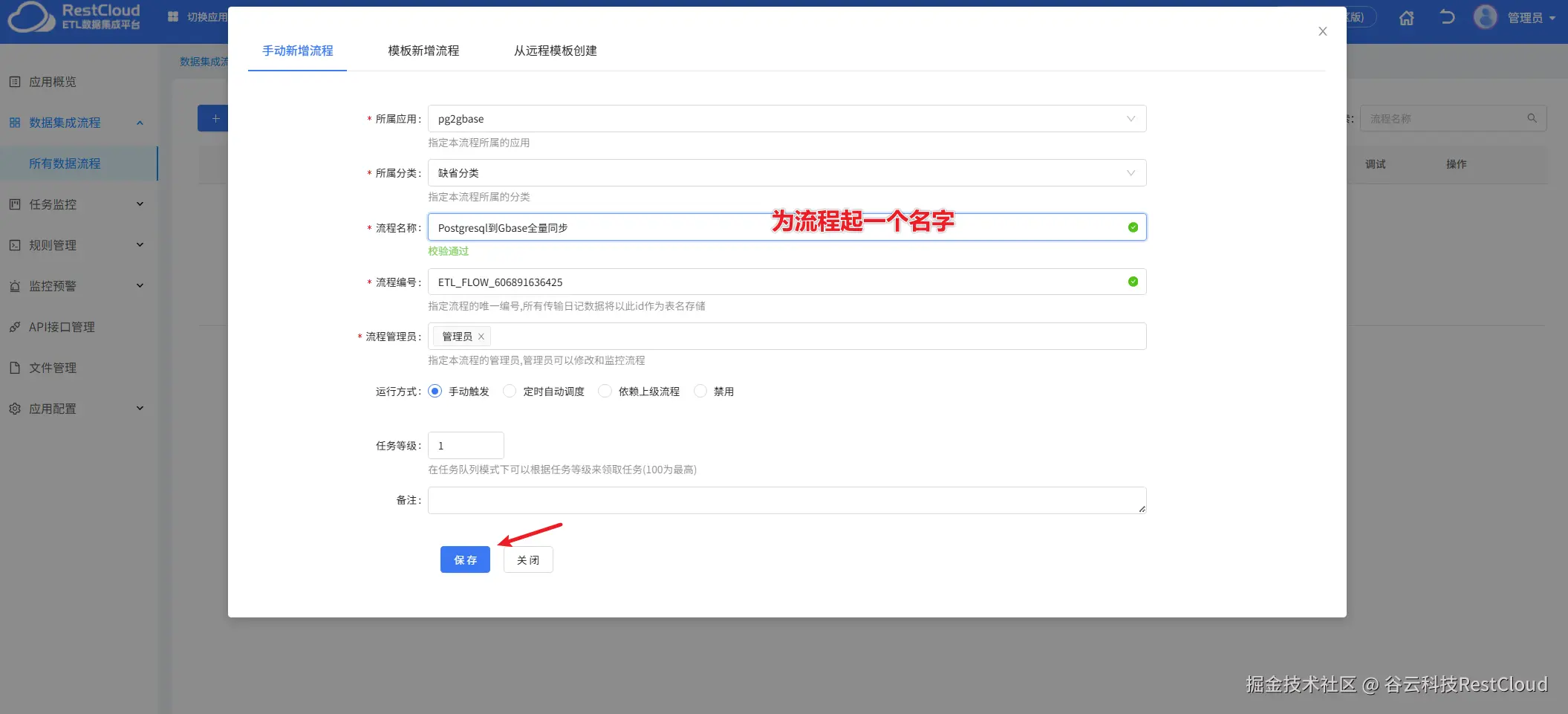
进入流程设计页配置流程组件。
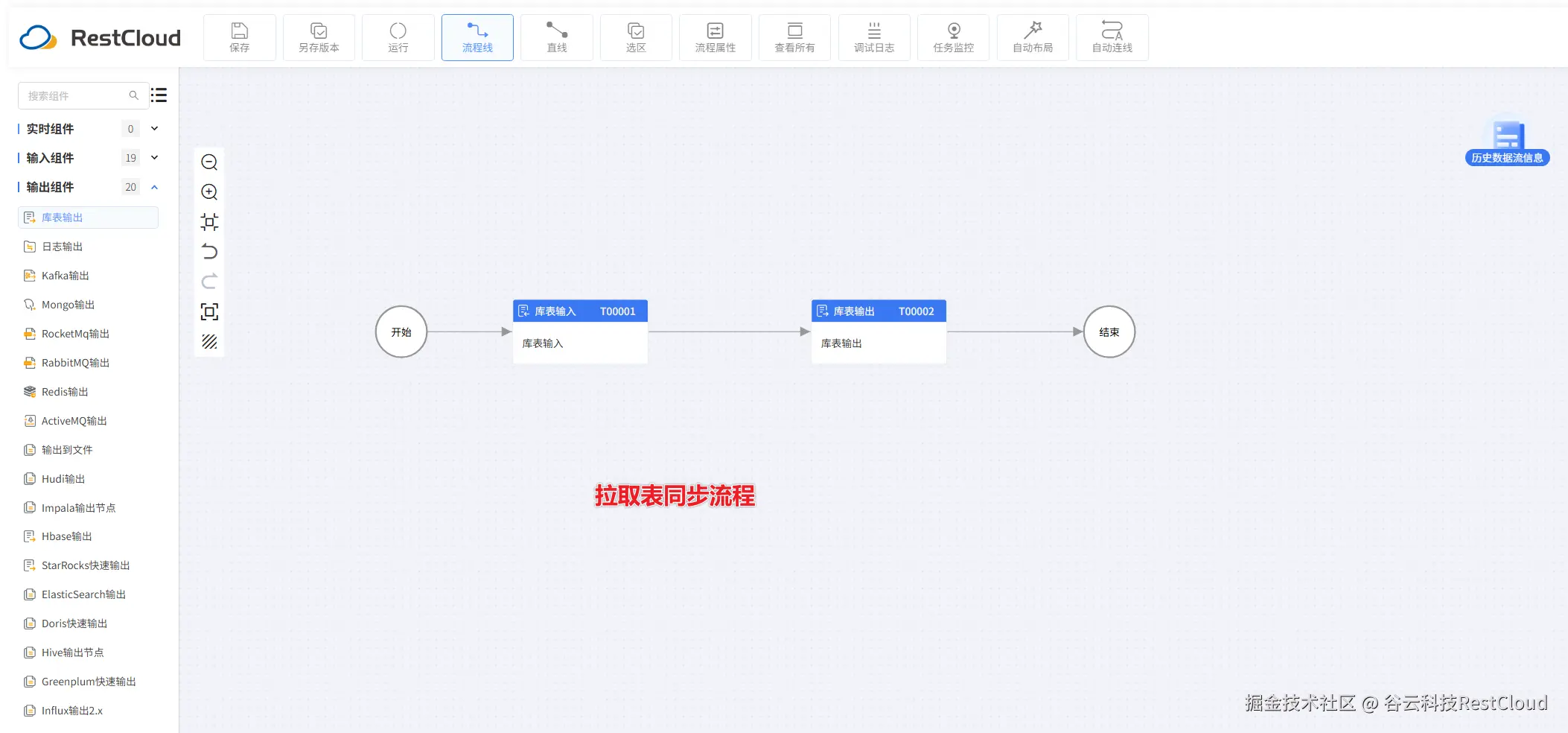
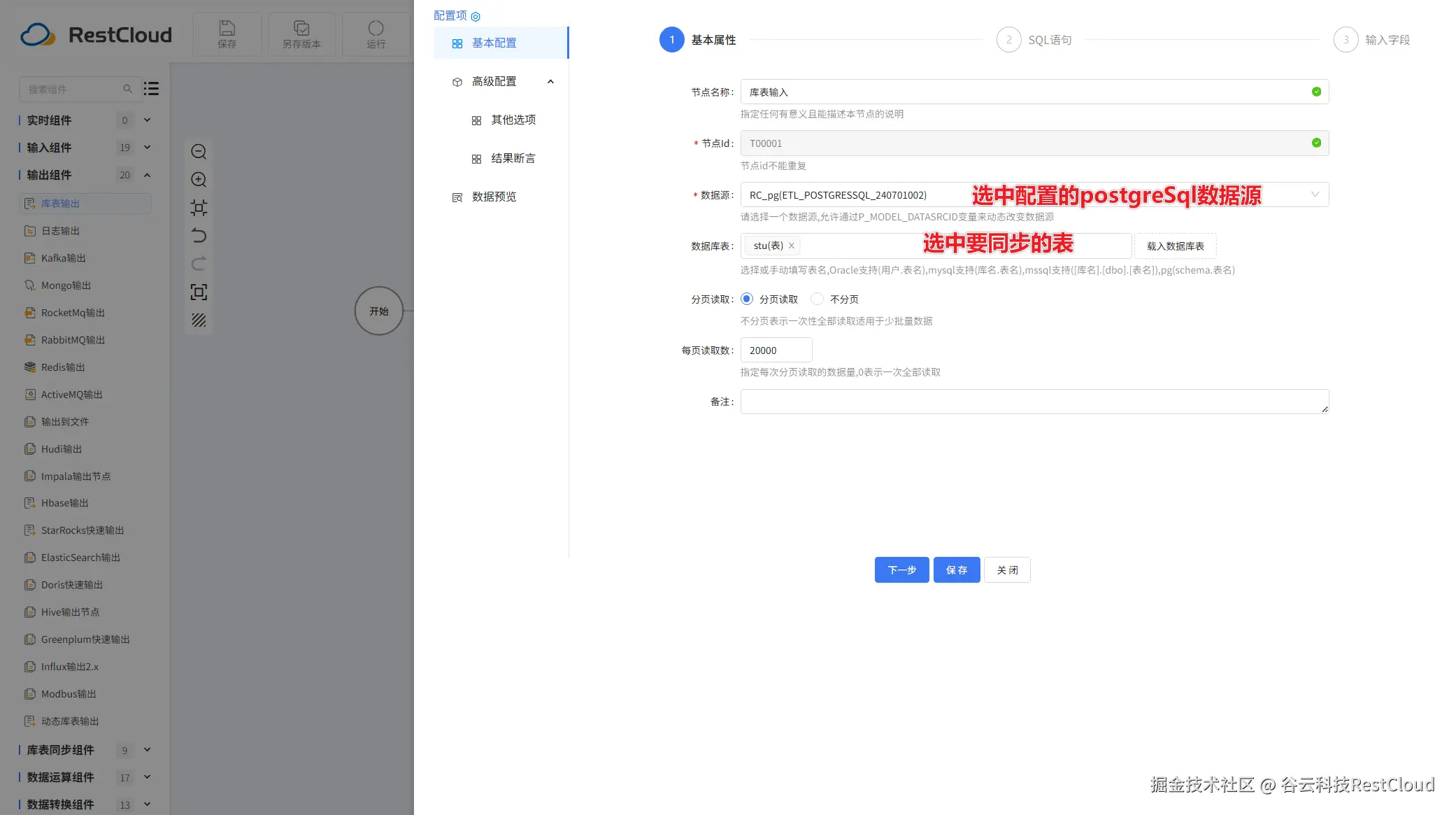
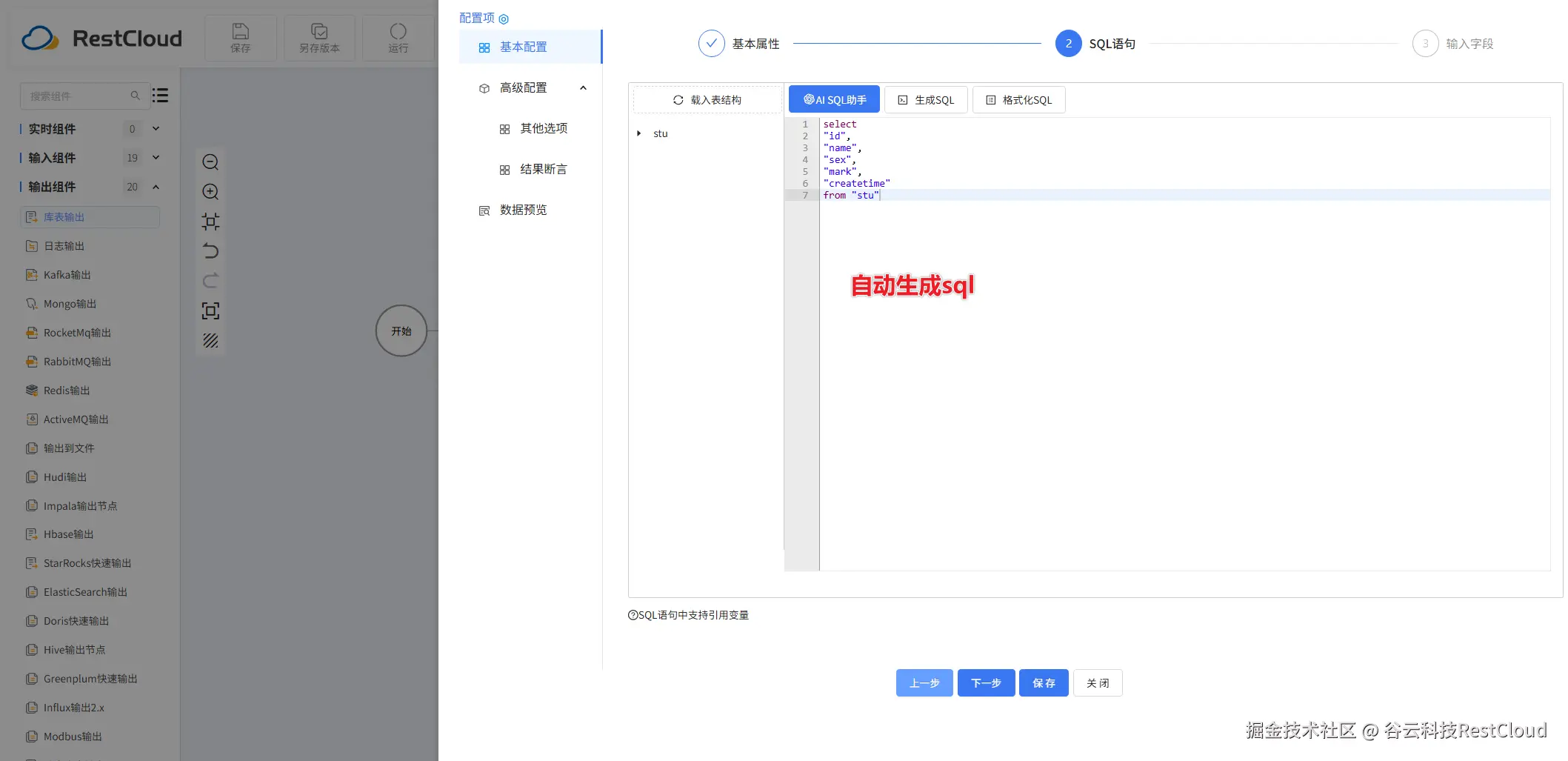
