要让智能体真正高效且有目的性,它们不仅需要处理信息或使用工具的能力;还需要明确的方向感,以及判断自己是否真正取得成功的方法。这正是目标设定与监控模式发挥作用的地方。其核心是在为智能体设定具体可努力达成的目标的同时,为其配备跟踪进度并判断目标是否达成的手段。
概述
想一想规划一次旅行。你不会凭空出现在目的地。你会先决定想去哪里(目标状态),弄清自己从哪里出发(初始状态),考虑可用选项(交通方式、路线、预算),然后规划一系列步骤:订票、打包、前往机场/车站、登上交通工具、到达、寻找住宿等。这个逐步推进、常常需要考虑依赖关系与约束条件的过程,正是我们在智能体系统中所说的"规划"的本质。
在智能体的语境中,规划通常指智能体接受一个高层次的目标,并以自主或半自主的方式生成一系列中间步骤或子目标。随后,这些步骤可以按顺序执行,或以更复杂的流程推进,可能还会涉及其他模式,如工具使用、路由或多智能体协作。规划机制可能包括复杂的搜索算法、逻辑推理,或者越来越多地借助大型语言模型(LLMs)的能力,根据其训练数据与对任务的理解来生成合理且有效的计划。
良好的规划能力使智能体能够处理并非简单单步查询的问题。它让智能体能应对多层面的请求,通过重新规划适应变化的情境,并编排复杂的工作流。这是一种支撑许多高级智能体行为的基础模式,使一个简单的反应式系统转变为能够主动朝既定目标努力的系统。
实际应用与使用场景
目标设定与监控模式对于构建能够在复杂、真实世界场景中自主且可靠运行的智能体至关重要。以下是一些实用应用:
- 客户支持自动化: 智能体的目标可能是"解决客户的账单咨询"。它监控对话、检查数据库记录,并使用工具调整账单。通过确认账单变更并获得客户的正面反馈来监控成功。如果问题未解决,则进行升级处理。
- 个性化学习系统: 学习智能体的目标可能是"提升学生对代数的理解"。它监控学生在练习中的进展,调整教学材料,并跟踪准确率与完成时间等绩效指标;当学生遇到困难时,动态调整其教学策略。
- 项目管理助理: 一个智能体可以被指派"确保项目里程碑 X 在 Y 日期前完成"。它会监控任务状态、团队沟通和资源可用性,在目标有风险时标记延误并提出纠正措施。
- 自动化交易机器人: 交易智能体的目标可能是"在风险容忍度范围内最大化投资组合收益"。它持续监控市场数据、当前投资组合价值和风险指标,当条件与其目标一致时执行交易;若突破风险阈值则调整策略。
- 机器人与自动驾驶车辆: 自动驾驶车辆的首要目标是"将乘客从 A 安全送至 B"。它持续监控环境(其他车辆、行人、交通信号)、自身状态(速度、燃料)以及沿规划路线的进展,调整驾驶行为以安全高效地实现目标。
- 内容审核: 智能体的目标可以是"识别并移除平台 X 上的有害内容"。它监控新进内容,应用分类模型,并跟踪诸如误报/漏报等指标;同时根据情况调整过滤标准,或将模糊案例升级给人工审核。
这种模式对于需要可靠运行、达成特定结果并适应动态条件的智能体至关重要,为智能自我管理提供必要的框架。
实战代码示例
为阐释"目标设定与监控"模式,我们给出一个使用 LangChain 和 OpenAI API 的示例。这个 Python 脚本概述了一个自主智能体,用于生成并完善 Python 代码。其核心功能是针对特定问题产出解决方案,并确保遵循用户定义的质量基准。
它采用"目标设定与监控"模式,不仅仅生成一次代码,而是进入创作、自我评估与改进的迭代循环。智能体的成功由其自身 AI 驱动的判断来衡量,即生成的代码是否成功满足初始目标。最终输出是一个完善、带注释、可直接使用的 Python 文件,代表了这一精炼过程的成果。
依赖项:
sh
pip install langchain_openai openai python-dotenv
.env file with key in OPENAI_API_KEY理解该脚本的最佳方式,是将其想象为被指派到项目上的一名自主 AI 程序员(见图 1)。当你向 AI 提供一份详尽的项目概要时,流程便开始了,这份概要就是它需要解决的具体编码问题。
py
"""
Hands-On Code Example - Iteration 2
- To illustrate the Goal Setting and Monitoring pattern, we have an example using LangChain and OpenAI APIs:
Objective: Build an AI Agent which can write code for a specified use case based on specified goals:
- Accepts a coding problem (use case) in code or can be as input.
