文章目录
拆分代码
处理核心流程
- 验证输入
- 读取数据
- 拆分数据
- 保存文件
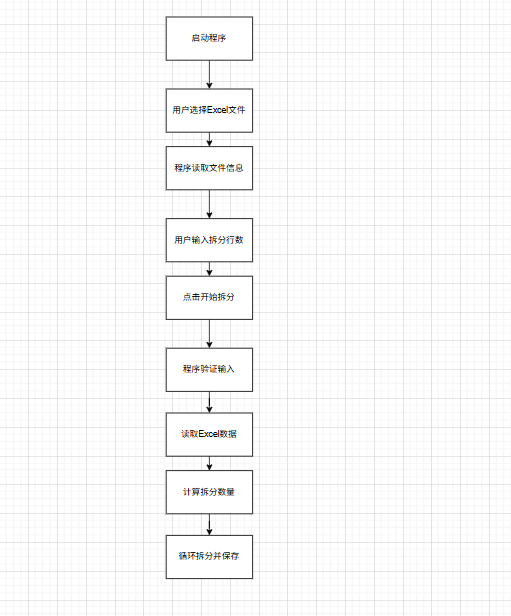
拆分代码的核心逻辑可以总结为:"读取数据→计算拆分规则→按规则切割数据→保存小文件",具体步骤如下,结合代码细节一步步解释:
一、前提:用户输入准备
在拆分前,程序需要两个关键信息:
- 要拆分的Excel文件路径(用户通过"浏览"按钮选择)
- 每个小文件包含的行数(用户在输入框填写,默认10000行)
这两个信息会通过start_split函数做有效性检查:
- 检查文件是否存在(如果没选文件或文件路径无效,弹出警告)
- 检查行数是否为正数(如果填0或负数或文字,弹出警告)
二、核心拆分函数split_excel的逻辑(重点)
当输入有效后,程序调用split_excel(file_path, rows_per_file)函数,这个函数是拆分的核心,步骤如下:
步骤1:读取Excel数据
用pandas库的pd.read_excel(file_path)读取整个Excel文件,得到一个"数据框"df(可以理解为内存中的表格,包含所有行和列)。
然后用len(df)获取总数据行数(比如总共有25000行)。
步骤2:检查数据是否为空
如果总行数为0(即Excel里没数据),直接弹出"错误"提示,终止拆分。
步骤3:计算需要拆分成多少个文件
用"总行数 ÷ 每个文件的行数",并向上取整(避免最后一个文件行数不足时被漏掉)。
例如:总共有25000行,每个文件10000行 → 25000 ÷ 10000 = 2.5 → 向上取整后是3个文件。
代码里用math.ceil(total_rows / rows_per_file)实现这个计算。
步骤4:确定拆分后文件的保存位置和名称
- 保存位置:和原文件在同一个文件夹(用
os.path.dirname(file_path)获取原文件目录)。 - 文件名称:原文件名 + "_拆分_序号"(比如原文件叫
data.xlsx,拆分后是data_拆分_1.xlsx、data_拆分_2.xlsx...)。
步骤5:循环拆分并保存每个小文件
用for循环遍历每个要生成的小文件(从0到"文件数量-1"),每次循环做3件事:
-
计算当前小文件的"起始行"和"结束行":
- 起始行 = 序号 × 每个文件的行数(比如第1个文件是0×10000=0,第2个是1×10000=10000)
- 结束行 = (序号+1)× 每个文件的行数,但如果超过总行数,就取总行数(避免越界)。
例如总25000行,第3个文件的结束行是min(3×10000, 25000) = 25000。
-
提取当前小文件的数据:
用
df.iloc[start_row:end_row]从总数据中"切出"当前范围的行(比如第3个文件取20000到25000行),得到子数据框df_subset。 -
保存子文件:
用
df_subset.to_excel(output_path, index=False)将子数据框保存为Excel文件(index=False表示不保存行号,避免多余数据)。
步骤6:反馈结果
- 如果所有文件都保存成功,弹出"成功"提示,显示拆分的文件数量(比如"共拆分成3个文件")。
- 如果过程中出错(比如文件损坏、没有权限保存等),弹出"错误"提示,显示具体错误原因。
总结:拆分逻辑一句话概括
"先读全表,算好要拆成几个文件,再按行数一段一段切下来,每段存成一个新Excel,最后告诉用户结果"。
整个过程不需要手动计算,程序会自动处理边界情况(比如最后一个文件行数不足),并通过图形界面让操作更简单。
python
import pandas as pd
import os
import tkinter as tk
from tkinter import filedialog, messagebox
from tkinter import ttk
import math
def split_excel(file_path, rows_per_file):
"""将Excel文件按指定行数拆分成多个文件"""
try:
# 读取Excel文件
df = pd.read_excel(file_path)
total_rows = len(df)
if total_rows == 0:
messagebox.showerror("错误", "Excel文件中没有数据!")