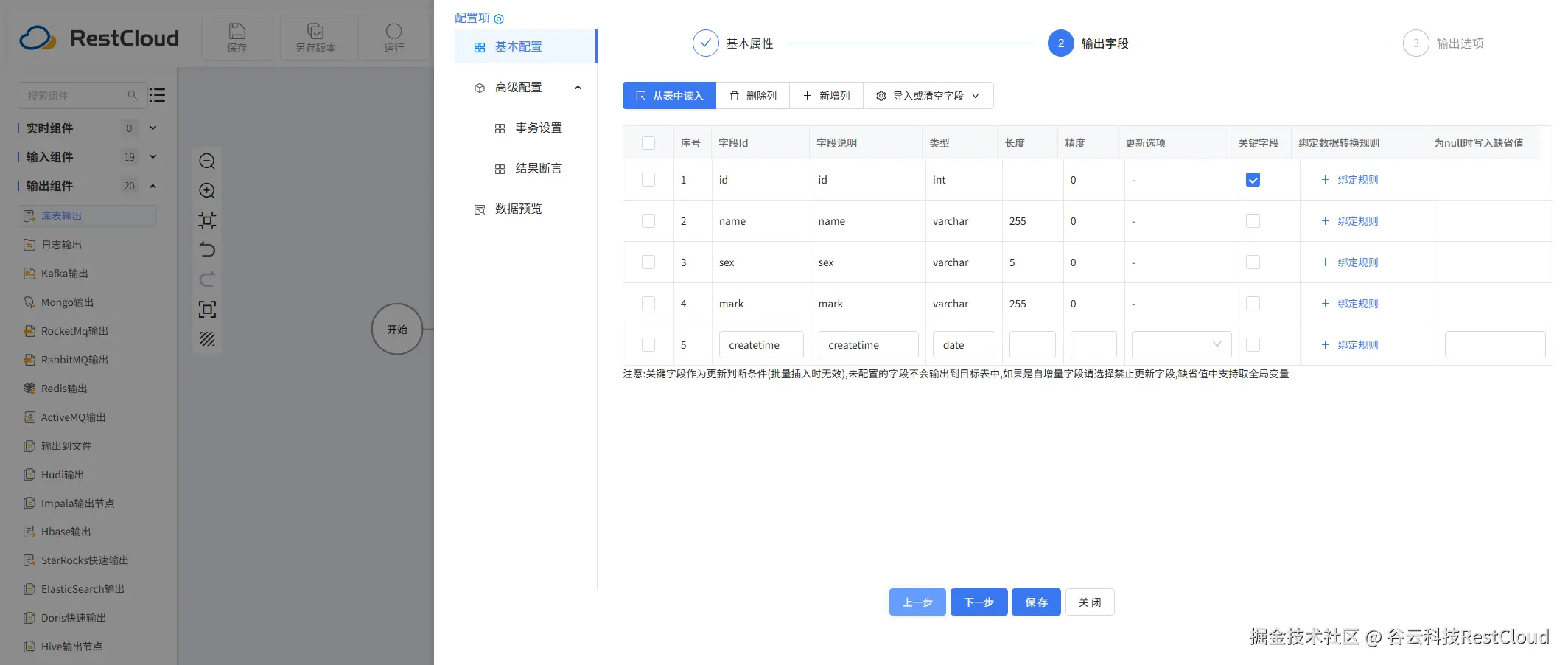
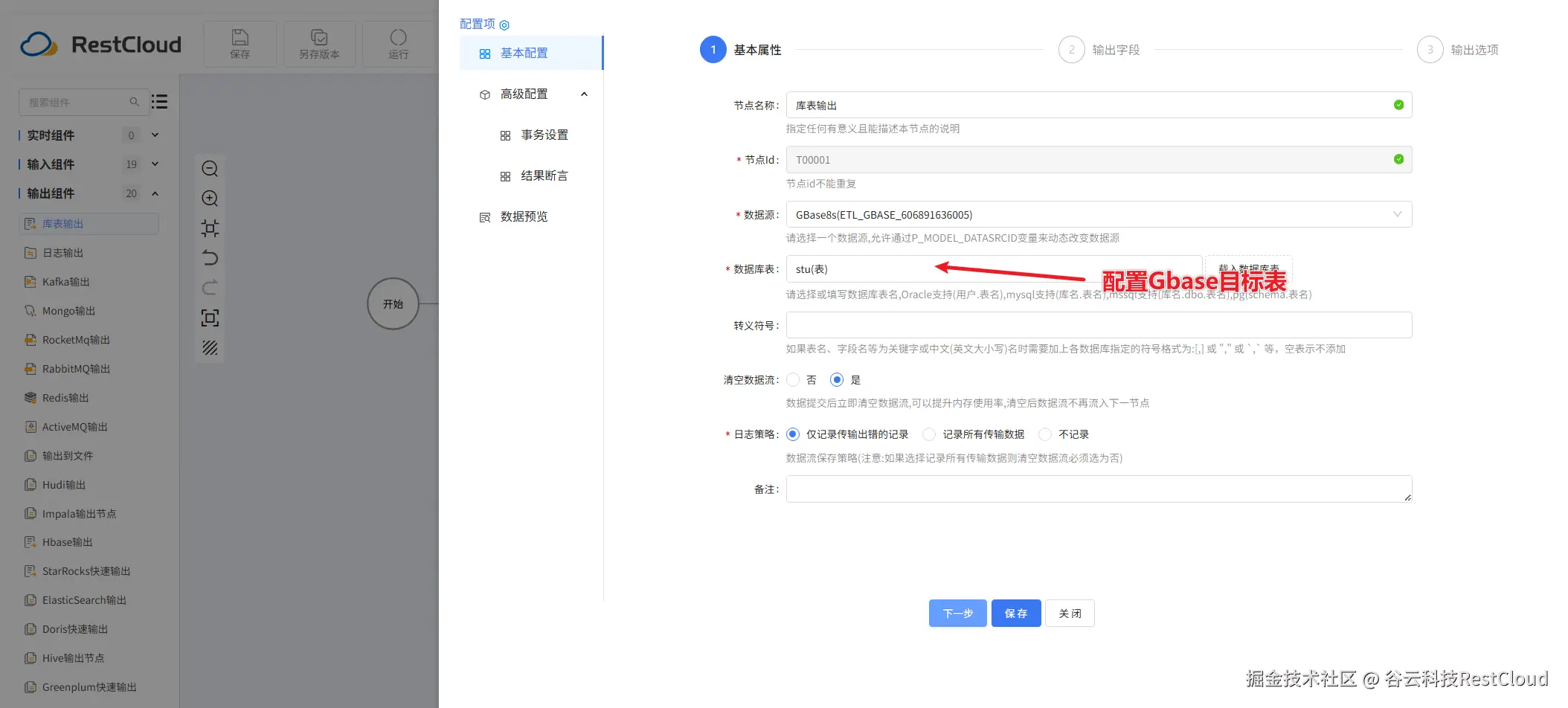
库表输入配置:
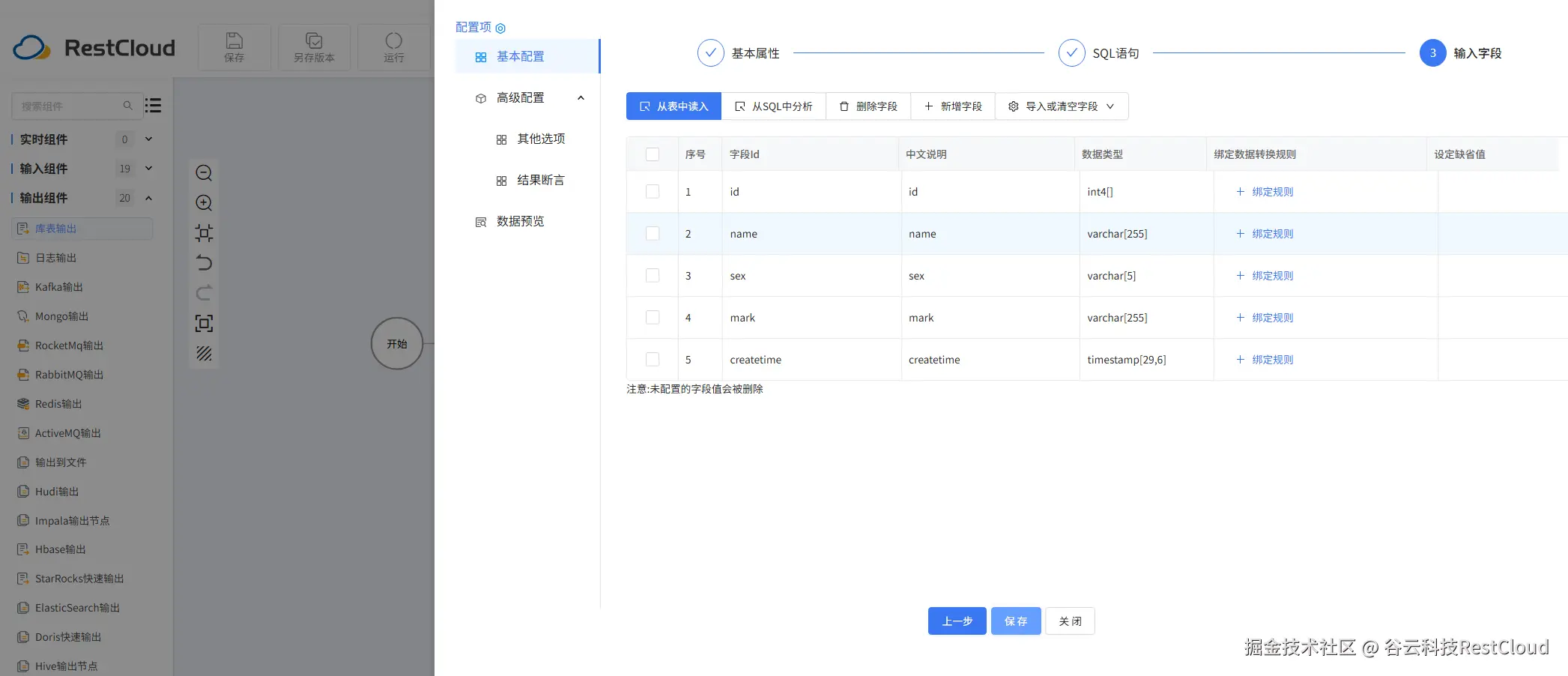
库表输出配置:
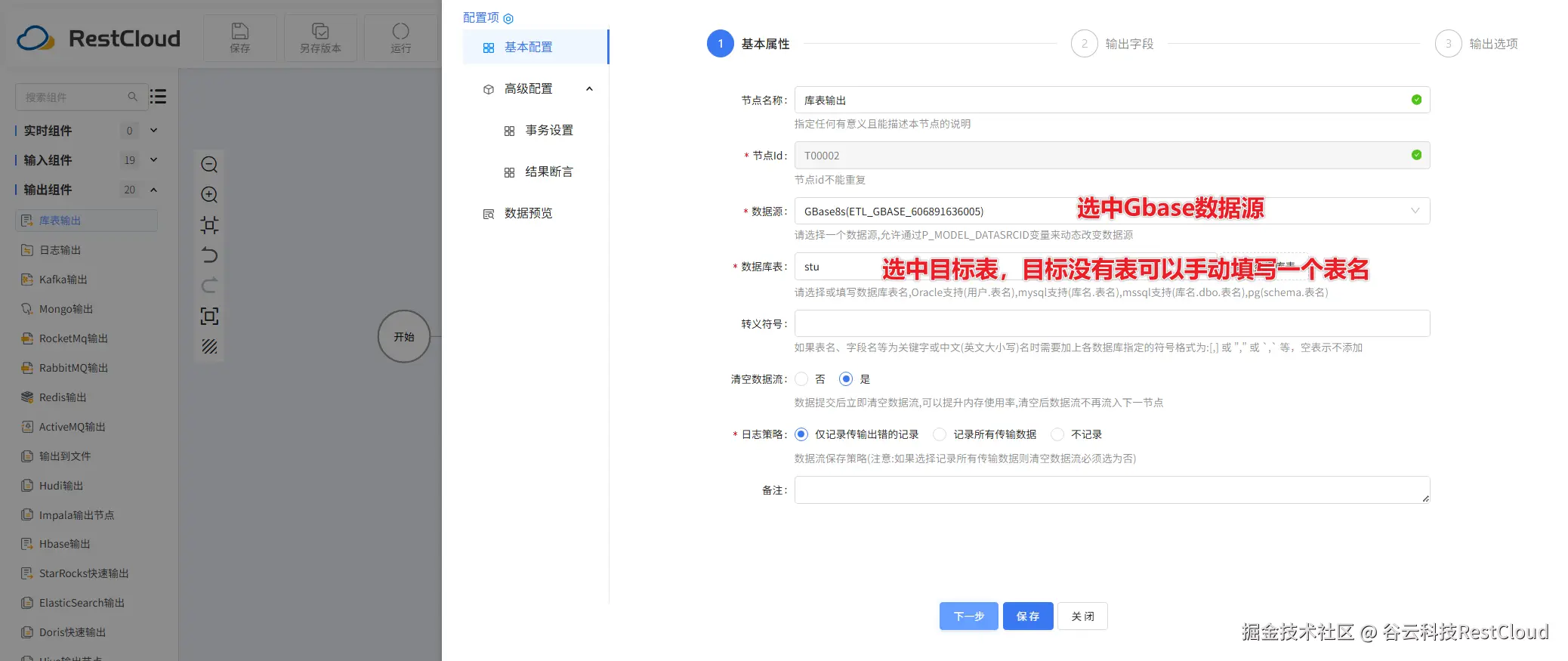
