从0到1,构建你的专属AI知识库:My-Chat-LangChain项目深度解析
摘要: 你是否曾想过,如何打造一个能"学习"特定网页或私有PDF文档,并像专家一样回答你问题的个性化AI?本文将为你完整揭秘一个名为My-Chat-LangChain的全栈AI应用。我们将从项目的设计理念、技术架构出发,深入到每一行核心代码的实现,手把手带你了解如何利用LangChain、FastAPI和Streamlit这三大神器,从零开始构建一个强大的企业级RAG(检索增强生成)系统。
一、前言:让人人都能拥有专属知识AI
大家好!想象一下,你能否拥有一个私人AI助理,它不仅能和你聊天,还能成为特定领域的"专家"?比如,让它精读一篇冗长的在线技术文档,然后用自然语言回答你的任何疑问;或者,让它学习一份几十页的PDF市场报告,并帮你快速提炼核心观点。
这正是My-Chat-LangChain项目诞生的初衷------将强大的大语言模型(LLM)与你指定的私有知识相结合,创造一个真正为你所用的、可定制的AI知识库。
在这篇博客中,我将毫无保留地分享这个项目的全部细节:从它的两大核心功能,到前后端分离的架构设计,再到每一段关键代码的逐行解读。无论你是刚刚踏入AI领域的新手,还是正在寻找一个完整、可落地的实战项目,相信这篇文章都能为你点亮一盏明灯。
二、项目核心功能:你的全能AI知识助理
My-Chat-LangChain是一个设计简洁、功能强大的问答平台,它提供了两种构建知识库的核心模式:
-
网页知识库 (Webpage Knowledge Base): 你只需输入任意一个网站的URL,系统便会自动抓取、解析该网站的内容,并在几分钟内构建一个可供对话的知识库。你可以用它来学习在线教程、分析新闻文章,或者快速理解任何网页的核心信息。
-
文档知识库 (Document Knowledge Base): 你可以直接从本地上传PDF文件。系统会智能地解析文档内容,并为你创建一个完全私密的、基于该文档的问答机器人。这对于学习研究报告、阅读法律文件或理解产品手册等场景非常有用。
为了实现优雅、高效的人机交互,整个应用在设计上遵循了几个关键原则:
- 清晰的功能分区: 前端界面采用
Streamlit Tabs(选项卡)设计,将"网页"和"文档"两大功能清晰地隔离开,用户可以自由切换,操作流程一目了然。 - 前后端分离架构: 采用现代Web开发模式,前端(Streamlit)负责用户交互和展示,后端(FastAPI)负责繁重的AI计算和数据处理。这种模式让项目结构更清晰,也更容易维护和扩展。
- 智能缓存机制: 为了提升效率和节省资源,后端设计了一套智能持久化策略。无论是URL还是上传的文件,只要内容不变,系统处理过一次后就会将知识库保存在本地。下次再处理相同内容时,系统会直接加载缓存,实现秒级响应,极大提升了用户体验。
三、技术栈探秘:构建AI应用的"神兵利器"
一个完整的应用,离不开前后端技术的协同配合。本项目精心挑选了一套现代化、高效率的技术栈:
-
前端 (Frontend):
Streamlit: 一个神奇的Python库,能让你用纯Python代码快速构建出漂亮、交互式的Web应用,是AI和数据科学项目敏捷开发的首选。requests: Python中最经典的HTTP客户端库,作为前端与后端API通信的桥梁。
-
后端 (Backend):
FastAPI: 一个现代、高性能的Python Web框架,用于构建API。它的自动文档生成和数据校验功能,让开发和调试变得异常轻松。Uvicorn: 一个闪电般快速的ASGI服务器,是运行FastAPI应用的标配。
-
AI核心 (The Brain):
LangChain: 整个项目的灵魂!它是一个强大的AI应用开发框架,帮助我们轻松地"编排"大语言模型(LLM)、知识库和各种工具,构建复杂的RAG(检索增强生成)管道。Google Gemini: 我们选用Google的gemini-2.5-flash作为大语言模型(LLM),它负责在理解上下文和检索到的知识后,生成最终的自然语言回答。SentenceTransformers: 一个用于生成高质量文本嵌入(Embeddings)的模型库。我们将文本转换成向量,才能在向量数据库中进行高效的相似度搜索。本项目使用的是all-MiniLM-L6-v2这个轻量且高效的模型。ChromaDB: 一个开源的向量数据库,用于存储文本块的向量表示,并提供快速的检索功能。FlashRank: 一个轻量级的重排(Re-ranker)模型。它能在初步检索出一批相关文档后,进行二次精排,选出与问题最最相关的几个文档,极大地提升了问答的精准度。PyPDFLoader: LangChain提供的PDF加载器,用于解析我们上传的PDF文件。
四、代码深度解读:跟我一起"庖丁解牛"
理论说再多,不如看代码来得实在。接下来,我将带你深入项目的核心代码,并附上极其详尽的注释,保证你能看懂每一行!
1. 后端大脑:langchain_qa_backend.py
这个文件是整个RAG流程的核心,它定义了如何处理数据、构建和加载知识库。
python
# backend/langchain_qa_backend.py
import os
import asyncio
import logging
from urllib.parse import urlparse
import hashlib # 导入 hashlib 用于生成 MD5 哈希
# 导入 LangChain 核心组件
from langchain_community.document_loaders import SitemapLoader, RecursiveUrlLoader
from langchain_community.document_loaders import PyPDFLoader # 新增 PyPDFLoader
# 新增导入
from langchain_community.document_transformers import BeautifulSoupTransformer
from langchain.text_splitter import RecursiveCharacterTextSplitter
# ****** 关键修改 1: 导入新的 HuggingFaceEmbeddings ******
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_chroma import Chroma
from langchain_google_genai import ChatGoogleGenerativeAI # 我们仍然使用 Google 的 LLM
# --- 核心修改 1: 使用最新的、最正确的导入路径 ---
from langchain_community.document_compressors import FlashrankRerank
from langchain.retrievers import ContextualCompressionRetriever
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains import create_retrieval_chain
from langchain import hub
from langchain_core.messages import HumanMessage, AIMessage
# 导入 dotenv,用于从 .env 文件加载环境变量
from dotenv import load_dotenv
# 配置日志记录
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
# 加载 .env 文件中的环境变量
load_dotenv()
# 确保 API 密钥已设置 (这对于 ChatGoogleGenerativeAI 仍然是必需的)
if "GOOGLE_API_KEY" not in os.environ:
raise ValueError("GOOGLE_API_KEY not found in environment variables. Please set it in a .env file.")
# --- 新增辅助函数:为 URL 生成唯一的目录名 ---
def get_persist_directory_for_url(url: str) -> str:
"""根据 URL 生成一个唯一的、安全的文件夹名"""
# 使用 MD5 哈希算法,确保任何 URL 都能转换成一个固定长度的字符串
url_hash = hashlib.md5(url.encode('utf-8')).hexdigest()
# 返回一个基于哈希值的路径
return f"./chroma_db_{url_hash}"
# --- 新增辅助函数:为文件生成唯一的目录名 ---
def get_persist_directory_for_file(filename: str, file_content: bytes) -> str:
"""
根据文件名和文件内容的哈希生成唯一的、安全的文件夹名。
这样即使用户上传同名但内容不同的文件,也能被区分。
"""
# 计算文件内容的 MD5 哈希值
file_hash = hashlib.md5(file_content).hexdigest()
# 获取文件名(不含扩展名),并确保其对于路径是安全的
basename = os.path.splitext(filename)[0].replace(" ", "_")
# 结合文件名和内容哈希,创建唯一目录名
return f"./chroma_db_{basename}_{file_hash}"
# --- 核心重构 1: URL 处理函数,专门负责从零构建向量数据库 ---
async def create_vector_store_from_url(url: str, persist_directory: str):
"""
从 URL 抓取、处理文档,并创建一个新的 Chroma 向量数据库并持久化。
"""
logging.info(f"知识库 '{persist_directory}' 不存在,开始从零创建...")
