一,相关面试题
1.在海量数据里查询某一固定的前缀的key(阿里)
2.在生产上你是如何限制key */flushdb/flushall等危险命令以防止误删误用?(小红书)
3.MEMORY USAGE 命令你使用过吗?(美团)
4.BigKey问题,多大算big?你是如何发现的?如何删除?如何处理?
5.BigKey你是如何进行调优的?惰性释放lazyfree了解过吗?
6.在上生产上redis数据库中有100W条记录,你是如何遍历的?keys * 可以吗?
面试题的答案下面全都有欧!!!看完你就全明白了
二,MoreKey案例
2.1向redis中插入100W条测试数据
第一步:在Linux Bach下面插入100W条数据
bash
for((i=1;i<=100*10000;i++)); do echo "set k$i v$i" >> /tmp/redisTest.txt ;done;第二步:通过pipe管道命令向redis中灌入这100W条数据
bash
cat /tmp/redisTest.txt | /opt/redis-7.0.0/src/redis-cli -h 127.0.0.1 -p 6379 -a 密码 --pipe2.2 keys * 访问100W条数据

由图可知访问100W条数据所用的时间为10.93s(不同的电脑可能会用所不同),访问时间达到10.93s,相比于内存的运转时间,差距还是非常大的,使用此命令可能会导致redis宕机。
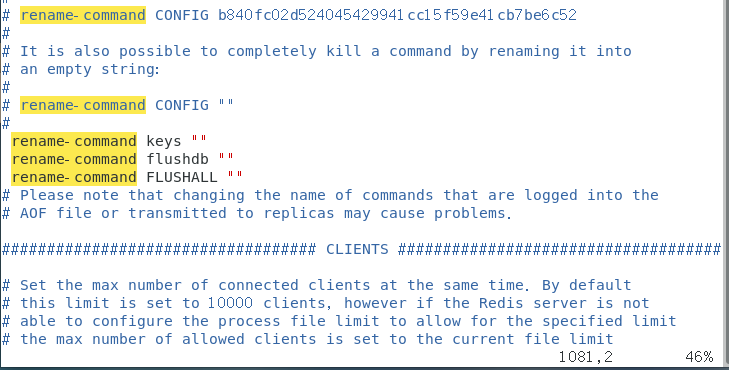
那么生产中如何进行keys *,flushdb,flushall等危险命令的使用呢?
答:修改redis.conf的配置文件,可以在redis中通过SECURITY进行相关配置如图所示
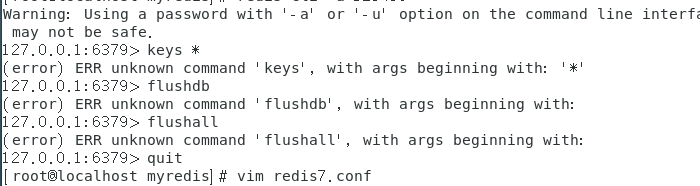
修改后重启redis数据库效果如下
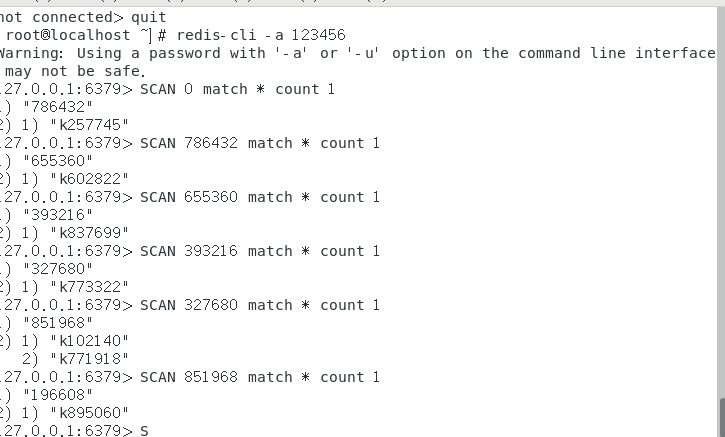
在上面我们提到当数据量过大的时候,不能用keys *命令来查询,那么我们改如何去进行查询呢?用什么命令?
答:SCAN命令来进行查询,此命令可以用来进行模糊查询,用来迭代数据库中的键。
用法讲解:SACN cursor MATCH pattern COUNT count 基于游标的迭代器,需要将上一一次迭代的游标作为下一次迭代的开始,直到游标返回0时代表一次迭代完成。一次返回的数量不可控,只能说是大约符合count值,支持模糊查询。
具体操作如下图
三,BigKey案例
3.1 BigKey多大才算大?

在阿里开发手册中明确提出,string类型的应该控制在10KB以内,hash,list,set,zset类型的元素个数不超过5000个。
*注意在一般情况下list最大存储元素一般为2的32次方-1个,但是没有人需要在value值中存储近40个值,并且这个值仅仅是理论值。set和zset类似。
3.2BigKey可能存在哪些危害?