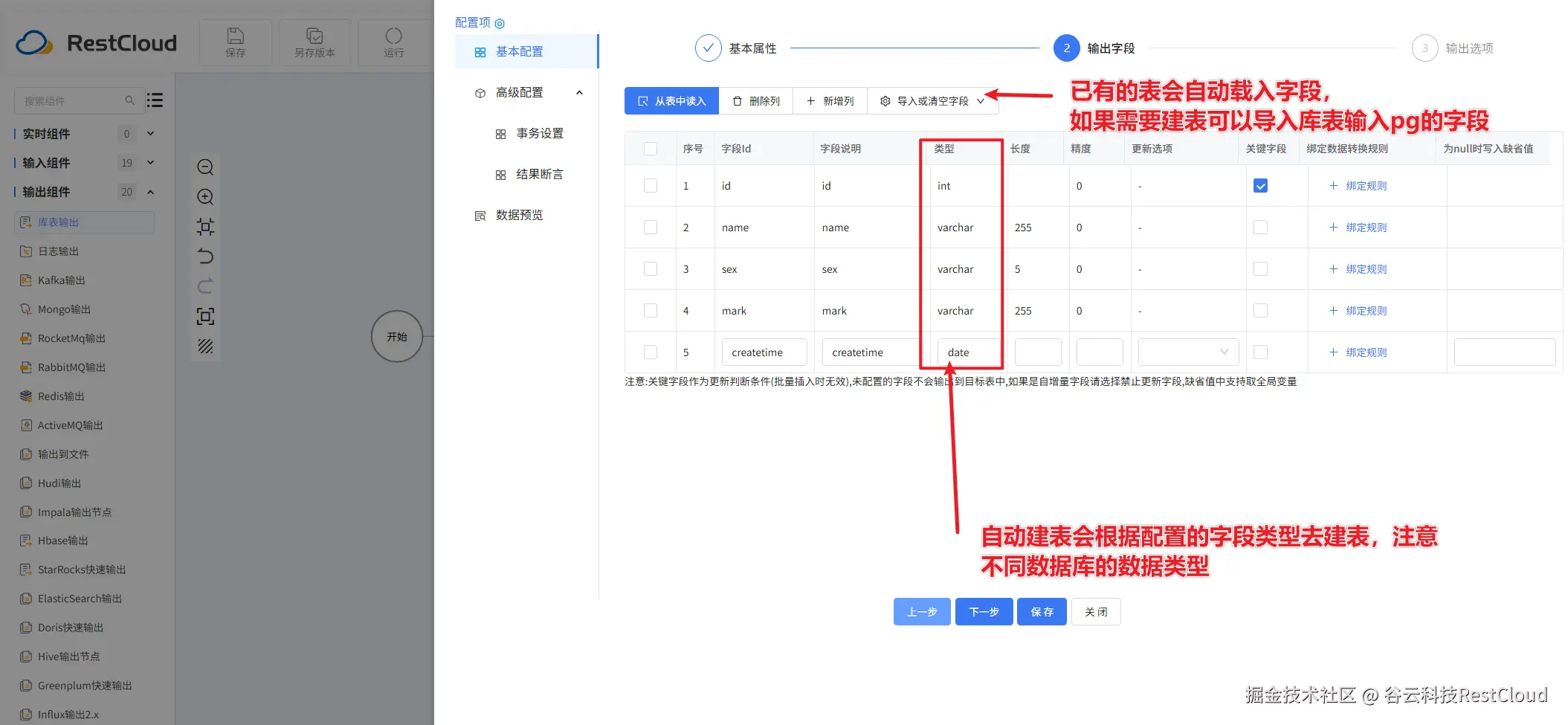
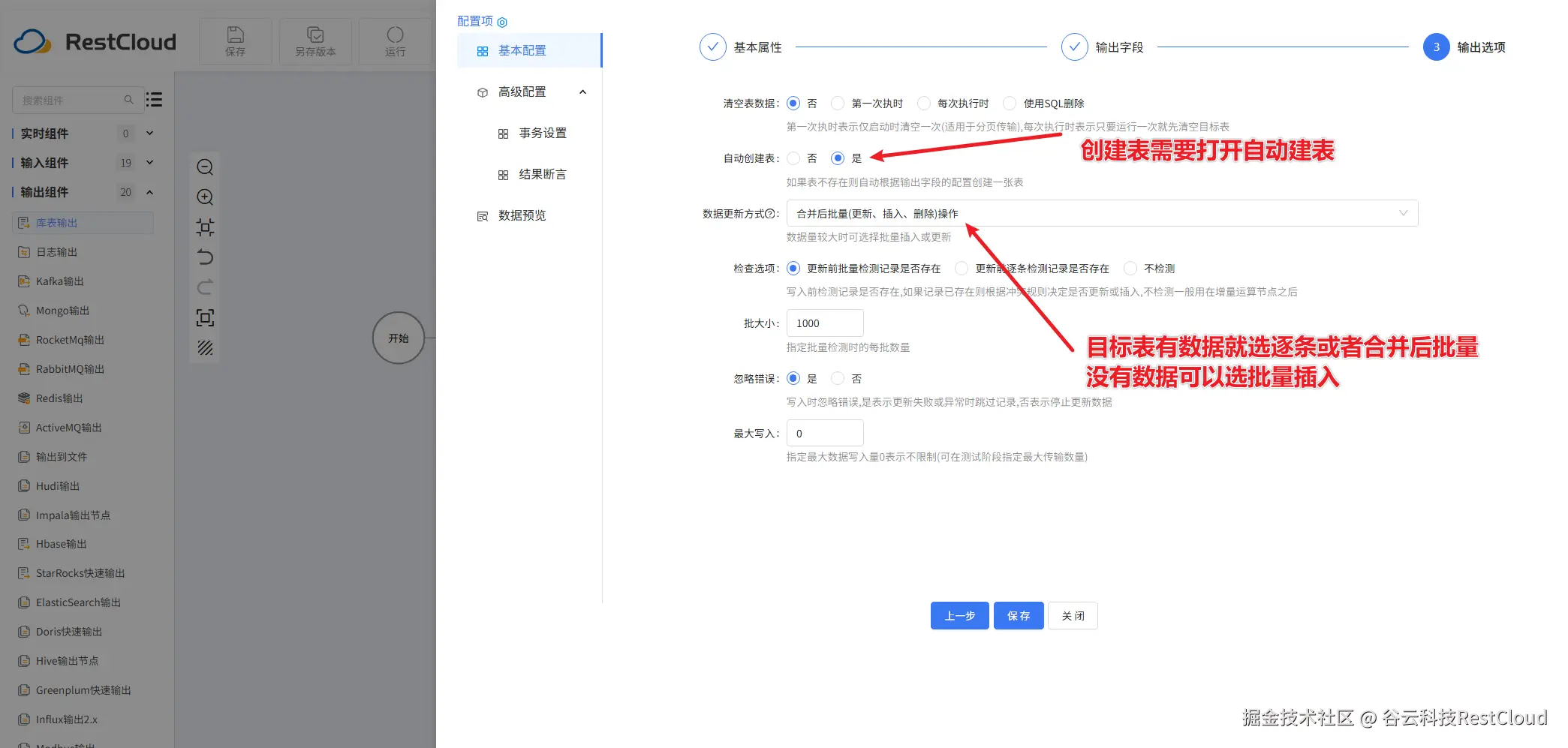
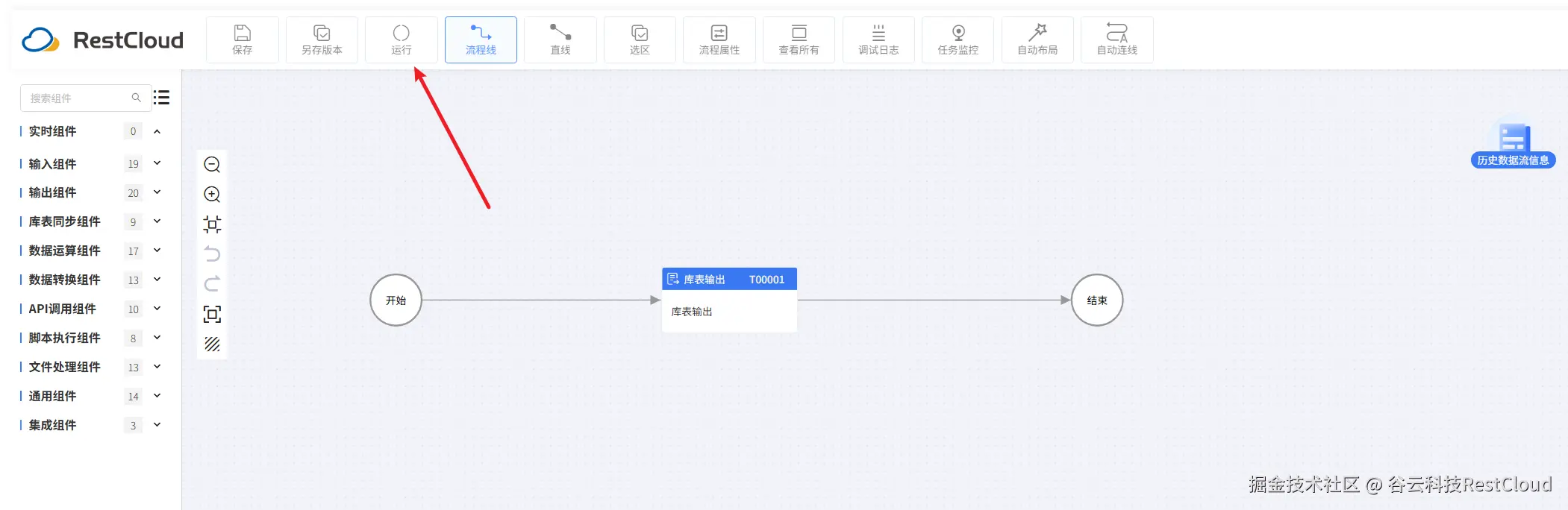
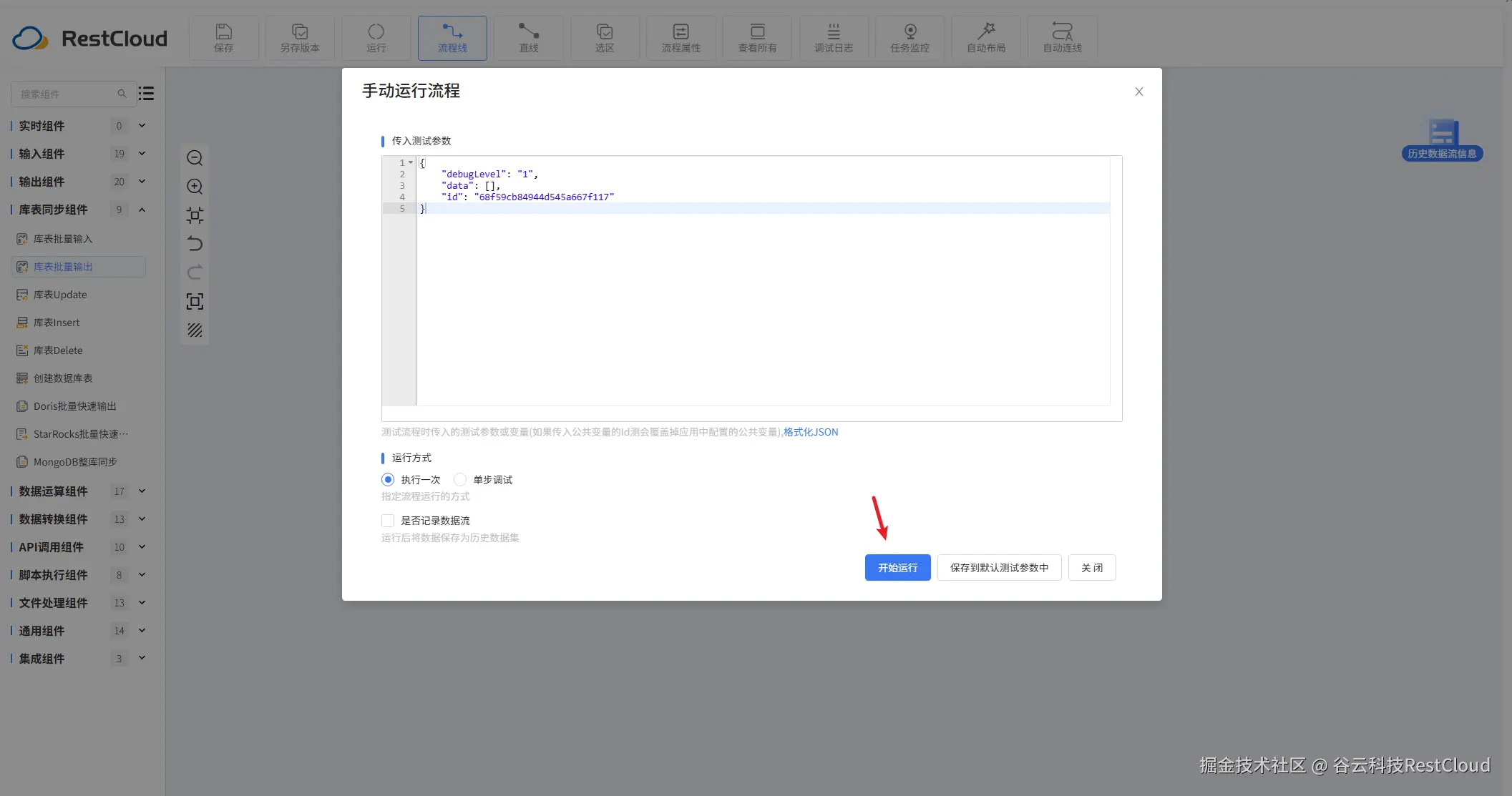
