在目标检测领域,YOLO 系列一直是绕不开的经典框架,而 YOLOv3 更是凭借对小目标检测的优化,成为众多开发者的首选模型。本文将从性能对比、核心改进、技术细节三个维度,带您全面拆解 YOLOv3 的创新之处,看懂它为何能在当年掀起目标检测热潮。
一、先看硬实力:YOLOv3 性能碾压同级模型
评判一个目标检测模型,mAP(平均精度均值) 和推理速度是两大核心指标。从 COCO 数据集的测试结果来看,YOLOv3 在 "精度 - 速度" 平衡上表现惊艳,尤其是小目标检测能力远超同期模型。
YOLOv3 最大的改进就是网络结构,使其更适合小目标检测 特征做的更细致,融入多持续特征图信息来预测不同规格物体 先验框更丰富了,3种scale,每种3个规格,一共9种 softmax改进,预测多标签任务
二、核心改进:四大创新让 YOLOv3 "脱胎换骨"
YOLOv3 的性能突破,源于对网络结构、特征处理、先验框设计的全方位优化,其中四大改进直接解决了前代模型的痛点。
2.1 多尺度特征融合:专门针对小目标检测
这是 YOLOv3 最关键的改进。为了检测不同大小的物体,模型设计了3 个 scale(尺度) 的特征图,分别对应不同尺寸的目标:
13×13 特征图 :感受野大,负责检测大目标(如汽车、行人);
26×26 特征图 :感受野中等,负责检测中目标(如手机、书本);
52×52 特征图 :感受野小,专门检测小目标(如硬币、按钮)。
通过将高层(语义信息丰富)与低层(位置信息精准)特征融合,YOLOv3 彻底解决了前代模型 "漏检小目标" 的问题,这也是它在小目标场景中表现出色的核心原因。
2.2 scale 变换:解锁特征图潜力的经典方法
在计算机视觉的目标检测等任务中,scale 变换是极为关键的技术,它关乎对不同尺度目标的有效识别。这里展示了 scale 变换的两种经典方法,为理解多尺度特征处理提供了直观视角。
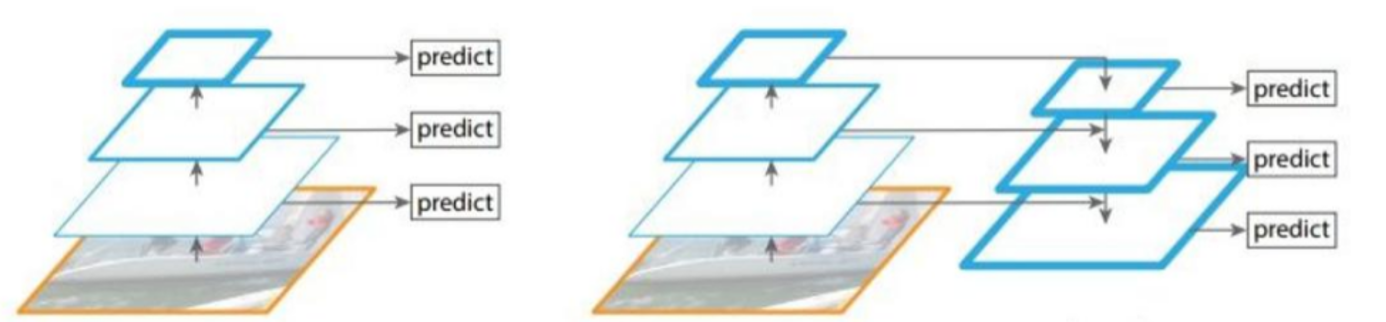
左图呈现的是对不同特征图分别利用的方式。可以看到,从原始图像衍生出的不同层级特征图,各自独立地进行 "predict(预测)" 操作。每一层特征图都有其独特的优势,比如浅层特征图可能包含更丰富的细节信息,利于小目标的定位;深层特征图则蕴含更抽象的语义信息,对大目标的类别判断更有帮助。这种分别利用的方式,能让每一层特征图的潜力在对应尺度的目标检测中得到发挥,不过,由于各层特征图之间缺乏信息交互,可能会在跨尺度目标检测时出现精度不足的情况。
右图展示的是不同特征图融合后进行预测的方法。与左图不同,它并非让各特征图孤立工作,而是通过一定的技术手段,将不同层级的特征图融合在一起。这样做的好处是,能够整合浅层特征的细节信息和深层特征的语义信息,使融合后的特征图兼具多方面的优势。在进行预测时,融合后的特征能更全面地描述目标,无论是小目标还是大目标,都能在融合特征中找到更精准的匹配信息,从而极大提升目标检测的精度,尤其是在处理复杂场景下的多尺度目标时,优势更为明显。
总的来说,这两种 scale 变换的经典方法各有特点,分别利用更注重单一层级的高效,融合后预测则更强调多层级信息的协同,它们为后续多尺度特征处理技术的发展奠定了基础,也让我们更清晰地认识到特征融合在提升计算机视觉任务性能中的重要性。