return
# 计算需要拆分的文件数量
num_files = math.ceil(total_rows / rows_per_file)
# 获取文件目录和文件名(不含扩展名)
file_dir = os.path.dirname(file_path)
file_name = os.path.splitext(os.path.basename(file_path))[0]
# 拆分文件
for i in range(num_files):
start_row = i * rows_per_file
end_row = min((i + 1) * rows_per_file, total_rows)
# 提取数据子集
df_subset = df.iloc[start_row:end_row]
# 生成输出文件名
output_filename = f"{file_name}_拆分_{i+1}.xlsx"
output_path = os.path.join(file_dir, output_filename)
# 保存拆分后的文件
df_subset.to_excel(output_path, index=False)
messagebox.showinfo("成功", f"文件拆分完成!\n共拆分成 {num_files} 个文件\n每个文件约 {rows_per_file} 行")
except Exception as e:
messagebox.showerror("错误", f"拆分过程中出现错误:{str(e)}")
def select_file():
"""选择Excel文件"""
file_path = filedialog.askopenfilename(
title="选择要拆分的Excel文件",
filetypes=[("Excel files", "*.xlsx *.xls"), ("All files", "*.*")]
)
if file_path:
file_var.set(file_path)
# 自动读取文件信息
try:
df = pd.read_excel(file_path)
total_rows = len(df)
info_var.set(f"文件总行数: {total_rows} 行")
except Exception as e:
info_var.set("无法读取文件信息")
def start_split():
"""开始拆分"""
file_path = file_var.get()
if not file_path or not os.path.exists(file_path):
messagebox.showwarning("警告", "请先选择有效的Excel文件!")
return
try:
rows_per_file = int(rows_var.get())
if rows_per_file <= 0:
messagebox.showwarning("警告", "请输入有效的行数(大于0)!")
return
except ValueError:
messagebox.showwarning("警告", "请输入有效的数字!")
return
split_excel(file_path, rows_per_file)
# 创建主窗口
root = tk.Tk()
root.title("Excel文件拆分工具:数据分析")
root.geometry("550x200")
# 变量
file_var = tk.StringVar()
rows_var = tk.StringVar(value="10000") # 默认10000行
info_var = tk.StringVar(value="请选择Excel文件")
# 界面布局
frame = ttk.Frame(root, padding="15")
frame.grid(row=0, column=0, sticky=(tk.W, tk.E, tk.N, tk.S))
# 文件选择行
ttk.Label(frame, text="选择Excel文件:").grid(row=0, column=0, sticky=tk.W, pady=5)
ttk.Entry(frame, textvariable=file_var, width=40).grid(row=0, column=1, padx=5, pady=5)
ttk.Button(frame, text="浏览", command=select_file).grid(row=0, column=2, padx=5, pady=5)
# 文件信息显示
ttk.Label(frame, textvariable=info_var, foreground="blue").grid(row=1, column=1, sticky=tk.W, pady=2)
# 行数设置行
ttk.Label(frame, text="每份文件行数:").grid(row=2, column=0, sticky=tk.W, pady=10)
ttk.Entry(frame, textvariable=rows_var, width=15).grid(row=2, column=1, sticky=tk.W, padx=5, pady=10)
ttk.Label(frame, text="行").grid(row=2, column=1, sticky=tk.W, padx=100, pady=10)
# 开始拆分按钮
ttk.Button(frame, text="开始拆分", command=start_split).grid(row=3, column=1, pady=20)
# 配置网格权重
root.columnconfigure(0, weight=1)
root.rowconfigure(0, weight=1)
frame.columnconfigure(1, weight=1)
root.mainloop()合并代码
合并代码的核心逻辑可以总结为:"选一个基准文件→自动找相似文件→确认后合并→统一格式并保存",整个过程不需要手动逐个选择文件,重点在"智能识别相似文件"和"兼容不同格式的表格"。下面分步骤拆解逻辑:
一、前提:用户输入准备
程序需要用户先做一件事:选择一个"基准Excel文件"(通过"浏览"按钮选择)。这个文件的作用是"模板"------程序会以它的文件名为线索,去同目录下找其他"长得像"的文件。
二、核心合并函数combine_similar_files的逻辑(重点)
当用户点击"开始智能合并"后,程序调用这个函数,核心步骤如下:
步骤1:定位文件目录并收集所有Excel文件
- 先确定基准文件所在的文件夹(比如基准文件在
D:\数据,就只在这个文件夹里找其他文件)。 - 遍历这个文件夹,把所有以
.xlsx或.xls结尾的文件都挑出来(这些是潜在的合并对象)。 - 如果文件夹里没有Excel文件,直接弹"错误"提示(比如"目录中没有找到Excel文件")。
步骤2:从基准文件名中提取"相似模式"(核心!)
