InnoDB的聚簇索引和非聚簇索引工作原理
- 聚簇索引:决定了数据行在磁盘上的物理存储顺序。一张表有且只有一个聚簇索引。
- 非聚簇索引(二级索引):是独立于聚簇索引的额外索引结构,它保存的是指向数据行的"指针"。
一、工作原理
1. 聚簇索引
-
如何工作?
- 聚簇索引的叶子节点直接存储了整个数据行。
- 当你通过聚簇索引的键(通常是主键)查询时,InnoDB只需在索引的B+树中进行一次查找,到达叶子节点后,就直接拿到了完整的数据行,效率非常高。
- 因为数据行是按聚簇索引键的顺序物理存储的,所以范围查询(如
BETWEEN,>,<)和排序(ORDER BY)在主键上进行时,效率也很高,因为读取的是连续的磁盘块。
-
示例:
假设我们有一个
users表,以id为主键(即聚簇索引)。sqlSELECT * FROM users WHERE id = 5;InnoDB会从B+树的根节点开始,找到
id=5所在的叶子节点,然后直接从该节点中取出整行数据返回。 -
聚簇索引的选取规则:
- 如果表定义了主键(PRIMARY KEY),则主键就是聚簇索引。
- 如果没有主键,则选择第一个唯一的非空索引(UNIQUE NOT NULL)作为聚簇索引。
- 如果以上都没有,InnoDB会隐式地创建一个名为
GEN_CLUST_INDEX的隐藏聚簇索引(通常是自增的ROWID)。
2. 非聚簇索引(二级索引)
-
如何工作?
- 非聚簇索引的叶子节点不包含完整的数据行 ,它只存储了两部分内容:
a. 该索引自身的列值
b. 对应数据行的聚簇索引键(主键值) - 当你通过非聚簇索引查询时,InnoDB会先遍历非聚簇索引的B+树,找到目标记录的叶子节点,从而获得该记录的主键值。
- 然后,InnoDB再拿着这个主键值 ,回到聚簇索引 的B+树中再查找一次,最终在聚簇索引的叶子节点拿到完整的数据行。这个过程被称为 回表。
- 非聚簇索引的叶子节点不包含完整的数据行 ,它只存储了两部分内容:
-
示例:
假设在
users表的email列上有一个非聚簇索引。sqlSELECT * FROM users WHERE email = 'alice@example.com';- InnoDB先在
email索引的B+树中查找'alice@example.com'。 - 在
email索引的叶子节点上,找到了email = 'alice@example.com'和对应的主键值,比如id = 5。 - 然后,InnoDB再以
id = 5为条件,回到聚簇索引(主键索引)的B+树中进行查找。 - 最终在聚簇索引的叶子节点上拿到
id=5的完整用户数据。
- InnoDB先在
-
覆盖索引优化:
如果查询的列都包含在非聚簇索引中,InnoDB就不需要回表。
sqlSELECT id, email FROM users WHERE email = 'alice@example.com';在这个查询中,
id和email在email索引的叶子节点上都能直接拿到,所以引擎在email索引树中查找到结果后就直接返回了,避免了二次查找,性能极高。
二、物理存储上的区别
这是理解两者区别的关键,我们可以通过下图来直观地理解它们的物理存储结构和工作流程:
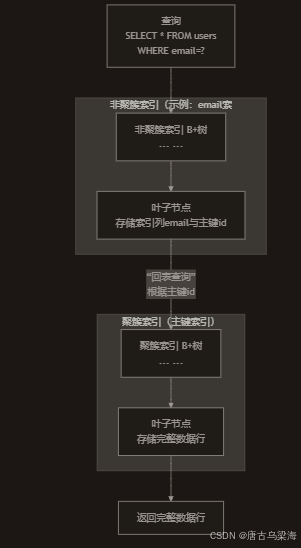
如上图所示,它们的物理存储区别主要体现在B+树的叶子节点所存放的内容上:
| 特性 | 聚簇索引 | 非聚簇索引 |
|---|---|---|
| 叶子节点内容 | 存储完整的Data Page(数据页),即整行数据。 | 存储索引键的列值 + 对应的主键值。 |
| 索引数量 | 每张表有且仅有一个。 | 每张表可以有多个。 |
| 数据物理顺序 | 与索引的逻辑顺序一致。 | 与索引的逻辑顺序不一致。数据的物理顺序只由聚簇索引决定。 |
| 依赖关系 | 独立存在,是数据的存储方式。 | 依赖于聚簇索引。它通过存储主键值来"指向"数据。 |
| 查询效率 | 主键查询极快,一次B+树查找即可。 | 普通查询通常需要两次B+树查找(除非覆盖索引)。 |
总结与最佳实践
- 理解"回表":非聚簇索引查询比主键查询慢的根本原因在于可能需要回表。优化查询的关键之一就是尽量使用覆盖索引,避免回表。
- 主键的选择非常重要 :
- 主键应尽可能短(因为所有二级索引都包含主键值,过长的主键会导致二级索引占用更大空间)。
- 最好使用自增整数(AUTO_INCREMENT)。自增主键的插入总是在末尾进行,不会导致频繁的页分裂和碎片产生。而使用UUID等随机值作为主键,会导致频繁的页分裂,影响插入性能并产生碎片。
- 索引设计权衡:非聚簇索引能加速查询,但会降低写操作(INSERT/UPDATE/DELETE)的速度,并占用额外的磁盘空间,因为每次数据变更都需要同步更新所有相关的索引。
通过理解这些底层原理,你就能更好地进行数据库表结构设计和SQL优化了。