# 1. 文档加载
# ... (这部分逻辑从原函数移动过来,保持不变) ...
parsed_url = urlparse(url)
base_domain_url = f"{parsed_url.scheme}://{parsed_url.netloc}"
sitemap_url = f"{base_domain_url}/sitemap.xml"
loader = SitemapLoader(sitemap_url, filter_urls=[url], continue_on_failure=True, show_progress=True)
documents = await asyncio.to_thread(loader.load)
if not documents:
loader_fallback = RecursiveUrlLoader(url, max_depth=1)
documents = await asyncio.to_thread(loader_fallback.load)
if not documents:
logging.error(f"无法从 {url} 加载任何文档。")
return None
logging.info(f"成功加载 {len(documents)} 篇文档。")
# 1.5. HTML 清洗
bs_transformer = BeautifulSoupTransformer()
cleaned_documents = bs_transformer.transform_documents(documents, unwanted_tags=["script", "style"])
# 2. 文本分割
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
all_splits = text_splitter.split_documents(cleaned_documents)
# 3. 初始化嵌入模型
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2", model_kwargs={'device': 'cpu'})
# 4. 创建并持久化向量存储
logging.info(f"开始为新知识库创建向量存储于 '{persist_directory}'...")
vector_store = Chroma.from_documents(
documents=all_splits,
embedding=embeddings,
persist_directory=persist_directory
)
logging.info("新向量存储创建并持久化完成。")
return vector_store
# --- 核心重构 2: 新增的文件处理函数 ---
async def create_vector_store_from_file(filepath: str, persist_directory: str):
"""
从本地文件路径加载文档,并创建一个新的 Chroma 向量数据库。
"""
logging.info(f"知识库 '{persist_directory}' 不存在,开始从文件 {filepath} 创建...")
try:
# 1. 文档加载
# 根据文件扩展名选择合适的加载器
if filepath.lower().endswith(".pdf"):
loader = PyPDFLoader(filepath)
# 未来可以在这里添加对 .txt, .docx, .md 等文件的支持
# elif filepath.lower().endswith(".txt"):
# loader = TextLoader(filepath)
else:
logging.error(f"不支持的文件类型: {filepath}")
return None
# PyPDFLoader 的 load 是同步阻塞的,所以也用 to_thread
documents = await asyncio.to_thread(loader.load)
if not documents:
logging.error(f"无法从 {filepath} 加载任何文档。")
return None
logging.info(f"成功从文件加载 {len(documents)} 页/篇文档。")
# 2. 文本分割 (PDF 通常不需要复杂的HTML清洗)
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
all_splits = text_splitter.split_documents(documents)
logging.info(f"文档被分割成 {len(all_splits)} 个块。")
# 3. 初始化嵌入模型 (与 URL 版本完全相同)
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2", model_kwargs={'device': 'cpu'})
# 4. 创建并持久化向量存储 (与 URL 版本完全相同)
logging.info(f"开始为新知识库创建向量存储于 '{persist_directory}'...")
vector_store = Chroma.from_documents(
documents=all_splits,
embedding=embeddings,
persist_directory=persist_directory
)
logging.info("新向量存储创建并持久化完成。")
return vector_store
except Exception as e:
logging.error(f"从文件创建向量存储时发生错误: {e}", exc_info=True)
return None
# --- 核心重构 2: 创建一个函数,负责加载现有的数据库 ---
def load_vector_store(persist_directory: str):
"""
从指定的磁盘目录加载一个已存在的 Chroma 向量数据库。
"""
logging.info(f"开始从 '{persist_directory}' 加载现有知识库...")
# 嵌入模型必须和创建时使用的模型完全一样
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2", model_kwargs={'device': 'cpu'})
# 直接使用 Chroma 的构造函数加载
vector_store = Chroma(
persist_directory=persist_directory,
embedding_function=embeddings
)
logging.info("现有知识库加载完成。")
return vector_store
def get_retrieval_chain(base_retriever):
"""
(函数被重构) 根据基础检索器,创建一个包含本地开源 Rerank 模型的高级 RAG 链。
"""
if base_retriever is None: return None
# --- 核心修改 2: 初始化本地 FlashrankRerank ---
logging.info("初始化本地 FlashrankRerank 模型...")
# FlashrankRerank 会自动从 Hugging Face 下载并缓存重排序模型
# 第一次运行时会需要一些时间下载
reranker = FlashrankRerank( top_n=20 )
logging.info("本地 Rerank 模型加载完成。")
# --- 核心修改 3: 创建上下文压缩检索器 (逻辑不变) ---
# 这里的逻辑和使用 Cohere 时完全一样,我们只是把"复赛评委"换成了本地模型
compression_retriever = ContextualCompressionRetriever(
base_compressor=reranker,
base_retriever=base_retriever
)
logging.info("上下文压缩检索器 (带本地重排功能) 创建成功。")
# --- 后续构建 RAG 链的步骤完全不变 ---
model = ChatGoogleGenerativeAI(model="gemini-2.5-flash", temperature=0.3)
retrieval_qa_chat_prompt = hub.pull("langchain-ai/retrieval-qa-chat")
combine_docs_chain = create_stuff_documents_chain(
model, retrieval_qa_chat_prompt
)
retrieval_chain = create_retrieval_chain(compression_retriever, combine_docs_chain)
logging.info("带本地 Rerank 功能的高级 RAG 问答链创建成功。")
return retrieval_chain2. 后端服务员:main.py
这个文件使用FastAPI框架,负责接收前端发来的请求,调用langchain_qa_backend.py中的函数进行处理,然后把结果返回给前端。
python
# backend/main.py
from fastapi import FastAPI, HTTPException, UploadFile, File, Form
from pydantic import BaseModel, Field
from typing import List, Dict, Any # 引入 Dict 和 Any 用于更灵活的类型定义
import numpy as np # 导入 numpy 库,以便我们能识别它的类型
import os # 导入 os 库来检查文件夹是否存在
import json
import tempfile
import hashlib
# 导入我们重构后的后端逻辑模块
from langchain_qa_backend import (
create_vector_store_from_url,
create_vector_store_from_file,
load_vector_store,
get_retrieval_chain,
get_persist_directory_for_url,
get_persist_directory_for_file
)
from langchain_core.messages import HumanMessage, AIMessage
# --- 1. 初始化 FastAPI 应用 ---
app = FastAPI(
title="Enterprise RAG Backend API",
description="An API for the RAG application powered by LangChain and Google Gemini.",
version="1.0.0",
)
# --- 2. 简单的内存缓存 ---
rag_chain_cache = {}
# --- 3. 定义 API 数据模型 (核心修改) ---
class ChatHistoryItem(BaseModel):
"""定义聊天历史中单条消息的结构"""
role: str
content: str
class ChatRequest(BaseModel):
"""定义 /chat 接口的请求体结构"""
url: str
query: str
chat_history: List[ChatHistoryItem]
# --- 新增模型:定义单个源文档的数据结构 ---
class SourceDocument(BaseModel):
"""定义返回给前端的单个源文档的结构"""
page_content: str = Field(..., description="源文档的文本内容片段")
metadata: Dict[str, Any] = Field({}, description="源文档的元数据,通常包含来源URL等")
class ChatResponse(BaseModel):
"""
定义 /chat 接口的响应体结构
--- 核心修改:新增 source_documents 字段 ---
"""
answer: str = Field(..., description="由RAG系统生成的回答")
source_documents: List[SourceDocument] = Field([], description="答案所依据的源文档列表")
# --- 4. 新增:一个用于清理 NumPy 类型的辅助函数 ---
def clean_metadata(metadata: dict) -> dict:
"""
递归地遍历元数据字典,将所有 numpy.float32 类型转换为标准的 float 类型。
"""
cleaned = {}
for key, value in metadata.items():
if isinstance(value, np.float32):
cleaned[key] = float(value)
elif isinstance(value, dict):
cleaned[key] = clean_metadata(value)
else:
cleaned[key] = value
return cleaned
# --- 4. API 端点 ---
@app.get("/", tags=["Health Check"])
def read_root():
return {"status": "ok", "message": "Welcome to the RAG Backend API v4.0!"}
# --- URL 问答端点 (逻辑重构) ---
@app.post("/chat_url", response_model=ChatResponse, tags=["RAG Chat"])
async def chat_url_endpoint(request: ChatRequest):
url = request.url
query = request.query
if url in rag_chain_cache:
retrieval_chain = rag_chain_cache[url]
print(f"从内存缓存中获取 RAG 链 (URL): {url}")
else:
persist_directory = get_persist_directory_for_url(url)
if os.path.exists(persist_directory):
print(f"从磁盘加载知识库 (URL): {persist_directory}")
vector_store = load_vector_store(persist_directory)
else:
print(f"创建新知识库 (URL): {url}")
vector_store = await create_vector_store_from_url(url, persist_directory)
if not vector_store:
raise HTTPException(status_code=500, detail="Failed to process URL.")
