背景介绍
为保障货拉拉资金安全,团队构建并维护了实时对账平台(算盘),旨在通过实时比对链路上下游服务产生的数据,快速发现潜在资损风险,保障资金安全与业务健壮性。
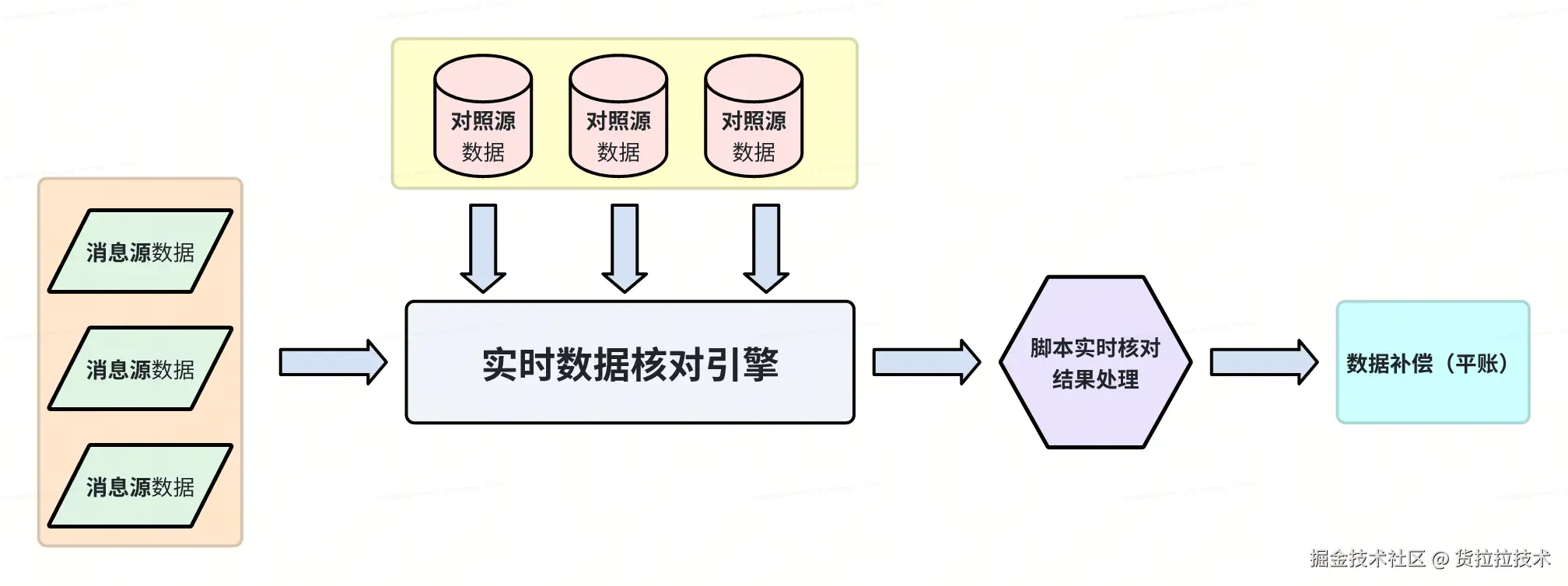
算盘平台以 Kafka 作为核心消息中间件,高效接入对账源数据,支持高吞吐、低延迟的海量数据处理。随着接入的业务场景扩张,接入平台的 Kafka Topic 超过100个,对应的 partition 数量超过1000个,日均处理消息达数亿。在此背景下,初期的消费调度方案已无法支撑快速膨胀的数据规模。
我们曾面临消息积压、延迟上升、资源分配不均匀等问题,且无法通过横向扩展算力资源解决,这些问题威胁到平台稳定性,制约了平台发展。为此,团队设计并落地了一套动态可扩展的 Kafka 消费集群调度方案。
本文将系统性地分享该方案在应对大规模集群,高并发消费场景下的设计思路、关键技术实现与线上验证效果。
原方案与面临的挑战
原有架构设计
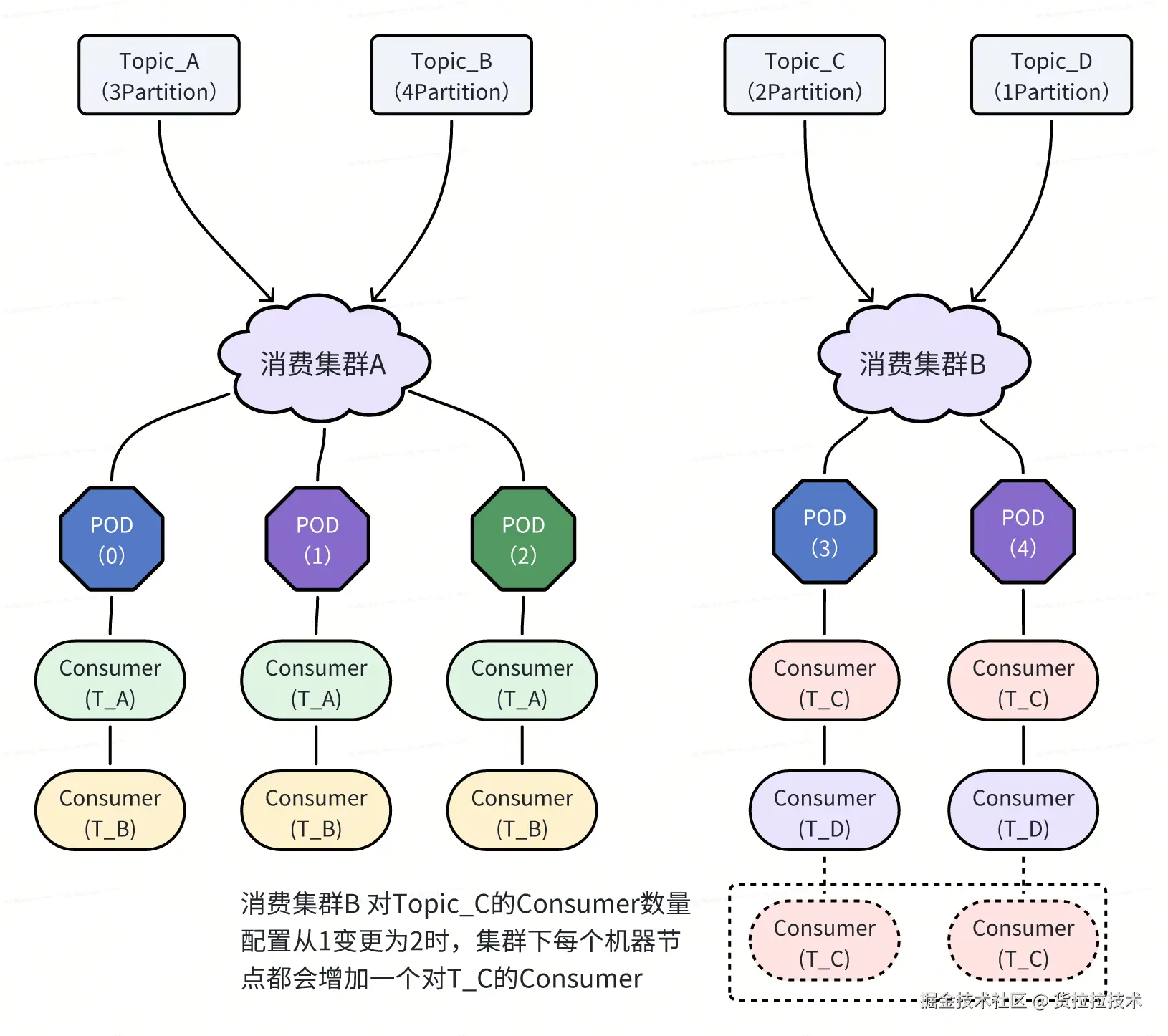
在项目初期,我们采用了一种基于集群划分的静态 Kafka 消费管理模型,其核心设计如下:
- 虚拟集群设计:将所有机器资源划分为多个虚拟集群,通过抢注算法进行集群动态注册。
- 集群与机器的绑定关系:每台机器在同一时刻仅隶属于一个集群。