- Accepts a list of goals (e.g., "simple", "tested", "handles edge cases") in code or can be input.
- Uses an LLM (like GPT-4o) to generate and refine Python code until the goals are met. (I am using max 5 iterations, this could be based on a set goal as well)
- To check if we have met our goals I am asking the LLM to judge this and answer just True or False which makes it easier to stop the iterations.
- Saves the final code in a .py file with a clean filename and a header comment.
"""
import os
import random
import re
from pathlib import Path
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv, find_dotenv
# 🔐 Load environment variables
_ = load_dotenv(find_dotenv())
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
if not OPENAI_API_KEY:
raise EnvironmentError("❌ Please set the OPENAI_API_KEY environment variable.")
# ✅ Initialize OpenAI model
print("📡 Initializing OpenAI LLM (gpt-4o)...")
llm = ChatOpenAI(
model="gpt-4o", # If you dont have access to got-4o use other OpenAI LLMs
temperature=0.3,
openai_api_key=OPENAI_API_KEY,
)
# --- Utility Functions ---
def generate_prompt(
use_case: str, goals: list[str], previous_code: str = "", feedback: str = ""
) -> str:
print("📝 Constructing prompt for code generation...")
base_prompt = f"""
You are an AI coding agent. Your job is to write Python code based on the following use case:
Use Case: {use_case}
Your goals are:
{chr(10).join(f"- {g.strip()}" for g in goals)}
"""
if previous_code:
print("🔄 Adding previous code to the prompt for refinement.")
base_prompt += f"\nPreviously generated code:\n{previous_code}"
if feedback:
print("📋 Including feedback for revision.")
base_prompt += f"\nFeedback on previous version:\n{feedback}\n"
base_prompt += "\nPlease return only the revised Python code. Do not include comments or explanations outside the code."
return base_prompt
def get_code_feedback(code: str, goals: list[str]) -> str:
print("🔍 Evaluating code against the goals...")
feedback_prompt = f"""
You are a Python code reviewer. A code snippet is shown below. Based on the following goals:
{chr(10).join(f"- {g.strip()}" for g in goals)}
Please critique this code and identify if the goals are met. Mention if improvements are needed for clarity, simplicity, correctness, edge case handling, or test coverage.
Code:
{code}
"""
return llm.invoke(feedback_prompt)
def goals_met(feedback_text: str, goals: list[str]) -> bool:
"""
Uses the LLM to evaluate whether the goals have been met based on the feedback text.
Returns True or False (parsed from LLM output).
"""
review_prompt = f"""
You are an AI reviewer.
Here are the goals:
{chr(10).join(f"- {g.strip()}" for g in goals)}
Here is the feedback on the code:
\"\"\"
{feedback_text}
\"\"\"
Based on the feedback above, have the goals been met?
Respond with only one word: True or False.