base_retriever = vector_store.as_retriever(search_kwargs={"k": 20})
retrieval_chain = get_retrieval_chain(base_retriever)
if not retrieval_chain:
raise HTTPException(status_code=500, detail="Failed to create RAG chain.")
rag_chain_cache[url] = retrieval_chain
print(f"RAG 链已为 URL {url} 创建并缓存。")
# --- 后续调用逻辑 (与文件端点复用) ---
return await invoke_rag_chain(retrieval_chain, query, request.chat_history)
# --- 新增:文件问答端点 ---
@app.post("/chat_file", response_model=ChatResponse, tags=["RAG Chat"])
async def chat_file_endpoint(
query: str = Form(...),
chat_history_str: str = Form("[]"),
file: UploadFile = File(...)
):
# 1. 安全地处理上传的文件
# 使用 with 语句确保临时目录在操作完成后被自动清理
with tempfile.TemporaryDirectory() as temp_dir:
temp_filepath = os.path.join(temp_dir, file.filename)
# 读取文件内容用于计算哈希和写入临时文件
file_content = await file.read()
with open(temp_filepath, "wb") as f:
f.write(file_content)
# 2. 持久化与加载逻辑
persist_directory = get_persist_directory_for_file(file.filename, file_content)
# 使用持久化目录作为内存缓存的 key,因为它是唯一的
if persist_directory in rag_chain_cache:
retrieval_chain = rag_chain_cache[persist_directory]
print(f"从内存缓存中获取 RAG 链 (File): {file.filename}")
else:
if os.path.exists(persist_directory):
print(f"从磁盘加载知识库 (File): {persist_directory}")
vector_store = load_vector_store(persist_directory)
else:
print(f"创建新知识库 (File): {file.filename}")
vector_store = await create_vector_store_from_file(temp_filepath, persist_directory)
if not vector_store:
raise HTTPException(status_code=500, detail="Failed to process File.")
base_retriever = vector_store.as_retriever(search_kwargs={"k": 20})
retrieval_chain = get_retrieval_chain(base_retriever)
if not retrieval_chain:
raise HTTPException(status_code=500, detail="Failed to create RAG chain.")
rag_chain_cache[persist_directory] = retrieval_chain
print(f"RAG 链已为文件 {file.filename} 创建并缓存。")
# 3. 解析聊天历史并调用链
chat_history = json.loads(chat_history_str)
return await invoke_rag_chain(retrieval_chain, query, chat_history)
# --- 修改:复用的 RAG 调用函数 ---
async def invoke_rag_chain(chain, query: str, history: List[Any]): # 将类型提示改为更通用的 List[Any]
"""
一个可复用的函数,用于格式化历史记录、调用 RAG 链并处理响应。
现在它可以同时接受字典列表和 Pydantic 对象列表。
"""
# 格式化聊天历史
formatted_chat_history = []
for item in history:
# --- 核心修改:使用 hasattr 和 getattr 来安全地访问属性 ---
# 这种方式对字典 (用 .get()) 和对象 (用 .) 都有效
if isinstance(item, dict):
# 如果是字典,使用 .get()
role = item.get("role")
content = item.get("content")
else:
# 如果是 Pydantic 对象,使用 .role 和 .content
role = item.role
content = item.content
if role == "user":
formatted_chat_history.append(HumanMessage(content=content))
elif role == "assistant":
formatted_chat_history.append(AIMessage(content=content))
try:
# 调用链 (后续逻辑不变)
response = chain.invoke({
"input": query,
"chat_history": formatted_chat_history
})
# 清洗并格式化源文档
source_documents = response.get("context", [])
formatted_sources = [
SourceDocument(page_content=doc.page_content, metadata=clean_metadata(doc.metadata))
for doc in source_documents
]
return ChatResponse(answer=response["answer"], source_documents=formatted_sources)
except Exception as e:
print(f"调用 RAG 链时出错: {e}")
raise HTTPException(status_code=500, detail=str(e))3. 前端展示台:app.py
这是用户直接交互的界面,用Streamlit构建,代码非常直观易懂。
python
# frontend/app.py
import streamlit as st
import requests
import json
import os
# --- 1. API 配置 (保持不变) ---
BACKEND_URL_ENDPOINT = "http://127.0.0.1:8000/chat_url"
BACKEND_FILE_ENDPOINT = "http://127.0.0.1:8000/chat_file"
# --- 2. 页面配置 & 样式加载 (保持不变) ---
st.set_page_config(
page_title="Chat LangChain | Enterprise Edition",
page_icon="🔗",
layout="wide",
initial_sidebar_state="expanded"