- Topic 与集群的绑定关系:每个 Kafka Topic 被分配到一个特定的消费集群中,一个 Topic 同时仅由一个集群消费。
- 集群内统一的 Consumer 配置 :集群内的所有机器会按照 Kafka 原生客户端逻辑,同时启动该集群下所有 Topic 的 Consumer 实例,每个 Topic 的 Consumer 数量由集群配置统一控制。如下图所示,当集群 B 中 Topic_C 的 Consumer 数量配置从 1 调整为 2 时,POD3 和 POD4 将各自为 Topic_C 新增一个 Consumer 实例(虚线部分)。
该方案设计初衷是简化运维管理,适用于业务初期场景:接入的 Topic 数量少、数据吞吐量低、消费逻辑简单,整体消费压力远未触及瓶颈。
遇到的问题与瓶颈
随着业务快速发展,接入的 Topic 数量和数据量级持续增长,消费逻辑也日益复杂。原有方案的局限性逐渐暴露,主要体现在以下两个方面:
资源利用率低与负载不均
在流量高峰期,我们观察到同一集群内的机器出现严重的 CPU 负载不均衡现象:部分机器 CPU 使用率持续处于高位,而另一些机器则相对空闲。
深入分析后发现,其根本原因在于 Kafka Consumer 的分配机制与静态 Kafka 消费管理模型的冲突:
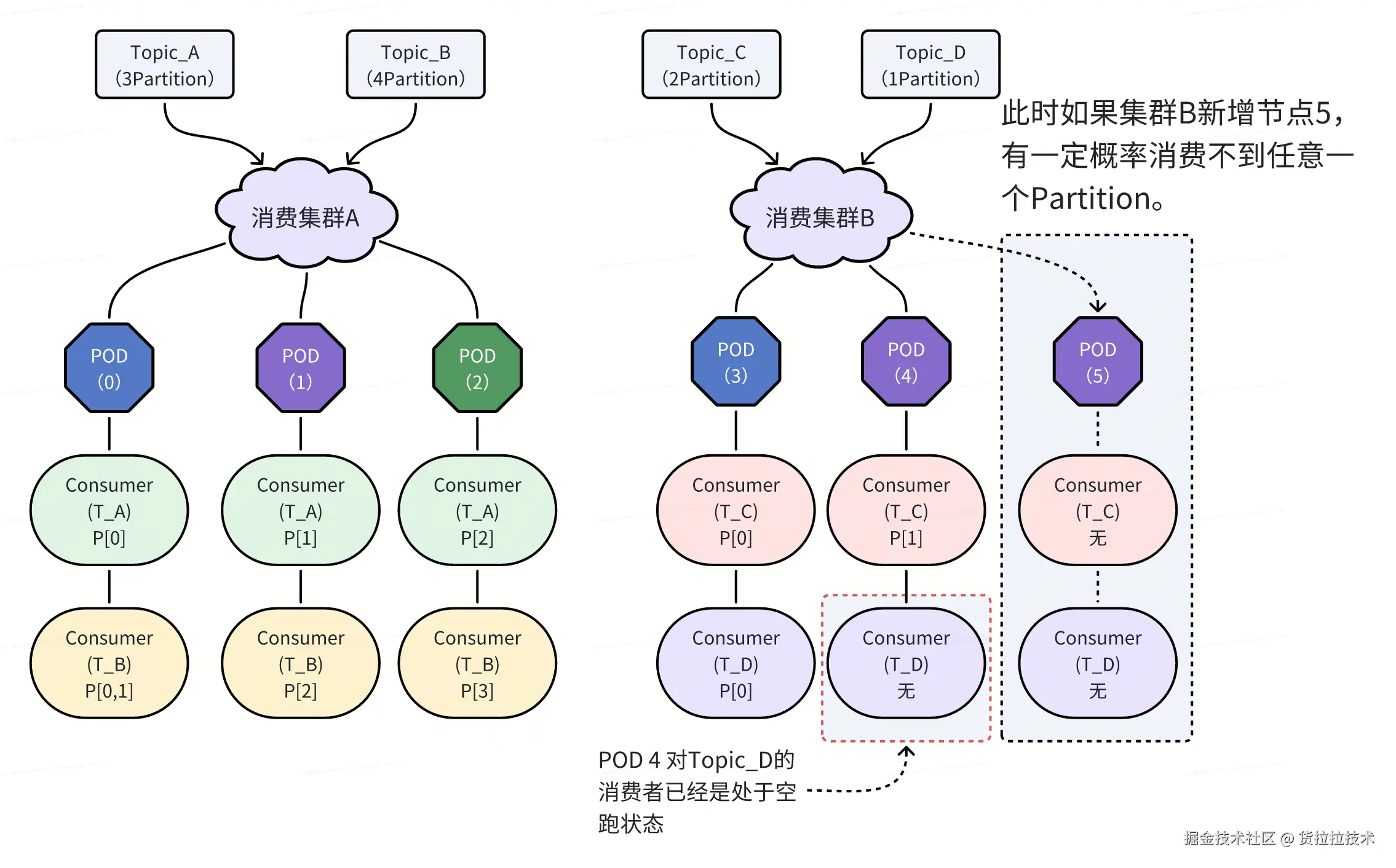
