源码、配套笔记&讲解视频,点击文末名片
- 研究背景与动机
1)老问题:照片修复像"翻新旧书"
图像修复(去噪、超分、去块)就像把一本受潮起皱的旧书翻新:
- 去噪:把纸页上的小砂粒(噪声)拂掉;
- 超分:把模糊的小字补清晰;
- JPEG 去块:把压缩留下的方块痕抹平。
深度CNN很擅长干这活儿,但网络越深,就越容易忘记前面层学到的"早期线索"(细边、纹理的初级特征),导致"越到后面越想不起来前面说过啥"。这就是所谓的长程依赖缺失问题。
2)为什么深而"健忘"?------传话游戏的失真
想象一列工人排队修书:前面的人发现"第3页上半有细裂纹",往后传......
- 传统的"单一路径前馈"(VDSR/DRCN/DnCNN等)更像人挨人传话:信息只主要影响下一位,传远了就走样或消失;
- 有些网络加了跳连(Res/RED):能偶尔越级喊话,但能记住的远程信息仍然有限。
结果:当网络很深时,早期细节很难被后面的层长期、稳定地利用。
3)核心动机:让"早期线索"被长期保存并可随时调用
作者的直觉是:人类思考有"持久性"------学到的旧知识不会很快蒸发。那在网络里也该有一个"记忆仓库":
- 能把短期发现(当前层/附近层刚抓到的花纹)临时入库;
- 也能把早期层的有用信息长久保存,到后面随时按需取用;
- 同时要有个"门卫/闸门(gate)",学会该留多少旧记忆、该写多少新记忆,避免把噪声当宝也避免信息爆仓。
基于此,MemNet引入了"记忆块(Memory Block)":里面有递归单元(反复提炼当前状态,形成短期记忆)和门控单元(把来自之前所有记忆块的长期记忆与当前短期记忆拼起来,再学习权重决定取舍)。
4)工程上的三大痛点与目标
痛点 A:深网络训练/推理容易丢高频信息。
MemNet通过跨块的致密长程连接,把早期的中高频"线索"直接送到后面,减少"传话走样"。目标:细节更锐利、纹理更还原。
痛点 B:只学"直接映射"训练难。
MemNet采用残差重建(学"观测与干净之间的差"),让优化更稳。目标:更好训、更易收敛。
痛点 C:模型泛化与复用。
作者希望一个架构同时处理去噪、超分、去块三类任务,并且单模型覆盖多强度/多倍率/多质量。目标:统一、实用。
5)一句话总结
动机=给超深网络装上"记忆仓库+闸门":
把"当前发现"(短期记忆)与"早期经验"(长期记忆)统一管理、按需调度,让深层也能记住前面说过的重要细节,从而在去噪/超分/JPEG 去块上取得更好的效果与稳定性。
- 核心创新点
2.1 "记忆块":把"短期线索"和"长期经验"装进同一个仓库
- 怎么做:每个**记忆块(Memory Block)**里有两件核心部件:
- 递归单元:用多次残差单元反复提炼当前特征,形成短期记忆(像在同一处来回细刷几遍,把纹理/边缘刷干净);
- 门控单元:把之前所有记忆块的输出(长期记忆)与当前的短期记忆拼接,再用 1×1 卷积学一组自适应权重,决定"旧知识留多少、新线索存多少"。
- 要领:短期 × 长期,拼接后再门控,让网络在超深情况下也不忘早期细节。
2.2 "长程致密连接":前面有用的信息,后面都能直接拿
- 怎么做:在块与块之间建立长程、致密的连接,把早期/中期层的特征一路送到后面的记忆块与重建头;这能补回在普通前馈CNN中逐层丢失的中高频细节,并畅通梯度。
- 要领:不是"局部的Dense",而是跨块的全局Dense,专为图像复原的细节保真而设计。
2.3 "门控机制不走极端":按特征图而非按像素分配权重