2.3 残差连接:解决深层网络梯度消失
YOLOv3 引入 ResNet 的残差连接思想,通过 "F (x)+x" 的结构(即输出 = 卷积结果 + 输入),让网络能堆叠更多层(最多 53 层)进行特征提取:
避免深层网络的梯度消失问题,保证模型能有效学习到复杂特征;
提升特征复用效率,让低层细节信息能传递到高层,进一步优化小目标检测。
如今残差连接已成为主流网络的标配,但在当时,这一改进让 YOLOv3 的特征提取能力大幅超越前代。
2.4 先验框升级:从 5 种到 9 种,适配更多场景
YOLOv2 首次引入先验框(Anchor Box)提升定位精度,而 YOLOv3 将先验框数量扩展到 9 种,且为不同尺度特征图匹配专属先验框:
13×13 特征图:匹配大尺寸先验框(116×90、156×198、373×326);
26×26 特征图:匹配中尺寸先验框(30×61、62×45、59×119);
52×52 特征图:匹配小尺寸先验框(10×13、16×30、33×23);
9 种先验框通过 K-means 聚类 COCO 数据集得到,能覆盖绝大多数目标的宽高比例,减少模型训练难度。
2.5 Softmax 替代:支持多标签检测
前代 YOLO 使用 Softmax 函数输出类别概率,默认 "一个目标只有一个类别",但实际场景中存在 "多标签目标"(如 "红色汽车" 同时属于 "汽车" 和 "红色物体")。
YOLOv3 改用 Logistic 激活函数,为每个类别单独输出 "是否属于该类" 的概率;
配合交叉熵损失函数,实现真正的多标签检测,更贴合真实业务需求。
三、网络架构细节:无池化、全卷积的高效设计
YOLOv3 的网络架构摒弃了传统的池化层和全连接层,采用全卷积设计,这一设计减少了特征信息在传递过程中的损耗,让特征提取更高效、完整。下采样不再依赖传统池化,而是通过设置卷积的步长(stride)为 2 来实现,在缩小特征图尺寸的同时,更好地保留了图像细节。
这一设计通过以下细节实现高效特征提取与下采样:
下采样靠 Stride=2 的卷积:传统池化会丢失细节,YOLOv3 用步长为 2 的卷积层实现下采样,在缩小特征图尺寸的同时,保留更多位置信息,对小目标检测友好;
特征图尺寸关联输入: 采用 3 种不同尺度的特征图,搭配更多先验框,能够精准适配大、中、小各类目标的检测需求,让不同尺寸的目标都能被有效捕捉。
特征融合用 Concat:将高层特征上采样后,与低层特征通过 "拼接(Concat)" 融合,而非简单相加,确保两种特征的信息都能被充分利用。
四、总结:为何 YOLOv3 至今仍不过时?
YOLOv3 的成功,在于它没有追求 "单点突破",而是将 "残差连接、多尺度融合、先验框优化" 等当时的前沿技术,以极高的兼容性整合到一起,实现了 "速度 + 精度" 的最优平衡。
即使现在有 YOLOv5、v7、v8 等后续版本,YOLOv3 依然是许多开发者入门目标检测的首选 ------ 它的网络结构更简洁,原理更容易理解,代码实现门槛更低,同时性能足以支撑大部分工业场景。如果你想学习目标检测,从 YOLOv3 入手,绝对是性价比最高的选择。