- Kafka 的消费能力上限由 Topic 的 Partition 数量决定。当 Consumer 数量 ≥ Partition 数时,额外的 Consumer 将处于闲置状态。
- 在静态消费模型中,每台机器需启动集群内所有 Topic 的 Consumer。当集群规模扩大(机器数增多)时,总 Consumer 数极易超过 Partition 数。
- 此时,Kafka 的默认 Rebalance 策略(基于 Consumer Group 内 Consumer 实例的字典序)会导致资源分配不均:字典序较小的 Consumer 实例优先分配 Partition,而字典序较大的实例则无法参与消费,处于空转状态。
- 因此,某些机器(其 Consumer 实例字典序普遍较小)承担了绝大部分消费任务,导致 CPU 过载,而其他机器则处于空转闲置状态。
扩容能力受限,系统缺乏弹性
更严重的问题是,横向扩容无法有效解决性能瓶颈。
- 横向扩容(增加机器):新增机器会继承集群内所有 Topic 的 Consumer 配置。对于Consumer数量已达到 Partition 数上限的 Topic,新增的 Consumer 实例极有可能不仅无法获得 Partition ,反而还会加剧资源浪费和负载不均。
综上,原有方案的静态绑定、粗粒度调度特性,使其在面对多 Topic、高吞吐、动态变化的业务场景时,表现出严重的资源浪费、负载不均和扩展性差等问题,已无法满足系统对高可用与高吞吐的诉求。
