文章目录
- 思考:到底是更新数据库的时候,同步删除缓存好还是同步更新缓存好??
- [方案1: 先删除缓存,后更新数据库(目前已经废弃的做法,拉裤里拉完了)](#方案1: 先删除缓存,后更新数据库(目前已经废弃的做法,拉裤里拉完了))
- [方案2: 先更新数据库,后删除缓存(适合绝大多数的读多写少场景)](#方案2: 先更新数据库,后删除缓存(适合绝大多数的读多写少场景))
- 方案3:延迟双删(NPC)
- 方案4:canal订阅MySQL的binlog来完成和Redis的同步(人上人)
- 方案5:canal+RocketMQ(夯爆了)
思考:到底是更新数据库的时候,同步删除缓存好还是同步更新缓存好??
如果是更新数据库的时候,同步更新缓存,那么更新100次MySQL,就同步更新100次缓存,并且有缓存乱序问题
如果是更新数据库,删除缓存策略,那么第二次来了就不需要操作再删除缓存,仅第一次删除了缓存,发现缓存查询不到再到数据库更新对应的缓存.
因此,一般采用更新数据库,删除缓存策略
更新缓存的缓存乱序问题
age=18
两个请求来了,R1要age+1,R2要age=25
MySQL中先进行了R1,然后R2,就age=25,
MySQL↓↓↓↓↓↓↓↓
- age=19(MySQL)
- age=25(MySQL)
但是由于网络延迟,R2对应的缓存请求先执行,R1对应的缓存请求反而后执行,