)
def load_css(file_path):
with open(file_path) as f:
st.markdown(f"<style>{f.read()}</style>", unsafe_allow_html=True)
load_css("style.css")
# --- 3. API 调用函数 (保持不变) ---
def get_backend_response_from_url(url: str, query: str, chat_history: list):
# ... (函数内容不变)
try:
payload = {"url": url, "query": query, "chat_history": chat_history}
proxies = {"http": None, "https": None}
response = requests.post(BACKEND_URL_ENDPOINT, json=payload, timeout=180, proxies=proxies)
response.raise_for_status()
return response.json()
except Exception as e:
return {"answer": f"请求后端服务时出错 (URL): {e}", "source_documents": []}
def get_backend_response_from_file(query: str, chat_history: list, uploaded_file):
# ... (函数内容不变)
try:
files = {'file': (uploaded_file.name, uploaded_file.getvalue(), uploaded_file.type)}
data = {'query': query, 'chat_history_str': json.dumps(chat_history)}
proxies = {"http": None, "https": None}
response = requests.post(BACKEND_FILE_ENDPOINT, files=files, data=data, timeout=300, proxies=proxies)
response.raise_for_status()
return response.json()
except Exception as e:
return {"answer": f"请求后端服务时出错 (File): {e}", "source_documents": []}
# --- 4. 侧边栏内容 (保持不变) ---
with st.sidebar:
# ... (内容不变)
st.markdown("## 🔗 Chat LangChain v4.0", unsafe_allow_html=True)
st.markdown("---")
st.markdown("**v4.0 新增功能:**\n- **文档知识库:** 新增了通过上传 PDF 文件进行问答的功能。\n\n**工作模式:**\n1. **网页知识库:** 在 Tab 中输入 URL 进行在线内容问答。\n2. **文档知识库:** 在 Tab 中上传 PDF 文件进行本地文档问答。\n")
st.markdown("---")
st.markdown("**核心技术:**\n- 前端: Streamlit\n- 后端: FastAPI\n- RAG: LangChain, ChromaDB, SentenceTransformers, Flashrank\n")
# --- 5. 主内容区域 ---
st.title("My Chat LangChain 🤖 (Enterprise Edition)")
tab_url, tab_file = st.tabs(["🔗 网页知识库", "📄 文档知识库"])
# --- Tab 1: 网页知识库 (逻辑微调) ---
with tab_url:
st.header("与在线网页内容对话")
if "url_messages" not in st.session_state:
st.session_state.url_messages = []
if "current_url" not in st.session_state:
st.session_state.current_url = "https://python.langchain.com/docs/modules/agents/"
col1, col2 = st.columns([3, 1])
with col1:
new_url = st.text_input("知识库 URL:", st.session_state.current_url, key="url_input")
with col2:
st.selectbox("模型:", ["Gemini 2.5 Flash (Backend)"], disabled=True, key="url_model_select")
if st.session_state.current_url != new_url:
st.session_state.current_url = new_url
st.session_state.url_messages = []
st.info(f"网页知识库已切换到: {new_url}。")
st.rerun()
# 渲染历史消息 (逻辑不变)
for message in st.session_state.url_messages:
# ... (渲染逻辑不变)
avatar = "🧑💻" if message["role"] == "user" else "🤖"
with st.chat_message(message["role"], avatar=avatar):
st.markdown(message["content"])
if message["role"] == "assistant" and "sources" in message and message["sources"]:
with st.expander("📖 查看答案来源"):
for i, source in enumerate(message["sources"]):
source_url = source.get("metadata", {}).get("source", "未知来源")
st.markdown(f"**来源 {i+1}:** [{source_url}]({source_url})")
st.markdown(f"> {source['page_content']}")
if i < len(message["sources"]) - 1: st.markdown("---")
# --- 核心修改:将输入框移到 Tab 逻辑的末尾 ---
if prompt := st.chat_input("就当前网页提问..."):
st.session_state.url_messages.append({"role": "user", "content": prompt})
with st.chat_message("user", avatar="🧑💻"):
st.markdown(prompt)
with st.chat_message("assistant", avatar="🤖"):
with st.spinner("正在基于网页内容思考..."):
response_data = get_backend_response_from_url(
url=st.session_state.current_url,
query=prompt,
chat_history=st.session_state.url_messages[:-1]
)
answer = response_data.get("answer", "抱歉,出错了。")
sources = response_data.get("source_documents", [])
st.markdown(answer)
if sources:
with st.expander("📖 查看答案来源"):
for i, source in enumerate(sources):
source_url = source.get("metadata", {}).get("source", "未知来源")
st.markdown(f"**来源 {i+1}:** [{source_url}]({source_url})")
st.markdown(f"> {source['page_content']}")
if i < len(sources) - 1: st.markdown("---")
st.session_state.url_messages.append({"role": "assistant", "content": answer, "sources": sources})
# 添加 rerun 确保来源展开器状态正确更新
st.rerun()
# --- Tab 2: 文档知识库 (核心重构) ---
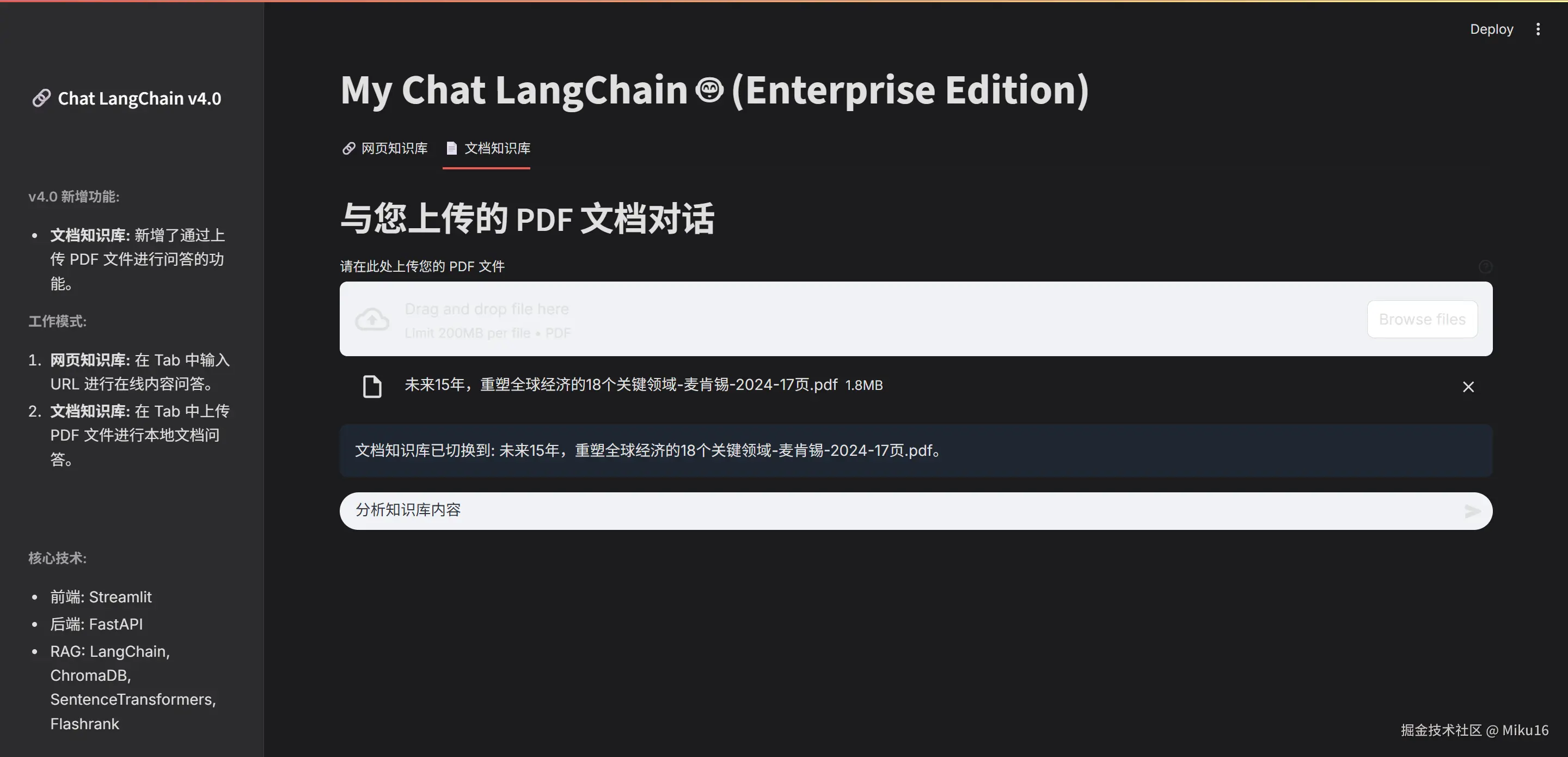
with tab_file:
st.header("与您上传的 PDF 文档对话")
if "file_messages" not in st.session_state:
st.session_state.file_messages = []
if "current_file_id" not in st.session_state:
st.session_state.current_file_id = None
uploaded_file = st.file_uploader(
"请在此处上传您的 PDF 文件",
type=['pdf'],
help="上传后,您可以就该文档的内容进行提问。"
)
# --- 核心修改:使用 uploaded_file.file_id 替换 .id ---
if uploaded_file and (st.session_state.current_file_id != uploaded_file.file_id):
st.session_state.current_file_id = uploaded_file.file_id
st.session_state.file_messages = []
st.info(f"文档知识库已切换到: {uploaded_file.name}。")
# 渲染历史消息 (逻辑不变)
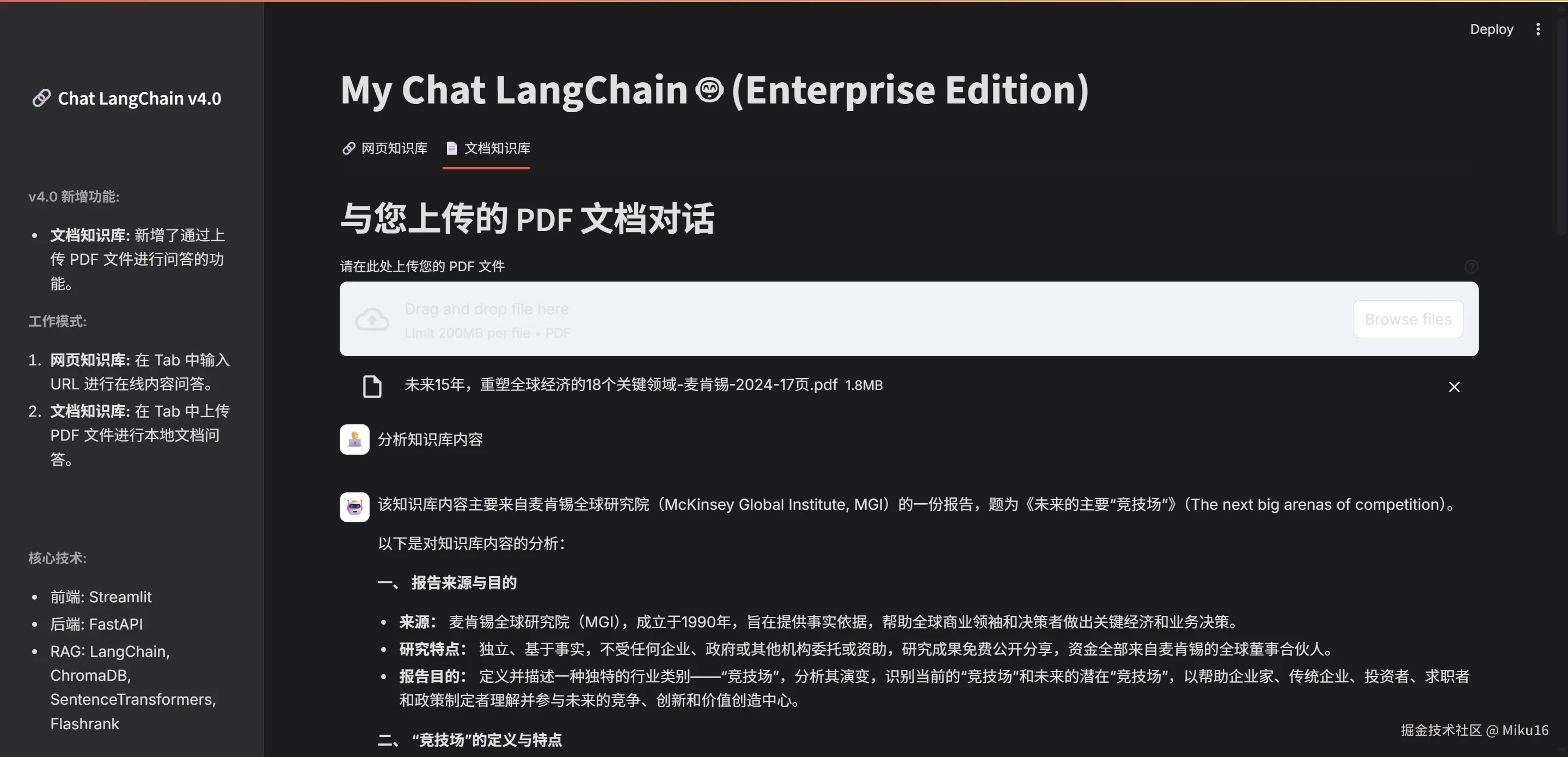
for message in st.session_state.file_messages:
# ... (渲染逻辑不变)
avatar = "🧑💻" if message["role"] == "user" else "🤖"
with st.chat_message(message["role"], avatar=avatar):
st.markdown(message["content"])
if message["role"] == "assistant" and "sources" in message and message["sources"]:
with st.expander("📖 查看答案来源"):
for i, source in enumerate(message["sources"]):
page_num = source.get("metadata", {}).get("page", -1)
st.markdown(f"**来源 {i+1}:** 第 {page_num + 1} 页")
st.markdown(f"> {source['page_content']}")
if i < len(message["sources"]) - 1: st.markdown("---")
# --- 核心修改:将输入框移到 Tab 逻辑的末尾,并用 disabled 参数控制 ---
# 如果没有上传文件,输入框会显示但不可用
if prompt := st.chat_input(
f"就 {uploaded_file.name} 提问..." if uploaded_file else "请先上传一个 PDF 文件",
disabled=not uploaded_file
):
st.session_state.file_messages.append({"role": "user", "content": prompt})
with st.chat_message("user", avatar="🧑💻"):
st.markdown(prompt)
with st.chat_message("assistant", avatar="🤖"):
with st.spinner("正在基于文档内容思考..."):
response_data = get_backend_response_from_file(
query=prompt,
chat_history=st.session_state.file_messages[:-1],
uploaded_file=uploaded_file
)
answer = response_data.get("answer", "抱歉,出错了。")
sources = response_data.get("source_documents", [])
st.markdown(answer)
if sources:
with st.expander("📖 查看答案来源"):
for i, source in enumerate(sources):
page_num = source.get("metadata", {}).get("page", -1)
st.markdown(f"**来源 {i+1}:** 第 {page_num + 1} 页")
st.markdown(f"> {source['page_content']}")
if i < len(sources) - 1: st.markdown("---")
st.session_state.file_messages.append({"role": "assistant", "content": answer, "sources": sources})
# 添加 rerun 确保来源展开器状态正确更新
st.rerun()五、如何运行:三步启动你的AI知识库
想亲手体验一下吗?非常简单!
准备工作:
-
确保你已经安装了Python和Git。
-
克隆项目代码到本地:
powershellgit clone https://github.com/16Miku/LangChain-Learning.git cd LangChain-Learning/My-Chat-LangChain -
在项目根目录(
My-Chat-LangChain)下创建一个.env文件,并填入你的Google API密钥: GOOGLE_API_KEY="你的API密钥"
启动步骤:
-
安装依赖:
powershell# 激活虚拟环境 # 确保所有库都已安装 pip install fastapi "uvicorn[standard]" langchain langchain-community langchain-core langchain-google-genai langchain-huggingface sentence-transformers langchain-chroma python-dotenv beautifulsoup4 tqdm FlagEmbedding flashrank numpy pypdf streamlit requests -
启动后端服务: 打开一个PowerShell终端,进入
backend目录,运行:powershelluvicorn main:app --reload
看到Application startup complete.就表示后端成功启动了!
-
启动前端应用: 再打开一个PowerShell终端,进入
frontend目录,运行:powershellstreamlit run app.py浏览器会自动打开一个新的页面,你就可以开始和你的AI知识库互动了!