这是程序"智能"的关键------通过基准文件名,提炼出一个"共同特征",用来判断其他文件是否相似。比如:
- 若基准文件是
销售数据_1.xlsx,会提炼出销售数据(去掉数字和后缀); - 若基准文件是
报表-202401.xlsx,会提炼出报表-2024(去掉末尾的日期序号); - 若基准文件是
客户列表 v2.xlsx,会提炼出客户列表(去掉版本号)。
具体由extract_common_pattern函数实现,逻辑是:
- 先去掉文件后缀(如
.xlsx),只看文件名主体; - 去掉文件名里的数字(比如
文件123→文件); - 按常见分隔符(
_、-、空格)拆分,取前面的部分(比如数据_拆分_3→数据_拆分); - 如果以上都不适用,就用整个文件名主体作为模式。
步骤3:用"相似模式"筛选同目录的文件
有了"相似模式"后,程序会在步骤1收集的所有Excel文件中,筛选出符合模式的文件。由find_similar_files函数实现,比如:
- 模式是
销售数据,则销售数据_2.xlsx、销售数据_3.xlsx会被选中(包含销售数据); - 模式是
报表-2024,则报表-202402.xlsx、报表-202403.xlsx会被选中(以模式开头)。
筛选时会自动排除基准文件本身吗?不,会包含基准文件(最终合并的文件列表里,基准文件是第一个)。
步骤4:让用户确认要合并的文件
如果筛选出的相似文件只有1个(也就是只有基准文件自己),会弹"提示"说"没有找到其他相似文件",终止流程。
如果有多个,会列出所有文件(比如"销售数据_1.xlsx、销售数据_2.xlsx、销售数据_3.xlsx"),让用户选"是"或"否"------用户确认后才继续合并。
步骤5:合并文件数据(处理格式兼容)
这一步是实际合并数据,核心是解决"不同文件列不一致"的问题(比如A文件有"姓名、金额",B文件只有"姓名")。步骤:
- 逐个读取相似文件的表格数据(用
pd.read_excel),得到每个文件的"数据框"(内存中的表格)。 - 第一个文件的数据作为"基准结构",后续文件的数据会和它对齐:
- 如果列名完全一致(比如都有"姓名、金额"),直接拼接(按行叠加);
- 如果列名不一致(比如B文件缺"金额"),则给B文件自动补一个"金额"列,空值填充(保证合并后所有列名和第一个文件一致)。
- 用
pd.concat把所有数据框"拼"成一个大的数据框(df_combined)。
步骤6:保存合并结果(避免文件名冲突)
- 生成结果文件名:用步骤2提炼的"相似模式"+"_合并结果.xlsx"(比如
销售数据_合并结果.xlsx)。 - 检查是否有重名:如果同名文件已存在,自动加序号(比如
销售数据_合并结果(1).xlsx、(2).xlsx)。 - 保存到基准文件所在的文件夹(用
to_excel函数)。
步骤7:反馈合并结果
- 成功:弹窗显示"合并了3个文件,总行数1500,保存路径XXX";
- 失败:弹窗显示具体错误(比如"某文件损坏无法读取""没有权限保存")。
总结:合并逻辑一句话概括
"以一个文件为模板,自动找到同目录下名字相似的其他Excel文件,对齐它们的表格列,拼在一起后存成一个新文件,过程中让用户确认并反馈结果"。
这个逻辑的核心优势是"智能找文件"(不用手动选)和"自动兼容格式"(不怕列不一致),特别适合处理按序号拆分的文件(如数据1、数据2)或按时间拆分的文件(如202401报表、202402报表)。
python
import pandas as pd
import os
import tkinter as tk
from tkinter import filedialog, messagebox
from tkinter import ttk
from collections import defaultdict
def combine_similar_files(selected_file):
"""合并与选定文件类似的所有Excel文件"""
try:
file_dir = os.path.dirname(selected_file)
file_name = os.path.basename(selected_file)
# 获取目录下所有Excel文件
listdir = os.listdir(file_dir)
excel_files = [f for f in listdir if f.endswith(('.xlsx', '.xls'))]
if not excel_files:
messagebox.showerror("错误", "目录中没有找到 Excel 文件!")
