在目标检测领域,YOLO 系列一直是 "速度与精度" 平衡的代名词,而 YOLOv4 更是将这一优势推向新高度。它不仅延续了系列 "快准狠" 的核心特质,还凭借 "单 GPU 可训练" 的亲民设计,让普通开发者也能触及目标检测的技术天花板。今天,我们就拆解 YOLOv4 的核心黑科技,看它如何用两大核心策略、N 种优化技巧,成为当年 CV 界的 "劳模级" 模型。
一、YOLOv4 凭什么 "出圈"?核心优势先睹为快
YOLOv4 的爆红并非偶然,而是精准击中了开发者的两大痛点:设备门槛高、精度提升难。其核心优势:
亲民政策 , 单GPU就能训练的非常好 , 接下来很多小模块都是这个出发点
两大核心方法 ,从数据层面和网络设计层面来进行改善,既提精度又保速度。
消融实验 ,几乎覆盖了当时所有主流优化方案的消融实验,每一个模块的效果都有数据支撑,不是 "玄学调参"。 感觉能做的都让他给做了 ,这工作量不轻 。
全部实验都是单GPU完成 ,不用太担心设备了
先看性能硬指标 ------ 在 V100 显卡上,YOLOv4 的 mAP(平均精度)远超 YOLOv3,同时保持实时推理速度(FPS),直接碾压同期的 EfficientDet、ASFF 等模型,妥妥的 "精度速度双冠军"。
二、Bag of Freebies:只加训练成本,不耗推理速度
"Bag of Freebies(BOF)" 是 YOLOv4 的 "数据魔法"------ 只在训练阶段增加计算量,推理时完全不耗时,却能让精度飙升。核心是数据增强 和损失函数优化,我们挑最关键的技巧拆解:
1. 数据增强:让模型 "见多识广"
YOLOv4 的数据集增强不是简单的翻转缩放,而是一套 "组合拳",调整亮度、 对比度、 色调、 随机缩放、 剪切、 翻转、 旋转,让模型面对复杂场景时更鲁棒:
Mosaic 拼接:参考 CutMix,将 4 张不同图像随机拼接成 1 张训练图,瞬间扩大数据集多样性,还能让模型同时学习多个目标场景。
Random Erase/Hide and Seek:前者用随机像素或均值像素覆盖图像局部,后者按概率隐藏部分补丁,强迫模型关注全局特征而非局部细节。
Self-adversarial Training(SAT):给图像 "加噪音"------ 先让模型对图像生成对抗性扰动,再用扰动后的图像训练,相当于 "故意给模型出难题",提升泛化能力。