因此Redis↓↓↓↓↓↓↓↓中的age经历了如下变化 - age=25(Redis)
- age=26(Redis)
因此导致
age=25(MySQL)
age=26(Redis)
乱了套了!!!
方案1: 先删除缓存,后更新数据库(目前已经废弃的做法,拉裤里拉完了)
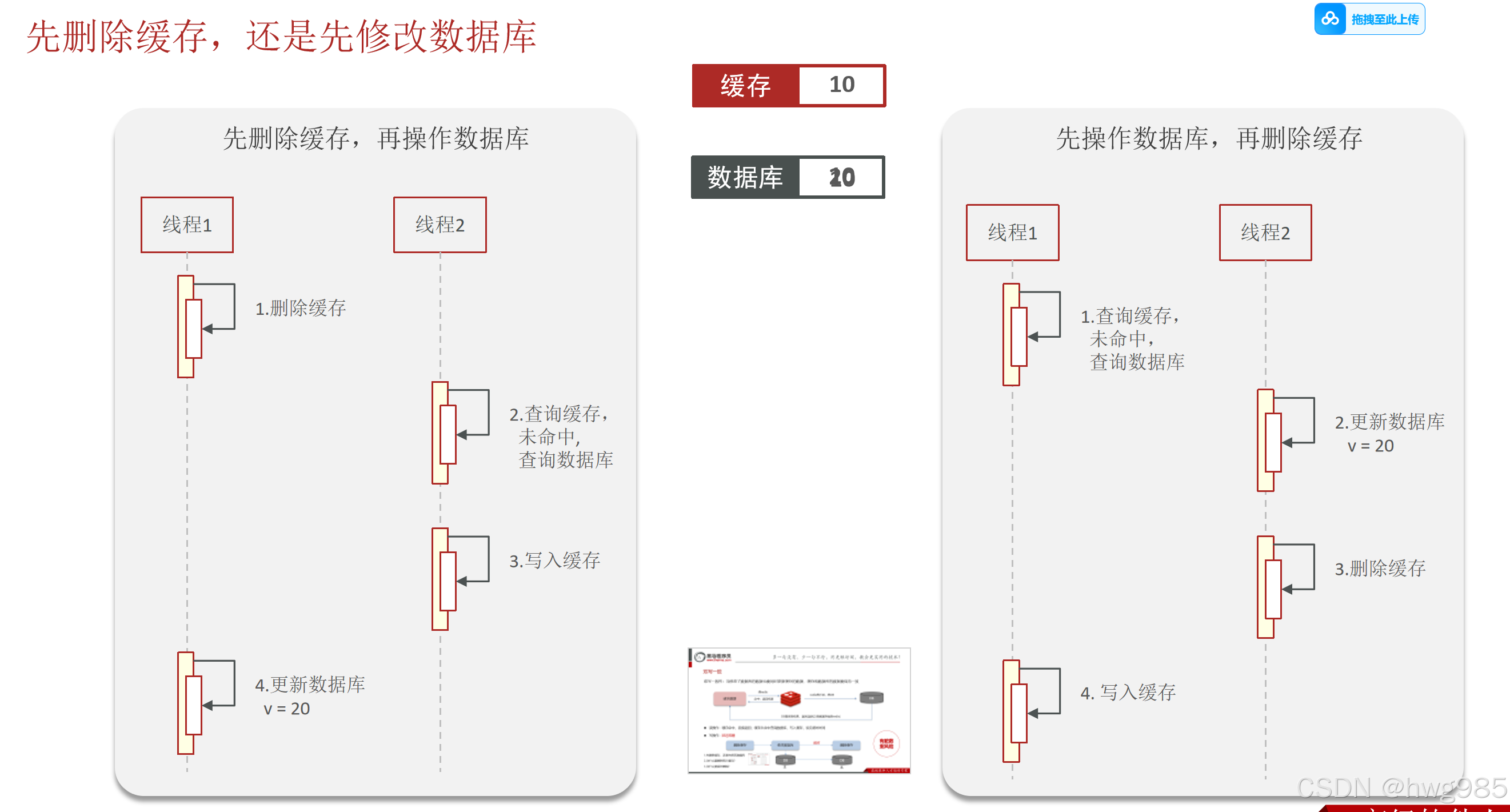
由于访问操作缓存和访问MySQL的线程1的两个操作之间不是原子性,中间来了其他线程就出现脏读了
cache:A
mysql:A
- T1删除A
- T2访问cache未命中,查询MySQL
- 写入cache=A
- T2 更新MySQL=B
结果:
cache:A
MySQL:B
方案2: 先更新数据库,后删除缓存(适合绝大多数的读多写少场景)
由于访问操作缓存和访问MySQL的线程1的两个操作之间不是原子性,中间来了其他线程就出现脏读了
cache:A
mysql:A
- T1查询了过期缓存A,未命中
- T2更新MySQL的A为B,
- T2删除缓存A
- 写入A
cache:A
MySQL:B
A!=B,不一致了,芭比Q了!!!
使用场景
适合绝大多数的读多写少场景
本方案翻车概率较低,因为翻车的要求必须是T1的写入MySQL操作比T2写入MySQL+T2写入缓存还要更耗时!