return
# 分析选定文件的特征(文件名模式)
base_name = file_name
# 尝试提取共同前缀(去除序号、版本号等)
common_patterns = extract_common_pattern(base_name)
# 根据特征筛选相似文件
similar_files = find_similar_files(excel_files, common_patterns, base_name)
if len(similar_files) <= 1:
messagebox.showinfo("提示", f"没有找到与 '{file_name}' 相似的其他文件")
return
# 显示找到的相似文件列表
file_list = "\n".join(similar_files)
confirm = messagebox.askyesno(
"确认合并",
f"找到以下相似文件,是否合并?\n\n{file_list}\n\n共 {len(similar_files)} 个文件"
)
if not confirm:
return
# 合并文件
df_combined = None
for filename in similar_files:
file_path = os.path.join(file_dir, filename)
df_temp = pd.read_excel(file_path)
if df_combined is None:
df_combined = df_temp
else:
# 检查列结构是否一致
if set(df_combined.columns) != set(df_temp.columns):
# 如果不一致,尝试对齐列
df_temp = df_temp.reindex(columns=df_combined.columns, fill_value=None)
df_combined = pd.concat([df_combined, df_temp], ignore_index=True, sort=False)
# 生成输出文件名
output_name = generate_output_name(common_patterns, base_name)
output_path = os.path.join(file_dir, f"{output_name}_合并结果.xlsx")
# 避免文件名冲突
counter = 1
while os.path.exists(output_path):
output_path = os.path.join(file_dir, f"{output_name}_合并结果({counter}).xlsx")
counter += 1
# 保存合并后的文件
df_combined.to_excel(output_path, index=False)
messagebox.showinfo(
"成功",
f"数据合并完成!\n"
f"合并了 {len(similar_files)} 个文件\n"
f"保存位置:{output_path}\n"
f"总行数:{len(df_combined)}"
)
except Exception as e:
messagebox.showerror("错误", f"合并过程中出现错误:{str(e)}")
def extract_common_pattern(filename):
"""提取文件名的共同模式"""
# 去除扩展名
name_without_ext = os.path.splitext(filename)[0]
patterns = []
# 常见模式识别
# 1. 按数字分割(如:文件1.xlsx, 文件2.xlsx)
if any(char.isdigit() for char in name_without_ext):
# 提取非数字部分作为模式
non_digit_parts = []
current_part = ""
for char in name_without_ext:
if char.isdigit():
if current_part:
non_digit_parts.append(current_part)
current_part = ""
else:
current_part += char
if current_part:
non_digit_parts.append(current_part)
if non_digit_parts:
patterns.append(''.join(non_digit_parts).strip(' _-'))
# 2. 按常见分隔符分割
separators = ['_', '-', ' ']
for sep in separators:
if sep in name_without_ext:
parts = name_without_ext.split(sep)
# 取前面几个部分作为模式
if len(parts) > 1:
patterns.append(sep.join(parts[:-1]))
# 3. 如果以上都不适用,使用整个文件名(不含扩展名)
if not patterns:
patterns.append(name_without_ext)
return patterns
def find_similar_files(all_files, patterns, base_file):
"""根据模式查找相似文件"""
similar_files = [base_file] # 包含选定的文件
for pattern in patterns:
if pattern: # 确保模式不为空
for filename in all_files:
if filename == base_file:
continue # 跳过选定的文件本身
name_without_ext = os.path.splitext(filename)[0]
# 多种匹配策略
if (pattern in filename or
pattern in name_without_ext or
filename.startswith(pattern) or
name_without_ext.startswith(pattern)):
similar_files.append(filename)
# 去重并返回
return list(dict.fromkeys(similar_files))
def generate_output_name(patterns, base_file):
"""生成输出文件名"""
if patterns:
# 使用最长的模式作为基础名称
longest_pattern = max(patterns, key=len)
if len(longest_pattern) > 3: # 确保模式有足够长度
return longest_pattern
# 回退方案:使用基础文件名(不含扩展名)
return os.path.splitext(base_file)[0]
def select_file():
"""选择Excel文件"""
file_path = filedialog.askopenfilename(
title="选择要合并的Excel文件",
filetypes=[("Excel files", "*.xlsx *.xls"), ("All files", "*.*")]
)
if file_path:
file_var.set(file_path)
# 显示选中的文件名
file_name = os.path.basename(file_path)
info_var.set(f"已选择: {file_name}")
def start_combine():
"""开始合并"""
file_path = file_var.get()
if not file_path or not os.path.exists(file_path):
messagebox.showwarning("警告", "请先选择有效的Excel文件!")