内存分配不均匀,迁移困难;删除超时,大key做怪;网络流量阻塞;
3.3BigKey如何产生的呢?
一般情况下,不会有人去专门设置BigKey,BigKey一般存在社交类和汇总类中,比如某个明星的粉丝列表暴增,在一些年度财务报表统计当中,数据的累计增加。都会产生BigKey。
3.4 那么改如何发现BigKey呢?
发现BigKey常用的命令有两条:1.redis-cli -h 127.0.0.1 -p 6379 -a 111111 --bigkeys 2.MEMORY USAGE key。查看每个Key所占RAM的中字节数;第一种给出每种数据结构Top 1 bigkey,同时给出每种数据类型的键值个数+平均大小,但是想查询大于10kb的所有key,--bigkeys参数就无能为力了,需要用到memory usage来计算每个键值的字节数。
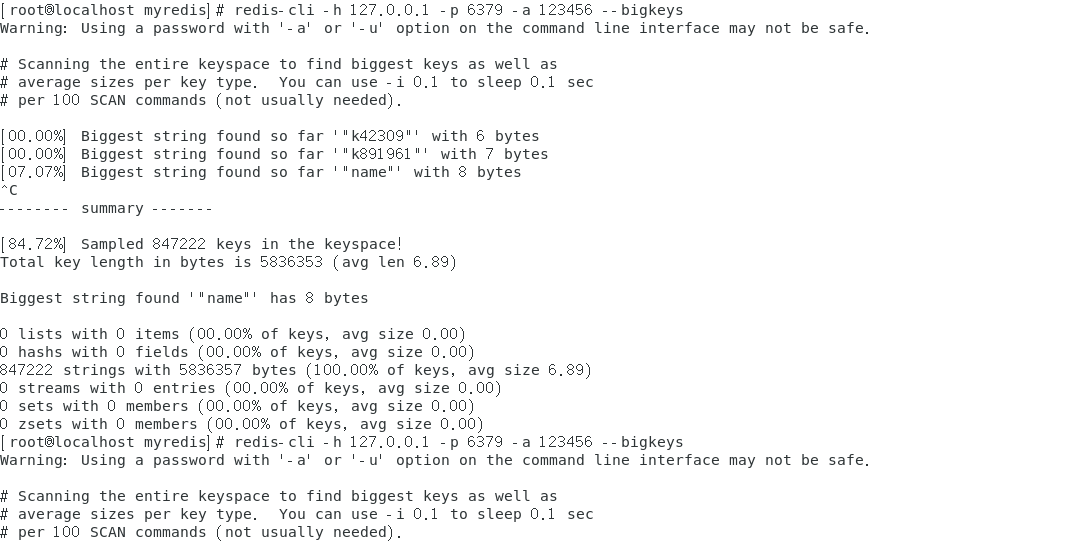

3.5 当BigKey产生的时候,我们改如何进行删除呢?