新方案设计与实现
设计目标
新方案旨在解决原有系统存在的主要问题,同时提升系统的整体性能和稳定性。具体目标如下:
- 解决集群 Consumer 分配不均导致的"热点"问题:确保各机器间的 CPU 负载均衡,减少因个别节点过载而影响整体系统性能的情况。
- 支持横向扩容:允许系统在无需改变现有架构的前提下,通过添加更多机器节点来应对业务增长的需求。
- 自动调整集群内节点负载:引入智能负载均衡算法,根据实时监控数据动态调整各节点的任务分配,降低运维成本。
- 完善熔断降级机制:提高系统在面对异常情况(如网络故障、服务不可用)时的鲁棒性,保障核心功能不受影响。
- 增加兜底机制,保障消费稳定性:即使在极端情况下,也能确保消息的可靠消费,防止数据丢失。
技术选型与架构设计
为达成上述目标,我们设计并实现了动态可扩展的 Kafka 消费集群调度方案。该方案的核心设计如下:
- 虚拟集群设计:保持与原方案一致,将一组无状态的机器节点划分为一个"消费集群"。每台机器在同一时刻仅隶属于一个集群。
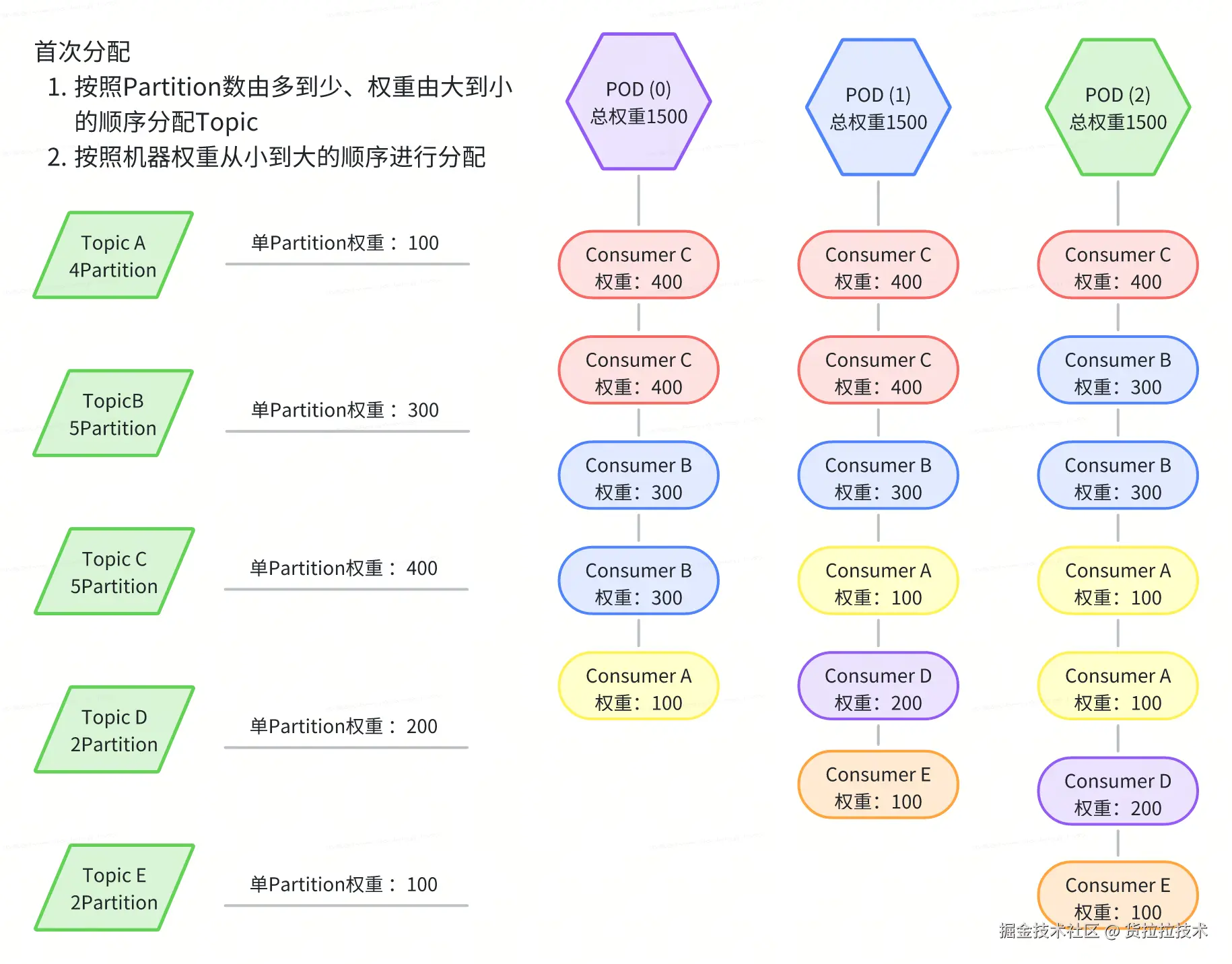