配置好流程后,在上方的工具栏里面,找到运行按钮并点击。
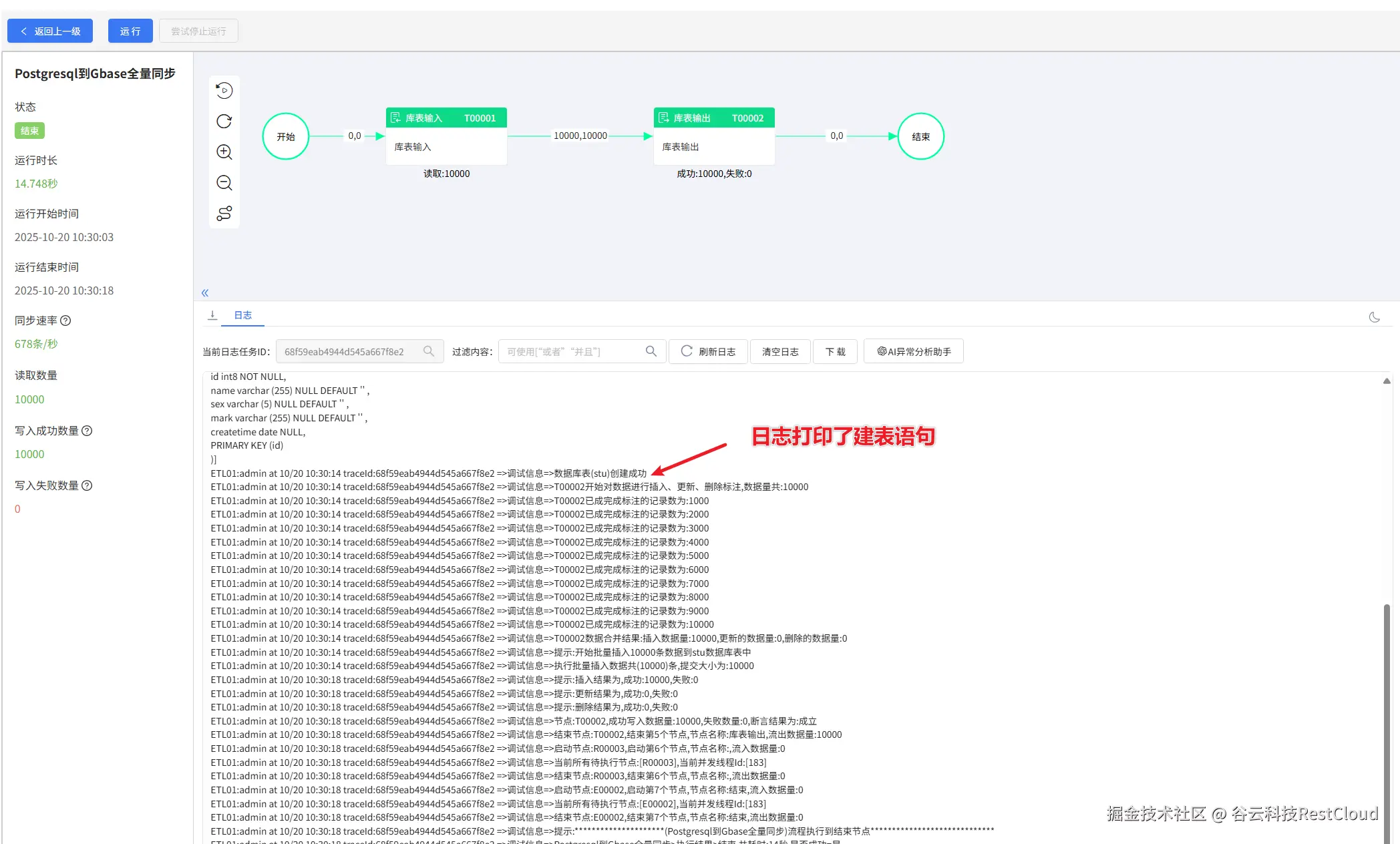
流程成功运行。
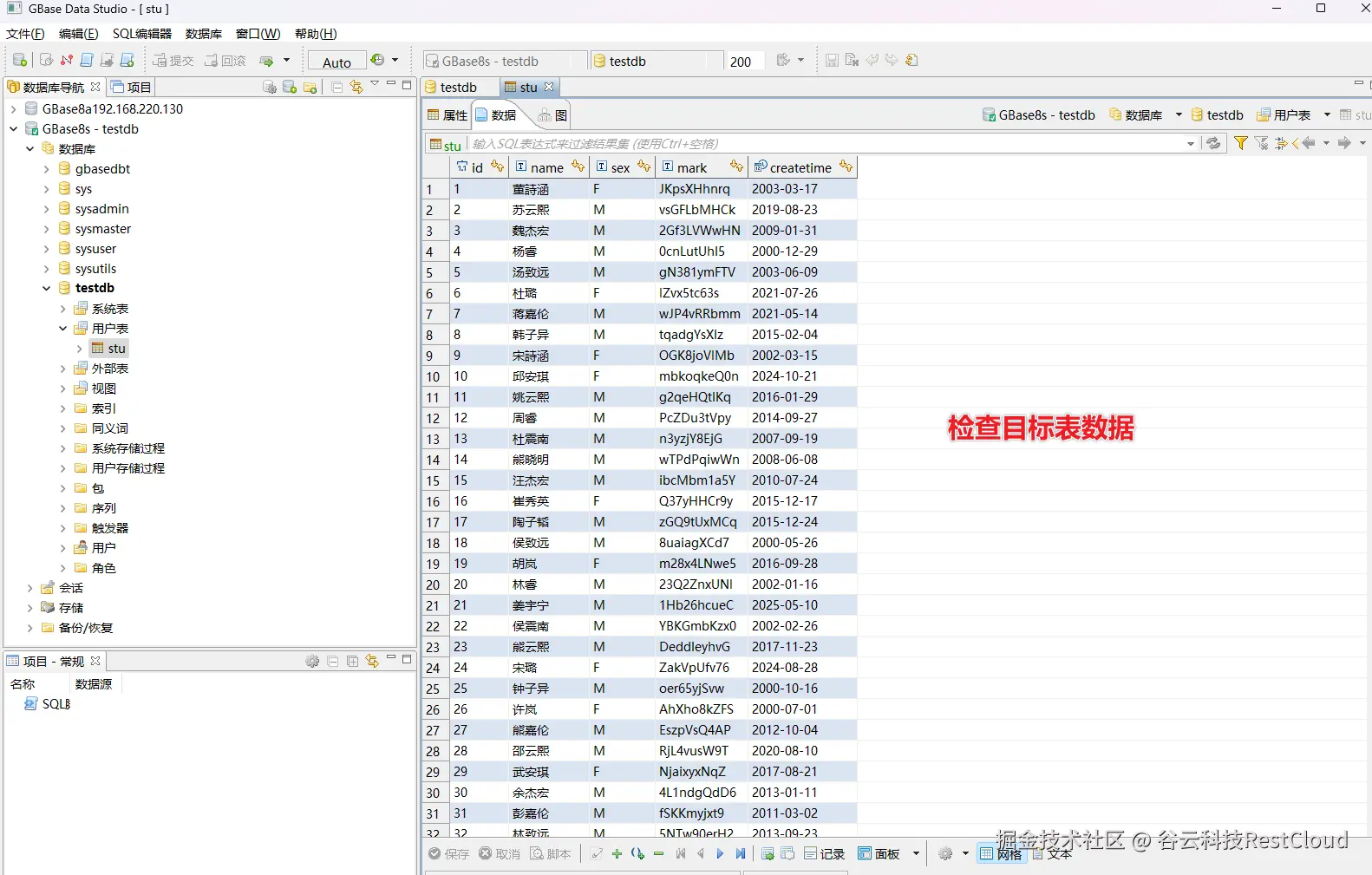
三、配置实时增量同步流程
首先先在离线流程这里创建一个流程。