方案3:延迟双删(NPC)
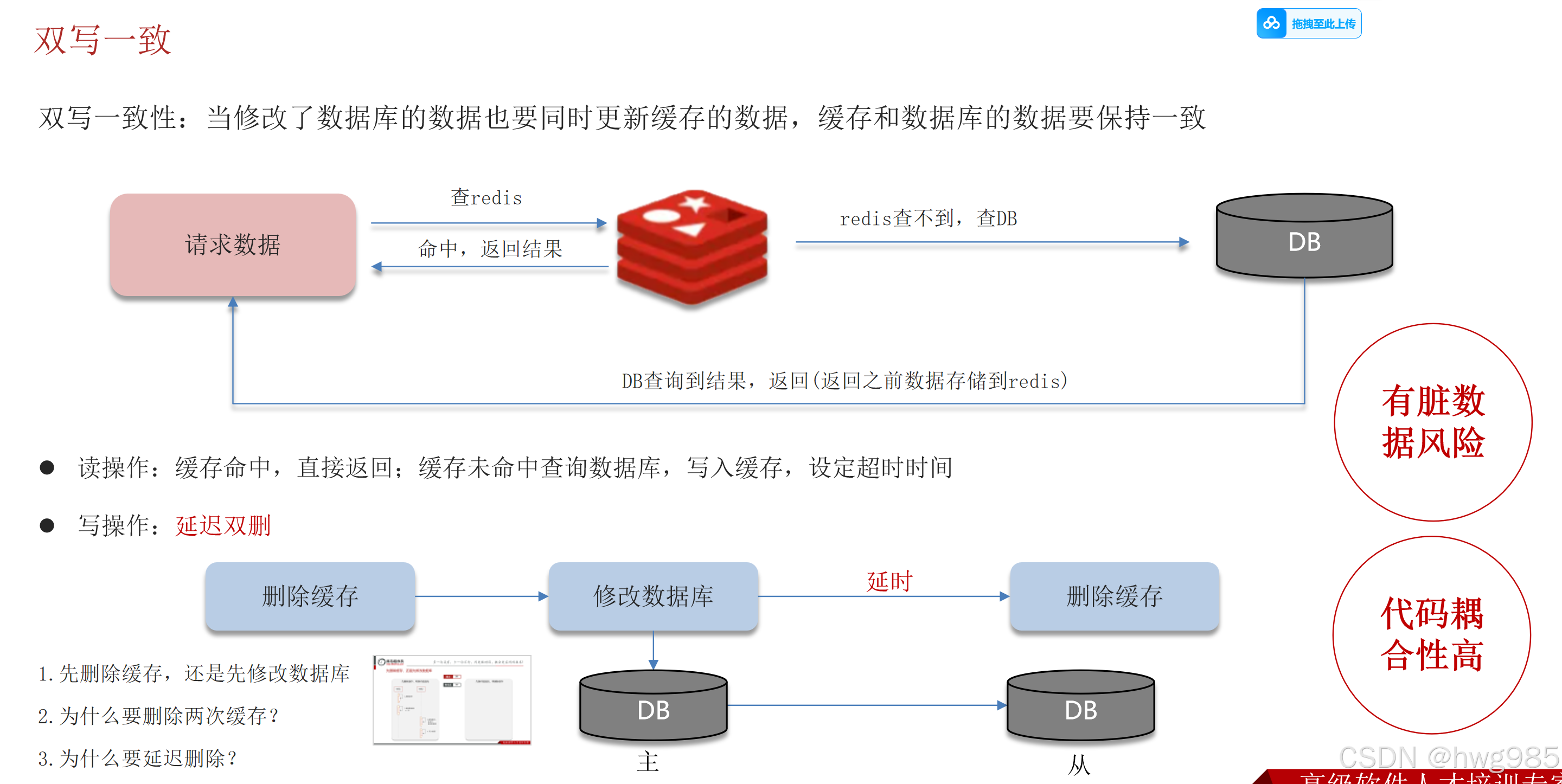
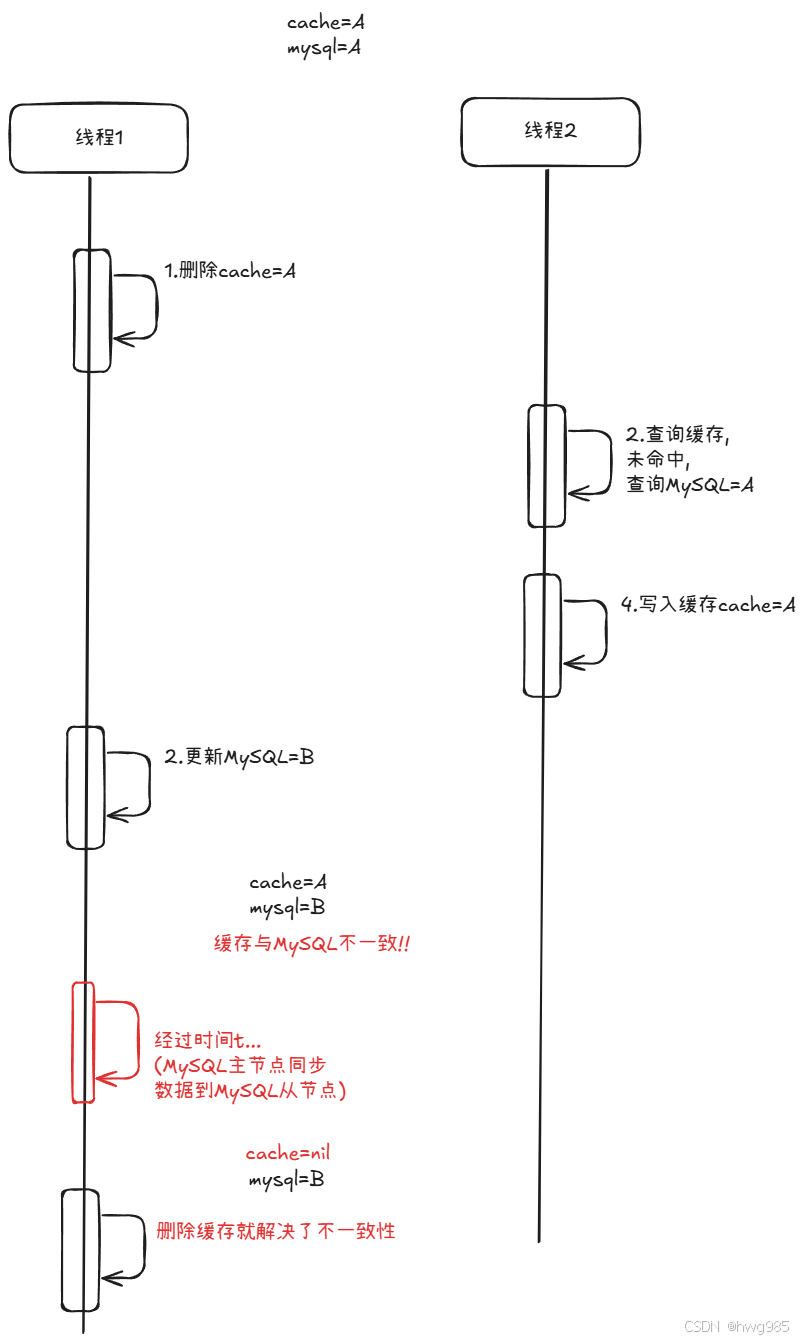
延迟双删策略与其他策略的区别在于T1更新MySQL之后延迟几秒在删除,为什么要延迟?原因是需要等待MySQL主从同步之后,再通过删除缓存的方式解决不一致,缓存都没了,就不存在不一致性啦!
适用场景:
当你使用方案1或方案2,但又非常担心(或实际遇到了)并发导致的脏数据问题,且无法引入Canal等更重的基础设施时,作为一种妥协的"补丁"方案
方案4:canal订阅MySQL的binlog来完成和Redis的同步(人上人)
binlog知识点的回顾
我们知道,binlog的形式有3种,row,statement和mix ,最初目的是用来MySQL主从同步,然后row格式里面记录的是具体的数值记录
,比如insert into (name,age,time) values ('mike',20,某个时间戳);
statement里面记录的是包含函数的语句insert into (name,age,time) values ('mike',20,NOW())
mix格式就是混着的,statement和row格式的都有
然后主节点进行了什么样的更新,从节点也进行什么样的更新.
然后本方案就是模拟这种更新策略,只不过不更新MySQL从节点,而是同步更新Redis节点,避免网络请求中的乱序性导致数据错乱!!
严格按照MySQL中数据变化,Redis中也进行严格的顺序变化
优点:
- 和业务完全解耦,更新MySQL的时候,没有额外操作
- 没有时序性问题,可靠性强
缺点:
- 往往需要引入更重量级的MQ(比如方案5),维护高可用性,额外的金钱成本很多!!
