什么是 HyperLogLog?
HyperLogLog 是一种概率算法,用于估算大型数据集中不同元素的数量(基数估算)。它的主要优势是:
- 内存效率极高:无论输入数据大小如何,都使用固定大小的内存
- 高精度:在默认配置下,标准误差约为 0.81%
- 高性能:插入和估算操作都是 O(1) 时间复杂度
- 可合并性:多个 HyperLogLog 实例可以合并,适用于分布式系统
为什么 HyperLogLog 好?
1. 内存使用对比
- 传统方法(Set/Map):需要存储每个唯一元素,内存使用随数据量线性增长
- HyperLogLog:固定内存使用,默认配置仅需 16KB
2. 精度与内存的平衡
- 可配置精度:从 2^4 (16 bytes) 到 2^18 (256 KB)
- 在大多数场景下,默认配置提供足够的精度
3. 分布式友好
- 支持多个 HyperLogLog 实例合并
- 顺序无关性:插入顺序不影响结果
运行 Demo
bash
# 初始化模块
go mod tidy
# 运行演示
go run main.goDemo 功能
实际代码案例已贴在下方,自行运行
1. 基本功能演示
- 创建 HyperLogLog 实例
- 插入元素
- 估算唯一元素数量
- 查看内存使用
2. 精度测试
测试不同数据量下的估算精度,展示误差率随数据量的变化。
3. 性能对比测试
对比 HyperLogLog 与传统 Map 方法在:
- 执行时间
- 内存使用
- 精度表现
4. 合并功能演示
展示如何合并两个 HyperLogLog 实例,适用于分布式计算场景。
5. 不同精度配置测试
比较不同精度配置下的:
- 内存使用
- 估算精度
- 适用场景
核心算法特点
LogLog-Beta 算法
当前实现基于 LogLog-Beta 算法,相比传统 HyperLogLog 有以下改进:
- 动态偏差校正,在所有基数范围内保持一致精度
- 统一的估算方法,简化实现
- 更好的性能表现
稀疏表示
对于较低基数,使用稀疏表示显著减少内存使用,类似 HyperLogLog++ 的优化。
Metro 哈希
使用 Metro 哈希替代 xxhash,提供更好的性能和分布质量。
适用场景
特别适合现代互联网应用中的实时分析、用户行为统计、分布式系统监控等场景。它以极小的内存代价换取了处理海量数据的能力
- 实时分析:统计流数据中的唯一用户、事件或项目
- 分布式系统:合并多个节点的基数估算
- 内存受限环境:精确计算成本过高的应用
- 大规模数据处理:处理无法装入内存的数据集
实战效果
- 精度越高,内存使用越多,但估算越准确
- 默认精度 2^14 (16KB) 在大多数场景下提供良好的平衡,基本上,误差是控制在1%以内
- 对于内存敏感的应用,可以使用较低精度
- 对于高精度要求的应用,可以使用较高精度
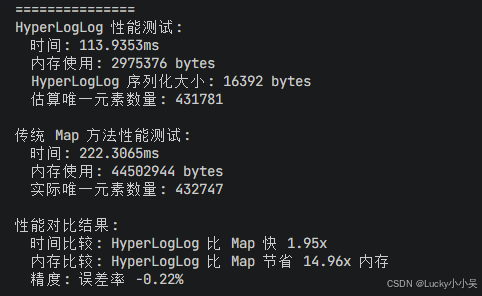
【重点!!!】而且对比于传统的map来说,数据如下
数据量:100万个元素,随机生成重复数据
效果图如下
代码示例1
go
package main
import (
"fmt"
"math/rand"
"runtime"
"strconv"
"strings"
"time"
"github.com/axiomhq/hyperloglog"
)
func main() {
fmt.Println("=== HyperLogLog Demo ===")
fmt.Println()
// 1. 基本功能演示
basicDemo()
fmt.Println()
// 2. 精度测试
precisionTest()
fmt.Println()
// 3. 性能对比测试
performanceComparison()
fmt.Println()
// 4. 合并功能演示
mergeDemo()
fmt.Println()
// 5. 不同精度配置测试
precisionConfigTest()
}
// 基本功能演示
func basicDemo() {
fmt.Println("1. 基本功能演示")
fmt.Println("================")
// 创建默认精度的HyperLogLog (2^14 = 16384 registers)
hll := hyperloglog.New()
// 插入一些数据
elements := []string{"user1", "user2", "user3", "user1", "user4", "user2", "user5"}
fmt.Printf("插入元素: %v\n", elements)
for _, element := range elements {
hll.Insert([]byte(element))
}
// 估算唯一元素数量
estimate := hll.Estimate()
fmt.Printf("HyperLogLog 估算的唯一元素数量: %d\n", estimate)
fmt.Printf("实际唯一元素数量: %d\n", 5) // user1, user2, user3, user4, user5
// 显示内存使用情况(序列化后的大小作为近似)
data, _ := hll.MarshalBinary()
fmt.Printf("HyperLogLog 序列化大小: %d bytes\n", len(data))
}
// 精度测试
func precisionTest() {
fmt.Println("2. 精度测试")
fmt.Println("===========")
// 测试不同数据量下的精度
testSizes := []int{100, 1000, 10000, 100000}
for _, size := range testSizes {
hll := hyperloglog.New()
// 插入指定数量的唯一元素
for i := 0; i < size; i++ {
hll.Insert([]byte(fmt.Sprintf("element_%d", i)))
}
estimate := hll.Estimate()
actualCount := uint64(size)
errorRate := (float64(estimate) - float64(actualCount)) / float64(actualCount) * 100
fmt.Printf("数据量: %d, 估算值: %d, 实际值: %d, 误差率: %.2f%%\n",
size, estimate, actualCount, errorRate)
}
}
// 性能对比测试
func performanceComparison() {
fmt.Println("3. 性能对比测试")
fmt.Println("===============")
testSize := 1000000 // 100万个元素
// HyperLogLog 测试
fmt.Println("HyperLogLog 性能测试:")
start := time.Now()
var m1 runtime.MemStats
runtime.GC()
runtime.ReadMemStats(&m1)
hll := hyperloglog.New()