return
combine_similar_files(file_path)
# 创建主窗口
root = tk.Tk()
root.title("智能文件合并:数据分析")
root.geometry("600x180")
# 变量
file_var = tk.StringVar()
info_var = tk.StringVar(value="请选择Excel文件")
# 界面布局
frame = ttk.Frame(root, padding="15")
frame.grid(row=0, column=0, sticky=(tk.W, tk.E, tk.N, tk.S))
# 文件选择行
ttk.Label(frame, text="选择基准Excel文件:").grid(row=0, column=0, sticky=tk.W, pady=5)
ttk.Entry(frame, textvariable=file_var, width=50).grid(row=0, column=1, padx=5, pady=5)
ttk.Button(frame, text="浏览", command=select_file).grid(row=0, column=2, padx=5, pady=5)
# 文件信息显示
ttk.Label(frame, textvariable=info_var, foreground="blue").grid(row=1, column=1, sticky=tk.W, pady=5)
# 说明文字
info_text = "系统会自动查找与选定文件相似的其他文件进行合并\n(基于文件名模式识别,如:文件1.xlsx, 文件2.xlsx)"
ttk.Label(frame, text=info_text, foreground="gray", font=("Arial", 9)).grid(row=2, column=1, sticky=tk.W, pady=5)
# 开始合并按钮
ttk.Button(frame, text="开始智能合并", command=start_combine).grid(row=3, column=1, pady=15)
# 配置网格权重
root.columnconfigure(0, weight=1)
root.rowconfigure(0, weight=1)
frame.columnconfigure(1, weight=1)
root.mainloop()整合代码
python
import pandas as pd
import os
import tkinter as tk
from tkinter import filedialog, messagebox
from tkinter import ttk
import math
import logging
import sys
# --- 1. 日志配置 ---
# 配置日志输出到控制台 (CMD) 和文件,用于调试和运行状态跟踪
def setup_logging():
# 使用 StreamHandler 将日志输出到标准输出,确保在 CMD 中可见
logging.basicConfig(
level=logging.INFO, # 默认级别为 INFO,会输出 INFO, WARNING, ERROR, CRITICAL
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.StreamHandler(sys.stdout)
]
)
logging.info("日志初始化完成。Excel 处理工具启动。")
# --- 2. 文件合并逻辑 (Merge Functions) ---
def extract_common_pattern(filename):
"""提取文件名的共同模式(用于智能识别相似文件)"""
name_without_ext = os.path.splitext(filename)[0]
logging.debug(f"分析文件名模式: {name_without_ext}")
patterns = []
# 1. 按数字分割(提取非数字部分作为模式)
non_digit_parts = []
current_part = ""
for char in name_without_ext:
if char.isdigit():
if current_part:
non_digit_parts.append(current_part)
current_part = ""
else:
current_part += char
if current_part:
non_digit_parts.append(current_part)
pattern1 = ''.join(non_digit_parts).strip(' _-')
if pattern1:
patterns.append(pattern1)
logging.debug(f"模式 1 (非数字部分): {pattern1}")
# 2. 按常见分隔符分割(提取前缀)
separators = ['_', '-']
for sep in separators:
if sep in name_without_ext:
parts = name_without_ext.split(sep)
if len(parts) > 1:
pattern2 = sep.join(parts[:-1]).strip()
if pattern2:
patterns.append(pattern2)
logging.debug(f"模式 2 (分隔符 '{sep}' 前缀): {pattern2}")
# 3. 回退方案:使用整个文件名(不含扩展名)
if not patterns:
patterns.append(name_without_ext)
return list(set(patterns))
def find_similar_files(all_files, patterns, base_file):
"""根据提取的模式查找相似文件"""
similar_files = [base_file]
logging.info(f"基准文件: {base_file}")
for pattern in patterns:
logging.debug(f"检查模式: '{pattern}'")
if not pattern:
continue
for filename in all_files:
if filename == base_file:
continue
name_without_ext = os.path.splitext(filename)[0]
# 匹配逻辑:文件名中包含模式,或文件名以模式开头
if (pattern in name_without_ext or
name_without_ext.startswith(pattern)):
if filename not in similar_files:
similar_files.append(filename)
logging.info(f"找到相似文件: {filename}")
return list(dict.fromkeys(similar_files))
def generate_output_name(patterns, base_file):
"""生成输出文件名"""
# 优先使用最长的、有意义的模式
meaningful_patterns = [p for p in patterns if len(p) > 3]
if meaningful_patterns:
longest_pattern = max(meaningful_patterns, key=len)
return longest_pattern
# 回退到基准文件名(不含扩展名)
return os.path.splitext(base_file)[0]
def combine_similar_files(selected_file):
"""执行文件合并操作的核心逻辑"""
logging.info("-" * 50)
logging.info(f"开始合并操作,基准文件: {selected_file}")
try:
file_dir = os.path.dirname(selected_file)
file_name = os.path.basename(selected_file)
# 1. 查找所有 Excel 文件
listdir = os.listdir(file_dir)
excel_files = [f for f in listdir if f.lower().endswith(('.xlsx', '.xls', '.xlsm'))]
if not excel_files:
logging.error("目录中未找到 Excel 文件。")
messagebox.showerror("错误", "目录中没有找到 Excel 文件!")
return
# 2. 分析模式并查找相似文件
common_patterns = extract_common_pattern(file_name)
similar_files = find_similar_files(excel_files, common_patterns, file_name)
if len(similar_files) <= 1:
logging.warning("未找到相似的其他文件。")
messagebox.showinfo("提示", f"没有找到与 '{file_name}' 相似的其他文件")
return
# 3. 确认合并
file_list = "\n".join(similar_files)
logging.info(f"共找到 {len(similar_files)} 个文件准备合并。")
confirm = messagebox.askyesno(
"确认合并",
f"找到以下相似文件,是否合并?\n\n{file_list}\n\n共 {len(similar_files)} 个文件"
)
if not confirm:
logging.info("用户取消了合并操作。")
return
# 4. 执行合并
df_combined = pd.DataFrame()
for filename in similar_files:
file_path = os.path.join(file_dir, filename)
logging.info(f"正在读取文件: {filename}")
try:
# 使用 openpyxl 引擎处理 .xlsx 文件
df_temp = pd.read_excel(file_path, engine='openpyxl')
df_combined = pd.concat([df_combined, df_temp], ignore_index=True, sort=False)
logging.debug(f"文件 {filename} 读取成功,已合并。")
except Exception as read_e:
logging.error(f"读取文件 {filename} 时出错: {str(read_e)}")
messagebox.showwarning("文件读取警告", f"无法读取文件 '{filename}'。该文件将被跳过。")
continue
if df_combined.empty:
messagebox.showerror("错误", "所有文件读取失败,无法合并。")
logging.error("合并后的 DataFrame 为空。")
return
# 5. 保存结果
output_name = generate_output_name(common_patterns, file_name)
output_path = os.path.join(file_dir, f"{output_name}_合并结果.xlsx")
# 避免文件名冲突
counter = 1
while os.path.exists(output_path):
output_path = os.path.join(file_dir, f"{output_name}_合并结果({counter}).xlsx")
counter += 1
logging.info(f"保存合并结果到: {output_path}")
df_combined.to_excel(output_path, index=False, engine='openpyxl')
messagebox.showinfo(
"成功",
f"数据合并完成!\n合并了 {len(similar_files)} 个文件\n保存位置:{output_path}\n总行数:{len(df_combined)}"
)
logging.info(f"合并成功,总行数: {len(df_combined)}")
except Exception as e:
logging.critical(f"合并过程中发生致命错误: {str(e)}")
messagebox.showerror("错误", f"合并过程中出现错误:{str(e)}")
# --- 3. 文件拆分逻辑 (Split Functions) ---
def split_excel(file_path, rows_per_file):
"""执行文件拆分操作的核心逻辑"""
logging.info("-" * 50)
logging.info(f"开始拆分操作,文件: {file_path}")
logging.info(f"每份文件行数: {rows_per_file}")
try:
df = pd.read_excel(file_path, engine='openpyxl')
total_rows = len(df)
if total_rows == 0:
messagebox.showerror("错误", "Excel文件中没有数据!")
