1、PDF文件加载和切片
PDF 中的文本通常是通过文本框表示。它们也可能包含图像。PDF 解析器可能会执行以下作的某种组合:
-
通过启发式或 ML 推理将文本框聚合为行、段落和其他结构;
-
对图像运行 OCR 以检测其中的文本;
-
将文本分类为属于段落、列表、表格或其他结构;
-
将文本构建为表格行和列或键值对。
Python中有许多 PDF 解析器集成。有些是简单且相对较低的;其他 API 将支持 OCR 和图像处理,或执行高级文档布局分析。正确的选择将取决于具体的需求。
2、PyPDF
PyPDFLoader将返回一个Document对象列表(每页一个),在Document的属性中包含页面文本的单个字符串(详情见后文中pdf加载示例的输出结果)
1> 安装Langchain的第三方库
bash
pip install langchain langchain-community2> PDF文件加载示例
python
# 导入Python的异步I/O库
import asyncio
# 导入LangChain第三方库PyPDFLoader,这是一个用于加载PDF文件的工具
from langchain_community.document_loaders import PyPDFLoader
# 自定义一个异步函数,接收需要加载的文件名
async def pdfLoader(file_name):
# PyPDFLoader将返回一个Document对象列表(每页一个),
# 在Document的属性中包含页面文本的单个字符串
loader = PyPDFLoader(file_name)
pages = []
# 使用异步 for 循环逐页读取,避免一次性加载整个 PDF 文件到内存
# (alazy_load()是 PyPDFLoader 的异步方法,用于惰性加载 PDF 页面)
async for page in loader.alazy_load():
# 每页都会返回一个Document对象,包含页面文本和元数据
pages.append(page)
# 打印总页数
print(len(pages))
# 打印第二页的内容(Document对象)
print(pages[1]) # pages[0]是第一页(第一页是封面,这里不演示打印,封面内容也是可以读取到的)
async def main():
await pdfLoader(".\\documents\\ebpf-firewall-LPC.pdf")
# 使用 asyncio.run () 运行主函数,启动异步事件循环
asyncio.run(main())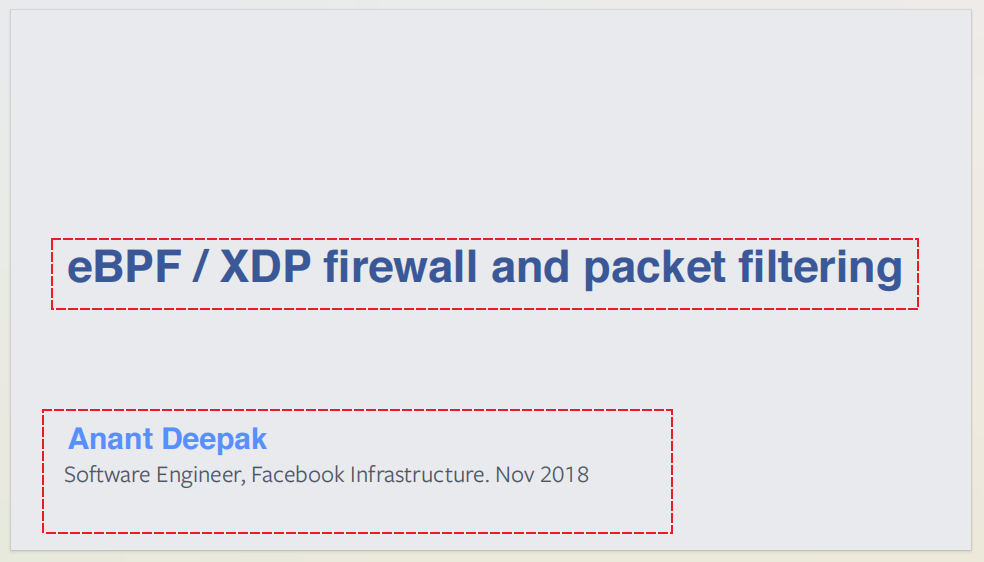
输出结果
bash
# 加载的文档总行数,本实例加载的文档是29行
29
# 输出的第二页Document对象(以下给出各字段详细含义)
# page_content表示文档内容
page_content='Software Engineer, Facebook Infrastructure. Nov 2018
eBPF / XDP firewall and packet filtering
Anant Deepak' metadata={
'producer': 'MacOSX10.13.6QuartzPDFContext', # 使用 MacOS 10.13.6 的 QuartzPDFContext 生成
'creator': 'Keynote', # 使用 Apple Keynote 创建(演示文稿软件)