- Topic 与集群的绑定关系:每个 Kafka Topic 可以被手动配置到一个或多个集群中。Consumer 数量基于集群比例配置。对于每个 Topic,其 Partition 数量决定了所需 Consumer 的总数。例如,若某 Topic 有 10 个 Partition,则在其所属的所有集群中总共需要启动 10 个 Consumer 实例。
- 机器与 Topic 的动态消费配置:根据集群与机器、Topic 与集群的绑定关系,系统会计算出每台机器针对各个 Topic 的理想 Consumer 配置。每台机器将"抢占"一份唯一的 Consumer 配置,并据此创建相应的 Kafka Consumer 实例。
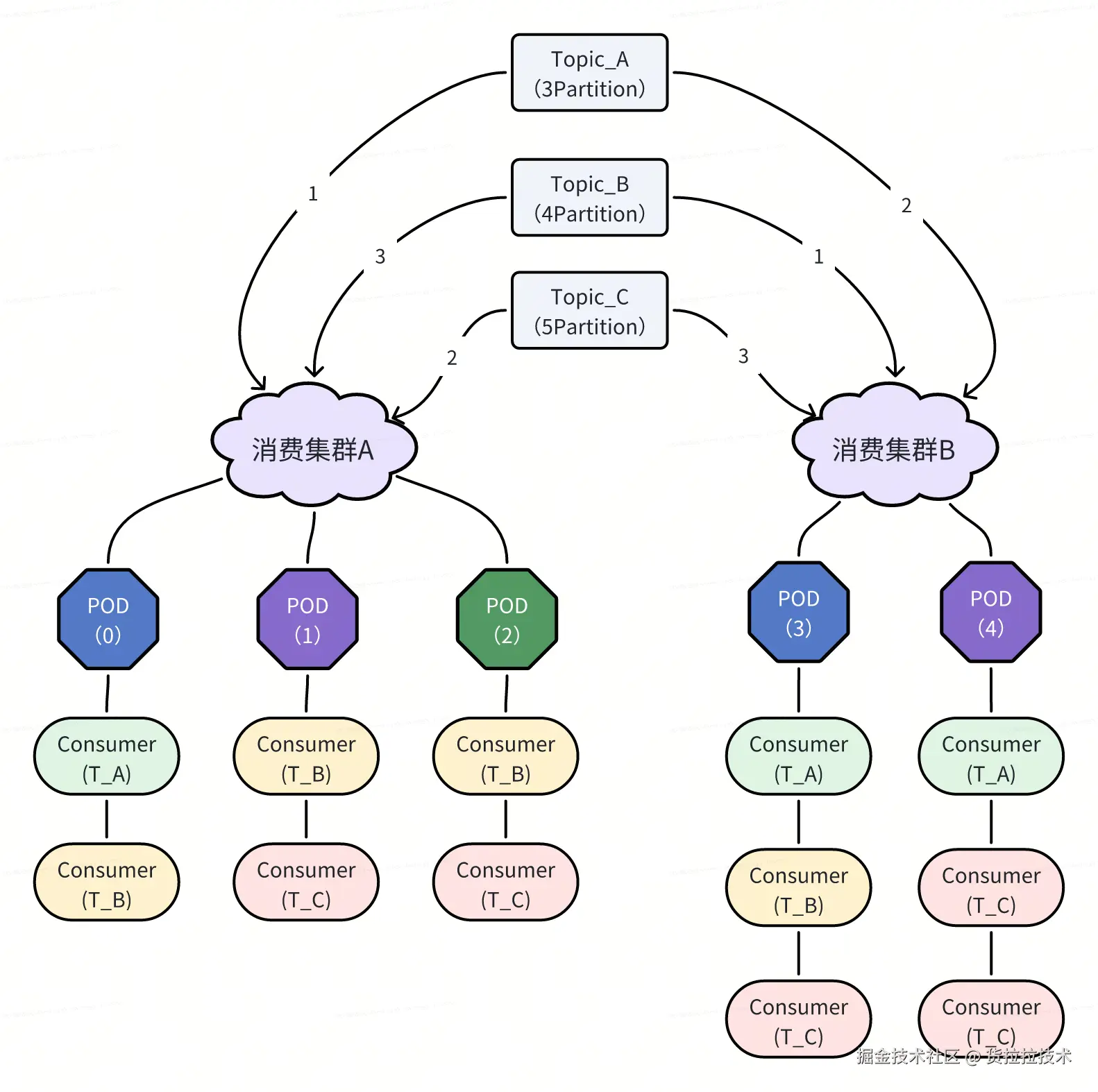
本方案的核心在于以下几点:
- 最小单元细化至 Partition:不同于以往以 Topic 作为最小管理单位的做法,现在我们将 Kafka 消费的最小单位精确到 Partition 级别,从而实现更细粒度的资源管理和负载均衡。
- 比例化多集群消费:支持一个 Topic 同时由多个集群消费,并通过设置各集群间的 Consumer 数量比例,来灵活控制资源分配。
- 加权负载均衡:通过收集各 Topic 在单位时间内消耗的总 CPU 时间,并除以其 Partition 数,得出 Topic-Partition 维度的权重值。这一指标用于衡量每个 Topic-Partition 对系统资源的需求程度,在负载均衡过程中起到关键作用。基于权重值,系统能够更合理地分配资源,有效避免"热点"问题和资源负载不均现象。