logging.error("待拆分文件为空。")
return
# 计算文件数量
num_files = math.ceil(total_rows / rows_per_file)
file_dir = os.path.dirname(file_path)
file_name = os.path.splitext(os.path.basename(file_path))[0]
logging.info(f"总行数: {total_rows} 行,将拆分成 {num_files} 个文件。")
# 拆分和保存
for i in range(num_files):
start_row = i * rows_per_file
end_row = min((i + 1) * rows_per_file, total_rows)
df_subset = df.iloc[start_row:end_row]
output_filename = f"{file_name}_拆分_{i+1}.xlsx"
output_path = os.path.join(file_dir, output_filename)
logging.info(f"保存第 {i+1}/{num_files} 份文件 (行 {start_row+1} 到 {end_row}) 到: {output_path}")
df_subset.to_excel(output_path, index=False, engine='openpyxl')
logging.info(f"文件拆分操作成功完成。")
messagebox.showinfo("成功", f"文件拆分完成!\n共拆分成 {num_files} 个文件\n每个文件约 {rows_per_file} 行")
except Exception as e:
logging.critical(f"拆分过程中发生致命错误: {str(e)}")
messagebox.showerror("错误", f"拆分过程中出现错误:{str(e)}")
# --- 4. Tkinter GUI 界面 ---
class ExcelProcessorApp:
def __init__(self, root):
self.root = root
self.root.title("Excel文件智能处理工具 (合并与拆分)")
# 优化界面样式
try:
style = ttk.Style()
style.theme_use('vista') # 尝试使用Windows风格主题
style.configure('TButton', font=('Arial', 10, 'bold'), padding=6)
except:
pass # 如果主题不存在,保持默认
self.root.geometry("650x300")
self.root.resizable(False, False)
# 变量初始化
self.merge_file_var = tk.StringVar()
self.merge_info_var = tk.StringVar(value="请选择Excel文件作为合并基准")
self.split_file_var = tk.StringVar()
self.split_rows_var = tk.StringVar(value="10000")
self.split_info_var = tk.StringVar(value="请选择待拆分的Excel文件")
# 初始化日志
setup_logging()
# 创建 Notebook (标签页界面)
self.notebook = ttk.Notebook(root)
self.notebook.pack(pady=10, padx=10, expand=True, fill="both")
# 创建标签页框架
self.merge_frame = ttk.Frame(self.notebook, padding="15 15 15 15")
self.split_frame = ttk.Frame(self.notebook, padding="15 15 15 15")
self.notebook.add(self.merge_frame, text="文件智能合并")
self.notebook.add(self.split_frame, text="文件按行拆分")
# 构建标签页 UI
self._build_merge_tab()
self._build_split_tab()
# --- UI 构建器 ---
def _build_merge_tab(self):
self.merge_frame.columnconfigure(1, weight=1)
# 1. 文件选择
ttk.Label(self.merge_frame, text="选择基准Excel文件:", font=('Arial', 10, 'bold')).grid(row=0, column=0, sticky=tk.W, pady=10)
ttk.Entry(self.merge_frame, textvariable=self.merge_file_var, width=50).grid(row=0, column=1, padx=5, pady=10, sticky=(tk.W, tk.E))
ttk.Button(self.merge_frame, text="浏览", command=self._select_merge_file).grid(row=0, column=2, padx=5, pady=10)
# 2. 文件信息
ttk.Label(self.merge_frame, textvariable=self.merge_info_var, foreground="#0056b3", font=("Arial", 10)).grid(row=1, column=1, sticky=tk.W, pady=5)
# 3. 功能说明
info_text = "功能说明:系统将根据文件名模式(例如:文件_1, 文件_2)自动查找同目录下所有相似文件,并将它们合并。\n请确保所有文件的表头结构大致一致。"
ttk.Label(self.merge_frame, text=info_text, foreground="gray", font=("Arial", 9)).grid(row=2, column=0, columnspan=3, sticky=tk.W, pady=10)
# 4. 开始按钮
ttk.Button(self.merge_frame, text="⭐ 开始智能合并 ⭐", command=self._start_merge, style='TButton').grid(row=3, column=1, pady=20)