六、效果展示
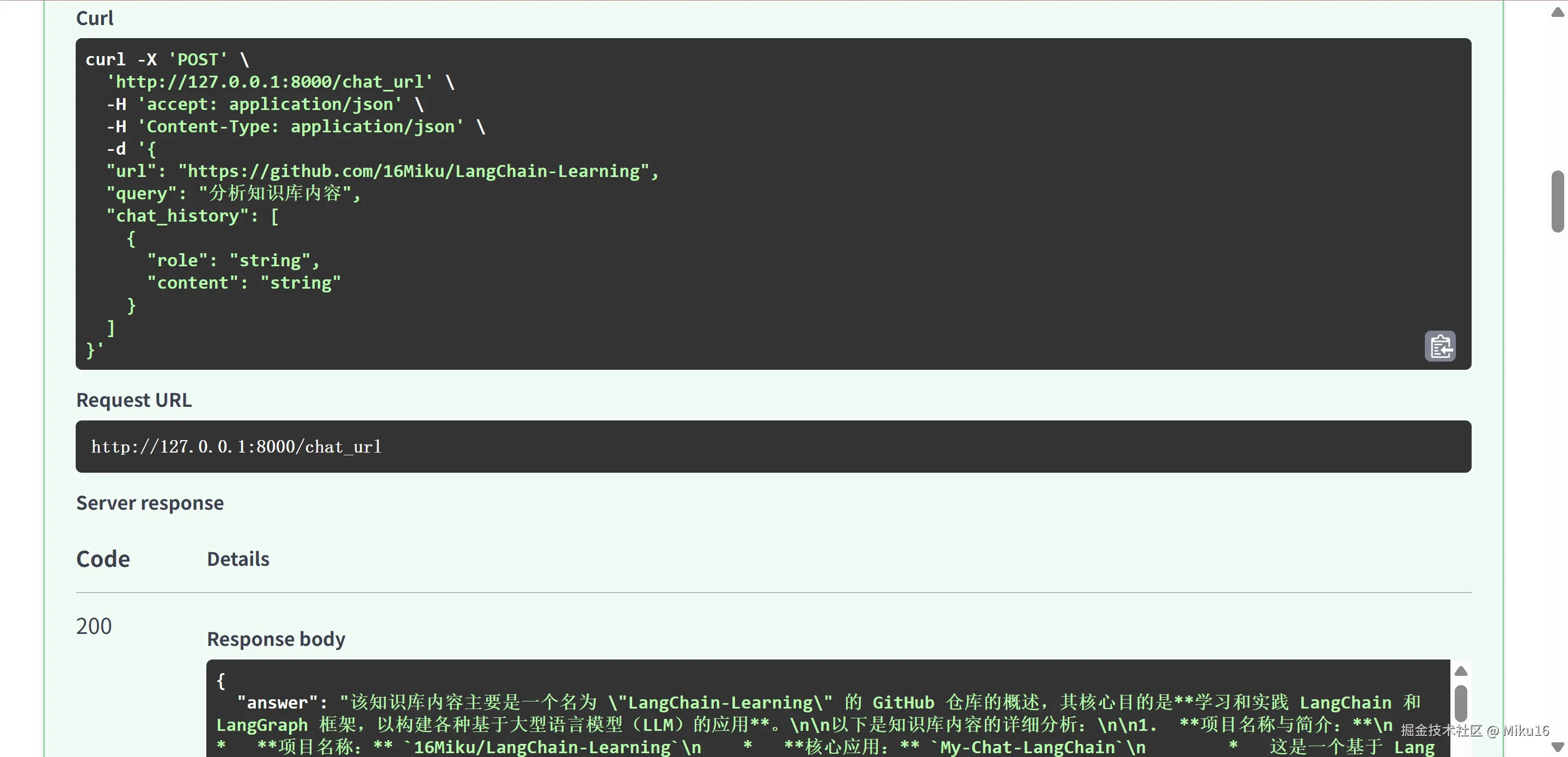
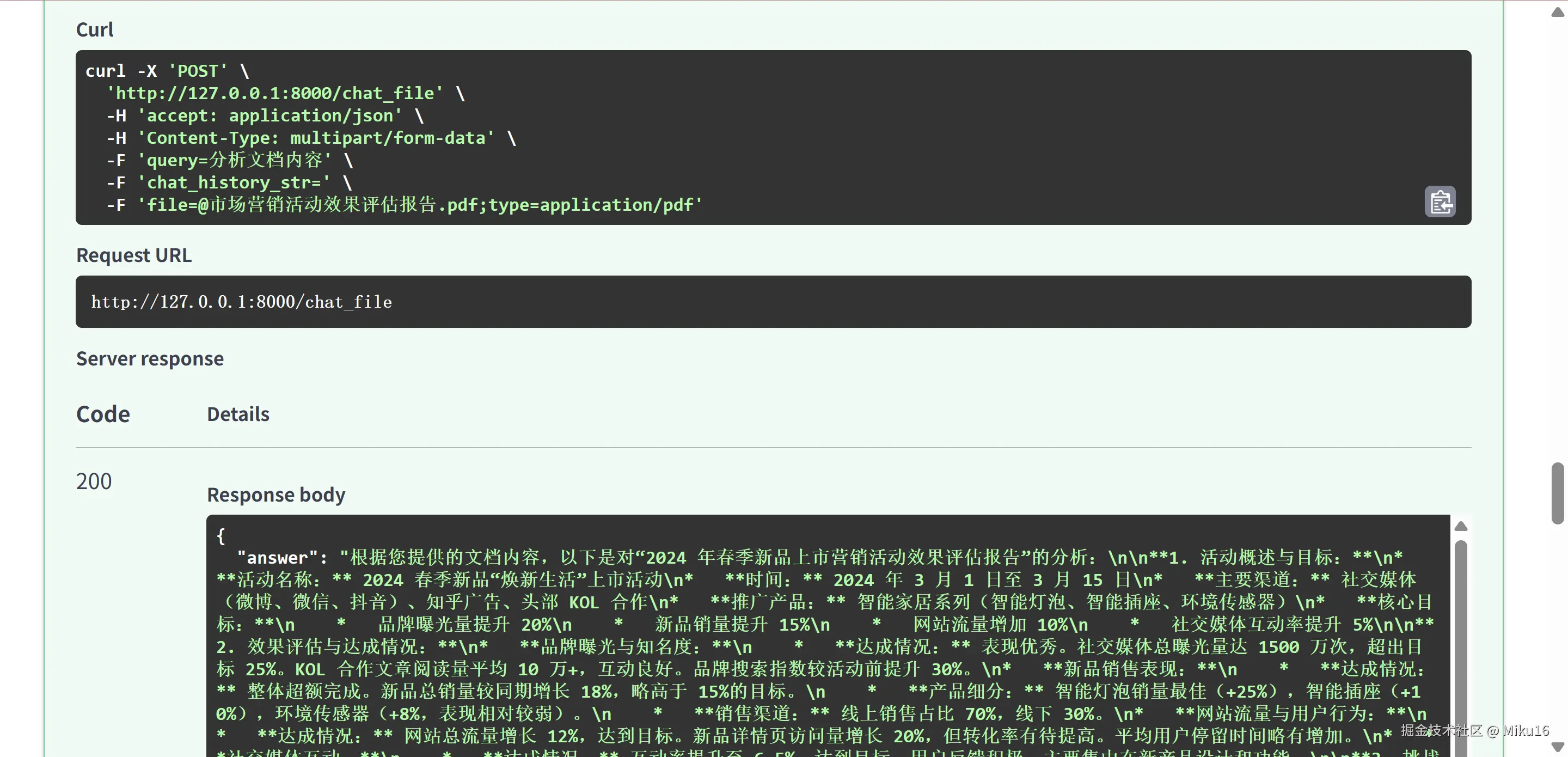
后端FastAPI接口测试
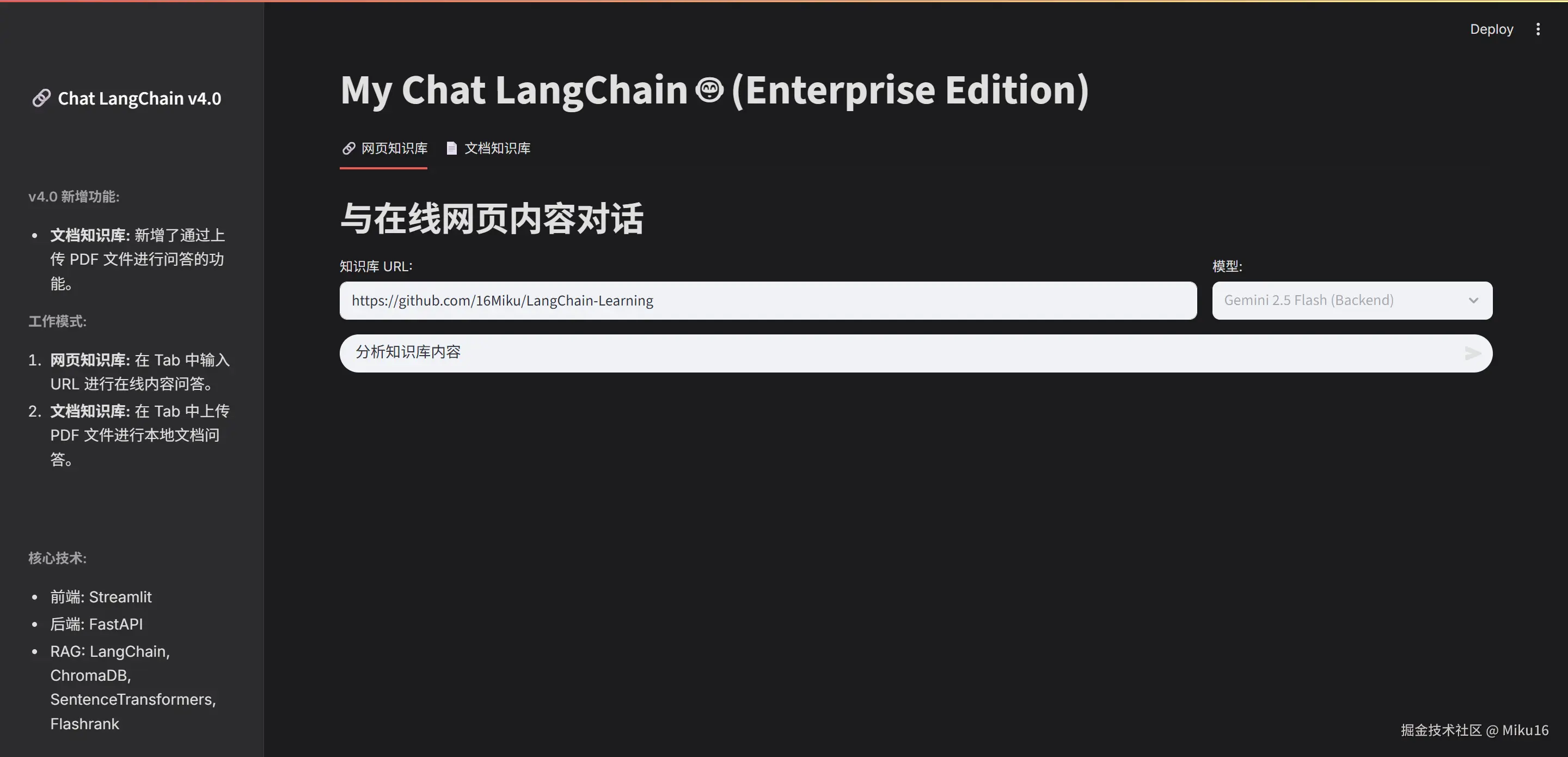
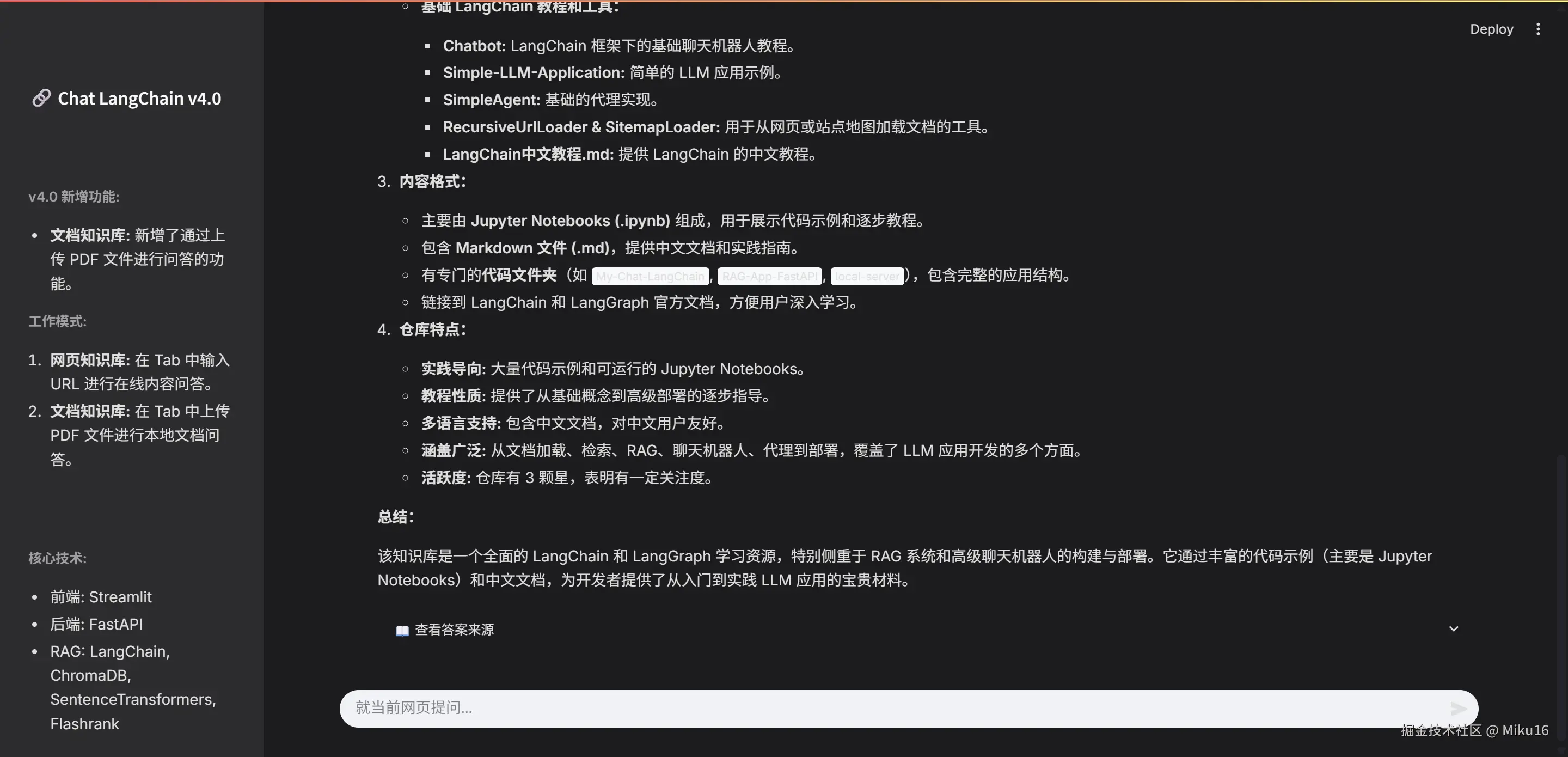
网页知识库效果

文档知识库效果
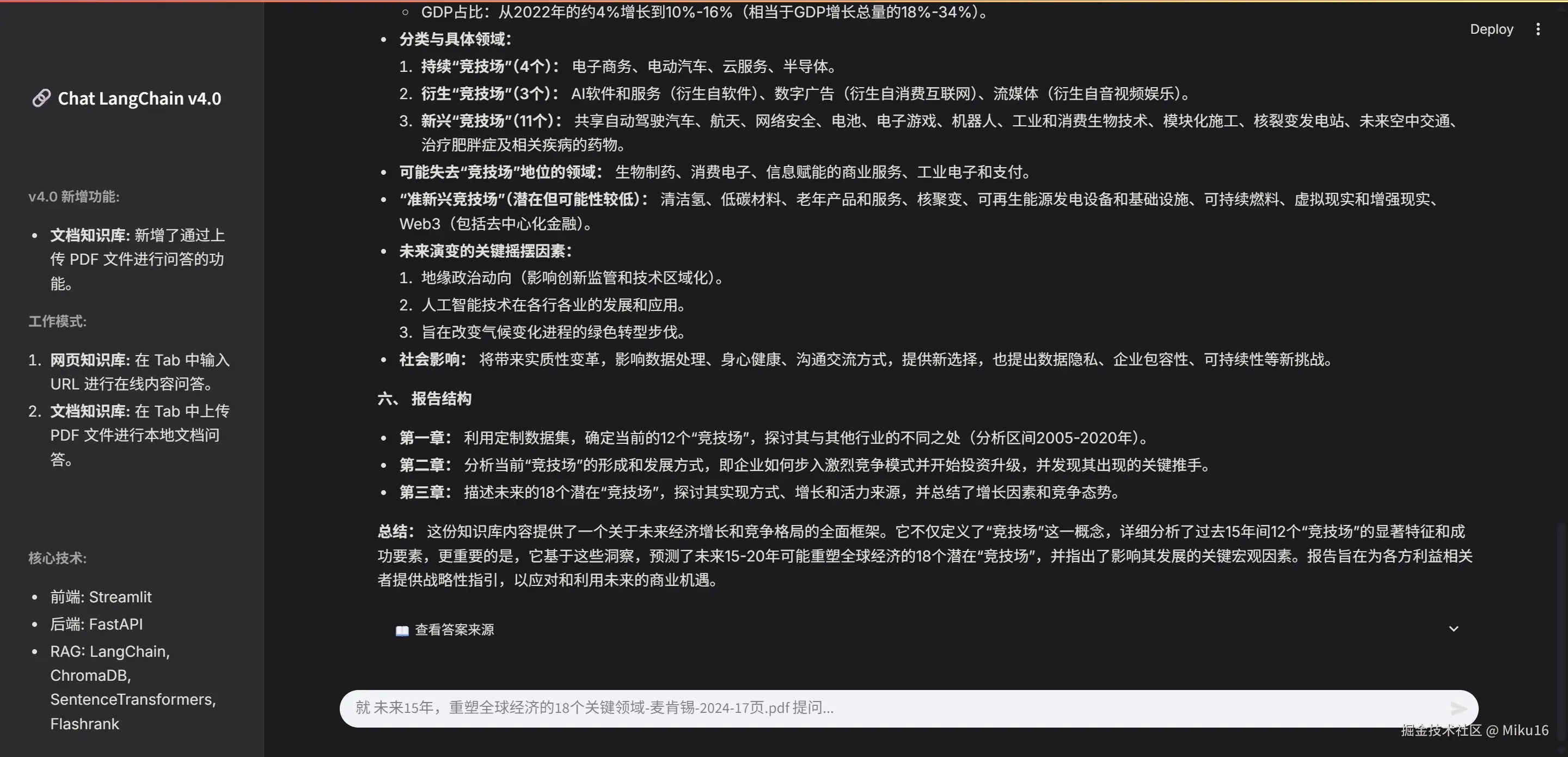