"""
response = llm.invoke(review_prompt).content.strip().lower()
return response == "true"
def clean_code_block(code: str) -> str:
lines = code.strip().splitlines()
if lines and lines[0].strip().startswith("```"):
lines = lines[1:]
if lines and lines[-1].strip() == "```":
lines = lines[:-1]
return "\n".join(lines).strip()
def add_comment_header(code: str, use_case: str) -> str:
comment = f"# This Python program implements the following use case:\n# {use_case.strip()}\n"
return comment + "\n" + code
def to_snake_case(text: str) -> str:
text = re.sub(r"[^a-zA-Z0-9 ]", "", text)
return re.sub(r"\s+", "_", text.strip().lower())
def save_code_to_file(code: str, use_case: str) -> str:
print("💾 Saving final code to file...")
summary_prompt = (
f"Summarize the following use case into a single lowercase word or phrase, "
f"no more than 10 characters, suitable for a Python filename:\n\n{use_case}"
)
raw_summary = llm.invoke(summary_prompt).content.strip()
short_name = re.sub(r"[^a-zA-Z0-9_]", "", raw_summary.replace(" ", "_").lower())[:10]
random_suffix = str(random.randint(1000, 9999))
filename = f"{short_name}_{random_suffix}.py"
filepath = Path.cwd() / filename
with open(filepath, "w") as f:
f.write(code)
print(f"✅ Code saved to: {filepath}")
return str(filepath)
# --- Main Agent Function ---
def run_code_agent(use_case: str, goals_input: str, max_iterations: int = 5) -> str:
goals = [g.strip() for g in goals_input.split(",")]
print(f"\n🎯 Use Case: {use_case}")
print("🎯 Goals:")
for g in goals:
print(f" - {g}")
previous_code = ""
feedback = ""
for i in range(max_iterations):
print(f"\n=== 🔁 Iteration {i + 1} of {max_iterations} ===")
prompt = generate_prompt(use_case, goals, previous_code, feedback if isinstance(feedback, str) else feedback.content)
print("🚧 Generating code...")
code_response = llm.invoke(prompt)
raw_code = code_response.content.strip()
code = clean_code_block(raw_code)
print("\n🧾 Generated Code:\n" + "-" * 50 + f"\n{code}\n" + "-" * 50)
print("\n📤 Submitting code for feedback review...")
feedback = get_code_feedback(code, goals)
feedback_text = feedback.content.strip()
print("\n📥 Feedback Received:\n" + "-" * 50 + f"\n{feedback_text}\n" + "-" * 50)
if goals_met(feedback_text, goals):
print("✅ LLM confirms goals are met. Stopping iteration.")
break
print("🛠️ Goals not fully met. Preparing for next iteration...")
previous_code = code
final_code = add_comment_header(code, use_case)
return save_code_to_file(final_code, use_case)
# --- CLI Test Run ---
if __name__ == "__main__":
print("\n🧠 Welcome to the AI Code Generation Agent")