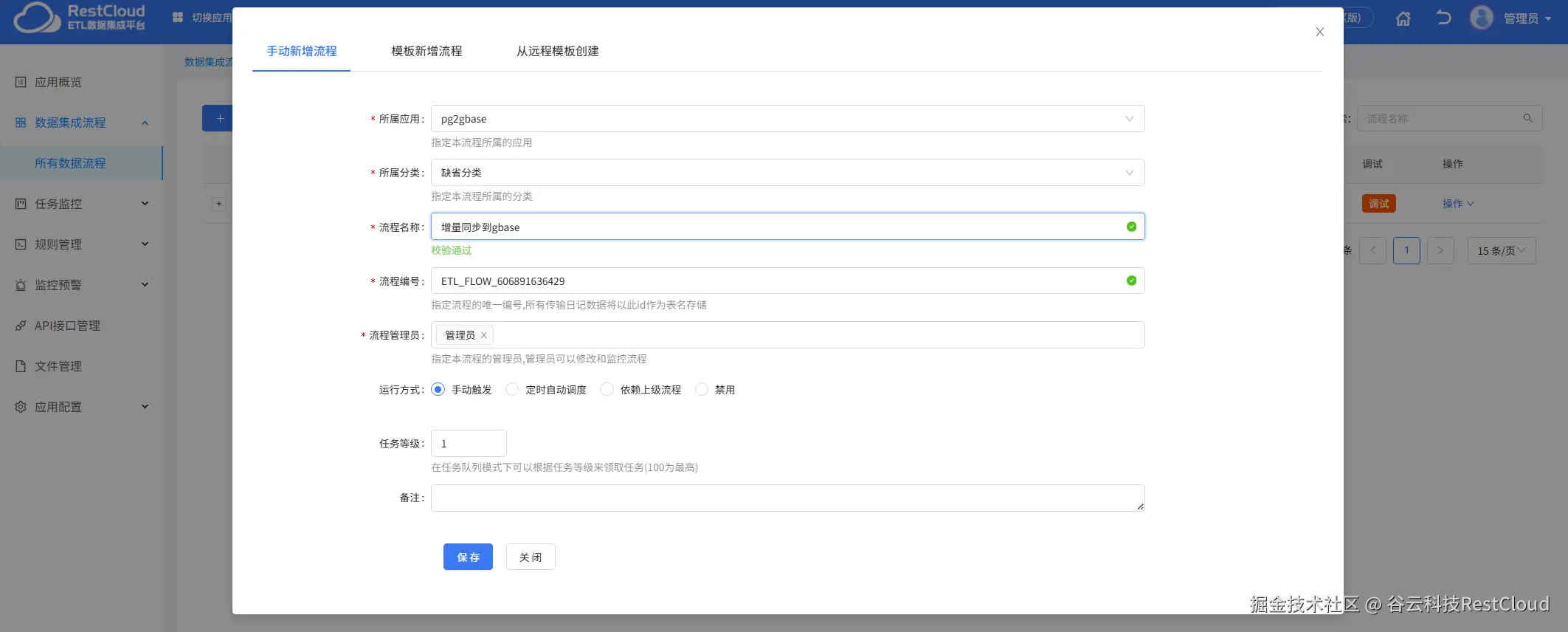
配置流程,只需要一个库表输出组件即可。
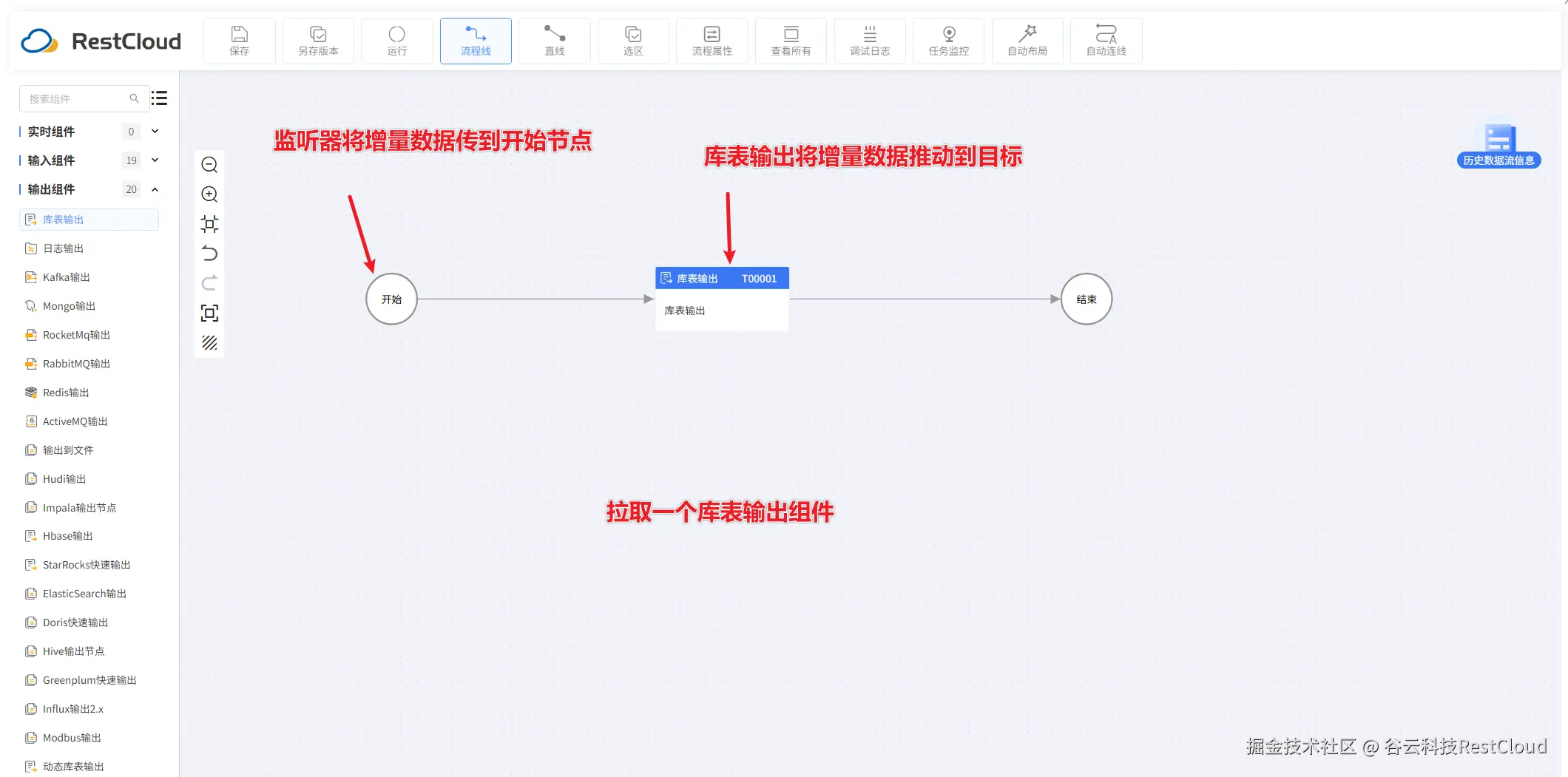
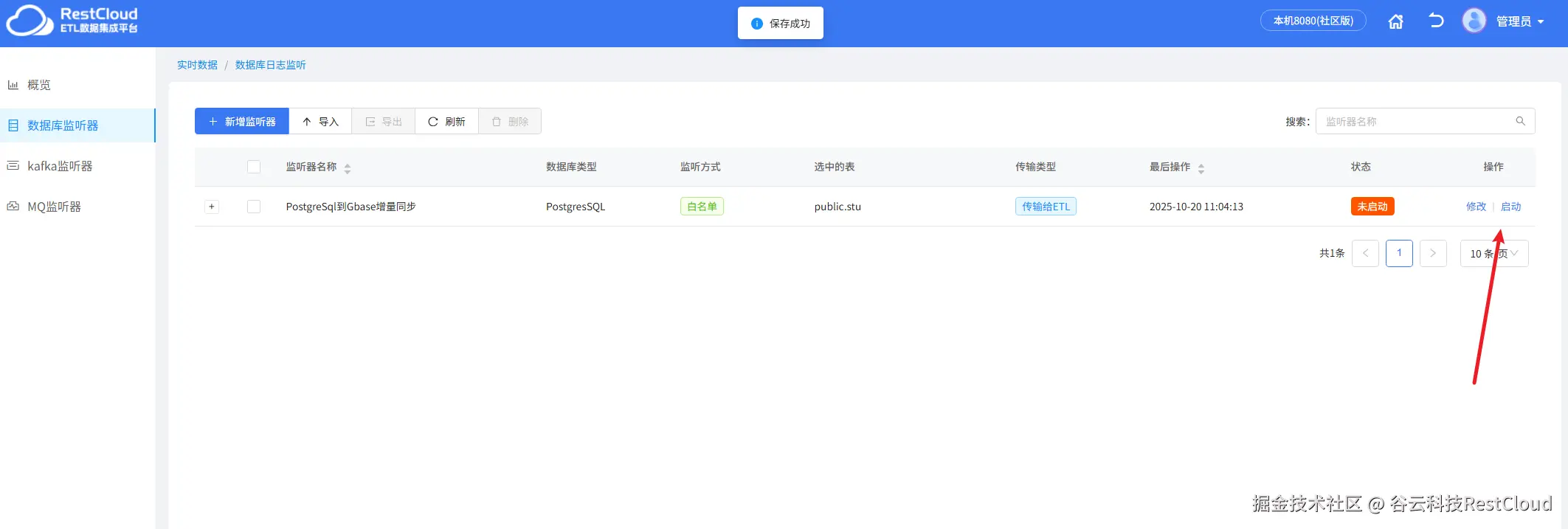
配置好流程后,来到首页,进入实时数据集成模块,创建数据库监听器。