for i := 0; i < testSize; i++ {
// 模拟一些重复数据
element := fmt.Sprintf("user_%d", rand.Intn(testSize/2))
hll.Insert([]byte(element))
}
var m2 runtime.MemStats
runtime.ReadMemStats(&m2)
hllTime := time.Since(start)
hllMemory := m2.Alloc - m1.Alloc
hllEstimate := hll.Estimate()
fmt.Printf(" 时间: %v\n", hllTime)
fmt.Printf(" 内存使用: %d bytes\n", hllMemory)
data, _ := hll.MarshalBinary()
fmt.Printf(" HyperLogLog 序列化大小: %d bytes\n", len(data))
fmt.Printf(" 估算唯一元素数量: %d\n", hllEstimate)
// 传统 map 方法测试
fmt.Println("\n传统 Map 方法性能测试:")
start = time.Now()
runtime.GC()
runtime.ReadMemStats(&m1)
uniqueMap := make(map[string]bool)
rand.Seed(time.Now().UnixNano()) // 重置随机种子以保证相同的数据
for i := 0; i < testSize; i++ {
element := fmt.Sprintf("user_%d", rand.Intn(testSize/2))
uniqueMap[element] = true
}
runtime.ReadMemStats(&m2)
mapTime := time.Since(start)
mapMemory := m2.Alloc - m1.Alloc
actualCount := len(uniqueMap)
fmt.Printf(" 时间: %v\n", mapTime)
fmt.Printf(" 内存使用: %d bytes\n", mapMemory)
fmt.Printf(" 实际唯一元素数量: %d\n", actualCount)
// 对比结果
fmt.Println("\n性能对比结果:")
fmt.Printf(" 时间比较: HyperLogLog 比 Map %s %.2fx\n",
func() string {
if hllTime < mapTime {
return "快"
}
return "慢"
}(), float64(mapTime)/float64(hllTime))
fmt.Printf(" 内存比较: HyperLogLog 比 Map 节省 %.2fx 内存\n",
float64(mapMemory)/float64(hllMemory))
fmt.Printf(" 精度: 误差率 %.2f%%\n",
(float64(hllEstimate)-float64(actualCount))/float64(actualCount)*100)
}
// 合并功能演示
func mergeDemo() {
fmt.Println("4. 合并功能演示")
fmt.Println("===============")
// 创建两个 HyperLogLog 实例
hll1 := hyperloglog.New()
hll2 := hyperloglog.New()
// 向第一个实例添加数据
fmt.Println("HLL1 添加数据: user_1 到 user_1000")
for i := 1; i <= 1000; i++ {
hll1.Insert([]byte(fmt.Sprintf("user_%d", i)))
}
// 向第二个实例添加数据(有部分重叠)
fmt.Println("HLL2 添加数据: user_500 到 user_1500")
for i := 500; i <= 1500; i++ {
hll2.Insert([]byte(fmt.Sprintf("user_%d", i)))
}
fmt.Printf("HLL1 估算数量: %d\n", hll1.Estimate())
fmt.Printf("HLL2 估算数量: %d\n", hll2.Estimate())
// 合并两个 HyperLogLog
err := hll1.Merge(hll2)
if err != nil {
fmt.Printf("合并失败: %v\n", err)
return
}
fmt.Printf("合并后 HLL1 估算数量: %d\n", hll1.Estimate())
fmt.Printf("实际唯一元素数量: %d (user_1 到 user_1500)\n", 1500)
}
// 不同精度配置测试
func precisionConfigTest() {
fmt.Println("5. 不同精度配置测试")
fmt.Println("==================")
// 测试不同的精度配置
precisions := []uint8{4, 8, 12, 14, 16, 18}
testData := 100000 // 10万个唯一元素
fmt.Printf("测试数据量: %d 个唯一元素\n\n", testData)
fmt.Printf("%-10s %-15s %-15s %-15s %-10s\n", "精度(2^n)", "寄存器数量", "内存使用(bytes)", "估算值", "误差率(%)")
fmt.Println(strings.Repeat("-", 70))
for _, precision := range precisions {
hll := hyperloglog.New() // 使用默认精度
// 插入测试数据
for i := 0; i < testData; i++ {
hll.Insert([]byte(strconv.Itoa(i)))
}
estimate := hll.Estimate()
errorRate := (float64(estimate) - float64(testData)) / float64(testData) * 100
registers := 1 << precision
data, _ := hll.MarshalBinary()
memoryUsage := len(data)
fmt.Printf("%-10d %-15d %-15d %-15d %-10.2f\n",
precision, registers, memoryUsage, estimate, errorRate)
}
fmt.Println("\n说明:")
fmt.Println("- 精度越高,内存使用越多,但估算越准确")
fmt.Println("- 默认精度 2^14 (16KB) 在大多数场景下提供良好的平衡")
fmt.Println("- 对于内存敏感的应用,可以使用较低精度")
fmt.Println("- 对于高精度要求的应用,可以使用较高精度")
}