-
怎么做:门控用 1×1 卷积在特征图层面学权重,控制长期与短期记忆的占比;相比 Highway Network 的"逐像素门控",这样参数更少、泛化更稳。
-
要领:轻量门控,更不容易过拟合。
2.4 "多重监督 + 加权集成":每一层的中间预测都被利用
-
怎么做:把每个记忆块的输出都送到同一个重建头做一次中间预测,训练时逐一监督;推理时再用一组自学的权重对这些中间结果做加权平均得到最终输出。
-
要领:像"多次排版,投票定稿",训练稳、效果好。
2.5 "残差重建":学"错误"更容易
-
怎么做:最终不直接学"干净图",而是学"残差图(观测与干净之差)",最后把残差加回输入得到输出;这能降低优化难度,更易收敛
-
要领:学差值不学全图,训练更顺手。
2.6 "专为复原而生的超深设计":80层、统一三大任务
-
怎么做:整网由特征提取(FENet)→ 多记忆块 → 重建网(ReconNet)构成,深度可达约80层;同一结构直接用于去噪 / 超分 / JPEG 去块三类任务。
-
要领:一套骨架,多种场景,且在很深的情况下仍保持信息不过期。
2.7 与相关方法的区别(一眼看懂)
-
对比 DRCN:MemNet 的基本单元是记忆块(非单层卷积),权重不共享,并有跨块致密连接;因此信息流动与梯度回传更顺畅,训练并不依赖多监督手段。
-
对比 DenseNet:DenseNet 的稠密连接局限在每个 dense block 内(做分类的局部特征复用),而 MemNet 做的是跨记忆块的全局致密连接,针对图像复原的细节补偿。
一句话总括
MemNet = "记忆块(短期×长期)" + "长程致密连接" + "轻量门控" + "多监督投票" + "残差重建":
让超深网络记得住前面学到的细节,把有用信息一路"护送"到最后,从而在去噪/超分/JPEG 去块上更稳更清晰。
- 模型的网络结构
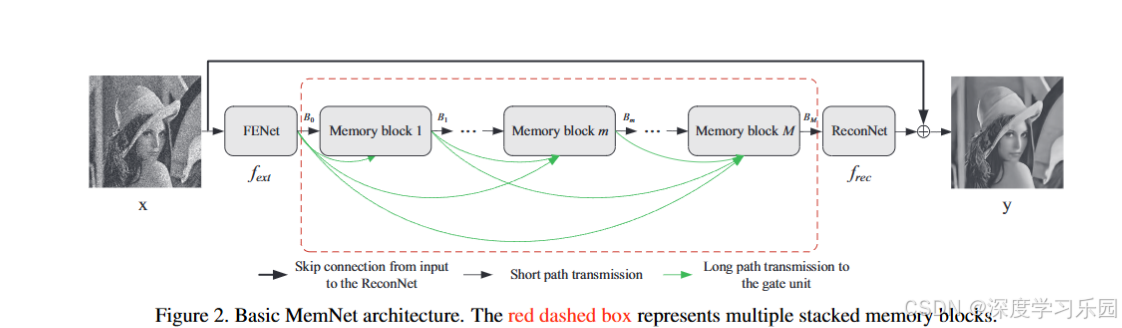
这张图可以看成是一条**"信息接力链"**:从模糊/带噪的输入图像出发,一路经过多个"记忆工坊",边清理边保留经验,最后输出干净的结果。
我们来一段一段拆解:
🧩 一、整体结构:三段式设计
整网可以分为三大部分:
暂时无法在飞书文档外展示此内容
在图中,红色虚框包围的部分就是"多个记忆块串联"的中间修复核心。
🧠 二、FENet:把图像"翻译成特征语言"
- 输入是带噪或模糊的图像 xxx。
- FENet 用几层卷积,把图像转换成特征图(相当于让网络"看懂"图像的纹理和边缘)。
- 输出的特征记作 B0B_0B0,这就是"第0份记忆"。
👉 可以类比成:给一张模糊照片拍个底稿草图,让后面的修复工坊有参照物。
🧱 三、Memory Blocks:一个个"有记忆的修复工坊"
这部分是 MemNet 的灵魂。每个记忆块由两部分组成:
① 递归单元(短期记忆 Short-term Memory)
- 就像工坊里的一组工人,反复打磨当前特征几次(通过多层残差单元),让这一阶段的图像细节越来越清晰。
- 输出的结果就是这批工人的"短期记忆"------它只代表当前阶段的理解。
② 门控单元(长期记忆 Long-term Memory) - 每个工坊在开始工作时,会收到之前所有工坊留下的经验(即长程绿色箭头那部分)。
- 它把这些"历史经验"与当前的短期记忆拼在一起,然后用一个"门控卷积"来决定:
- "旧的经验留多少?新的发现加多少?"