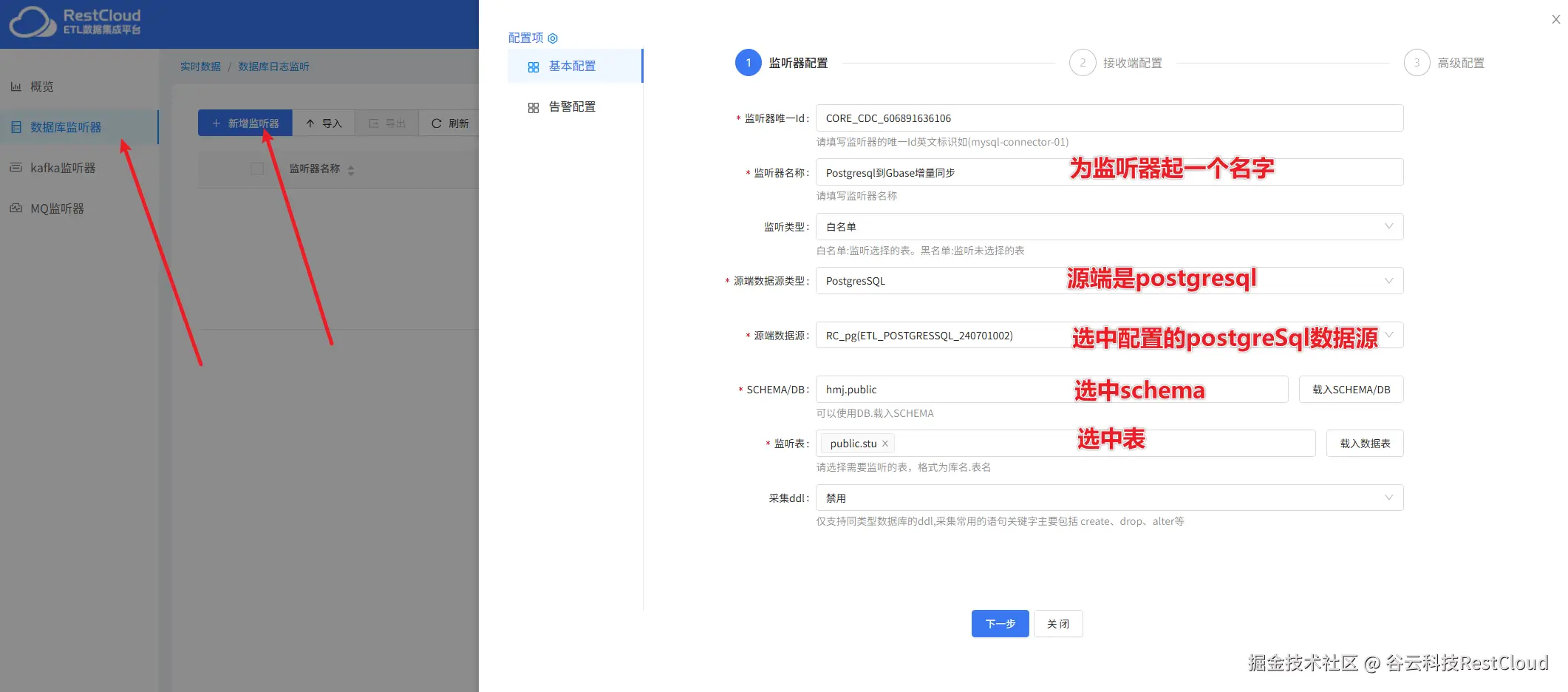
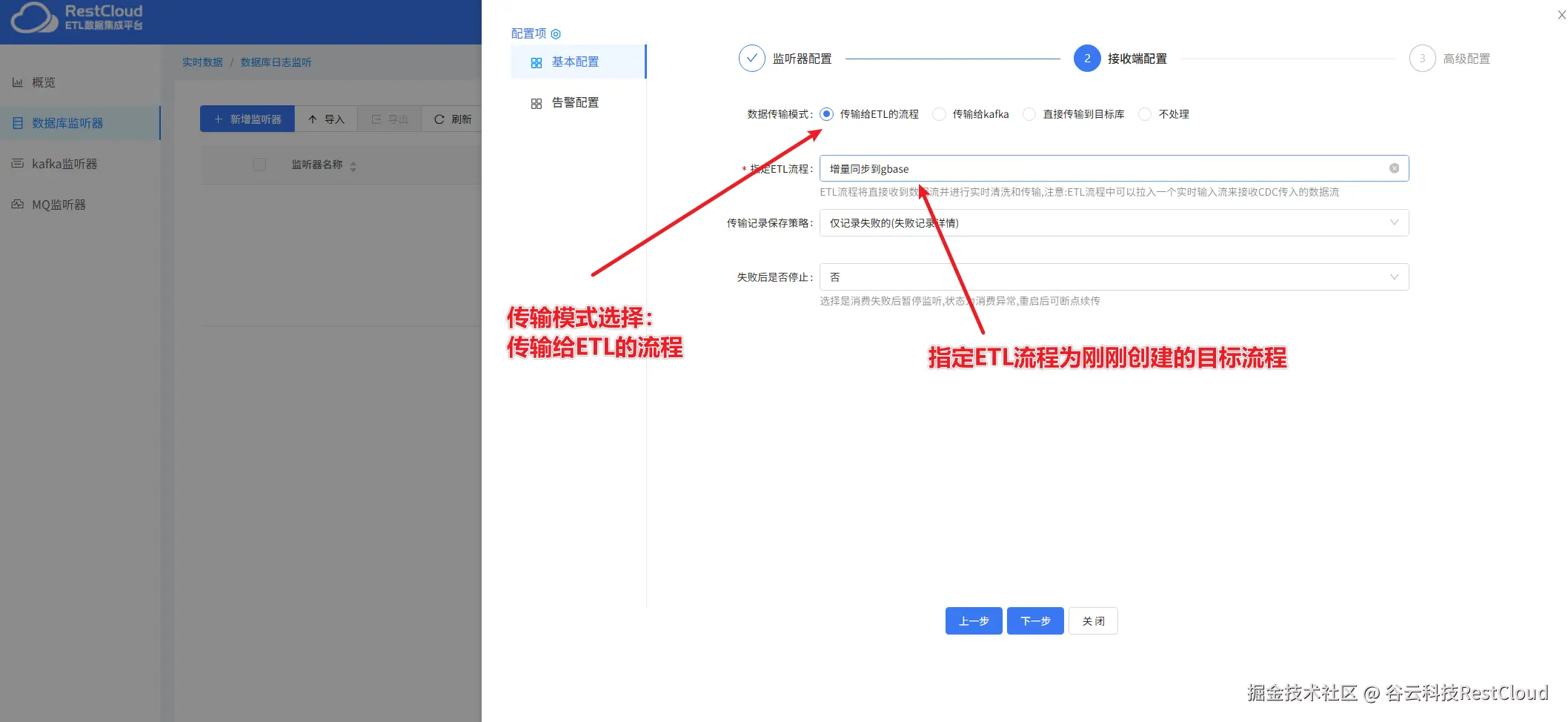
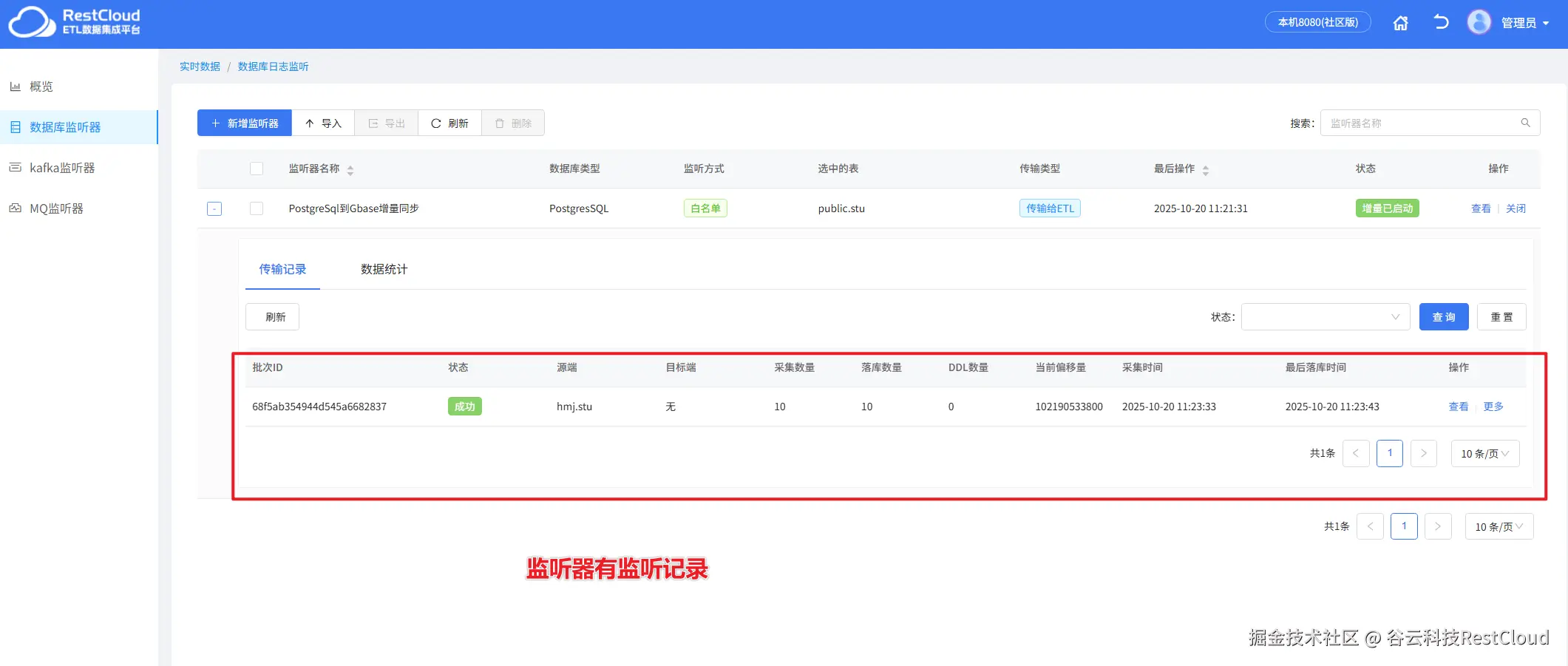
创建好监听器,启动监听器,显示增量已启动证明监听器已经正常启动。