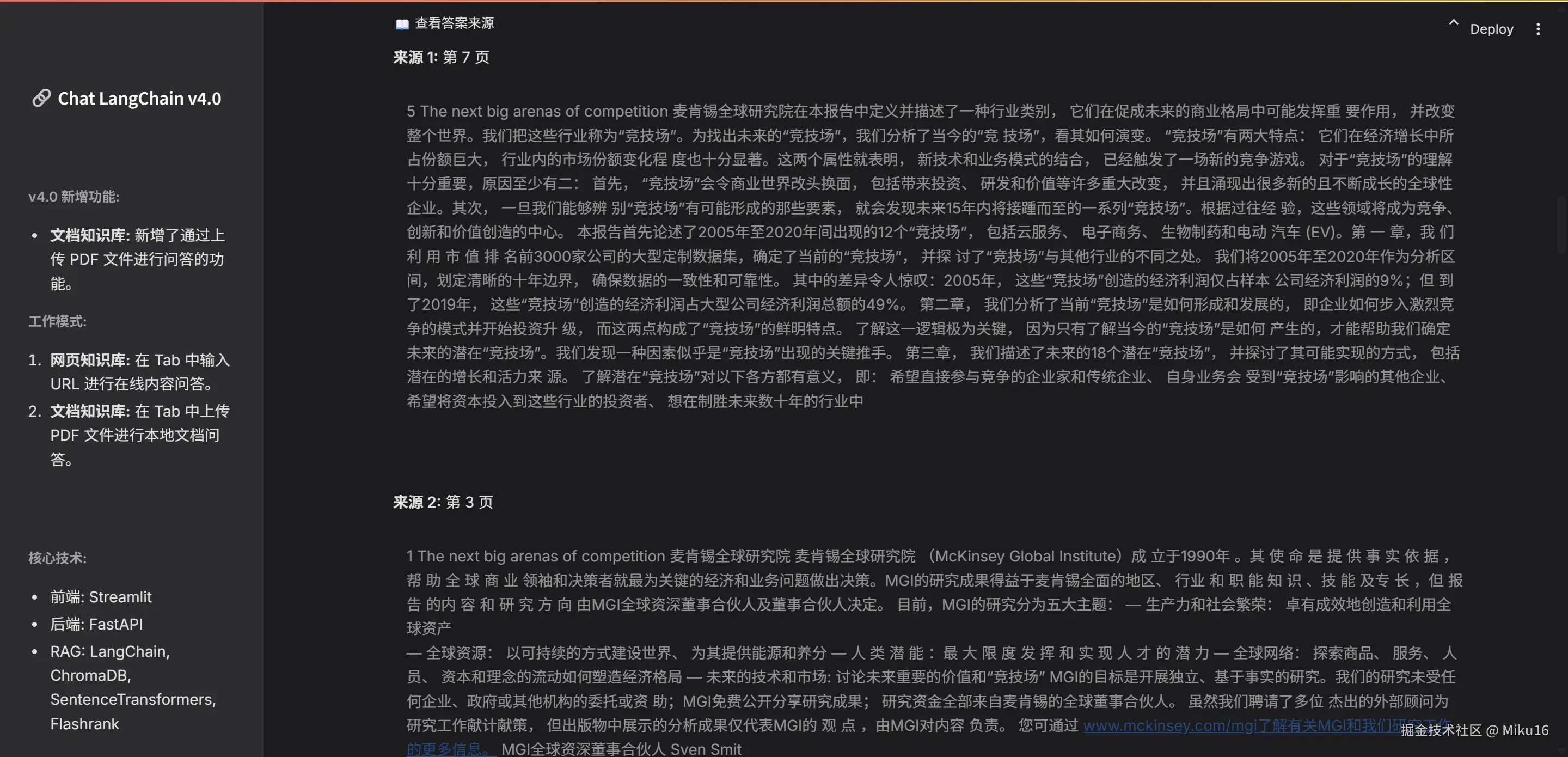
七、结语与展望
My-Chat-LangChain项目是一个绝佳的起点,它向我们展示了如何将多个强大的框架(LangChain, FastAPI, Streamlit)有机地结合起来,构建一个功能完整、体验流畅的全栈AI应用。通过这个项目,你可以学习到企业级RAG系统的核心思想、前后端分离的工程实践、以及通过缓存等手段优化性能的技巧。
当然,技术的探索永无止境,这个项目也为未来的扩展留下了广阔的空间:
- 支持更多文档格式: 比如
.txt,.docx,.md等。 - 会话管理: 允许用户保存和加载不同的聊天会话。
- 模型切换: 在前端提供选项,让用户可以切换不同的LLM或嵌入模型。
- 容器化部署: 使用Docker将其打包,实现一键部署,让更多人能轻松使用。
希望这次的深度解析能为你打开一扇通往AI应用开发世界的大门。项目的完整代码已在GitHub开源,我非常欢迎大家提出问题、建议,或是贡献代码。让我们一起在构建AI的道路上不断前行!