2. 正则化:防止模型 "过度自信"
模型训练常犯 "过拟合" 的错,YOLOv4 用两大正则化技巧 "降温":
DropBlock:比传统 Dropout 更聪明 ------ 不再随机丢弃单个像素,而是丢弃一整个区域,避免模型依赖局部像素 "作弊",迫使它学习更全局的特征。
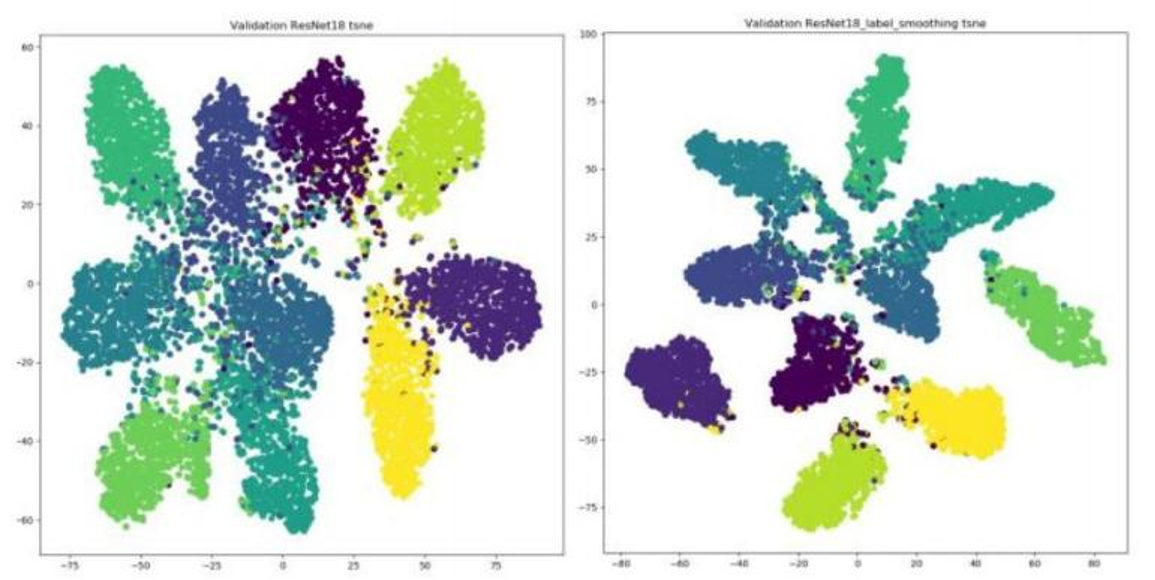
Label Smoothing:解决模型 "自信爆棚" 的问题。比如原本标签是(0,1)(非猫即狗),平滑后变成(0.05, 0.95),让模型明白 "分类没有绝对",减少过拟合。
使用之后效果分析(右图) :簇内更紧密 , 簇间更分离
3. 损失函数:从 "IOU" 到 "CIOU" 的精度飞跃
目标检测的核心是 "框准目标",而损失函数决定了模型如何学习 "框的位置"。YOLOv4 迭代了三代损失函数,解决了 IOU 的天生缺陷:
IOU 损失:基础款,但两个框不重叠时 IOU=0,梯度消失,模型无法学习。
GIOU 损失 :引入 "最小封闭框 C",即使框不重叠,也能通过 C 与两框的面积差计算损失,让模型朝着 "靠近目标" 的方向优化。公式: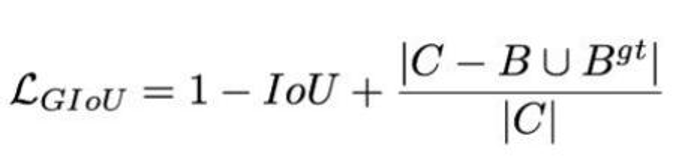
DIOU/CIOU 损失:GIOU 只看面积,DIOU 额外加入 "中心点距离",让框更快对齐目标;CIOU 再增加 "长宽比" 约束,彻底解决 "框对不准形状" 的问题,最终实现更高的定位精度。DIOU 公式:
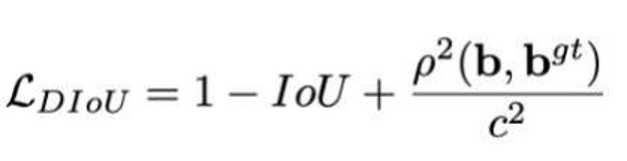 分子计算预测框与真实框的中心点欧式距离d,分母是能覆盖预测框与真实框的最小BOX的对角线长度c。
分子计算预测框与真实框的中心点欧式距离d,分母是能覆盖预测框与真实框的最小BOX的对角线长度c。
CIOU 公式: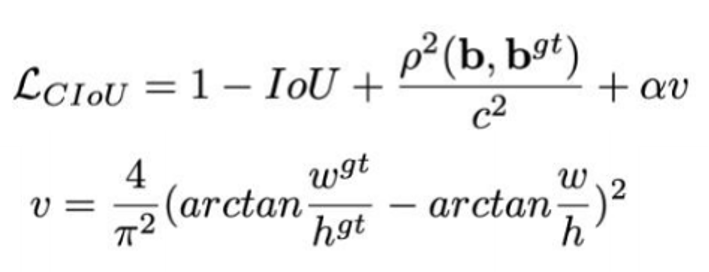
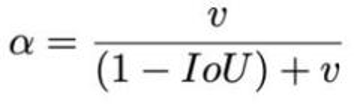
损失函数必须考虑三个几何因素: 重叠面积 , 中心点距离 , 长宽比,其中α可以当做权重参数。