'creationdate': "D:20181030055304Z00'00'", # 创建时间:2018 年 10 月 30 日 05:53:04 UTC
'title': 'edgewall-LPC', # 文档标题
'moddate': "D:20181030055304Z00'00'", # 修改时间:与创建时间相同
'source': '.\\documents\\ebpf-firewall-LPC.pdf',
'total_pages': 29, # 总页数
'page': 1, # 当前是第 1 页(索引从 0 开始)
'page_label': '2' # 页面标签为 2(可能是实际显示的页码)
}3、Unstructured(非结构化文档加载器)
非结构化文档加载器可以对文档进行更精细化的分隔(比如,分割成不同的段落、标题、表格、或者其他结构)、或者从图像中提取文本。Unstructured将返回Document对象列表,其中每个对象列表代表页面上的一个结构。Document中存储元数据的页面和与元数据相关的其他信息(比如table对象的行和列)。
1>本地构建Unstructured环境
在本地解析需要安装其他依赖项。
Poppler (PDF 分析)
-
Linux的:
apt-get install poppler-utils -
苹果电脑:
brew install poppler
Tesseract (OCR)
-
Linux的:
apt-get install tesseract-ocr -
苹果电脑:
brew install tesseract -
Windows:https://github.com/UB-Mannheim/tesseract/wiki#tesseract-installer-for-windows
我们还需要安装 PDF 解析器:unstructured
2> 安装Langchain第三方库
bash
pip install langchain langchain-community langchain-unstractured iPython 等等UnstructuredLoader 是 LangChain 中用于加载非结构化文档(如 PDF、Word、HTML 等)的工具,以下是接口参数(详见官方文档:https://python.langchain.com/api_reference/unstructured/document_loaders/langchain_unstructured.document_loaders.UnstructuredLoader.html#langchain_unstructured.document_loaders.UnstructuredLoader):
-
file_path: str | Path | liststr | listPath | None = None,
指定要加载的 PDF 文件路径(可以是单个路径或者多个文件路径的列表)。可以是本地文件路径或 URL。
-
file: IObytes | listIO\[bytes] | None = None,
文件对象或文件对象列表。用于直接传入已打开的文件对象。
-
partition_via_api: bool = False,
是否通过 API 进行文档分区处理。如果为True,会使用 Unstructured API 服务处理文档。
-
post_processors: listCallable\[\[str, str]] | None = None,