- 这样一来,网络就不会"遗忘"前面学到的细节,也不会重复犯错。
③ 多块串联 - 这种记忆块会重复好几层(例如 M=6~10 个),前面的块像初级工坊,后面的块像高级工坊,信息在中间不断循环、整合、提纯。
- 每个记忆块都会输出自己的结果,并把它传给下一块,同时作为"长期记忆"备份。
💡 形象比喻:
每个记忆块像一个修图师团队: - 他们手上有上个团队留下的经验(长期记忆),
- 也有自己反复修整的最新成果(短期记忆),
- 两者融合后再传下去,越修越细致。
🔗 四、长程致密连接(绿色箭头)
在图中,绿色箭头代表"长期记忆传输线":
- 不只是相邻的块互联,而是每一块都能访问前面所有块的输出。
- 这样后面的工坊可以直接借用前面的"经验特征",而不需要重新学一遍。
👉 就像一条"知识高速公路",让信息不再逐层衰减。
这既保持了高频细节(纹理、边缘),又使得梯度流动更顺畅,网络容易训练。
🏗️ 五、ReconNet:汇总成果,拼出干净图像
- 当所有的记忆块都工作完后,ReconNet 作为"终审编辑"出场。
- 它把最后的特征结果 BMB_MBM 和最初的输入 xxx融合(黑色直线那条是"跳连"),预测出"残差图"(即噪声或误差)。
- 最终输出 y=x+残差y = x + \text{残差}y=x+残差,就得到了干净、清晰的图像。
💡 类比:就像报刊出版前的总编辑,把各个部门写好的稿子整合、修订,输出最终成品。
🔁 六、"短路+长路"双路线传输(图里的黑线 vs 绿线)
- 黑色箭头(short path):是相邻模块之间的普通传递,保证"信息连续";
- 绿色箭头(long path):是跨越多个模块的"长期记忆通道",保证"信息不丢";
- 两者结合,就像网络里有"快递专线"和"铁路干线"------既能快速传递最近的更新,又能随时调用历史经验。
🎯 七、整体总结(一句话概括)
MemNet = 特征提取 + 多级有记忆的修复工坊 + 最终重建整合
它让深层神经网络拥有"长期记忆",既能记住前面的经验,又能持续学习新的细节。
最后得到的图像更清晰、更锐利,尤其在超分辨率、去噪、去块任务中表现优异。
模型的核心不足与缺陷
虽然 MemNet 在图像复原任务(去噪、超分、去块)上表现出色,但它仍存在一些内在的限制与缺点,从工程与理论角度看都有改进空间
🚧 1. 模型过深,训练代价高、效率低
MemNet 为了解决"长期依赖遗忘"问题,设计了超深结构(约80层),每个记忆块内部还包含多次递归运算。
-
问题:这使得训练时间非常长(论文中提到:训练一个 MemNet 模型需约 5 天、仅用 91 张图像、1 块 Tesla P40 GPU)
-
。
-
形象理解:就像一个"超级复杂的流水线",每个工人都很忙但流程太长,整体速度被拖慢。
-
影响:推理(测试)时也较慢,不适合实时或移动端应用。
🧮 2. 记忆机制带来的计算与存储开销大
- 每个记忆块都会存储来自所有前序块的特征图(长程连接),并在门控单元中做融合。
- 这意味着显存(GPU 内存)占用非常高,训练大图像时容易"爆显存"。
- 同时这些多重连接在反向传播时也会带来额外梯度计算负担。
💡 类比:这像一个"信息仓库",每一层都要查阅所有老档案,信息冗余且占空间大。
⚙️ 3. 门控单元设计简单,可能无法精细控制记忆更新
- 门控单元采用 1×1 卷积 来决定长短期记忆的融合比例。虽然轻量,但它只在特征层面加权,没有真正学习"内容依赖"的动态机制。
- 因此在复杂场景(如非均匀噪声、结构纹理变化大时)容易记得不该记的东西,导致复原细节不一致。
💡 类比:像是"仓库管理员"只按文件厚度分配空间,而不看文件的重要性。
🧱 4. 递归与多监督增加实现复杂度
- 每个记忆块都有多个递归单元,还带中间输出用于多重监督。
- 这种设计在理论上稳训练,但实现起来很复杂,调参难度大;
- 如果监督权重(α)不合适,反而会导致各层竞争学习、影响收敛稳定性。
💡 类比:多位导师同时指导学生,反馈频繁但方向不一,学生(网络)反而困惑。
🧩 5. 泛化能力有限:同一模型跨任务表现仍需微调
虽然作者声称 MemNet 能"一网多用"(去噪、超分、去块),但实际上不同任务仍需单独训练或调参。