def _build_split_tab(self):
self.split_frame.columnconfigure(1, weight=1)
# 1. 文件选择
ttk.Label(self.split_frame, text="选择待拆分的Excel文件:", font=('Arial', 10, 'bold')).grid(row=0, column=0, sticky=tk.W, pady=10)
ttk.Entry(self.split_frame, textvariable=self.split_file_var, width=50).grid(row=0, column=1, padx=5, pady=10, sticky=(tk.W, tk.E))
ttk.Button(self.split_frame, text="浏览", command=self._select_split_file).grid(row=0, column=2, padx=5, pady=10)
# 2. 文件信息
ttk.Label(self.split_frame, textvariable=self.split_info_var, foreground="#0056b3", font=("Arial", 10)).grid(row=1, column=1, sticky=tk.W, pady=5)
# 3. 行数设置
ttk.Label(self.split_frame, text="每份文件行数:").grid(row=2, column=0, sticky=tk.W, pady=10)
ttk.Entry(self.split_frame, textvariable=self.split_rows_var, width=15).grid(row=2, column=1, sticky=tk.W, padx=5, pady=10)
ttk.Label(self.split_frame, text="行 (默认 10000)").grid(row=2, column=1, sticky=tk.W, padx=120, pady=10)
# 4. 开始按钮
ttk.Button(self.split_frame, text="⚙️ 开始拆分 ⚙️", command=self._start_split, style='TButton').grid(row=3, column=1, pady=20)
# --- 5. 事件处理器 ---
def _select_file(self, file_var, info_var, mode="select"):
"""通用文件选择逻辑,并自动读取文件信息(总行数)"""
title = "选择 Excel 文件"
file_path = filedialog.askopenfilename(
title=title,
filetypes=[("Excel files", "*.xlsx *.xls *.xlsm"), ("All files", "*.*")]
)
if file_path:
file_var.set(file_path)
file_name = os.path.basename(file_path)
try:
# 尝试读取文件行数
df = pd.read_excel(file_path, engine='openpyxl')
total_rows = len(df)
if mode == "split":
info_var.set(f"已选择: {file_name} | 文件总行数: {total_rows} 行")
logging.info(f"拆分文件已选择: {file_path}. 总行数: {total_rows}")
else:
info_var.set(f"已选择: {file_name} | 总行数: {total_rows} 行")
logging.info(f"合并基准文件已选择: {file_path}. 总行数: {total_rows}")
except Exception as e:
info_var.set(f"已选择: {file_name} | 无法读取文件信息或文件损坏。")
logging.error(f"读取文件信息出错: {e}")
def _select_merge_file(self):
self._select_file(self.merge_file_var, self.merge_info_var, mode="merge")
def _select_split_file(self):
self._select_file(self.split_file_var, self.split_info_var, mode="split")
def _start_merge(self):
file_path = self.merge_file_var.get()
if not file_path or not os.path.exists(file_path):
messagebox.showwarning("警告", "请先选择有效的Excel文件!")
return
# 运行合并逻辑
combine_similar_files(file_path)
def _start_split(self):
file_path = self.split_file_var.get()
if not file_path or not os.path.exists(file_path):
messagebox.showwarning("警告", "请先选择有效的Excel文件!")
return
try:
rows_per_file = int(self.split_rows_var.get())
if rows_per_file <= 0:
messagebox.showwarning("警告", "请输入有效的行数(大于0)!")
return
except ValueError:
messagebox.showwarning("警告", "每份文件行数必须是有效的数字!")
return
# 运行拆分逻辑
split_excel(file_path, rows_per_file)
# --- 6. 主程序入口 ---
if __name__ == '__main__':
root = tk.Tk()
app = ExcelProcessorApp(root)
root.mainloop()执行打包命令
python
pyinstaller --onefile --console --upx-dir D:\upx excel_tool.py