(springboot服务器一台,Redis专门的服务器一台,RocketMQ服务器又一台,canal还有要一台专门的服务器去部署,) - 数据同步压力大,如果canal崩溃了,那么长时间内,Redis都是旧数据
方案5:canal+RocketMQ(夯爆了)
canal订阅MySQL的binlog,监控所有库和所有表的变化,把变动通过MQ发送到下游服务,下游服务就是消费者,比如有订单服务,物流服务,积分服务,通过严格的顺序性变化,同步到下游所有的服务
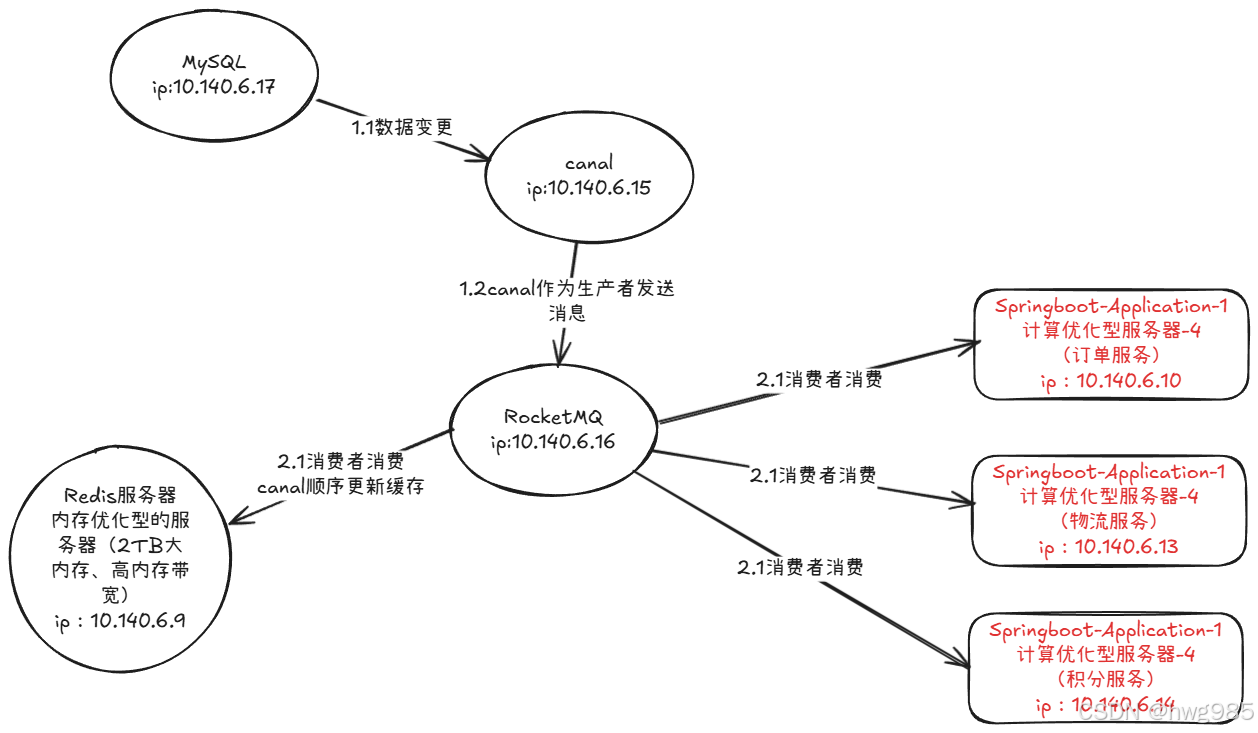
适用场景
- 大型微服务架构。
- 数据变更需要通知多个下游系统的场景。
- 数据库写入压力非常大,需要 MQ 来保护下游消费者的场景。
- 高并发、高性能的写场景(因为业务代码更新完DB就立刻返回了)。
- 对数据一致性要求高(要求"最终一致性"),无法忍受方案2的低概率脏数据。
- 系统架构清晰,希望将"缓存维护"这种非核心逻辑从业务代码中剥离的场景。