由阿里开发者手册可知,我们可以进行渐进式删除,那么什么叫渐进式删除呢?简单的来说就是一部分一部分删,比如custom:id 1000 name zhansan age 10 gender 男.........,这样的value我们可以先删除age 10 gender 男等相关字段,直到进行全部删除为止。
string:一般用del ,如果过于庞大用unlink
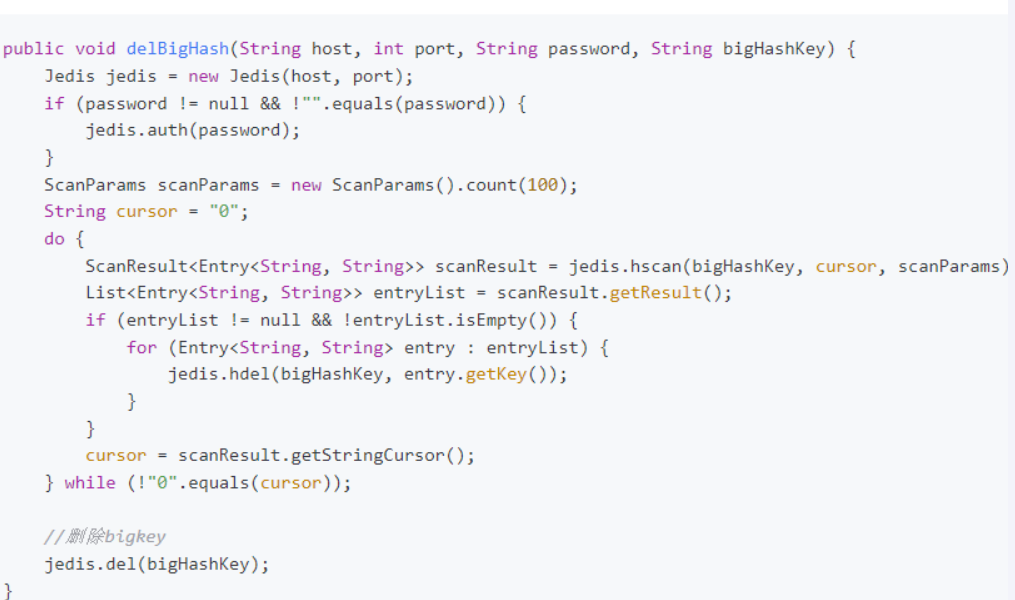
hash:每次获取少量的field-value,用hdel命令删除每个field:命令:HSCAN key cursor MATCH patternCOUNT count
代码
list:渐进式命令ltrim进行删除,命令ltrim key_name strat stop ;代码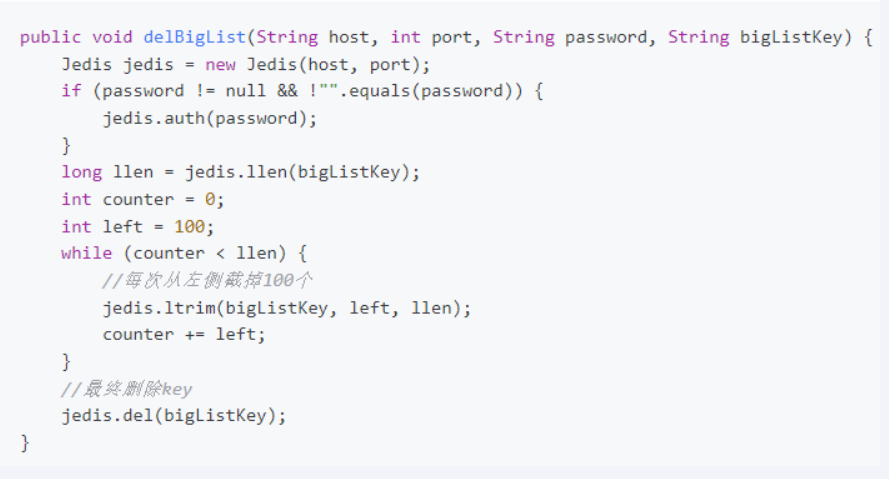
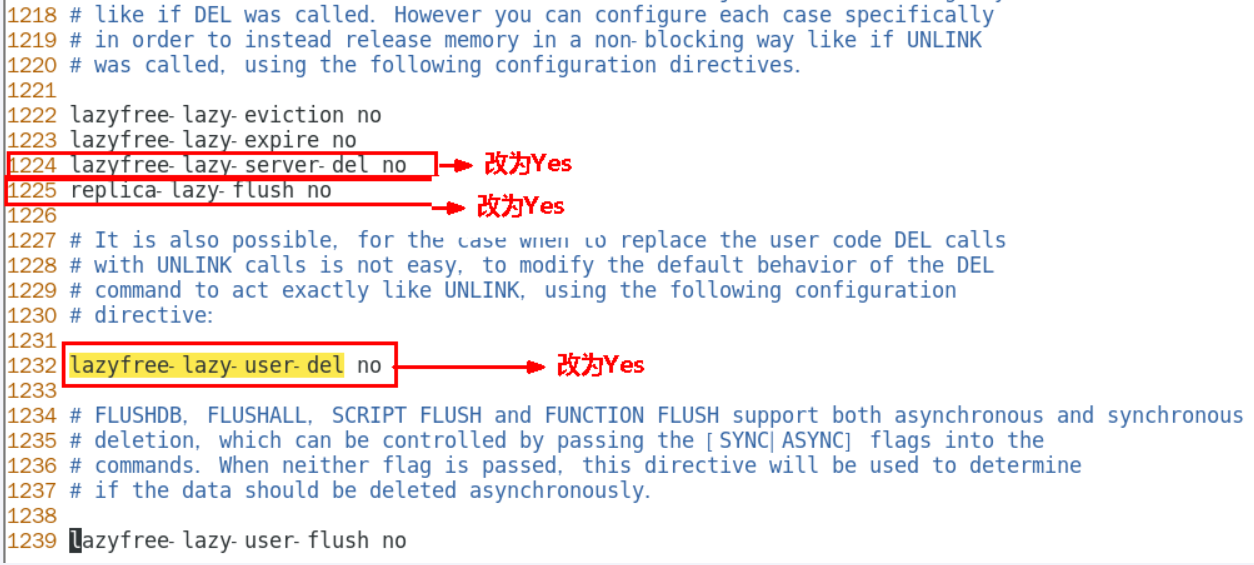
四.BigKey生产调优
在redis.conf中的 LAZY FREEIG中的配置进行相关说明。