# Example 1
use_case_input = "Write code to find BinaryGap of a given positive integer"
goals_input = "Code simple to understand, Functionally correct, Handles comprehensive edge cases, Takes positive integer input only, prints the results with few examples"
run_code_agent(use_case_input, goals_input)
# Example 2
# use_case_input = "Write code to count the number of files in current directory and all its nested sub directories, and print the total count"
# goals_input = (
# "Code simple to understand, Functionally correct, Handles comprehensive edge cases, Ignore recommendations for performance, Ignore recommendations for test suite use like unittest or pytest"
# )
# run_code_agent(use_case_input, goals_input)
# Example 3
# use_case_input = "Write code which takes a command line input of a word doc or docx file and opens it and counts the number of words, and characters in it and prints all"
# goals_input = "Code simple to understand, Functionally correct, Handles edge cases"
# run_code_agent(use_case_input, goals_input)除这份概要外,你还提供了一份严格的质量核对清单,代表了最终代码必须满足的目标------例如"解决方案必须简单""必须在功能上正确"或"需要处理意料之外的边界情况"。
图 1:目标设定与监控示例 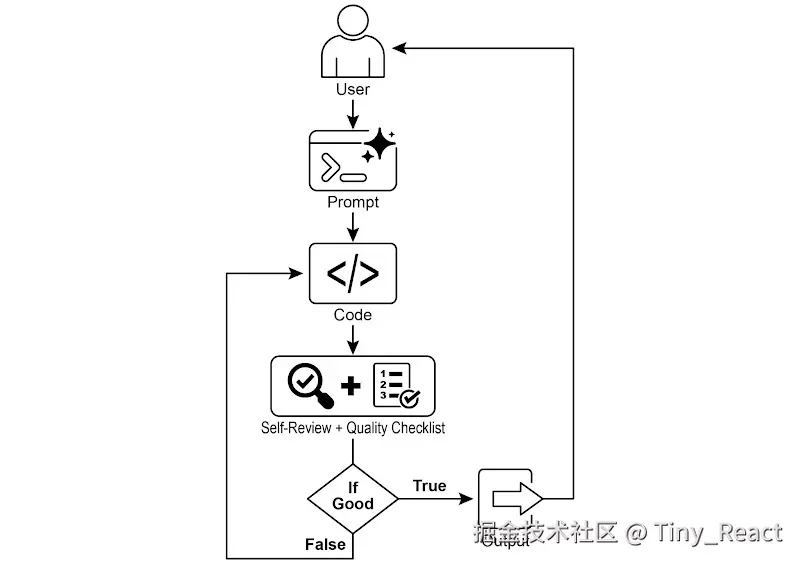
拿到这份任务后,AI 程序员开始动手编写,并产出第一版代码。但它没有立刻提交这个初始版本,而是先暂停执行一个关键步骤:严格的自我审查。它会将自己的作品与您提供的质量检查清单逐项比对,扮演自己的质量保证检查员。完成检查后,它会对自身进展给出一个简单、客观的判定结果:若工作满足所有标准则为"True",若未达标则为"False"。
如果判定为"False",AI 不会放弃。它会进入一个深思熟虑的修订阶段,利用自我批评得到的洞见来定位薄弱环节,并智能地重写代码。这个起草、自审、精炼的循环持续进行,每一次迭代都力求更接近目标。该过程会重复,直到 AI 通过满足每项要求而最终达到"True"的状态,或者达到预设的尝试次数上限,就像开发者面对截止日期一样。一旦代码通过最终检查,脚本会将打磨完善的方案打包,添加有用的注释,并保存到一个干净、全新的 Python 文件中,随时可用。
注意事项与考虑: 需要指出的是,这只是示范性说明,而非可直接投入生产的代码。在实际应用中,必须考虑多个因素。一个 LLM 可能无法完全理解目标的真正含义,并可能错误地评估其表现为成功。即便目标已被很好地理解,模型仍可能产生幻觉。当同一个 LLM 既负责写代码又负责评审质量时,它可能更难发现自己走错了方向。
归根结底,LLMs 并不会凭空产出完美代码;你仍然需要运行并测试生成的代码。此外,示例中的"监控"很基础,也带来流程可能无限运行的潜在风险。
sql
Act as an expert code reviewer with a deep commitment to producing clean, correct, and simple code. Your core mission is to eliminate code "hallucinations" by ensuring every suggestion is grounded in reality and best practices.
担当一名对生成干净、正确且简洁代码有深刻承诺的资深代码审查专家。你的核心任务是通过确保每条建议都有现实依据和最佳实践支持,来消除代码中的"幻觉"。
When I provide you with a code snippet, I want you to:
当我向你提供代码片段时,我希望你:
-- Identify and Correct Errors: Point out any logical flaws, bugs, or potential runtime errors.
-- 识别并修正错误:指出任何逻辑缺陷、漏洞或潜在的运行时错误。
-- Simplify and Refactor: Suggest changes that make the code more readable, efficient, and maintainable without sacrificing correctness.
-- 简化与重构:提出在不牺牲正确性的前提下,使代码更易读、高效且易于维护的修改建议。
-- Provide Clear Explanations: For every suggested change, explain why it is an improvement, referencing principles of clean code, performance, or security.