- 自动化扩缩容支持:在实现细粒度负载均衡的基础上,系统支持机器节点的自动扩缩容。扩容后,新节点能自动参与负载均衡并获取消费任务;缩容时,系统会平滑迁移任务,全程无需人工干预配置调整,显著降低运维成本。
核心实现细节
系统以 Partition 为最小调度单元,基于各 Topic-Partition 的资源权重进行动态分配。分配过程遵循以下核心原则:
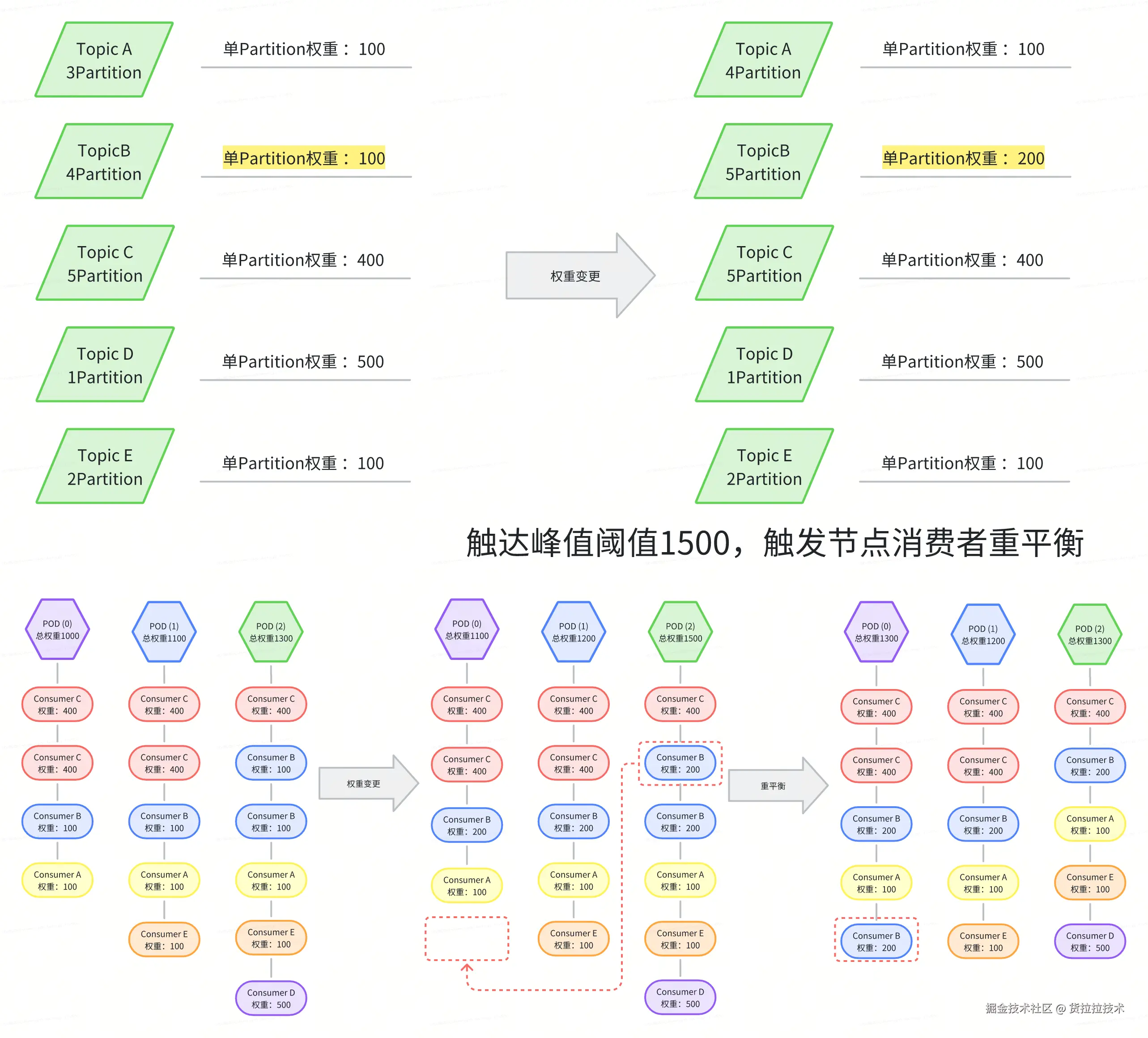
- 多机分散分配原则 : 对于拥有多个 Partition 的 Topic,系统优先将其分散到不同机器上消费,避免单机独占。此举旨在充分利用集群整体算力,并提升容错能力------即使单台机器故障,基于 Consumer 的负载均衡,其他机器仍能完整消费整个 Topic 的消息,不会导致 Topic 消费阻塞。
- 基于阈值的动态再平衡 : 随着业务流量波动,某些 Partition 的权重可能持续上升。当某台机器的累计权重超过预设阈值 时,系统将触发局部再平衡。 在再平衡过程中,优先迁移高权重 Partition,以最小化 Consumer Rebalance 次数,降低对 Kafka 消费组的冲击,保障对账任务的连续性。
节点的动态刷新机制
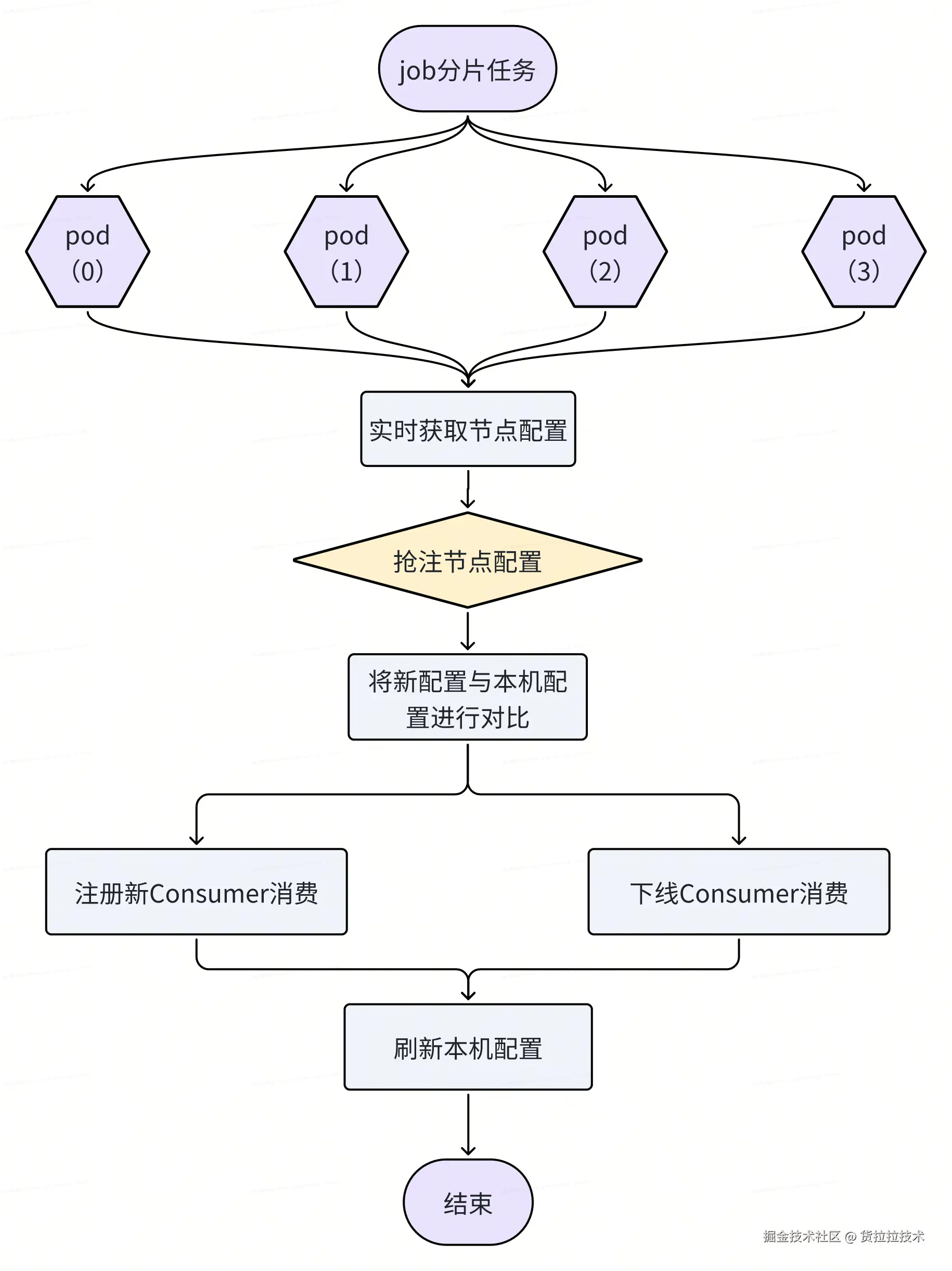