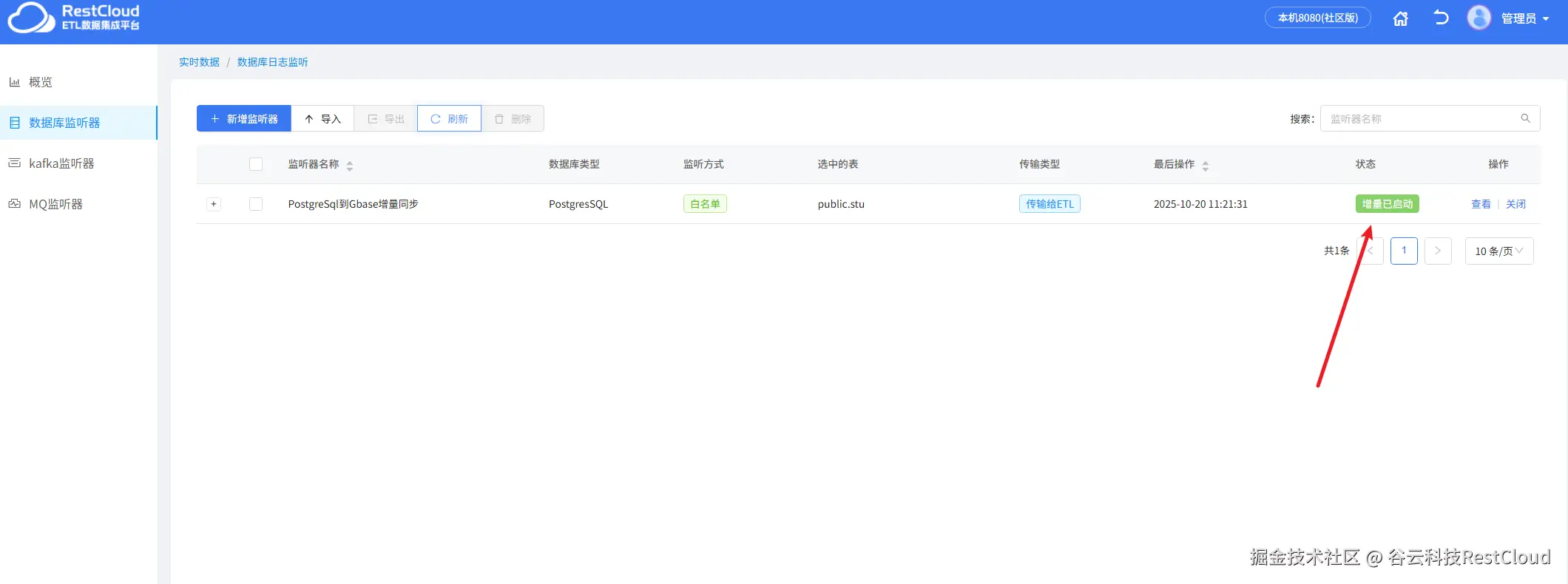
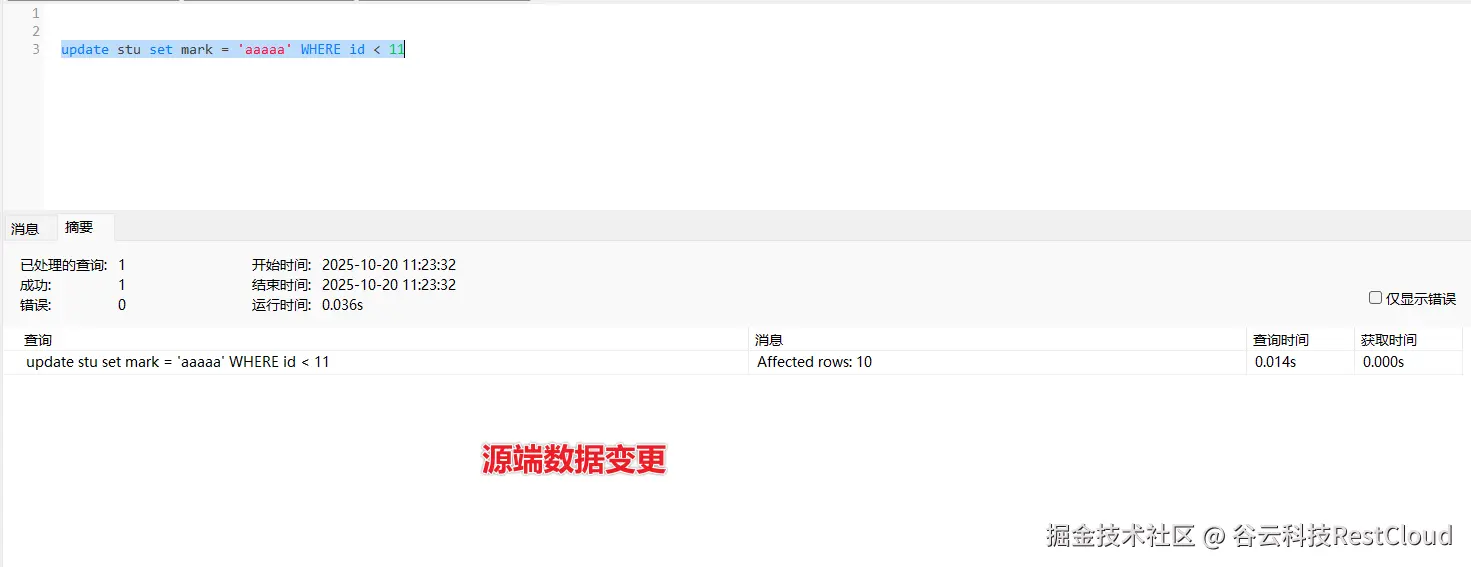
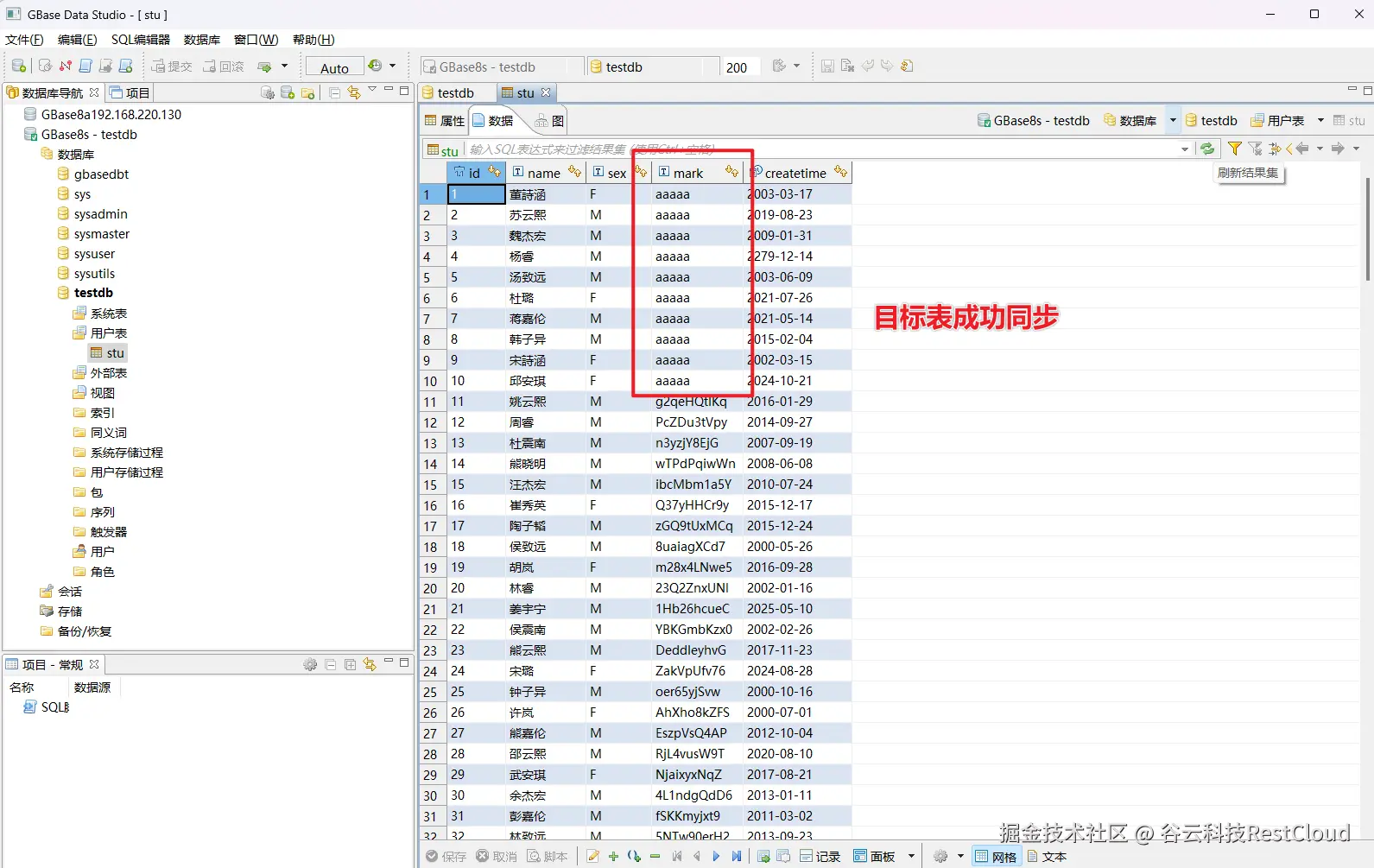
当源端数据发生变更,监听器便会监听到变更的增量数据。
四、最后
以上便是通过ETLCloud打通PostgreSql与南大通用数据库的流程,总而言之,从GBase数据库到最终的企业应用,ETL工具扮演了不可或缺的"数据桥梁"角色。它不仅能处理稳定可靠的全量数据迁移,更能胜任对实时性要求极高的增量数据同步。通过这样一套完整的数据流水线,企业得以将沉睡在数据库中的原始数据,高效、准确地转化为支撑业务决策、优化用户体验、驱动企业创新的宝贵资产,最终在激烈的市场竞争中赢得先机。