文档处理后的后置处理器列表。每个处理器都是一个函数,接收字符串输入并返回处理后的字符串。
-
api_key: str | None = None,
Unstructured API 的 API 密钥。当partition_via_api为True时需要提供。
-
client: UnstructuredClient | None = None,
预配置的 Unstructured 客户端实例。如果提供,将使用此客户端而不是创建新的。
-
url: str | None = None,
Unstructured API 的 URL。当partition_via_api为True时使用。
-
web_url: str | None = None,
要加载的网页 URL。用于从网页加载内容。
-
**kwargs: Any,
其他关键字参数,会传递给底层的文档处理函数。
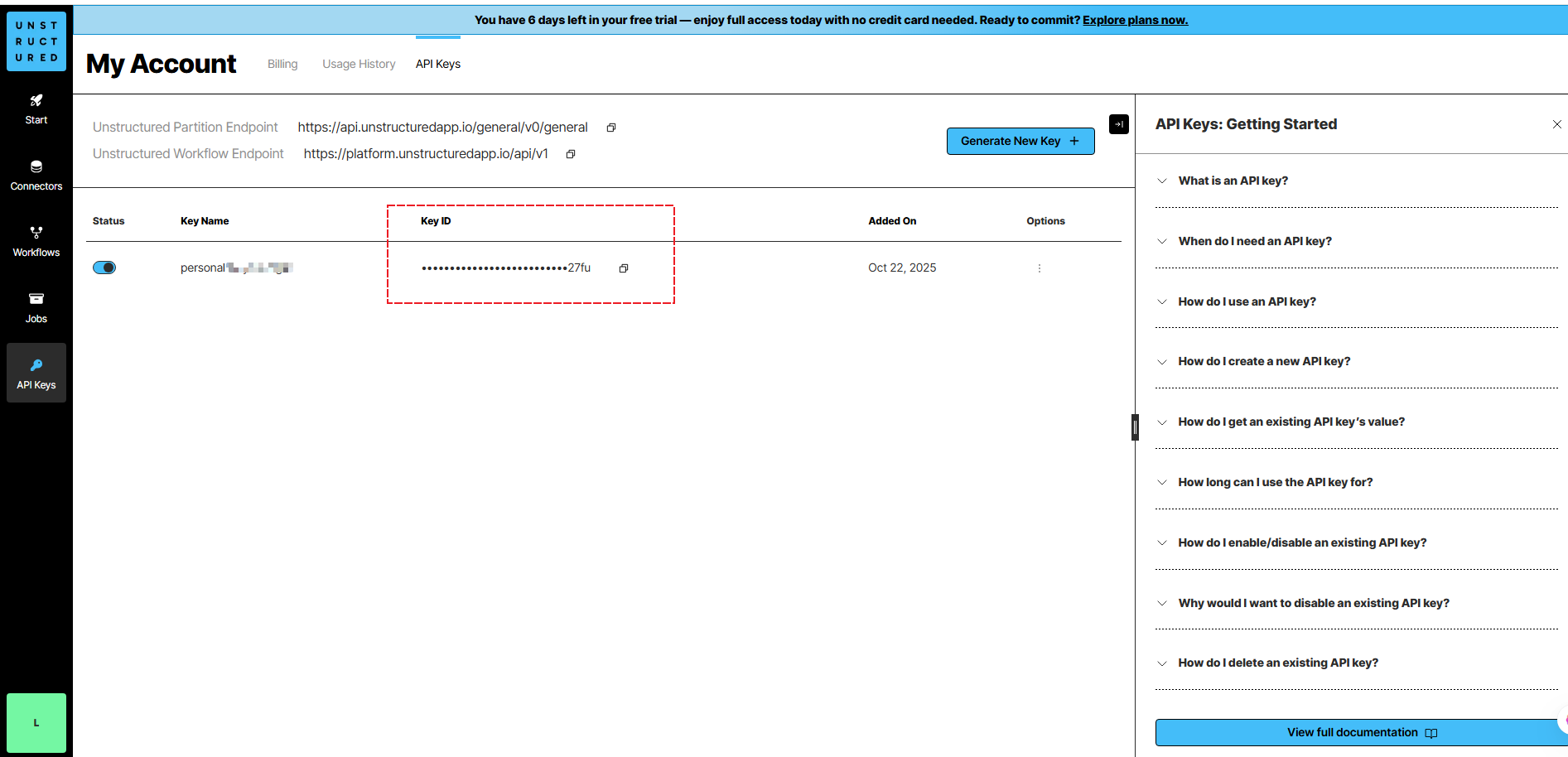
3> 申请API Key
前往unstructured.io注册 Unstructured 并生成 API 密钥。

4> PDF文档加载示例
python
# 导入UnstructuredLoader包
from langchain_unstructured import UnstructuredLoader
# PDF文档路径
file_path=r"C:\ebpf-firewall-LPC.pdf"
loader_local = UnstructuredLoader(
file_path=file_path,
strategy="hi_res",
partition_via_api=True, # 调用API接口的话:True
coordinates=True,
api_key='*****************************27fu' # API KEY
)
docs_local = []
for doc in loader_local.lazy_load():
docs_local.append(doc)
print(docs_local[1])输出结果:
bash
page_content = 'eBPF / XDP firewall and packet filtering'
metadata = {
'source': 'C:\\Users\\wangxiaolong\\Downloads\\ebpf-firewall-LPC.pdf',
'coordinates': {
'points': [
[133.40505981445312, 649.6126098632812],
[133.40505981445312, 796.646240234375],
[2500.917724609375, 796.646240234375],
[2500.917724609375, 649.6126098632812]
],
'system': 'PixelSpace',
'layout_width': 2667,
'layout_height': 1500
},
'filetype': 'application/pdf',
'languages': ['eng'],
'page_number': 2,
'filename': 'ebpf-firewall-LPC.pdf',
'category': 'Title',
'element_id': '945970bbe1d4faf71a2bfcccf51ec038'
}