为确保消费节点能及时响应调度决策,系统采用"中心计算 + 分布式拉取"的配置分发模式,实现配置的高效同步。
具体流程如下:
- 调度计划生成 :调度中心周期性(每 30 秒)执行负载均衡算法,生成全局消费分配计划,并写入 Redis 。
- 节点主动拉取 :每台机器节点内置一个定时拉取任务(Pull Job),每 30 秒从 Redis 拉取最新分配计划。
- 本地热更新:节点根据最新配置,动态启动或停止指定 Topic 的 Kafka Consumer 实例。该过程在运行时完成,无需重启服务,且仅影响目标 Topic 的消费任务,其他 Topic 的 Consumer 实例继续正常运行,保障整体消费的稳定性。流程如下:
自动化扩缩容支持
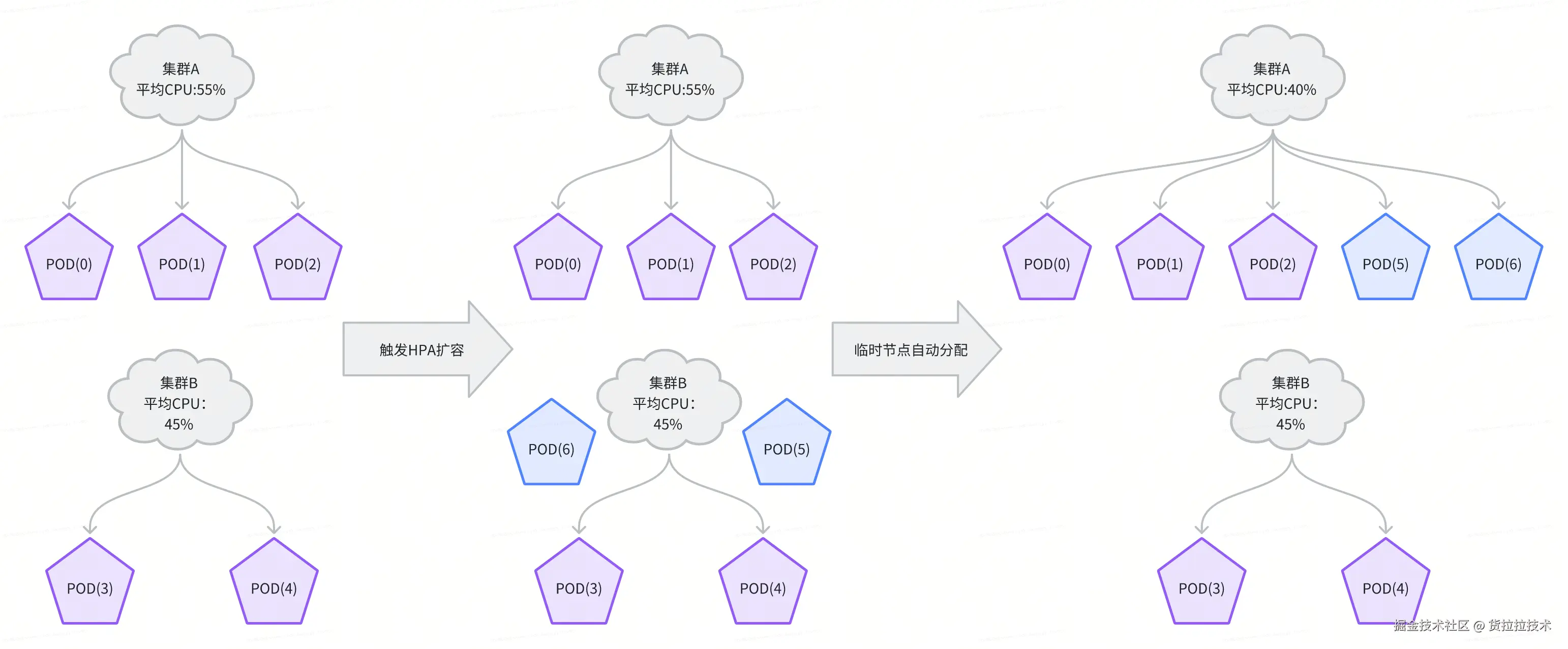
新方案与 Kubernetes HPA 深度集成,实现消费能力的弹性伸缩。当业务流量增长触发扩容时,系统自动完成新节点的接入与负载分配:
- 新节点注册:扩容后启动的新 Pod 会向集群注册心跳,表明其就绪状态。
- 动态配置响应 :调度中心检测到集群总节点数变化后,会立即触发一次全量负载重算 。系统优先将新节点加入当前 CPU 负载最高的消费集群,并以"临时节点"身份参与分配。
- 平滑纳入调度:新节点通过"动态刷新机制"获取最新配置,自动承担分配给它的 Partition 消费任务,全程无需人工干预。