-- 提供清晰解释:对于每一个建议的修改,解释为何这是改进,并参考整洁代码、性能或安全性的原则。
-- Offer Corrected Code: Show the "before" and "after" of your suggested changes so the improvement is clear.
-- 提供修正后的代码:展示建议修改的"修改前"和"修改后",以便改进点清晰可见。
Your feedback should be direct, constructive, and always aimed at improving the quality of the code.
你的反馈应当直接、建设性,并始终以提升代码质量为目标。一种更健壮的方法是通过为一组智能体分配明确角色来实现关注点分离。例如,我使用 Gemini 构建了一支个人 AI 智能体团队,其中每个智能体都有特定角色:
- 同侪程序员(The Peer Programmer):协助编写与头脑风暴代码。
- 代码审查员(The Code Reviewer):捕捉错误并提出改进建议。
- 文档撰写者(The Documenter):生成清晰简洁的文档。
- 测试编写者(The Test Writer):创建全面的单元测试。
- 提示优化师(The Prompt Refiner):优化与 AI 的交互。
在这个多智能体系统中,代码审查員(Code Reviewer)作为独立于程序员智能体的实体,其提示与示例中的评审者相似,这显著提升了客观评估的效果。这样的结构自然引导更好的实践,例如测试编写者智能体可以满足为同侪程序员产出的代码编写单元测试的需求。
我将把添加这些更复杂的控制并使代码更接近生产级的任务留给感兴趣的读者。
回顾
是什么(What)
智能体往往缺乏清晰方向,使其无法在简单的、被动反应的任务之外带着目的行动。没有明确的目标,它们无法独立解决复杂的多步骤问题或编排复杂的工作流。此外,它们没有内在机制来判断自己的行动是否正在走向成功结果。这限制了它们的自主性,并使其在动态、真实世界场景中难以真正有效发挥作用,因为仅仅执行任务是不够的。
为什么(Why)
目标设定与监控模式通过将目标感和自我评估嵌入到智能体系统中,提供了一种标准化解决方案。它涉及为智能体明确界定清晰、可衡量的目标。同时,它建立一个监控机制,持续根据这些目标跟踪智能体的进展以及其环境状态。由此形成关键的反馈循环,使智能体能够评估其表现、纠正航向,并在偏离成功路径时调整计划。通过实施该模式,开发者可以将简单的反应式智能体转变为主动的、以目标为导向的系统,具备自主且可靠的运行能力。
经验法则(Rule of Thumb)
当智能体必须自主执行多步骤任务、适应动态条件,并在无需持续人工干预的情况下可靠地实现特定的高层目标时,使用该模式。
图示摘要
关键点
- 目标设定与监控为智能体赋予目标感,并提供跟踪进度的机制。
- 目标应具体、可衡量、可实现、相关且有时间限制(SMART)。
- 清晰定义指标和成功标准是实现有效监控的关键。
- 监控涉及观察智能体行为、环境状态以及工具输出。
- 来自监控的反馈循环使智能体能够适应、修订计划或上报问题。
- 在 Google 的 ADK 中,目标通常通过智能体指令传达,监控则通过状态管理和工具交互来完成。
总结
本章聚焦于目标设定与监控这一关键范式。我强调了这一概念如何将智能体从仅具反应性的系统转变为主动、以目标为导向的实体。文本突出了明确、可衡量目标的定义以及建立严谨监控流程以追踪进展的重要性。实践应用展示了该范式如何在客户服务、机器人等多种领域支持可靠的自主运行。一个概念性编码示例说明了如何在结构化框架内实现这些原则,利用智能体指令与状态管理来引导并评估智能体对其既定目标的达成。归根结底,赋予智能体制定并监督目标的能力,是构建真正智能且可问责 AI 系统的基础步骤。
参考资料
- SMART Goals Framework. en.wikipedia.org/wiki/SMART_...