- 这说明网络虽然共享结构,但在特征分布变化大的任务间,泛化性不如预期。
- 在真实复杂噪声环境(非高斯噪声)下效果下降明显。
💡 类比:一个多才多艺的工人,虽然能做木工、电工、油漆,但每项都要重新培训。
📉 6. 没有结合自注意力或全局特征机制(设计时代局限)
- MemNet 的设计主要依赖卷积与局部特征堆叠。
- 没有像现代网络(例如 SwinIR、Restormer 等)那样利用自注意力机制去捕捉全局依赖。
- 因此在大尺度图像或复杂全局结构中,它的"记忆"仍然是局部化的。
💡 类比:工人记得细节很多,但看不到整幅画的全貌。
🎯 小结一句话
MemNet 的优点是"记得住",缺点是"太会记、太慢记"。
它通过持久记忆机制解决了信息遗忘的问题,但代价是:
- 模型超深、计算量大、实现复杂;
- 门控与记忆调度机制简单,难以高效利用所有信息;
- 泛化与全局理解能力不足。
- 改进方向与启示(如何优化 MemNet 思想)
🌉 一、从"记忆堆叠"到"特征再利用"
MemNet 的核心思想是:把过去的特征留着用。这启发了后续很多网络改进成更灵活的"特征复用"机制。
- 改进思路 1:引入更高效的密集连接(Dense 连接)
- MemNet 的长程连接是"全局级别"的(跨多个记忆块),但实现复杂、计算量大。
- 后续的 RDN(Residual Dense Network) 和 EDSR 改进为 局部密集连接 + 全局残差,既保留信息流动,又减轻了参数和显存负担。
- 🧩 类比:MemNet 是"所有档案全都备份",而 RDN/EDSR 是"只保存重要的文件摘要"。
🧬 二、从"静态记忆"到"自适应注意力"
MemNet 的门控机制用 1×1 卷积学习每个特征图的权重,但它是静态的(输入固定,权重不变)。
- 改进思路 2:引入注意力机制(Attention)或通道自适应(Channel Attention)
- 像 RCAN(Residual Channel Attention Network) 就是直接继承了 MemNet 的"信息筛选"思路,但把静态门控升级为动态注意力模块。
- 网络能根据内容自动判断"该看哪里",从而更精准地利用长期与短期信息。
- 💡 类比:MemNet 的门是"固定密码锁",而注意力机制是"智能指纹门锁",能自动识别重要信息。
⚙️ 三、从"超深结构"到"高效轻量化"
MemNet 用了 80 层深度,虽然效果好,但训练耗时、内存占用高。
- 改进思路 3:模块化与高效化设计
- 后来的 DRRN、CARN、SwinIR 等模型通过 可复用模块 + 层内共享权重 的方式减少计算量。
- 轻量型变体(如 MemNet-lite)可将门控与递归单元压缩合并。
- 💡 类比:MemNet 是"大型工厂流水线",而改进版是"模块化生产线",更灵活省电。
🛰️ 四、从"局部记忆"到"全局依赖建模"
- MemNet 的特征融合仍以局部卷积为主,无法有效建模全局关系。
- 改进思路 4:引入 Transformer / 自注意力 全局建模机制
- Restormer、SwinIR、NLSN 等模型借鉴 MemNet 的"信息记忆"思想,但进一步扩展为"全局自适应记忆"。
- 这样模型不仅能记住前面的信息,还能跨空间、跨层"全局取特征"。
- 💡 类比:MemNet 记得"我上次修这块木头的纹理",而 SwinIR 能记得"整张桌面的结构"。
🎯 五、从"单任务复原"到"多任务记忆共享"
MemNet 在设计上虽然能兼容三类任务(去噪、去块、超分辨率),但要分别训练。
- 改进思路 5:任务共享 + 记忆迁移(Multi-task + Memory Transfer)
- 可将不同任务的特征记忆分为"共用层 + 任务专属层",实现跨任务知识迁移。
- 类似 NTIRE 竞赛 中的"统一复原网络"(Unified Restoration Network)思想。
- 💡 类比:原来的每个项目组单独写总结,现在是"公司统一知识库",任务共享经验。
🔭 六、MemNet 对后续研究的启示总结
完整文档内容点击文末名片↓↓↓