该机制确保了系统在面对流量洪峰时,能够分钟级完成扩容与负载均衡,保障对账任务的实时性 SLA。
实施效果与数据验证
当前运行规模与吞吐能力
新方案已全面支撑算盘平台的实时对账业务,当前核心指标如下:
- 计算资源规模 :在线运行的机器节点超 200台,支持横向弹性扩展。
- 消息接入规模 :接入 Kafka Topic 超过 360 个 ,Partition数量超3000个,涵盖多个核心资金业务场景。
- 消费吞吐能力 :峰值消费速率突破 20 万 QPS 、对账任务峰值突破300万QPS。
这些数据表明,系统已具备处理超大规模消息流的能力,不仅满足现有业务需求,还可为未来业务的快速发展提供充足保障。
集群调度与弹性能力
- 动态集群管理 :系统动态管理 6 个独立的消费集群,各集群可根据业务优先级和负载情况独立配置资源。集群内部各节点的CPU负载在高峰期的波动控制在10%以内。
- 实时扩缩容支持 :得益于细粒度的 Partition 级调度与加权负载均衡机制,系统支持集群下机器节点的实时扩展。新增节点可自动加入集群并参与负载均衡,无需人工干预配置,显著提升了系统的弹性与运维效率。
稳定性与业务价值
在新方案的支撑下,系统未再出现因消费能力不足导致的消息积压或对账延迟问题。对账任务的实时性与 SLA 得到有效保障,为业务的资损防控提供了坚实的技术底座。